CS144 Lab:Lab0
CS144的github官方环境每年都重置,所有要做往年版本的话只能去找别人的github仓库回滚。我这里找的是这位大佬的CS144 Lab:Lab0 – LRL52 的博客。这里克隆老哥的仓库后,回滚至最初的版本,这里的每个分支都是一个干净的实验环境,并且实验lab0说明书也说了每次工作都是在原有工作基础上做的,所以每次试验前,将该实验的分支合并到主分支,在主分支上实现即可。
Fetch a Web page
这个实验就是通过命令行的形式体验可靠字节流,体验和浏览器访问资源同样的效果。
直接在浏览器中输入http://cs144.keithw.org/hello,可以访问到Hello CS144!的字样,如下图
接下来体验用命令行的形式体验:
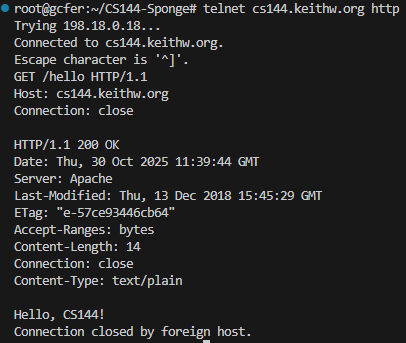
1.在系统终端输入telnet cs144.keithw.org http。talnet是一个古老的网络命令,以前用来连接服务器和远程登陆,但由于其明文传输安全性太低的特性被淘汰,现在更多用SSH远程登陆服务器。现在更多只用来测试某网站某端口是否开放等。该命令的具体内容是和一个名为cs144.keithw.org的计算机的http端口上建立一个可靠字节流。
2.继续在终端键入GET /hello HTTP/1.1(动作要快,建议复制粘贴。因为建立连接后长时间不发送服务器端会断开连接)。连接之后我们要发送HTTP请求,一个完整的HTTP请求至少包括请求行和Host头,并以空行结束。这是请求行,GET是方法,/hello是资源路径即URL,HTTP/1.1是协议版本。
3.继续在终端键入Host: cs144.keithw.org(同理动作要快,建议复制粘贴)。这是HTTP请求的请求头,具体含义是告知Web服务器需要访问哪个网站(原因是一个IP地址可能托管多个网站,需要Host头显示告知需要访问哪个)。
4.随后键入Connection: close(同理,快),告知服务器你结束了请求,并且在他响应请求之后应该结束连接。
5.注意,这里还需要额外的打一个空行,表示HTTP请求服务结束。随后便可以收到对方发送收到请求的消息,并最终传回我们需要的资源,最终展示Hello CS144!的字样,如下图:
第二个互动即Send yourself an email没有做,需要有Stanford的邮箱。
Listening and connecting
第一个互动是体验客户端,这次是体验服务器端的互动。
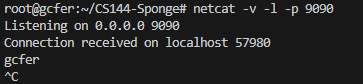
这个互动比较简单,在一个终端输入netcat -v -l -p 9090。整体是一个监听命令,netcat收是“网络瑞士军刀”一个简单的Unix工具用于读取和写入网络连接,是-v表示详细模式,-l表示listen接听,-p 9090表示指定端口9090)。
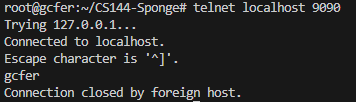
再开另一个终端输入telnet localhost 9090,此时两个终端就通过localhost:9090建立了可靠的字节流。此时在一端输入什么,另一端会同步出现(需要回车去结束你的输入)。最后用ctrl + C结束服务器端,客户端也会结束。
服务器端:
客户端:
配置开发环境
按照文档要求来,出现问题->问大模型,解决问题。
首先编译构建开始代码:
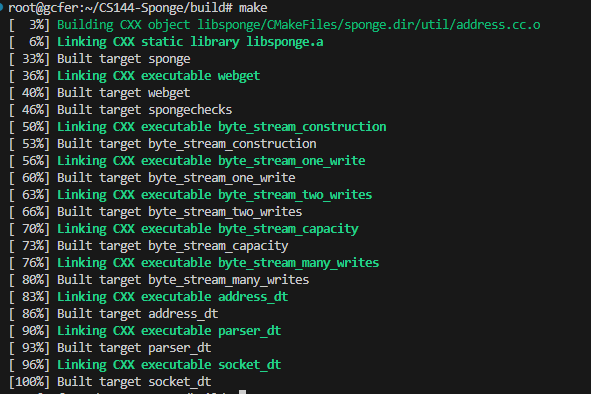
代码用现代C++的风格进行编写,基本思想是每个对象都被设计为具有尽可能小的公共接口。具有大量的内部检查,并且知道如何自我清理,避免操作的配对。(如:malloc/free、new/delete等)还有很多现代C++风格的建议,比如不要使用malloc/free、new/delete;不要使用普通指针,要使用智能指针(仅在必要时使用);避免模板、线程、锁和虚函数等;避免C语言的字符串,用C++提供的字符串std::string;不要使用C风格的强制转换,必要的话采用C++静态强制转换static_cast;更喜欢通过常量引用传递函数参数,将变量和方法设置为常量;避免使用全局变量,对每个变量赋予最小范围;遵循RAII(Resource Acquisition Is Initialization)原则,即资源的获取与初始化绑定,资源的释放与对象的销毁绑定。
Weget
这个实验主要是熟悉TCP的socket(套接字)来执行之前Fetch a Web page的命令。如下所示:
void get_URL(const string &host, const string &path) {// Your code here.// You will need to connect to the "http" service on// the computer whose name is in the "host" string,// then request the URL path given in the "path" string.