排序算法
排序的概念及其运用
排序的概念
常见的排序算法
// 排序实现的接口
// 插入排序
void InsertSort(int* a, int n);
// 希尔排序
void ShellSort(int* a, int n);
// 选择排序
void SelectSort(int* a, int n);
// 堆排序
void AdjustDwon(int* a, int n, int root);
void HeapSort(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n)
// 快速排序递归实现
// 快速排序hoare版本
int PartSort1(int* a, int left, int right);
// 快速排序挖坑法
int PartSort2(int* a, int left, int right);
// 快速排序前后指针法
int PartSort3(int* a, int left, int right);
void QuickSort(int* a, int left, int right);
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
// 归并排序递归实现
void MergeSort(int* a, int n)
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
// 计数排序
void CountSort(int* a, int n)常见排序算法的实现
1 插入排序

//升序
void insertsort(int* a, int n)
{for (int i = 1; i < n; i++){int end=i-1;int tmp=a[i];//将tmp插入到[0,end]区间中,保持有序while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];--end;}else{break;}}a[end + 1] = tmp;}}2、希尔排序( 缩小增量排序 )
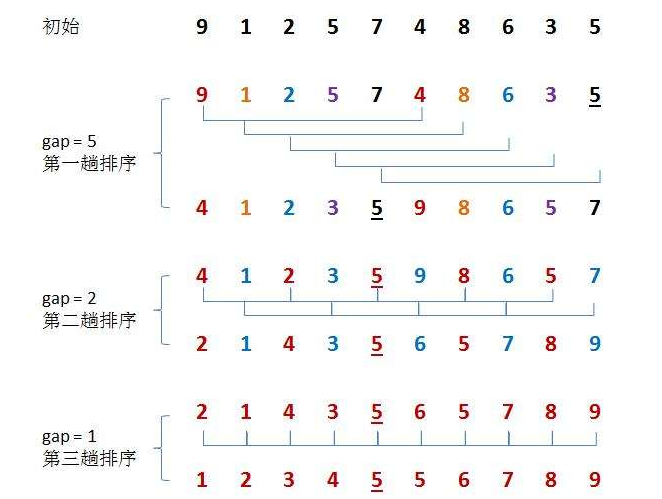
void ShellSort(int* a, int n)
{int gap;for (gap = n / 2; gap > 0; gap /= 2){for (int i = gap; i < n; i++){int tmp = a[i];int end = i - gap;while (end >= 0){if (a[end] > tmp){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}
3、 选择排序
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}
void SelectSort(int* a, int n)
{int left = 0;int right = n - 1;while (left < right){int mini;int maxi;mini = maxi = left;for (int i = left + 1; i <= right; i++){if (a[i] < a[mini]){mini = i;}if (a[i] > a[maxi]){maxi = i;}}Swap(&a[left], &a[mini]);if (left == maxi){maxi = mini;}Swap(&a[right], &a[maxi]);++left;--right;}
}注意,当left和maxi相等时,在交换left和mini后,left下标的数据和mini下标的数据发生交换,此时我们要添加判断,将mini的下标赋值给maxi。但这种优化毕竟是有限的。
4、堆排序
堆排序也是选择排序的一种,但是其时间复杂度相较于直接选择排序优秀很多,为N*logN。注意,在建堆时,我们使用向下调整算法时时间复杂度为N,而使用向上调整算法时间复杂度为N*logN。所以我们使用向下调整算法建堆。
