深入理解 C++ STL 中的 map 与 set:从原理到实战
在 C++ STL(标准模板库)中,容器是代码效率与可读性的重要保障。除了 vector、list 等我们熟悉的序列式容器,还有一类专门用于高效查找、排序的关联式容器——map 和 set 系列。它们底层基于红黑树实现,兼具排序特性与 O(logN) 级别的增删查效率,在算法题、工程开发中应用广泛。本文将从容器分类入手,逐步拆解 map 和 set 的用法、特性差异,并通过实战案例带你掌握其核心价值。
1. 容器分类
在学习 map 和 set 之前,我们需要先明确 STL 容器的两大分类,理解它们的本质区别:
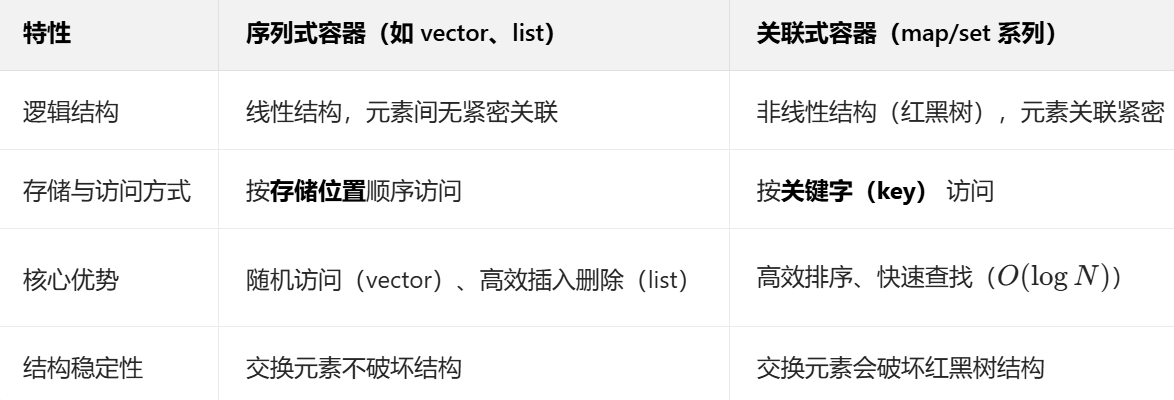
map 和 set 属于关联式容器的 “有序家族”(底层红黑树,红黑树底层为我们之前学习的平衡二叉搜索树,后面的文章我们会进行讲解),此外还有基于哈希表的 “无序家族”(unordered_map/unordered_set),本文聚焦前者。
2. set
set 的核心定位是 **“关键字集合”**—— 仅存储单个关键字(key),且自动去重、按 key 有序排列。其变体 multiset 支持关键字冗余(允许重复),二者用法高度相似,仅在 “去重” 特性上有差异。
2.1 模板定义
set 的模板声明如下,一般情况下只需关注第一个参数(关键字类型),不需要传后两个模板参数:
template <class T, // 关键字类型(key_type = value_type,因仅存key)class Compare = less<T>, // 比较仿函数(默认升序,可改为greater<T>降序)class Alloc = allocator<T> // 空间配置器(默认无需修改)
> class set;比较仿函数:默认用 less<T> 实现升序,若需降序,可显式指定 set<int, greater<int>>。
迭代器特性:set 的 iterator 和 const_iterator 均为常量迭代器,不允许修改元素 —— 因为修改关键字会破坏红黑树的有序结构。
2.2 构造与迭代器
set支持正向和反向迭代遍历,遍历默认按升序顺序,因为底层是二叉搜索树,迭代器遍历走的是中序;支持迭代器就意味着支持范围for,set的iterator和const_iterator都不支持迭代器修改数据,修改关键字数据,破坏了底层搜索树的结构。
// 1. 无参构造
set<int> s1;// 2. 迭代器区间构造(常用:快速去重排序)
vector<int> nums = { 4,2,7,2,8 };
set<int> s2(nums.begin(), nums.end()); // s2: {2,4,7,8}// 3. 拷贝构造
set<int> s3(s2);// 4. 初始化列表构造
set<int> s4 = { 1,3,5,3 }; // s4: {1,3,5}(自动去重)// 遍历:默认升序(中序遍历红黑树)
for (auto it = s4.begin(); it != s4.end(); ++it)
{cout << *it << " "; // 输出:1 3 5
}
cout << endl;
// 范围 for 遍历(更简洁)
for (auto e : s4)
{cout << e << " ";
}迭代器:
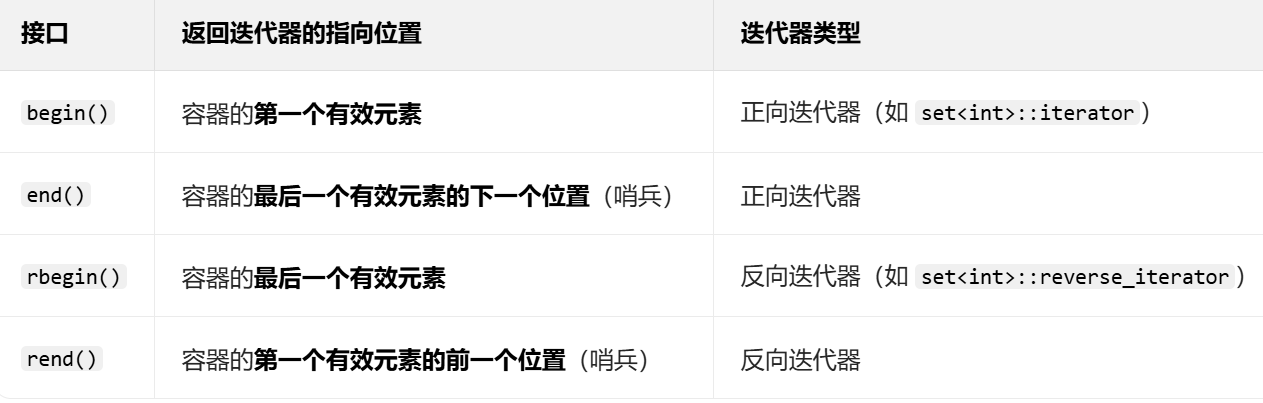
迭代器的使用与其他容器的迭代器使用非常类似,非常简单:
正向迭代器:
// 初始化 set:自动去重并升序排序
