英伟达41页VLA框架:Alpamayo-R1凭“因果链推理”重塑端到端自动驾驶
一、导读
当前的端到端自动驾驶模型在处理常见路况时表现不错,但在面对那些罕见但至关重要的长尾场景时,其决策往往显得脆弱且不可靠。这主要是因为模型缺乏对驾驶决策背后深层次的因果关系理解,仅仅是通过模仿来学习,导致在未知或复杂的安全关键时刻表现不佳。
为了解决这一难题,本论文提出了Alpamayo-R1,一个集成了因果链推理与轨迹规划的视觉-语言-动作模型。该模型首先像人类驾驶员一样,通过语言“思考”和“推理”当前场景中的因果关系(例如“因为前方有行人,所以我需要减速”),然后再根据这个推理结果规划出具体的行车轨迹。这种方法显著提升了模型在复杂场景下的决策准确性和安全性,向着更可靠的L4级别自动驾驶迈出了实用的一步。
二、论文基本信息

论文标题: Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
作者姓名与单位: Yulong Cao, Tong Che, Yuxiao Chen, Wenhao Ding, Boris Ivanovic, Peter Karkus, Boyi Li 等(核心贡献者),来自 NVIDIA。
发表日期与会议/期刊来源: 2025年10月30日,发表于arXiv。
论文链接: https://arxiv.org/abs/2511.00088
三、主要贡献与创新
- 提出了一个结构化的 因果链 (Chain of Causation, CoC) 标注框架,通过人机混合流程,生成了与驾驶行为对齐的、具有因果关联的推理数据。
- 采用了一个 基于扩散的动作专家轨迹解码器,能高效生成符合车辆动力学、且与语言推理对齐的连续多模态轨迹规划。
- 设计了一种 多阶段训练策略,通过监督微调引出推理能力,并利用强化学习(RL)来提升推理质量和推理与动作之间的一致性。
四、研究方法与原理
该模型的核心思路是将自动驾驶任务分解为“先推理,后行动”。它利用一个强大的视觉语言模型(VLM)来理解场景并生成结构化的因果推理文本,然后基于这个推理结果,指导一个专门的解码器生成具体、可执行的驾驶轨迹。
【模型结构图】
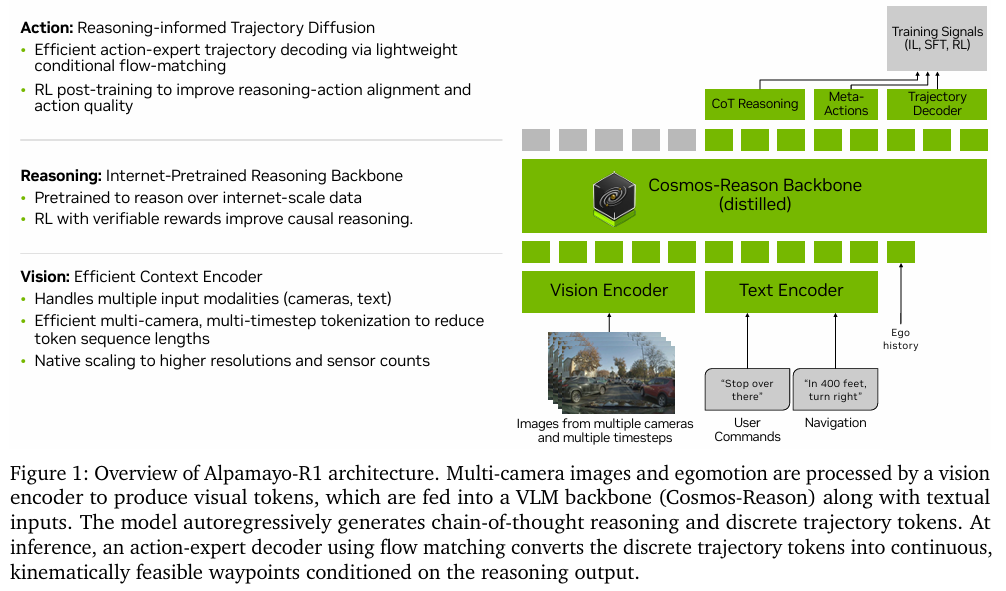
模型整体架构
Alpamayo-R1的整体流程如上图所示。它接收多摄像头图像和车辆历史运动状态作为输入,可选地加入用户指令或导航信息。所有输入被转换成统一的 多模态token序列,送入VLM骨干网络 Cosmos-Reason。该网络会自回归地生成 因果链(CoC)推理文本 和 离散的轨迹token。在推理时,一个基于流匹配的 动作专家解码器 会将这些离散token转换为连续且运动学可行的轨迹点。整体任务被建模为一个序列预测问题,其序列构造为:
