n8n + Pinecone + ModelScope:知识库向量查询工作流实战

🎏:你只管努力,剩下的交给时间
🏠 :小破站
n8n + Pinecone + ModelScope:知识库向量查询工作流实战
- 前言
- 环境准备
- 工作流设计
- 创建 Webhook 接收请求
- 验证 API Key
- 生成查询向量
- 格式化查询参数
- 执行向量检索
- 格式化输出结果
- 返回最终结果
- 验证效果
- 总结
- 感谢
前言
在构建智能知识库系统时,如何快速实现语义检索是个核心问题。本文记录了使用 n8n 搭建知识库查询工作流的完整过程,采用 ModelScope 生成文本向量,通过 Pinecone 进行相似度检索,整个流程通过 Webhook 对外提供 API 服务。
这套方案的优势在于无需编写后端代码,通过可视化节点编排就能实现企业级的向量检索服务,适合快速验证技术方案或为现有系统增加智能检索能力。
环境准备
需要提前准备以下资源:
- n8n 实例:已部署并可通过域名访问(本文使用
https://your-n8n-domain.com) - ModelScope API:用于生成文本 Embedding,需要申请 API Key
- Pinecone 向量数据库:已创建索引,记录下 API URL 和 Key
- API 密钥管理:准备一个用于验证请求来源的密钥(如
your-secret-api-key)
确保 n8n 已配置好 Header Auth 凭证,分别添加 ModelScope 和 Pinecone 的认证信息。
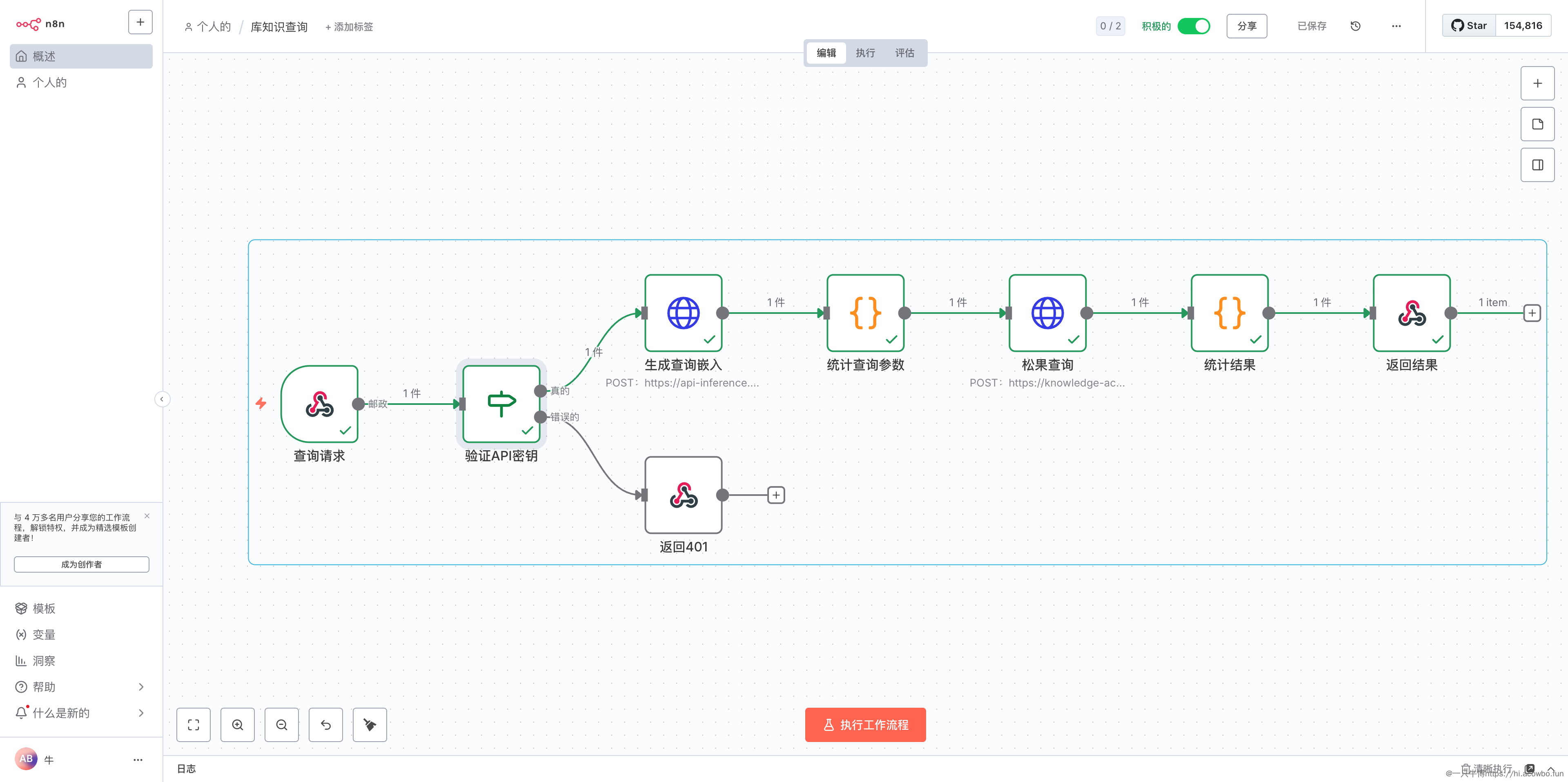
工作流设计
整个查询流程分为五个核心环节:接收查询请求、验证身份、生成查询向量、执行向量检索、格式化返回结果。下面通过实际配置来展示每个节点的作用。
创建 Webhook 接收请求
在 n8n 中新建工作流,第一个节点选择 Webhook,配置如下关键参数:
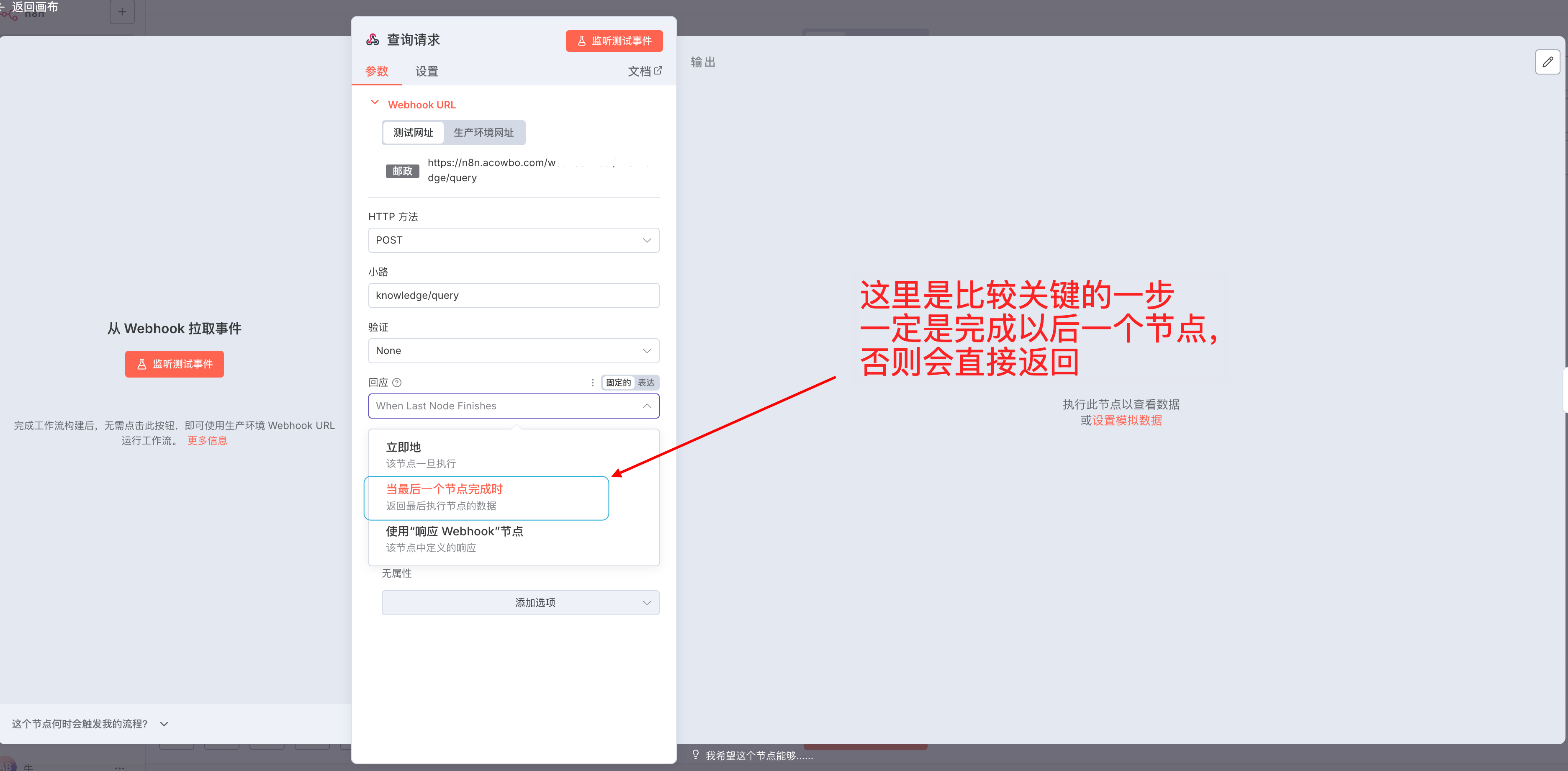
HTTP 方法选择 POST,路径设置为 knowledge/query,这样生成的完整 URL 就是 https://your-n8n-domain.com/webhook/knowledge/query。需要注意的是,响应方式必须选择 “使用 Respond to Webhook 节点”,否则会在节点执行完就立即返回,无法控制最终的响应内容。
Webhook 验证选择 None,因为我们会在后续节点中手动验证 API Key,这样能更灵活地控制错误返回格式。
验证 API Key
