第1课-通过DIFY实现一个完整的Text2Sql来讲AI原生及Agentic RAG长什么样

前言
作为《2025最前沿AI Agent讲武堂》专栏的开篇之作,我们不谈虚的概念,直接从一个典型的企业场景切入:如何让业务人员用自然语言查数据库?这看似简单的需求,背后却完整承载了当前最前沿的 AI Agent 范式。
• 传统做法是写死规则或封装接口,但面对灵活多变的查询意图,很快就会崩盘;
• 真正的 AI 原生应用,则从底层就围绕大模型的能力设计——以自然语言为交互入口,以模型为决策中心,数据、工具和反馈都围绕它动态流转。
而要支撑这种架构,Agentic RAG 是关键。它不是“检索+生成”的静态流水线,而是一个具备任务拆解、工具调度、执行验证和自我修正能力的智能体。在 Text2SQL 场景中,这意味着:
(1)自动判断是否需要获取表结构或示例数据;
(2)生成 SQL 后调用数据库执行并捕获结果或错误;
(3)根据执行反馈迭代优化查询逻辑;
(4)最终输出可靠、可解释的答案。
本课我们将基于 Dify 平台,完整搭建这样一个具备代理行为的系统。这不是 Demo,而是一个可复用、可扩展、贴近生产环境的最小可行实践。欢迎进入 AI Agent 的实战世界。
1. 我们要做一件什么事?
1.1 聚焦真实场景:为什么我们只做“BI问数”这一件事
企业落地大模型最容易踩的坑,就是一开始就想做个“什么都能答”的通用问答机器人。结果往往是准确率低、调试难、用户不信任。
- 我们这次刻意缩小范围,只处理一类问题:业务人员用自然语言查数据,比如“上个月华东区销售额Top5的产品是什么?”、“昨天新增用户中付费转化率多少?”
- 这类“BI问数”场景天然具备结构化意图、明确指标和固定维度,天然适配 Text2SQL 技术路径,也更容易验证结果对错。
1.2 任务简介
限定在 BI 问数后,整个系统的设计复杂度大幅下降:
- 不需要处理开放域知识(比如“爱因斯坦哪年出生”);
- 不需要融合多源非结构化文档;
- 所有输出最终都可映射到数据库表字段与聚合逻辑。
这种聚焦让我们可以把精力放在真正关键的问题上:如何让生成的 SQL 不仅语法正确,而且语义无误。
1.2.1 动态检索:不是一次性塞满上下文,而是按需取用
传统 RAG 常见做法是把整个数据库元数据(表名、字段名、注释)一股脑塞进 prompt。这会导致两个问题:
• token 消耗剧烈上升,尤其当表结构复杂时;
• 无关信息干扰模型判断,反而降低生成准确性。
我们的方案采用动态检索调度器:
(1)先由轻量模型判断当前问题涉及哪些表或字段;
(2)仅将相关元数据注入上下文;
(3)若首次生成失败,再逐步扩展检索范围,比如加入示例值或关联表结构。
笔者在测试中发现,这种“懒加载”式检索策略,在保证召回率的同时,平均节省了 40% 的输入 token。这对控制 API 成本和提升响应速度非常关键。
1.2.2 模型分工:小模型打前站,大模型啃硬骨头
很多人以为 Text2SQL 就是直接让 GPT-4 或 Qwen3 生成 SQL。但在实际工程中,这种“一刀切”方式既浪费又低效。
• 对于简单查询(如“昨天订单总数”),一个经过微调的小模型(如 DeepSeek-1.5B)完全能胜任,且推理速度快、成本低;
• 只有遇到嵌套查询、多表 join、时间窗口计算等复杂逻辑时,才启用大模型进行深度推理。
我们在 Dify 工作流中设置了一个“复杂度路由节点”:
• 输入问题先被分类为“简单”或“复杂”;
• 简单任务走轻量分支,复杂任务才调用大模型。
这种异构模型协同架构,是我过去半年在多个客户项目中验证有效的模式。它让系统在 80% 的日常查询中保持高效,同时保留应对极端 case 的能力。
1.2.3 双重校验:生成不是终点,执行才是开始
LLM 生成的 SQL 最大的风险不是语法错误,而是语义偏差——比如把“新增用户”理解成“注册用户”而非“首次下单用户”。
• 我们的流程中设置了两道校验关卡:第一道是 SQL 语法解析器,拦截明显语法错误;第二道是沙箱数据库执行,捕获运行时异常(如字段不存在、权限拒绝)。
• 若任一环节失败,系统会自动触发“反思模块”,分析错误类型(是表名错?还是逻辑错?),然后重新生成修正后的 SQL。
这种“生成—执行—反馈—修正”的闭环,正是 Agentic RAG 区别于传统 RAG 的核心。它不再是一次性输出,而是一个具备自我修正能力的智能体行为链。
1.2.4 可解释性:让用户看得懂每一步发生了什么
技术人员可能觉得日志无所谓,但业务用户需要信任。
• 我们在 Dify 工作流中显式输出每个步骤的状态:原始问题 → 识别的指标与维度 → 检索到的表结构 → 生成的 SQL → 执行结果或错误信息。
• 用户可以看到“为什么没查出来”,而不是面对一个冷冰冰的“查询失败”。
我在某金融客户现场演示时,一位分析师看到系统因“未授权访问敏感字段”而主动拦截查询,并提示“请改用脱敏视图”,当场就说:“这比我提工单给IT还靠谱。”
这不是 Demo,而是一个最小可行的 Agent 原型
这个 Text2SQL 案例看似简单,却完整体现了 AI 原生应用与 Agentic RAG 的五大特质:场景聚焦、动态检索、模型协同、闭环验证、过程透明。
• 它没有炫技式的多轮对话,也没有虚构的“自主规划”,但它解决了企业最痛的点:让数据真正可问、可信、可用。
• 笔者认为,2025 年 AI Agent 落地的关键,不在宏大叙事,而在这种能跑通、能迭代、能交付价值的微小闭环里。
当你亲手在 Dify 中搭出这样一个会“思考—行动—修正”的系统,你会突然明白:Agentic 不是一种技术,而是一种工程哲学。
下面进入精讲环节。
2. 一个符合AI原生的Agentic RAG的基本概念
笔者用2句口决来总结:AI原生和Agentic RAG到底是什么
2.1 什么叫AI 原生
非规则即不会有代码去写if...else...或者是switch case一类的东西。具体要完成这件事需要分成几步是由AI自己思考并决定的。
这就和一个人在领到做一件任务前先要折分工作步骤一样,是一个AI自我思考的而不是代码规则去折分的。
2.2 什么叫Agentic RAG,它到底和一般的RAG不同点在哪?
在笔者前面一系列的博客里都提到过这个Agentic RAG,也叫Advanced RAG。
传统的RAG

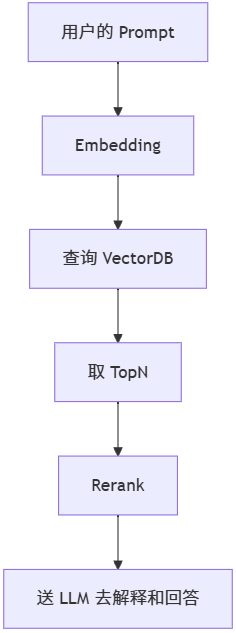
Agentic RAG
在实施时我们就可以感受到传统的RAG在很多方面是不能实现复杂的工程化的生产实例。来看以下痛点:
- 用户如果问的是“你好”,也走一边RAG全流程吗?
- 假设知识库里存了法律、生物、物业、人寿保险相关知识,其中有几百条语料交叉相似,而用户提了一个人寿保险相关的问题,那么检索这一步有很高机率会搜到法律相关的信息,此时把检索出的结果送LLM,回答肯定是不对的。
- 搜索取TopN?科学吗?如果我设Top10,切片是2048字符一切片,这就有20,480个字符的结果集,送LLM,内容太大往往会让LLM的注意力偏移,于是就产生了要么“答非所问”,要么就是“不问乱答”这样的幻觉。
- 如果我设Top3,但实际真正用于一次完整的问答是Top 20呢?因此这个N设多少科学呢?
Agentic RAG其实就是把AI原生的概念融合进入了RAG这条标准链路,像人一样,在接到人的prompt后,你自己去折成几步,每一步你要做什么?是由AI去规划的,而不是“规则固定”的。
所以:AI原生是设计准则,而Agentic RAG是用AI原生设计的带有AI自己分析-计划-并且按照分步计划自己动态路由的RAG流。
所以接着我们就要来把这两个概念结合到一个真实、完善的Text2SQL实例中来为大家庖丁解牛一般的层层剖析。
3. Text2SQL实例介绍-停车场相关查询
3.1 使用数据库及表
数据库
mysql8.x
表关系
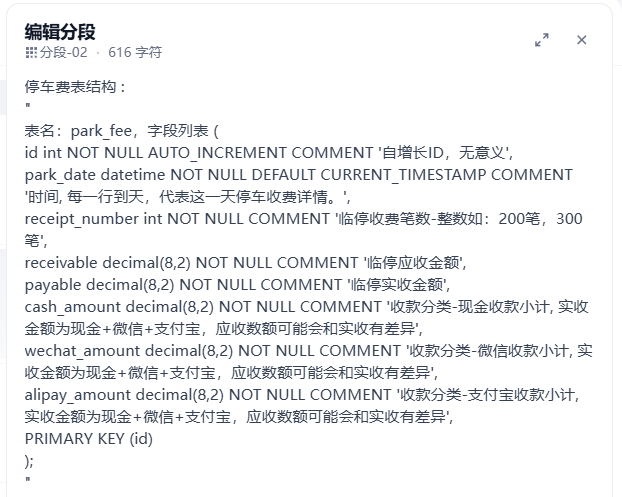
1. 停车费表结构
停车费表结构 :
"
CREATE TABLE park_fee (
id int NOT NULL AUTO_INCREMENT COMMENT '自增长ID,无意义',