我们来讲一下向上调整算法和向下调整算法的使用场景:
向上调整算法:
在数据结构中,向上调整算法(也称为 “上浮操作”)是维护堆(Heap)结构的另一种核心操作,与向下调整算法对应。它的作用是当堆中某个节点的值不符合堆的性质(大根堆或小根堆)时,通过将该节点 “向上调整”,使整个堆重新满足堆的特性。
核心场景
当堆中新增元素(通常添加到堆的末尾)后,新元素可能破坏堆的性质,此时需要通过向上调整将其 “上浮” 到合适的位置,恢复堆的结构。
算法思想
以大根堆为例(父节点值 ≥ 子节点值),向上调整的步骤如下:
- 从当前节点(通常是新增的尾节点)开始,比较其与父节点的值。
- 如果当前节点的值 大于 父节点的值,则交换两者的位置。
- 交换后,以被交换的父节点为新的当前节点,重复步骤 1-2,直到当前节点的值 ≤ 父节点的值,或当前节点已是根节点(无父节点)。
对于小根堆,逻辑类似,只需比较 “当前节点是否小于父节点”,若满足则交换,直到当前节点的值 ≥ 父节点的值或成为根节点。
示例(大根堆)
假设大根堆的数组表示为 [7, 5, 6, 2, 3](满足大根堆性质),新增元素 8 后数组变为 [7, 5, 6, 2, 3, 8](新元素在索引 5,破坏堆性质),调整过程如下:
- 当前节点为索引 5(值 8),父节点索引为
(5-1)//2 = 2(值 6)。 - 8 > 6,交换索引 5 和 2,数组变为
[7, 5, 8, 2, 3, 6]。 - 新当前节点为索引 2(值 8),父节点索引为
(2-1)//2 = 0(值 7)。 - 8 > 7,交换索引 2 和 0,数组变为
[8, 5, 7, 2, 3, 6]。 - 新当前节点为索引 0(根节点),调整结束。最终堆满足大根堆性质。
向下调整算法:
在数据结构中,向下调整算法(也称为 “下沉操作”)是维护堆(Heap)结构的核心操作之一。它的作用是当堆中某个节点的值不符合堆的性质(大根堆或小根堆)时,通过将该节点 “向下调整”,使整个堆重新满足堆的特性。
核心场景
当堆的根节点被替换(例如堆顶元素被移除,用最后一个元素填充根节点)后,新的根节点可能破坏堆的性质,此时需要通过向下调整将其 “下沉” 到合适的位置,恢复堆的结构。
算法思想
以大根堆为例(父节点值 ≥ 子节点值),向下调整的步骤如下:
- 从当前节点(通常是根节点)开始,比较其与左右子节点的值。
- 找出左右子节点中值最大的节点(称为 “较大子节点”)。
- 如果当前节点的值 小于 较大子节点的值,则交换两者的位置。
- 交换后,以被交换的子节点为新的当前节点,重复步骤 1-3,直到当前节点的值 ≥ 所有子节点的值,或当前节点是叶子节点(无子女)。
对于小根堆,逻辑类似,只需将 “找较大子节点” 改为 “找较小子节点”,并比较 “当前节点是否大于较小子节点”。
示例(大根堆)
假设大根堆的数组表示为:[2, 7, 6, 5, 3](根节点为 2,不符合大根堆性质),调整过程如下:
- 当前节点为索引 0(值 2),左子节点索引 1(值 7),右子节点索引 2(值 6)。较大子节点为 7(索引 1)。
- 2 < 7,交换索引 0 和 1,数组变为
[7, 2, 6, 5, 3]。 - 新当前节点为索引 1(值 2),左子节点索引 3(值 5),右子节点索引 4(值 3)。较大子节点为 5(索引 3)。
- 2 < 5,交换索引 1 和 3,数组变为
[7, 5, 6, 2, 3]。 - 新当前节点为索引 3(值 2),无子女(叶子节点),调整结束。最终堆为
[7, 5, 6, 2, 3],满足大根堆性质。
for (int i = (n-2)/2; i >0; i--)
{AdjustDown(a,n, i);//建大根堆
}那么,如果我们排升序建大堆还是小堆,答案是大堆。首先我们明确我们要排升序,我们需要把数据从小到大全部找出来,如果我们建的是小根堆,根节点是最小的,但是,我们如果把根节点删除,那么其余节点父子关系全乱了,我们需要重新建堆,比较繁琐,并且,我们需要额外空间存储这个最小值,比较麻烦。建大根堆,根节点为最大值,我们将根节点与最后节点交换一下,再使用向下调整算法,就可以得到次大数,再与倒数第二个节点交换,以此类推...
