深度解析Andrej Karpathy访谈:关于AI智能体、AGI、强化学习与大模型的十年远见
在人工智能浪潮席卷全球的今天,各种关于“AGI(通用人工智能)元年”、“AI智能体革命”的论调不绝于耳。然而,当我们有机会聆听一位真正身处风暴中心、亲手构建了AI技术版图关键部分的科学家的声音时,往往能获得一种更为清醒和深刻的认知。Andrej Karpathy正是这样一位人物。
作为OpenAI的创始成员之一、前特斯拉AI总监,以及斯坦福大学著名课程CS231n的设计者和讲师,Karpathy的职业生涯几乎与深度学习的崛起完全同步。他不仅是理论的探索者,更是将理论付诸实践、解决工业界最棘手问题的核心人物。近期,他在知名播客主Dwarkesh Patel的长达2.5小时的访谈中,分享了他对当前AI领域热点问题的深度思考,其内容信息密度极高,充满了宝贵的“内部视角”和基于数十年经验的冷静判断。
本篇技术博客旨在系统性地梳理和解析这次访谈的精华内容。我们将不仅仅是转述,而是结合Karpathy的个人经历、相关技术背景以及更广泛的行业资料,深入剖析他提出的核心观点,为关注AI发展的技术人员、研究者和决策者提供一份结构清晰、内容详实的参考。
核心观点思维导图

第一章:智能体的“十年之约”,而非“元年神话”
在访谈的开篇,Karpathy就针对业界普遍存在的“智能体元年”的说法,提出了一个更为审慎的观点。他认为,我们正处在“智能体的十年(Decade of Agents)”的开端,而非一个可以立即宣告成功的“元年”。
核心论点:这是“智能体的十年”,而非“智能体的元年”
“我之所以被(‘智能体元年’)这个说法触发,是因为我觉得行业中存在一些过度预测……在我看来,这更准确地应被描述为‘智能体的十年’。我们将与这些系统共事十年,它们会变得越来越好,但这需要时间。”
这个论断的背后,是Karpathy对当前AI智能体能力的深刻洞察。他将理想中的智能体比作一个可以雇佣的“实习生”或“员工”。以此为标准,他反问:你现在愿意将你员工的工作交给一个AI智能体吗?答案显然是否定的。因为它们“根本无法胜任(just don’t work)”。
当前智能体的核心缺陷
Karpathy具体指出了当前智能体在走向实用化过程中面临的几个核心障碍:
认知能力不足与可靠性缺失
目前的LLM虽然在特定任务上表现惊艳,但其综合智能水平和稳定性远未达到人类员工的水平。它们在处理复杂、多步骤、需要常识推理和规划的任务时,表现得非常脆弱。一个微小的干扰或未曾见过的场景就可能导致整个任务链的失败。这种“玻璃大炮”式的能力,使其难以在需要高可靠性的生产环境中被委以重任。
缺乏持续学习与世界模型
一个合格的员工能够从每一次任务和互动中学习、积累经验,并记住你的指令和偏好。而当前的AI智能体普遍缺乏有效的持续学习(Continual Learning)能力。你无法简单地告诉它一件事,然后期望它能永久记住并应用。每一次交互在很大程度上都是“无状态”的,这极大地限制了它们与人类进行长期、深度协作的可能。它们没有一个动态更新的、关于世界和任务的内部模型。
多模态能力的鸿沟
现实世界的工作是多模态的。一个办公室助理需要阅读邮件(文本)、理解图表(图像)、操作软件界面(视觉+动作)、甚至接听电话(语音)。虽然多模态模型正在快速发展,但要将这些能力无缝集成到一个能够熟练使用电脑、与各种软件交互的智能体中,仍然有巨大的工程和算法挑战。Karpathy在OpenAI早期就曾领导过Universe项目,旨在让AI通过键盘和鼠标操作网页,他深知其中的困难。
为何是十年?—— 一个基于经验的务实预测
当被问及“十年”这个时间尺度的来源时,Karpathy坦言这更多是基于他近二十年AI领域从业经验的直觉和外推。他亲历了数次AI领域的“地震式”转变,也目睹了无数预测的起落。