set<int> s = { 5, 2, 7, 2, 9, 1 }; // 最终存储:1, 2, 5, 7, 9// 1. 显式声明迭代器(set<int>::iterator)
set<int>::iterator it = s.begin();
while (it != s.end())
{// 仅支持读元素,写操作会编译报错(如 *it = 10; 错误)cout << *it << " ";++it; // 双向迭代器支持前置自增(高效)
}
cout << endl; // 输出:1 2 5 7 9// 2. 简化写法(auto 自动推导迭代器类型,推荐)
for (auto it_auto = s.begin(); it_auto != s.end(); ++it_auto) {cout << *it_auto << " ";
}
cout << endl; // 输出:1 2 5 7 9反向迭代器:
set<int> s = { 5, 2, 7, 2, 9, 1 }; // 正向顺序:1, 2, 5, 7, 9// 反向迭代器类型:set<int>::reverse_iteratorset<int>::reverse_iterator rit = s.rbegin();while (rit != s.rend()) {cout << *rit << " ";++rit; // 反向迭代器的 ++ 是“向前移动”(对应正向的 --)}cout << endl; // 输出:9 7 5 2 1// auto 简化反向遍历for (auto rit_auto = s.rbegin(); rit_auto != s.rend(); ++rit_auto) {cout << *rit_auto << " ";}cout << endl; // 输出:9 7 5 2 12.3 常见成员函数
set的常见成员函数如下表:

我们接下来看几个重点函数的使用场景:
insert使用样例:
int main()
{// 去重+升序排序set<int> s;// 去重+降序排序(给一个大于的仿函数) //set<int, greater<int>> s;s.insert(3);s.insert(1);s.insert(5);s.insert(7);for (auto e : s){cout << e << " ";}cout << endl;// 插入一段initializer_list列表值,已经存在的值插入失败 s.insert({ 2,8,3,9 });for (auto e : s){cout << e << " ";}cout << endl;set<string> strset = { "sort", "insert", "add" };// 遍历string比较ascll码大小顺序遍历的 for (auto& e : strset){cout << e << " ";}cout << endl;return 0;
}输出结果:

find和erase使用样例:
int main()
{set<int> s = { 4,2,7,2,8,5,9 };for (auto e : s){cout << e << " ";}cout << endl;// 删除最小值 s.erase(s.begin());for (auto e : s){cout << e << " ";}cout << endl;// 直接删除x int x;cin >> x;int num = s.erase(x);if (num == 0){cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;// 直接查找再利用迭代器删除x cin >> x;auto pos = s.find(x);if (pos != s.end()){s.erase(pos);}else{cout << x << "不存在!" << endl;}for (auto e : s){cout << e << " ";}cout << endl;return 0;