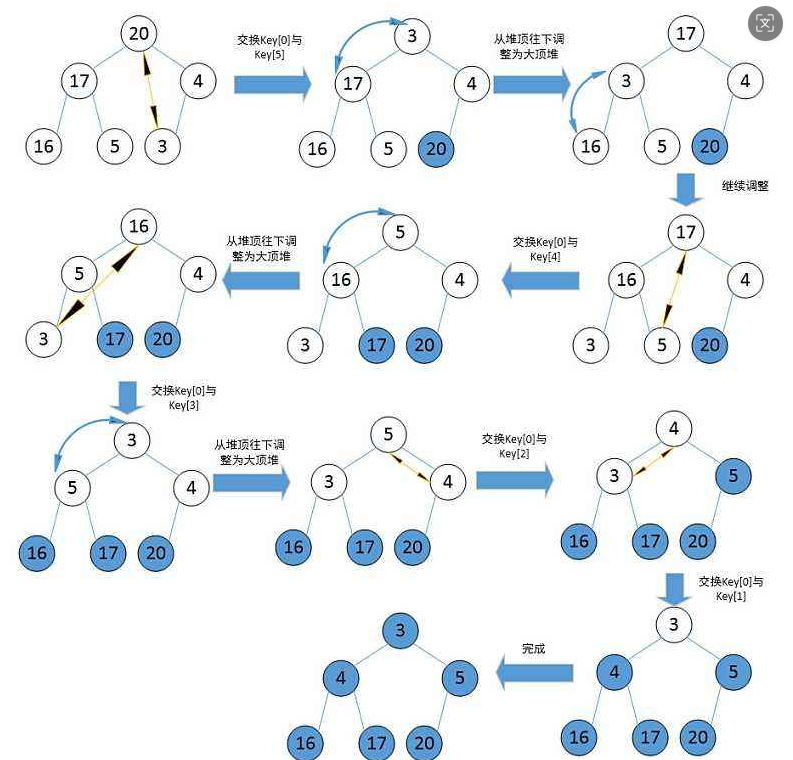
具体代码:
//升序要建大根堆
void AdjustDown(int* a, int parent, int n)
{int child = parent * 2 + 1;while (child<n){if (child + 1 < n && a[child + 1] > a[child]){child++;}if (a[parent] < a[child]){Swap(&a[parent], &a[child]);parent = child;child = child * 2 + 1;}else{break;}}
}
void HeapSort(int* a, int n)
{for (int i = (n - 2) / 2; i >= 0; i--){AdjustDown(a, i, n);}int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, 0, end);end--;}
}5、冒泡排序
冒泡排序是最为简单的排序算法了,但是效率也很低,时间复杂度为O(N*2),思想也比较简单,数组元素两两比较,便能找出最大值放到数组最后,接着比较前n-1个元素,在此不做赘述。
void BubbleSort(int* a, int n)
{for (int j = n; j > 0; --j){int i = 0;int flag = 0;while (i + 1 < j){if (a[i + 1] < a[i]){Swap(&a[i], &a[i + 1]);flag = 1;}i++;}if (flag == 0){break; // 本趟无交换,说明数组已有序,提前退出}}
}6、快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
版本一:Hoare版本快速排序:
首先,我们可以选定基准值,通常为最左边元素或者最右边的元素。如果选择最左边元素为基准值,那么右边就要先走;如果右边为基准值,那么左边就要先走。
接着,以升序为例,右边定义一个right指针,同时左边定义一个left指针。right指针往左走,遇到比基准值小的数字,则与left指针的数字交换一下。同时,左边指针往右走,找到比基准值大的数字则与right交换一下。最后,左右指针相遇,将相遇的地方的下标的数字与基准值交换一下,那么,基准值左边的数字就一定比基准值小,右边的数字一定比基准值大。那么基准值就到了它应该在的位置。接下来就递归基准值左边区间,基准值右边区间,直到区间只有一个元素(类似二叉树)。
以下是代码:
void QuickSort1(int* a, int left,int right)
{if (left >= right){return;}int begin = left;int end = right;//随机选key/*int randomi = left + rand() % (right - left);Swap(&a[left], &a[randomi]);*/int midi = GetMiddleNumi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;while (left < right){while (left<right && a[right]>=a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);keyi = left;//递归QuickSort1(a, begin, keyi - 1);QuickSort1(a, keyi + 1, end);
