大模型应用03 || 函数调用 Function Calling || 概念、思想、流程
1. Function Calling 的概念
1.1 要解决的问题
大型语言模型(LLM)虽然具备强大的语言理解和生成能力,但其本质上是一个封闭的数字大脑。传统的聊天模型仅限于对话,缺乏与外部世界交互的“手”和“脚”,这带来了两大核心局限:
- 无法感知环境(信息局限性):模型无法主动获取其训练数据之外的信息。它不能访问实时API(如查询天气、股价)、浏览网页、读取用户本地文件或连接到数据库。
- 无法改变环境(行动局限性):模型无法为用户执行实际操作。它不能替用户发送邮件、在代码编辑器中运行脚本、或在业务系统中创建一条记录。
Function Calling 技术正是为了打破这些局限,将LLM从一个“只会说”的模型,转变为一个“能做事”的智能代理。
1.2 核心思想
Function Calling 的核心思想是让 LLM 扮演一个“智能任务调度员”。当模型判断用户的请求需要通过外部工具(如API或本地代码)才能完成时,它不会自己执行代码,而是会生成一个结构化的、包含函数名和参数的调用请求(通常是JSON格式)。
开发者的应用程序接收这个请求,负责执行真正的函数,然后将执行结果返回给LLM。最后,LLM根据这个结果,生成最终的自然语言回答。
这个过程可以概括为以下几个关键步骤:
- 定义 (Define):开发者向LLM提供一份可用的“工具清单”,清单中详细描述了每个函数的名称、功能说明以及参数的结构。
- 判断 (Infer):用户发起请求后,LLM根据对话上下文和提供的工具清单,判断是否需要以及需要调用哪个函数来回答问题。
- 生成 (Generate):如果需要调用函数,LLM会暂停生成自然语言回复,转而输出一个包含函数名和参数的结构化调用请求。
- 执行 (Execute):开发者的应用程序捕获这个请求,解析出函数名和参数,并执行相应的本地代码或API调用。
- 响应 (Respond):应用程序将函数的执行结果(例如API的返回值或错误信息)再次发送给LLM。
- 总结 (Summarize):LLM接收到函数执行结果后,结合原始问题,生成最终的自然语言回复给用户。
2. 实现方案的演进
在实现“让LLM调用工具”这一目标上,技术方案经历了从简单到复杂的演进。
2.1 传统方案(后端逻辑判断)
在早期,所有判断逻辑都由后端应用程序负责。
- 工作流程:后端接收用户输入后,通过关键词匹配、正则表达式或意图识别模型来判断是否需要调用某个工具。如果需要,后端自己提取参数,调用工具,然后将工具结果和原始问题一起交给LLM进行总结。
- 存在的问题:
- 逻辑复杂且易错:判断是否调用、调用哪个工具的逻辑完全由后端代码实现,面对复杂多样的用户表达,规则很难写全,容易误判或漏判。
- 参数提取困难:从自然语言中准确提取结构化参数,本身就是一个技术难题。
2.2 基于提示词的 Function Calling
随着LLM能力的增强,开发者开始尝试让LLM自己来完成判断和参数提取。
- 工作流程:开发者在System Prompt中详细定义规则,要求LLM根据用户问题,判断是否需要调用函数,并严格按照指定的JSON格式输出函数名和参数。
- 存在的问题:
- 输出格式不稳定:LLM有时仍会输出多余的自然语言,导致后端JSON解析失败。
- 容易产生幻觉:模型可能编造出不存在的函数名或参数。
- 提示词冗长:为了保证效果,System Prompt需要写得非常详细,消耗大量Token。
2.3 基于原生API的 Function Calling
为了解决上述问题,以OpenAI为首的模型提供商,将Function Calling能力直接内置到了模型和API层,形成了当前最主流、最可靠的方案。
- 工作流程:开发者直接在API请求中,通过专门的
tools参数传入工具的定义。模型经过了专门的微调,能够非常稳定地理解这些工具,并以标准化的格式返回调用请求。 - 优势:格式稳定、不易出错、上下文效率高,将开发者从复杂的提示词工程中解放出来。本文后续内容主要围绕此方案展开。
3. Function Calling 的应用场景
Function Calling 极大地扩展了LLM的能力边界,使其能胜任更广泛的任务。
-
外部API集成与实时数据查询:
- 场景描述:用户提问:“帮我查一下北京现在天气怎么样?”
