Mamba YOLO: 基于状态空间模型的目标检测简单基线
摘要
在深度学习技术快速发展的推动下,YOLO系列为实时目标检测器设立了新的基准。此外,基于Transformer的结构已成为该领域最强大的解决方案,极大地扩展了模型的感受野并实现了显著的性能提升。然而,这种改进是以牺牲计算量为代价的,因为自注意力机制的二次复杂度增加了模型的计算负担。为了解决这个问题,我们引入了一种简单而有效的基线方法,称为Mamba YOLO。我们的贡献如下:1)我们提出ODMamba骨干网络引入具有线性复杂度的状态空间模型(SSM)来解决自注意力的二次复杂度问题。与其他基于Transformer和基于SSM的方法不同,ODMamba无需预训练即可轻松训练。2)针对实时性要求,我们设计了ODMamba的宏观结构,确定了最佳阶段比例和缩放尺寸。3)我们设计了采用多分支结构对通道维度进行建模的RG Block,以解决SSM在序列建模中可能存在的局限性,例如感受野不足和图像定位能力弱。该设计更准确、更显著地捕获局部图像依赖性。在公开可用的COCO基准数据集上进行的大量实验表明,与先前的方法相比,Mamba YOLO实现了最先进的性能。具体来说,Mamba YOLO的小型版本在单个4090 GPU上实现了7.5%的mAP提升,推理时间为1.5毫秒。PyTorch代码可在以下网址获取:https://github.com/HZAI-ZJNU/Mamba-YOLO
引言
近年来,深度学习迅速发展,特别是在计算机视觉领域,一系列强大的架构取得了令人印象深刻的性能。从卷积神经网络(CNNs)(Huang等人2017;Tan和Le 2020;Liu等人2022)到视觉Transformer(ViTs)(Liu等人2021;Shi 2023),各种结构的应用展示了它们在计算机视觉中的强大潜力。在下游任务
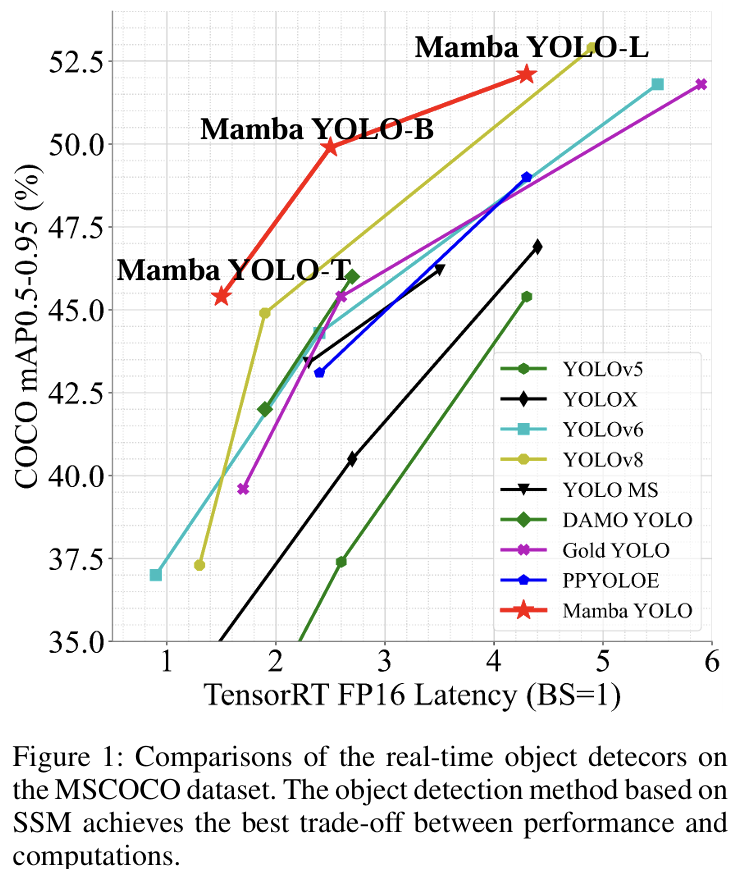
目标检测中,主要使用CNNs(Ren等人2016;Liu等人2016)和Transformer结构(Carion等人2020;Zhang等人2022)。虽然CNNs及其一系列改进在保证精度的同时提供了快速的执行速度,但它们存在图像关联性差的问题。为了解决这个问题,研究人员将ViTs引入目标检测领域,例如DETR系列(Carion等人2020;Zhu等人2020),它利用了自注意力的强大全局建模能力。随着硬件的进步,这种结构带来的内存计算增加不会造成太大问题。然而,近年来,更多的工作(Liu等人2022;Zhang等人2023;Wang等人2023)开始重新思考如何设计CNNs以使模型更快,并且更多的实践者对Transformer结构的二次复杂度感到不满。他们开始
使用混合结构来重建模型并降低复杂度,例如MobileVit(Mehta和Rastegari 2021)、EdgeVit(Chen等人2022)和EfficientFormer(Li等人2023)。混合模型也带来了挑战,性能的明显下降是一个令人担忧的问题。因此,在性能和速度之间找到平衡一直是研究人员关注的问题。最近,基于结构化状态空间模型(SSM)的方法,如Mamba(Gu和Dao 2023),因其对长距离依赖性的强大建模能力以及线性时间复杂度的优越特性,为解决这些问题提供了新思路。
本文提出了一种名为Mamba YOLO的检测器模型。我们设计了目标检测结构化ODSSBlock模块,如图2所示,将SSM应用于目标检测领域。与用于图像分类的视觉状态空间块(Liu等人2024)相比,目标检测任务通常涉及分辨率更高、像素密度更大的图像。鉴于SSM主要用于文本序列建模,它缺乏充分利用图像中通道深度的固有能力。为了利用这些高分辨率图像提供的增强细节和多通道信息,我们引入了残差门控(RG)块结构。该结构采用选择性扫描2D(SS2D)处理来细化输出,利用高维点积操作来增强通道间相关性并提取更丰富的特征表示。我们在MSCOCO(Lin等人2015)上进行了详尽的实验,结果表明Mamba YOLO在MSCOCO的一般目标检测任务中非常有竞争力。本文的主要贡献可总结如下:
· 我们提出的基于SSM的Mamba YOLO具有简单高效的结构,具有线性内存复杂度,并且不需要在大规模数据集上进行预训练,为YOLO在目标检测中建立了新的基线。
我们提出ODSSBlock来弥补SSM的局部建模能力。通过重新思考MLP层的设计,我们结合门控聚合思想与有效卷积和残差连接引入了RG Block,有效捕获局部依赖性并增强模型鲁棒性。
我们设计了一组不同尺度的模型,Mamba YOLO(Tiny/Base/Large),以支持不同规模和尺度的任务部署。在MSCOCO上的实验,如图1所示,表明我们的Mamba YOLO与现有最先进方法相比实现了显著的性能提升。
相关工作