}在代码书写过程中也有注意事项:首先,while (left<right && a[right]>=a[keyi]),有很多人没有写left<right这一条件,以为上面写了下面就可以不写,这是错误的。如果基准值是数组中最小的数字,那么right指针便会一直向左移动直至跑到left左边,这是不被允许的。还有,就是while循环中a[right],a[left]与a[keyi]的比较问题,如果相等交换其实没任何区别,因为交换后数字不变。但是不能在while循环前先left++,可能会导致问题。
版本二:挖坑法:
挖坑法相较于hoare版本的快速排序相对简单一些。首先将基准值存到一个临时key中,然后那个基准值可以看作一个没有数据的坑位。接下来right指针先走,遇到比基准值key小的数据,则放到原先那个坑里,right指针位置形成新的坑位,接着left指针走,遇到比基准值大的数,则与坑位交换,以此类推,直到left与right相遇,key放在那个位置。
首先将
void QuickSort2(int* a, int left, int right)
{if (left >= right){return;}int begin = left;int end = right;//随机选key/*int randomi = left + rand() % (right - left);Swap(&a[left], &a[randomi]);*/int midi = GetMiddleNumi(a, left, right);Swap(&a[left], &a[midi]);int key = a[left];int hole = left;while (left < right){while (left < right && a[right] >= key){right--;}a[hole] = a[right];hole = right;while (left < right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;hole = left;//递归QuickSort2(a, begin, hole - 1);QuickSort2(a, hole + 1, end);
}版本三:前后指针法:
前后指针法是一个形象的说法,我们定义两个指针一个prev一个cur。

逻辑相对于前两种方法比较简单
1、cur找到比key小的值,++prev,cur和prev位置的值交换,++cur
2、cur找到比key大的值,++cur
说明:
1、prev要么紧紧跟着cur(prev下一个就是cur)
2、prev跟cur中间隔着比key大的一段值区间
代码:
说明:第一个函数是单趟排序,第二个函数是整体。
//前后指针法
int PartSort3(int* a, int left, int right)
{int midi=GetMiddleNumi(a, left, right);if (midi != left){Swap(&a[left], &a[midi]);}int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur){Swap(&a[prev], &a[cur]);}++cur;}Swap(&a[prev], &a[keyi]);keyi = prev;return keyi;
}
void QuickSort3(int* a, int left, int right)
{if (left > right){return;}//小区间优化--小区间直接使用插入排序if ((right - left + 1) > 10){int keyi = PartSort3(a, left, right);QuickSort3(a, left, keyi - 1);QuickSort3(a, keyi + 1, right);}else{InsertSort(a, right - left + 1);}