[Oimage,Oegomotion,Reason,τ]
[O_{\text{image}}, O_{\text{egomotion}}, \text{Reason}, \tau ]
[Oimage,Oegomotion,Reason,τ]
其中 OOO 代表观测数据,Reason\text{Reason}Reason 是生成的推理文本,τ\tauτ 是预测的未来轨迹。
VLM骨干网络:Cosmos-Reason
模型采用 Cosmos-Reason 作为其推理核心。这是一个专为物理世界AI应用设计的VLM,经过了大量视觉问答(VQA)样本的训练,具备了物理常识和具身推理能力。为了更好地适应自动驾驶,研究者们还用覆盖了多种物理AI领域(包括自动驾驶、机器人、医疗等)的补充数据集对其进行了 领域特定的监督微调 (SFT)。
领域特定的适应性设计
-
视觉编码 (Vision Encoding):为了处理自动驾驶中多摄像头、多时间步的输入,并满足实时性要求,AR1支持多种视觉编码方案。传统的 单图像编码 将每张图像独立编码为token,token数量会随摄像头数量线性增长,成本高昂。为了解决这个问题,AR1引入了更高效的编码器:
- 多摄像头编码器:利用 三平面(triplanes) 这种3D归纳偏置,将多个摄像头的图像编码到一个固定的中间表示中,再进行token化。这样,产生的token数量与摄像头数量和分辨率解耦。对于一个三平面,其产生的token总数为:
(Sx−pxpx+1)(Sy−pypy+1)+(Sx−pxpx+1)(Sz−pzpz+1)+(Sy−pypy+1)(Sz−pzpz+1) \left( \frac{S_x - p_x}{p_x} + 1 \right) \left( \frac{S_y - p_y}{p_y} + 1 \right) + \left( \frac{S_x - p_x}{p_x} + 1 \right) \left( \frac{S_z - p_z}{p_z} + 1 \right) + \left( \frac{S_y - p_y}{p_y} + 1 \right) \left( \frac{S_z - p_z}{p_z} + 1 \right) (pxSx−px+1)(pySy−py+1)+(pxSx−px+1)(pzSz−pz+1)+(pySy−py+1)(pzSz−pz+1)
其中 Sx,Sy,SzS_x, S_y, S_zSx,Sy,Sz 是三平面的网格尺寸,px,py,pzp_x, p_y, p_zpx,py,pz 是patch的尺寸。这能将token数量减少近4倍。 - 多摄像头视频编码器:例如Flex,可以直接压缩来自多个摄像头和多个时间步的视频序列,实现高达20倍的token压缩率。
