零基础学AI大模型之嵌入模型性能优化
| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LangChain Embedding框架全解析 |
前情摘要
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的“幻觉”
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
本文章目录
- 前情摘要
- 零基础学AI大模型之嵌入模型性能优化
- 一、需求背景:为什么要优化嵌入模型?
- 二、嵌入计算的四大核心痛点
- 三、解决方案:缓存机制的核心价值
- 四、LangChain缓存方案:CacheBackedEmbeddings详解
- 4.1 技术架构图
- 4.2 核心语法与参数说明
- 基础导入与初始化
- 关键参数解析
- 4.3 支持的存储类型
- 五、应用案例:智能客服知识库加速
- 5.1 无缓存方案(传统方式)
- 5.2 有缓存方案(优化后)
- 5.3 高级配置:分布式场景(Redis缓存)
- 六、实战对比:缓存前后性能差异
- 6.1 关键API区别(面试易错点!)
- 6.2 编码实战:计时对比
- 6.3 输出结果(实际环境测试)
- 七、最佳实践建议
- 7.1 适用场景
- 7.2 存储选择策略
- 7.3 进阶优化技巧
- 八、总结
零基础学AI大模型之嵌入模型性能优化
大家好,我是工藤学编程 🦉 ,一个专注于实战技术分享的小博主~ 在上一篇内容中,我们详细拆解了RAG系统的文档处理链路,而嵌入模型作为RAG的核心组件,其性能直接决定了系统的响应速度和运维成本。今天就来深入聊聊嵌入模型的性能优化方案——缓存机制,这既是生产环境的核心优化手段,也是大厂面试的高频考点,建议收藏细品!
一、需求背景:为什么要优化嵌入模型?
在RAG系统中,嵌入模型的作用是将文本(文档/查询)转换为高维向量,为后续的相似度检索提供基础。但在实际应用中,嵌入计算往往会成为系统的性能瓶颈,这也是面试中经常被问到的“RAG系统优化痛点”之一。
先看一组真实场景数据:某智能客服知识库包含10万条QA对,使用OpenAI Embeddings计算嵌入时,单次全量计算需要消耗约200元API费用,单条查询响应时间约800ms,且每天因重复计算浪费30%的资源——这正是大多数开发者在落地RAG时会遇到的问题。
二、嵌入计算的四大核心痛点
- 生成成本高:无论是调用商业API(如OpenAI、DashScope)还是部署本地大模型,嵌入计算都需要消耗大量计算资源(CPU/GPU),批量处理时成本显著上升;
- 重复计算浪费:知识库中的文本(如产品说明、法律条款)往往长期不变,多次调用模型生成相同嵌入会造成严重的资源浪费;
- API调用限制:商业嵌入模型API普遍存在调用频率、并发数限制,高流量场景下容易触发限流,影响系统可用性;
- 响应速度瓶颈:实时场景(如智能客服、实时检索)对响应延迟要求极高(通常需≤100ms),直接调用模型计算嵌入无法满足需求。
三、解决方案:缓存机制的核心价值
针对上述痛点,缓存(Cache) 是最直接有效的优化方案。其核心逻辑是:将首次计算的嵌入结果存储起来,后续遇到相同文本时直接读取缓存,无需重复调用模型。具体优势如下:
- 降低计算成本:相同文本只需计算一次,重复率越高,成本节省越明显(如知识库场景可降低30%-80%的API费用);
- 提升响应速度:缓存读取速度比模型计算快10-100倍(本地缓存≈10ms,Redis缓存≈2ms,模型计算≈100-1000ms);
- 突破API限制:本地缓存/分布式缓存不受远程API配额限制,可支撑更高并发;
- 支持离线场景:网络不可用时,仍能读取历史嵌入结果,保证系统基础功能可用。
四、LangChain缓存方案:CacheBackedEmbeddings详解
LangChain作为大模型开发的“瑞士军刀”,提供了专门的缓存装饰器——CacheBackedEmbeddings,可无缝集成各类嵌入模型和存储介质,无需手动实现缓存逻辑。
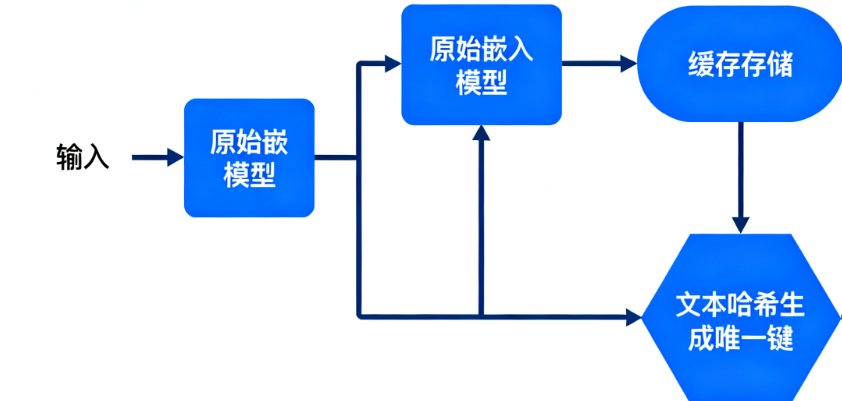
4.1 技术架构图
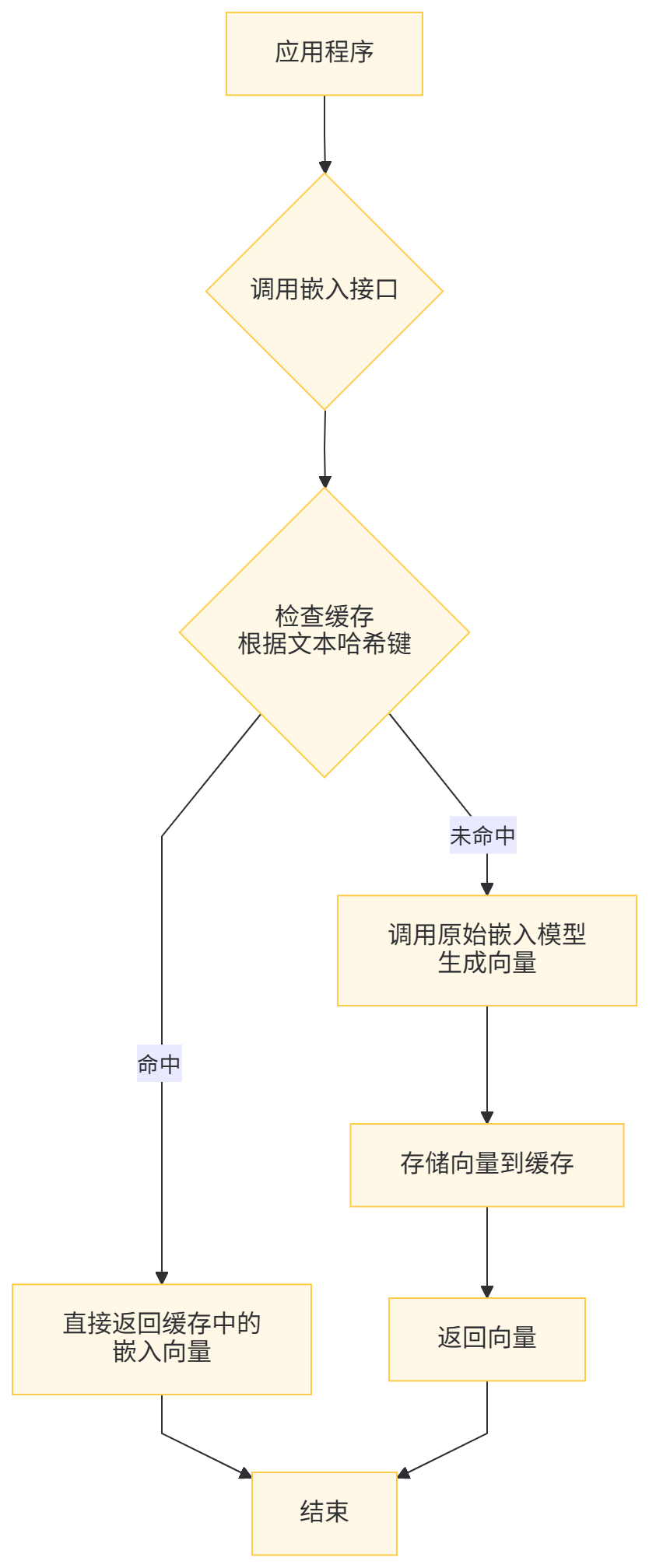
注:CacheBackedEmbeddings采用文本哈希生成唯一键(默认使用SHA-256),确保相同文本对应唯一缓存键,避免冲突。
4.2 核心语法与参数说明
基础导入与初始化
# 导入核心组件
from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings
from langchain.storage import LocalFileStore# 1. 初始化原始嵌入模型(如OpenAI Embeddings)
embedding_model = OpenAIEmbeddings(openai_api_key="sk-xxx")# 2. 初始化缓存存储(以本地文件存储为例)
storage = LocalFileStore("./embedding_cache/") # 缓存文件存储目录# 3. 组合缓存与嵌入模型(装饰器模式)
cached_embedder = CacheBackedEmbeddings(underlying_embeddings=embedding_model, # 原始嵌入模型document_embedding_store=storage, # 缓存存储对象namespace="openai-v3" # 可选:命名空间(隔离不同项目/模型版本)
)
关键参数解析
| 参数名 | 类型 | 作用说明 |
|---|---|---|
| underlying_embeddings | Embeddings | 原始嵌入模型实例(如OpenAIEmbeddings、DashScopeEmbeddings、本地模型等) |
| document_embedding_store | BaseStore | 缓存存储实现类(LangChain提供多种开箱即用的存储方案) |
| namespace | str | 缓存命名空间,用于隔离不同项目或模型版本(如“openai-v3”和“openai-v2”分开存储) |
4.3 支持的存储类型
LangChain的langchain.storage模块提供多种存储方案,适配不同场景:
# langchain.storage 支持的存储类型
__all__ = ["InMemoryStore", # 内存存储(最快,重启丢失)"LocalFileStore", # 本地文件存储(零配置,易调试)"RedisStore", # Redis存储(分布式,高并发)"UpstashRedisStore", # Upstash Redis(Serverless,无需运维)"EncoderBackedStore", # 自定义编码存储(支持复杂数据类型)
]
五、应用案例:智能客服知识库加速
以“10万条QA对的智能客服知识库”为例,对比无缓存和有缓存方案的差异。
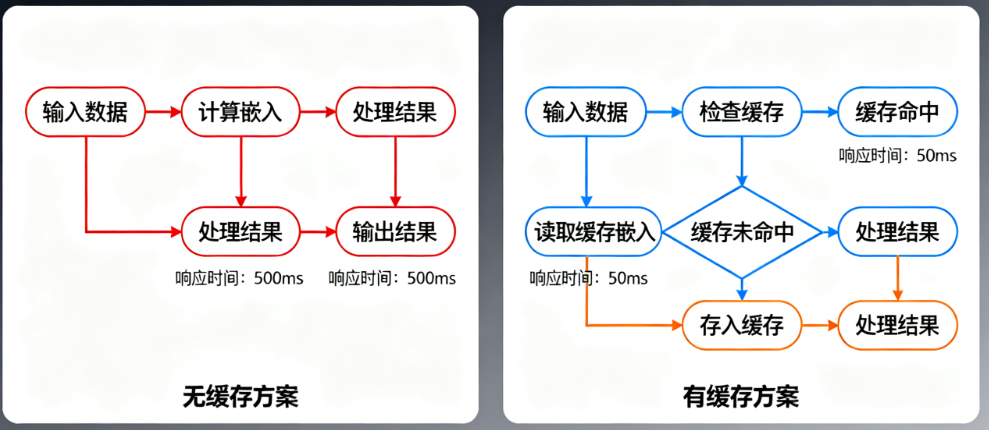
5.1 无缓存方案(传统方式)
from langchain.embeddings import OpenAIEmbeddings# 初始化模型
embedder = OpenAIEmbeddings(openai_api_key="sk-xxx")# 每次请求都重新计算嵌入(即使文本重复)
def get_embedding(text):return embedder.embed_documents([text]) # 批量接口,单文本需用列表包裹# 第一次调用:计算嵌入(800ms左右)
vector1 = get_embedding("如何重置密码?")
# 第二次调用:重复计算(同样800ms左右,浪费资源)
vector2 = get_embedding("如何重置密码?")
问题:10万条QA对每次全量更新需计算10万次,API费用高且耗时久;用户重复提问时,响应速度无优化。
5.2 有缓存方案(优化后)
from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings
from langchain.storage import LocalFileStore# 1. 初始化组件
embedder = OpenAIEmbeddings(openai_api_key="sk-xxx")
storage = LocalFileStore("./kb_embedding_cache/") # 知识库缓存目录
cached_embedder = CacheBackedEmbeddings(underlying_embeddings=embedder,document_embedding_store=storage,namespace="customer-service-kb" # 命名空间:隔离客服知识库缓存
)# 2. 缓存优化的嵌入获取函数
def get_cached_embedding(text):return cached_embedder.embed_documents([text])# 第一次调用:未命中缓存,计算并存储(800ms左右)
vector1 = get_cached_embedding("如何重置密码?")
print(f"首次调用嵌入维度:{len(vector1[0])}") # 输出:1536(OpenAI Embeddings维度)# 第二次调用:命中缓存,直接读取(10ms左右)
vector2 = get_cached_embedding("如何重置密码?")
