李宏毅深度强化学习课程笔记
课程链接:
https://www.bilibili.com/video/BV1aes8ebEz3/?spm_id_from=333.1007.0.0&vd_source=132c74f7a893f6ef64b723d9600c40b7![]() https://www.bilibili.com/video/BV1aes8ebEz3/?spm_id_from=333.1007.0.0&vd_source=132c74f7a893f6ef64b723d9600c40b7
https://www.bilibili.com/video/BV1aes8ebEz3/?spm_id_from=333.1007.0.0&vd_source=132c74f7a893f6ef64b723d9600c40b7
Policy based approach:学习actor(policy)
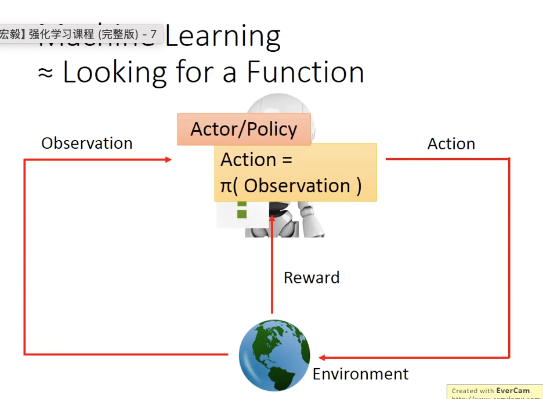
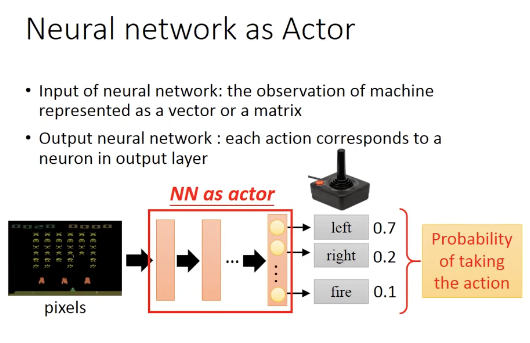
actor(policy)就是一个function,输入是observation(或者叫state),输出是action,一般用
表示, 其中网络的参数用
表示。
优化目标:一场游戏中一连串action的reward的综合,叫做total reward(也叫return),用
表示,其中
强化学习的过程如下:其目标就是最大化total reward的期望
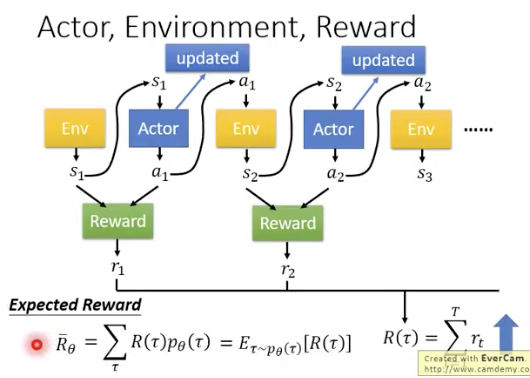

代表一整个episode的state,action,reward的序列,通过不停的玩游戏,得到非常多的轨迹
,假设从中sample出N次玩的轨迹,假设这个N特别大。那么toral reward的期望
就可以由这N次轨迹的toral reward来估计
其中代表,使用
作为actor时,得到轨迹
的概率

