Hudi和Iceberg的Specification规范角度详细比较异同点

Apache Hudi 和 Apache Iceberg 作为主流的开源数据湖框架,均通过定义一套 元数据规范(Specification) 来实现数据的事务性管理、版本控制和高效读写。从规范角度看,两者的核心目标一致(构建可靠的湖仓架构),但在元数据结构、版本管理、事务模型等设计上存在显著差异。以下从核心规范维度详细对比:
一、元数据规范:结构与存储
元数据是数据湖的 “大脑”,定义了表的结构、数据文件位置、版本信息等核心信息。两者的元数据规范在层级结构、存储格式和内容上有明显区别。
1. 元数据层级结构
| 维度 | Apache Hudi 规范 | Apache Iceberg 规范 |
|---|---|---|
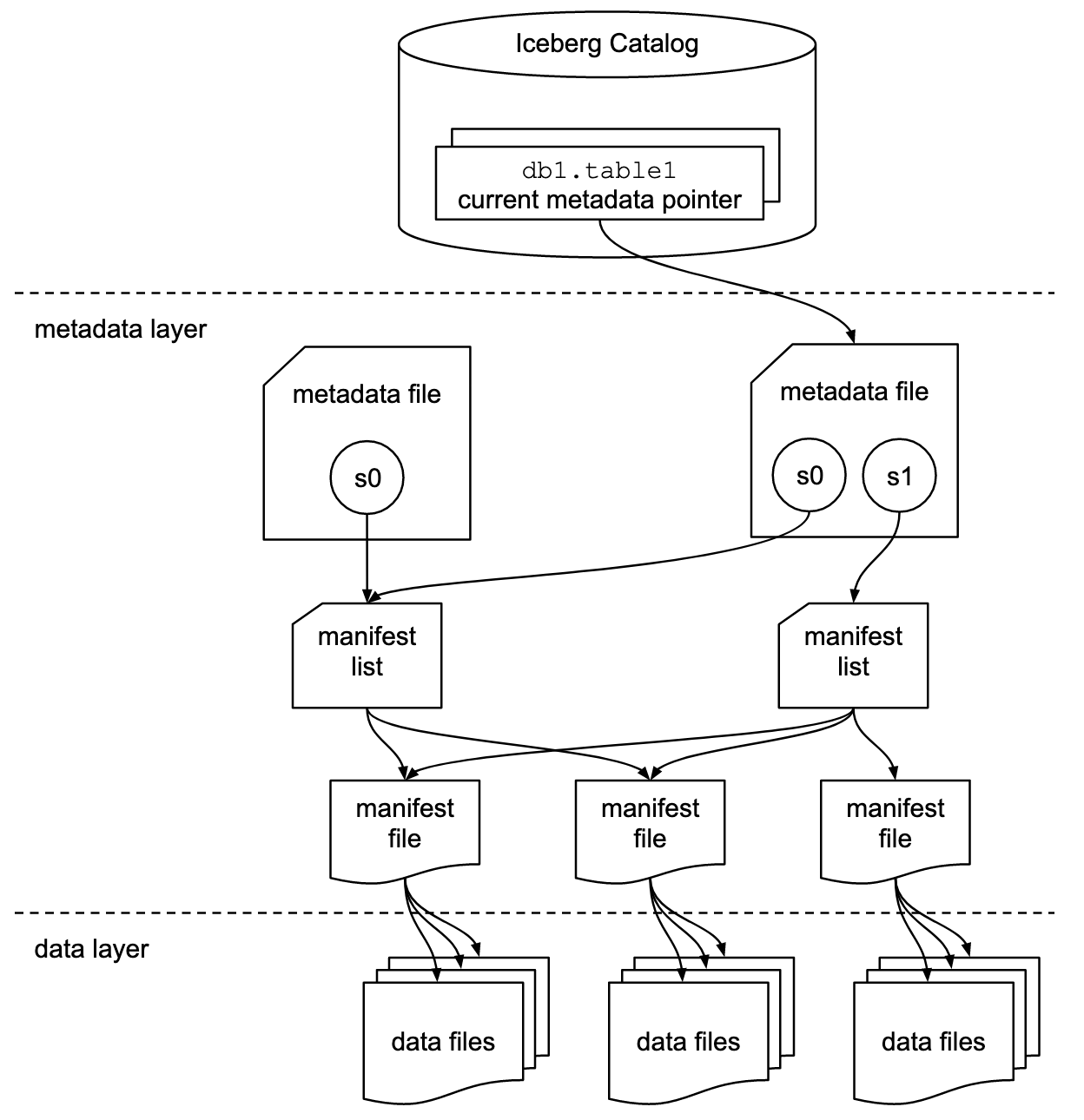
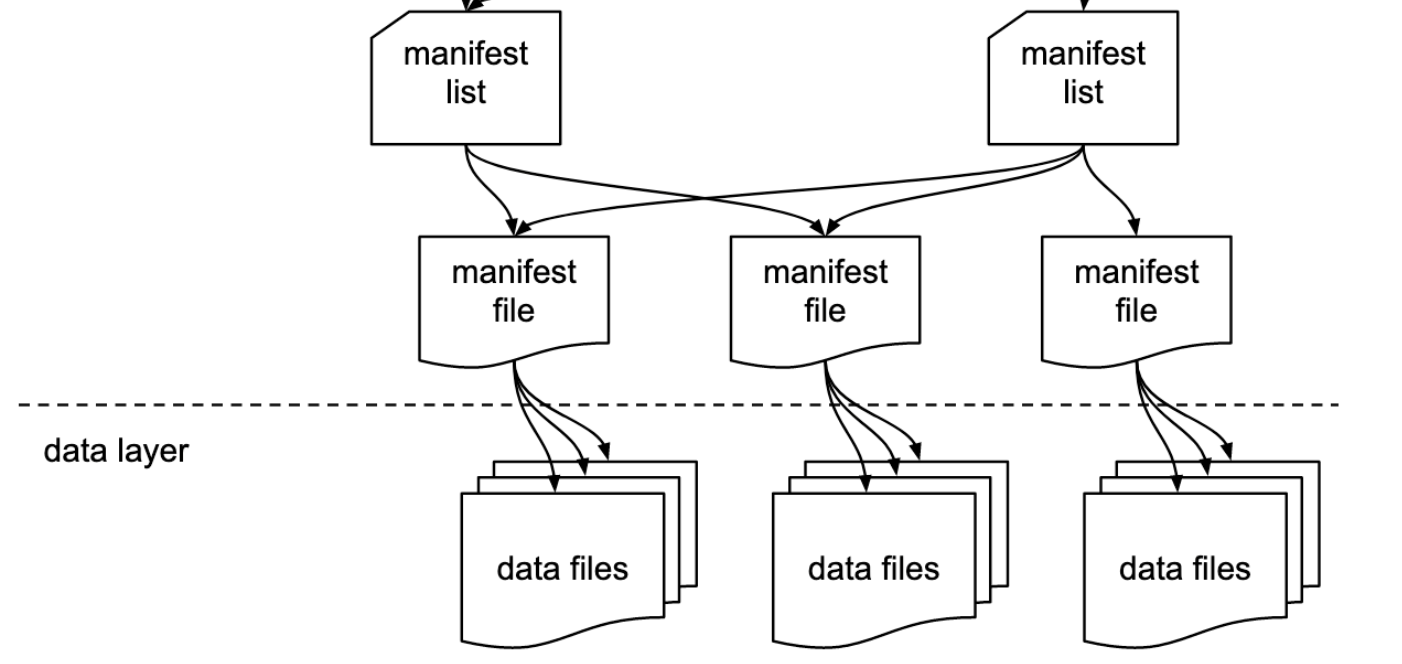
| 核心层级 | 扁平 + 时间线驱动:表级元数据(Table Config) + 时间线(Timeline) + 分区元数据(Partition Metadata) + 数据文件(Data Files) | 树状层级:表元数据(Table Metadata) → 快照(Snapshot) → 清单列表(Manifest List) → 清单文件(Manifest File) → 数据文件(Data File) |
| 元数据核心载体 | Delta Log(事务日志):以 JSON 格式存储,记录所有操作(写入、更新、Clustering 等)的元数据变更。 | 表元数据文件(.metadata.json):二进制序列化格式(默认 Avro),记录当前最新快照及 Schema;清单文件(Manifest)记录数据文件的元数据(路径、分区键、大小等)。 |
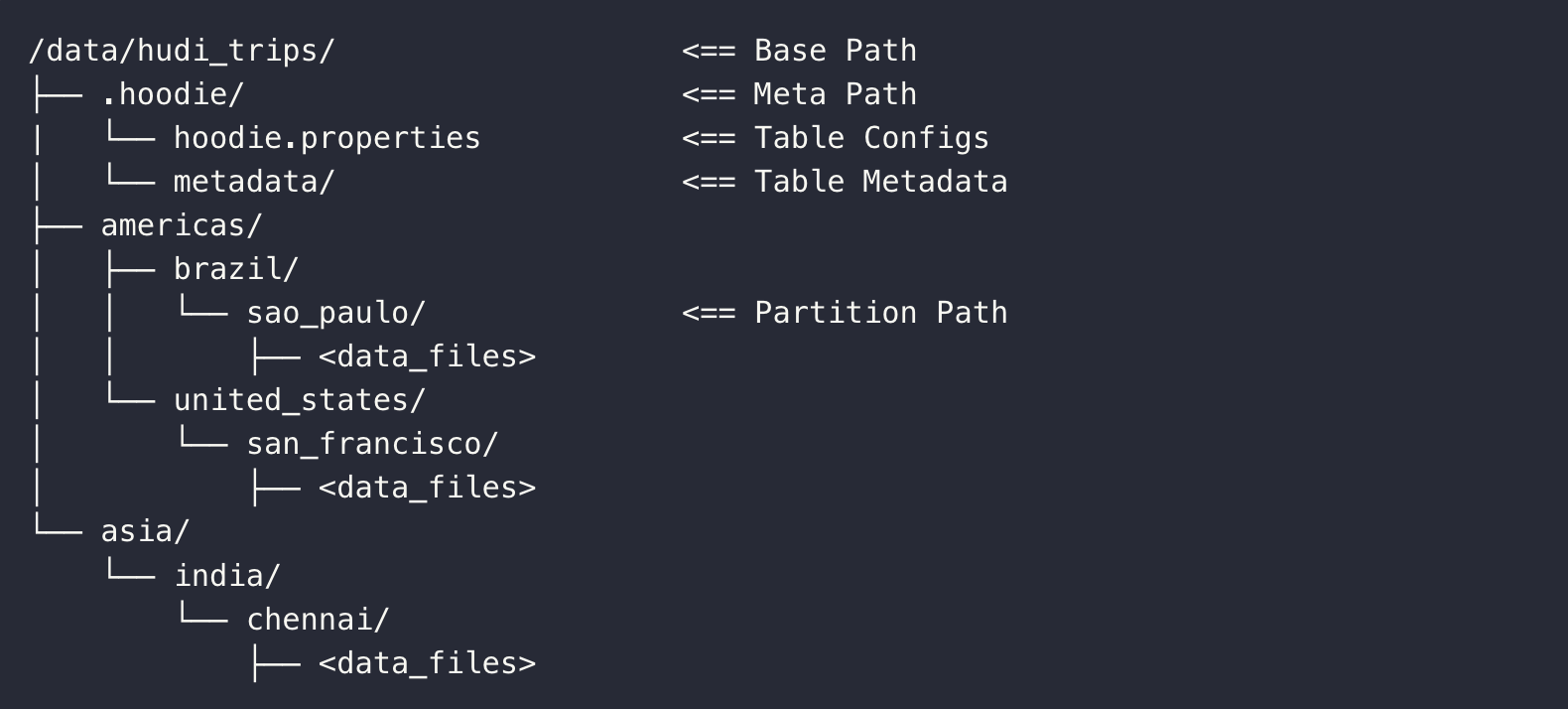
| 元数据定位方式 | 依赖表根目录下的 .hoodie 文件夹,通过时间线中的 Instant ID 定位历史版本元数据。 | 依赖表根目录下的 metadata 文件夹,通过表元数据文件中的 “当前快照 ID” 指向最新版本,历史快照通过快照 ID 链式关联。 |
