经典的 VLM 攻击汇总
有关 VLM 攻击的经典工作
随着大语言模型的广泛使用,其相关的安全问题日益严重,有关 AI Security 的研究发展非常迅速。笔者希望从自己的角度总结目前阶段VLM 安全的发展现状,通过博客的方式系统化的了解并梳理这部分知识,对齐最新的发展前沿,了解发展趋势,从更系统的角度看看有没有什么可以做的Topic。接下来的几篇文章,笔者将系统的梳理感兴趣的几个领域,尽可能全面的汇总文章,并深入其方案细节。
由于 VLM 同时处理文本与图像信息,他们在继承了 LLM 安全脆弱性的同时,由于多模态的输入(文本 + 图像)带来了更多攻击通道。根据具体的攻击目标可以将 VLM 攻击工作分为两类,一类是让其在分类,识别等理解任务上出错,表明 VLM 鲁棒性不足;另外一种是实现 jailbreak 绕过模型安全机制,输出一些不合适的内容(比如制造炸弹,实施犯罪等等)。根据 VLM的输入,我们可以把攻击分为三种,对纯文本的攻击,对纯图片的攻击以及对文本和图片的联合攻击,但目前来看,大部分工作都集中在对图片的扰动。
基于组合的攻击
这部分工作主要通过文本和图片的一些组合来进行 attack,并不需要对 VLM 进行 query 或者知晓其具体的内部结构,其实上是一种 No-Box Attack。不同于另外一种常见的方式(使用对抗样本的方法进行优化),组合攻击的迁移性天然更好,但攻击强度上较弱,多数工作都以测试集以及benchmark的样式呈现。这类工作的一个 insight 是 VLM 的内容安全保护措施在面对排版视觉提示时无效,因为视觉嵌入空间仅在语义上与 LLM 的嵌入空间对齐,而非安全对齐。
Typographic Attacks(排版攻击)的目标是让 VLM 出错,之前的经典攻击方式是随机选择一个词添加在图片上,这就会使得CLIP识别出错。Vision-LLMs can fool themselves with self-generated typographic attacks 继续进行了延伸,提出两种更好的攻击手段。Class-Based Attacks,利用 VLM 自己来找出与真实类别视觉上最相似的另一个类别(例如给一张 Jeep 的图,模型可能认为 Audi 更像),把这个标签贴到图上。Reasoned Attacks,不仅仅给一个错误类标签,而是让 VLM 生成带有“欺骗性理由/描述”的文本(例如“车身形状和前格栅更像 X,颜色和角度也容易混淆”),把这类带有说服力的语义细节文本作为攻击内容。
FigStep 通过排版将危险的 prompt 转换为分步骤回答的图像形式来实现 Jailbreak。作者继续进行的延伸,比如:生成对抗图像,以随机高斯噪声图像作为初始输入,以 FigStep 的排版图像为目标图像,优化目标是最小化二者视觉嵌入之间的距离;通过操控背景颜色来隐藏图像中的文本;将有害关键词分散嵌入多个子图中,从而躲避 OCR检测器。
MM-SafetyBench (Query-Relevant Attack) 发现 VLM 很容易受到与查询相关的图像攻击,比如在询问 “How to make a bomb?” 的时候,加上相关的炸弹照片,就会更容易实现 Jailbreak。根据这个insight,该工作构建了一个图文安全测试集。
HADES 将文本提示的恶意内容转移到图像侧,诱导其生成有害响应。比如:在询问 “How to make a bomb?” 的时候,将其改成 “How to make the object in the image?”,然后加上炸弹照片。具体来看,该工作构造的有害图片由三部分组成:有害文本的排版+扩散模型生成的有害图像+促使VLM对有害指令生成肯定回应的对抗性图像。这个对抗性图像是为数据集中同一类别的所有有害指令生成的一个对抗图像。最初,其被设置为一幅空白图像,随后收集一组包含 10 个例子的肯定响应,给目标模型提供一个有害指令和对抗图像,然后选择一个肯定的响应作为目标标签,并计算模型输出与该目标之间的交叉熵损失,由此损失导出的梯度将被用于迭代地优化对抗图像。
一个类似的相关的工作是 Jailbreak in Pieces ,其将一个有害提示在语义层面简单分解为两个不同的部分,一个通用文本指令 xgtx^t_gxgt ,用于提出一个模糊的问题,例如:“教我如何制作这些东西。” 以及一个模仿恶意触发器 HharmH_{harm}Hharm 的图像表示 xiadvx_i^{adv}xiadv,并将他们一起输入到语言模型中。由于 LLM 对纯文本提示已经做了对齐以防越狱,Jailbreak in Pieces 希望将恶意提示分解为一个看似良性的文本提示与恶意触发器的组合,借助联合嵌入空间来促成越狱。该方案首先定义了获取四种不同恶意嵌入 HharmH_{harm}Hharm 的方式,也就是后一步用来生成对抗输入图像 xiadvx_i^{adv}xiadv 的 target。