实时目标检测器 YOLO早期的性能改进与骨干网络的改进密切相关,并导致了DarkNet的广泛采用。YOLOv7(Wang,Bochkovskiy和Liao 2023)提出了E-ELAN结构,在不破坏原始梯度路径的情况下增强模型能力。YOLO8(Jocher, Chaurasia,
和 Qiu 2023) 结合了前几代YOLO的特点,采用CSPDarknet53到2阶段FPN(C2f) (Jocher, Chaurasia, and Qiu 2023) 结构,具有更丰富的梯度流,在考虑精度的同时轻量且适应不同场景。最近,Gold YOLO (Wang等人2024) 引入了一种名为 Gather-and-Distribute (GD) 的新机制,通过自注意力操作实现,解决了传统特征金字塔网络 (Lin等人2017) 和 Rep-PAN (Li等人2022) 的信息融合问题,并成功达到了SOTA。
端到端目标检测器 DETR (Carion等人2020) 首次将Transformer引入目标检测,使用Transformer编码器-解码器架构,绕过了传统的手工组件,如锚点生成和非极大值抑制,将检测视为一个直接的集合预测问题。Deformable DETR (Zhu等人2020) 引入了可变形注意力,是Transformer注意力的一种变体,用于在参考位置周围采样一组稀疏的关键点,解决了DETR在处理高分辨率特征图时的局限性。DINO (Zhang等人2022) 集成了混合查询选择策略、可变形注意力,并通过注入噪声训练和查询优化展示了性能提升。RT-DETR (Zhao等人2023) 提出了一种混合编码器,解耦了尺度内交互和尺度间融合,以实现高效的多尺度特征处理。然而,DETR的优异性能严重依赖于在大规模数据集上的预训练操作,并且面对DETR训练收敛、计算成本和小目标检测的挑战,YOLO在兼具精度和速度的小模型领域仍然是SOTA。
视觉状态空间模型 基于SSM的研究 (Gu, Goel, and Ré 2022; Gu等人2021; Smith, Warrington, and Linderman 2023),Mamba (Gu and Dao 2023) 在输入大小上显示出线性复杂度,并解决了Transformer在长序列建模状态空间时的计算效率问题。在通用视觉骨干网络领域,Vision Mamba (Zhu等人2024) 提出了一个基于选择性SSM的纯视觉骨干模型,标志着Mamba首次被引入视觉领域。VMamba (Liu等人2024) 引入了Cross-Scan模块,使模型能够对2D图像进行选择性扫描,增强了视觉处理能力,并在图像分类任务上展示了优越性。LocalMamba (Huang等人2024) 关注视觉空间模型的窗口扫描策略,优化视觉信息以捕获局部依赖性,并引入动态扫描方法为不同层搜索最优选择。受VMamba在视觉任务中取得的显著成果启发,本文首次提出了Mamba YOLO,一种新的SSM模型,与传统的基于SSM的视觉骨干网络不同,它不需要在大规模数据集(例如ImageNet (Deng等人2009), Object365 (Shao等人2019))上进行预训练,旨在兼顾全局感受野的同时展示其在目标检测中的潜力。
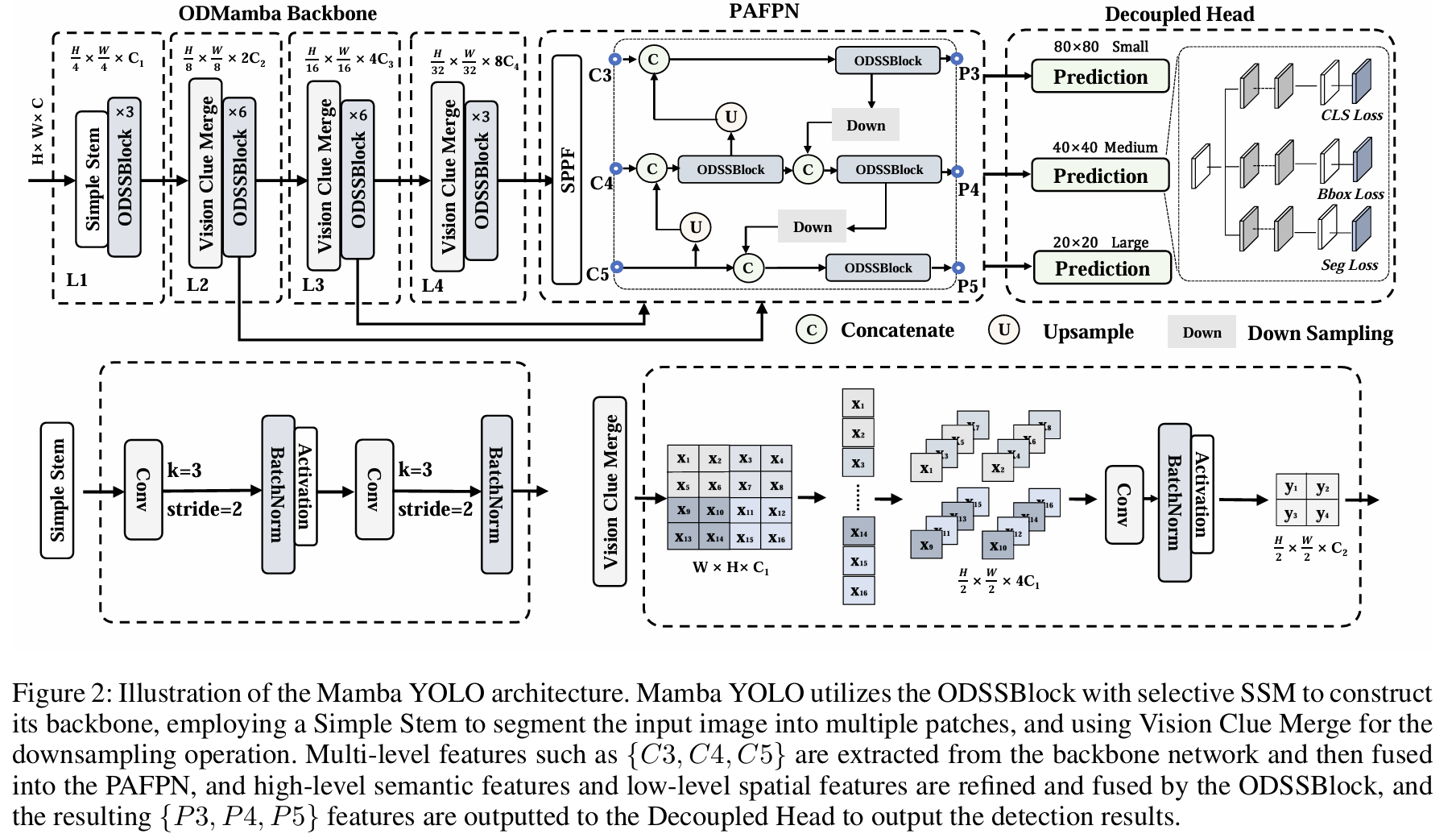
图2:Mamba YOLO架构示意图。Mamba YOLO利用带有选择性SSM的ODSSBlock构建其骨干网络,使用Simple Stem将输入图像分割成多个块,并使用Vision Clue Merge进行下采样操作。从骨干网络提取多级特征如{C3, C4, C5},然后融合到PAFPN中,通过ODSSBlock细化和融合高层语义特征和低层空间特征,将得到的{P3,P4,P5}\{P3,P4,P5\}{P3,P4,P5}特征输出到解耦头以输出检测结果。
方法
预备知识
结构化状态空间序列模型S4 (Gu, Goel, and Ré 2022) 和 Mamba (Gu and Dao 2023),植根于SSM,都源于一个连续系统,该系统将一个单变量序列x(t)∈Rx(t)\in\mathbb{R}x(t)∈R通过一个隐式的潜在中间状态h(t)∈RN\boldsymbol{h}(t)\in\mathbb{R}^{N}h(t)∈RN映射到一个输出序列y(t)y(t)y(t)。这种设计不仅建立了输入和输出之间的关系,还封装了时间动态。该系统可以在数学上定义如下:
h′(t)=Ah(t)+Bx(t)y(t)=Ch(t)\begin{array}{c}{h^{\prime}(t)=\mathbf{A}h(t)+\mathbf{B}x(t)}\\ {y(t)=\mathbf{C}h(t)}\end{array}h′(t)=Ah(t)+Bx(t)y(t)=Ch(t)