}随机选数以及三数取中
在上述代码中,getmiddlenumi就是三数取中代码,还有一个随机选数。
随机选数:
int randomi = left + rand() % (right - left);Swap(&a[left], &a[randomi]);*/三数取中:
//三数取中,因为顺序或者逆序时间复杂度都很大
int GetMiddleNumi(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[left] < a[mid]){if (a[mid] < a[right]){return mid;}else if (a[left] > a[right]){return left;}else{return right;}}else//a[left] > a[mid]{if (a[mid] > a[right]){return mid;}else if (a[left] < a[right]){return left;}else{return right;}}}这两者的作用都是防止原数组为顺序数组或者逆序数组。当原数组为顺序数组时,那么key选最左边或最右边时,选的基准值为原数组中最大或者最小的,那么必然有一个指针会遍历原数组,为最坏情况,所以为了避免这种情况,我们不得不选择数组中间某个数字,来避免这种情况发生。随机选数也有一定概率选到最左边或者最右边的数字,但这种情况必然比较少见,如果还是不放心,我们可以采取三数取中,比较最左边、最右边以及中间位置的数字,选择第二大的数字与基准值位置的数字做交换,那么基准值必定不是数组中最大值或者最小值,快速排序的效率也就得到了提升。
插入排序做优化
大家一定很好奇,为什么我第三个快速排序最后没有用递归,而是用了插入排序。
其实递归也有坏处:递归层次太深可能会导致栈溢出,所以当区间比较小时,我们可以直接使用插入排序。所以我在前后指针法中最后使用插入排序。
将递归改成循环写法
上面已经分析了,用递归法,递归层次太深,可能会导致递归层次太深,导致栈溢出,所以,在此给出一种循环的方法写快速排序,在此我们要用到栈这种数据结构。
void QuickSortNoR(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, right);STPush(&st, left);while (!STEmpty(&st)){int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);int keyi=PartSort3(a, begin, end);if (keyi + 1 < end){STPush(&st, end);STPush(&st, keyi + 1);}if (begin < keyi - 1){STPush(&st, keyi - 1);STPush(&st, begin);}}STDestory(&st);
}因为栈是先入后出,所以我们在压栈的时候要先将right压入栈内,再将left压入栈内,这样出栈就是left先出了。
再看while循环内,判断条件自然是栈不为空。我们先对整个区间进行单趟排序,排序完自然而然得到基准值左边区间,基准值以及基准值右边区间,接着对左区间和右区间进行相同操作,那么就写好了。
7、归并排序
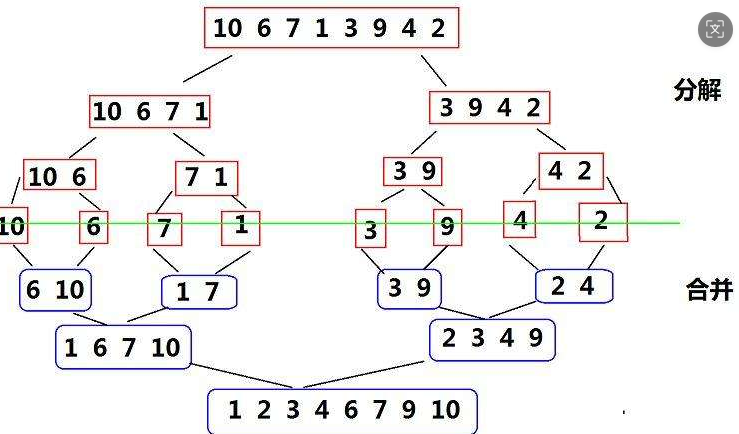
if (left == right)
{return;
}
int mid =left+(right - left) / 2;
_MergeSort(a, left, mid,tmp);