“我大概有15年的经验,见证了人们做出预测,也看到了它们最终的结果……我感觉这些问题是棘手的,是可以克服的,但它们仍然很困难。如果我把这些因素平均一下,对我来说,感觉就像是十年。”
这个预测并非凭空而来,而是建立在对解决上述核心缺陷所需的技术突破和工程实践复杂度的深刻理解之上。它提醒我们,从一个令人惊艳的技术演示(Demo)到一个稳定可靠、能融入社会经济体系的产品(Product),中间隔着漫长的、充满挑战的道路。
第二章:大语言模型(LLM)的认知缺陷与学习范式反思
作为智能体的“大脑”,LLM的能力边界直接决定了智能体的天花板。Karpathy在访谈中深入探讨了当前LLM在认知层面存在的根本性缺陷,并对它们赖以成功的学习范式——“预测下一个词元(Token)”——进行了深刻反思。
LLM当前的核心认知短板
被动的“预测机器” vs. 主动的“思考者”
Karpathy指出,LLM的训练机制决定了它们本质上是一个被动的序列预测引擎。当它们“阅读”一本书时,它们所做的只是在庞大的文本序列上不断预测下一个词元,并从中吸收知识。这与人类的学习过程截然不同。
“当你在读书时,你不会觉得这本书是我应该关注并进行训练的论述。这本书是一系列提示,促使我进行合成数据生成,或者让你去读书俱乐部和朋友讨论。正是通过操纵这些信息,你才真正获得了知识。我们在LLM中没有与之等价的东西。”
他渴望看到一种新的训练阶段,在这个阶段,模型能够“思考”它所接收到的材料,尝试将其与已知知识进行协调和整合,而不是简单地进行模式匹配和预测。这种从被动接收到主动思考的转变,是实现更深层次理解的关键。
“模型坍塌”的幽灵:合成数据训练的悖论
随着高质量人类数据的日益稀缺,使用模型自身生成的合成数据进行再训练,成为了一个热门的研究方向。然而,Karpathy对此提出了严峻的警告——模型坍塌(Model Collapse)。
他解释说,如果一个模型过多地用自己生成的数据进行训练,它会逐渐失去对真实世界数据分布的多样性和细微之处的把握。就像一个不断复印同一张纸的复印机,每一代都会引入微小的错误和失真,最终导致图像模糊不清。模型的输出分布会逐渐偏离真实分布,最终“坍塌”到一个狭窄、贫乏的状态。
有趣的是,他将此现象类比于人类的“认知固化”:
“我认为人类也会随着时间的推移而坍塌……这就是为什么孩子们还没有过度拟合,他们会说出让你震惊的话,因为它们……不是人们通常会说的话。”
这暗示了解决模型坍塌可能需要引入某种机制,来保持模型的“开放性”和对新颖、真实数据的持续接触,就像儿童通过与真实世界的互动来不断修正和扩展自己的认知模型一样。
人类学习的启示:超越简单的序列预测
Karpathy认为,要突破LLM的认知瓶颈,必须从人类学习的方式中汲取灵感。
将信息作为“思考的提示”
人类学习不是单向的信息灌输。我们阅读、聆听,然后会停下来思考、质疑、联系旧知、提出假设。这个内部的“合成数据生成”和“反思”过程,是知识内化的核心。未来的LLM需要具备类似的能力,能够在接收信息后,启动一个内部的“思考循环”,而不是立即输出下一个词元。
互动、反思与知识内化
与他人讨论、尝试应用知识解决问题、甚至教授他人,这些都是人类巩固学习的有效方式。这表明,一个孤立的、仅通过静态数据集训练的模型,其学习深度是有限的。未来的智能体可能需要在与环境、与其他智能体、与人类的持续互动中,通过一个包含行动、反馈、反思的闭环来真正实现学习和成长。
第三章:对强化学习(RL)的批判性审视
强化学习(RL)曾被视为通往AGI的希望之路,尤其是在AlphaGo等事件之后。Karpathy作为早期OpenAI的核心成员,曾深度参与了以RL为中心的技术路线。然而,在这次访谈中,他给出了一个极为坦率和批判性的评价。
“强化学习很糟糕,只是其他方法更糟”
这句看似矛盾的话,精准地概括了Karpathy对RL的复杂情感。他承认RL在概念上的强大——让智能体通过与环境互动、从奖励信号中学习,这是构建自主智能体的理想范式。但他也毫不留情地指出了其在实践中的巨大缺陷。
