【论文精读】SV3D:基于视频扩散模型的单图多视角合成与3D生成
论文标题:SV3D: Novel Multi-view Synthesis and 3D Generation from a Single Image using Latent Video Diffusion
作者:Vikram Voleti, Chun-Han Yao, Mark Boss 等单位:Stability AI
发表时间:2024年3月
项目主页:https://sv3d.github.io/论文链接:https://arxiv.org/pdf/2403.12008
模型链接:https://huggingface.co/stabilityai/sv3d
关键词:SV3D;单图 3D 生成;视频扩散模型;多视角合成;3D 优化;Stable Video Diffusion
欢迎关注,获取更多精读文章!
在生成式AI席卷视觉领域的今天,“从2D到3D”始终是横亘在研究者面前的硬核难题——如何仅凭一张平面图像,还原出兼具细节精度与视角一致性的3D模型?来自Stability AI的团队给出了颠覆性答案:SV3D(Stable Video 3D)。这款基于 latent 视频扩散模型的框架,不仅实现了高分辨率多视角合成,更通过创新的3D优化策略,让单图生成高质量3D网格成为现实。
一、核心问题:单图3D生成的三大痛点
单图3D重建并非新鲜课题,但传统方法和早期生成式模型始终受限于三大核心痛点,这也是SV3D要解决的核心矛盾:
-
视角一致性缺失:多数2D扩散模型衍生方案生成的多视角图像“各自为战”,比如正面视图的纹理与侧面视图无法匹配,直接导致3D模型出现几何错乱。
-
视角可控性不足:部分方法仅能生成固定角度的有限视图(如仅环绕360°同一高度),无法灵活生成任意 elevation(仰角)和 azimuth(方位角)的视角,对物体顶部、底部等关键区域覆盖不足。
-
3D优化瓶颈:即便合成了多视角图像,传统优化方法易出现“光照烘焙”(纹理与光照无法分离)、 unseen 区域(未被视角覆盖区域)细节缺失等问题,导致3D模型质感粗糙。
而SV3D的突破之处在于:借视频扩散模型的“时序一致性”赋能3D的“空间一致性”,同时通过相机姿态控制和精细化3D优化,一次性解决三大痛点。
二、核心创新:SV3D的两大技术支柱
SV3D的架构可拆解为“高质量多视角合成”和“精细化3D生成”两大模块,前者为后者提供精准输入,后者通过创新策略挖掘前者的3D潜力,形成闭环。
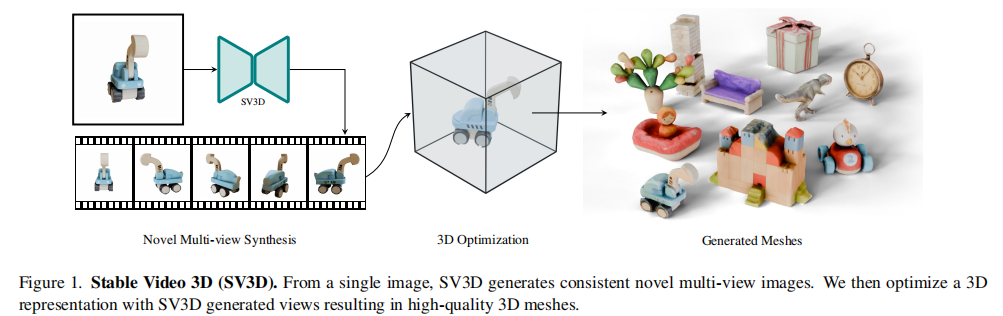
支柱一:基于视频扩散的可控多视角合成