在方程(1)中,A∈RN×N\mathbf{A}\;\in\;\mathbb{R}^{N\times N}A∈RN×N表示状态转移矩阵,它控制隐藏状态随时间如何演化,而B∈RN×1\mathbf{B}\ \in\ \mathbb{R}^{N\times 1}B ∈ RN×1表示关于隐藏状态的输入空间的权重矩阵。此外,C∈RN×1\mathbf{C}\in\mathbb{R}^{N\times 1}C∈RN×1是观测矩阵,它将隐藏的中间状态映射到输出。Mamba通过采用固定的离散化规则将参数A和B分别转换为其离散对应物A‾\overline{\mathbf{A}}A和B‾\overline{\mathbf{B}}B,从而将该连续系统应用于离散时间序列数据,更好地将其集成到深度学习架构中。用于此目的的常用离散化方法是零阶保持(ZOH)。离散化版本可以定义如下:
A‾=exp(ΔA)\overline{{\mathbf{A}}}=\mathrm{exp}(\mathbf{\Delta}\mathbf{A})A=exp(ΔA)
B‾=(ΔA)−1(exp(ΔA)−I)ΔB\mathbf{\overline{{B}}}=\mathbf{(\Delta A)}^{-1}(\mathtt{exp}(\mathbf{\Delta A})-\mathbf{I})\mathbf{\Delta B}B=(ΔA)−1(exp(ΔA)−I)ΔB
在方程(4)中,Δ\DeltaΔ表示一个时间尺度参数,用于调整模型的时间分辨率,ΔA\Delta \mathbf{A}ΔA和ΔB\Delta \mathbf{B}ΔB相应地表示给定时间间隔内连续参数的离散时间对应物。这里,I\mathbf{I}I表示单位矩阵。变换后,模型通过线性递归形式计算,可以定义如下:
ht=A‾ht−1+B‾xth_{t}=\overline{{\mathbf{A}}}h_{t-1}+\overline{{\mathbf{B}}}x_{t}ht=Aht−1+Bxt
yt=Chty_{t}=\mathbf{C}h_{t}yt=Cht
整个序列变换也可以表示为卷积形式,定义如下:
K‾=(CB‾,CA‾B‾,...,CA‾L−1B‾)\mathbf{\overline{{K}}}=(\mathbf{C}\mathbf{\overline{{B}}},\mathbf{C}\mathbf{\overline{{A}}}\mathbf{\overline{{B}}},...,\mathbf{C}\mathbf{\overline{{A}}}^{L-1}\mathbf{\overline{{B}}})K=(CB,CAB,...,CAL−1B)
y=x∗K‾y=x*\overline{{\mathbf{K}}}y=x∗K
其中,K‾∈RL\overline{{\mathbf{K}}}\;\in\;{\cal R}^{L}K∈RL表示结构化的卷积核,LLL表示输入序列的长度。在本文提出的设计中,模型采用卷积形式进行并行训练,并利用线性递归公式进行高效的自回归推理。
整体架构
Mamba YOLO架构的概述如图2所示。我们的目标检测模型分为ODMamba骨干网络和颈部部分。ODMamba由Simple Stem、Downsample Block组成。在颈部,我们遵循PAFPN (Jocher, Chaurasia, and Qiu 2023) 的设计,使用ODSSBlock模块代替C2f来捕获更丰富的梯度信息流。骨干网络
首先通过一个Stem模块进行下采样,得到一个分辨率为H4×W4\scriptstyle{\frac{H}{4}\times \frac{W}{4}}4H×4W的2D特征图。随后,所有模型都由ODSSBlock后接一个VisionClue Merge模块进行进一步下采样。在颈部,我们采用PAFPN的设计,使用ODSSBlock替换C2f,其中Conv仅负责下采样。
简单Stem 现代ViT通常使用分块作为其初始模块,将图像划分为不重叠的块。这种分割过程是通过核大小为4、步长为4的卷积操作实现的。然而,最近的研究,如EfficientFormerV2 (Li等人2023) 表明,这种方法可能会限制ViT的优化能力,影响整体性能。为了在性能和效率之间取得平衡,我们提出了一个简化的stem层。我们不使用不重叠的块,而是使用两个核大小为3、步长为2的卷积。
视觉线索合并 虽然CNN和ViT结构通常使用卷积进行下采样,但我们发现这种方法会干扰SS2D (Liu等人2024) 在不同信息流阶段的选择性操作。为了解决这个问题,VMamba将2D特征图拆分并使用1×1卷积降维。我们的发现表明,为SSM保留更多的视觉线索有利于模型训练。与传统的维度减半相比,我们通过以下步骤简化了这一过程:
- 移除归一化层。
- 拆分维度图。
