基于spark岗位招聘推荐系统 基于用户协同过滤算法 Django框架 数据分析 可视化 大数据 (建议收藏)✅
博主介绍:✌全网粉丝50W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅
1、2026年计算机专业毕业设计选题大全(建议收藏)✅
2、大数据、计算机专业选题(Python/Java/大数据/深度学习/机器学习)(建议收藏)✅
1、项目介绍
技术栈:python语言、Django框架、MySQL数据库、前端用的bootstrap做界面渲染设计、基于用户的协同过滤算法、Echarts可视化
项目主要的功能模块
1、用户登录,注册,退出登录
2、前台:岗位操作(查看、评论、评分等)、投递简历、推荐岗位、图表分析展示
3、后台:岗位管理、用户管理、评论管理、打分管理、分类管理等
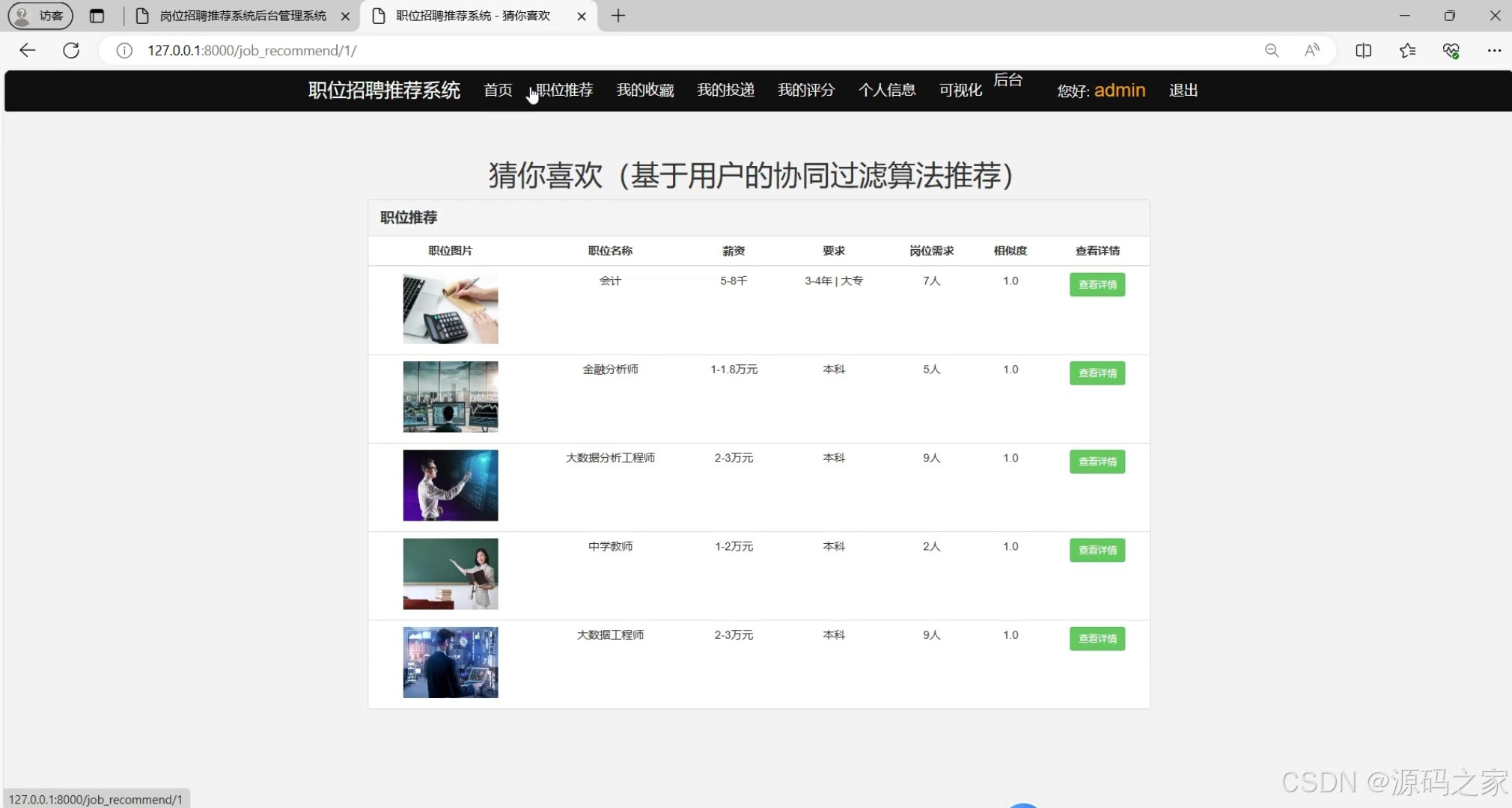
4、推荐岗位(推荐列表),使用推荐系统(基于用户的协同过滤)算法,给用户推荐可能喜欢的岗位
基于python+django+MySQL+基于用户的协同过滤算法的岗位招聘推荐系统
2、项目界面
(1)首页
(2)岗位推荐
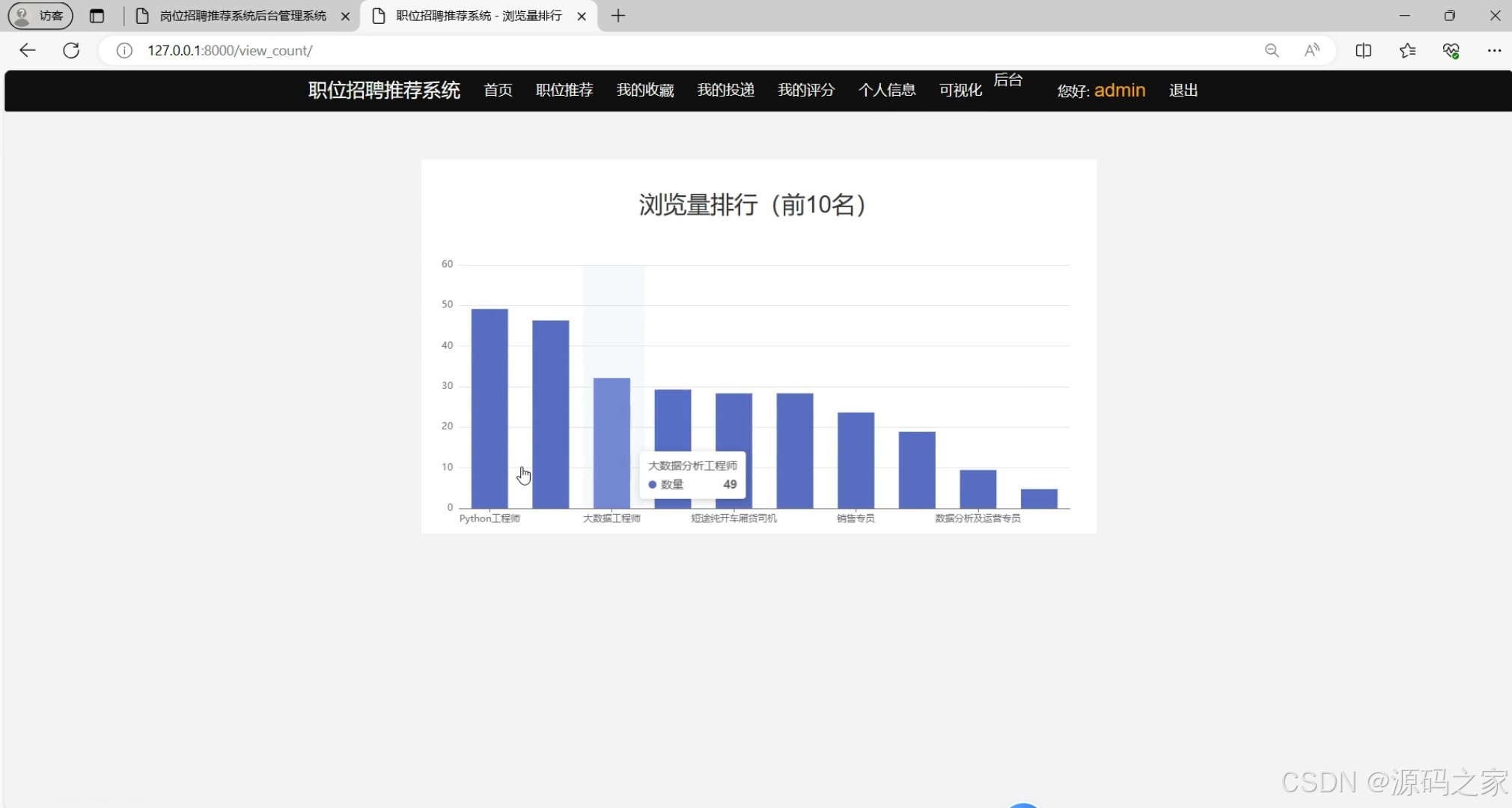
(3)数据可视化
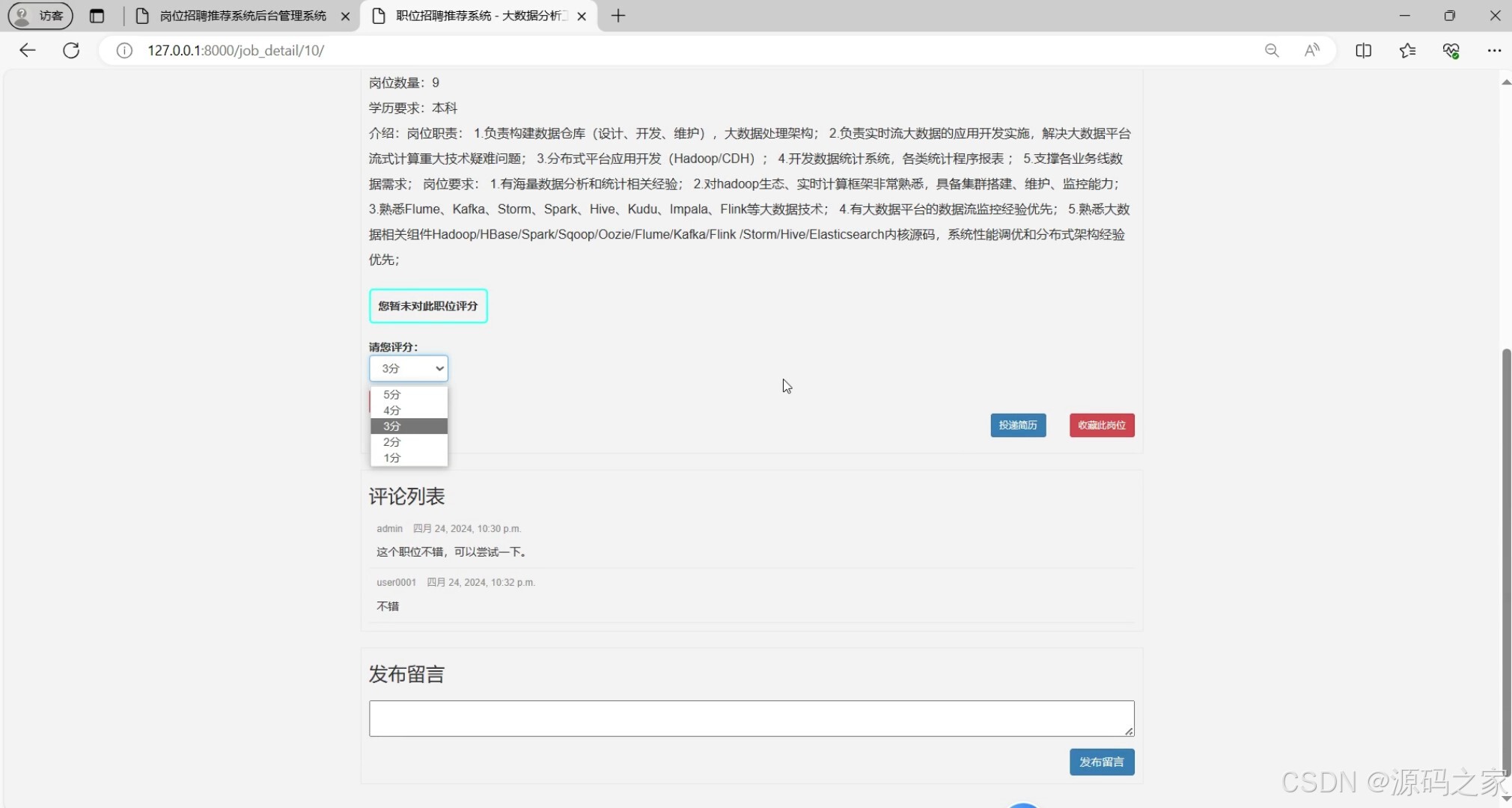
(4)岗位评分
(5)岗位详情页
(6)我的投递
(7)我的评分
(8)个人信息
(9)注册登录
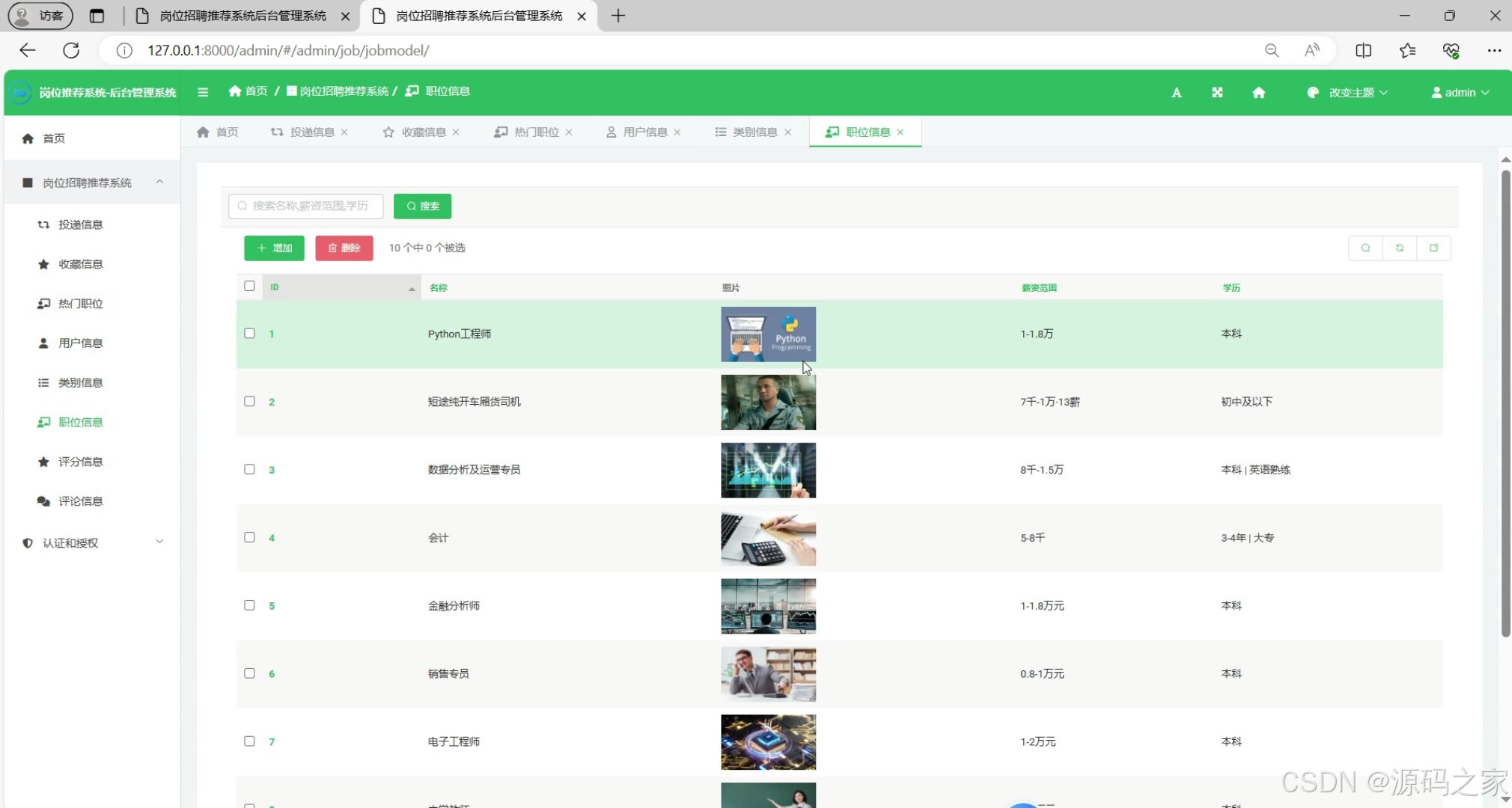
(10)后台管理
3、项目说明
本岗位招聘推荐系统以 Python 为开发语言,依托 Django 框架搭建后端架构,采用 MySQL 数据库存储数据,前端通过 Bootstrap 实现响应式界面渲染,结合基于用户的协同过滤算法与 Echarts 可视化技术,构建了人岗交互、智能推荐、数据管理一体化平台。
系统功能覆盖用户全流程需求:前台端支持用户登录、注册、退出操作,用户可浏览岗位详情、对岗位评论评分、提交简历投递,核心推荐模块通过协同过滤算法分析用户偏好,生成个性化岗位列表,提升人岗匹配效率;同时嵌入 Echarts 可视化模块,直观展示岗位分布、投递趋势等数据,辅助用户决策。
后台管理端聚焦运营管控,提供岗位管理(新增 / 编辑 / 删除)、用户管理(权限控制 / 信息维护)、评论管理(审核 / 筛选)、打分管理(数据统计)及分类管理功能,保障平台有序运行。
界面设计贴合使用场景,首页布局清晰、岗位推荐页重点突出,“我的投递”“我的评分”“个人信息” 页面便于用户追踪操作记录,注册登录界面简洁易用,后台管理界面功能分区明确,整体兼顾用户体验与运营效率,有效解决传统招聘 “信息冗杂、匹配低效” 问题。
4、核心代码
