从测试小白到高手:JUnit 5 核心注解 @BeforeEach 与 @AfterEach 的实战指南
在 Java 开发领域,单元测试是保证代码质量的基石,而 JUnit 作为 Java 生态中最主流的测试框架,早已成为开发者的必备技能。随着 JUnit 5 的发布,其模块化设计和丰富的注解体系让测试代码更加灵活、可读。其中,@BeforeEach 与 @AfterEach 这对注解看似简单,却暗藏着测试隔离的核心逻辑,直接影响测试的可靠性与效率。本文将从底层原理到实战场景,全方位剖析这两个注解,让你不仅 “会用”,更能 “用好”,彻底告别测试代码混乱、资源泄漏的烦恼。
一、JUnit 5:现代 Java 测试的基石
1.1 为什么需要单元测试?
在软件开发中,“没有测试的代码就是不可靠的代码” 已成为行业共识。单元测试作为测试金字塔的底层,具有以下不可替代的价值:
- 快速反馈:在开发阶段就能发现代码缺陷,避免问题流入生产环境
- 重构保障:确保代码重构后功能依然正确,降低修改风险
- 文档作用:测试用例本身就是最直观的代码使用文档
- 设计优化:难以测试的代码往往是设计不合理的信号,推动代码解耦
根据 Martin Fowler 的统计,单元测试能发现项目中 70% 以上的逻辑缺陷,而修复成本仅为生产环境的 1/10。
1.2 JUnit 的演进:从 4 到 5 的跨越
JUnit 诞生于 1997 年,由 Kent Beck 和 Erich Gamma 共同创建,历经 20 余年发展,已从最初的简单框架演变为功能完善的测试生态。其中,JUnit 5(2017 年发布)是一次颠覆性升级,与 JUnit 4 相比有三大核心变化:
| 特性 | JUnit 4 | JUnit 5 |
|---|---|---|
| 最低 JDK 版本 | JDK 5 | JDK 8+(支持 Lambda、Stream 等新特性) |
| 架构 | 单一 jar 包 | 模块化设计(Platform/Jupiter/Vintage) |
| 注解体系 | 有限注解(@Before/@After 等) | 丰富注解(支持重复注解、元注解等) |
| 扩展性 | 较差 | 强大的扩展 API(Extension 模型) |
JUnit 5 的模块化设计使其能更好地适应现代 Java 开发需求,而本文重点讲解的 @BeforeEach 与 @AfterEach 正是其注解体系中的核心成员。
1.3 JUnit 5 的核心架构
JUnit 5 采用 “三大组件” 架构,彼此独立又协同工作:
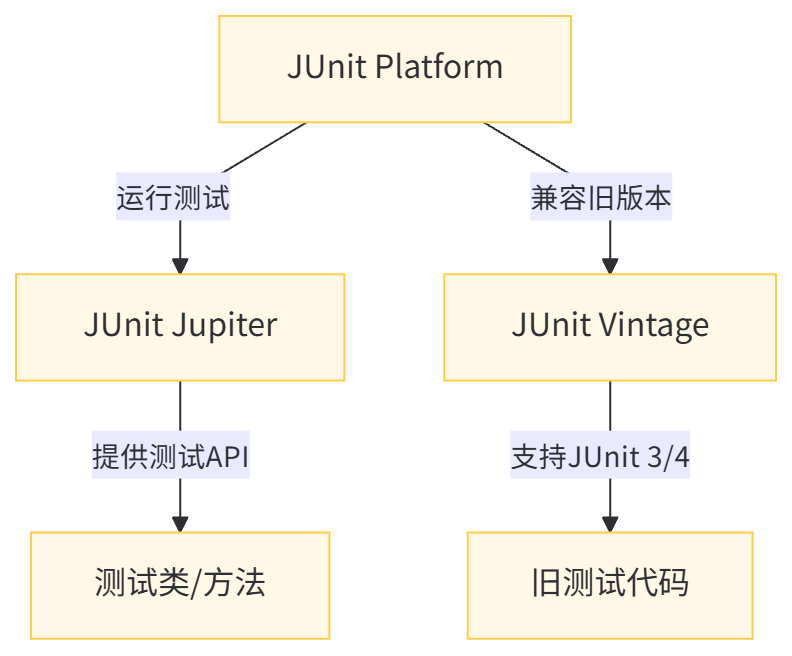
- JUnit Platform:测试运行的基础平台,负责启动测试引擎、提供控制台输出等
- JUnit Jupiter:包含测试 API 和引擎,提供 @BeforeEach、@Test 等注解及执行逻辑
- JUnit Vintage:兼容 JUnit 3 和 JUnit 4 的测试代码(需单独引入依赖)
这种架构让 JUnit 5 既能支持新特性,又能兼容旧代码,是企业级项目升级的理想选择。
二、@BeforeEach 与 @AfterEach:测试方法的 “前后管家”
2.1 注解的核心作用
在单元测试中,我们经常需要在测试方法执行前做一些准备工作(如初始化对象、连接数据库),在测试后做一些清理工作(如释放资源、删除临时数据)。@BeforeEach 与 @AfterEach 正是为解决这类问题而生:
- @BeforeEach:标记的方法会在每个测试方法执行前自动运行
- @AfterEach:标记的方法会在每个测试方法执行后自动运行
它们就像测试方法的 “前后管家”,确保每个测试都在干净、一致的环境中执行,这是 “测试隔离” 原则的核心体现。
2.2 底层执行逻辑:测试实例的生命周期
要理解这两个注解的工作原理,必须先掌握 JUnit 5 中测试实例的生命周期。与 JUnit 4 不同,JUnit 5 默认采用 “per-method” 模式:每个测试方法都会创建一个新的测试类实例。
执行流程如下:
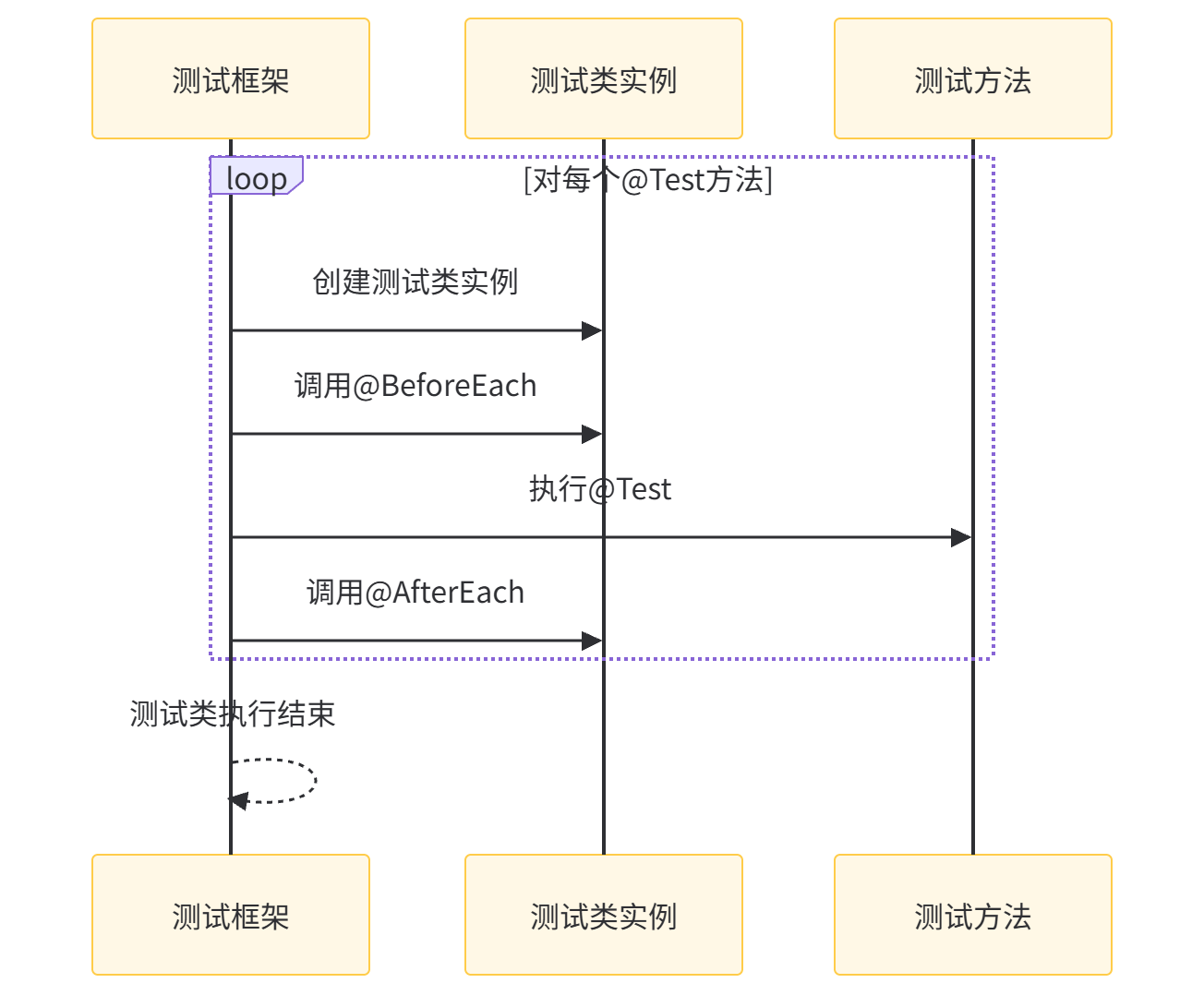
这种设计的好处是:每个测试方法完全独立,不会受其他测试方法的状态影响。例如,测试方法 A 修改了某个成员变量,测试方法 B 不会受此影响,因为它们属于不同的实例。
而 @BeforeEach 与 @AfterEach 正依赖这一机制:它们与测试方法属于同一个实例,因此可以安全地操作实例变量,为每个测试方法提供专属的初始化和清理逻辑。
2.3 注解的使用规范
使用 @BeforeEach 与 @AfterEach 需遵循以下规范(来自 JUnit 5 官方文档):
- 注解的方法必须是非静态的(因为依赖实例生命周期)
- 方法返回值必须是void
- 方法不能有参数(除非结合 ParameterResolver 扩展)
- 访问修饰符可以是 public、protected、package-private 或 private(推荐 package-private 或 private,减少外部依赖)
违反这些规范会导致测试引擎抛出org.junit.platform.commons.JUnitException异常。
三、实战示例:从简单到复杂的应用场景
3.1 基础示例:工具类测试
假设我们有一个简单的计算器工具类,需要测试其加减功能。我们可以用 @BeforeEach 初始化计算器实例,用 @AfterEach 记录测试结果。
步骤 1:定义被测试类
/*** 简单计算器工具类** @author ken*/
public class Calculator {/*** 加法运算** @param a 被加数* @param b 加数* @return 两数之和*/public int add(int a, int b) {return a + b;}/*** 减法运算** @param a 被减数* @param b 减数* @return 两数之差*/public int subtract(int a, int b) {return a - b;}
}
步骤 2:编写测试类
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import static org.junit.jupiter.api.Assertions.assertEquals;/*** 计算器测试类** @author ken*/
@Slf4j
class CalculatorTest {private Calculator calculator;private long startTime;/*** 每个测试方法执行前初始化资源*/@BeforeEachvoid setUp() {calculator = new Calculator();startTime = System.currentTimeMillis();log.info("测试开始,初始化计算器实例");}/*** 测试加法功能*/@Testvoid testAdd() {int result = calculator.add(2, 3);// 断言结果是否符合预期assertEquals(5, result, "加法运算错误");log.info("加法测试执行完成");}/*** 测试减法功能*/@Testvoid testSubtract() {int result = calculator.subtract(5, 3);assertEquals(2, result, "减法运算错误");log.info("减法测试执行完成");}/*** 每个测试方法执行后清理资源*/@AfterEachvoid tearDown() {long endTime = System.currentTimeMillis();log.info("测试结束,耗时: {}ms,计算器实例将被销毁", (endTime - startTime));// 手动置空,帮助GC回收(非必需,仅作演示)calculator = null;}
}
步骤 3:添加 Maven 依赖