传统多视角合成多基于图像扩散模型,但SV3D另辟蹊径——改造Stable Video Diffusion(SVD)视频扩散模型,将时序一致性转化为空间视角一致性。这一改造并非简单微调,而是从输入编码到推理策略的全链路优化。
1. 核心设计:相机姿态与视频扩散的深度融合
SV3D的架构核心是将“相机轨迹信息”无缝注入视频扩散模型,实现视角的精准控制。其架构细节如图2所示:
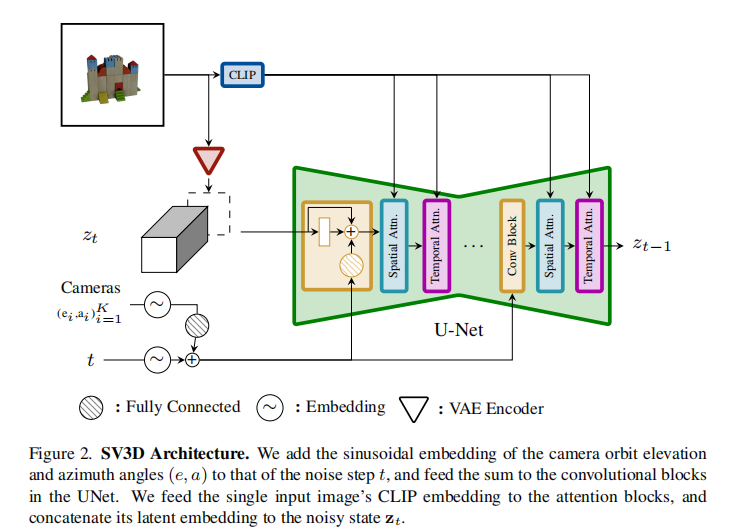
关键改造点有四:
-
冗余条件移除:删除SVD中与视角合成无关的“fps id”“motion bucket id”等条件,降低模型冗余。
-
输入图像双嵌入:将输入单图通过SVD的VAE编码为 latent 特征,与 noisy latent 拼接后输入UNet;同时提取图像的CLIP嵌入,作为Transformer交叉注意力的键值对(Key/Value),保证生成视角与输入语义一致。
-
相机轨迹正弦嵌入:将每个视角的 elevation(e)和 azimuth(a)与扩散步长 t 一起,通过正弦位置编码转化为嵌入向量,经线性变换后注入每个残差块,让模型精准感知视角变化。
-
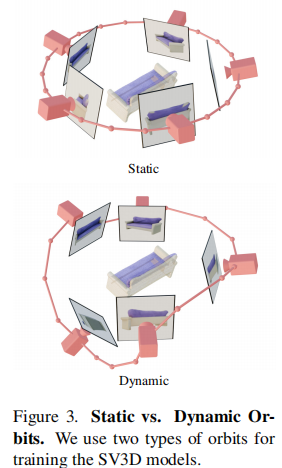
动态轨迹设计:为解决静态轨迹(固定仰角)无法覆盖物体顶部/底部的问题,设计动态轨迹——在静态轨迹基础上为方位角添加随机噪声,为仰角添加多频率正弦波组合,既保证轨迹平滑,又覆盖全视角(如图3)。
2. 推理优化:三角形CFG缩放解决视角失真
SVD默认采用“1→4线性递增”的分类器自由引导(CFG)策略,但这会导致环绕轨迹的最后几帧过度锐化(如图4上侧)。SV3D提出三角形CFG缩放:从正面视角(初始帧)的1线性递增到背面视角(中间帧)的2.5,再线性递减回正面视角的1,既保证背面细节,又避免边缘失真(如图4下侧)。

3. 模型变体:渐进式训练提升可控性
为验证姿态控制的有效性,作者训练了三个模型变体:
-
SV3Du(姿态无条件):仅输入单图,生成固定仰角的静态轨迹,模型自主推断初始仰角。
-
SV3Dc(姿态条件):输入单图+相机轨迹,训练于动态轨迹数据。
-
SV3Dp(渐进式训练):先在静态轨迹上训练55k轮(学习基础视角一致性),再在动态轨迹上训练50k轮(学习灵活视角控制),是性能最优的变体。
支柱二:从多视角到3D网格的精细化优化
有了高质量多视角图像后,SV3D进一步提出“粗→细”两阶段3D优化策略,解决光照烘焙、unseen区域细节缺失等经典问题。其流程如图7所示:
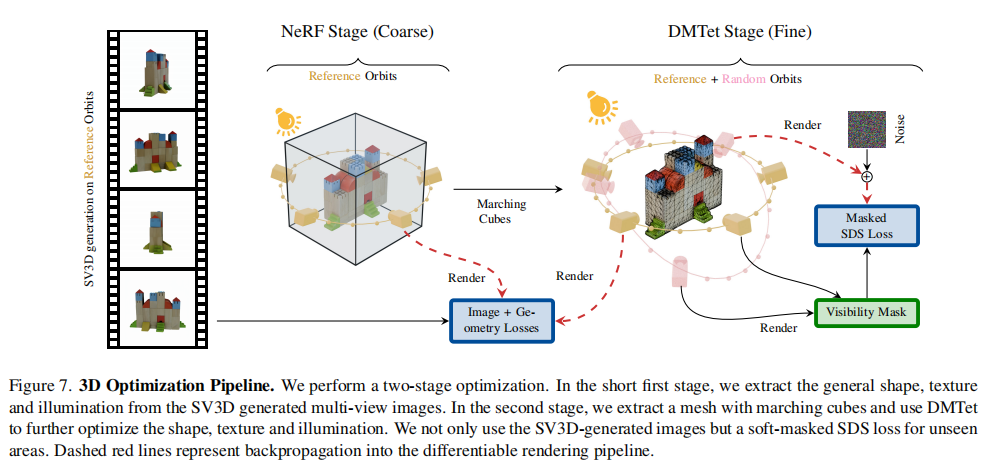
1. 两阶段优化:从NeRF到DMTet的精度跃升
-