为了防止接口被滥用,需要验证请求头中的密钥。添加一个 If 节点,从 Webhook 的输出中提取 x-api-key 请求头进行比对:
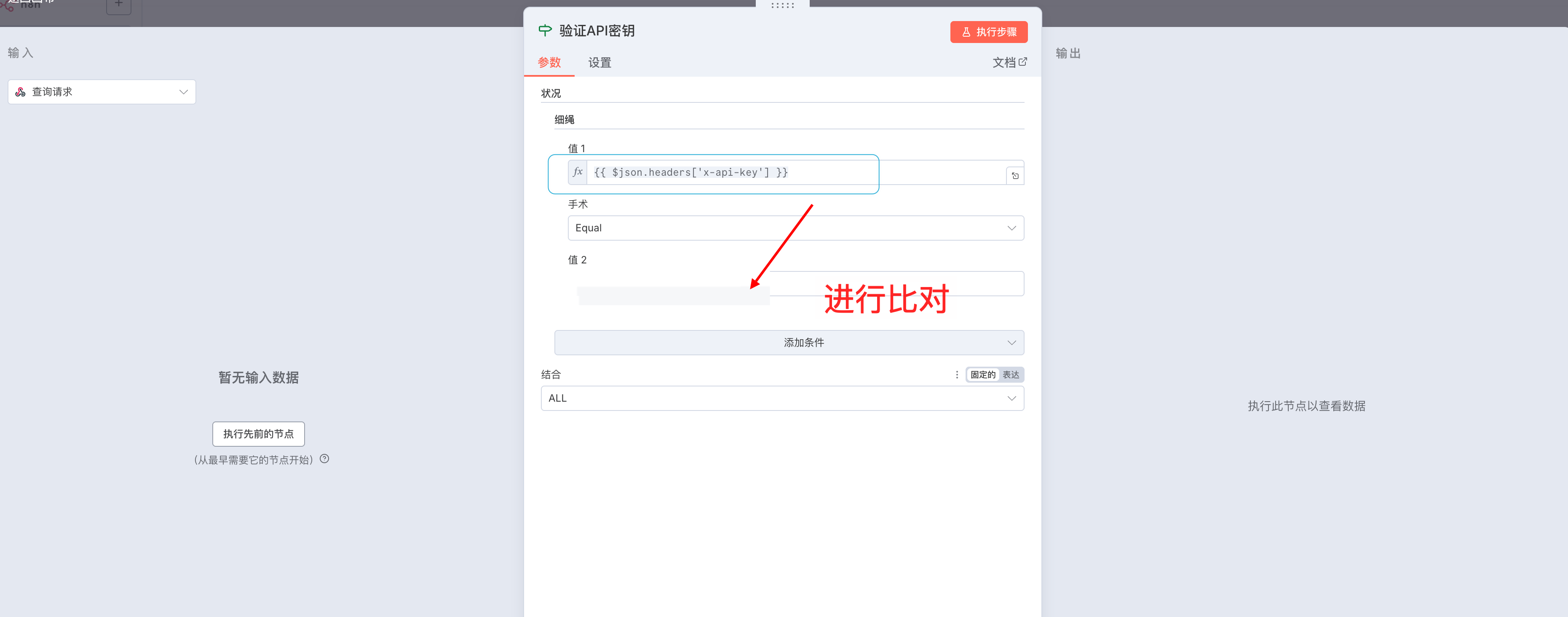
条件配置为:{{ $json.headers['x-api-key'] }} 等于 your-secret-api-key(替换为你自己的密钥)。如果验证失败,连接到一个 Respond to Webhook 节点返回 401 错误:
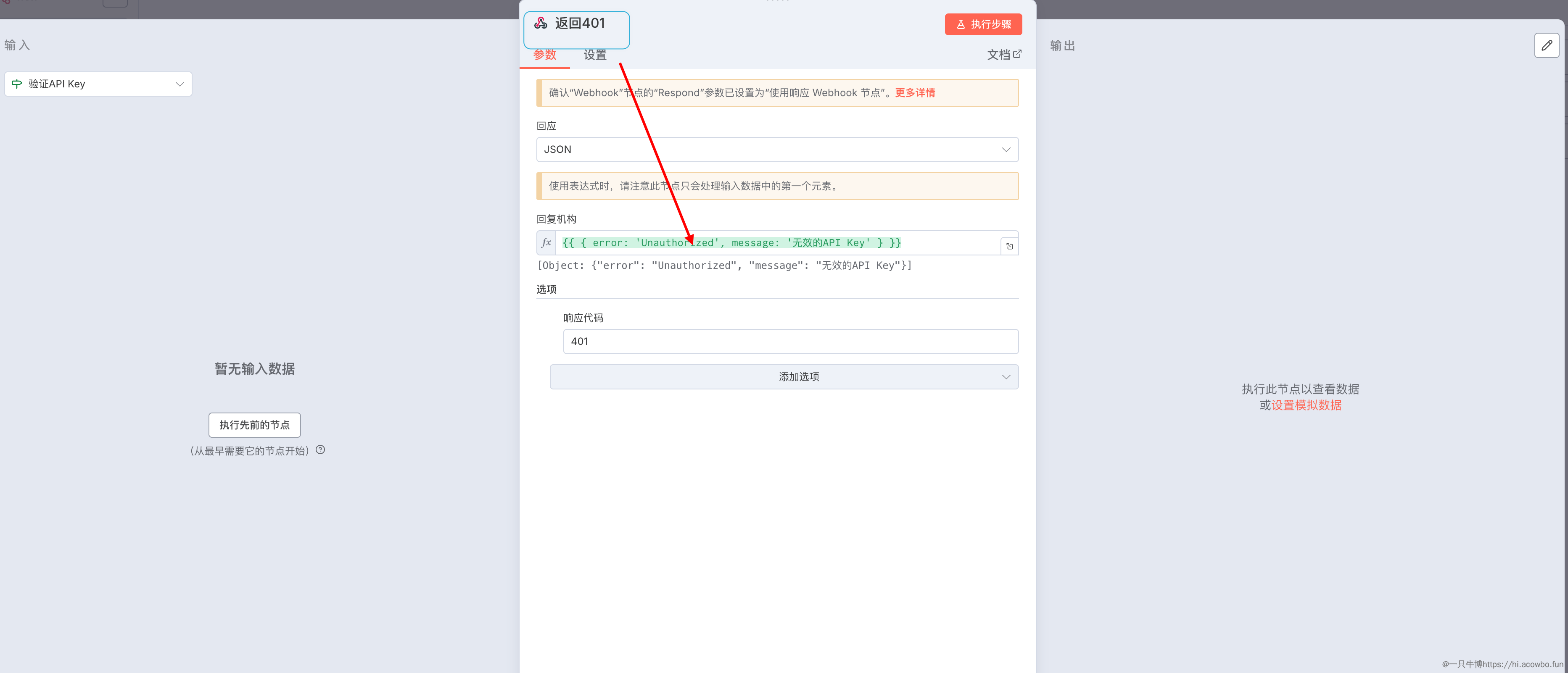
响应格式选择 JSON,内容设置为:
{"error": "Unauthorized","message": "无效的 API Key"
}
响应代码填写 401。这样当密钥错误时,调用方能清晰地知道问题所在,而不是收到模糊的执行失败提示。
生成查询向量
验证通过后,需要调用 ModelScope 的 Embedding 接口,将用户的查询文本转换为向量。添加一个 HTTP Request 节点:
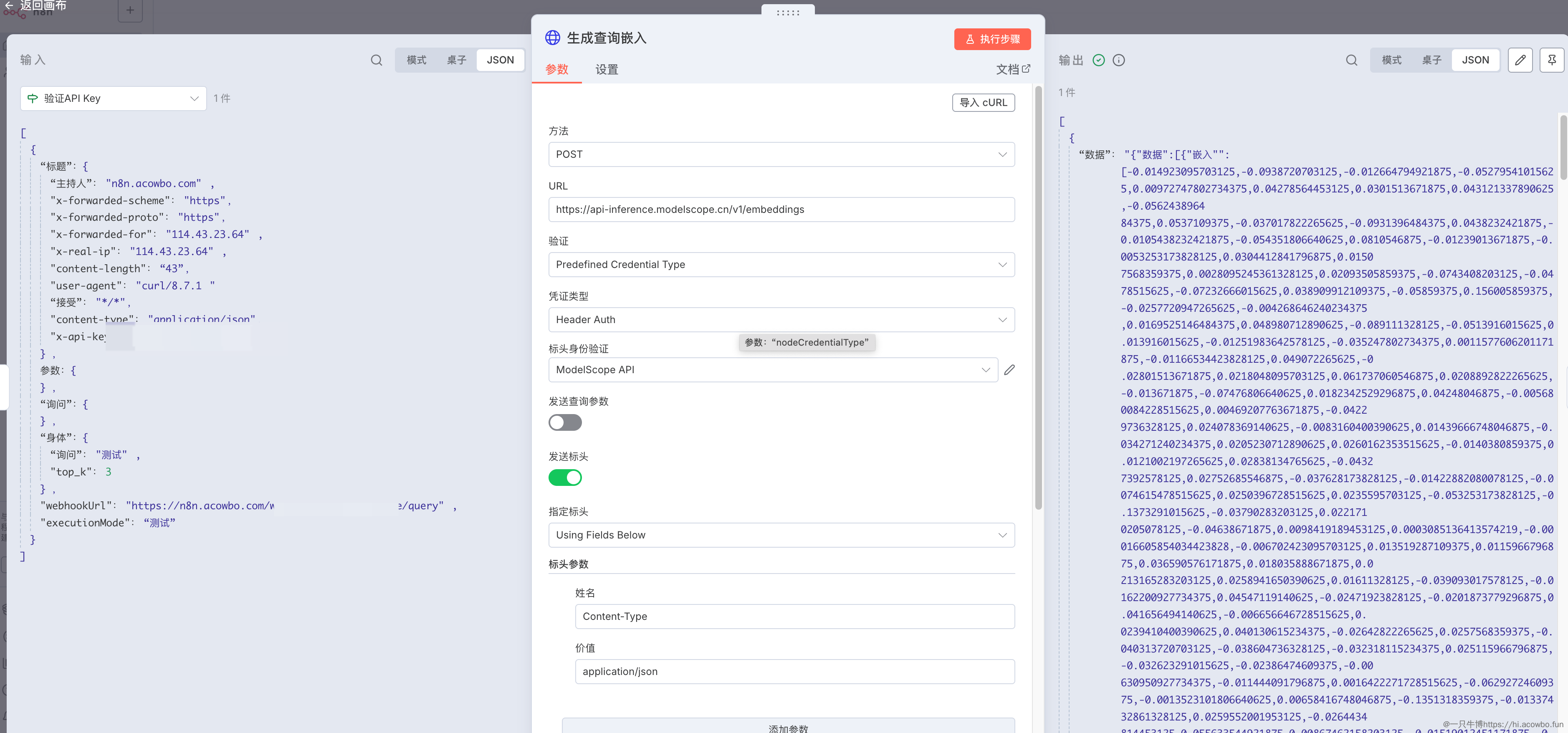
关键配置项:
-
URL:
https://api-inference.modelscope.cn/v1/embeddings -