- 将多余的特征图附加到通道维度。
- 利用4倍压缩的点卷积进行下采样。
与使用步长为2的3×33\times33×3卷积不同,我们的方法保留了前一层SS2D选择的特征图。
ODSSBlock
如图3所示,ODSSBlock是Mamba YOLO的核心模块,在输入阶段,它通过一个ConvModule使网络能够学习更深层、更丰富的特征表示,我们假设输入特征Zl−3Z^{l-3}Zl−3的形状为RC×H×W\mathbb{R}^{C\times H\times W}RC×H×W,我们有:
Zl−2=σ(BatchNorm(ConvModule(Zl−3)))Z^{l-2}=\sigma\left(BatchNorm\left(ConvModule(Z^{l-3})\right)\right)Zl−2=σ(BatchNorm(ConvModule(Zl−3)))
其中σ\sigmaσ表示激活函数(非线性SiLU)。ODSSBlock的层归一化和残差连接设计借鉴了Transformer Blocks的风格架构,这使得模型在深度堆叠时能够高效流动和训练。
Zl−1=SS2D(LayerNorm(Zl−2))+Zl−2Zl=RGBlock(LayerNorm(Zl−1))+Zl−1\begin{array}{c}{{Z^{l-1}=SS2D\left(LayerNorm(Z^{l-2})\right)+Z^{l-2}}}\\ {{{}}}\\ {{Z^{l}=RGBlock\left(LayerNorm(Z^{l-1})\right)+Z^{l-1}}}\end{array}Zl−1=SS2D(LayerNorm(Zl−2))+Zl−2Zl=RGBlock(LayerNorm(Zl−1))+Zl−1
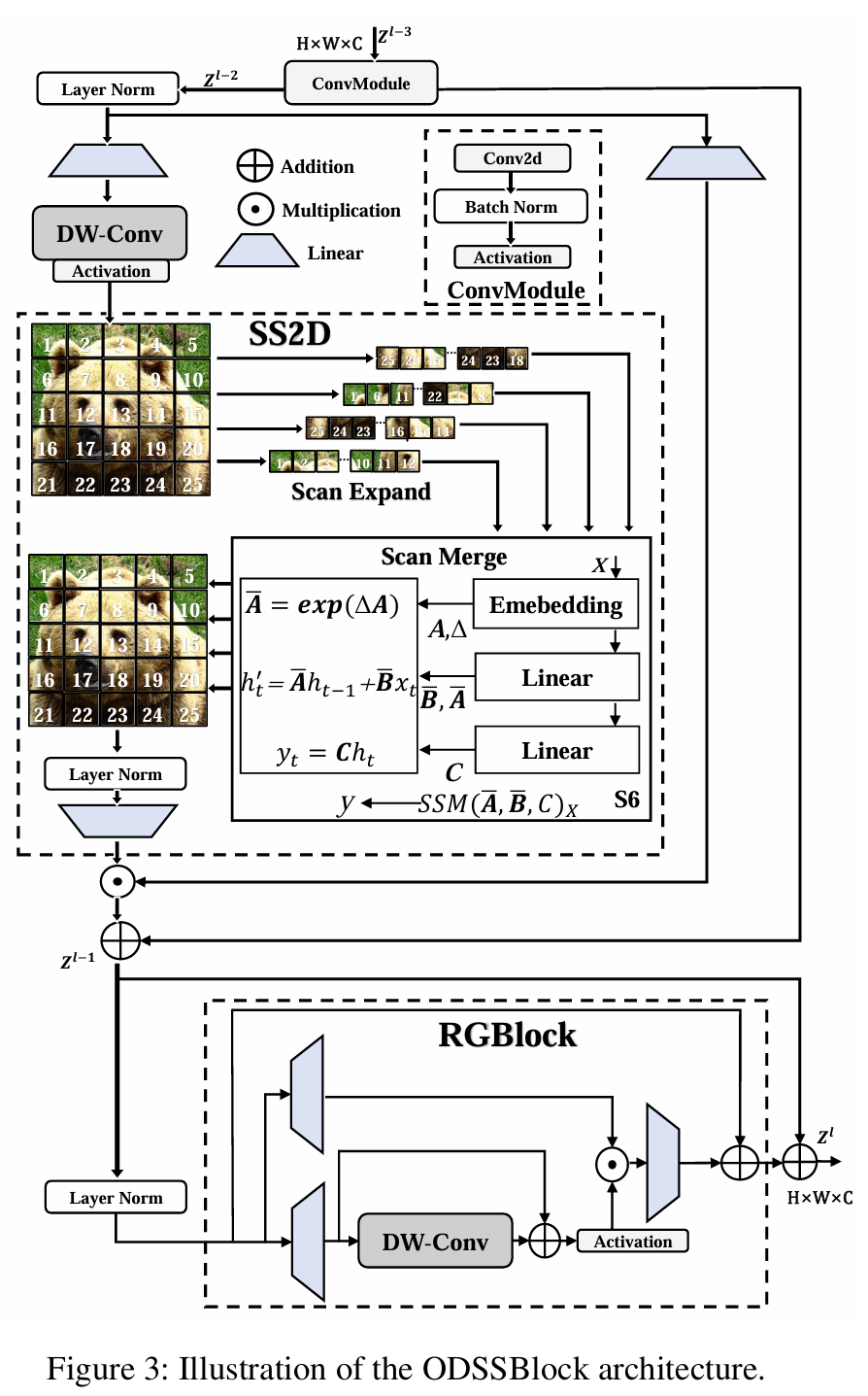
ODSSBlock可以解耦为两个独立的功能组件SS2D(⋅)SS2D(\cdot)SS2D(⋅)和RGBlock(⋅)RGBlock(\cdot)RGBlock(⋅),分别用于全局空间信息传播和通道信息传播,其中Zl−1Z^{l-1}Zl−1表示SS2D之后的中间状态。
SS2D 扫描扩展、S6块和扫描合并是SS2D算法的三个主要步骤,其主要流程如图3所示。扫描扩展操作将输入图像扩展为一系列子图像,每个子图像表示一个特定的方向,当从对角线视角观察时,扫描扩展操作沿着四个对称方向进行,分别是自上而下、自下而上、从左到右和从右到左。这样的布局不仅全面覆盖了输入图像的所有区域,而且通过系统性的方向变换为后续特征提取提供了丰富的多维信息基础,从而提高了图像特征多维捕获的效率和全面性。SS2D中的扫描合并操作将获得的序列作为S6块 (Gu and Dao 2023)的输入,并合并来自不同方向的序列,以便将特征提取为全局特征。
RG Block 原始的MLP仍然是最广泛采用的,VMamba架构中的MLP也遵循Transformer的设计,对输入序列执行非线性变换以增强模型的表达能力。最近的研究,门控MLP (Dauphin等人2017; Rajagopal和Nirmala 2021) 在自然语言处理中表现出强大的性能,我们发现门控机制在视觉领域也具有同样的潜力。在图3中,本文提出残差门控块的简单设计旨在以较低的计算成本提高模型的性能,RG Block从输入fA′f_{A}^{\prime}fA′和fB′f_{B}^{\prime}fB′创建两个分支,分别保留全局和局部信息,T(⋅)\mathcal{T}(\cdot)T(⋅)表示线性层。
Rlocall−1=Tlocall−1(fA′)\mathcal{R}_{\mathrm{local}}^{l-1}=\mathcal{T}_{\mathrm{local}}^{l-1}(f_{A}^{\prime})Rlocall−1=Tlocall−1(fA′)
Rgloball−1=Tgloball−1(fB′)\mathcal{R}_{\mathrm{global}}^{l-1}=\mathcal{T}_{\mathrm{global}}^{l-1}(f_{B}^{\prime})Rgloball−1=Tgloball−1(fB′)
深度可分离卷积在Rgloball−1\mathcal{R}_{\mathrm{global}}^{l-1}Rgloball−1分支上用作位置编码模块,通过残差连接在训练期间更有效地回流梯度,具有较低的计算成本,并通过保留和利用图像的空间结构信息显著提高了性能。RG Block采用非线性GeLU作为激活函数来控制每一层的信息流。Y(x)\mathcal{Y}(x)Y(x)过程可以写为:
Y(x)=Φ(DWConv(x)⊕x)\mathcal{Y}(x)=\Phi(DWConv(x)\oplus x)Y(x)=Φ(DWConv(x)⊕x)