是环境给出的,是一个黑盒子,只返回一个reward的数值
优化目标:最大化total reward的期望

轨迹的计算方式如下:
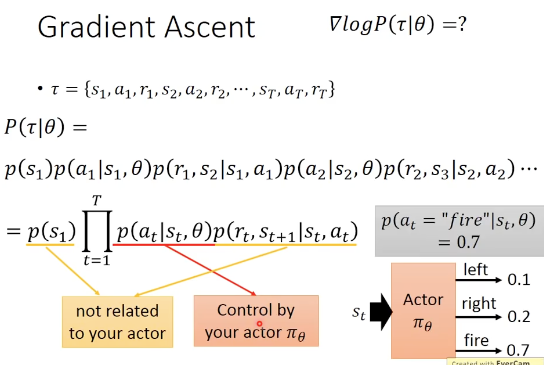
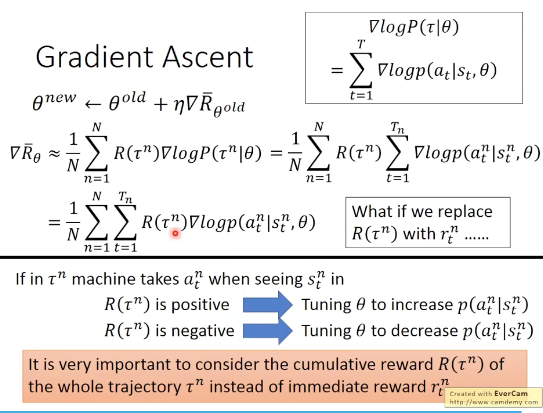
对上面的式子进一步简化,并只保留和梯度相关的部分,得到最终的梯度表达式如下:

注意:1,在计算单个action时乘的R是整个trajectory的,而不是该单个步骤的,为什么?因为如果是单步,那么模型就学不到长期的(最终的reward)。比如需要经过一系列中间状态没有reward的trajectory。
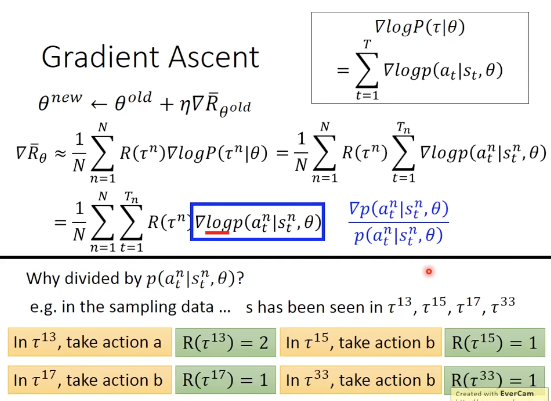
2,为什么取log?为什么分母还要除以一个几率,为了避免频率高的reward差的action造成的影响,相当于做了一个normalization
如果全为正会出现问题:会导致正的reward部分变得平滑,反而选不出更好的决策
解决方案:减去一个baseline(表示为b)的值,使得最后的reward有正有负
最简单的baseline就是的平均值
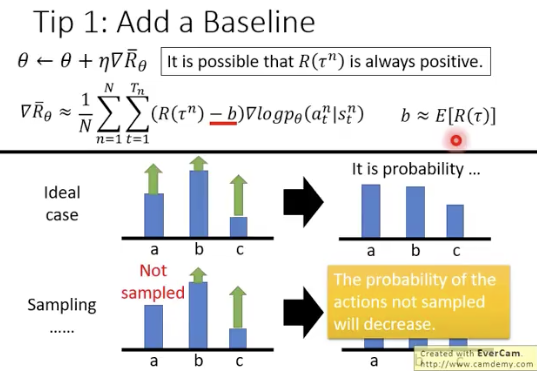
原本的式子中,每个action的weight都是乘以整个轨迹的total reward,这样不合理。
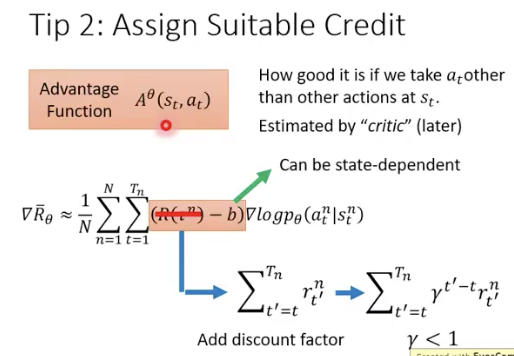
我们希望给每个action都赋值不同的weight,这样才更合理,解决方案时reward只跟执行该action之后的reward,这样就引出了advantage function的概念:因为会减掉baseline,所以得到的是一个相对的值,对应英文advantage
PPO:
on policy和off policy
on policy:
首先一个由参数决定的policy和环境做交互,得到多个轨迹
表示为:,其中p代表“分布的意思”,参数
代表这个分布由参数
决定。这个式子表示:轨迹
服从一个由参数
决定的分布。
当参数更新时,data也要重新收集
Off-policy:
同一笔data 反复用多次,希望用另外一套polciy 来训练参数
,而
‘是固定的。用
得到的data可以用很多次。