<dependencies><!-- JUnit 5 核心依赖 --><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-api</artifactId><version>5.10.0</version><scope>test</scope></dependency><dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter-engine</artifactId><version>5.10.0</version><scope>test</scope></dependency><!-- Lombok 用于日志 --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.30</version><scope>provided</scope></dependency><!-- Spring 工具类 --><dependency><groupId>org.springframework</groupId><artifactId>spring-core</artifactId><version>6.1.1</version></dependency>
</dependencies>
执行结果分析
运行测试后,控制台输出如下(日志级别为 INFO):
测试开始,初始化计算器实例
加法测试执行完成
测试结束,耗时: 2ms,计算器实例将被销毁
测试开始,初始化计算器实例
减法测试执行完成
测试结束,耗时: 1ms,计算器实例将被销毁
可以看到:
- 两个测试方法分别对应两次
setUp()和tearDown()调用 - 每次测试都是独立的,互不干扰
- 通过 @BeforeEach 和 @AfterEach,我们优雅地实现了 “重复代码抽取”,避免了在每个测试方法中写初始化 / 清理逻辑
3.2 进阶示例:数据库测试(结合 MyBatis-Plus)
在实际开发中,我们经常需要测试与数据库交互的代码(如 DAO 层)。这时 @BeforeEach 可用于插入测试数据,@AfterEach 可用于清理数据,确保测试环境干净。
步骤 1:定义实体类和 Mapper
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import io.swagger.v3.oas.annotations.media.Schema;
import lombok.Data;/*** 用户实体类** @author ken*/
@Data
@TableName("t_user")
@Schema(description = "用户实体")
public class User {@TableId(type = IdType.AUTO)@Schema(description = "用户ID")private Long id;@Schema(description = "用户名")private String username;@Schema(description = "年龄")private Integer age;
}
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import org.apache.ibatis.annotations.Mapper;/*** 用户Mapper接口** @author ken*/
@Mapper
public interface UserMapper extends BaseMapper<User> {
}
步骤 2:编写测试类(使用 Spring Boot Test)
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.util.Assert;
import org.springframework.util.ObjectUtils;import java.util.List;/*** UserMapper测试类** @author ken*/
@Slf4j
@SpringBootTest