- 扮演角色:LLM生成调用
get_current_weather(location="北京")的请求。应用程序执行API调用后,将获取的实时天气数据返回给LLM,由LLM整理成自然语言回答。
-
结构化数据提取:
- 场景描述:从“你好,我叫张三,我的订单号是123456,我想咨询一下物流进度”中提取用户信息。
- 扮演角色:开发者定义一个
extract_user_info(name: str, order_id: str)的函数。LLM会直接生成一个函数调用请求:extract_user_info(name="张三", order_id="123456"),保证了输出格式的稳定可靠。
-
业务系统操作与自动化:
- 场景描述:用户说:“帮我在CRM系统中为客户李四创建一个新的跟进任务,内容是回访产品使用情况”。
- 扮演角色:LLM可以调用内部的
create_crm_task(customer_name="李四", task_content="回访产品使用情况")函数,实现对内部系统的操作。
4. 流程细节
整个 Function Calling 流程可以清晰地分为三个主要阶段,涉及两次与 LLM API 的交互。
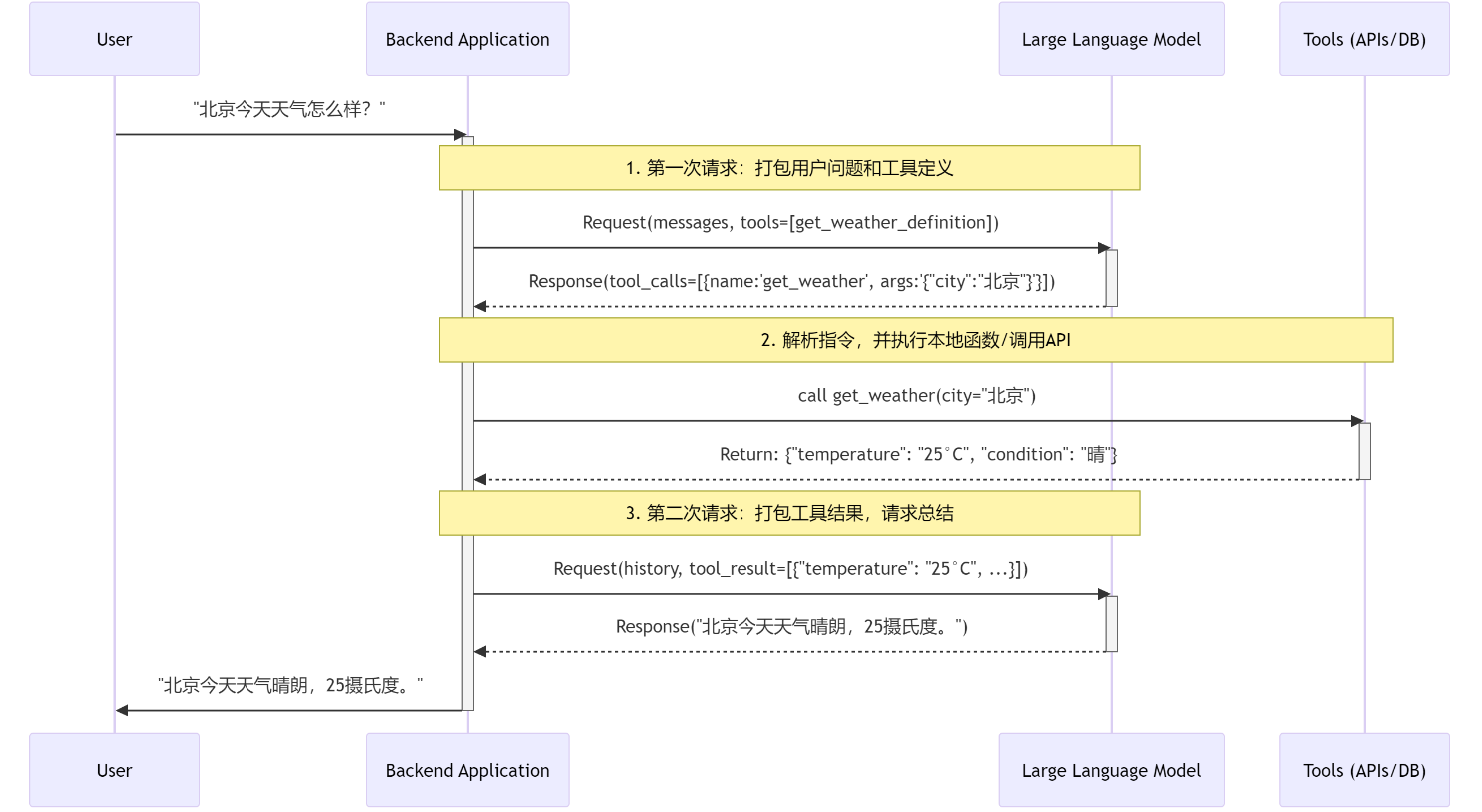
阶段一:模型决策 (LLM Decides)
这个阶段的目标是让 LLM 判断用户的意图,并决定是否需要、以及如何调用工具。
-
用户发起请求:
- 用户向你的后端应用发送一个自然语言请求,例如:“北京今天天气怎么样?”