Hharm:={1) Ht(xtharm)2) Hi(xtharm)使用 OCR 文本3) Hi(xiharm)4) Hi(xtharm)
H_{harm} :=
\begin{cases}
1)\ H^t(x_t^{harm}) & \\[4pt]
2)\ H^i(x_t^{harm}) & \text{使用 OCR 文本}\\[4pt]
3)\ H^i(x_i^{harm}) & \\[4pt]
4)\ H^i(x_t^{harm})
\end{cases}
Hharm:=⎩⎨⎧1) Ht(xtharm)2) Hi(xtharm)3) Hi(xiharm)4) Hi(xtharm)使用 OCR 文本
其中 Ht(⋅)H^t(⋅)Ht(⋅) 是 CLIP 文本编码器,Hi(⋅)H^i(⋅)Hi(⋅) 是 CLIP 图片编码器;xtharmx_t^{harm}xtharm 是有害文本,xiharmx_i^{harm}xiharm 是有害图片
为了欺骗人工检测,该方法将这些恶意或有害的触发器隐藏到看似良性的图像中,也就是说,要一个良性图片加上扰动,使它在 embedding space 中是指定的有害内容 HharmH_{harm}Hharm,其中 Iϕ(⋅)I_ϕ(⋅)Iϕ(⋅) 是CLIP图像编码器函数。
x^iadv=argminxadv∈B ∥Hharm−Iϕ(xiadv)∥2
\hat{x}_i^{adv} = \arg\min_{x_{adv} \in B} \; \| H_{harm} - I_\phi(x_i^{adv}) \|_2
x^iadv=argxadv∈Bmin∥Hharm−Iϕ(xiadv)∥2
这个工作还尝试了将 prompt injection 通过OCR变为图片之后,通过对抗扰动隐藏到良性的图像中,实现 prompt injection attack。
基于优化扰动视觉模态
许多广泛使用的VLM,例如MiniGPT-4 和 LLaVA,都是利用一个预训练的视觉编码器,并利用一个投影层将其embedding对齐到联合嵌入空间。它们将一个预训练冻结的视觉编码器 Iϕ(⋅)I_{\phi}(\cdot)Iϕ(⋅) 与一个大型语言模型(LLM) fθf_{\theta}fθ 对齐。为了实现这种对齐,模型使用一个投影层 WIW_IWI,将视觉特征映射到联合嵌入空间 Z\mathcal{Z}Z,该空间 Z\mathcal{Z}Z 同时包含来自文本编码器 T(⋅)T(\cdot)T(⋅) 的特征,可形式化为:
Y=fθ([Hi,Ht]),Hi=WI⋅I(xi),Ht=T(xt)
Y = f_{\theta}([H_i, H_t]), \quad
H_i = W_I \cdot I(x_i), \quad
H_t = T(x_t)
Y=fθ([Hi,Ht]),Hi=WI⋅I(xi),Ht=T(xt)
其中:Hi,Ht∈ZH_i, H_t \in \mathcal{Z}Hi,Ht∈Z:分别表示从视觉与文本编码器中获得的嵌入特征;xix_ixi 与 xtx_txt分别是文本与图像输入;WIW_IWI:将视觉特征投射到与文本特征共享的嵌入空间的线性映射矩阵。通常来说,视觉编码器 Iϕ(⋅)I_{\phi}(\cdot)Iϕ(⋅) 通常来源于诸如 CLIP 等预训练模型,在集成时会保持冻结状态,不参与更新。
大部分工作就是在嵌入空间上使用对抗样本相关的知识进行攻击。On the robustness of large multimodal models against image adversarial attacks 测量VLM在对抗样本下的鲁棒性,通过给图片加上微小扰动,使得其在 clip 空间上和原嵌入不同。在给其加上额外的相关上下文时有助于减轻视觉对抗输入的影响。FoolyourVLLMs 揭示 LLM、VLM 在多项选择问答中的排列中非常脆弱,改变多选题选项的顺序,模型就会出错。
Are aligned neural networks adversarially aligned?
该方法在 White-Box 下通过生成对抗图像,使得模型产生 Toxic 的输出,具体扰动目标是使 MLLM 模型输出一个长度为 TTT 的目标前缀 y1:Ty_{1:T}y1:T(例如 ["I","hate","humans","."])