class UserMapperTest {@Autowiredprivate UserMapper userMapper;private User testUser;/*** 测试前插入测试数据*/@BeforeEachvoid setUp() {// 创建测试用户testUser = new User();testUser.setUsername("test_user");testUser.setAge(25);// 插入数据库int insert = userMapper.insert(testUser);Assert.isTrue(insert == 1, "测试数据插入失败");log.info("测试数据插入成功,用户ID: {}", testUser.getId());}/*** 测试查询用户功能*/@Testvoid testSelectUser() {// 根据用户名查询LambdaQueryWrapper<User> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.eq(User::getUsername, "test_user");List<User> userList = userMapper.selectList(queryWrapper);// 验证结果Assert.isTrue(!ObjectUtils.isEmpty(userList), "查询结果为空");Assert.isTrue(userList.size() == 1, "查询结果数量错误");Assert.isTrue(userList.get(0).getAge() == 25, "用户年龄错误");log.info("查询测试执行成功");}/*** 测试后清理测试数据*/@AfterEachvoid tearDown() {if (!ObjectUtils.isEmpty(testUser) && !ObjectUtils.isEmpty(testUser.getId())) {// 删除测试数据int delete = userMapper.deleteById(testUser.getId());Assert.isTrue(delete == 1, "测试数据清理失败");log.info("测试数据清理成功,用户ID: {}", testUser.getId());}}
}
步骤 3:添加数据库相关依赖
<!-- Spring Boot Test -->
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><version>3.2.0</version><scope>test</scope>
</dependency>
<!-- MyBatis-Plus -->
<dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.5</version>
</dependency>
<!-- MySQL 驱动 -->
<dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId><version>8.3.0</version><scope>runtime</scope>
</dependency>
<!-- Swagger3 -->
<dependency><groupId>org.springdoc</groupId><artifactId>springdoc-openapi-starter-webmvc-ui</artifactId><version>2.2.0</version>
</dependency>
关键逻辑说明
- 测试隔离:通过 @BeforeEach 为每个测试方法插入独立的测试数据,@AfterEach 确保测试后数据被删除,避免多个测试相互干扰
- 资源管理:利用 Spring 的依赖注入获取 UserMapper 实例,无需手动管理连接
- 断言使用:使用 Spring 的 Assert 工具类替代 JUnit 的 Assertions,功能一致但更符合 Spring 项目习惯
- 异常处理:通过 Assert 的 isTrue 方法,在条件不满足时直接抛出异常,中断测试