认证方式:选择之前配置的 ModelScope API 凭证(Header Auth)
-
请求体:
{"model": "Qwen/Qwen3-Embedding-0.6B","input": "{{ $json.body.query }}","encoding_format": "float" }
这里从 Webhook 请求体中提取 query 字段作为输入文本。ModelScope 会返回一个包含向量数组的 JSON 响应,数据嵌套在 data.data[0].embedding 路径下。
格式化查询参数
拿到向量后,需要转换成 Pinecone 接受的查询格式。添加一个 Code 节点,使用 JavaScript 处理数据:
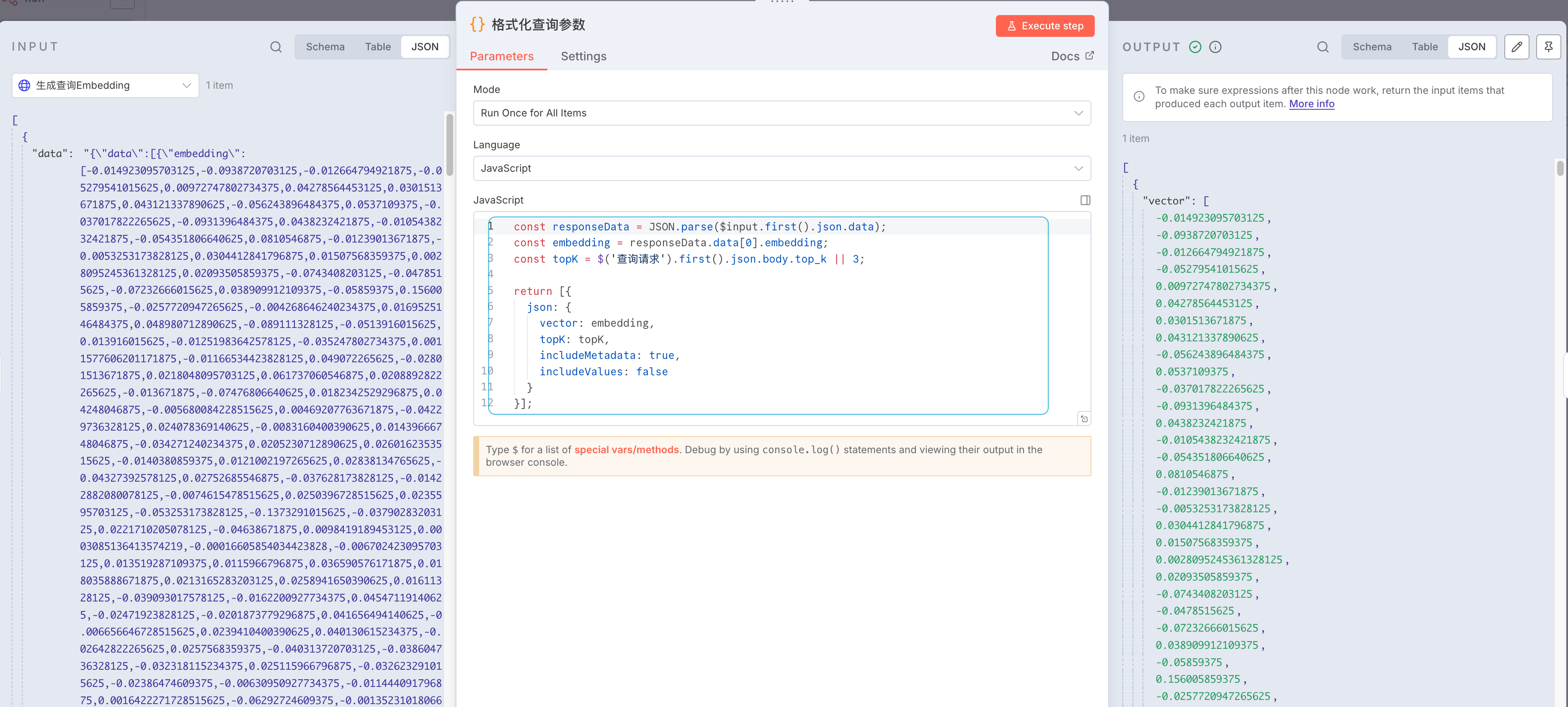
const responseData = JSON.parse($input.first().json.data);
const embedding = responseData.data[0].embedding;
const topK = $('查询请求').first().json.body.top_k || 3;return [{json: {vector: embedding,topK: topK,includeMetadata: true,includeValues: false}