2. 元数据内容差异
Hudi 元数据(Delta Log):每个事务(Instant)生成一条 Delta Log 记录,包含:
- 操作类型(如
UPSERT、DELETE、CLUSTERING);- 涉及的数据文件(新增 / 删除的文件路径、分区信息);
- 统计信息(记录数、文件大小);
- 索引信息(如布隆索引的元数据)。
特点:元数据与操作强绑定,随时间线线性追加。
Iceberg 元数据:
- 表元数据:记录表名、Schema、分区键、当前快照 ID、属性配置等;
- 快照(Snapshot):记录该版本的创建时间、涉及的清单列表路径、操作类型(如
APPEND、OVERWRITE);- 清单文件(Manifest):记录单个数据文件的元数据(路径、分区值、记录数、列级统计信息如 min/max)。
特点:元数据按 “表→快照→文件” 分层,统计信息更细(支持列级过滤)。
二、版本管理规范:时间线与快照
版本管理是数据湖支持 “时间旅行” 和数据回溯的核心,两者的规范在版本定义、状态流转和保留策略上差异显著。
1. 版本定义与标识
| 维度 | Apache Hudi 规范 | Apache Iceberg 规范 |
|---|---|---|
| 版本核心概念 | 时间线(Timeline)上的 “Instant”:每个操作对应一个 Instant,由 “时间戳 + 操作类型” 标识(如 20240520103000_commit)。 | 快照(Snapshot):每个版本是一个 Snapshot,由全局唯一的 “快照 ID”(长整型)标识,关联一个或多个清单列表。 |
| 版本状态流转 | Instant 有明确的状态机:REQUESTED(请求)→ INFLIGHT(执行中)→ COMPLETED(完成)/FAILED(失败)。仅COMPLETED状态的 Instant 为有效版本。 | 快照无状态流转,创建后即不可变(Immutable),新版本通过生成新快照实现,旧快照保留至过期。 |
| 版本关联关系 | 时间线按时间戳有序排列,版本间是线性关系(后一个 Instant 依赖前一个的状态)。 | 快照间可并行(如分支场景),通过 “序列号(Sequence Number)” 保证线性一致性(用于并发写冲突处理)。 |