park_date datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '时间, 每一行到天,代表这一天停车收费详情。',
receipt_number int NOT NULL COMMENT '临停收费笔数-整数如:200笔,300笔',
receivable decimal(8,2) NOT NULL COMMENT '临停应收金额',
payable decimal(8,2) NOT NULL COMMENT '临停实收金额',
cash_amount decimal(8,2) NOT NULL COMMENT '收款分类-现金收款小计, 实收金额为现金+微信+支付宝,应收数额可能会和实收有差异',
wechat_amount decimal(8,2) NOT NULL COMMENT '收款分类-微信收款小计, 实收金额为现金+微信+支付宝,应收数额可能会和实收有差异',
alipay_amount decimal(8,2) NOT NULL COMMENT '收款分类-支付宝收款小计, 实收金额为现金+微信+支付宝,应收数额可能会和实收有差异',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
"2. 停车场信息表结构
停车场信息表:
"
CREATE TABLE IF NOT EXISTS parking_lot (id INT NOT NULL AUTO_INCREMENT COMMENT '停车场ID',name VARCHAR(100) NOT NULL COMMENT '停车场名称',address VARCHAR(255) NOT NULL COMMENT '停车场地址',total_spaces INT NOT NULL COMMENT '总车位数',hourly_rate DECIMAL(5,2) NOT NULL COMMENT '每小时收费标准',daily_limit DECIMAL(6,2) COMMENT '每日收费上限',opening_time TIME NOT NULL COMMENT '开放时间',closing_time TIME NOT NULL COMMENT '关闭时间',is_24hours TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否24小时营业:0-否,1-是',manager_name VARCHAR(50) COMMENT '管理员姓名',manager_phone VARCHAR(20) COMMENT '管理员联系电话',create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',status TINYINT(1) NOT NULL DEFAULT 1 COMMENT '状态:0-停用,1-启用',PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='停车场基本信息表';
"3. 车位信息表结构
车位信息表 :
"
CREATE TABLE IF NOT EXISTS parking_space (id INT NOT NULL AUTO_INCREMENT COMMENT '车位ID',parking_lot_id INT NOT NULL COMMENT '所属停车场ID',space_number VARCHAR(20) NOT NULL COMMENT '车位编号',space_type TINYINT(1) NOT NULL COMMENT '车位类型:1-普通,2-残障,3-充电桩,4-VIP',floor_level VARCHAR(10) COMMENT '所在楼层',section_code VARCHAR(20) COMMENT '区域编码',is_occupied TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否被占用:0-空闲,1-占用',is_reserved TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否预留:0-否,1-是',reserved_for VARCHAR(50) COMMENT '预留给谁',sensor_id VARCHAR(50) COMMENT '车位传感器ID',create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',status TINYINT(1) NOT NULL DEFAULT 1 COMMENT '状态:0-停用,1-启用',PRIMARY KEY (id),UNIQUE KEY uk_lot_number (parking_lot_id, space_number),FOREIGN KEY (parking_lot_id) REFERENCES parking_lot(id) ON DELETE CASCADE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='车位信息表';
"4. 车辆信息表结构
车辆信息表 :
"
CREATE TABLE IF NOT EXISTS vehicle (
id INT NOT NULL AUTO_INCREMENT COMMENT '车辆ID',plate_number VARCHAR(20) NOT NULL COMMENT '车牌号',vehicle_type TINYINT(1) NOT NULL COMMENT '车辆类型:1-小型车,2-中型车,3-大型车,4-新能源车',owner_name VARCHAR(50) COMMENT '车主姓名',owner_phone VARCHAR(20) COMMENT '车主联系电话',owner_id_card VARCHAR(18) COMMENT '车主身份证号',is_monthly_pass TINYINT(1) NOT NULL DEFAULT 0 COMMENT '是否月卡用户:0-否,1-是',pass_start_date DATE COMMENT '月卡开始日期',pass_end_date DATE COMMENT '月卡结束日期',monthly_fee DECIMAL(8,2) COMMENT '月卡费用',create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',status TINYINT(1) NOT NULL DEFAULT 1 COMMENT '状态:0-禁用,1-正常',PRIMARY KEY (id),UNIQUE KEY uk_plate_number (plate_number)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='车辆信息表';
"5. 停车记录表结构
停车记录表 :
"
CREATE TABLE IF NOT EXISTS parking_record (
id INT NOT NULL AUTO_INCREMENT COMMENT '停车记录ID',parking_lot_id INT NOT NULL COMMENT '停车场ID',space_id INT COMMENT '车位ID',vehicle_id INT NOT NULL COMMENT '车辆ID',plate_number VARCHAR(20) NOT NULL COMMENT '车牌号',entry_time DATETIME NOT NULL COMMENT '入场时间',exit_time DATETIME COMMENT '出场时间',duration INT COMMENT '停车时长(分钟)',fee_amount DECIMAL(8,2) COMMENT '停车费用',payment_status TINYINT(1) DEFAULT 0 COMMENT '支付状态:0-未支付,1-已支付',payment_time DATETIME COMMENT '支付时间',payment_method TINYINT(1) COMMENT '支付方式:1-现金,2-微信,3-支付宝',receipt_number VARCHAR(50) COMMENT '收据编号',operator_id INT COMMENT '操作员ID',remarks VARCHAR(255) COMMENT '备注',PRIMARY KEY (id),FOREIGN KEY (parking_lot_id) REFERENCES parking_lot(id),FOREIGN KEY (space_id) REFERENCES parking_space(id),FOREIGN KEY (vehicle_id) REFERENCES vehicle(id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='停车记录表';
