李宏毅机器学习笔记42
目录
摘要
1.selective synaptic plasticity
2.additional neural resource allocation
3.memory reply
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是life long learning的三种解决办法,分别为selective synaptic plasticity,additional neural resource allocation,memory reply。
1.selective synaptic plasticity
catastrophic forgetting问题发生原理是:假设任务1和任务2的模型参数只有两个,下图代表任务1和任务2的error surfaces,颜色越偏蓝,loss越小。在任务1上初始参数为,训练后得到
,将同样的参数copy到任务2上,在任务2上更新参数得到
。将
放会任务1上看就会发现在任务1上出现了“忘记”的现象(效果变差)。

如果更新不向右上移动,而是更偏向右移动是否会让任务1没有“忘记”的情况出现?这个就是selective synaptic plasticity的做法,它的基本思路是:每一个参数对过去学过的任务的重要性是不一样的,在学习新的任务时,希望那些旧的重要的参数尽量不要变,新的任务更改那些不重要的旧参数即可。同样的例子,
是上一个任务训练出的参数,selective synaptic plasticity 给每个参数一个保镖b_i,它代表参数对过去任务的重要性。

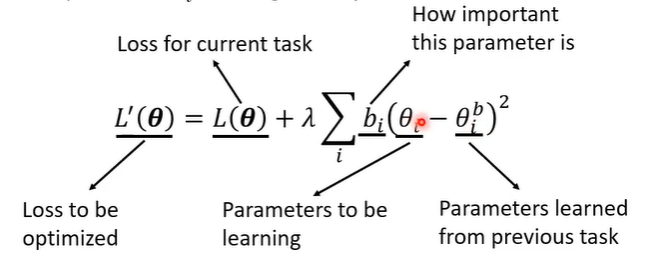
在更新参数时,也需要更改loss function,原来的loss为,更改后为
,
在原来的loss
上多增加了一项,
表示需要更新的参数,
表示过去任务训练出来的参数,让
和
相减,代表他们越接近越好,
则代表
的重要性。
仅代表部分参数,不需要所有参数都接近
。还有一个问题是,如果
为0(过小),会导致catastrophic forgetting问题,如果
过大,虽然不会导致“遗忘”,但是也会无法学好新的任务。