这种方式特别适合 DAO 层测试,既能验证数据库操作的正确性,又不会污染测试环境。
3.3 高级示例:多线程环境下的资源控制
在测试多线程相关代码时,@BeforeEach 和 @AfterEach 可用于初始化线程池和关闭线程池,避免资源泄漏。
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.util.Assert;import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;/*** 多线程测试类** @author ken*/
@Slf4j
class ThreadPoolTest {private ExecutorService executorService;/*** 初始化线程池*/@BeforeEachvoid setUp() {// 创建固定大小的线程池executorService = Executors.newFixedThreadPool(3);log.info("线程池初始化完成");}/*** 测试线程池执行任务** @throws InterruptedException 线程中断异常*/@Testvoid testThreadPoolTask() throws InterruptedException {// 提交10个任务for (int i = 0; i < 10; i++) {int taskId = i;executorService.submit(() -> {log.info("任务{}执行中...", taskId);try {TimeUnit.MILLISECONDS.sleep(100);} catch (InterruptedException e) {Thread.currentThread().interrupt();}});}// 等待所有任务完成executorService.shutdown();boolean allDone = executorService.awaitTermination(1, TimeUnit.SECONDS);Assert.isTrue(allDone, "任务未在规定时间内完成");log.info("所有任务执行完成");}/*** 关闭线程池,防止资源泄漏*/@AfterEachvoid tearDown() {if (!executorService.isTerminated()) {// 强制关闭未完成的任务executorService.shutdownNow();log.warn("线程池强制关闭");} else {log.info("线程池正常关闭");}}
}
此示例中,@BeforeEach 创建线程池,@AfterEach 确保线程池被关闭(即使测试失败),避免线程资源泄漏。这是资源密集型测试中必须注意的点。
四、与其他生命周期注解的对比与协同
JUnit 5 提供了丰富的生命周期注解,除了 @BeforeEach 和 @AfterEach,还有 @BeforeAll、@AfterAll、@BeforeEach、@AfterEach 等,它们各自适用不同场景。
4.1 注解对比表
| 注解 | 执行时机 | 方法类型 | 典型用途 |
|---|---|---|---|
| @BeforeAll | 测试类加载后,所有测试方法执行前 | 静态方法 | 初始化静态资源(如数据库连接池、全局配置) |
| @BeforeEach | 每个测试方法执行前 | 实例方法 | 初始化实例资源(如创建对象、插入测试数据) |
| @AfterEach | 每个测试方法执行后 | 实例方法 | 清理实例资源(如删除测试数据、释放内存) |
| @AfterAll | 所有测试方法执行后,测试类销毁前 | 静态方法 | 销毁静态资源(如关闭数据库连接池) |
4.2 执行顺序演示
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;/*** 生命周期注解执行顺序测试** @author ken*/
@Slf4j