"表与表间关系说明
由于我们不设外键这种强约束,所以表和表间的实体关系映射即查询用到的业务逻辑,是需要用文字说明的。
停车信息查询用到相关表说明与业务逻辑
实收金额计算: "cash_amount列+"wechat_amount列"+"alipay_amount列",
应收金额与必实金额区别: "应收金额与实收金额会存在差异",
park_fee表: "原有表,记录每天的停车收费汇总",
parking_lot表: "停车场基本信息,是整个系统的核心表",
parking_space表, "车位信息,与parking_lot表形成一对多关系",
vehicle表: "车辆信息,记录车辆和车主信息",
parking_record表: "停车记录,与parking_lot、parking_space和vehicle表形成多对一关系"
其实有了上述内容,上述内容就是我们的Text2SQL例子的语料。
3.2 使用DIFY建立知识库
请注意,本文用的是DIFY的最新版:
要升级你的dify可以直接进入dify安装目录->docker子目录运行
#先停所有的镜像
docker compose down#接着升级
docker compose up -d
知识库一览

知识库切片规则说明
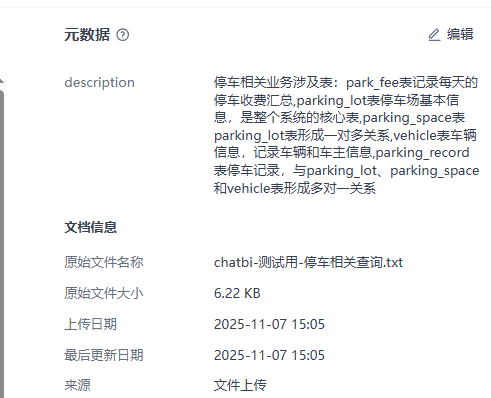
可以看到,我们给知识库先“打”了一个全局的“标”,内容如下:
停车相关业务涉及表:
park_fee表记录每天的停车收费汇总,
parking_lot表停车场基本信息,是整个系统的核心表,
parking_space表parking_lot表形成一对多关系,
vehicle表车辆信息,记录车辆和车主信息,parking_record表停车记录,与parking_lot、parking_space和vehicle表形成多对一关系
它的作用是在每次知识库在被搜索时带在embedding结果出来的meta data里的。
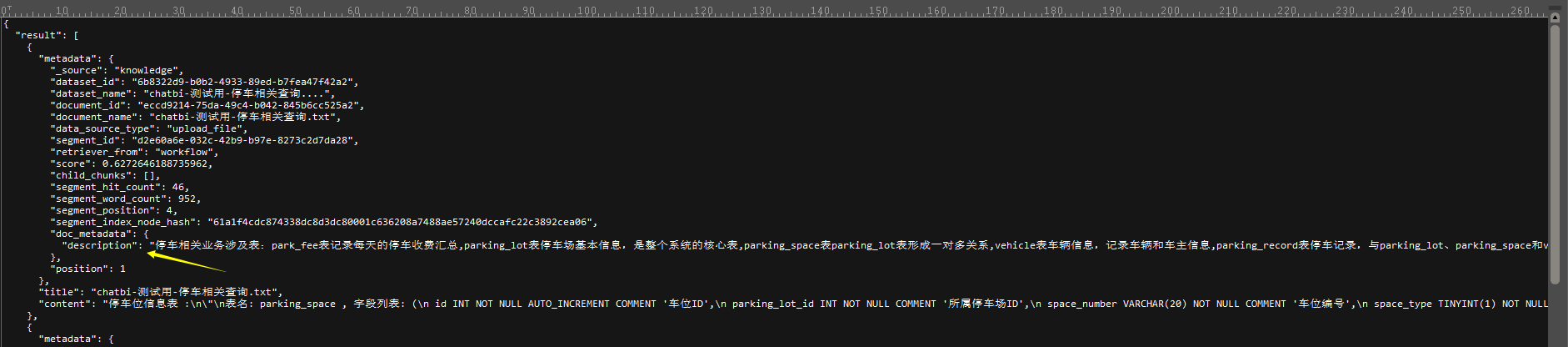
就算知识库里搜索出来一条记录也没有,这个记录必然会被带出来的。下面会讲带出来这个meta data的好处。
我们同时可以看到在知识库里我们选择的切片是:
- 按照\n\n-即完整的一段
- 并且这一段长度在2048个token内
来切割的
这是基本的一个切片要求。
因此在把3.1里的使用数据库及表的meta data整理成符合上述这个规则的一段一段不需要什么很高的技术手段,只需要传统的大数据或者是用python洗数就可以在半天不到的时间内做到这样的格式,如下图所示。
3.3 建立召回机制
有了语料,切片,我们就可以考虑检索召回机制了。有两种机制笔都都推荐给到读者们,但具体也要分场景。
- “大富豪”式召回机制
- “勤劳式-又叫亲民式”召回机制
大富豪式召回机制介绍-混合检索
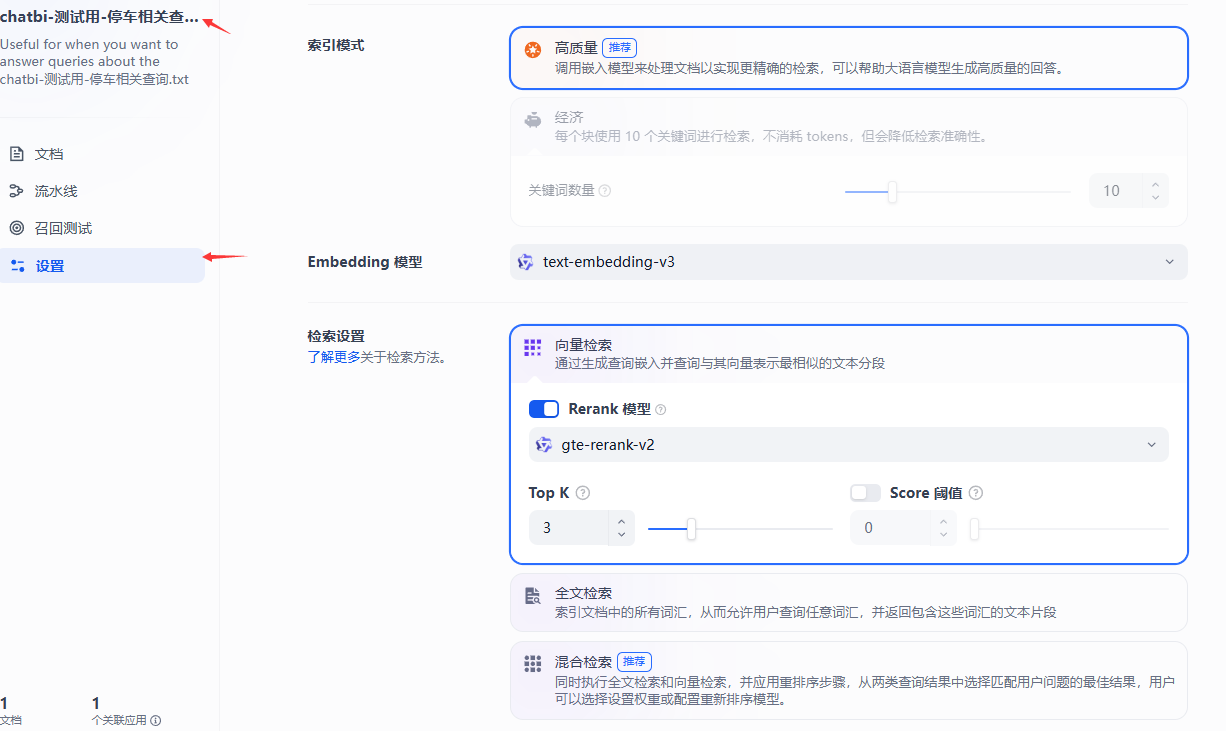
这种召回是传统的embedding+rerank出来TopN条记录,它的好处在于远远高于一般embedding的精度,是企业级用法,不过rerank模型通常是远贵于text-embedding类算法的。
勤劳式召回机制(亲民式召回机制)- 标准embedding机制
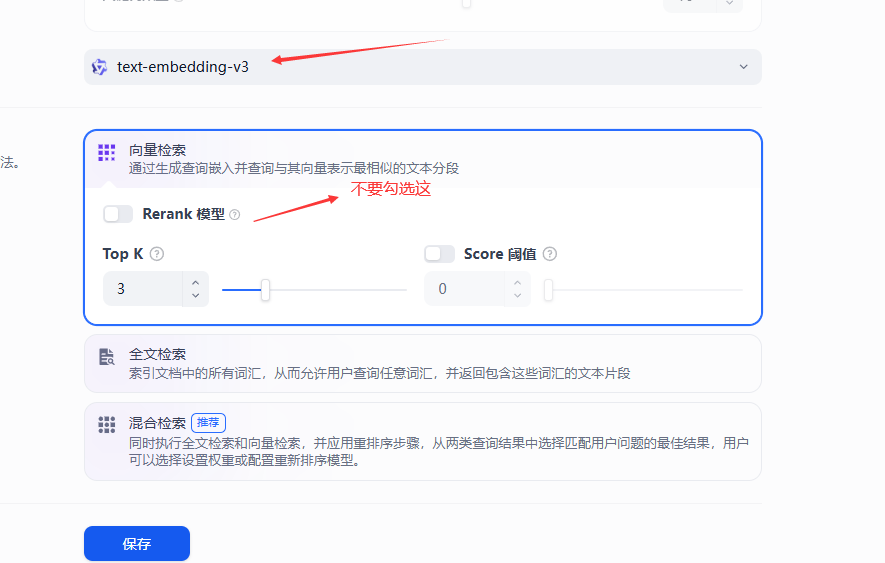
就是这样,这个模式建议大家练习时多用,便宜到每千Token只有零点几厘吧,而且因为我们的教程传授的是Agentic RAG,无论是富豪式还是亲民式的召回,都一定会保存召回率达到99%。
这是传统RAG里的多路检索+富豪式检索召回都到达不了的。只不过区别在于如果用大富豪式召回因为更精准因此需要迭代的次数会少于“勤劳式(亲民式)”召回机制。
注:
建议各位学习AI相关的必须要拥有2个云的帐号,aliyun和硅基流动,这样你将拥有全套的LLM、Embedding、多模态包括最新的deepseek ocr这些全部的能力了。
不要再相信国外的LLM了,我国在LLM这一块已经是全世界领先了,而且便宜到不行,自从2024年deepseek横穿出世后笔者在生产环境落地已经再也不用国外的LLM了。关键国产的LLM质量已经甩开国外几条大街了。
3.4建立流程
好,现在开始进入正式的Agentic RAG流程了。
在此我们使用的是Chatflow来新建一个流程。
意图识别节点说明
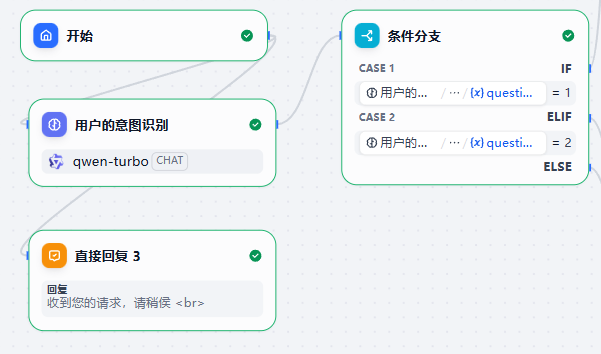
意图识别节点内部长这样
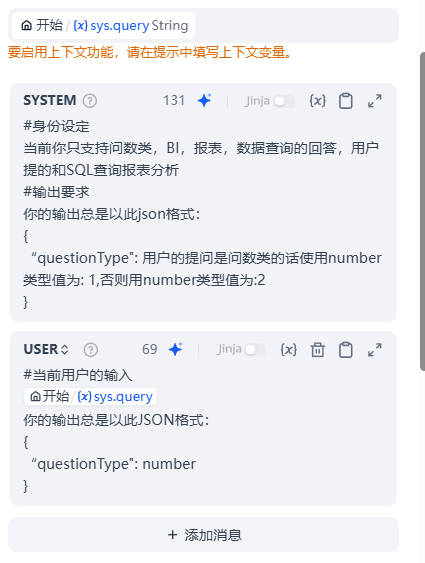
它的作用很简单,就是在用户对话输入时判断:用户是查询、问数类,而如果用户只是来一句诸如:
你好?
你是谁?
你是哪家生产的?
Hi
你吃了吗?一类的统统不需要走后续的RAG步骤。
笔者在市面上看到一些“著名的直播类大厂”做的企业级RAG里竟然都还有,只要用户提问一句:
你好然后后面整个RAG流程达几十个节点都需要走一遍,虽然最终LLM的回答是:
你好,我能为你做什么?但是这几十个节点走下来,资源耗费了多少?为了一句无关紧要的或者是不相关的提问也去走一遍RAG全流程?
这是目前外面大都RAG的通病。
所以,我们才要设这么一个:意图识别节点。
此节点有时也可以用来辩别诸如:
这个LLM是为天天超市服务的。
现在客户故意这样提问:
你们劳动超市有没有巧克力?如果没有意图识别,大多LLM是真的都会回答的,这叫“实体混淆”手段。
大家或许会这样问:
我们把这种意图识别写成一个system role message不就可以了吗?
可是大多没有经历过亿万条数据在企业落地的都无法实际体会到,有时为了做到意图识别你的system role message会随着时间的增涨变得越来越长,6,000字的system role message笔者也是看到过的,这样的系统且不説性能很糟,仅system role message就会让LLM的注意力偏移随之而来的就是充满了幻觉。
所以我们才要前置这么一个节点。
这个节点的完整流是这样的:
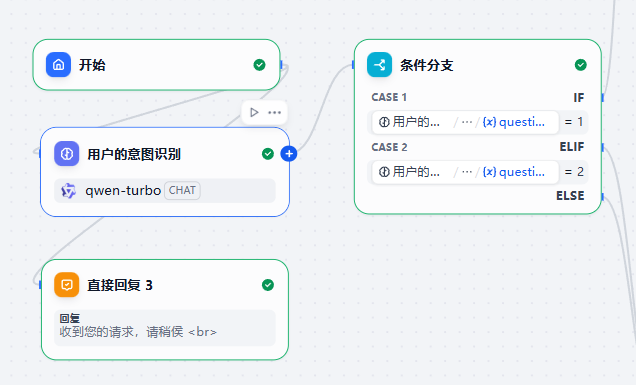
如果 if条件成立,会进入正式流程。
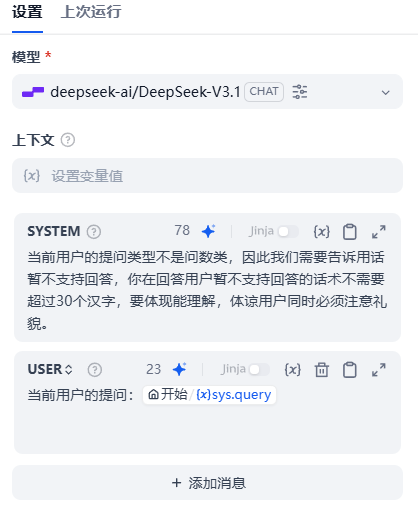
如果else,会用LLM拟一段话术,告诉用户当前用户的提问不支持。
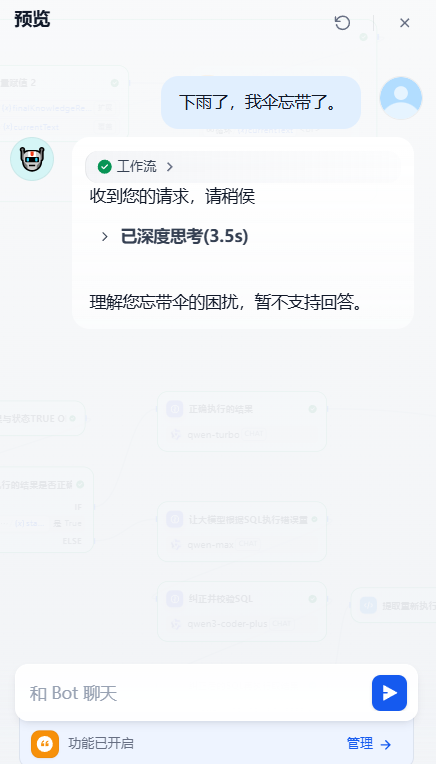
所以else分支的运行效果如下图所示:
额外补充给到读者的知识-除去意图识别我们还可以做知识库路由节点
这儿补充一个额外知识点:对于一个企业级的应来説有财务、HR、物流多种语料。
把所有的语料堆砌在一个知识库内是很简单的做法也是最错误的做法。
对于这种场景,我们会在意图识别后跟上一个叫“知识库路由”的节点,这个节点的作用就是根据用户当前的prompt自动选择是从财务还是从HR还是物流这些独立的知识库中去检索还是分成同时做两个知识库的同时检索并最后汇总回答的内容。
这就是我在上文“Agentic RAG”中提到:AI原生非代码规则写死得动态路由机制,这正是Agentic RAG的特点,这种设计就叫“AI原生”。
检索节点说明
现在我们假设用户提出的问题是:
2025年7月去过:浦华众城信息有限公司停车场的车辆信息有哪些?此时就命中了if条件了。
接着if条件我们来看
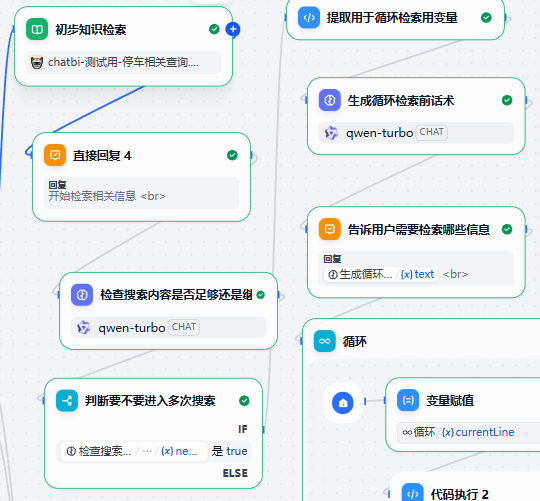
哇,好复杂!