低效的反馈机制:“通过吸管学习”
Karpathy用了一个生动的比喻来形容RL的学习效率:“像用吸管喝水一样学习(sipping learning through a straw)”。RL智能体通常需要海量的试错才能学到一个简单的策略,因为奖励信号往往是稀疏、延迟且信息量低的。与监督学习中每个样本都带有明确标签相比,RL的反馈机制显得极为低效和狭窄。
他认为,这种学习方式缺乏人类的反思和元认知能力。AI在RL框架下不会思考“我为什么会失败?”、“这个策略的根本问题是什么?”,它只是机械地根据标量奖励信号调整其行为策略。
从游戏到现实世界的“误入歧途”
Karpathy回顾了2013年左右由DeepMind的Atari游戏研究引领的RL热潮。当时,整个领域都沉浸在让AI玩转各种虚拟游戏的环境中,OpenAI早期也投入了大量资源。但他现在认为,这在某种程度上是一个“失误(misstep)”。
“我一直对游戏能否真正通向AGI持怀疑态度,因为在我看来,你想要的是像会计师一样的东西,或者说能与真实世界互动的东西。我看不出玩游戏如何能最终实现这一点。”
游戏环境虽然可以提供无限的、可控的实验数据,但它们与现实世界的复杂性、开放性和模糊性相去甚远。过度专注于在封闭、规则明确的游戏中取得高分,可能会让研究偏离解决现实世界问题的正确方向。
RL的未来:融合记忆、元学习与推理
尽管批判了当前RL的局限,Karpathy并未完全否定它。他认为,未来的突破在于将RL与更高级的认知架构相结合,构建一个能够在行动前“思考”的系统。这包括:
- 记忆(Memory):让智能体能够记住过去的经验,并从中进行归纳和推理。
- 元学习(Meta-learning):让智能体学会“如何学习”,能够快速适应新任务和新环境。
- 推理循环(Reasoning Loops):在接收到观察(Observation)和做出行动(Action)之间,加入一个显式的思考和规划过程。
只有当RL不再是简单的“试错-奖励”循环,而是成为一个更庞大的、包含世界模型、记忆和推理的认知系统的一部分时,它才能真正释放其潜力。
第四章:AGI与自动驾驶的现实主义路线图
作为同时在AGI前沿研究(OpenAI)和尖端AI应用(特斯拉自动驾驶)领域都有过深入实践的专家,Karpathy对这两者的发展路径给出了非常务实和接地气的看法。
AGI的到来:融入2%的GDP增长,而非经济爆炸
与许多人预测AGI将带来经济“奇点”或爆炸式增长不同,Karpathy的观点要温和得多。他预测,即使是强大的AI系统,其影响也将是渐进的,会逐渐融入并加速现有的经济增长模式,而不是引发一场颠覆性的革命。
“AGI将融入过去约2.5个世纪以来2%的GDP增长中。”
这个观点背后是一种对技术采纳、社会适应和经济结构惯性的深刻理解。他认为,AGI更可能像电力或互联网一样,作为一个长期的“通用目的技术”,逐步渗透到经济的各个角落,提升整体生产力,而不是一夜之间重塑世界。这为我们思考如何应对AGI的社会影响提供了一个更平稳、更具建设性的视角——是演进,而非革命。
自动驾驶的漫长征途:从理论到现实的“亿万级”边缘案例
Karpathy在特斯拉领导Autopilot视觉团队的经历,让他对将AI技术从实验室推向现实世界应用的难度有着切肤之痛。他解释了为什么完全自动驾驶(FSD)的实现比许多人最初预期的要漫长得多。
“(自动驾驶的挑战)是残酷的复杂。教一台机器去看、去预测罕见事件,并保证人类的安全,这不仅仅是‘再来一次模型更新’的问题。这是数十亿的边缘案例、不可预测的行为和社会责任。”
问题的核心在于长尾分布的边缘案例(Long-tail Edge Cases)。你可以用99%的常见驾驶场景数据训练出一个看起来很不错的模型,但真正决定系统安全性和可靠性的,是那剩下1%的、无穷无尽的罕见甚至从未发生过的场景。