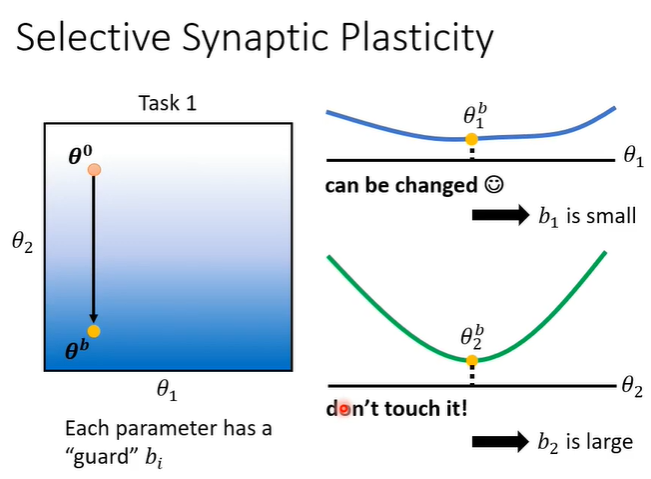
那么确定,就是要确定某个参数重不重要。可以在训练完某个模型后,看看模型中每个参数对这个任务的影响,举例来说,将下图的
在
方向上移动,可以发现对loss没有什么影响,这就代表
对这个任务没有很重要,所以就可以给
的
较小的值。以此类推,在
方向上移动,可以发现对loss的影响较大,这就代表
对这个任务很重要,所以就可以给
的
较大的值。
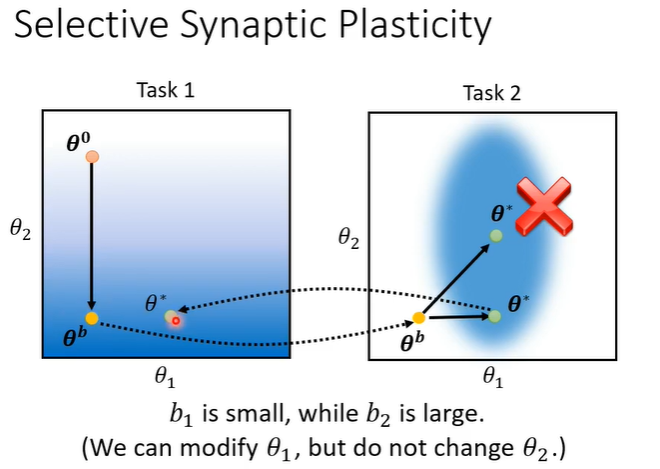
给的
较小的值,给
的
较大的值会呈现下图所示的情况,此时将
放会任务1上看就会发现在任务1上效果依然可观,避免了“忘记”的现象。
2.additional neural resource allocation
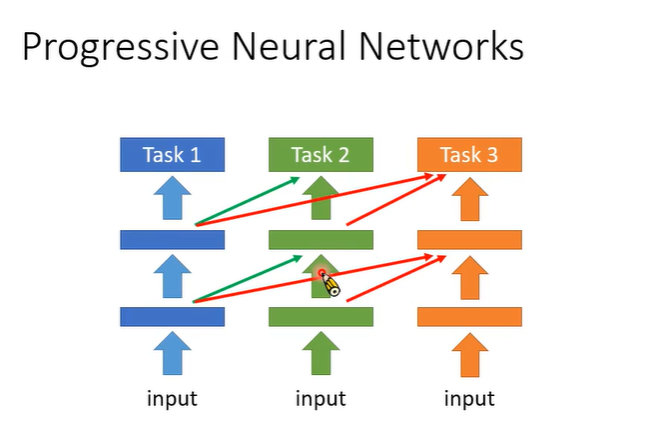
一个最早的做法叫做progressive neural network,想法是任务1是一个模型,任务2是另一个模型,但是任务2的模型会接收任务1hidden layer的输出,它会吸收任务1所学到的有用的资讯,但是不动任务1的参数,只会增加新的参数,任务三也是同理,不动前两个任务的参数。这样也解决了catastrophic forgetting问题,但是每次训练新的任务时需要额外的空间产生额外的neural,最后会导致模型过大,大到无法存储。
还有一个与progressive neural network相反的做法叫做packnet,想法是先开一个较大的network,每次有新任务,就取用部分参数,例如任务1只用下图灰色部分的参数,任务2只用橙色部分的参数,任务3只用绿色部分的参数。好处是参数量不会随着任务增多而增多,但是最终也是有上限的。

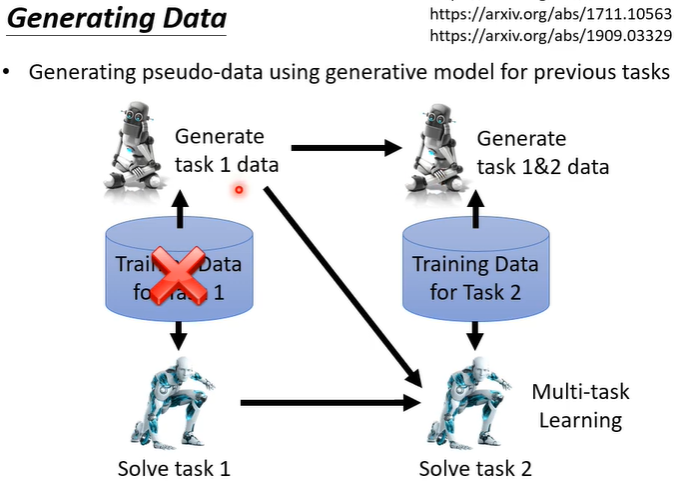
3.memory reply
memory reply非常直接,之前我们知道当所有资料混在一起训练,就没有catastrophic forgetting问题,但是不能存储过去的所有资料,所以训练一个generating model,能让过去的资料在训练时及时产生出来。举例来说,在训练任务1时,同时训练一个generator,他会产生任务1的资料。在训练任务2时,用generator产生任务1的资料一起训练,同时再训练一个会产生任务1和任务2的资料generator,以此类推。