2. 版本保留与清理
Hudi 规范:通过配置保留策略(如保留最近 N 个版本、保留 N 天内版本),清理旧版本时直接删除对应的 Delta Log 和数据文件。支持 “保存点(Savepoint)” 机制,标记关键版本为永久保留(不被自动清理)。
Iceberg 规范:通过 “过期快照(Expire Snapshots)” 操作清理旧版本,删除快照关联的清单文件和数据文件(仅当数据文件无快照引用时)。支持 “分支(Branch)” 和 “标签(Tag)”,可将快照关联到分支 / 标签实现长期保留。
三、事务与一致性规范
两者均通过规范保证 ACID 事务,但事务边界、冲突处理和一致性模型不同。
1. 事务边界与提交
Hudi 规范:事务以 “Instant” 为单位,一个 Instant 对应一次原子操作(如一批 UPSERT)。提交过程:1. 生成新的 Instant(状态为
REQUESTED);2. 执行数据写入(生成新数据文件);3. 写入 Delta Log 记录(状态改为COMPLETED),事务完成。特点:事务提交是 “单阶段”,依赖 Delta Log 的原子写入(如 HDFS 的 rename 原子性)。
Iceberg 规范:事务以 “快照创建” 为单位,提交过程:1. 基于当前快照生成新的数据文件和清单文件;2. 创建新快照(关联新清单列表);3. 原子更新表元数据(指向新快照),事务完成。特点:事务提交是 “多阶段”,通过表元数据的原子更新保证最终一致性。
2. 冲突处理机制
Hudi 规范:基于乐观锁,通过时间线的 “最后写入获胜” 原则处理冲突。若两个事务同时修改同一批数据,后完成的事务会覆盖先完成的(通过 Instant 时间戳判断)。支持 “并发控制级别” 配置(如
OPTIMISTIC_CONCURRENCY_CONTROL)。Iceberg 规范:基于快照隔离(Snapshot Isolation),通过 “序列号” 检测冲突。每个事务开始时读取当前快照的序列号,提交时若发现序列号被其他事务修改(即有并发写),则提交失败(需重试)。支持 “行级冲突检测”(通过删除文件记录冲突行)。
四、数据文件与布局规范
数据文件的组织方式直接影响读写性能,两者的规范在文件格式、更新方式和分区策略上有明显差异。