Importance sampling:
假设有一个function ,f(x)。假设要从p分布中sample 出x,然后带到f(x)中,算出其期望。
假设只能从另外一个q分布中sample 出x
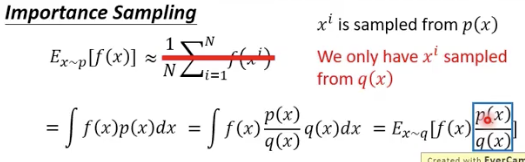
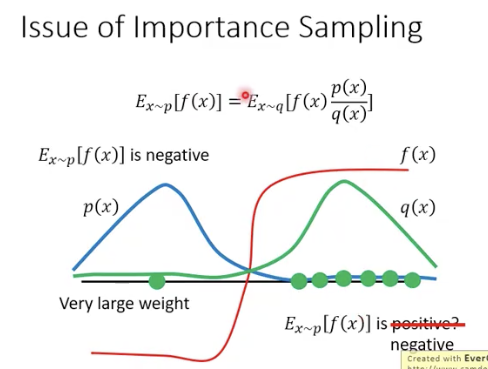
可以把p换成q,但是p和q的差距不能太大,如果sample次数不过,难么结果差距就会非常大

用一个来sample出
,作为示范。然后用Importance sampling的思想,补上一个权重,就可以变成从固定的
中采样

这样的话,就可以利用来sample出
,然后可以对
来update多次
是advantage function,是用来估计
时刻采取
时的累积reward并减去baseline的值(也叫advantage),衡量了这一步选择action的好坏程度

log被消掉了
PPO和TRPO的区别:

TRPO会把KL散度单独作为一个constraint

clip函数clip(x,0.8,1.2)
其中clip函数部分的作用是蓝色虚线
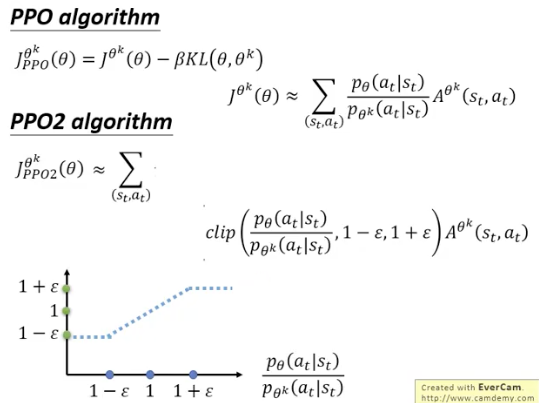
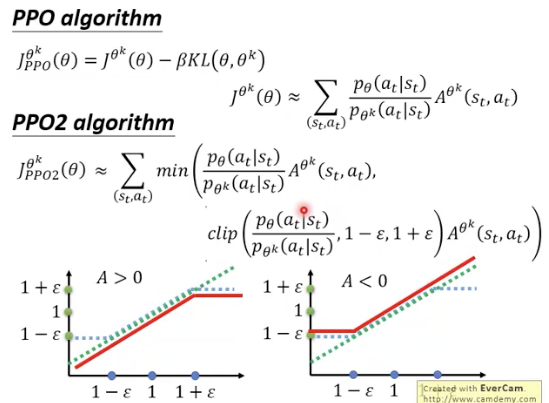
如果A>0,则这个值越大越好,但是不能够太大,不能超过,如果A过大,就不再增加A
A<0,则这个值越大越好,但是不能够太大,不能超过,如果A过大,就不再增加A
这样的目的是为了不让和
相差过大
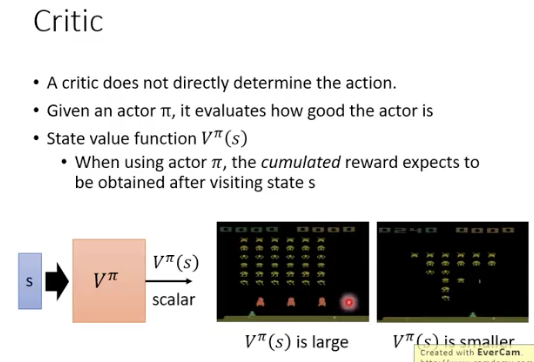
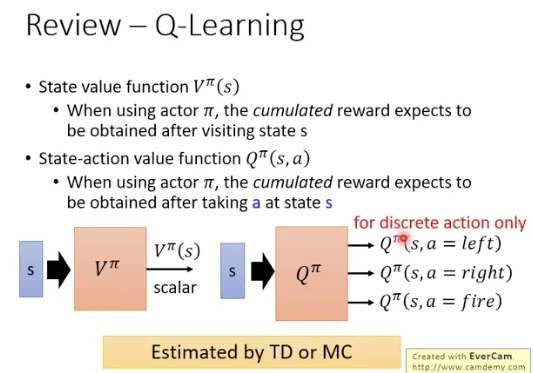
Critics
Critics是用来估计reward的,
其中只估计actor 在某个state s时,能得到的total reward