- 多摄像头编码器:利用 三平面(triplanes) 这种3D归纳偏置,将多个摄像头的图像编码到一个固定的中间表示中,再进行token化。这样,产生的token数量与摄像头数量和分辨率解耦。对于一个三平面,其产生的token总数为:
-
轨迹解码 (Trajectory Decoding):为了生成精确且实时的轨迹,AR1没有直接预测 (x,y)(x, y)(x,y) 坐标点,而是采用了一种基于 单车模型动力学 的控制表示,预测未来的加速度 aia_iai 和曲率 κi\kappa_iκi 序列。通过欧拉离散化,可以从控制量计算出轨迹点:
xi+1=(xi+1yi+1θi+1vi+1)=(xi+ΔT2(vicosθi+vi+1cosθi+1)yi+ΔT2(visinθi+vi+1sinθi+1)θi+ΔTκivi+ΔT22κiaivi+ΔTai)\mathbf{x}_{i+1} =\begin{pmatrix}x_{i+1} \\y_{i+1} \\\theta_{i+1} \\v_{i+1} \\\end{pmatrix}=\begin{pmatrix}x_i + \frac{\Delta T}{2} (v_i \cos\theta_i + v_{i+1} \cos\theta_{i+1}) \\y_i + \frac{\Delta T}{2} (v_i \sin\theta_i + v_{i+1} \sin\theta_{i+1}) \\\theta_i + \Delta T \kappa_i v_i + \frac{\Delta T^2}{2} \kappa_i a_i \\v_i + \Delta T a_i\end{pmatrix}xi+1=xi+1yi+1θi+1vi+1=xi+2ΔT(vicosθi+vi+1cosθi+1)yi+2ΔT(visinθi+vi+1sinθi+1)θi+ΔTκivi+2ΔT2κiaivi+ΔTai
其中 ΔT=0.1s\Delta T=0.1sΔT=0.1s。这种表示更适合底层车辆控制器执行。
同时,AR1采用 双重表示策略:在训练阶段,轨迹被量化为 离散token,与推理文本一起在VLM中统一学习;在推理阶段,一个独立的 动作专家(action-expert) 使用 流匹配(flow matching) 框架来高效地解码这些token,生成连续、平滑的轨迹。流匹配通过学习从一个噪声分布到一个目标数据分布的向量场来实现生成,其训练损失为:
Lcfm(Θ)=Et∈pschedule,(O,Reason)∈Ddata∥vΘ(at,O,Reason)−u(at∣a)∥\mathcal{L}_{\text{cfm}}(\Theta) = \mathbb{E}_{t \in p_{\text{schedule}}, (O, \text{Reason}) \in \mathcal{D}_{\text{data}}} \| \mathbf{v}_\Theta(\mathbf{a}_t, O, \text{Reason}) - \mathbf{u}(\mathbf{a}_t | \mathbf{a}) \|Lcfm(Θ)=Et∈pschedule,(O,Reason)∈Ddata∥vΘ(at,O,Reason)−u(at∣a)∥
推理时,通过欧拉积分进行降噪,从一个随机噪声 a0\mathbf{a}_0a0 生成最终的控制序列:
at+δt=at+δtvΘ(at,O,Reason)\mathbf{a}_{t+\delta_t} = \mathbf{a}_t + \delta_t \mathbf{v}_\Theta(\mathbf{a}_t, O, \text{Reason})at+δt=at+δtvΘ(at,O,Reason)
这种设计既利用了VLM强大的联合学习能力,又保证了推理的实时性和轨迹的物理可行性。
因果链(CoC)数据集
为了教会模型进行有效的因果推理,论文构建了 CoC 数据集。与以往自由形式的描述不同,CoC强制推理过程具有明确的结构,解决了现有数据集中 行为描述模糊、推理肤浅和因果混淆 的问题。
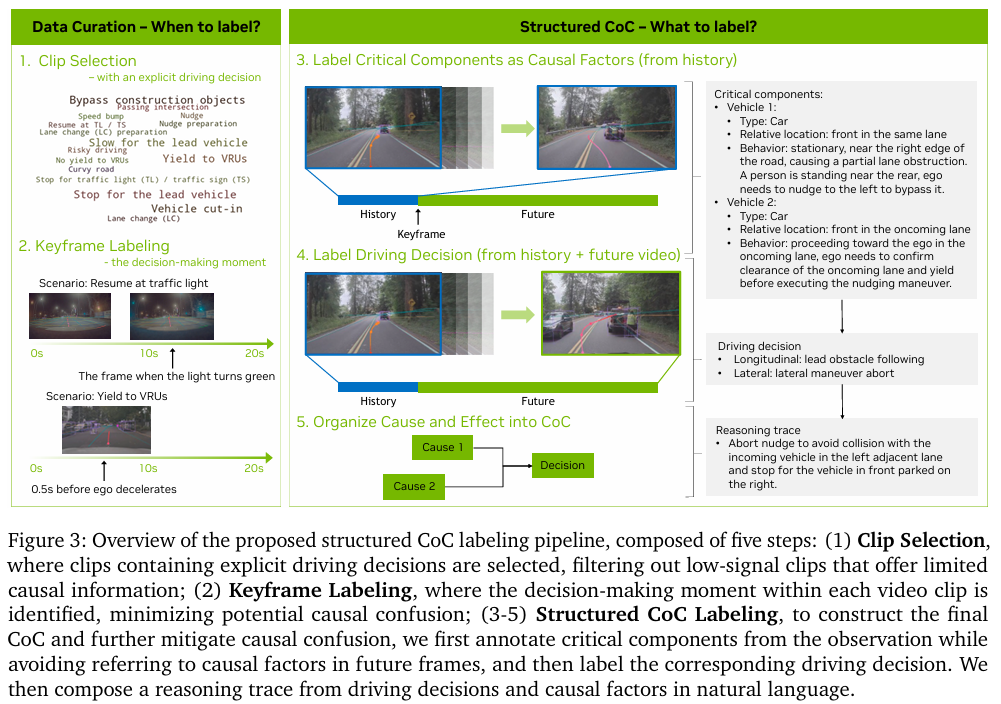
其标注流程如上图所示,包含三个核心结构化组件:
- 驾驶决策 (Driving Decision):从一个封闭的决策集合(如 “跟车”、“变道”、“避让” 等)中选择一个,确保推理有明确的目标。
- 因果因素 (Critical Components):标注场景中直接导致该决策的关键元素(如 “前方车辆”、“行人”、“红绿灯” 等),确保了因果的局部性。
- 组合的CoC推理迹 (Composed CoC Traces):将决策和原因组合成一句通顺的自然语言,形成最终的标注。
多阶段训练策略
AR1的训练分为三个阶段:
- 动作模态注入 (Action Modality Injection):在VLM中加入轨迹预测能力。通过在CoC数据集上进行监督学习,模型学会同时预测推理文本和离散化的轨迹token。
- 引出推理能力 (Eliciting Reasoning):通过在CoC数据集上进行 监督微调 (SFT),模型模仿专家的“思考过程”,学习生成有因果逻辑的推理文本。SFT的损失函数为:
LSFT(θ)=−E(O,Reason,a)∼DCoC[logπθ(Reason,a∣O)] \mathcal{L}_{\text{SFT}}(\theta) = -\mathbb{E}_{(O, \text{Reason}, \mathbf{a}) \sim \mathcal{D}_{\text{CoC}}} [\log \pi_\theta(\text{Reason}, \mathbf{a} | O)] LSFT(θ)=−E(O,Reason,a)∼DCoC[logπθ(Reason,a∣O)] - 基于强化学习的后训练 (RL-based Post-Training):SFT学习到的推理可能存在不一致或幻觉。因此,论文使用 强化学习 进一步优化模型。通过设计三个奖励信号,对模型进行微调:
- 推理质量奖励 rreasonr_{\text{reason}}rreason:利用一个更强的 大型推理模型(LRM) 作为“批判家”,为AR1生成的推理文本打分。
- 推理-动作一致性奖励 rconsistencyr_{\text{consistency}}rconsistency:检查生成的推理文本(如“加速”)是否与预测的轨迹(实际在减速)相符,不符则惩罚。
- 轨迹质量奖励 rtrajr_{\text{traj}}rtraj:评估轨迹的安全性(是否碰撞)、平顺性(jerk值)和专家相似度(L2距离)。
这三个奖励共同引导模型生成既合理又可靠的驾驶策略。
五、实验设计与结果分析
- 数据集与评测:实验在NVIDIA内部大规模驾驶数据集上进行,包含8万小时的驾驶数据。评测分为 开环(Open-loop) 和 闭环(Closed-loop)。开环评测使用 minADE(最小平均位移误差)指标,衡量预测轨迹与真值的接近程度。闭环评测在 AlpaSim 模拟器中进行,评估 越野率、近距离接触率 和 AlpaSim分数(两次危险事件之间行驶的平均距离)。
Policy Improvements from Reasoning (推理带来的策略提升)
实验证明,加入CoC推理能力后,模型性能显著提升。
- 开环评测:如下表所示,无论是否带有导航信息,以及模型参数大小如何,加入了CoC推理的AR1模型(表中
+ Ft. w/ CoC & Traj.)在minADE@6s指标上均优于仅预测轨迹的基线模型。在最具挑战性的场景中,AR1带来了高达 12% 的性能提升。
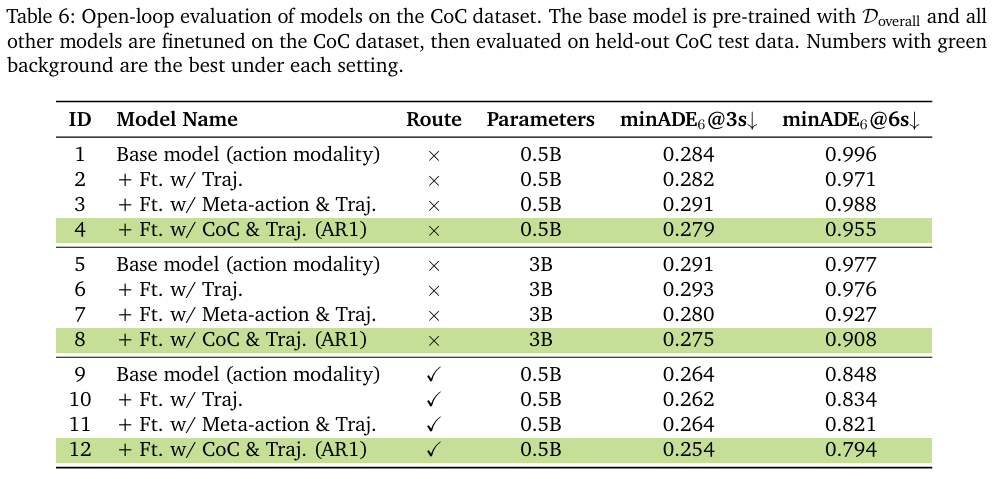
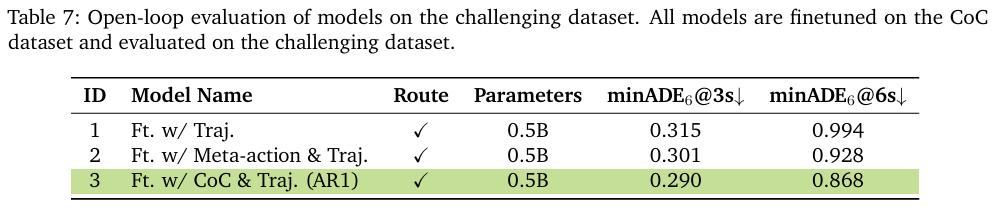
- 闭环评测:在AlpaSim模拟器中,AR1相比基线模型,越野率降低了35%,近距离接触率降低了25%,AlpaSim分数也更高,证明了推理能力在实际闭环控制中的有效性。
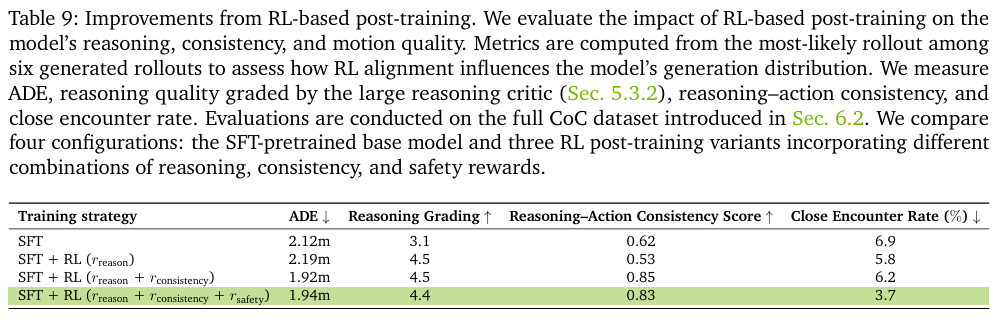
Improvements of Reasoning, Consistency, and Safety via RL Post-Training (通过RL后训练提升推理、一致性和安全性)