}];
这段代码做了三件事:解析 ModelScope 返回的数据、提取向量数组、构造 Pinecone 查询对象。topK 参数允许调用方指定返回结果数量,默认为 3。includeMetadata 设置为 true 可以拿到文档的元数据(文件名、分块索引、上传时间等),而 includeValues 设置为 false 能减少响应体积。
执行向量检索
添加 HTTP Request 节点调用 Pinecone 的查询接口:
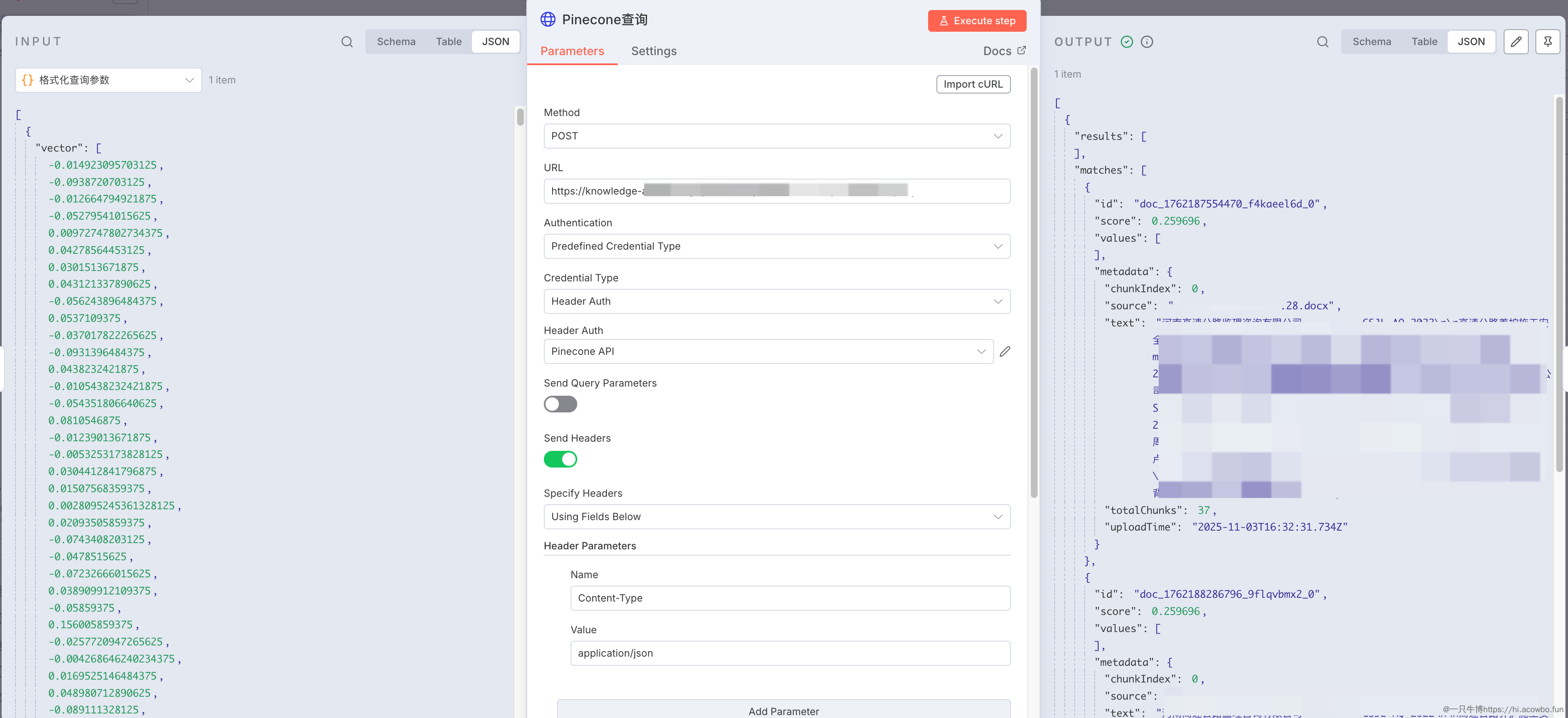
配置 POST 请求到你的 Pinecone 索引地址,格式类似 https://your-index-name.svc.region.pinecone.io/query。请求体引用上一步的输出:
{"vector": "{{ $json.vector }}","topK": "{{ $json.topK }}","includeMetadata": "{{ $json.includeMetadata }}","includeValues": "{{ $json.includeValues }}"
}
Pinecone 会返回最相似的 K 个文档,每个结果包含文档 ID、相似度得分和元数据。