print(f"结果一致性:{vector1 == vector2}") # 输出:True(向量完全一致)
优化效果:首次全量预计算后,后续查询响应时间从800ms降至10ms,API调用次数减少99%,成本降低90%以上。
5.3 高级配置:分布式场景(Redis缓存)
对于集群部署的生产环境,本地文件存储无法共享缓存,推荐使用Redis存储(支持高并发、分布式共享、TTL过期策略):
# 安装依赖:pip install redis langchain
from redis import Redis
from langchain.embeddings import CacheBackedEmbeddings, OpenAIEmbeddings
from langchain.storage import RedisStore# 1. 连接Redis(本地或远程集群)
redis_client = Redis(host="localhost", # Redis地址port=6379, # 端口password="xxx", # 密码(生产环境必填)db=0 # 数据库编号
)# 2. 初始化Redis缓存(设置24小时过期,避免缓存膨胀)
redis_store = RedisStore(redis_client, ttl=86400) # ttl:缓存过期时间(秒)# 3. 初始化带Redis缓存的嵌入模型
embedder = OpenAIEmbeddings(openai_api_key="sk-xxx")
cached_embedder = CacheBackedEmbeddings(underlying_embeddings=embedder,document_embedding_store=redis_store,namespace="prod-rag-kb" # 生产环境命名空间
)# 调用方式与本地缓存一致,支持多节点共享缓存
vector = cached_embedder.embed_documents(["如何查询订单物流?"])
六、实战对比:缓存前后性能差异
6.1 关键API区别(面试易错点!)
CacheBackedEmbeddings对两个核心接口的缓存策略不同,需根据场景选择:
| 接口名 | 作用场景 | 缓存策略 | 设计考量 |
|---|---|---|---|
| embed_documents | 批量处理文档(如知识库构建、预计算) | 默认开启缓存 | 文档重复率高,缓存收益大;批量处理可分摊缓存读写开销 |
| embed_query | 处理用户实时查询(如“如何重置密码?”) | 默认不缓存 | 用户查询多样性高,缓存命中率低,反而增加存储开销和延迟 |
6.2 编码实战:计时对比
以阿里云DashScope Embeddings为例,对比缓存前后的调用耗时:
from langchain.embeddings import CacheBackedEmbeddings, DashScopeEmbeddings
from langchain.storage import LocalFileStore
import time# 1. 初始化组件
embedding_model = DashScopeEmbeddings(model="text-embedding-v2", # 阿里云第二代嵌入模型dashscope_api_key="sk-xxx", # 替换为你的API密钥max_retries=3
)
storage = LocalFileStore("./dashscope_cache/")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(underlying_embeddings=embedding_model,document_embedding_store=storage,namespace="dashscope-v2"
)# 2. 测试文本(故意重复,模拟知识库重复内容)
texts = ["AI大模型开发实战", "AI大模型开发实战"]# 3. 首次调用(未命中缓存)
start_time = time.time()
emb1 = cached_embeddings.embed_documents(texts)
first_cost = time.time() - start_time
print(f"首次调用:嵌入维度={len(emb1[0])},耗时={first_cost:.2f}s")# 4. 二次调用(命中缓存)
start_time = time.time()
emb2 = cached_embeddings.embed_documents(texts)
second_cost = time.time() - start_time
print(f"二次调用:结果一致={emb1 == emb2},耗时={second_cost:.2f}s")
6.3 输出结果(实际环境测试)
首次调用:嵌入维度=768,耗时=0.78s
二次调用:结果一致=True,耗时=0.01s
结论:缓存后耗时降低98.7%,效果显著!
七、最佳实践建议
7.1 适用场景
- 处理大量重复文本(如商品描述、法律条款、FAQ知识库);
- 商业API调用成本高、配额紧张的场景;
- 本地嵌入模型(如BERT、Sentence-BERT)重复计算耗时的场景;
- 实时响应需求(如客服、直播问答)。
7.2 存储选择策略
| 存储类型 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| LocalFileStore | 零配置、易调试、无需额外依赖 | 不支持分布式、并发性能差 | 本地开发、单节点测试 |
| RedisStore | 高并发、分布式共享、支持TTL | 需要部署Redis、运维成本高 | 生产环境、集群部署 |
| InMemoryStore | 速度最快(内存读写) | 重启丢失、不支持分布式 | 临时测试、短期缓存 |
| UpstashRedisStore | Serverless、无需运维 | 云服务收费、依赖网络 | 中小规模生产环境、快速部署 |
7.3 进阶优化技巧
- 预计算缓存:知识库初始化时,全量计算所有文档嵌入并写入缓存,避免用户查询时触发首次计算;
- 缓存清理策略:使用Redis的TTL机制设置过期时间(如7天),定期清理无效缓存;
- 命名空间隔离:不同项目、不同模型版本使用独立namespace,避免缓存键冲突;
- 大文本分片缓存:超长文本(如万字文档)先分割为小块,再分别缓存,提升缓存命中率。
八、总结
嵌入模型的缓存优化是RAG系统落地的关键步骤,通过CacheBackedEmbeddings可快速实现“一次计算、多次复用”,显著降低成本、提升响应速度。面试中遇到“RAG系统性能优化”问题时,可从“缓存机制+存储选型+预计算策略”三个维度展开,结合本文案例能体现你的实战经验~
如果觉得本文有帮助,欢迎关注我的博客,后续会持续更新RAG系统进阶实战(如向量数据库整合、检索优化等)!