RL后训练进一步提升了模型表现。如下表所示,相比仅使用SFT的模型,加入了 推理(rreasonr_{\text{reason}}rreason)、一致性(rconsistencyr_{\text{consistency}}rconsistency)和安全(rsafetyr_{\text{safety}}rsafety) 奖励的RL训练后,模型在 推理评分、推理-动作一致性得分 上大幅提升,同时降低了轨迹误差和近距离接触率。这证明RL能有效修正SFT模型的缺陷,使推理更可靠、行动更安全。
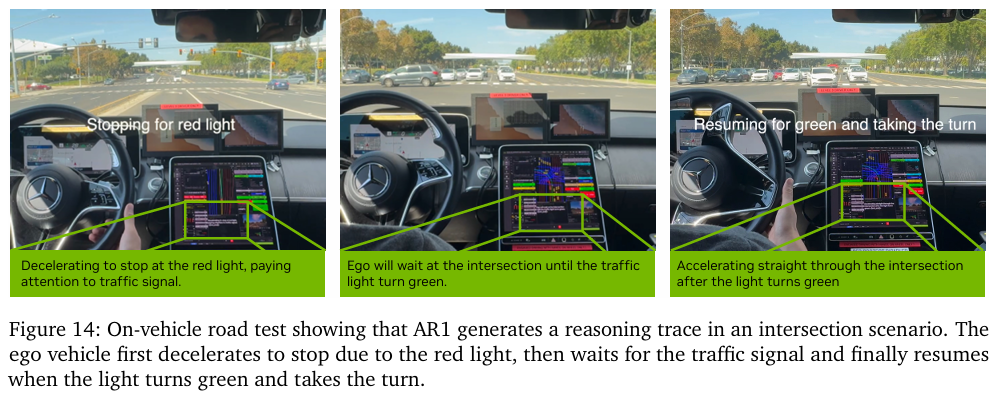
On-Vehicle Road Tests (实车路测)
模型被成功部署在真实测试车辆上,在城市环境中完成了自动驾驶任务。端到端的推理延迟为 99毫秒,满足了自动驾驶的实时性要求。下图展示了AR1在真实十字路口场景下生成的推理,准确地识别了红灯并执行了“减速-等待-启动”的连续动作。
六、论文结论与评价
本文的核心结论是,通过将 结构化的因果推理 与 动作预测 相结合,可以显著提升自动驾驶模型在复杂长尾场景中的性能和安全性。实验证明,Alpamayo-R1模型不仅能生成合理的决策解释,而且这些解释能够有效指导其生成更安全、更准确的驾驶轨迹。
这项研究为自动驾驶领域带来的启示是, 단순히模仿驾驶行为是不够的,赋予模型“思考”和“推理”的能力,是通向更高级别自动驾驶的关键路径。它展示了如何利用大型语言模型的推理能力来解决具身AI(如自动驾驶)中的实际问题,为后续研究提供了一个功能强大且可解释的框架。
该方法的 优点 非常突出:首先,它通过语言推理极大地 增强了模型的可解释性,让我们能理解AI的决策逻辑;其次,它在安全关键的长尾场景中表现出 更高的鲁棒性和安全性;最后,其 模块化的设计 允许方便地更换或升级视觉编码器、VLM骨干等部分。
但该方法也存在一些 潜在的缺点和挑战。第一,整个训练流程(特别是RL后训练) 计算成本极高,需要大量的计算资源。第二,模型的性能在很大程度上 依赖于CoC数据集的质量,而自动标注的数据难免会存在噪声和不完美之处。第三,虽然模型可以生成推理,但评估这些开放式文本的 “推理质量”本身就是一个难题,当前的评估方法仍有改进空间。
对于未来的研究,一个有价值的方向是探索 “按需推理” (reasoning on demand)。目前的模型对每个场景都生成推理,但在简单场景下 это可能是一种浪费。如果模型能学会判断何时需要深入思考,何时可以快速反应,将能大幅提升推理效率。此外,如何让模型从更少的、更高质量的人类标注数据中学习到更强的因果推理能力,也是一个值得探索的方向。