# 职位详情
def job_detail(request, job_id):job = JobModel.objects.get(id=job_id) # 查询岗位信息comments = CommentModel.objects.filter(job_id=job_id) # 查询岗位评论user_id = request.session.get('user_id')if user_id:flag_mask = MarkModel.objects.filter(item_id=job_id, user_id=user_id).first() # 打分情况else:flag_mask = Falsejob.view_number += 1 # 浏览量+1job.save()context = {'job': job,'comments': comments,'flag_mask': flag_mask}return render(request, 'job_detail.html', context=context)# 分类下职位列表
def job_list(request, category_id):jobs = JobModel.objects.filter(category_id=category_id)return render(request, 'job_list.html', {'jobs': jobs})# 投递简历
def add_order(request):user_id = request.session.get('user_id')if not user_id:return JsonResponse({'code': 400, 'message': '请先登录'})job_id = request.POST.get('job_id')flag = OrderModel.objects.filter(user_id=user_id, job_id=job_id).first()if flag:return JsonResponse({'code': 400, 'message': '您已投递该岗位,请勿重复投递!'})OrderModel.objects.create(user_id=user_id,job_id=job_id)return JsonResponse({'code': 200})# 添加收藏
def add_collect(request):user_id = request.session.get('user_id')if not user_id:return JsonResponse({'code': 400, 'message': '请先登录'})job_id = request.POST.get('job_id')flag = CollectModel.objects.filter(user_id=user_id, job_id=job_id).first()if flag:return JsonResponse({'code': 400, 'message': '您已收藏该岗位,请勿重复收藏!'})CollectModel.objects.create(user_id=user_id,job_id=job_id)return JsonResponse({'code': 200})# 添加评论