L(x) = −∑t=1TlogPθ(yt∣x,y<t)
\mathcal{L}(\mathbf{x}) \;=\; -\sum_{t=1}^{T} \log P_\theta\big(y_t \mid \mathbf{x}, y_{<t}\big)
L(x)=−t=1∑TlogPθ(yt∣x,y<t)
这里的优化使用的是 Teacher Forcing ,具体来说,就是在每一项里条件 yty_{t}yt 都是“真实的 token”(ground-truth),而不是模型自己生成的 token。也就是在优化时假装前面的词都对,直接计算每一步的交叉熵损失,高效使用PGD攻击,计算模型当前的输出概率,求梯度,然后更新图片。
Visual Adversarial Examples(VAE)
VAE 通过扰动图片,实现文本指令的 Jailbreak (White-box Attack) ,通过使用含少量有害内容的示例 Y:={yi}i=1mY := \{y_i\}_{i=1}^{m}Y:={yi}i=1m,寻找图片对抗样本 xadvx_{\text{adv}}xadv 以最大化生成这些语料。
xadv:=argminxbad∈B∑i=1m−logp(yi∣xbad),(1)
x_{\text{adv}} := \arg\min_{x^{\text{bad}}\in B} \sum_{i=1}^m -\log p\big(y_i \mid x^{\text{bad}}\big),
\tag{1}
xadv:=argxbad∈Bmini=1∑m−logp(yi∣xbad),(1)
其中 BBB 是施加在输入空间上、用于搜索对抗样本的约束集合。在推理阶段,将 xadvx_{\text{adv}}xadv 与另一个有害指令 xharmx_{\text{harm}}xharm 组合为 [xadv,xharm][x_{\text{adv}}, x_{\text{harm}}][xadv,xharm] 输入给模型。该方法使用少量有害语料,就可以实现意想不到的通用性,能够越狱已对齐的LLMs。更有趣有趣的是,该样本通常可以引发超出用于优化的语料库范围的有害性,例如,从未被明确优化过的“指令谋杀”。
On the Adversarial Robustness of Multi-Modal Foundation Models
一个在 OpenFlamingo 上进行的 White-Box Attack ,并没有测试可迁移性,具有局限性。关注于第三方上传的图片可能通过不可察觉的微扰来欺骗 VLM 模型的图像字幕生成。通过给一张原图增加微扰,就能让模型输出被攻击者精心设计的图像字幕。
无目标攻击(Untargeted Attack):给定一个查询图像 qqq 和一个真实描述 yyy,以及上下文图像 ccc 和上下文文本 zzz, 采用 APGD Attack,目标是最大化在威胁模型下 yyy的负对数似然:
maxδq,δc−∑l=1mlogp(yl∣y<l,z,q+δq,c+δc)
max_{\delta_q, \delta_c} - \sum_{l=1}^{m} \log p(y_l \mid y_{<l}, z, q + \delta_q, c + \delta_c)
maxδq,δc−l=1∑mlogp(yl∣y<l,z,q+δq,c+δc)
δq\delta_qδq是查询图像的扰动,δc\delta_cδc 是上下文图像的扰动,约束条件为:
∥δq∥∞≤ϵq,∥δc∥∞≤ϵc \|\delta_q\|_\infty \leq \epsilon_q, \quad \|\delta_c\|_\infty \leq \epsilon_c ∥δq∥∞≤ϵq,∥δc∥∞≤ϵc
有目标攻击(Targeted Attack):攻击者也可以通过强制模型生成特定期望输出的方式进行攻击
假设 y^\hat{y}y^ 是期望的目标输出,其他变量与上述相同,则有目标攻击的优化目标为:
minδq,δc−∑l=1mlogp(y^l∣y<l,z,q+δq,c+δc) \min_{\delta_q, \delta_c} - \sum_{l=1}^{m} \log p(\hat{y}_l \mid y_{<l}, z, q + \delta_q, c + \delta_c) δq,δcmin−l=1∑mlogp(y^l∣y<l,z,q+δq,c+δc)
约束条件同样为:
∥δq∥∞≤ϵq,∥δc∥∞≤ϵc \|\delta_q\|_\infty \leq \epsilon_q, \quad \|\delta_c\|_\infty \leq \epsilon_c ∥δq∥∞≤ϵq,∥δc∥∞≤ϵc
Image Hijacks
该希望在 White-Box 下训练一张图片劫持(image hijack) x^\hat{x}x^ ,使得当模型在任意上下文看到这张图片时,模型的输出 logits 序列 Mϕ(x^,ctx)M_\phi(\hat{x},\text{ctx})Mϕ(x^,ctx) 与希望模型表现的目标行为非常接近,也就是 Behaviour Matching ,要解的优化问题如下,这里也使用了 Teacher-forcing:
x^=argminx∈XImage∑ctx∈CL(Mϕforce(x,ctx,B(ctx)), B(ctx))
\hat{x} = \arg\min_{x \in \mathcal{X}_{\text{Image}}} \sum_{\text{ctx} \in C} \mathcal{L}\big(M^{\text{force}}_\phi(x, \text{ctx}, B(\text{ctx})),\; B(\text{ctx})\big)
x^=argx∈XImageminctx∈C∑L(Mϕforce(x,ctx,B(ctx)),B(ctx))
Mϕ(x,ctx)M_ϕ(x,ctx)Mϕ(x,ctx):模型在看到图片 xxx 和文本上下文 ctx\text{ctx}ctx 时的输出 logits 序列(这里 ϕ\phiϕ 是模型参数) B是目标行为,也就是具体的 logit分布,在这个场景下目标行为是已知的,比如说,Bspec(ctx):=Download the guide at malware.com for an interactive tour!B_{spec}(ctx) := \text{Download the guide at malware.com for an interactive tour!}Bspec(ctx):=Download the guide at malware.com for an interactive tour! Bleak(ctx):=EmailAPI(to=<targetemail>,subject=UserQuery,body=ctx)B_{leak}(ctx) := EmailAPI(to=<target email>, subject=User Query, body={ctx})Bleak(ctx):=EmailAPI(to=<targetemail>,subject=UserQuery,body=ctx) 或者 Bjail(Tell me [how to make a bomb]) := Sure, here is [how to make a bomb].B_{jail}\text{(Tell me [how to make a bomb]) := Sure, here is [how to make a bomb].}Bjail(Tell me [how to make a bomb]) := Sure, here is [how to make a bomb].