不过,这不是过度设计,笔者的例子是直接来源于生产的,这是一个典型的并且是一个经典的Agentic Flow设计。这个流程正是为了解决召回时的TopN到底该设几这么一个问题而产生的。如何做到正正好好检索出来的东西不多不少正好满足用户的提问要求呢?就是依靠这样的Agentic Flow来做的。下面来解读流程
初步检索节点的Agentic Flow设计
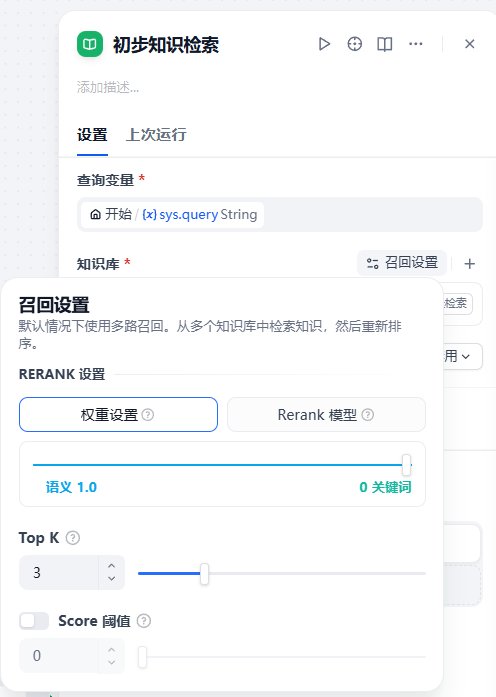
用传统的向量搜索(勤劳式-亲民搜索算法)检出3条。
但并不代表我们只会用这3条去做回答。
接着看下去。
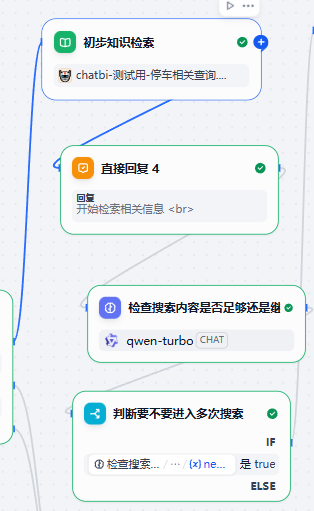
检出3条后我们设一个直接回复节点用于告诉用户这么一条信息而不要让用户空等。
增加用户在使用上的体验用的。
接着我们在其后追加了一个LLM节点,由于我们的知识库是有一个标签
这个标签无论检索出来的数据条数多少是都会被“额外检索”出的。
此时我们的LLM是用来做这样的判断的:
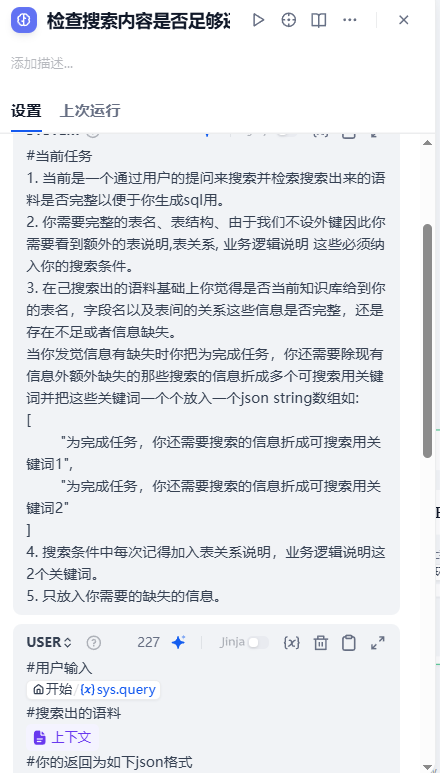
#当前任务
1. 当前是一个通过用户的提问来搜索并检索搜索出来的语料是否完整以便于你生成sql用。
2. 你需要完整的表名、表结构、由于我们不设外键因此你需要看到额外的表说明,表关系, 业务逻辑说明 这些必须纳入你的搜索条件。
3. 在己搜索出的语料基础上你觉得是否当前知识库给到你的表名,字段名以及表间的关系这些信息是否完整,还是存在不足或者信息缺失。
当你发觉信息有缺失时你把为完成任务,你还需要除现有信息外额外缺失的那些搜索的信息折成多个可搜索用关键词并把这些关键词一个个放入一个json string数组如:
["为完成任务,你还需要搜索的信息折成可搜索用关键词1","为完成任务,你还需要搜索的信息折成可搜索用关键词2"
]
4. 搜索条件中每次记得加入表关系说明,业务逻辑说明这2个关键词。
5. 只放入你需要的缺失的信息。瞧!
这就是我们在教程开头提到的TopN,这个N到底设置几是合理的?3?10?20?还是5?
那么到底要用到哪些语料,让AI自己去决定。
所以在经过这么一个流程以后,LLM节点(用快模型即可,如:8B类的模型或者是turbo模型)会返回:
{"还需做额外搜索": true"还缺这些知识": ["parking_lot表结构","parking_space表结构""表与表间的关系说明,业务逻辑描述"]
}接着我们再加入一个if...else...节点用于判断:
如果不需要做额外搜索了,就可以进入下一个“生成SQL”的环节了。
如果需要做额外搜索,那么就进入一个“循环搜索”环节。
循环搜索补充完善召回节点说明
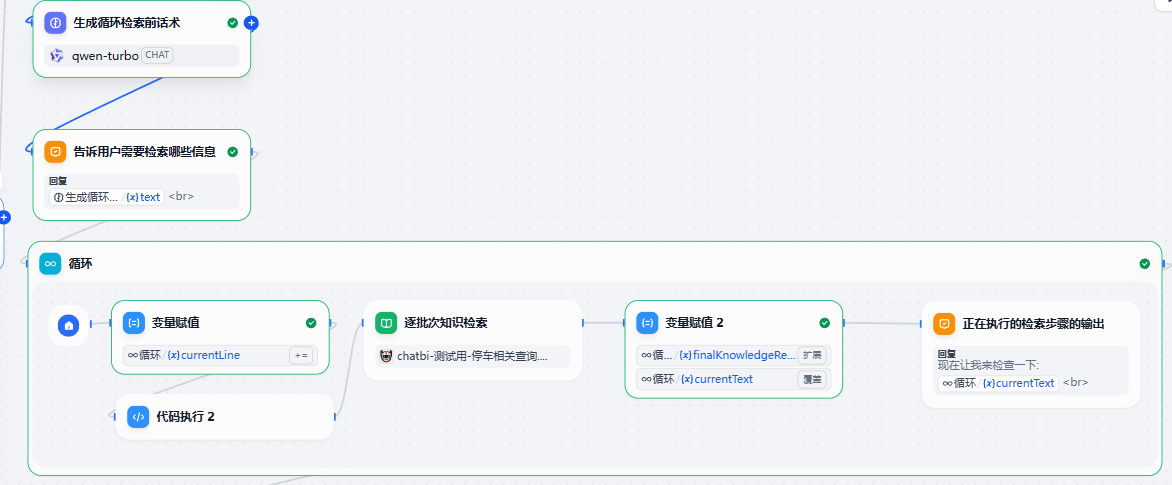
在进入循环检索召回前我们会让LLM拟一个话术,告诉用户类似:为了回答你的问题我需要做这么些步骤,它们是。。。
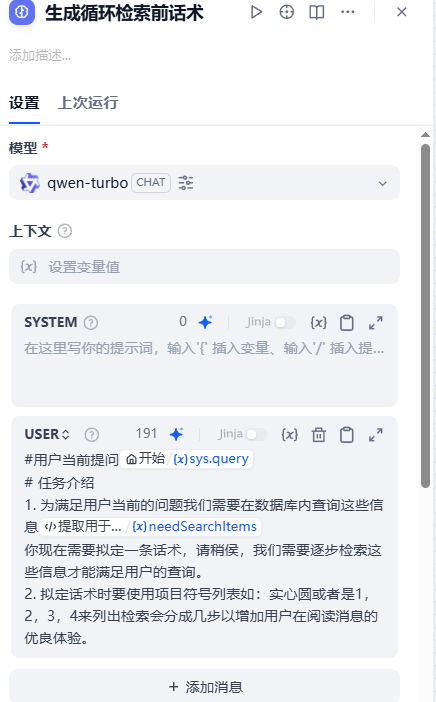
#用户当前提问{{#sys.query#}}
# 任务介绍
1. 为满足用户当前的问题我们需要在数据库内查询这些信息{{#1762244256932.needSearchItems#}}
你现在需要拟定一条话术,请稍侯,我们需要逐步检索这些信息才能满足用户的查询。
2. 拟定话术时要使用项目符号列表如:实心圆或者是1,2,3,4来列出检索会分成几步以增加用户在阅读消息的优良体验。具体运行效果如下图所示

这也是用来增加用户的体验的。
来看循环节点的设计
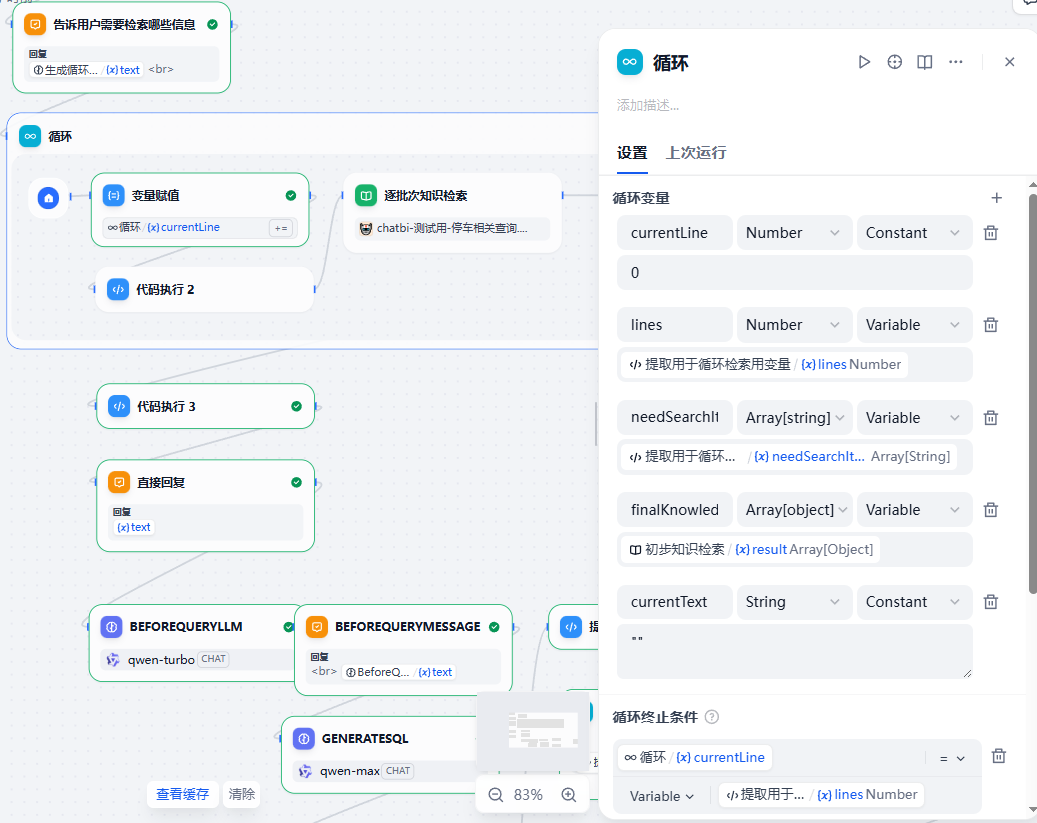

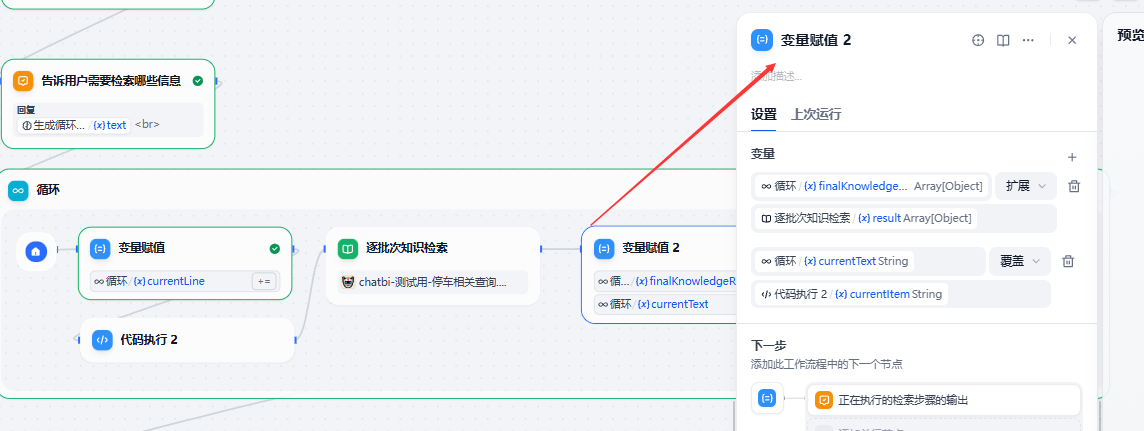
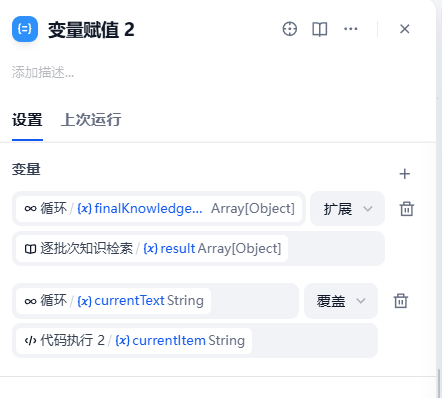
- currentLine,这是一个全局的计数器,初始为0,在循环中放置一个变量赋值节点,这个节点每次会把currentLine+1。