通过Y(x)\mathcal{Y}(x)Y(x)的局部信息与Rgloball−1\mathcal{R}_{global}^{l-1}Rgloball−1的全局信息相乘,全局特征通过线性层进行细化以融合局部通道的信息,并且允许残差连接与fA′f_{A}^{\prime}fA′的原始输入和隐藏层特征相加。RG Block在仅略微增加计算成本的情况下捕获了更多的全局和局部特征,得到的输出特征fRGf_{RG}fRG定义如下:
Rfusionl=Rgloball−1⊙Y(Rlocall−1)fRG=Tfusionl(Rfusionl)⊕fA′\begin{array}{r}{\mathcal{R}_{\mathrm{fusion}}^{l}=\mathcal{R}_{\mathrm{global}}^{l-1}\odot\mathcal{Y}(\mathcal{R}_{\mathrm{local}}^{l-1})}\\ {f_{RG}=\mathcal{T}_{\mathrm{fusion}}^{l}(\mathcal{R}_{\mathrm{fusion}}^{l})\oplus f_{A}^{\prime}}\end{array}Rfusionl=Rgloball−1⊙Y(Rlocall−1)fRG=Tfusionl(Rfusionl)⊕fA′
其中Φ\PhiΦ表示激活函数(非线性GELU)。在本文中,RG Block中的门控机制通过集成卷积操作保留了空间信息,同时使模型对图像中的细粒度特征更加敏感。与传统的MLP相比,RG Block将全局依赖性和全局特征传递给每个像素以捕获相邻特征的依赖性,这使得上下文信息丰富,进一步增强了模型的表达能力。
实验
在本节中,我们对Mamba YOLO在目标检测任务上进行了全面的实验。我们采用MSCOCO数据集来验证所提出的Mamba YOLO的优越性。我们所有的模型都在8个NVIDIA H800 GPU上进行训练。
与最先进技术的比较 表1展示了MSCOCO val的结果,证明我们提出的方法在FLOPs、参数数量和精度之间实现了最佳的整体平衡,同时测量了GPU延迟。具体来说,与高性能的微型轻量模型(如PPYOLOE-S (Long等人2020) /YOLO-MS-XS (Chen等人2023))相比,Mamba YOLO-T的AP显著提高了1.1%/1.5%,同时GPU推理延迟减少了0.9ms/0.2ms。与精度相似的基线模型YOLOv8-S相比,Mamba YOLO-T将参数数量减少了48%,FLOPs减少了53%,同时将GPU推理延迟降低了0.4ms。
Mamba YOLO-B与参数数量和FLOPs相似的Gold-YOLO-M相比,实现了3.7%的AP增益。即使与精度相当的PPYOLOE-M相比,Mamba YOLO-B将参数数量减少了18%,FLOPs减少了9%,同时将GPU推理延迟降低了1.8ms。对于更大的模型,Mamba YOLO-L在所有先进的目标检测器中也取得了更好或相当的性能。与表现最佳的Gold-YOLO-L (Wang等人2024) 相比,Mamba YOLO-L将AP提高了0.3%,同时参数数量减少了0.9%。从该表可以看出,使用从头开始训练方法的Mamba YOLO-T比所有其他训练方法表现更好。
此外,图4比较了Mamba YOLO-L与DINO-R50在每秒帧数(FPS)和GPU内存使用方面的表现,显示Mamba YOLO-L在增加分辨率时保持了更好的精度和速度,内存效率和FLOPs呈线性增长。这些比较结果表明,在不同尺度的Mamba YOLO上,我们提出的模型相对于现有最先进方法具有显著优势。
| ODSSBlock | RGBlock | Clue Merge | $\mathrm{AP}^{val}(\%)$ | $\mathrm{AP}_{50}^{val}(\%)$ |
| ✗ | ✗ | ✗ | 37.3 | 52.6 |
| ✓ | ✗ | ✗ | 43.1 | 59.2 |
| ✗ | ✓ | ✗ | 37.9 | 53.9 |
| ✗ | ✗ | ✓ | 35.6 | 50.9 |
| ✓ | ✓ | ✗ | 43.4 | 59.5 |
| ✓ | ✗ | ✓ | 44.1 | 60.1 |
| ✓ | ✓ | ✓ | 44.5 | 61.2 |
Mamba YOLO消融研究 在本节中,我们独立检查ODSSBlock中的每个模块,在没有Clue Merge的情况下,我们使用传统的卷积下采样来评估Vision Clue Merge对精度的影响。我们在MSCOCO数据集上对Mamba YOLO进行消融实验,测试模型为Mamba YOLO-T。我们的结果表2显示,线索合并为SSM保留了更多的视觉线索,也为ODSSBlock结构确实是最优的断言提供了证据。