}输出结果:

2.4 set和multiset的差异
multiset 与 set 的唯一核心差异是支持关键字冗余(允许重复元素),因此在 insert、find、count、erase 接口上有细微调整:

实际场景:
int main()
{// 相比set不同的是,multiset是排序,但是不去重 multiset<int> s = { 4,2,7,2,4,8,4,5,4,9 };auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;// 相比set不同的是,x可能会存在多个,find查找中序的第一个 int x;cin >> x;auto pos = s.find(x);while (pos != s.end() && *pos == x){cout << *pos << " ";++pos;}cout << endl;// 相比set不同的是,count会返回x的实际个数 cout << s.count(x) << endl;// 相比set不同的是,erase给值时会删除所有的x s.erase(x);for (auto e : s){cout << e << " ";}cout << endl;return 0;
}输出结果:

3. map
3.1 模板定义
map 的模板声明中,key 与 value 是分离的,底层用 pair<const Key, T> 存储键值对:
template <class Key, // 关键字类型(key_type)class T, // 值类型(mapped_type,即我们常说的 value)class Compare = less<Key>, // 比较仿函数(按 key 排序)class Alloc = allocator<pair<const Key, T>> // 空间配置器
> class map;value_type:map 的 value_type 是 pair<const Key, T>(红黑树节点存储的类型),其中 key 是 const 的,不允许修改(否则破坏红黑树结构),但 value 可修改。
3.2 pair类型
pair 是 STL 中的 “二元组” 结构,用于存储两个关联数据(如键值对 key-value),是 map、multimap 容器的键值对载体。
(1)定义与模板结构:
template <class T1, class T2>
struct pair {T1 first; // 第一个元素(如 map 的 key)T2 second; // 第二个元素(如 map 的 value)// 构造函数// 默认构造(值初始化)pair() : first(T1()), second(T2()) {} // 带参构造pair(const T1& a, const T2& b) : first(a), second(b) {}
};要点:
1. first 和 second 是公开成员,可直接访问(如 p.first、p.second)。
2. 支持任意类型组合(如 pair<int, string>、pair<vector<int>, double>)。
(2)便捷构造:make_pair
为简化 pair 的构造,STL 提供 make_pair 函数(自动推导模板参数):
// 传统构造(需显式指定类型)
pair<int, string> p1(1, "apple");// make_pair 构造(自动推导类型)