格式化输出结果
Pinecone 的原始响应格式对前端不够友好,需要再次转换。添加 Code 节点:
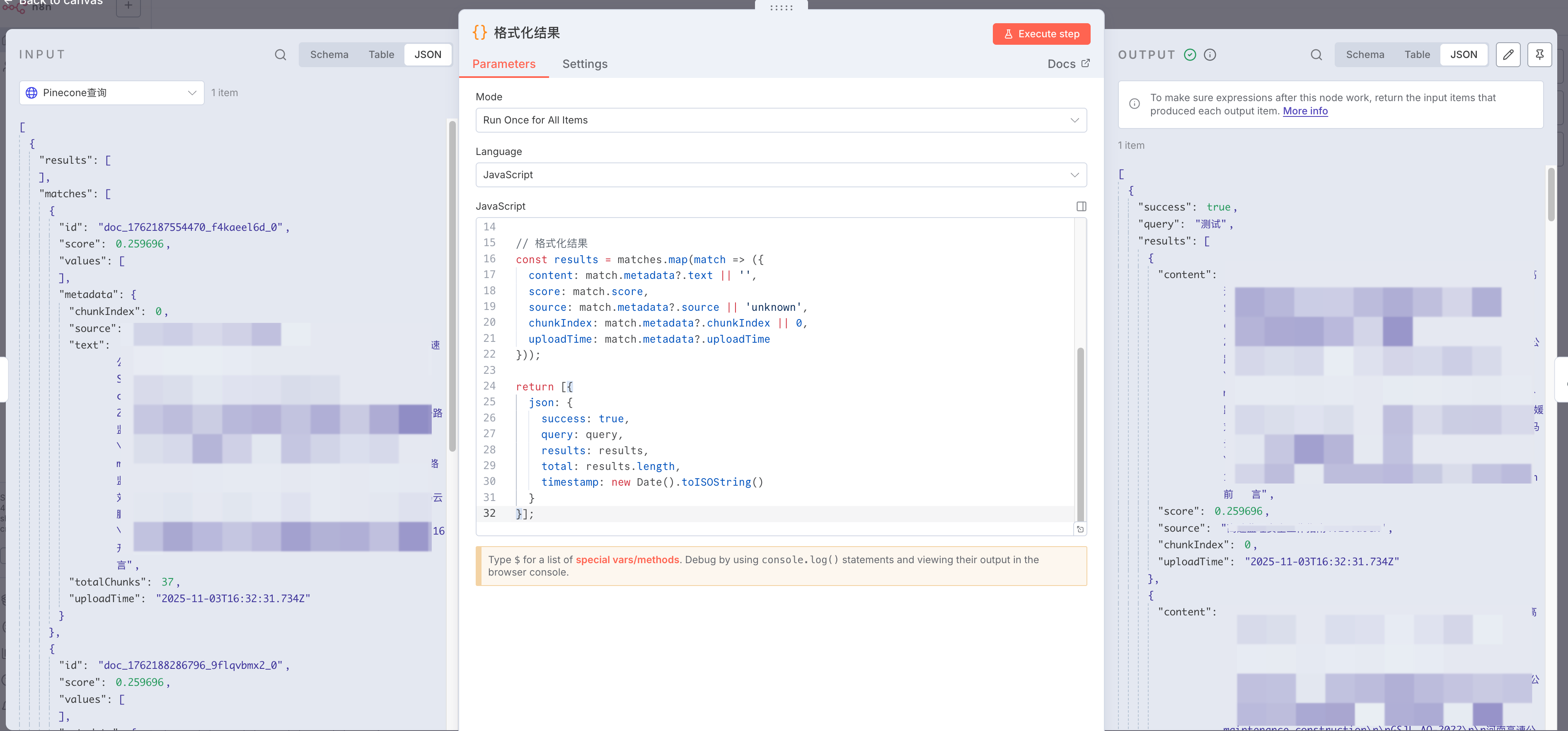
const query = $('查询请求').first().json.body.query;
const matches = $json.matches;// 格式化结果
const results = matches.map(match => ({content: match.metadata?.text || '',score: match.score,source: match.metadata?.source || 'unknown',chunkIndex: match.metadata?.chunkIndex || 0,uploadTime: match.metadata?.uploadTime || ''
}));return [{json: {success: true,query: query,results: results,total: results.length,timestamp: new Date().toISOString()}
}];