数据引擎的重要性
为了解决这个问题,特斯拉构建了一个强大的“数据引擎”。通过部署在数百万辆车上的“影子模式(Shadow Mode)”,系统可以在不实际控制车辆的情况下运行新版软件,并与人类驾驶员的行为进行比较。当出现不一致或系统感到困惑时,相关的传感器数据和场景就会被自动标记并上传,形成一个专门针对困难和边缘案例的高价值数据集。
Karpathy在CVPR 2021演讲中展示的特斯拉数据引擎规模,强调了海量、多样化和清洁数据的重要性。
从依赖雷达到纯视觉的转变
Karpathy也解释了特斯拉备受争议的“纯视觉”路线。他认为,当视觉系统(摄像头)和雷达系统给出的信息发生冲突时,融合它们反而会增加系统的复杂性和不确定性。与其花费精力去处理传感器之间的“分歧”,不如将所有资源投入到解决核心问题——让视觉系统本身变得足够强大和可靠。这是一种“加倍下注于视觉(double down on vision)”的策略,背后是对神经网络潜力的高度自信。
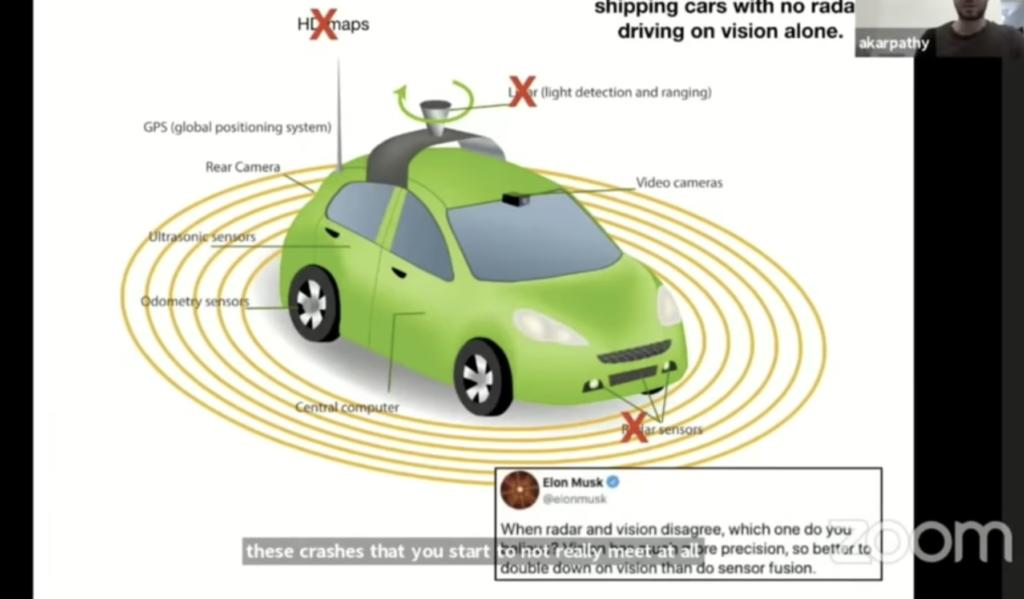
特斯拉决定放弃雷达等传感器,专注于构建一个基于纯视觉的自动驾驶系统。
第五章:对未来的展望——教育的变革与集体智能
在访谈的最后,Karpathy将目光投向了更远的未来,分享了他对AI将如何重塑教育以及对“智能”本质的哲学思考。
AI驱动的个性化教育革命
Karpathy对AI在教育领域的应用充满了热情和期待。他认为,AI有潜力彻底改变当前的“一刀切”教育模式,实现真正的个性化学习。
“每个学生都将拥有一个自适应的AI导师,可以按照自己的节奏前进,由好奇心引导。教师的角色将从信息传递者转变为意义的策展人。教育将回归其本应有的样子:探索、玩耍和发现。”
这与他自己热衷于教育的经历一脉相承。无论是创建广受欢迎的CS231n课程,还是在YouTube上发布“Neural Networks: Zero to Hero”系列教程,Karpathy始终在探索如何让复杂的知识变得更易于理解和掌握。他创立的新公司Eureka Labs也正是一个专注于AI与教育结合的尝试。
智能的本质:社会性与文化传承
最后,Karpathy分享了他对智能本质的看法。他认为,人类的智能并非孤立地存在于个体的大脑中,而是一种深刻的集体现象。
“人类智能是从文化、共享知识和协作中涌现出来的。我们的大脑是生物学的,但我们的心智是社会性的——与工具、语言共同进化,并向他人学习。我们之所以智能,是因为我们一起学习。”
这个观点为我们理解和构建AGI提供了重要的启示。一个真正智能的系统,或许不仅仅需要强大的计算能力和算法,更需要被置于一个丰富的社会和文化环境中,能够通过与他人的互动、学习和协作来不断成长。这再次呼应了他对当前LLM作为孤立“预测机器”的批判,并指向了一个更加宏大和复杂的AGI实现路径。
结论:在炒作与现实之间,保持建设性的耐心
Andrej Karpathy的这次访谈,如同一剂清醒剂,为当前略显狂热的AI领域注入了宝贵的理性和现实主义。他没有兜售遥不可及的梦想,也没有散播悲观的论调,而是以一位资深工程师和科学家的视角,清晰地剖析了通往更强大AI道路上真实存在的障碍、挑战和可能的路径。
从“智能体的十年之约”到对LLM认知缺陷的深刻反思,从对强化学习的批判性审视到对AGI和自动驾驶的务实路线图,Karpathy的观点贯穿着一条主线:真正的进步源于对问题的诚实面对、持续的工程努力和对复杂性的敬畏。
对于所有AI领域的从业者和关注者而言,这次访谈的价值在于,它提醒我们在追逐星辰大海的同时,也要脚踏实地,认识到从一个突破性的想法到一个改变世界的技术,中间需要的是时间、汗水和一种“建设性的耐心”。正如Karpathy所言,未来十年将是激动人心的,但我们需要做好迎接一场马拉松而非百米冲刺的准备。
© 2025 AI内容生成专家. 本文内容根据公开访谈资料整理分析,仅供学习交流使用。