RG Block结构消融研究 RG Block通过将全局依赖性和全局特征逐像素传递来捕获逐像素的局部依赖性。RG Block使用多分支结构对通道维度进行建模,解决了SSM在序列建模中感受野不足和图像定位弱的局限性。关于RG Block的设计细节,我们还考虑了三种变体:
- 卷积MLP,在原始MLP基础上添加DW-Conv。
- 残差卷积MLP,在卷积MLP基础上添加残差连接。
- 门控MLP,在门控机制下设计的MLP变体。
图6展示了这些变体,表3显示了原始MLP、RG Block以及每种变体在MSCOCO数据集上的性能,以验证我们对MLP分析的有效性,测试模型为Mamba YOLO-T。我们观察到,单独引入卷积并不能有效提高性能,而在变体图6门控MLP中,其输出由两个线性投影的元素乘法组成,其中一个由残差连接的DWConv和门控激活函数组成,这实际上赋予了模型通过层次结构传播重要特征的能力,并有效提高了模型的准确性和鲁棒性。该实验表明,在处理复杂图像任务时,引入卷积的性能提升与门控聚合机制密切相关,前提是它们在残差连接的背景下应用。
| 变体 | 模型 | $\mathrm{AP}^{val}(\%)$ | $\mathrm{AP}_{50}^{val}(\%)$ | FLOPs |
| (a) | 原始MLP | 43.0 | 59.6 | 13.2G |
| (b) | 卷积MLP | 43.2 | 60.1 | 13.3G |
| (c) | 残差卷积MLP | 43.3 | 60.5 | 13.3G |
| (d) | 门控MLP | 44.0 | 60.8 | 13.2G |
| (e) | RGBlock(我们的) | 44.5 | 61.2 | 13.2G |
Mamba YOLO变体数值设置类型消融研究 我们探索了骨干网络中ODSSBlock重复次数的四种不同配置:[9, 3, 3, 3]施加了额外的计算开销,但并未带来相应程度的精度提升。[3, 9, 3, 3], [3, 3, 9, 3] 和 [3, 3, 3, 9] 实际上是由于过度重复ODSSBlock造成的冗余。实验证明[3, 6, 6, 3]在Mamba YOLO中是更合理的配置。在颈部部分,虽然移除ODSSBlock可以实现更轻量化的模型,但这不可避免地会降低模型的精度,而颈部部分的ODSSBlock可以提供丰富的梯度流和特征融合。选择输出特征图为{P2,P3,P4,P5}



变体显著提高了精度,但不可避免地显著增加了GFLOPs。Mamba YOLO最终选择了Blocks=[3,6,6,3]Blocks=[3,6,6,3]Blocks=[3,6,6,3],FeatureMap={P3,P4,P5}FeatureMap=\{P3,P4,P5\}FeatureMap={P3,P4,P5}并在颈部部分使用ODSSBlock。这种配置在精度和复杂度之间取得了更好的平衡,更适合高效地执行实例分割任务。结果如表4所示。
可视化 为了进一步确认我们提出的检测框架的优势,我们从MSCOCO中随机选择了两个样本,图5显示了每个主流检测器与Mamba YOLO的可视化结果,可以看出Mamba YOLO能够在各种困难条件下实现准确检测,并在检测高度重叠、严重遮挡和复杂背景下的物体方面表现出强大的能力,同时也显示出在检测高度重叠和严重
| Blocks | w/ SSM Neck | FeatureMap | $\mathrm{AP}^{val}(\%)$ | $\mathrm{AP}_{50}^{val}(\%)$ | FLOPs |
| [9, 3, 3, 3] | ✓ | {P3,P4,P5} | 44.0 | 61.5 | 13.3G |
| [3, 9, 3, 3] | ✓ | {P3,P4,P5} | 43.4 | 60.9 | 13.2G |
| [3, 3, 9, 3] | ✓ | {P3,P4,P5} | 43.6 | 61.0 | 13.2G |
| [3, 3, 3, 9] | ✓ | {P3,P4,P5} | 43.8 | 61.0 | 13.1G |
| [3, 6, 6, 3] | ✗ | {P3,P4,P5} | 42.2 | 60.3 | 11.4G |
| [3, 6, 6, 3] | ✓ | {P2,P3,P4,P5} | 45.8 | 62.3 | 19.7G |
| [3, 6, 6, 3] | ✓ | {P3,P4,P5} | 44.5 | 61.2 | 13.2G |
遮挡物体方面也表现出强大的能力。
结论
在本文中,我们提出了一种基于SSM设计并由YOLO扩展的检测器,其训练过程非常简单,因为它不需要在广泛的数据集上进行预训练。我们重新分析了传统MLP的局限性,并提出了RG Block,其门控机制和深度卷积残差连接旨在赋予模型在层次结构中传播重要特征的能力。我们的目标是为YOLO建立一个新的基线,证明Mamba YOLO具有高度竞争力。我们的工作是Mamba架构在实时目标检测任务中的首次探索,我们也希望为该领域的研究人员带来新的思路。