这个转换的核心目的是提取必要字段、统一命名、增加业务标记(success、timestamp)。content 字段存储的是文档的文本内容,score 是相似度得分(0-1之间),source 标识文档来源文件名。
返回最终结果
最后添加 Respond to Webhook 节点,响应格式选择 JSON,内容直接引用上一步的输出:
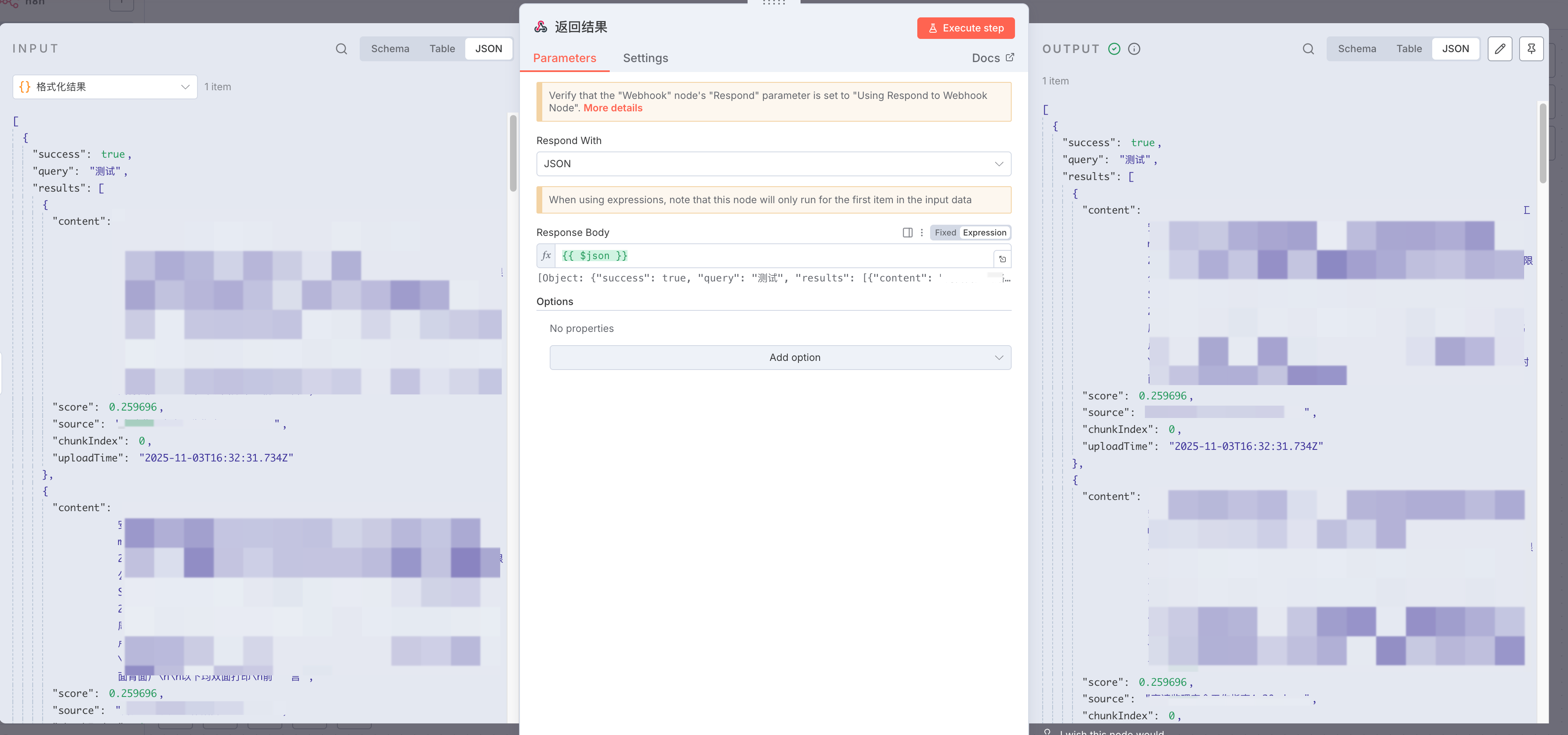
{{ $json }}
这样客户端会收到一个结构清晰的 JSON 响应,包含查询词、匹配结果列表、总数和时间戳。
验证效果
保存并激活工作流后,通过 curl 测试查询接口:
curl -X POST https://your-n8n-domain.com/webhook/knowledge/query \-H "Content-Type: application/json" \-H "x-api-key: your-secret-api-key" \-d '{"query": "测试","top_k": 3}'
成功后会返回类似这样的响应:
{"success": true,"query": "测试","results": [{"content": "测试文档内容:这是一个简单的测试。","score": 0.668823719,"source": "测试文档.txt","chunkIndex": 