学习的是critic: 评价某个state未来可能带来的reward效果有多好(看到某个state,对应的cumulated reward的估计值)
V的值取决于state以及actor 的好坏:V和
是有关的,是绑定的,所以是
看到相同的state,不同的actor的V的值是不一样的
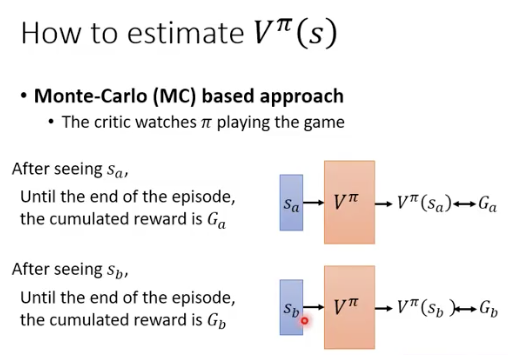
怎么计算V?
实际上是一个network
monte-carlo (MC)based approach
Temporal-difference (TD) approach

Q-learning
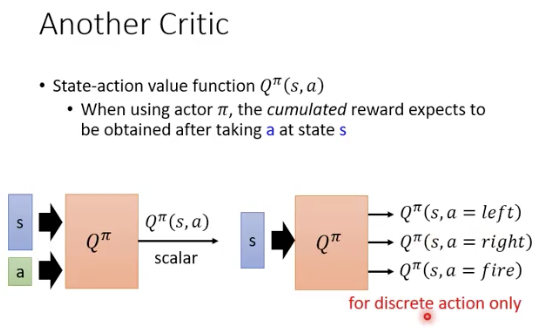
Q-function则是估计actor 在state s做出action a后会得到的total reward,采取的action不同,得到的reward也会不同
Q function:
Qfunction的核心在于,对于一个state,会穷举出当前state能做出的所有action对应的cumulated reward,这样就可以找到最好的action序列
Q function是用来衡量actor的好坏的
可以用Q-function找到一个好的actor
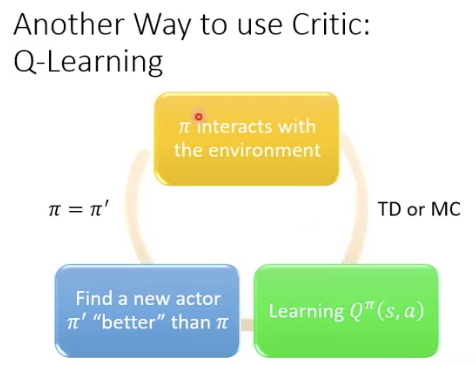
只要找到了一个actor的Q function,那么一定能找到一个更好的actor
假设学习到了一个Q,那么根据这个Q的估计,每次都选取Q最大的action,那么,采取这些action形成的actor‘就是一个更好的actor