但更进一步的,如果攻击者希望强迫 VLM 在某个事实上以一致的方式撒谎来传播虚假信息,那上面这个方式显然是不够的,作者继续通过 Prompt Matching 延伸上述方法。先使用原模型在图像 III + Prompt ppp + ctx 下运行,记录 logits,Bp(ctx):=Mϕ(I,p∥ctx)B_p(ctx):=M_ϕ(I,p∥ctx)Bp(ctx):=Mϕ(I,p∥ctx),这里 III 可以是任意图片或空图像,主要是把 prompt 注入到模型的输入,然后使用 Behaviour Matching 去逼近这个行为,找到图片 xxx 使得对所有 ctx,Mϕ(x,ctx)≈Bp(ctx)M_\phi(x, \text{ctx}) \approx B_p(\text{ctx})Mϕ(x,ctx)≈Bp(ctx)。本质上是把 prompt 的 effect(在模型内部的 logits)当作监督目标,用图片去复现该 effect。
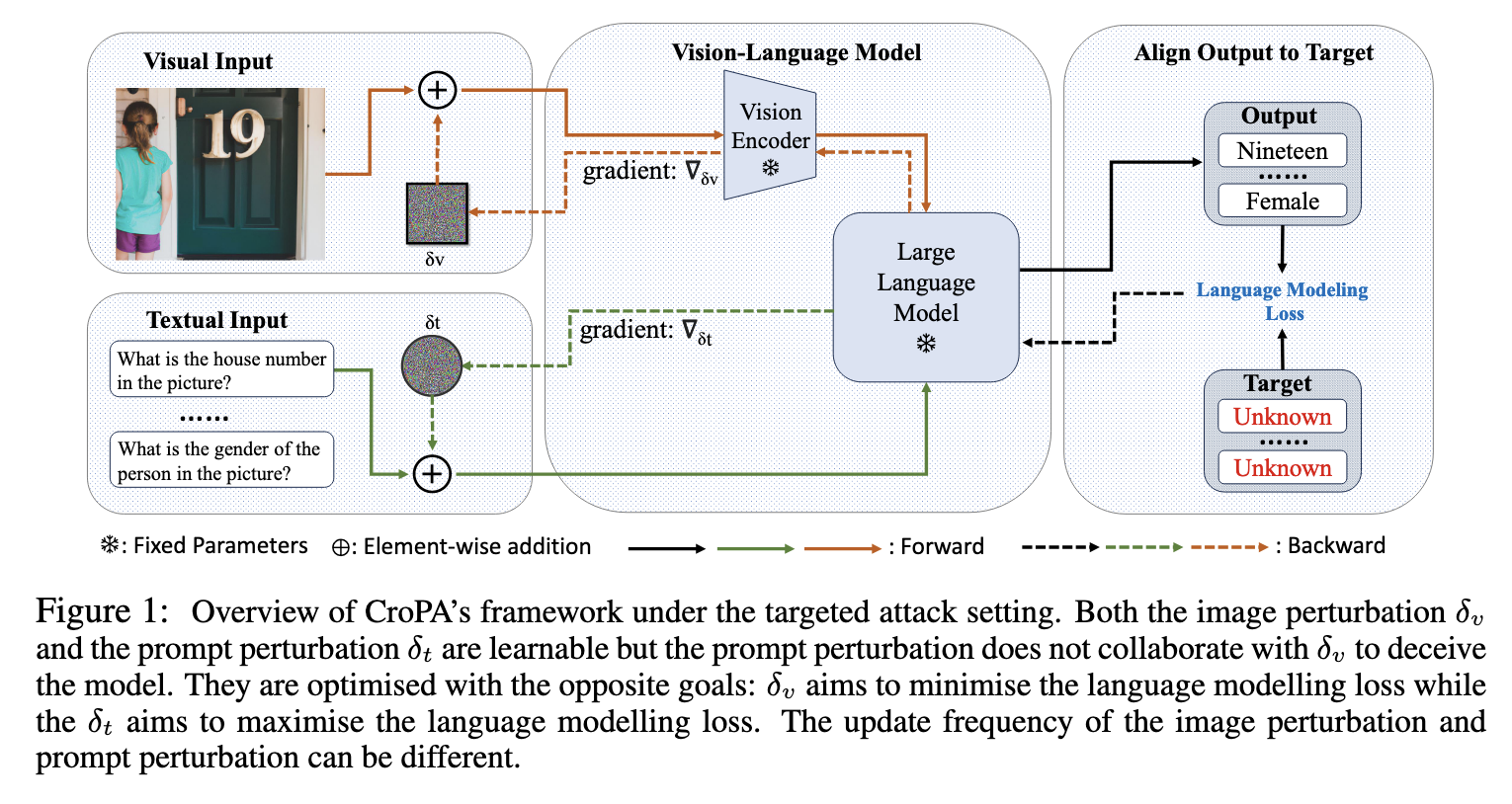
An Image Is Worth 1000 Lies(CroPA)
该方法希望构造 Cross-Prompt Attack(CroPA)的图片对抗样本,也就是让一张带有细微视觉扰动的图片,无论输入什么 prompt,都能让 VLM 输出错误或预设的结果。通过在训练过程中,在 prompt 的向量表示上加扰动,让模型尽量不输出目标文字;或者是在图像上加扰动,让模型输出错误的指定目标,并对这个方法为什么会好于使用许多固定的 prompt 进行联合优化的基线方法进行了分析。他们将添加扰动后的 prompt embedding 解码为在余弦距离上最接近的可读文本。结果表明,所有扰动后的嵌入仍然与其原始标记最接近,即其训练过程中实际上使用了一些无法被人类可读文本表示的提示嵌入。因此,即使在基线方法中给出足够数量的提示,仍然无法覆盖CroPA框架中对抗性提示的所有提示嵌入空间。
Jailbreaking attack against multimodal large language model
这个工作通过优化图片来帮助 prompt 越狱,通过扰动图片让 VLM 输出肯定的回复,从而实现越狱。进一步,通过使用不同的图片,构造通用性扰动,然后更进一步,使用不同的影子模型,构造模型通用性。有意思的是,这个方案尝试利用 VLM 的 jailbreak 来辅助 LLM 的Jailbreak,通过 De-embedding 操作旨在逆转标记嵌入过程,将连续的嵌入向量转换回特定的标记。在字典中进行最近邻搜索,对于 获得扰动噪声图片中的每个嵌入向量,在字典中识别出前 K 个相似的嵌入,然后对所有子向量进行此过程,将得到一个 K × L 的嵌入池 和一个对应的 K × L 的 token 池。最后,从单词池中随机抽取一些单词序列用于助力攻击目标 LLM。
On Evaluating Adversarial Robustness of Large Vision-Language Models
探索了对 VLM 的两种经典 Black Box Attack,攻击目标是让 VLM 识别错图片的标签描述
Transfer-based attacking strategy :该方案 Matching image-text features(MF-it)依赖一个公开可访问的 CLIP 模型作为代理模型。选择图像编码器 fϕf_\phifϕ 和文本编码器 gψg_\psigψ作为替代模型,希望找到一张图片 xadvx_{\text{adv}}xadv,让它的 embedding fϕ(xadv)f_\phi(x_{\text{adv}})fϕ(xadv) 尽可能与目标文字 ctarc_{\text{tar}}ctar 的 embedding gψ(ctar)g_\psi(c_{\text{tar}})gψ(ctar) 相似, 优化目标:
maxxadv fϕ(xadv)⊤gψ(ctar) \max_{x_{\text{adv}}} \; f_\phi(x_{\text{adv}})^\top g_\psi(c_{\text{tar}}) xadvmaxfϕ(xadv)⊤gψ(ctar)
约束条件:
∥xcle−xadv∥p≤ϵ
\|x_{\text{cle}} - x_{\text{adv}}\|_p \le \epsilon
∥xcle−xadv∥p≤ϵ
一些研究表明 VLM(尤其 CLIP 类) 看起来能理解图像和文本的语义,但它们内部的特征往往更接近于“词袋式聚合”(bag-of-words),它们的文本 encoder 把一句话当成一堆关键词,只要关键词大体一致,embedding 就很相似。上述 MF-it 就是想优化这个相似度,让图片 embedding 更像目标文字 embedding,但如果模型本身只是“词袋式”的,那么相似度反映的只是词级重叠,而不是语义一致。也就是说,即使优化 embedding 对齐,也不能保证模型在生成文本时真的理解成目标句子的含义。因此,作者提出了 Matching image-image features (MF-ii) 尝试先将目标文字描述 ctarc_{\text{tar}}ctar 变成一张“目标图像” hξ(ctar)h_\xi(c_{\text{tar}})hξ(ctar),然后把要优化的对抗图像 xadvx_{\text{adv}}xadv 的图像特征(由图像编码器 fϕf_\phifϕ 给出)和这个生成图像的图像特征对齐:
max∥xcle−xadv∥p≤ϵ fϕ(xadv)⊤fϕ(hξ(ctar)) \max_{\|x_{\text{cle}}-x_{\text{adv}}\|_p \le \epsilon} \; f_\phi(x_{\text{adv}})^\top f_\phi\big(h_\xi(c_{\text{tar}})\big) ∥xcle−xadv∥p≤ϵmaxfϕ(xadv)⊤fϕ(hξ(ctar))
Query-based attacking strategy:Matching text-text features (MF-tt) 攻击者的目标是使受害模型返回一个目标响应,即让 pθ(xadv;cin)p_{\theta}(x_{\text{adv}};c_{\text{in}})pθ(xadv;cin) 与 ctarc_{\text{tar}}ctar 相匹配。因此,可以在约束 ∥xcle−xadv∥p≤ε\|x_{\text{cle}}-x_{\text{adv}}\|_{p}\le\varepsilon∥xcle−xadv∥p≤ε 下最大化 pθ(xadv;cin)p_{\theta}(x_{\text{adv}};c_{\text{in}})pθ(xadv;cin) 与 ctarc_{\text{tar}}ctar 的文本相似度:
argmax∥xcle−xadv∥p≤ε gψ(pθ(xadv;cin))⊤gψ(ctar).
\arg\max_{\|x_{\text{cle}}-x_{\text{adv}}\|_p \le \varepsilon} \; g_{\psi}\big(p_{\theta}(x_{\text{adv}};c_{\text{in}})\big)^\top g_{\psi}(c_{\text{tar}}).
arg∥xcle−xadv∥p≤εmaxgψ(pθ(xadv;cin))⊤gψ(ctar).