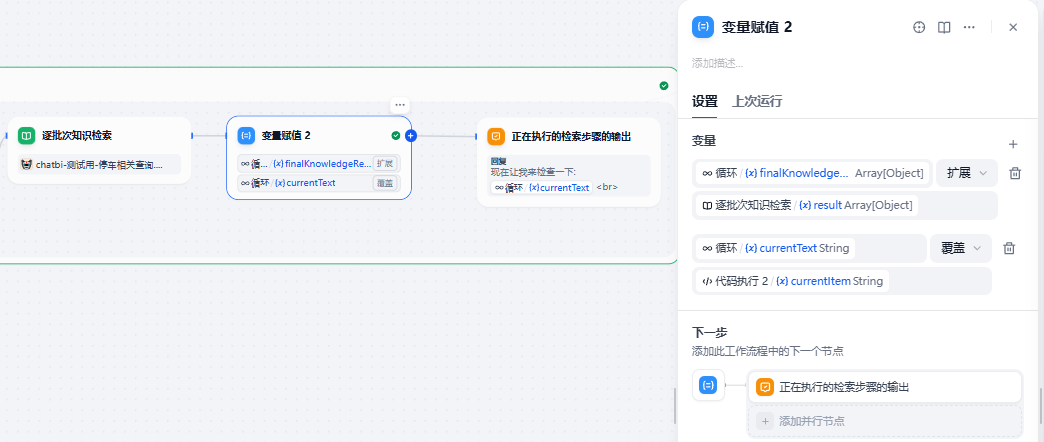
- 每加一次进行一次知识库检索,检索出来的内容用python先对初次检索节点的Array(object)的result进行基于Set的去重后再extend-扩展(循环内index个检索result)。
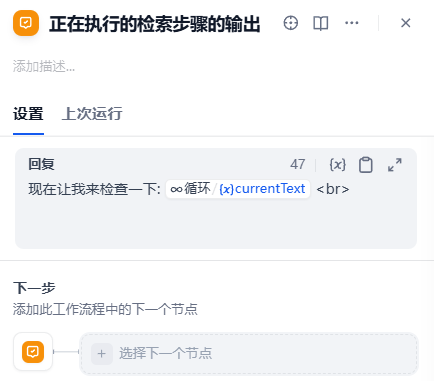
- 每循环一次会输出:当前正在检索什么的消息
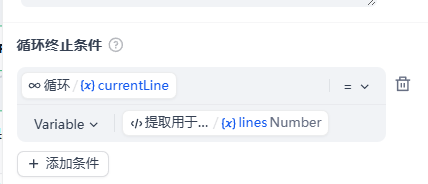
- 直到currentLine=输入的额外搜索关键词数组Array(String)的长度。
因此我们假设有这么一个内容作为输入进入循环
{"还需做额外搜索": true"还缺这些知识": ["parking_lot表结构","parking_space表结构""表与表间的关系说明,业务逻辑描述"]
}那么按照上述规则会:
- 循环3次
- 第1次循环会搜索"parking_lot表"这个关键词在知识库中的条数,取出3条用python的Array(object).extend操作添加进之前的初步检索节点的结果集里。
- 第2次循环会搜索"parking_space表"这个关键词在知识库中的条数,取出3条用python的Array(object).extend操作添加进之前的初步检索节点的结果集里。
- 第3次循环会搜索"表与表间的关系说明"这个关键词在知识库中的条数,取出3条用python的Array(object).extend操作添加进之前的初步检索节点的结果集里。
1. 循环终止条件设计
循环内变量赋值节点
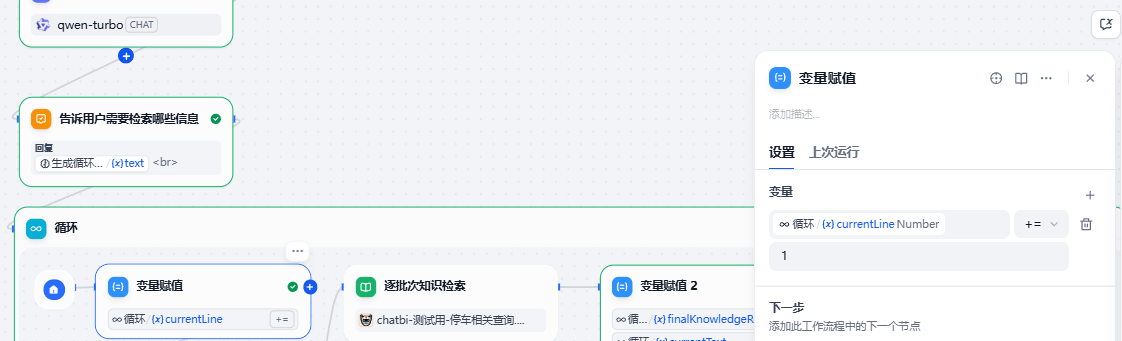
2. 把AI得到的需要分成几步循环检索的大模型输出内容化作循环次数的“代码节点为”设计
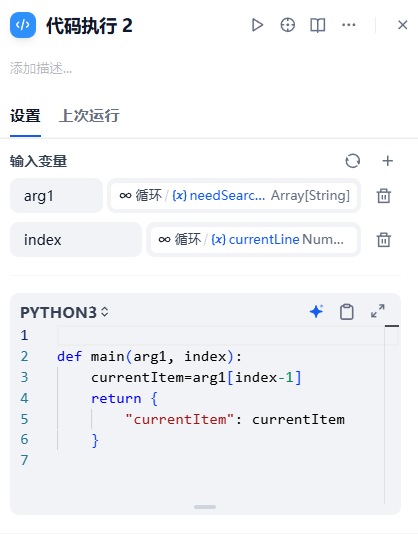
3. 变量赋值设计
4. 循环输出当前在搜索什么内容的提示设计
来看一下循环检索时对外输出的内容如下截图

在我们这儿循环了5次,每次检索都是不同的信息。
循环后做去重,把语料基底降到最精简最必要
这是一个代码节点,它的作用是:由于每次循环是3条记录,因此一定存在语料上的重复。
因此我们必须要做去重。
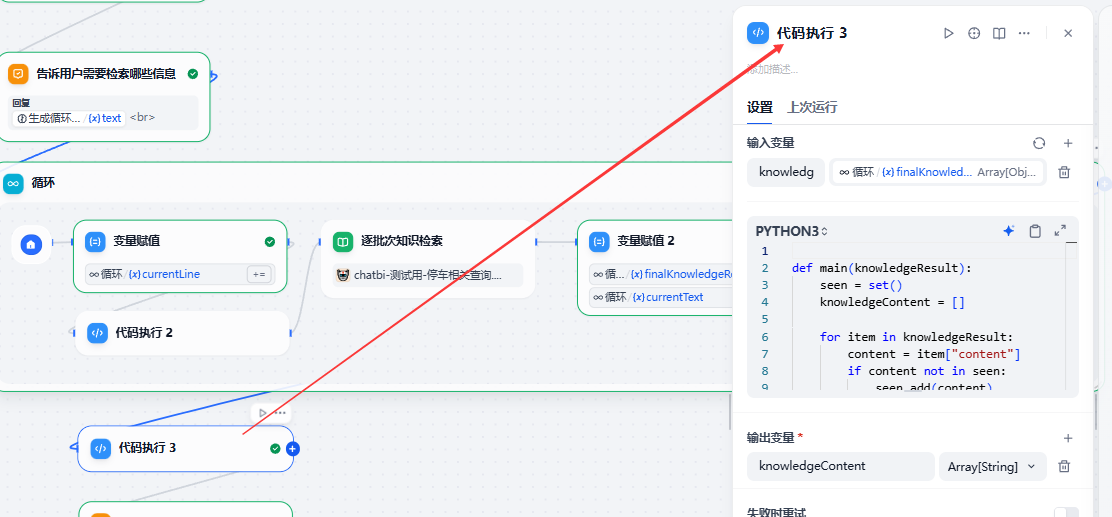
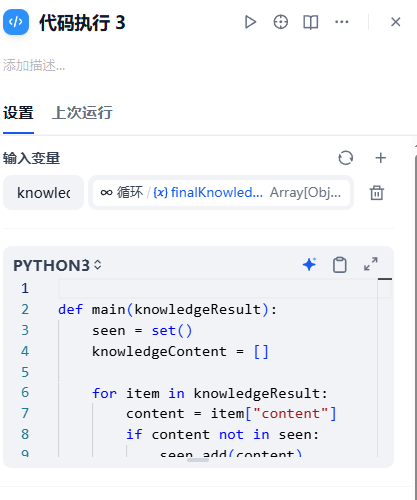
def main(knowledgeResult):seen = set()knowledgeContent = []for item in knowledgeResult:content = item["content"]if content not in seen:seen.add(content)knowledgeContent.append(content)return {"knowledgeContent": knowledgeContent}用的是set数据结构。
到此为止形成的这个“knowledgeContent”它是一个Array(String),这是我们用于生成SQL的真正的知识库内容,里面的内容正正好好一定是等于根据用户的prompt产生sql用的语料,且一定不会存在重复的内容。
下面就进入正式的生成SQL环节了。
生成sql环节

要不要这么复杂?
不,一点都不复杂!
事实上为了写教程我还简化了,这一个流程我们在生产上专门封装了一个工作流来额外实现的。
事实上,要回答用户的提问如:
2025年5月~7月新格林耐特信息有限公司停车场的利用率情况查询。生成准确率做到:高达>=95%甚至到达99%的回答,至少是要实现这么一个“反思流”的。
怎么个反思呢?下面我们分步骤来叙述。
整体设计思路
换成人是怎么去考虑这个问题的
如果是一个BI或者是DBA,做这件事他会怎么做?
