LangChain RAG 完整流程实战解析
目录
- 前言
- 1. RAG 的核心流程概述
- 2. 实战代码:从文件到回答
- 3. 阶段解析
- 3.1 加载文档(Document Loading)
- 3.2 文本切分(Text Splitting)
- 3.3 向量化与索引(Vectorization & Indexing)
- 3.4 检索相关内容(Retrieval)
- 3.5 生成回答(Generation)
- 4. LangChain RAG 流程示意图
- 5. 总结:RAG 的价值与应用场景
- 6. 参考资料
前言
在大语言模型(LLM)应用中,一个常见的问题是:模型虽然强大,但它的知识止步于训练数据。如果我们想让模型回答某份文件、公司资料或特定领域的知识,就需要一种机制——让模型先“查资料”,再作答。
这正是 RAG(Retrieval-Augmented Generation,检索增强生成) 的核心思想。
RAG 技术通过在生成阶段引入检索模块,让模型在回答之前访问外部文档,从而实现“带知识”的智能问答。
本文将结合一段完整的 LangChain 实战代码,一步步解析 RAG 的构建过程。
1. RAG 的核心流程概述
RAG 可以分为四个主要阶段:
| 阶段 | 功能描述 | 在程序中的对应组件 |
|---|---|---|
| 1. 数据准备 | 加载原始文本文件或资料 | TextLoader |
| 2. 文本切分 | 将文档分成更小的语义块 | CharacterTextSplitter |
| 3. 向量化与索引 | 将文本转为语义向量并存储 | OpenAIEmbeddings + FAISS |
| 4. 检索与生成 | 基于用户问题检索并生成回答 | retriever + ChatOpenAI |
LangChain 将这些步骤封装成可组合的模块,让我们能快速构建端到端的智能问答系统。
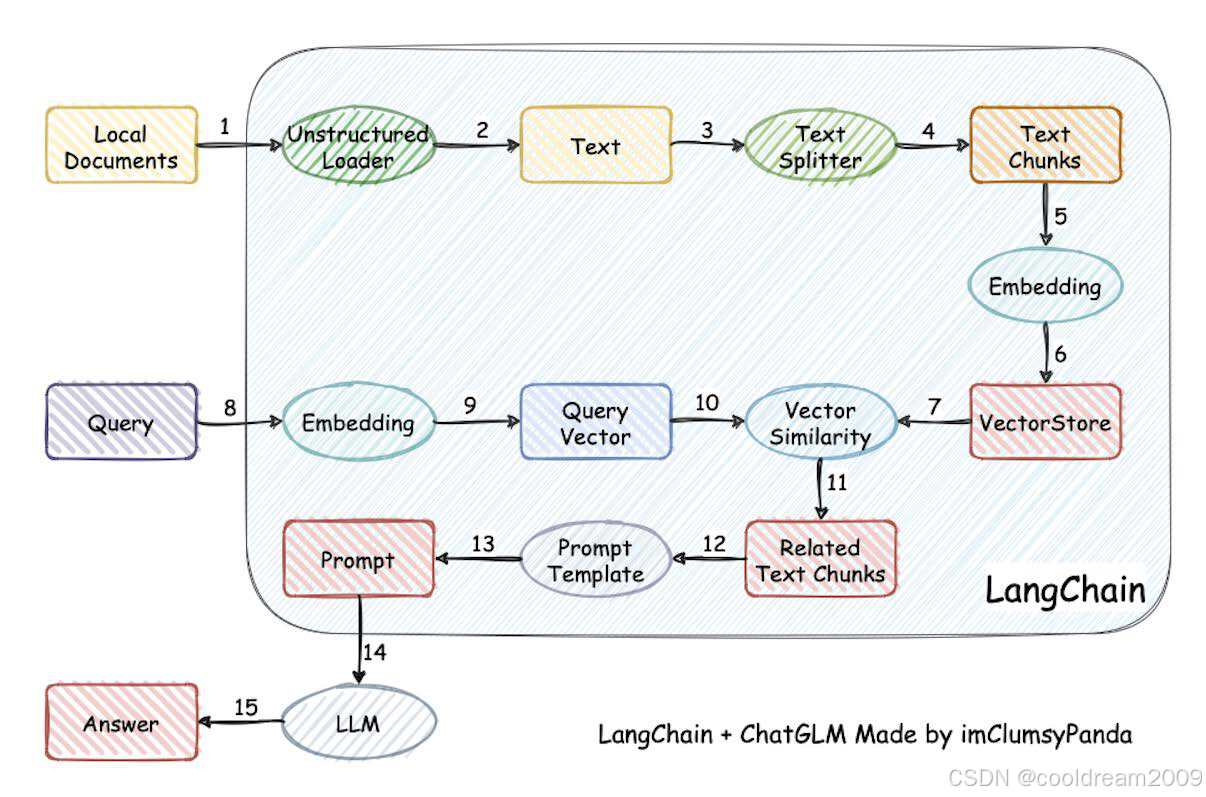
2. 实战代码:从文件到回答
下面的示例程序完整演示了一个基于 LangChain + OpenAI + FAISS 的 RAG 流程。
1. 导入所有需要的包
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
import os
import dotenvdotenv.load_dotenv()2. 自定义提示词模板
prompt_template = """请使用以下提供的文本内容来回答问题。
仅使用提供的文本信息,如果文本中没有相关信息,请回答"抱歉,提供的文本中没有这个信息"。
文本内容:
{context}
问题:{question}
回答:
"
"""
prompt = PromptTemplate.from_template(prompt_template)3. 初始化模型
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")4. 加载文档
loader = TextLoader("./test_doc.txt", encoding='utf-8')
documents = loader.load()5. 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
texts = text_splitter.split_documents(documents)6. 创建向量数据库
vectorstore = FAISS.from_documents(documents=texts, embedding=embedding_model)7. 获取检索器
retriever = vectorstore.as_retriever()
docs = retriever.invoke("长江流域有哪些著名的城市?")8. 构建 RAG 链
chain = prompt | llm9. 提问与回答
result = chain.invoke(input={"question": "长江流域有哪些著名的城市?","context": docs
})
print("\n回答:", result.content)
3. 阶段解析
3.1 加载文档(Document Loading)
loader = TextLoader("./test_doc.txt", encoding='utf-8')
documents = loader.load()
LangChain 提供了统一的 Document 加载接口,无论是 TXT、PDF、CSV 还是网页内容,都可以通过不同的 Loader 读取成 Document 对象:
[Document(page_content="文档内容...", metadata={'source': './test_doc.txt'})