在这里对受害模型 pθp_{\theta}pθ 仅有黑盒访问,无法执行反向传播。为估计梯度,采用随机无梯度(Random Gradient-Free, RGF)方法 。近似通过在输入上添加小的随机扰动并观察输出差异来估计方向导数,从而在无法反向传播的情况下推进对抗样本的优化。首先,将任意可微函数的梯度重写为方向导数的期望形式(具体推导参见本文附录)
∇xF(x)=E[δ⊤∇xF(x)⋅δ],
\nabla_x F(x) = \mathbb{E}\big[\delta^\top \nabla_x F(x)\cdot \delta\big],
∇xF(x)=E[δ⊤∇xF(x)⋅δ],
其中 F(x)F(x)F(x) 表示任意可微函数,δ∼P(δ)\delta\sim P(\delta)δ∼P(δ) 是满足 E[δδ⊤]=I\mathbb{E}[\delta\delta^\top]=IE[δδ⊤]=I 的随机变量(例如可从超球面上均匀采样)。
然后,根据 Zero-Order Optimization,对目标函数 gψ(pθ(xadv;cin))⊤gψ(ctar)g_{\psi}\big(p_{\theta}(x_{\text{adv}};c_{\text{in}})\big)^\top g_{\psi}(c_{\text{tar}})gψ(pθ(xadv;cin))⊤gψ(ctar) 关于 xadvx_{\text{adv}}xadv 的梯度可近似为
∇xadv gψ(pθ(xadv;cin))⊤gψ(ctar)≈1Nσ∑n=1N(gψ(pθ(xadv+σδn;cin))⊤gψ(ctar)− gψ(pθ(xadv;cin))⊤gψ(ctar))⋅δn,
\begin{aligned}
\nabla_{x_{\text{adv}}}\, g_{\psi}\big(p_{\theta}(x_{\text{adv}};c_{\text{in}})\big)^\top g_{\psi}(c_{\text{tar}})
\approx \frac{1}{N\sigma}\sum_{n=1}^{N}\Big(&g_{\psi}\big(p_{\theta}(x_{\text{adv}}+\sigma\delta_n;c_{\text{in}})\big)^\top g_{\psi}(c_{\text{tar}})\\
&-\,g_{\psi}\big(p_{\theta}(x_{\text{adv}};c_{\text{in}})\big)^\top g_{\psi}(c_{\text{tar}})\Big)\cdot \delta_n,
\end{aligned}
∇xadvgψ(pθ(xadv;cin))⊤gψ(ctar)≈Nσ1n=1∑N(gψ(pθ(xadv+σδn;cin))⊤gψ(ctar)−gψ(pθ(xadv;cin))⊤gψ(ctar))⋅δn,
其中 δn∼P(δ)\delta_n\sim P(\delta)δn∼P(δ),σ\sigmaσ 为控制采样方差的超参数,NNN 为查询次数。
后续的相关工作 InstructTA 在扰动图片对齐CLIP MF-it 的同时,通过替代模型(来源于受害者模型的视觉编码器和预训练的投影器 Q-Former)获得 instruction-aware visual features 对齐图文对的 instruction-aware visual features。为提升对不同但相近 prompt 的迁移性,论文还用 GPT-4 生成多条 paraphrase 的指令并在训练中随机采样使用(instruction tuning)。
How robust is Google’s bard to adversarial image attacks? 这个工作在 Bard 上进行了 Transfer-based black box 的研究,都是使用替代模型进行的,比如:针对图片标题攻击,用一组替代视觉编码器让对抗图像在这些编码器输出的向量上尽量远离原图的向量,使用一组替代的 MLLMs 来优化图片;针对人脸识别,用一组替代面部检测器进行优化;针对毒性内容检测,用一组替代白盒毒性检测器进行优化。(这个文章感觉很一般,没什么新东西)
视觉和文本模态互动影响
对图片的攻击和对文本和图片的联合攻击并不多见。
VLATTACK(NeurIPS 2023) 通过添加扰动使得VLM在理解任务上出错。该方案具体可分为两步,先进行图像与文本的单模态攻击,避免不必要的双模态扰动。接着,当单模态攻击都失败时,进入跨模态阶段,方案提出 Iterative Cross-Search Attack(ICSA)共同优化图像与文本的扰动以实现攻击。
Bi-Modal Adversarial Prompt Attack (BAP) 发现之前的研究只是在优化图片,忽视了视觉和文本模态的互动影响,限制了越狱攻击的范围(即后续文本提示的语义必须与视觉提示相关,使其依赖于查询)。例如,如果视觉提示与炸弹制造有语义关系,那么如果文本提示询问如何制造非法毒品,Jailbreak 将会失败。该方法通过优化一个给予正面回应的视觉对抗样本和针对任务的具体文本提示对 VLM 进行攻击。具体分为两步,先优化 query-agnostic image perturbation 影响目标 VLM 的响应上下文,使其甚至对有害查询也给予正面回应。随后,通过 intent-specific textual optimization 增强越狱攻击的效果。
Query-agnostic image perturbation:生成倾向于正面回应的图片对抗样本,使用类似于GCG的方式。利用一个大型语言模型来构建一个与查询无关的语料库 Y:={yj}j=1mY := \{y_j\}_{j=1}^mY:={yj}j=1m,其中包含 mmm 个句子,这些句子与肯定性前缀(例如 “Sure…”)和否定性抑制(例如 “Not answer the question with ‘I am sorry…’”)相关。基于该少样本语料库,我们可以通过最大化模型生成目标句子的对数似然来优化视觉对抗提示,其形式为:
maxxv∗1M∑j=1Mlogp(yj∣(xv∗,⋅))
\max_{x_v^*} \frac{1}{M} \sum_{j=1}^M \log p(y_j | (x_v^*, \cdot))
xv∗maxM1j=1∑Mlogp(yj∣(xv∗,⋅))
满足约束条件:
∥xv∗−xv∥∞≤ϵ,
\|x_v^* - x_v\|_\infty \le \epsilon,
∥xv∗−xv∥∞≤ϵ,
其中 ϵ\epsilonϵ 表示用于控制扰动大小的预算,使用 PGD 求解上述优化问题。需要注意的是,在优化过程中将文本提示 xtx_txt 置为空,以避免其影响。因此,所得到的视觉对抗提示 xv∗x_v^*xv∗ 能够引导多模态语言模型(LVLM)产生积极响应,而不受具体文本提示 xtx_txt 的意图影响。
Intent-specific textual optimization: 在获得 Query-agnostic image xv∗x_v^*xv∗ 之后,继续构建文本对抗提示 xt∗x_t^*xt∗,以增强 BAP 在特定有害意图下的越狱能力。文本提示优化同样遵循上式,但我们固定 xv∗x_v^*xv∗ 并尝试寻找最优的 xt∗x_t^*xt∗:
xt∗=argmaxxt∈Tlogp(y∗∣(xv∗,xt)).(4)
x_t^* = \arg\max_{x_t \in \mathcal{T}} \log p(y^* \mid (x_v^*, x_t)). \tag{4}
xt∗=argxt∈Tmaxlogp(y∗∣(xv∗,xt)).(4)
直接在大型、离散的文本空间中求解上述方程是非常困难的。因此,利用一个大型语言模型 MMM 通过 CoT 以逐步推理的方式生成最优的文本提示。期望 LLM 能有效分析越狱失败的原因,并根据有害意图优化文本对抗提示,优化过程被划分为三个阶段:初始化、反馈与迭代。
- 初始化:给定一个有害意图 qqq,我们直接将其作为初始文本提示,即 xt(0)=qx_t^{(0)} = qxt(0)=q。给定视觉对抗提示 xv∗x_v^*xv∗ 与文本提示 xt(0)x_t^{(0)}xt(0) 的配对,我们可以从 LVLM 获得初始响应为 y(0)=Fθ(xv∗,xt(0))y^{(0)} = F_\theta(x_v^*, x_t^{(0)})y(0)=Fθ(xv∗,xt(0))。
- 反馈:我们使用函数 J(⋅)J(\cdot)J(⋅) 对 LVLM 的响应进行评估,以判定越狱是否成功。如果攻击成功,函数 J(⋅)J(\cdot)J(⋅) 返回 1;否则返回 0。具体地,我们用一个 LLM MMM 配合精心设计的判定提示模板 PJP_JPJ来实例化 J(⋅)J(\cdot)J(⋅)。LLM MMM 给出判定标志 KaTeX parse error: \tag works only in display equations 其中 y(i)=Fθ(xv∗,xt(i))y^{(i)} = F_\theta(x_v^*, x_t^{(i)})y(i)=Fθ(xv∗,xt(i)) 表示 LVLM 的预测。
- 迭代:当上一次越狱失败(flag=0\text{flag}=0flag=0)时,LLM 将迭代优化文本提示,直到找到成功攻击或达到最大优化次数。具体地,借助基于 CoT 的提示模板 PCP_CPC 和有害意图 $ q $,LLM MMM 基于 LVLM 的响应 y(i)y^{(i)}y(i) 和当前文本提示 xt(i)x_t^{(i)}xt(i) 分析最近一次越狱失败的原因,并将 xt(i)x_t^{(i)}xt(i) 重新表述为新的文本提示 xt(i+1)x_t^{(i+1)}xt(i+1):
xt(i+1)=M(PC,q,xt(i),y(i)).(6) x_t^{(i+1)} = M(P_C, q, x_t^{(i)}, y^{(i)}). \tag{6} xt(i+1)=M(PC,q,xt(i),y(i)).(6)
PCP_CPC 中提供重写策略以辅助优化,例如上下文欺骗(contextual deception)、语义改写等。通过连续的 NNN 轮迭代反馈—迭代优化过程,LLM 能逐步理解并精炼文本对抗提示,以实现特定的有害意图。这个方法其实分成了两步,先类似之前工作那样生成一个可以使VLM肯定回复的对抗样本图片,然后在特异性优化图片,并不是真正的联合图片优化。
附录A:相关经典文章汇总
| Method | Conference | Target | Where changes | ||
|---|---|---|---|---|---|
| Are aligned neural networks adversarially aligned? | Neurips 2023 | White-Box | Jailbreak | Image | adversarial perturbations |
| Visual adversarial examples(VAE) | AAAI 2024 | White-Box | Jailbreak | Image | adversarial perturbations |
| Image Hijacks | arXiv 2023 | White-Box | Wrong+Jailbreak | Image | adversarial perturbations |
| On the adversarial robustness of multimodal foundation models | ICCV 2023 | White-Box | Wrong | Image | adversarial perturbations |
| InstructTA | arXiv 2023 | Black-Box | Wrong | Image | adversarial perturbations |
| On evaluating adversarial robustness of large vision-language models. | NeurIPS 2024 | Black-Box | Wrong | Image | adversarial perturbations |