_MergeSort(a, mid + 1, right, tmp);这就是分解的过程。
这是简单的图例,与上图一一对应起来了。
接下来就是归并的过程了。
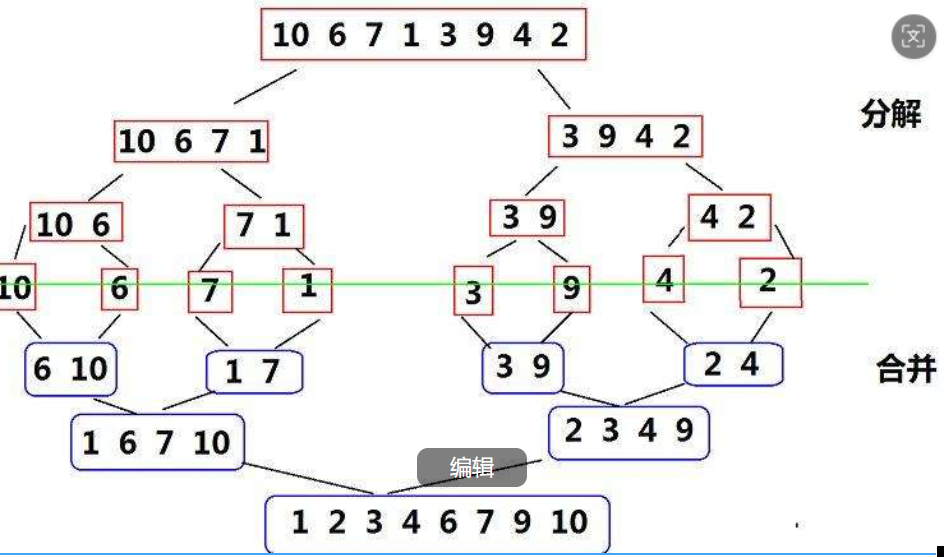
从第一步合并开始,我们不难看出,每一次合并都是两个有序数组比较大小的过程,这时,我们可以创建一个临时数组tmp,将两个数组排完序后放到那个临时数组,再将临时数组的值拷贝回原数组,那么,我们就合并完成一次,接着继续合并,直至原数组有序。
//归并
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}
}
while (begin1 <= end1)
{tmp[i++] = a[begin1];++begin1;
}while (begin2 <= end2)
{tmp[i++] = a[begin2];++begin2;
}memcpy(a + left, tmp + left, sizeof(int) * (i - left));当左右数组都存在时,我们就比较第一个元素谁小,小的放入临时数组中,再++第一个元素,同时tmp数组++,这样我们就能在左右数组都存在时,将元素排成升序。
但是,因为元数组不一定是偶数,所以分解的时候可能不一定均分,导致左右区间可能元素个数不一样,所以可能会出现有一个数组元素已经全部排完,另一个没有,此时,很好办
while (begin1 <= end1)
{tmp[i++] = a[begin1];++begin1;
}while (begin2 <= end2)
{tmp[i++] = a[begin2];++begin2;
}如果区间1没排完,进入循环1,不会进入循环2;同理,如果区间2没排完,进入循环2,不会进入循环1。最后tmp数组里就存放两个数组归并后的结果,再将其拷贝回原数组。注意,最后拷贝起始位置不一定是数组第一个元素,如上图3 9两个元素就不是原数组第一个元素开始,所以我们需要a+left位置开始拷贝。
以下是归并排序的全部代码:
void _MergeSort(int* a,int left, int right,int* tmp)
{if (left == right){return;}int mid =left+(right - left) / 2;_MergeSort(a, left, mid,tmp);_MergeSort(a, mid + 1, right, tmp);//归并int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int i = left;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1];++begin1;}while (begin2 <= end2){tmp[i++] = a[begin2];++begin2;}memcpy(a + left, tmp + left, sizeof(int) * (i - left));
}
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);_MergeSort(a, 0, n - 1, tmp);free(tmp);
}_MergeSort事实上是实现逻辑,MergeSort的作用是创建一个临时数组并调用_MergeSort。
非递归写法
与快速排序一样,归并排序也有非递归写法。但与归并排序递归写法不一样的是,非递归写法事实上是模拟合并的过程。我们定义一个gap,一开始令gap=1。
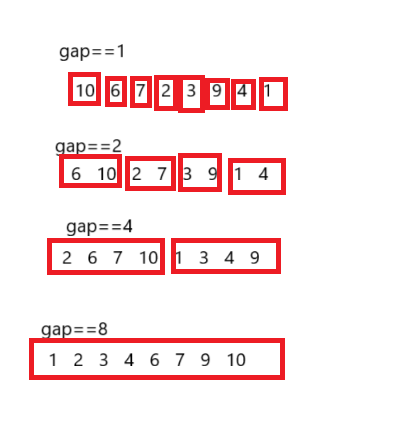
大致就是这个样子,核心依旧是两个数组归并成一个大数组放入临时数组中,最后拷贝回去。