class LifecycleTest {@BeforeAllstatic void beforeAll() {log.info("=== @BeforeAll 执行 ===");}@BeforeEachvoid beforeEach() {log.info("--- @BeforeEach 执行 ---");}@Testvoid test1() {log.info("测试方法1 执行");}@Testvoid test2() {log.info("测试方法2 执行");}@AfterEachvoid afterEach() {log.info("--- @AfterEach 执行 ---");}@AfterAllstatic void afterAll() {log.info("=== @AfterAll 执行 ===");}
}
执行结果:
=== @BeforeAll 执行 ===
--- @BeforeEach 执行 ---
测试方法1 执行
--- @AfterEach 执行 ---
--- @BeforeEach 执行 ---
测试方法2 执行
--- @AfterEach 执行 ---
=== @AfterAll 执行 ===
从结果可以清晰看到:
- @BeforeAll 和 @AfterAll 仅执行一次(静态方法特性)
- @BeforeEach 和 @AfterEach 在每个测试方法前后各执行一次
- 测试方法的执行顺序默认是不确定的(可通过 @Order 注解指定)
4.3 协同使用场景
实际项目中,这些注解往往协同工作。例如,一个完整的数据库测试流程:
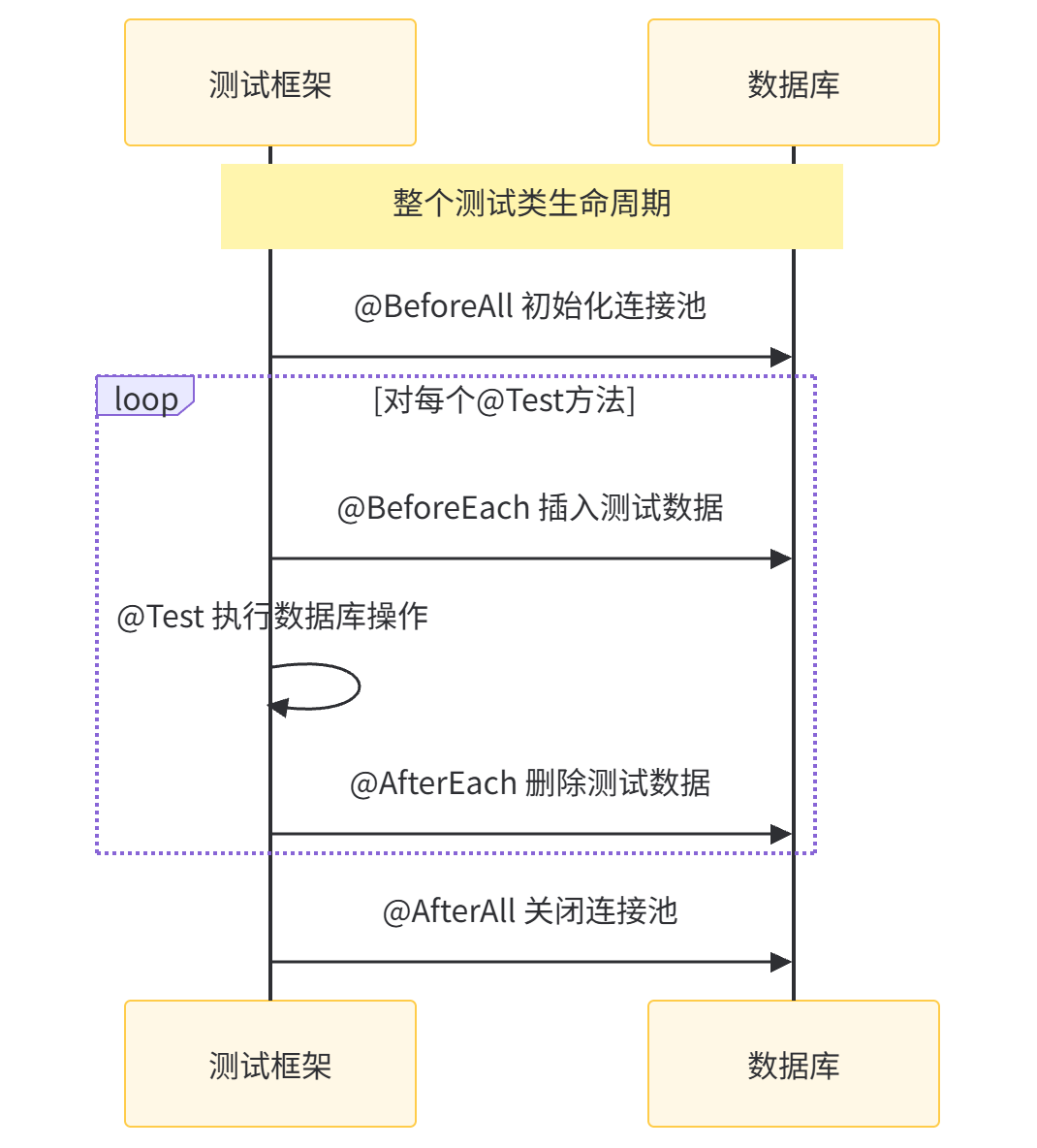
这种组合既保证了全局资源的高效利用(连接池只需初始化一次),又确保了每个测试的独立性(测试数据单独管理)。
五、最佳实践与避坑指南
5.1 最佳实践
保持 @BeforeEach 和 @AfterEach 的简洁性:这两个方法应只做必要的初始化和清理,避免包含复杂业务逻辑,否则会拖慢测试速度。
资源清理的幂等性:确保 @AfterEach 方法可以安全地重复执行(即使前一次执行失败)。例如,删除数据前先判断数据是否存在:
@AfterEach
void tearDown() {if (!ObjectUtils.isEmpty(testUser) && testUser.getId() != null) {userMapper.deleteById(testUser.getId());}
}
避免测试方法依赖顺序:即使通过 @Order 指定了顺序,也不要让测试方法 A 的执行结果影响测试方法 B,因为这违反了测试隔离原则。
日志记录关键信息:在 @BeforeEach 和 @AfterEach 中记录关键操作(如资源 ID、耗时),便于测试失败时排查问题。
优先使用构造函数初始化:对于简单的初始化逻辑(如创建对象),可直接在构造函数中完成,比 @BeforeEach 更高效(少一次方法调用)。
5.2 常见坑点与解决方案
坑点 1:测试实例共享状态
错误示例:
@Slf4j
class BadTest {private List<String> dataList = new ArrayList<>();@BeforeEachvoid setUp() {dataList.add("test");}@Testvoid test1() {log.info("test1 数据量: {}", dataList.size()); // 预期1,实际1(正确)}@Testvoid test2() {log.info("test2 数据量: {}", dataList.size()); // 预期1,实际1(正确?)}
}
很多人误以为 test2 中 dataList 的大小会是 2,其实是 1。因为 JUnit 5 每个测试方法创建新实例,dataList 是每个实例的独立变量。这是 “坑” 也是 “特性”,需正确理解。
坑点 2:资源未正确释放导致测试失败
当 @AfterEach 依赖 @BeforeEach 的执行结果时,如果 @BeforeEach 抛出异常,@AfterEach 可能无法正确执行。