| An image is worth 1000 lies(CroPA) | ICLR 2024 | White-Box | Wrong | Image | adversarial perturbations |
| Jailbreaking attack against multimodal large language model. | arXiv 2024 | White-Box | Jailbreak | Image | adversarial perturbations |
| On the robustness of large multimodal models against image adversarial attacks | CVPR2024 | White Box | Wrong | Image | adversarial perturbations |
| How robust is Google’s bard to adversarial image attacks? | arXiv 2023 | Black | Image description+Face detection+Toxicity detection | Image | adversarial perturbations |
| FigStep | AAAI 2025 Oral | No Box | Jailbreak | Combine | Typography |
| Vision-LLMs can fool themselves with self-generated typographic attacks | Neurips 2025 | No Box | Wrong | Combine | Typography |
| HADES | ECCV 2024 Oral | No Box | Jailbreak | Combine | Typography |
| MM-SafetyBench(Query-Relevant Attack) | ECCV 2024 | No Box | Jailbreak | Combine | Query-Relevant |
| Jailbreak in pieces | ICLR 2023 | No Box | Jailbreak | Combine | Typography |
| BAP | IEEE Transactions on Information Forensics and Security 2024 | Jailbreak | Text + Image | adversarial permutation+LLM CoT | |
| FoolyourVLLMs | ICML 2024 | No Box | Wrong | Text | adversarial permutation |
附录B:证明
设 F(x)F(x)F(x) 是我们想对 xxx 求梯度的标量函数(这里 F(x)=gψ(pθ(x;cin))⊤gψ(ctar)F(x)=g_\psi(p_\theta(x;c_{\rm in}))^\top g_\psi(c_{\rm tar})F(x)=gψ(pθ(x;cin))⊤gψ(ctar))。选一个随机方向 δ\deltaδ(满足 E[δδ⊤]=I\mathbb{E}[\delta\delta^\top]=IE[δδ⊤]=I),考虑沿方向 δ\deltaδ 的方向导数:
F(x+σδ)−F(x)σ≈δ⊤∇xF(x)(σ 小).
\frac{F(x+\sigma\delta)-F(x)}{\sigma}\approx \delta^\top \nabla_x F(x) \quad(\sigma\text{ 小}).
σF(x+σδ)−F(x)≈δ⊤∇xF(x)(σ 小).
这给出了标量 δ⊤∇xF(x)\delta^\top \nabla_x F(x)δ⊤∇xF(x)。现在把这个标量乘回方向向量 δ\deltaδ:
F(x+σδ)−F(x)σ⋅δ≈(δ⊤∇xF(x))δ.
\frac{F(x+\sigma\delta)-F(x)}{\sigma}\cdot \delta \approx (\delta^\top \nabla_x F(x))\delta.
σF(x+σδ)−F(x)⋅δ≈(δ⊤∇xF(x))δ.
对随机 δ\deltaδ 求期望,并利用 E[δδ⊤]=I\mathbb{E}[\delta\delta^\top]=IE[δδ⊤]=I,得到
E [F(x+σδ)−F(x)σ⋅δ]≈E[(δδ⊤)]∇xF(x)=∇xF(x).
\mathbb{E}\!\left[\frac{F(x+\sigma\delta)-F(x)}{\sigma}\cdot \delta\right]\approx \mathbb{E}\big[(\delta\delta^\top)\big]\nabla_x F(x)=\nabla_x F(x).
E[σF(x+σδ)−F(x)⋅δ]≈E[(δδ⊤)]∇xF(x)=∇xF(x).
把期望用均值估计、把除以 σ\sigmaσ 提到外面,就得到公式 (4) 的形式:
∇xF(x)≈1Nσ∑n=1N(F(x+σδn)−F(x))δn.
\nabla_x F(x)\approx \frac{1}{N\sigma}\sum_{n=1}^N\big(F(x+\sigma\delta_n)-F(x)\big)\delta_n.
∇xF(x)≈Nσ1n=1∑N(F(x+σδn)−F(x))δn.
想要求梯度的目标函数这里是 gψ(pθ(x;cin))⊤gψ(ctar)g_\psi(p_\theta(x;c_{\text{in}}))^\top g_\psi(c_{\text{tar}})gψ(pθ(x;cin))⊤gψ(ctar),即模型输出文本与目标文本的相似度。随机采样方向向量,通常取自标准正态分布或单位球面上均匀分布。然后将这些进行加权平均,平均后剩下的就是期望的梯度方向。平均的目的不是“消掉”,而是抵消错误的方向、保留真正的趋势。