而gap每次归并结束都要乘以2,直到gap>数组元素n的时候循环结束。

此时定义一个i=left,即数组第一个元素,则begin1=i,end1=i+gap-1;begin2=i+gap,end2=i+2*gap-1。这样我们就可以归并第一第二组数组了,接下来如果要比较第三第四组,那么我们直接i+=2*gap使得i指向第三组第一个元素就行。
int gap = 1;
while (gap < n)
{for (int i = 0; i < n; i +=2*gap ){int j = i;int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;nd1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}我们使用for循环就可以做到。
但是,我们的数组不一定是偶数,所以可能会出现一些情况。
同时,将begin1数组和begin2数组拷贝到临时数组也有两中方式,可以等归并完所有数组再一次性拷贝回a数组,也可以走一次for循环拷贝一次,我们这里先展示一次性拷贝完的写法。
我在下面做个示范
一次性拷贝和多次拷贝的区别示范:
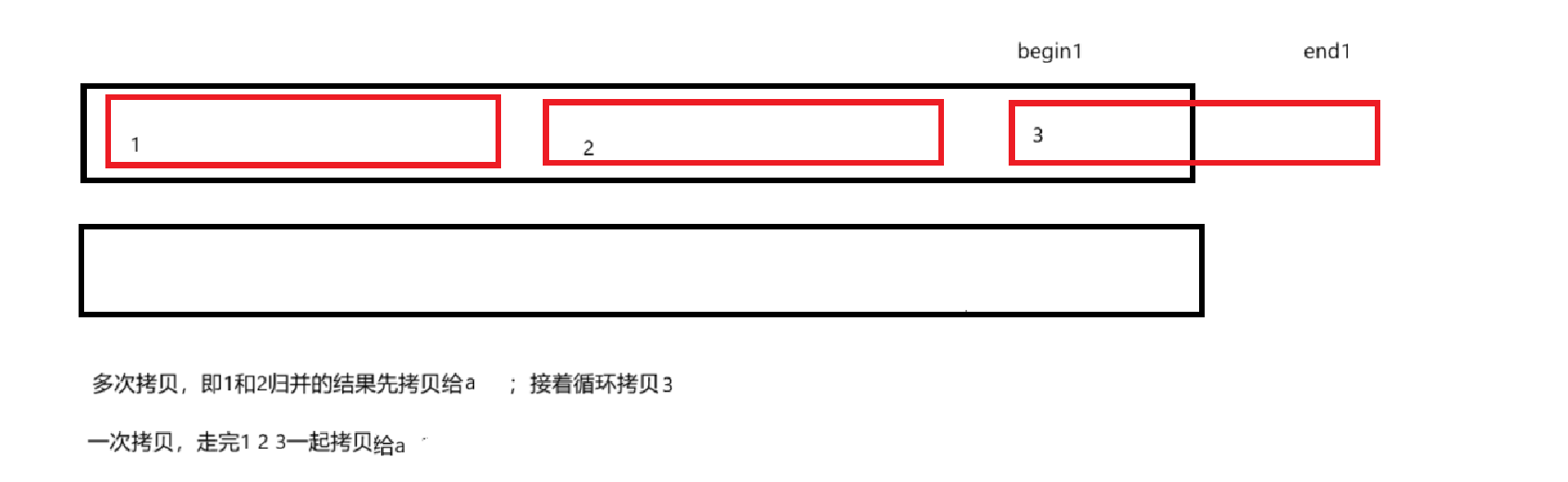
1、首先我们已经在for循环中定义了begin1=i<n,所以begin1不可能越界。
2、end1如果越界:
此时我们将end1定义为n-1即可,同时定义begin2=n,end2=n-1,那么第二组数就不会进入归并了。
3、如果begin2越界

定义begin2=n,end2=n-1,同样不会进入归并。
4、如果end2越界

定义end2=n-1即可。
if (end1 >= n)
{end1 = n - 1;begin2 = n;end2 = n - 1;
}
else if (begin2 >= n)
{begin2 = n;end2 = n - 1;
}
else if (end2 >= n)
{end2 = n - 1;
}最后走出for循环,说明这一轮归并结束,一次性拷贝回a。最后gap*2即可,直到gap>n外层while循环结束
int* tmp = (int*)malloc(sizeof(int) * n);
int gap = 1;
while (gap < n)
{for (int i = 0; i < n; i +=2*gap ){int j = i;int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//如果最后一把拷贝if (end1 >= n){end1 = n - 1;begin2 = n;end2 = n - 1;}else if (begin2 >= n){begin2 = n;end2 = n - 1;}else if (end2 >= n){end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}}memcpy(a, tmp,sizeof(int)*n);gap *= 2;
}如果多次拷贝,即走完一次拷贝一次呢,那么很简单,拷贝要写在for循环里,同时拷贝的起始位置要对应
#include <stdio.h>
#include <stdlib.h>
#include <string.h>void MergeSortNonR(int* a, int n)