-
后端应用打包第一次请求:
- 你的后端应用接收到请求。它并不知道答案,于是准备向 LLM 求助。
- 它会构建一个 API 请求,其中包含:
messages: 用户的原始问题和对话历史。tools: 一个描述了可用工具的列表(在本例中是get_weather函数的定义,包括其名称、功能描述和参数 Schema)。
-
LLM 生成调用指令:
- LLM API 接收到请求后,分析用户的意图(“查询天气”)并匹配
tools列表中的get_weather函数。 - 它判断需要调用此函数,并从用户问题中提取出参数
city="北京"。 - 关键点:此时,LLM 不会生成自然语言回答,而是返回一个结构化的
tool_calls对象,明确指示后端:“请帮我调用get_weather函数,参数是{'city':'北京'}”。
- LLM API 接收到请求后,分析用户的意图(“查询天气”)并匹配
阶段二:应用执行 (App Executes)
这个阶段完全在你的后端应用控制之下,负责实际地“干活”。
-
后端解析并执行:
- 你的后端应用检查来自 LLM 的响应,发现其中包含了
tool_calls。 - 它解析这个对象,得到函数名
get_weather和参数{'city':'北京'}。 - 应用根据函数名,调用自己代码中对应的函数(或外部 API、数据库查询等)。
- 你的后端应用检查来自 LLM 的响应,发现其中包含了
-
获取工具结果:
get_weather函数被执行,它可能向一个真实的天气 API 发送了请求,并得到了结果,例如:{"temperature": "25°C", "condition": "晴"}。这个结果是一个结构化的数据(通常是 JSON 字符串)。
阶段三:模型总结 (LLM Summarizes)
获取到原始数据后,还需要 LLM 将这些冰冷的数据转换成用户友好的自然语言。
-
后端应用打包第二次请求:
- 后端应用将上一步中获取到的工具执行结果,连同之前的全部对话历史(包括用户的原始问题和 LLM 的第一次
tool_calls响应),再次打包发送给 LLM API。 - 这次请求相当于告诉 LLM:“你之前让我查的数据,我已经查到了,结果是
{"temperature": "25°C", "condition": "晴"},现在请根据这个信息回答用户最初的问题。”
- 后端应用将上一步中获取到的工具执行结果,连同之前的全部对话历史(包括用户的原始问题和 LLM 的第一次
-
LLM 生成最终答复:
- LLM API 接收到包含工具结果的完整上下文。它现在拥有了回答用户问题所需的所有信息。
- 它将工具返回的结构化数据,整合成一句通顺、自然的回答:“北京今天天气晴朗,25摄氏度。”
-
返回给用户:
- 后端应用接收到这句最终的文本回答,并将其呈现给用户,完成了一次完整的交互闭环。
5. 高级功能
为处理复杂任务,一个成熟的工具调用系统需要支持以下高级功能。
-
并行工具调用 (Parallel Function Calling)
- 描述:当用户的单次请求包含多个可以独立执行的任务时,模型可以在一次回复中生成对多个工具的调用请求。后端系统可以并行执行它们,减少等待时间。
- 场景示例:“帮我查一下北京和上海今天的天气。”
- 模型输出:模型会生成一个包含两个独立函数调用的列表,例如调用
get_weather(city="北京")和get_weather(city="上海")。
-
多步工具调用 (Multi-step Tool Use)
- 描述:对于无法通过单次调用解决的复杂问题,模型需要将问题分解,并按顺序调用一系列工具。前一个工具的输出结果,会作为后续步骤的输入。
- 场景示例:“帮我查一下《三体》的作者,然后查找该作者的其他作品。”
- 执行流程:
- 模型先调用
search_book(name="三体"),得到作者“刘慈欣”。 - 将“刘慈欣”作为输入,模型再调用
find_works_by_author(author="刘慈欣")。 - 最后,模型整合所有信息,生成最终答复。
- 模型先调用
-
错误处理 (Error Handling)
- 描述:工具在执行中可能会失败。后端应捕获这些错误,并将错误信息返回给模型,模型会根据错误内容决定下一步行动。
- 场景示例:调用天气API时,用户输入了一个不存在的城市“火星市”。
- 处理流程:后端执行API后得到“城市未找到”的错误,并将此信息返回给模型。模型接收到后,可以向用户澄清:“抱歉,我无法查询到‘火星市’的天气,您能提供一个正确的城市名称吗?”