def add_comment(request):user_id = request.session.get('user_id')if not user_id:return JsonResponse({'code': 400, 'message': '请先登录'})content = request.POST.get('content')job_id = request.POST.get('job_id')if not content:return JsonResponse({'code': 400, 'message': '内容不能为空'})CommentModel.objects.create(user_id=user_id,content=content,job_id=job_id)return JsonResponse({'code': 200})# 用户对岗位进行评分
def input_score(request):user_id = request.session.get('user_id')if not user_id:return JsonResponse({'code': 400, 'message': '请先登录'})score = int(request.POST.get('score'))item_id = request.POST.get('job_id')mark = MarkModel.objects.filter(item_id=item_id, user_id=user_id).first()if mark:mark.score = scoremark.save()else:MarkModel.objects.create(item_id=item_id,score=score,user_id=user_id)return JsonResponse({'code': 200})# 我的收藏
def my_collect(request):user_id = request.session.get('user_id')collects = CollectModel.objects.filter(user_id=user_id)return render(request, 'my_collect.html', {'collects': collects})# 取消收藏
def delete_collect(request):collect_id = request.POST.get('collect_id')collect = CollectModel.objects.get(id=collect_id)collect.delete()return JsonResponse({'code': 200})# 我的投递信息
def my_order(request):user_id = request.session.get('user_id')orders = OrderModel.objects.filter(user_id=user_id)return render(request, 'my_order.html', {'orders': orders})# 我的评分信息