{if (a == NULL || n <= 1)return; // 空数组或单个元素无需排序int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc failed"); // 内存分配失败提示exit(EXIT_FAILURE);}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// 定义两组的区间:[begin1, end1] 和 [begin2, end2]int begin1 = i;int end1 = i + gap - 1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;int j = i; // tmp数组的起始写入位置(与a的当前分组起始一致)// 边界修正:确保不越界(核心简化逻辑)if (end1 >= n) end1 = n - 1;if (begin2 >= n) begin2 = n; // 第二组不存在,直接置为无效区间if (end2 >= n) end2 = n - 1;// 归并两组到tmpwhile (begin1 <= end1 && begin2 <= end2){tmp[j++] = (a[begin1] <= a[begin2]) ? a[begin1++] : a[begin2++];}// 拷贝第一组剩余元素while (begin1 <= end1){tmp[j++] = a[begin1++];}// 拷贝第二组剩余元素while (begin2 <= end2){tmp[j++] = a[begin2++];}// 关键:将当前分组的有序结果从tmp写回a(避免下一组覆盖tmp数据)memcpy(a + i, tmp + i, (j - i) * sizeof(int));}gap *= 2; // 每组大小翻倍(修复死循环)}free(tmp); // 释放临时内存tmp = NULL;
}// 测试代码
int main()
{int a[] = {5, 3, 8, 6, 2, 7, 1, 4};int n = sizeof(a) / sizeof(a[0]);printf("排序前:");for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");MergeSortNonR(a, n);printf("排序后:");for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");return 0;
}非比较排序
之前的排序算法说到底还是去比较数字的大小,称为比较排序,那么自然也有非比较排序。
计数排序:
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
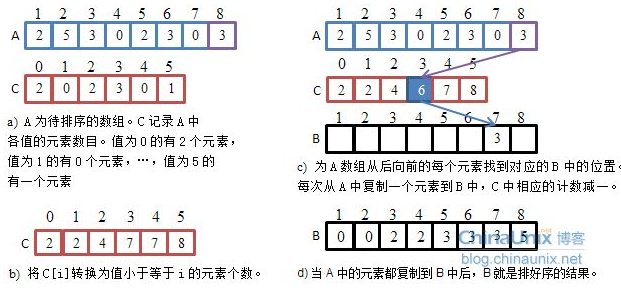
void CountSort(int* a, int n)
{if (a == NULL || n <=1){return;}int max=a[0], min = a[0];for (int i = 0; i < n; i++){if (a[i] > max){max = a[i];}if (a[i] < min){min = a[i];}}int range = max - min + 1;int* countA = (int*)calloc(range,sizeof(int));if (countA == NULL){perror("calloc fail");return ;}//计数for (int i = 0; i < n; i++){countA[a[i] - min]++;}//排序int j = 0;for (int i = 0; i < range; i++){while (countA[i]--){a[j++] = i + min;}}free(countA);countA = NULL;}计数那个操作使得计数排序可以对负数进行排序,算是一个优化。