]
这一步是构建知识源的起点。
3.2 文本切分(Text Splitting)
text_splitter = CharacterTextSplitter(chunk_size=1000,chunk_overlap=100,
)
texts = text_splitter.split_documents(documents)
由于 LLM 的上下文长度有限,我们不能直接把整份文档喂给模型。
CharacterTextSplitter 将长文本分为若干个小块:
- chunk_size=1000:每个片段最大 1000 字符;
- chunk_overlap=100:片段之间保留 100 字符的重叠,确保语义连续。
结果是一组可独立使用的语义单元,供后续的向量化阶段使用。
3.3 向量化与索引(Vectorization & Indexing)
embedding_model = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = FAISS.from_documents(documents=texts, embedding=embedding_model)
每个文本片段会被转换为一个 语义向量(embedding),即在高维空间中的数值表示。
模型 text-embedding-3-large 可以将语义相近的文本映射到相近的向量空间中。
然后,我们将这些向量存储在 FAISS(Facebook AI Similarity Search) 向量数据库中,以便后续高效检索。
例如:
文本片段: "长江流域包括武汉、南京、上海等城市"
向量表示: [0.12, -0.45, 0.78, ...]
3.4 检索相关内容(Retrieval)
retriever = vectorstore.as_retriever()
docs = retriever.invoke("长江流域有哪些著名的城市?")
当用户提出问题时,LangChain 会:
- 将问题向量化;
- 在 FAISS 向量数据库中查找最相似的文本;
- 返回若干相关片段作为“上下文”。
RAG 的检索部分就完成了。接下来模型会基于这些文本作答。
3.5 生成回答(Generation)
prompt_template = """请使用以下提供的文本内容来回答问题...
"""
chain = prompt | llm
result = chain.invoke({"question": "长江流域有哪些著名的城市?","context": docs
})
这里用 PromptTemplate 定义了严格的回答格式,确保模型只引用提供的文档信息。
chain = prompt | llm 表示将两个模块串联成 可执行链(Runnable Chain),
输入的 question 与 context 会自动填入模板中,然后交由模型生成最终答案。
最终输出的结果是:
回答: 根据提供的文本,长江流域的著名城市包括武汉、南京、重庆和上海等。
4. LangChain RAG 流程示意图
┌────────────────────┐│ 原始文档 (txt/pdf) │└────────┬───────────┘│┌────────▼───────────┐│ 文本切分 (chunks) │└────────┬───────────┘│┌────────▼───────────┐│ 向量化 (embedding) │└────────┬───────────┘│┌────────▼───────────┐│ 向量数据库 (FAISS) │└────────┬───────────┘│用户提问 ─────►│ 相似度检索 (Retriever) │└────────┬───────────┘│┌─────────────────▼──────────────────┐│ LLM 生成回答 (Prompt + ChatOpenAI) │└────────────────────────────────────┘
5. 总结:RAG 的价值与应用场景
通过本示例可以看到,LangChain 的 RAG 体系让我们能够快速构建基于知识库的问答系统。
它的核心优势包括:
- ✅ 知识可控:回答仅来源于提供的文档;
- ✅ 减少幻觉:避免模型胡编乱造;
- ✅ 便于扩展:新增文档无需重新训练;
- ✅ 多场景适用:企业文档问答、学术知识库、产品说明书智能客服等。
RAG 是连接 LLM 通用能力 与 领域知识专属能力 的关键技术。
6. 参考资料
1 LangChain 官方文档 - Question Answering
2 OpenAI Embeddings 官方指南
3 FAISS 向量数据库官方文档
4 LangChain Expression Language (LCEL)