def my_mark(request):user_id = request.session.get('user_id')marks = MarkModel.objects.filter(user_id=user_id)return render(request, 'my_mark.html', {'marks': marks})# 个人信息
def my_info(request):user_id = request.session.get('user_id')if request.method == 'GET':# 个人信息界面info = UserInfoModel.objects.get(id=user_id)return render(request, 'my_info.html', {'info': info})else:# 更新个人信息username = request.POST.get('username')password = request.POST.get('password')phone = request.POST.get('phone') or ''edu_level = request.POST.get('edu_level') or ''major = request.POST.get('major') or ''age = request.POST.get('age') or ''content = request.POST.get('content') or ''UserInfoModel.objects.filter(id=user_id).update(username=username,password=password,phone=phone,edu_level=edu_level,major=major,age=age,content=content,)return JsonResponse({'code': 200})# 浏览量统计
def view_count(request):if request.method == 'GET':return render(request, 'view_count.html')else:jobs = JobModel.objects.all().order_by('-view_number')[:10]name_list = []count_list = []for job in jobs:name_list.append(job.name)count_list.append(job.view_number)return JsonResponse({'code': 200, 'name_list': name_list, 'count_list': count_list})# 计算两用户的余弦相似度
def calculate_cosine_similarity(user_ratings1, user_ratings2):# 将用户1的职位评分存入字典,键为职位ID,值为评分 1:5 2:3item_ratings1 = {rating.item_id: rating.score for rating in user_ratings1}print('item_ratings1:', item_ratings1)# 将用户2的职位评分存入字典,键为职位ID,值为评分 1:4item_ratings2 = {rating.item_id: rating.score for rating in user_ratings2}print('item_ratings2:', item_ratings2)# 找出两个用户共同评价过的职位 1common_items = set(item_ratings1.keys()) & set(item_ratings2.keys())print('common_items:', common_items)if len(common_items) == 0:return 0.0 # 无共同评价的职位,相似度为0# 提取共同评价职位的评分,存入NumPy数组user1_scores = np.array([item_ratings1[item_id] for item_id in common_items]) # 5user2_scores = np.array([item_ratings2[item_id] for item_id in common_items]) # 4print('user1_scores:', user1_scores)print('user2_scores:', user2_scores)# 计算余弦相似度cosine_similarity = np.dot(user1_scores, user2_scores) / (np.linalg.norm(user1_scores) * np.linalg.norm(user2_scores))print('cosine_similarity:', cosine_similarity)return cosine_similarity# 基于用户协同过滤推荐
def user_based_recommendation(request, user_id):try:# 获取目标用户对象target_user = UserInfoModel.objects.get(id=user_id)except UserInfoModel.DoesNotExist:return JsonResponse({'code': 400, 'message': '该用户不存在'})# 获取目标用户的职位评分记录target_user_ratings = MarkModel.objects.filter(user=target_user)# 用于存储推荐职位的字典recommended_items = {}# 遍历除目标用户外的所有其他用户 test1 bhmlfor other_user in UserInfoModel.objects.exclude(pk=user_id):# 