致谢
本工作得到了国家自然科学基金(62376252);浙江省自然科学基金重点项目(LZ22F030003);浙江省领雁计划(2024C02G1123882)的资助。
参考文献
Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; and Zagoruyko, S. 2020. 基于Transformer的端到端目标检测。arXiv:2005.12872。
Chen, Y.; Yuan, X.; Wu, R.; Wang, J.; Hou, Q.; and Cheng, M.-M. 2023. YOLO-MS:重新思考实时目标检测的多尺度表示学习。arXiv:2308.05480。
Chen, Z.; Zhong, F.; Luo, Q.; Zhang, X.; and Zheng, Y. 2022. Edgevit:边缘计算的高效视觉建模。见《无线算法、系统与应用国际会议》,393-405。Springer。
Dauphin, Y. N.; Fan, A.; Auli, M.; and Grangier, D. 2017. 使用门控卷积网络的语言建模。arXiv:1612.08083。
Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; and Fei-Fei, L. 2009. Imagenet:一个大规模分层图像数据库。见《2009年IEEE计算机视觉与模式识别会议》,248-255。Ieee。
Gu, A.; and Dao, T. 2023. Mamba:具有选择性状态空间的线性时间序列建模。arXiv:2312.00752。
Gu, A.; Goel, K.; and Ré, C. 2022. 使用结构化状态空间高效建模长序列。arXiv:2111.00396。
Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.; and Ré, C. 2021. 将循环、卷积和连续时间模型与线性状态空间层相结合。arXiv:2110.13985。
Huang, G.; Liu, Z.; van der Maaten, L.; and Weinberger, K. Q. 2017. 密集连接卷积网络。见《IEEE计算机视觉与模式识别会议论文集》。
Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; and Xu, C. 2024. LocalMamba:具有窗口选择性扫描的视觉状态空间模型。arXiv:2403.09338。
Jocher, G.; Chaurasia, A.; and Qiu, J. 2023. Ultralytics YOLO。
Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; 等。 2022. YOLOv6:面向工业应用的单阶段目标检测框架。arXiv预印本 arXiv:2209.02976。
Li, Y.; Hu, J.; Wen, Y.; Evangelidis, G.; Salahi, K.; Wang, Y.; Tulyakov, S.; and Ren, J. 2023. 为MobileNet尺寸和速度重新思考视觉Transformer。见《IEEE国际计算机视觉会议论文集》。
Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; and Belongie, S. 2017. 用于目标检测的特征金字塔网络。见《IEEE计算机视觉与模式识别会议论文集》,2117-2125。
Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C. L.; and Dollar, P. 2015. Microsoft COCO:上下文中的常见物体。arXiv:1405.0312。
Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; and Berg, A. C. 2016. SSD:单次多框检测器,21-37。Springer International Publishing。ISBN 9783319464480。
Liu, Y.; Tian, Y.; Zhao, Y.; Yu, H.; Xie, L.; Wang, Y.; Ye, Q.; and Liu, Y. 2024. VMamba:视觉状态空间模型。arXiv预印本 arXiv:2401.10166。
Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; and Guo, B. 2021. Swin Transformer:使用移位窗口的分层视觉Transformer。见《IEEE/CVF国际计算机视觉会议(ICCV)论文集》。
Liu, Z.; Mao, H.; Wu, C.-Y.; Feichtenhofer, C.; Darrell, T.; and Xie, S. 2022. 2020年代的ConvNet。
Long, X.; Deng, K.; Wang, G.; Zhang, Y.; Dang, Q.; Gao, Y.; Shen, H.; Ren, J.; Han, S.; Ding, E.; 等。 2020. PP-YOLO:目标检测器的有效且高效实现。arXiv预印本 arXiv:2007.12099。
Mehta, S.; and Rastegari, M. 2021. Mobilevit:轻量、通用且移动友好的视觉transformer。arXiv预印本 arXiv:2110.02178。
Rajagopal, A.; and Nirmala, V. 2021. 卷积门控MLP:结合卷积和gMLP。arXiv:2111.03940。
Ren, S.; He, K.; Girshick, R.; and Sun, J. 2016. Faster R-CNN:通过区域提议网络实现实时目标检测。arXiv:1506.01497。
Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; and Sun, J. 2019. Objects365:一个大规模、高质量的目标检测数据集。见《IEEE/CVF国际计算机视觉会议论文集》,8430-8439。
Shi, D. 2023. TransNeXt:视觉Transformer的鲁棒中心凹视觉感知。arXiv:arXiv:2311.17132。
Smith, J. T. H.; Warrington, A.; and Linderman, S. W. 2023. 用于序列建模的简化状态空间层。arXiv:2208.04933。
Tan, M.; and Le, Q. V. 2020. EfficientNet:重新思考卷积神经网络的模型缩放。
Wang, A.; Chen, H.; Lin, Z.; Pu, H.; and Ding, G. 2023. Repvit:从vit角度重新审视移动cnn。arXiv预印本 arXiv:2307.09283。
Wang, C.; He, W.; Nie, Y.; Guo, J.; Liu, C.; Wang, Y.; and Han, K. 2024. Gold-YOLO:通过聚集-分发机制实现高效目标检测器。《神经信息处理系统进展》,36。
Wang, C.-Y.; Bochkovskiy, A.; and Liao, H.-Y. M. 2023. YOLOv7:可训练的免费赠品套件为实时目标检测器设定了最新水平。见《IEEE/CVF计算机视觉与模式识别会议论文集》,7464-7475。
Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; and Shum, H.-Y. 2022. DINO:具有改进去噪锚框的端到端目标检测DETR。arXiv:2203.03605。
Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; and Wang, C. 2023. 重新思考高效基于注意力的模型的移动块。见《2023年IEEE/CVF国际计算机视觉会议(ICCV)》,1389-1400。IEEE计算机学会。
Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; and Chen, J. 2023. 在实时目标检测上DETRs击败YOLOs。arXiv:2304.08069。
Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; and Wang, X. 2024. Vision Mamba:基于双向状态空间模型的高效视觉表示学习。arXiv预印本 arXiv:2401.09417。
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; and Dai, J. 2020. Deformable DETR:用于端到端目标检测的可变形Transformer。arXiv预印本 arXiv:2010.04159。