auto p2 = make_pair(2, "banana"); // 等价于 pair<int, string>(2, "banana")(3)在map中的使用场景
int main()
{//隐式转换map<int, string> dict = { {1, "one"}, {2, "two"} };for (const auto& p : dict){cout << p.first << ": " << p.second << endl; // 访问 key 和 value}return 0;
}输出结果:
3.3 构造与遍历
map 的构造方式与 set 类似,遍历需通过 pair 的 first(key)和 second(value)访问键值对:
int main()
{// 1. 初始化列表构造(常用:直接初始化字典)map<string, string> dict ={{"left", "左边"},{"right", "右边"},{"insert", "插入"}};// 2. 迭代器遍历:通过 -> 访问 pair 成员for (auto it = dict.begin(); it != dict.end(); ++it){// it 是迭代器,指向 pair<const string, string>cout << it->first << ":" << it->second << endl;}// 3. 范围 for 遍历(更简洁)for (const auto& e : dict){cout << e.first << ":" << e.second << endl;}return 0;
}输出结果:

其中迭代器部分与上面介绍的set迭代器十分相似,这里不再详细介绍。
3.4 常见成员函数
map和set的成员函数基本一致,只是多个一个[]运算符重载。

map 的增删查接口与 set 逻辑一致(均按 key 操作),但插入的是 pair 键值对,且有一个核心特色 —— [] 运算符,兼具插入、查找、修改功能。
接下来我们介绍几个重要的函数:
(1)insert
map的 insert 方法插入 pair 键值对,返回 pair<iterator, bool>,bool 标记插入是否成功;若成功,iterator为指向插入元素的迭代器;若失败,iterator 指向已存在的重复 key 对应的元素,可通过 ret.first->second 获取其当前 value:
auto ret = countMap.insert({ "apple", 5 });
应用场景:
int main()
{map<string, int> countMap;// 插入方式 1:直接构造 pair// map中无相同的键值:成功,返回pair对象<插入键值的迭代器(apple), true>countMap.insert(pair<string, int>("apple", 1));// 插入方式 2:make_pair(推荐,更简洁)countMap.insert(make_pair("banana", 2));// 插入方式 3:列表初始化(C++11+,最简洁)countMap.insert({ "orange", 3 });// 插入重复 key:失败,返回pair对象<相同键值所在的迭代器(apple), false>auto ret = countMap.insert({ "apple", 5 });if (!ret.second){cout << "apple 已存在,当前计数:" << ret.first->second << endl;}return 0;
}(2)find与erase