1. 数据文件格式与更新
| 维度 | Apache Hudi 规范 | Apache Iceberg 规范 |
|---|---|---|
| 支持的文件格式 | 主要支持 Parquet(默认)、ORC,不支持 Avro 作为数据文件(仅用于元数据)。 | 支持 Parquet、ORC、Avro,且对每种格式定义了严格的读写规范(如 Parquet 的列映射)。 |
| 更新机制 | 定义两种更新模式:- CoW(写时复制):更新时重写整个数据文件;- MoR(读时合并):更新数据写入日志文件(.log),读时合并基文件与日志。 | 统一通过 “删除文件(Delete File)” 实现更新:- 标记删除:删除文件记录待删除行的位置(如 Parquet 的 RowGroup+Offset);- 替换更新:通过新数据文件 + 删除文件组合实现。 |
| 小文件处理 | 通过 Clustering 规范定义小文件合并策略(基于文件数 / 大小 / 时间触发)。 | 无内置 Clustering 规范,依赖外部工具(如 Spark 的 RewriteDataFiles)合并小文件,通过清单文件的统计信息优化扫描。 |
2. 分区与分桶规范
Hudi 规范:- 分区:支持多级分区(如
dt=20240520/city=beijing),分区键在表创建时指定,元数据中记录分区路径与数据文件的映射;- 分桶:支持按主键分桶(hoodie.bucket.index.enable=true),用于优化更新定位(减少文件扫描范围)。Iceberg 规范:- 分区:支持 “隐藏分区”(分区键不显示在表 Schema 中)和 “转换分区”(如按
event_time的day()分区),元数据中通过 “分区规范(Partition Spec)” 定义分区逻辑;- 分桶:支持按列分桶(bucket(column, N)),分桶信息记录在表元数据中,用于优化 JOIN 性能(减少数据 Shuffle)。
五、索引规范
索引用于加速数据定位(如更新时找到目标文件),两者的索引规范在类型、存储和适用场景上差异显著。
| 维度 | Apache Hudi 规范 | Apache Iceberg 规范 |
|---|---|---|