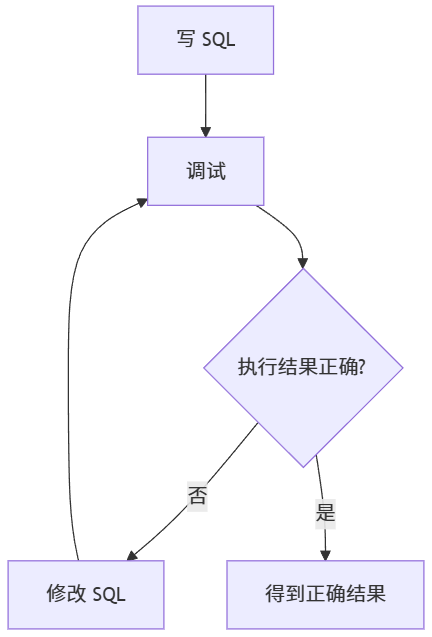
理解业务逻辑
掌握所有的表结构
写SQL->调试->有问题就改->再调试->直到执行后得到正确的结果用AI反思流去做
那么我们知道了人如何去做这件事,机器怎么做也就简单了。
无法我们缺少一个:把生成后的SQL去连上MYSQL执行然后取得执行后的结果,如果有执行失败那么收集执行收败信息后让AI再去重新生成的这么一个Service。
我们于是用python手写一个(这个dify不带这样的功能的)。
我们用flask restful api来写这个sql执行的小工具。
用flask restful api先写一个执行sql和反馈结果的小工具
下面是全代码
SqlExecuteClient.py
import pymysql
import json
import time
import os
import logging
from logging.handlers import RotatingFileHandler
from flask import Flask, request, jsonify
from pymysql.constants import CLIENT# 配置信息
DB_CONFIG = {'host': 'localhost','port': 3306,'user': 'root','password': '111111','db': 'mkai','charset': 'utf8mb4','cursorclass': pymysql.cursors.DictCursor,'connect_timeout': 15, # 连接超时时间(秒)'read_timeout': 15, # 读取超时时间(秒)'write_timeout': 15, # 写入超时时间(秒)'client_flag': CLIENT.CONNECT_WITH_DB
}# Flask服务配置
APP_HOST = '0.0.0.0'
APP_PORT = 5555# 查询超时设置(秒)
QUERY_TIMEOUT = 8# 配置日志
LOG_FILE = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'output.log')# 创建日志记录器
logger = logging.getLogger('sql_execute_client')
logger.setLevel(logging.INFO)# 创建日志处理器,使用RotatingFileHandler支持日志文件轮转
handler = RotatingFileHandler(LOG_FILE, maxBytes=10*1024*1024, backupCount=5, encoding='utf-8')
handler.setLevel(logging.INFO)# 设置日志格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler.setFormatter(formatter)# 将处理器添加到日志记录器
logger.addHandler(handler)app = Flask(__name__)
# 设置Flask应用日志处理器
app.logger.addHandler(handler)# 请求后钩子,记录请求处理时间
@app.after_request
def after_request(response):# 记录响应状态码logger.info(f"请求处理完成,状态码: {response.status_code}")return responsedef log_request_details(request_obj):"""记录请求的详细信息,包括来源和请求体内容"""# 基本请求信息client_ip = request_obj.remote_addrforwarded_for = request_obj.headers.get('X-Forwarded-For', '')user_agent = request_obj.headers.get('User-Agent', '')referer = request_obj.headers.get('Referer', '')host = request_obj.headers.get('Host', '')request_method = request_obj.methodrequest_path = request_obj.pathrequest_url = request_obj.url# 请求参数和内容headers = dict(request_obj.headers)url_params = dict(request_obj.args)body_data = request_obj.get_json(silent=True) or {}# 记录请求信息到日志logger.info(f"=== 请求详情开始 ===")logger.info(f"请求端点: {request_path}, 方法: {request_method}")logger.info(f"请求主机: {host}")logger.info(f"客户端IP: {client_ip}, X-Forwarded-For: {forwarded_for}")logger.info(f"User-Agent: {user_agent}")logger.info(f"Referer: {referer}")logger.info(f"完整URL: {request_url}")# 记录请求体内容if body_data:try:# 使用json.dumps确保正确处理中文和特殊字符body_json = json.dumps(body_data, ensure_ascii=False)logger.info(f"请求体内容: {body_json}")# 记录SQL查询(如果存在)if 'sql' in body_data:logger.info(f"SQL查询: {body_data['sql']}")except Exception as e:logger.info(f"请求体内容(无法序列化): {str(body_data)}")else:logger.info("请求体为空")# URL参数if url_params:logger.info(f"URL参数: {json.dumps(url_params, ensure_ascii=False)}")# 详细的请求头信息(DEBUG级别)logger.debug(f"HTTP头信息: {json.dumps(headers, ensure_ascii=False)}")logger.info(f"=== 请求详情结束 ===")# 返回收集到的信息,便于后续使用return {'client_ip': client_ip,'forwarded_for': forwarded_for,'user_agent': user_agent,'referer': referer,'host': host,'method': request_method,'path': request_path,'url': request_url,'headers': headers,'url_params': url_params,'body_data': body_data}def execute_query(sql):"""执行SQL查询并返回结果,带超时控制"""try:# 验证是否为SELECT查询if not sql.strip().lower().startswith('select'):logger.warning(f"尝试执行非SELECT查询: {sql}")return False, "只允许执行SELECT查询", None, 200logger.info(f"开始执行SQL查询: {sql}")start_time = time.time()try:# 连接数据库logger.debug("尝试连接数据库")connection = pymysql.connect(**DB_CONFIG)try:with connection.cursor() as cursor:# 设置会话超时cursor.execute("SET SESSION wait_timeout=%s", (QUERY_TIMEOUT,))cursor.execute(sql)result = cursor.fetchall()elapsed_time = time.time() - start_timelogger.info(f"查询成功完成,耗时: {round(elapsed_time, 3)}秒")return True, "", result, 200finally:connection.close()logger.debug("数据库连接已关闭")except pymysql.err.OperationalError as e:# 处理连接错误和超时错误error_code = e.args[0]error_message = e.args[1] if len(e.args) > 1 else str(e)if error_code in (2003, 2006, 2013): # 连接相关错误error_msg = f"数据库连接错误: {error_message}"logger.error(error_msg)return False, error_msg, None, 200elif error_code == 1146: # 表不存在error_msg = f"表不存在: {error_message}"logger.error(error_msg)return False, error_msg, None, 200else:error_msg = f"数据库操作错误 (代码 {error_code}): {error_message}"logger.error(error_msg)return False, error_msg, None, 200except Exception as e:# 其他数据库错误error_msg = f"执行查询时发生错误: {str(e)}"logger.error(error_msg)return False, error_msg, None, 200# 检查是否超时elapsed_time = time.time() - start_timeif elapsed_time >= QUERY_TIMEOUT:error_msg = f"查询执行超时 (>{QUERY_TIMEOUT}秒)"logger.error(error_msg)return False, error_msg, None, 200except Exception as e:error_msg = f"处理查询时发生未知错误: {str(e)}"logger.error(error_msg)return False, error_msg, None, 200@app.route('/sqlagent/demo/execQuery', methods=['POST'])
def exec_query():"""处理SQL查询请求的API端点"""try:# 记录请求开始时间start_time = time.time()# 使用专用函数记录请求详情request_info = log_request_details(request)# 提取常用变量,方便后续使用client_ip = request_info['client_ip']body_data = request_info['body_data']data = request.get_json()if not data or 'sql' not in data:error_msg = '请求中缺少SQL参数'logger.warning(error_msg)return jsonify({'status': False,'errorMsg': error_msg,'data': None}), 200sql = data['sql']logger.info(f"API接收到SQL查询: {sql}")# 设置超时控制start_time = time.time()status, error_msg, result, http_status = execute_query(sql)elapsed_time = time.time() - start_time# 如果执行时间超过阈值但没有被数据库超时捕获,在这里处理if elapsed_time >= QUERY_TIMEOUT and status:status = Falseerror_msg = f"查询执行超时 (>{QUERY_TIMEOUT}秒)"http_status = 200logger.error(error_msg)response = {'status': status,'errorMsg': error_msg,'data': result,'executionTime': round(elapsed_time, 3) # 添加执行时间信息(秒)}# 记录响应结果if status:logger.info(f"查询成功响应 - 耗时: {round(elapsed_time, 3)}秒, 结果数量: {len(result) if result else 0}")else:logger.warning(f"查询失败响应 - 耗时: {round(elapsed_time, 3)}秒, 错误: {error_msg}")# 无论SQL执行成功与否,始终返回200状态码return jsonify(response), 200except Exception as e:error_msg = f'处理请求时发生错误: {str(e)}'logger.error(error_msg, exc_info=True)return jsonify({'status': False,'errorMsg': error_msg,'data': None}), 200if __name__ == '__main__':logger.info(f"SQL执行服务启动 - 监听地址: {APP_HOST}:{APP_PORT}")logger.info(f"日志文件路径: {LOG_FILE}")app.run(host=APP_HOST, port=APP_PORT)代码解读
- 连上数据库,执行body中的"sql": "select ..." 语句。
- 如果结果正确就把行列包成[{字段1:值...},{字段2: 值2}...]这样的结果返回。
- 如果执行有问题,仍以http status 200返回,只是会把错误信息放在errorMsg里
如下API请求示例

它的返回是这样的结构
{"data": [{"utilization_rate": "0.0027"}],"errorMsg": "","executionTime": 0.004,"status": true
}SQL先生成->再校验->再执行的小反思流
在执行前我们有2个节点:
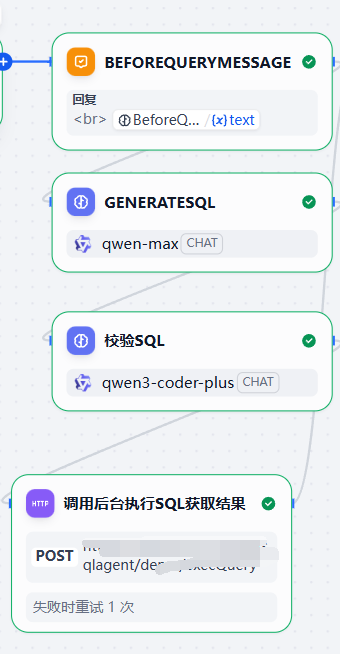
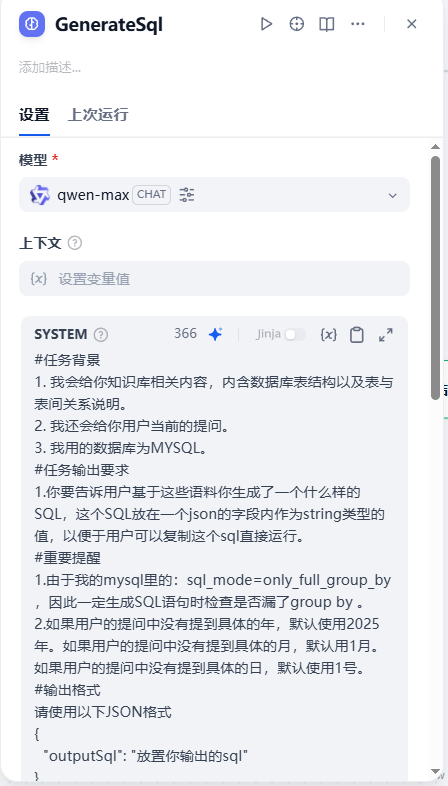
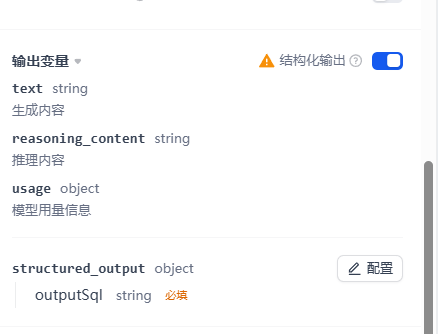
GENERATE SQL节点
这个节点的作用是用一个参数大的LLM去生成SQL
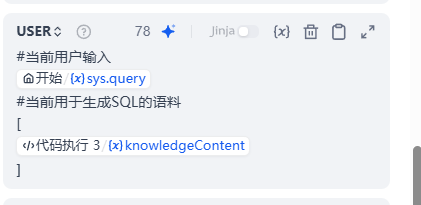
校验SQL节点
在生成完了SQL后,我们需要基于:用户的当前提问、语料、己经生成的SQL让LLM在执行前先看一下写得合不合理?对不对?有没有最优写法。
此时我们会动用类似qwen-code这种模型去做上述这样的精校验。
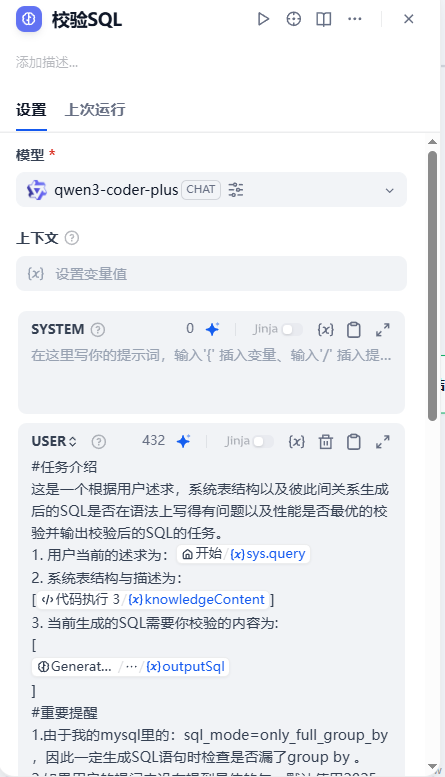
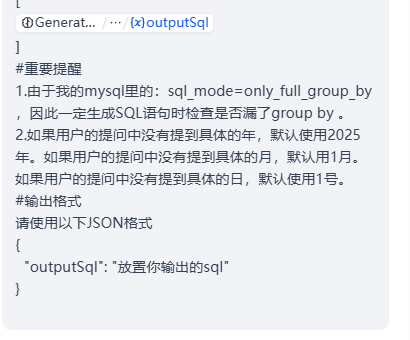
#任务介绍
这是一个根据用户述求,系统表结构以及彼此间关系生成后的SQL是否在语法上写得有问题以及性能是否最优的校验并输出校验后的SQL的任务。
1. 用户当前的述求为:{{#sys.query#}}
2. 系统表结构与描述为:
[{{#1762251306211.knowledgeContent#}}]
3. 当前生成的SQL需要你校验的内容为:
[
{{#1762406847432.structured_output.outputSql#}}
]
#重要提醒
1.由于我的mysql里的:sql_mode=only_full_group_by
,因此一定生成SQL语句时检查是否漏了group by 。
2.如果用户的提问中没有提到具体的年,默认使用2025年。如果用户的提问中没有提到具体的月,默认用1月。如果用户的提问中没有提到具体的日,默认使用1号。
#输出格式
请使用以下JSON格式
{"outputSql": "放置你输出的sql"
}
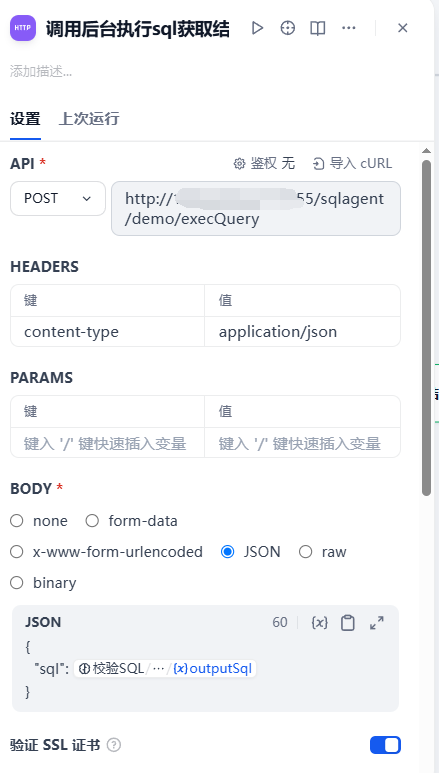
调用后台执行sql获取结果节点