获取其他用户的职位评分记录other_user_ratings = MarkModel.objects.filter(user=other_user)# 计算目标用户与其他用户的相似度similarity = calculate_cosine_similarity(target_user_ratings, other_user_ratings)if similarity > 0:# 遍历其他用户评价的职位for item_rating in other_user_ratings:# 仅考虑目标用户未评价过的职位if item_rating.item.id not in target_user_ratings.values_list('item', flat=True):if item_rating.item.id in recommended_items:# 累积相似度加权的评分和相似度recommended_items[item_rating.item.id]['score'] += similarity * item_rating.scorerecommended_items[item_rating.item.id]['similarity'] += similarityelse:# 创建推荐职位的记录recommended_items[item_rating.item.id] = {'score': similarity * item_rating.score,'similarity': similarity}# 将推荐职位按照加权评分排序sorted_recommended_items = sorted(recommended_items.items(), key=lambda x: x[1]['score'], reverse=True)# 获取排名靠前的推荐职位的IDtop_recommended_items = [item_id for item_id, _ in sorted_recommended_items[:5]]# 构建响应数据response_data = []for item_id in top_recommended_items:item = JobModel.objects.get(pk=item_id)similarity = recommended_items[item_id]['similarity']response_data.append({'job': item,'name': item.name,'id': item.id,'image': item.image,'similarity': similarity,})context = {'response_data': response_data}return render(request, 'job_recommend.html', context=context)
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