粗阶段(NeRF建模):用Instant-NGP(高效NeRF变体)以“ photometric 损失”(MSE+LPIPS+掩码损失)拟合SV3D生成的多视角图像,快速构建物体的整体形状、纹理和初始光照模型,仅需2分钟。
-
细阶段(DMTet优化):通过Marching Cubes从NeRF中提取初始网格,再用DMTet(混合SDF-网格表示)进行精细化优化。此阶段引入SV3D作为扩散引导,同时添加几何先验,提升细节精度,耗时约18分钟。
2. 三大关键优化策略
这一阶段的核心创新在于三个针对性策略,直接解决传统3D优化的痛点:
-
解耦光照模型:告别“光照烘焙”传统方法将光照信息直接“烤”进纹理,导致3D模型无法重新打光。SV3D用24个球面高斯(SG)建模光照,仅学习漫反射纹理(diffuse albedo),通过“光照损失”(匹配输入图像的HSV亮度分量)分离光照与纹理。效果如图8所示:动态轨迹生成的巴士模型,侧面无不合理暗区,可灵活重光照。

-
掩码SDS损失:补全unseen区域直接用SDS损失(扩散模型引导)会导致可见区域纹理过饱和。SV3D提出“软掩码SDS”:通过表面法向量与相机视角的点积判断区域可见性,仅对 unseen 区域(点积值低)应用SDS损失,既补全细节又保留可见区域真实性(如图10)。
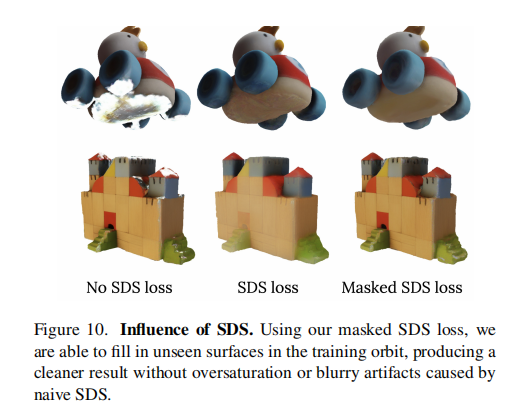
-
几何先验正则:保证表面平滑添加深度平滑损失(RegNeRF启发)、双边法向量平滑损失(仅在图像梯度小时约束法向量平滑)和单目法向量损失(用Omnidata估计的法向量作为监督),避免网格表面出现噪声和锯齿。
三、实验验证:全方位碾压SOTA的硬实力
作者在GSO(谷歌扫描物体)、OmniObject3D等标准数据集及真实世界图像上,从“多视角合成”和“3D生成”两大维度进行了全面验证,结果显示SV3D大幅超越现有SOTA方法。
1. 多视角合成:视角一致性与可控性双领先
定量指标采用LPIPS(感知相似度,越低越好)、PSNR(峰值信噪比,越高越好)等5项核心指标,在GSO静态轨迹上的结果如表1所示:
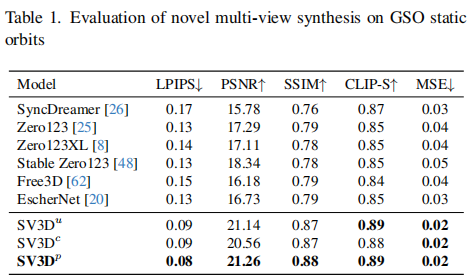
关键结论:
-
即便是姿态无条件的SV3Du,LPIPS(0.09)也远低于SyncDreamer(0.17)、Zero123(0.13)等SOTA,PSNR(21.14)则高出3dB以上,证明视频扩散模型的视角一致性优势。
-
SV3Dp(渐进式训练)性能最优,LPIPS低至0.08,PSNR达21.26,说明渐进式训练能有效提升模型对轨迹的适应能力。
定性效果如图6所示,SV3D生成的视角在纹理(如汽车格栅)、几何(如茶壶把手)上的一致性远超Zero123XL和SyncDreamer,且细节更丰富。