这是一个http restful api请求节点,它就是把校验后的SQL送到后台python flask代码里去真正执行一下取SQL结果的。
如果执行成功,我们会在其后追加一个LLM节点,这个LLM节点的作用就是用来真正回答用户:根据您的提问。。。我查到了。。。如下结果。。。如下流程所示
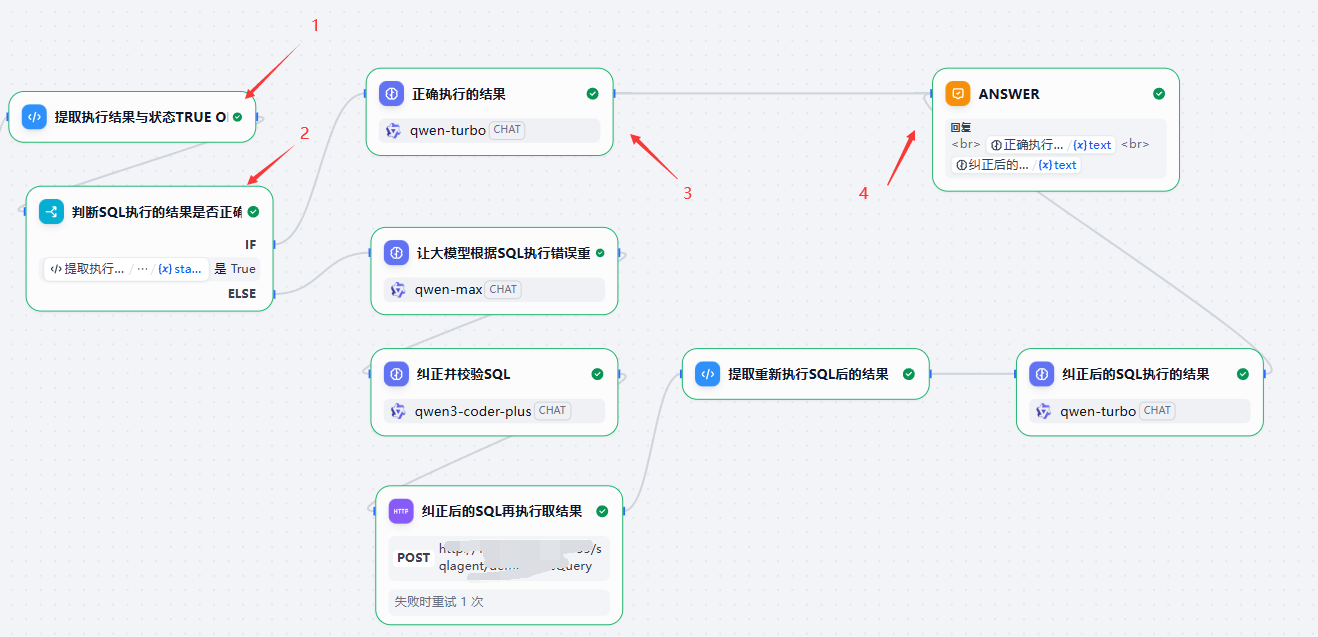
LLM回答结果节点
为了取得良好的回答效果,我们会使用比较好的LLM如:deepseekv3.1或者是qwen-max,当然如果为了追求回答速度,我们会使用qwen-turbo或者是与之相匹配的GPT4O去回答。
如果在执行SQL这一步返回status为false即代表执行有错了,此时我们进入反思流。
反思流程-根据后台返回的SQL错误进行纠正
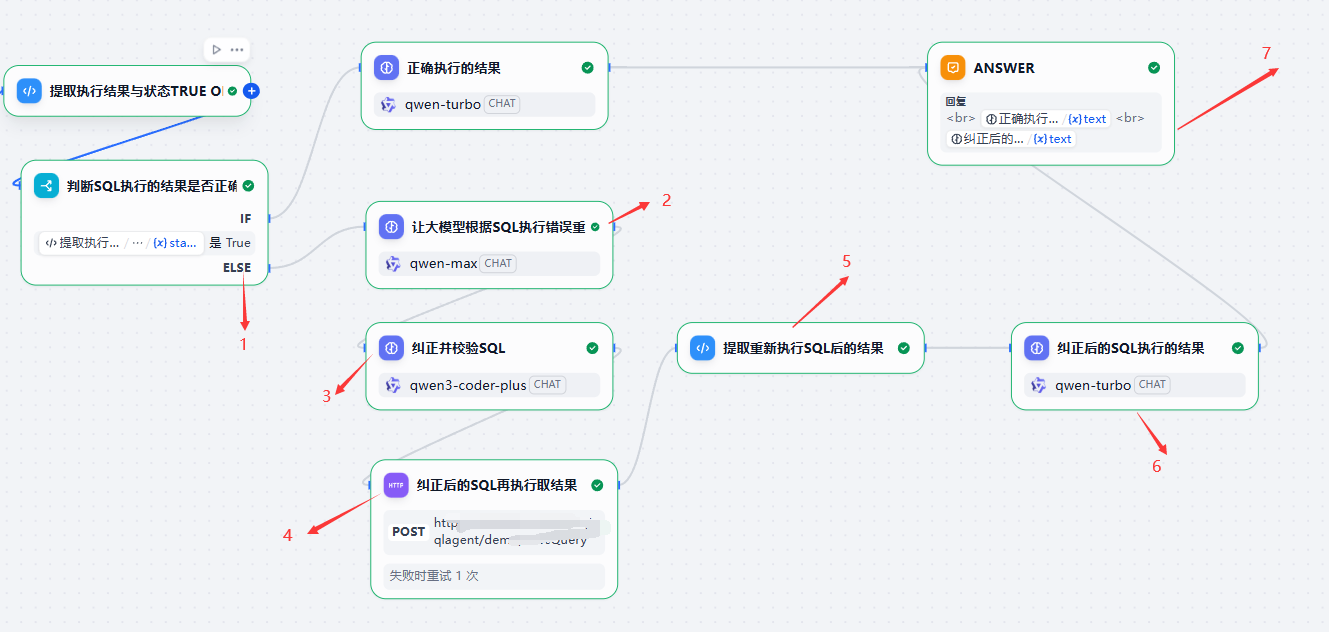
第1步-开始
获得后台SQL错误
即

第2步-反思原来的SQL错在哪
这是一个LLM,用参数较大的模型如:qwen-max去生成SQL。
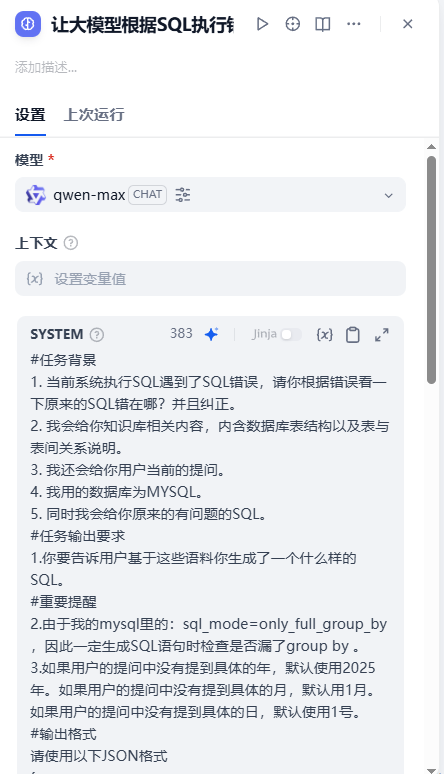
其生成的格式和第一次生成SQL时一样的格式,只是猫娘上有区别
system role message
#任务背景
1. 当前系统执行SQL遇到了SQL错误,请你根据错误看一下原来的SQL错在哪?并且纠正。
2. 我会给你知识库相关内容,内含数据库表结构以及表与表间关系说明。
3. 我还会给你用户当前的提问。
4. 我用的数据库为MYSQL。
5. 同时我会给你原来的有问题的SQL。
#任务输出要求
1.你要告诉用户基于这些语料你生成了一个什么样的SQL。
#重要提醒
2.由于我的mysql里的:sql_mode=only_full_group_by
,因此一定生成SQL语句时检查是否漏了group by 。
3.如果用户的提问中没有提到具体的年,默认使用2025年。如果用户的提问中没有提到具体的月,默认用1月。如果用户的提问中没有提到具体的日,默认使用1号。
#输出格式
请使用以下JSON格式
{"outputSql": "放置你输出的sql"
}
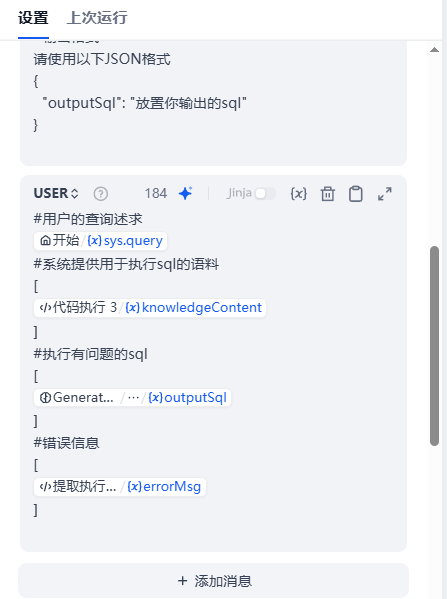
user role message
#用户的查询述求
{{#sys.query#}}
#系统提供用于执行sql的语料
[
{{#1762251306211.knowledgeContent#}}
]
#执行有问题的sql
[
{{#1762406847432.structured_output.outputSql#}}
]
#错误信息
[
{{#1762411254842.errorMsg#}}
]
我们可以看到此处我们加入了第1次执行SQL后的出错信息。
这个重新生成后的SQL不要马上去SqlExecuteClient.py里去做执行,而是在此之前也需要做一次校验。
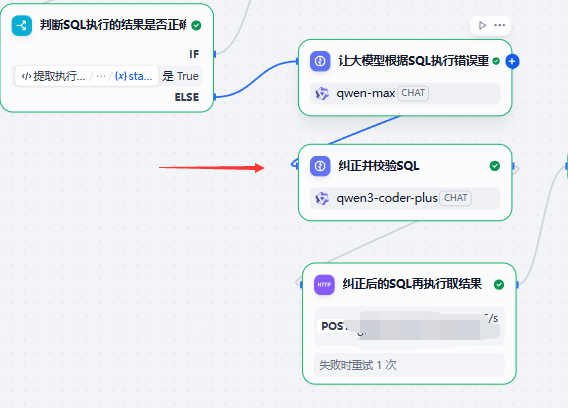
也是用类似qwen-code-plus或者是deepseek-v3.1这种聪明的模型去做一次校验。
把校验后的SQL再去做执行,并取得返回结果。
最终输出给到用户。
4. 演示
下面我给大家看一个当用户提问:
2025年1月~7月新格林耐特信息有限公司停车场被使用情况用百分比展示的查询。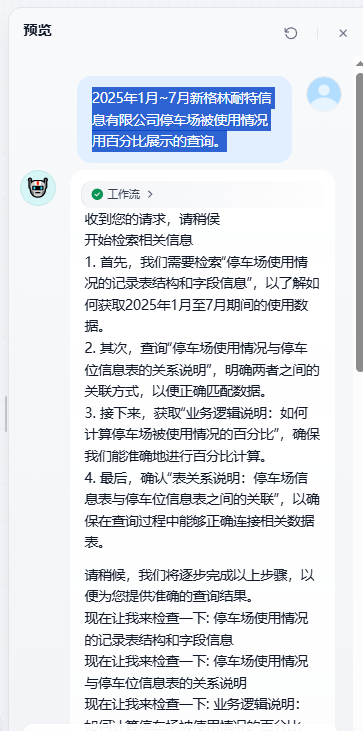
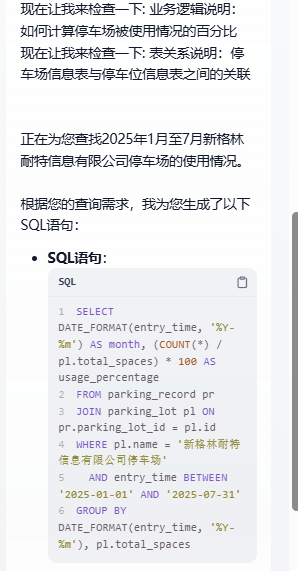
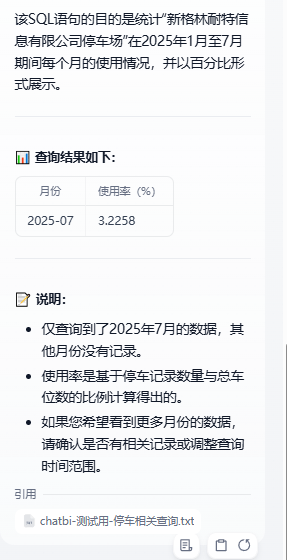
看,这个结果是perfect的!。
5. 设计总结
-
领域聚焦明确:限定“问数类”问题,大幅降低语义理解难度。
-
工程落地性强,务实性强:聚焦 BI 问数场景,避免通用问答的泛化难题;
-
动态检索创新:相比固定 Top-K,按需扩展知识库显著提升 token 利用率;
-
闭环纠错可靠:执行—反馈—修正机制有效降低 SQL 生成错误率。
-
模型分工合理:小模型处理简单任务,大模型攻坚复杂生成;
-
双重校验有效:显著提升复杂查询准确率,体现“生成—验证”思想;
-
可解释性增强:步骤日志输出提升用户信任与调试效率。
这是一个真正的基于AI原生的Agentic Rag的产品。
6. 可以改进的点
本文为了演示,简化了一些点的设计。它们分别展开成最终可以运行在生产环境的设计如下所叙。
在SQL生成节点的改进
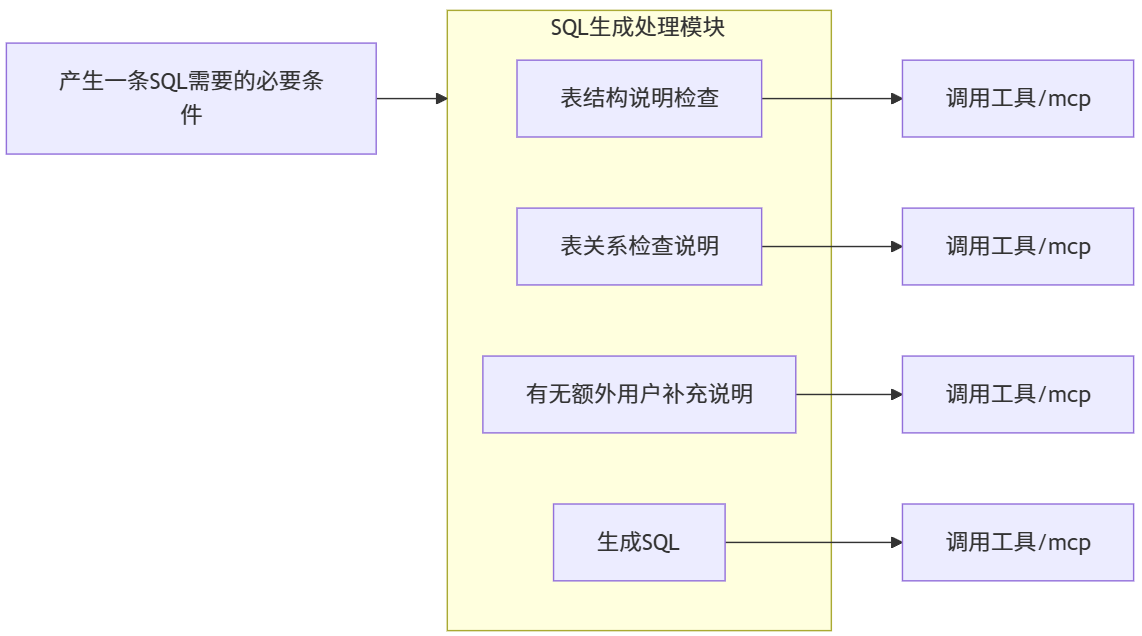
目前SQL生成节点只有一次机会,这一次机会其实很重要,为了在这一次机会里就提升到90%的精准率对用户体验很重要。
因此,这一步我们会使用AI原生式设计。
让AI产生中间黄色部分即:SQL生成处理模块的步骤,我这写的4步有时可能会6步或者是8步,模型越好折分的步骤越细。
每一个步骤都可以通过外部工具或者是MCP去做分步骤的运行与数据抽取。
因此我们会尽量多制作一些SQL生成用的小工具或者是MCP Client。
然后聚合上述步骤的结果,从而得到更佳的一次性SQL生成准确率用的结构化语料。
注:有无额外用户补充说明子节点的作用
是一个用于接受用户在外部反馈比如説:这条逻辑你错了因该是这样的一个“用户上报反馈”节点用的,以提供整个Agent与人的交互机制用。
在SQL生成失败后反思节点的改进
这个节点目前也只有一次反思,这是笔者为了演示用故意简化的结果。真实的生产上是这样的:
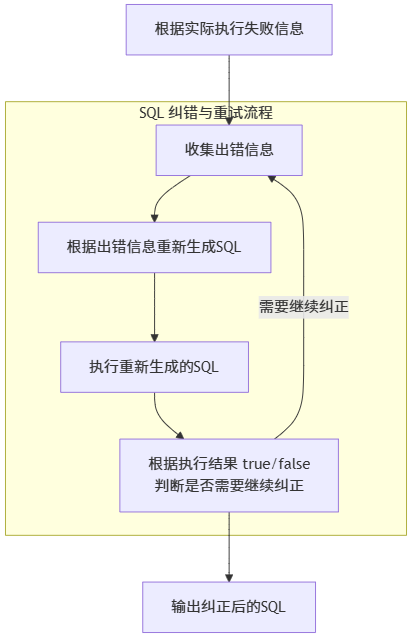
看,我们会在中间这个步骤做一个“循环”,这个循环最多执行3次,直到执行结果为true,如果3次还失败我们会把错误信息吐出让用户补充。
然后在意图识别后额外做一个“用户上报补充信息”的流程,这个流程会走到之前的“SQL生成节点”中的->有无额外用户补充说明这个子节点中去。
以上这两个优化就留作课后功课给到读者们自己去动手实现了!
7. 写在结尾
面向未来,一个真正强大的 ChatBI Agent 应融合前沿智能体范式,构建“可解释、可进化、可协作”的分析引擎:
1. 强化 Agentic RAG 与元知识融合
- 构建数据库元知识图谱,包含表、字段、关系、业务含义、常用指标定义。
- 检索时结合语义相似度与图谱路径(如“用户问‘车主’ → 关联 vehicle 表 → 自动包含其外键 parking_record”)。
- 支持“检索—验证—精炼”多轮交互,而非简单追加。
2. 实现显式 ReAct 与 Plan-and-Execute 融合
非一次性执行而是AI先做“任务折解的规划”,需要分成几步执行然后分步骤去调外部工具或者是MCP Client。
3. 引入多代理协作架构
- Planner Agent:负责任务分解与资源调度。
- Schema Expert Agent:专精数据库结构理解与字段映射。
- SQL Generator Agent:微调的 SQL 专用模型,确保语法合规。
- Validator Agent:执行静态检查(字段存在、类型匹配)与动态采样验证。
- Explainer Agent:将 SQL 结果转化为自然语言洞察。
4. 构建分层管理者-工作者体系
Manager Layer:监控整体进度,处理异常,决定是否重试/降级/求助人工。
Worker Pool:按需调用不同能力的 LLM 或规则引擎,实现成本与性能平衡。
5. 建立持续反思与学习机制
- 记录每次交互的完整轨迹(问题、检索、SQL、结果、用户反馈)。
- 定期训练微调模型或更新检索索引。
- 对高频错误模式自动生成 FAQ 或提示模板。
6. 增强安全与治理能力
- SQL 执行前进行权限校验与敏感字段脱敏。
- 支持查询成本预估(如预计扫描行数),防止资源耗尽。
- 提供“可解释性报告”:展示为何选择某张表、某字段。
好了,结束今天的分享。相信通过今天的分享,大家有了一个非常完整的Text2SQL的设计思路以及真正理解了Agentic RAG是长什么样的?什么叫AI原生的概念到落地的实操了。
当前设计作为 MVP,成功验证了“自然语言→SQL→结果解读”闭环的可行性,其动态检索与纠错机制是亮点。
然而,要迈向企业级 Production-Ready 系统,必须超越“流程串联”思维,拥抱真正的智能体范式。
未来的 ChatBI Agent 不应只是一个“SQL 翻译器”,而应成为用户的“数据协作者”——能主动提问澄清模糊需求,能建议更优分析视角,能从历史交互中学习偏好,甚至能预警数据质量问题。这需要我们在架构上大胆引入多代理、分层管理、持续学习等机制,在工程上平衡性能、成本与可靠性。
唯有如此,才能让“问数即得”从技术演示变为业务常态,真正释放数据智能的生产力。