解决方案:在 @AfterEach 中增加 null 判断,确保安全执行:
@AfterEach
void tearDown() {// 即使calculator初始化失败,也不会抛出空指针if (!ObjectUtils.isEmpty(calculator)) {// 释放资源}
}
坑点 3:与 Spring 事务的冲突
在 Spring Boot 测试中,如果使用@Transactional注解,测试方法执行后会自动回滚事务。此时 @AfterEach 中的数据库操作也会被回滚,导致清理失败。
解决方案:将清理逻辑放在@AfterTransaction中(需引入 spring-test 依赖),或禁用测试方法的事务回滚。
六、底层源码解析:注解是如何工作的?
要真正理解 @BeforeEach 和 @AfterEach,我们需要从 JUnit 5 的源码层面一探究竟。
6.1 注解的定义
@BeforeEach 的源码(简化版):
package org.junit.jupiter.api;import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface BeforeEach {
}
注解本身非常简单,仅标记方法。其功能实现依赖 JUnit Jupiter 的引擎。
6.2 执行逻辑的核心类
JUnit 5 通过TestInstanceLifecycleExtension处理测试实例生命周期,其中BeforeEachMethodAdapter和AfterEachMethodAdapter负责执行 @BeforeEach 和 @AfterEach 标记的方法。
核心流程如下:
- 测试引擎扫描测试类,收集所有标记 @BeforeEach、@Test、@AfterEach 的方法
- 为每个 @Test 方法创建测试类实例
- 执行该实例中所有 @BeforeEach 方法
- 执行 @Test 方法
- 执行该实例中所有 @AfterEach 方法
- 重复步骤 2-5,直到所有 @Test 方法执行完毕
关键源码位于org.junit.jupiter.engine.execution包下的TestMethodExecutor类:
// 简化版执行逻辑
public class TestMethodExecutor {public void execute(ExtensionContext context) {// 创建测试实例Object testInstance = createTestInstance(context);// 执行@BeforeEach方法executeBeforeEachMethods(testInstance, context);try {// 执行@Test方法executeTestMethod(testInstance, context);} finally {// 执行@AfterEach方法(确保无论测试成功与否都会执行)executeAfterEachMethods(testInstance, context);}}
}
从源码可以看出,@AfterEach 方法在 finally 块中执行,这保证了即使 @Test 方法抛出异常,清理逻辑也会执行,这是资源安全的重要保障。
七、总结:为什么这对注解如此重要?
@BeforeEach 与 @AfterEach 看似简单,却承载了 JUnit 5 测试隔离的核心思想。它们的价值体现在:
- 代码复用:将重复的初始化 / 清理逻辑抽取到专门的方法,提高测试代码的可读性和可维护性
- 测试隔离:确保每个测试方法在独立的环境中执行,避免测试相互干扰
- 资源安全:通过 @AfterEach 的 finally 执行机制,保证资源一定会被清理,防止泄漏
- 测试效率:合理使用可减少重复操作,提升测试执行速度
掌握这两个注解,是编写高质量单元测试的基础。但记住,工具的价值在于使用场景的匹配:简单测试可能只需 @Test 注解,复杂测试才需要结合 @BeforeEach、@AfterEach 与其他生命周期注解。