证明:
每次都选Q最大的action,那么这样做的actor就是一个更好的actor

Q的训练方法:
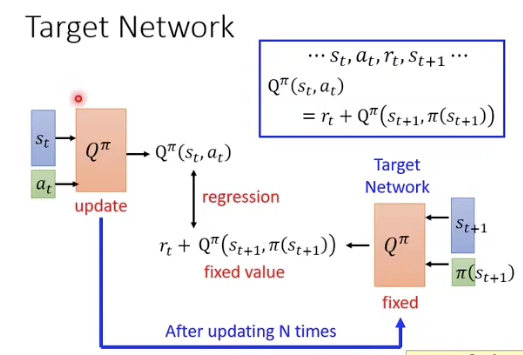

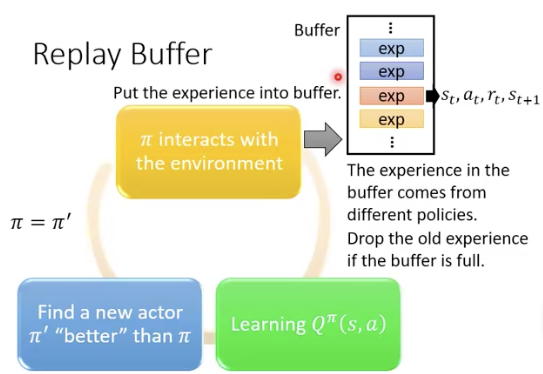
相当于做成了一个off policy的做法
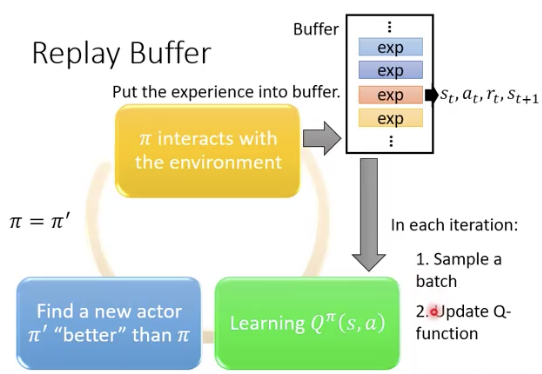
Q-learning的训练过程

Tips of Q-leanring

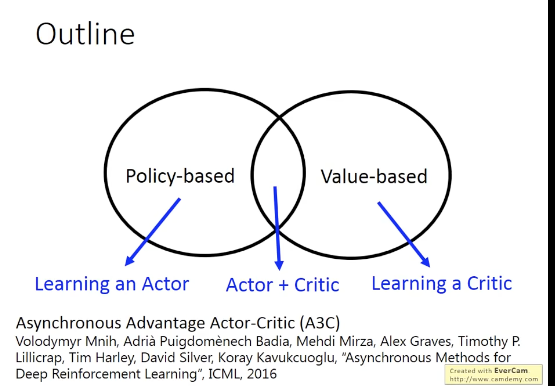
Actor-Critic
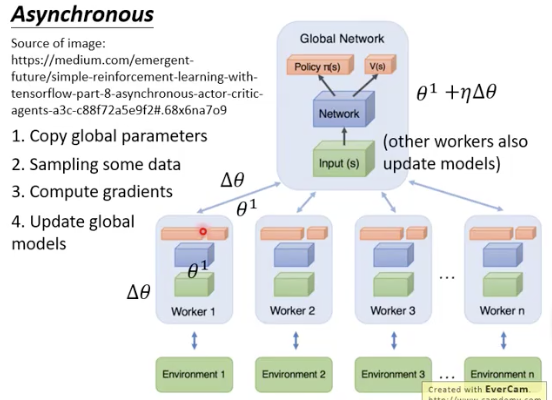
Asynchronous Advantage Actor-Critic (A3C)
用期望来替代sample
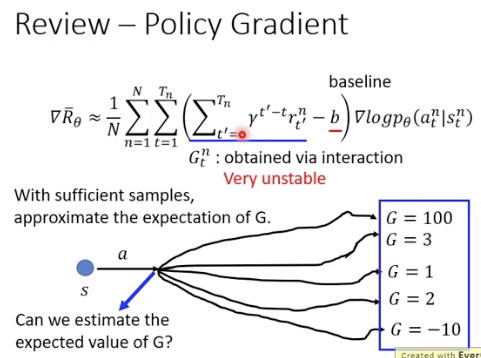