更关键的是真实世界用户研究:30名用户对22张真实图像的生成视频进行偏好投票,SV3D对Zero123XL、Stable Zero123的胜率分别达96%、99%,证明其在真实场景中的实用性。
2. 3D生成:几何与纹理精度双突破
3D评估采用“2D渲染指标”(生成网格渲染图与真实图的差异)和“3D几何指标”(Chamfer距离CD、3D IoU),在GSO数据集上的结果如表5和表6所示:
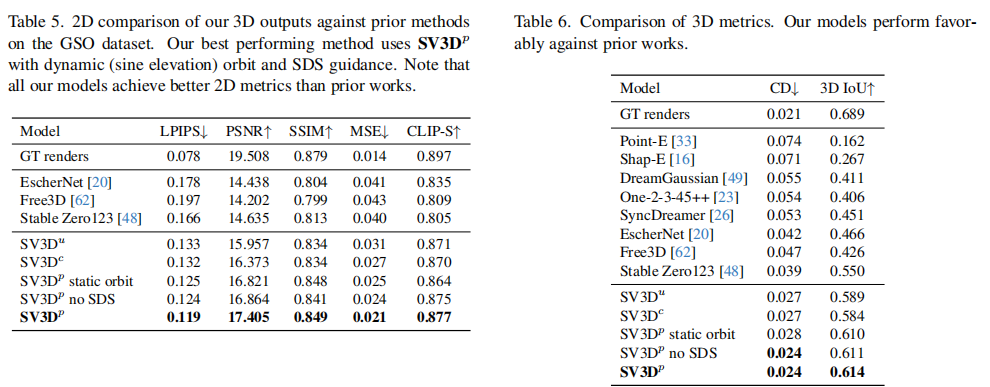
核心亮点:
-
SV3Dp生成的网格渲染图LPIPS仅0.119,接近真实渲染图(0.078),PSNR达17.405,远超Stable Zero123(0.166/14.635)。
-
几何指标上,SV3Dp的CD(0.024)仅为Point-E(0.074)的1/3,3D IoU(0.614)比Stable Zero123(0.550)提升11.6%,接近真实渲染图优化的结果(0.689)。
定性效果如图11所示,SV3D生成的网格能精准还原物体细节(如运动鞋纹路、咖啡杯手柄),而Point-E、Shap-E等方法常出现形状残缺或细节模糊。

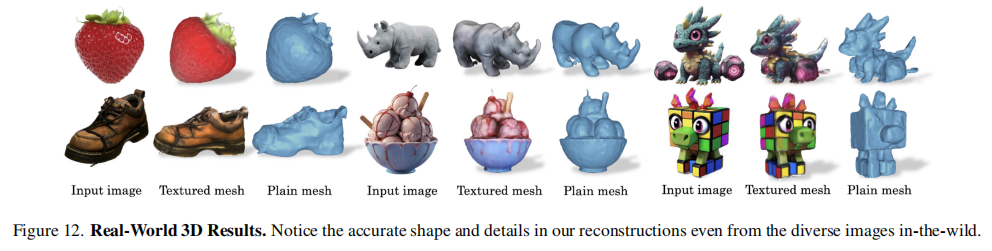
即便是真实世界图像(如图12),SV3D也能生成高质量网格,展现极强的泛化能力。
四、应用价值与未来方向
1. 落地场景:从设计到交互的全链路赋能
SV3D的突破为多个行业带来直接落地价值:
-
游戏/AR/VR:设计师仅需绘制一张概念图,即可快速生成3D模型,大幅降低资产制作成本。
-
电商:商家上传商品单图,自动生成360°可交互3D模型,提升用户购物体验。
-
机器人视觉:为机器人提供物体全视角模型,提升抓取、识别的精准度。
2. 局限性与未来方向
作者也坦诚指出SV3D的不足,这也是后续研究的核心方向:
-
相机自由度有限:仅支持elevation和azimuth控制,不支持相机平移或焦距调整,无法应对复杂场景。
-
反光物体处理不足:镜面、金属等反光表面的视角一致性较差,且 Lambertian shading 模型无法还原反光效果。
-
优化耗时:完整3D生成需20分钟,离实时生成还有差距。
五、总结:生成式3D的范式转移
SV3D的核心贡献并非简单的“视频扩散改3D”,而是确立了“视频扩散+精准姿态控制+精细化3D优化”的单图3D生成新范式:用视频模型的时序一致性解决3D视角一致性,用相机姿态嵌入解决可控性,用解耦光照和掩码SDS解决优化瓶颈。这一范式不仅实现了性能的碾压,更让单图3D生成从“实验室demo”走向“工业级应用”成为可能。
如果觉得本文有帮助,欢迎关注,获取更多精读文章!