| 核心索引类型 | 1. 布隆索引(默认):元数据中记录每个文件的布隆过滤器(基于主键);2. 全局索引:跨分区的主键→文件映射表(如 HBase/MySQL);3. 简表索引:基于文件路径的轻量映射。 | 1. 位置索引:通过删除文件记录行位置(隐含索引,无需额外存储);2. 二级索引:支持布隆索引、Bitmap 索引(记录列值→文件的映射,存储在单独的索引文件中);3. 分区剪枝:基于清单文件的分区统计信息快速过滤。 |
| 索引存储位置 | 布隆索引嵌入数据文件的元数据(Parquet 的 Footer);全局索引存储在外部系统。 | 二级索引存储在metadata/indexes目录下,与数据文件解耦;位置索引隐含在删除文件中。 |
| 索引更新机制 | 布隆索引随数据文件更新(CoW 模式重写,MoR 模式在 Compaction 时更新);全局索引需同步写入外部系统。 | 二级索引随数据文件异步更新(通过RewriteIndex操作);位置索引随删除文件创建自动更新。 |
六、Schema 演进规范
Schema 演进是数据湖适应业务变化的核心能力,两者均支持 Schema 变更,但规范中的操作范围和兼容性保证不同。
| 维度 | Apache Hudi 规范 | Apache Iceberg 规范 |
|---|---|---|
| 支持的变更类型 | 支持:添加字段、删除字段(软删除)、字段重命名、类型兼容变更(如 int→long)。不支持:类型不兼容变更(如 string→int)、字段顺序调整(可能导致读写异常)。 | 支持:添加字段、删除字段(逻辑删除)、字段重命名、类型兼容变更、类型不兼容变更(需显式声明allow-incompatible)、字段顺序调整(通过 ID 映射,与顺序无关)。 |
| 兼容性保证 | 基于 “写入 Schema 必须兼容读取 Schema”,依赖用户保证变更兼容性(无严格校验)。 | 基于 “Schema ID + 字段 ID” 实现强兼容性:每个字段有唯一 ID,读写通过 ID 映射(与名称 / 顺序无关),支持严格的兼容性校验(如禁止删除已被数据引用的字段)。 |