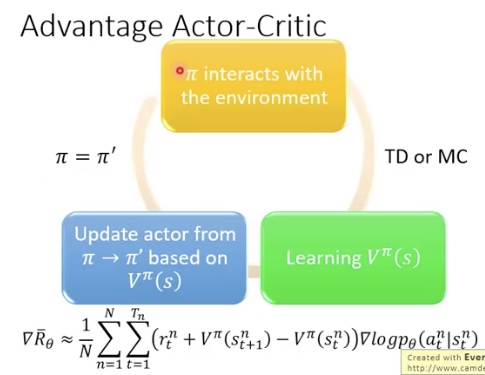
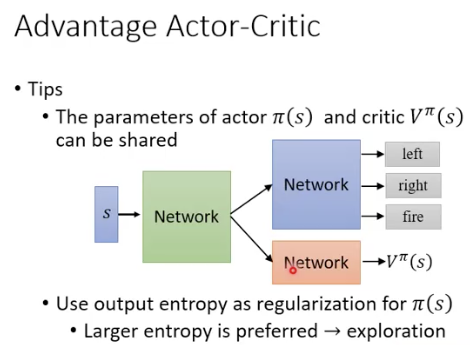
A3C:
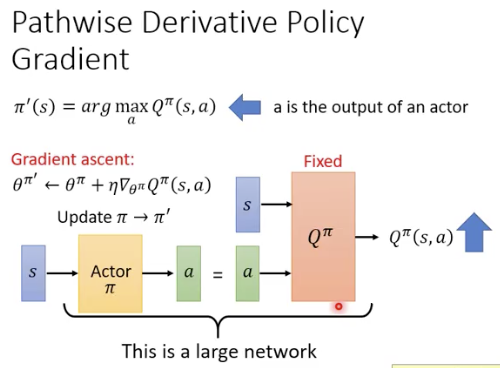
强化学习在LLM中的应用:
参考视频:
https://www.bilibili.com/video/BV1zP92YNEPW?spm_id_from=333.788.videopod.sections&vd_source=132c74f7a893f6ef64b723d9600c40b7![]() https://www.bilibili.com/video/BV1zP92YNEPW?spm_id_from=333.788.videopod.sections&vd_source=132c74f7a893f6ef64b723d9600c40b7
https://www.bilibili.com/video/BV1zP92YNEPW?spm_id_from=333.788.videopod.sections&vd_source=132c74f7a893f6ef64b723d9600c40b7
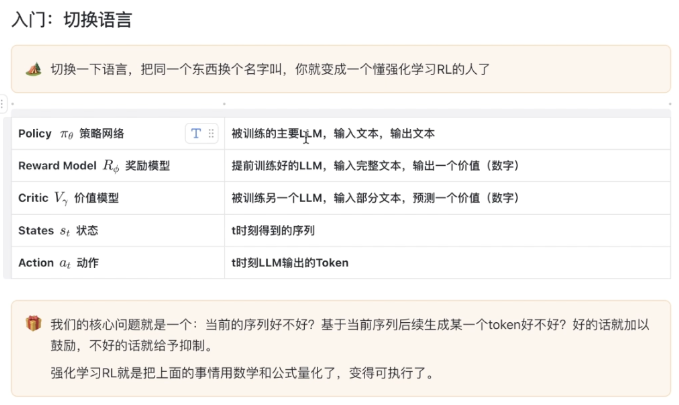
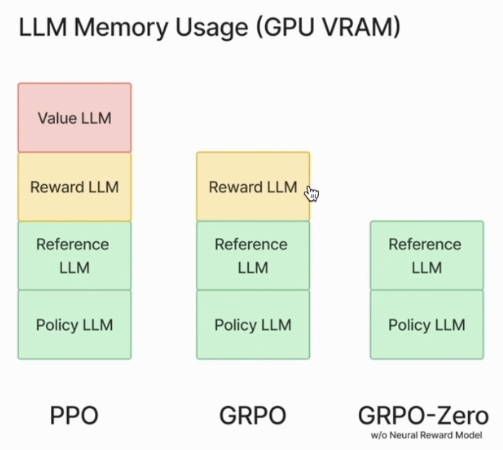
要训练的LLM就叫policy,用于预测action (next token)

reward model 输出的是一个分数(value)