0,"uploadTime": "2025-10-27T13:10:49.807Z"}],"total": 3,"timestamp": "2025-11-03T14:14:14.248Z"
}
从 n8n 的执行记录可以看到,所有节点都成功执行,响应时间在可接受范围内。相似度得分 0.67 说明找到了较为相关的内容,如果得分低于 0.5 通常意味着查询与知识库内容关联不强。
总结
通过 n8n 搭建向量检索服务的过程相当直观,核心在于理解数据在各个节点间的流转和转换。Webhook 负责接收请求并控制响应时机,If 节点用于权限控制和流程分支,HTTP Request 节点调用外部服务,Code 节点则处理复杂的数据转换逻辑。这套流程不仅适用于知识库查询,稍作调整就能扩展到文档上传、批量检索、智能推荐等场景,关键是把握好每个环节的输入输出格式。
感谢
感谢你读到这里,说明你已经成功地忍受了我的文字考验!🎉
希望这篇文章没有让你想砸电脑,也没有让你打瞌睡。
如果有一点点收获,那我就心满意足了。
未来的路还长,愿你
遇见难题不慌张,遇见bug不抓狂,遇见好内容常回访。
记得给自己多一点耐心,多一点幽默感,毕竟生活已经够严肃了。
如果你有想法、吐槽或者想一起讨论的,欢迎留言,咱们一起玩转技术,笑对人生!😄
祝你代码无bug,生活多彩,心情常青!🚀