| 元数据记录方式 | Schema 变更记录在 Delta Log 中,仅保留最新 Schema(历史 Schema 需通过版本回溯推导)。 | 每个快照关联一个 Schema ID,表元数据中保留所有历史 Schema(按 ID 存储),可直接回溯任意版本的 Schema。 |
七、规范的开放性与生态适配
Hudi 规范:元数据格式(Delta Log)为 JSON,易于解析,但规范文档较简洁(更多依赖代码实现)。生态适配以 Spark、Flink 为主,对 Trino、Presto 的支持需依赖社区插件,规范对计算引擎的绑定较强(如 MoR 模式的合并逻辑依赖引擎实现)。
Iceberg 规范:元数据格式(Avro 序列化)和操作流程定义极为详细(Apache 官方规范文档超过 100 页),强调 “计算引擎无关”,支持 Spark、Flink、Trino、Presto 等多引擎无缝对接,规范的开放性和中立性更强(不绑定特定引擎)。
总结:核心异同点
| 维度 | 相同点 | 不同点 |
|---|---|---|
| 元数据 | 均通过元数据管理数据文件和版本 | Hudi 是扁平时间线 + Delta Log;Iceberg 是树状层级 + 快照 + 清单文件 |
| 版本管理 | 支持多版本和时间旅行 | Hudi 基于 Instant 时间线;Iceberg 基于快照 + 序列号,支持分支 |
| 事务 | 保证 ACID,支持原子提交 | Hudi 乐观锁 + 单阶段提交;Iceberg 快照隔离 + 多阶段提交,冲突检测更严格 |
| 数据更新 | 支持 UPSERT/DELETE | Hudi 分 CoW/MoR 模式;Iceberg 基于删除文件统一实现 |
| 索引 | 支持加速数据定位的索引机制 | Hudi 侧重主键索引(布隆 / 全局);Iceberg 侧重二级索引和位置索引 |
| Schema 演进 | 支持基本的字段增删改 | Iceberg 支持更灵活的变更(如类型不兼容、顺序调整),通过 ID 保证强兼容性 |
| 开放性 | 均开源,支持主流存储系统 | Iceberg 规范更中立、详细,多引擎适配更好;Hudi 规范更简洁,绑定流处理场景 |
从规范设计看,Hudi 更侧重 “流批一体的增量更新”(规范围绕时间线和低延迟写入优化),而 Iceberg 更侧重 “通用湖仓的强一致性与多引擎兼容”(规范围绕快照隔离和严格的元数据分层设计)。