GRPO
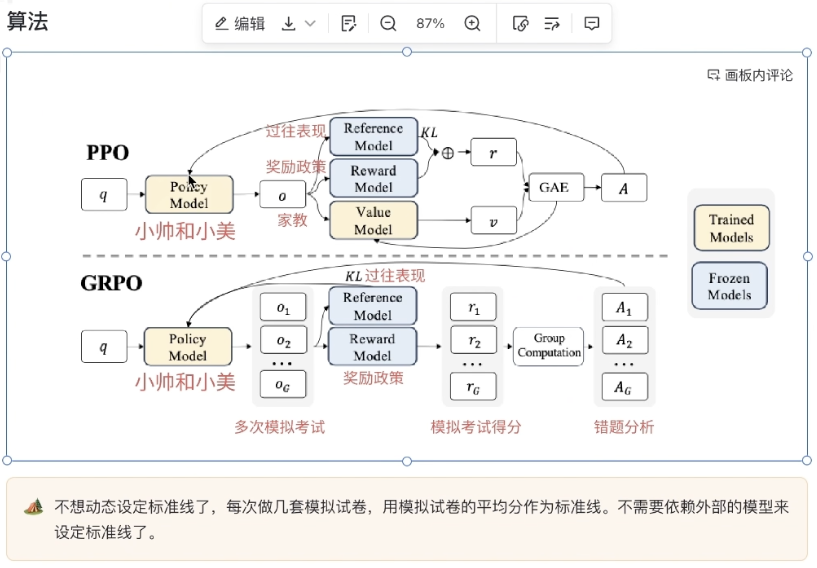

GRPO可视化理解:
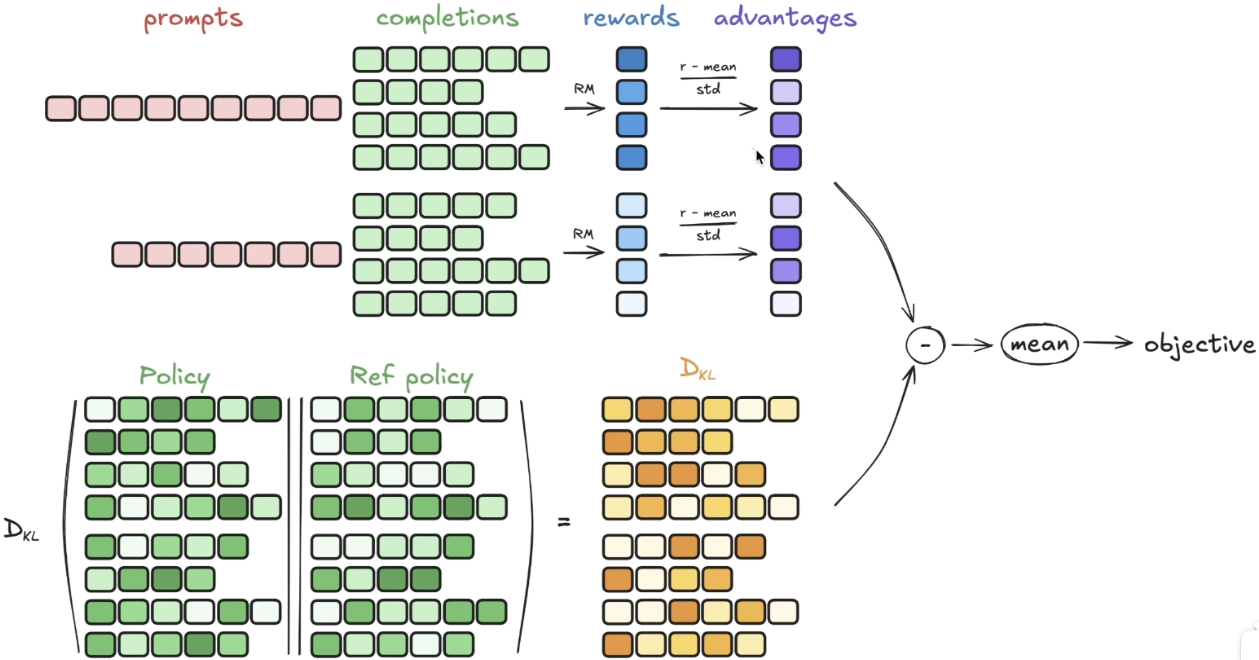
reward model 可以是一个简单的函数,比如字数限制,是否要出现think token