map 的查找(find)和删除(erase)接口与 set 完全一致,均按 key 操作:
int main()
{map<string, int> m = { {"apple", 5}, {"banana", 3}, {"orange", 4} };// 1. 查找:按 key 找,返回指向 pair 的迭代器auto pos = m.find("banana");if (pos != m.end()) {cout << "找到 " << pos->first << ",计数:" << pos->second << endl;// 修改 value(允许)pos->second = 6;}// 2. 删除:按 key 删或按迭代器删m.erase("orange"); // 按 key 删除m.erase(pos); // 按迭代器删除for (auto e : m){cout << e.first << " " << e.second << endl;}return 0;
}输出结果:

(3)[] 运算符
[] 是 map 最常用的接口,底层基于 insert 实现,支持插入、查找、修改三种功能,其内部逻辑如下:
// [] 运算符的伪代码实现
// mapped_type对应value值,key_type对应key值
mapped_type& operator[](const key_type& k)
{// 1. 尝试插入 {k, 默认值}(若 k 不存在,插入成功;若存在,插入失败)// 缺省值由 mapped_type 的默认构造生成,如 int 类型为 0,string 类型为空串pair<iterator, bool> ret = insert({ k, mapped_type() });// 2. 获取指向对应key值元素的迭代器iterator it = ret.first;// 3. 返回 key 对应的 value 引用(无论插入成功与否)return it->second;
}如果[]调用的键值不存在,则[]就相当于插入该键值,value由传入类型的默认构造生成;如果[]调用的值存在,则[]就相当于得到对应的value。所以通过该函数,我们可以简化map的插入与修改操作。
int main()
{map<string, int> m;//插入m["one"] = 1;m["two"] = 2;m["three"] = 3;map<string, int>::iterator it = m.begin();while (it != m.end()){cout << "<" << it->first << "," << it->second << ">" << " ";++it;}cout << endl;// four在map中并不存在,使用[]访问后插入键值为four的pair对象// "four" 会按照字符串字典序插入到合适的位置cout << m["four"] << endl;//修改m["one"] = 11;m["two"] = 22;m["three"] = 33;it = m.begin();while (it != m.end()){cout << "<" << it->first << "," << it->second << ">" << " ";++it;}cout << endl;return 0;
}输出结果:

3.5 map和multimap的差异
multimap 与 map 的核心差异是支持 key 冗余,因此接口上有两点调整:
1. 不支持[] 运算符:因为 key 不唯一,[] 无法确定修改哪个 value。
2. insert / find / count / erase 行为:与 set和multiset的差异 一致(find 返回中序第一个 key,erase 删除所有相同 key)。
4. 练习题
4.1 环形链表
142. 环形链表 II - 力扣(LeetCode)
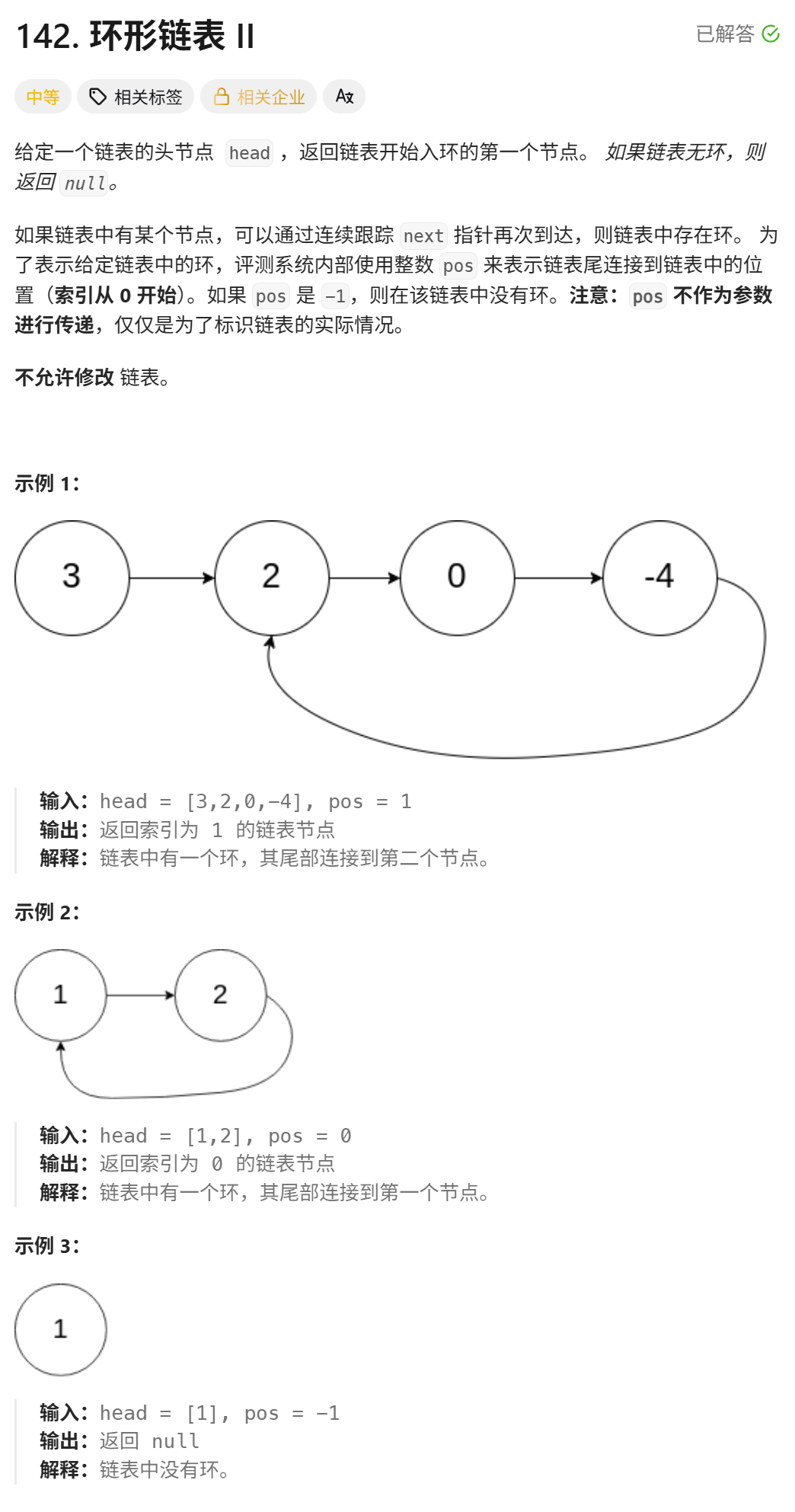
算法解析:
题目中给出一个链表然后我们需要判断这个链表是否有环,如果有环返回入环口处的节点,如果没有则返回空。
我们先创建一个set容器s,将链表中的每个节点都插入到s中,同时设置ret接收insert的返回值,如果ret.second也即返回值中的bool值为false,则代表该节点在s中已经存在,此时这个节点就是我们要的入环口处的节点,如果链表走到空了都没有出现上述情况,则代表该链表无环,返回空即可。
代码如下:
class Solution {
public:ListNode *detectCycle(ListNode *head) {set<ListNode*> s;ListNode* cur = head;while(cur){auto ret = s.insert(cur);if(ret.second == false)return cur;cur = cur->next;}return nullptr;}
};4.2 随机链表的复制
138. 随机链表的复制 - 力扣(LeetCode)
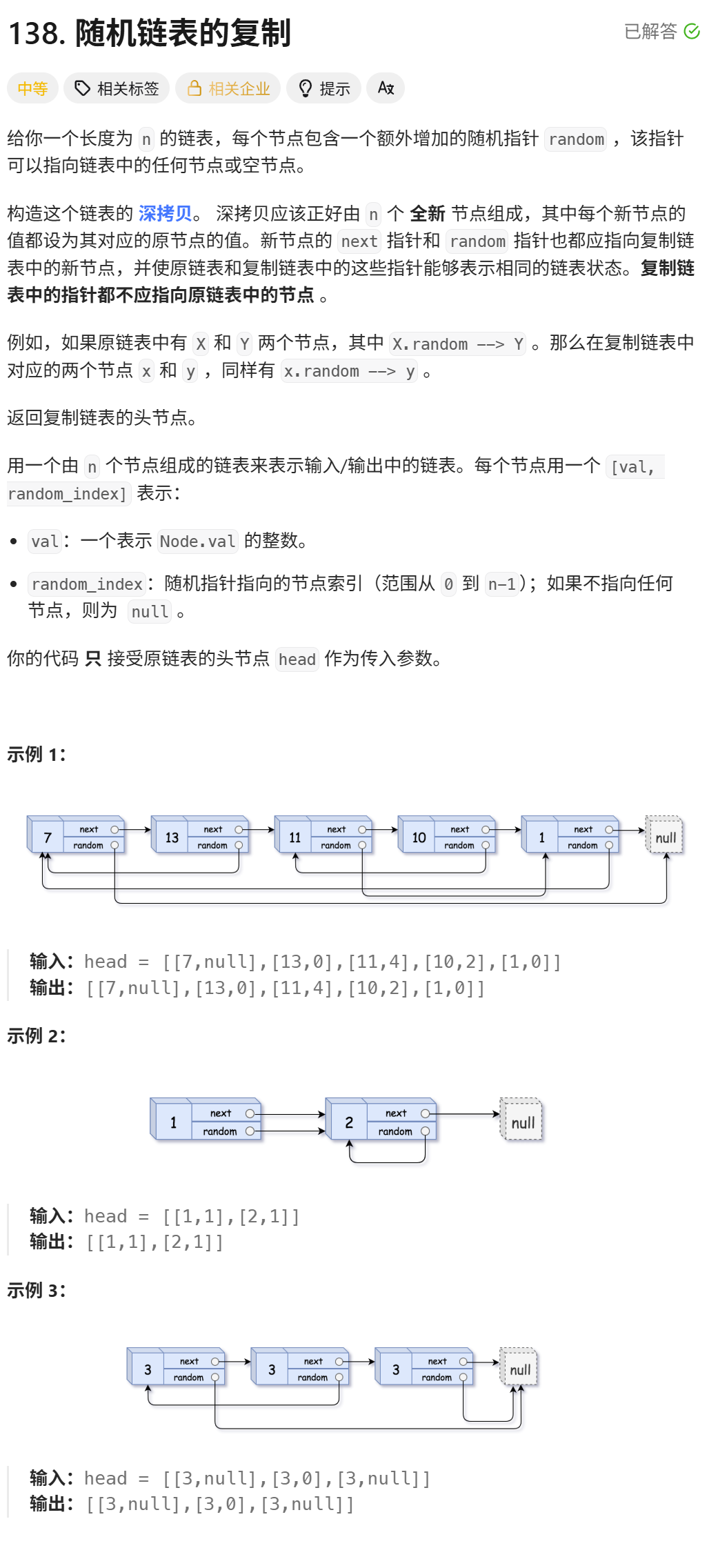
算法解析:
本题要求对包含 random 指针的链表进行深拷贝,需构造一个由全新节点组成的链表,且新链表的 next 和 random 指针需与原链表的结构完全一致(但所有指针不得指向原链表的节点)。
这道题的核心难点在于 random 指针的复制:由于原链表中 random 指针的指向具有不确定性(可能指向任意节点或 nullptr),直接根据原节点的 random 指针无法确定新节点 random 指针的指向。
为解决这一问题,我们可以利用 map 建立 “原节点 → 新节点” 的映射关系:以原节点为 key、对应的新节点为 value 存储。这样,当需要复制某个节点的 random 指针时,只需通过原节点的 random 指针找到对应的原节点,再通过map的映射关系即可定位到新链表中对应的节点,从而完成 random 指针的正确复制。
代码如下:
class Solution {
public:Node* copyRandomList(Node* head) {map<Node*,Node*> m;Node* copyhead = nullptr, *copytail = nullptr;Node* cur = head;while(cur){if(copyhead == nullptr){copyhead = copytail = new Node(cur->val);}else{copytail->next = new Node(cur->val);copytail = copytail->next;}// 原节点和拷⻉节点map kv存储m[cur] = copytail;cur = cur->next;}cur = head;Node* copy = copyhead;while(cur){// 复制random指针:原节点random为null时,复制节点也为nullif(cur->random == nullptr){copy->random = nullptr;}else{// 利用map找到对应复制节点copy->random = m[cur->random];}cur = cur->next;copy = copy->next;}return copyhead;}
};结语
好好学习,天天向上!有任何问题请指正,谢谢观看!