// Then you'll need to print out everything the server sends back,// (not just one call to read() -- everything) until you reach// the "eof" (end of file).TCPSocket sock; //创建一个TCP的套接字sock.connect(Address(host, "http")); //和host进行连接sock.write("GET " + path + " HTTP/1.1\r\n"); //之后编写HTTP请求,格式类似之前sock.write("Host: " + host + "\r\n"); sock.write("Connection: close\r\n");sock.write("\r\n");sock.shutdown(SHUT_WR); while(!sock.eof()) {cout << sock.read();}sock.close();// cerr << "Function called: get_URL(" << host << ", " << path << ").\n";// cerr << "Warning: get_URL() has not been implemented yet.\n";
}比较坑的点,这里测试时需要先执行以下两个命令,目的是取出webget_t.sh中的'\r',这里是windows和Unix系统之间的差别。
tr -d '\r' < ../tests/webget_t.sh > ../tests/webget_t2.sh tr -d '\r' < ../tests/webget_t2.sh > ../tests/webget_t.sh
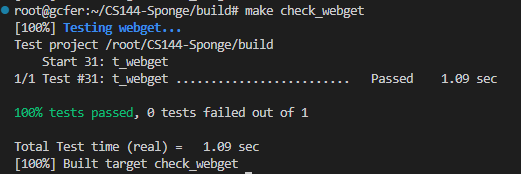
之后再执行make check_wbget即可,测试截图如下:
Byte Stream
这个实验的大概意思是在内存中用一个对象实现一个字节流(接下来的实验就是在网络中实现字节流)。有写入器,有流的容器还有读取器,具体还有很多要求,要保证流的长度>容器大小等。
总的实现采用了STL中的Vector,用两个变量表示读取和写入端,通过对容量取模实现环形队列,具体代码如下:
ByteStream类中添加私有成员如下:
class ByteStream {private:// Your code here -- add private members as necessary.//缓冲区,用vector确定std::vector<char> _buffer{};//容器容量,用常量固定const size_t _capacity;//读指针size_t _buffer_read{};//写指针,初始时两者相等都为0,write指向第一个空的位置,read指向第一个读的位置,两者相等时容器为空size_t _buffer_write{};//剩余空的容量,这里在构造函数处初始化。size_t _buffer_remain; //写入方是否结束。bool _end{};//总共写和读的数量。size_t _tot_read{};size_t _tot_write{};// Hint: This doesn't need to be a sophisticated data structure at// all, but if any of your tests are taking longer than a second,// that's a sign that you probably want to keep exploring// different approaches.bool _error{}; //!< Flag indicating that the stream suffered an error.
}函数实现如下:
#include "byte_stream.hh"// Dummy implementation of a flow-controlled in-memory byte stream.// For Lab 0, please replace with a real implementation that passes the
// automated checks run by `make check_lab0`.// You will need to add private members to the class declaration in `byte_stream.hh`template <typename... Targs>
void DUMMY_CODE(Targs &&... /* unused */) {}using namespace std;//构造函数用初始化列表进行初始化
ByteStream::ByteStream(const size_t capacity) :_buffer(capacity), _capacity(capacity), _buffer_remain(capacity) {}//往流中写一个字符串
size_t ByteStream::write(const string &data) {size_t count = 0; //统计写了多少个size_t lop_ct = min(data.length(), _buffer_remain);_tot_write += lop_ct;//能写的情况下尽可能的写,写不下的直接抛弃。while (count < lop_ct) {_buffer[_buffer_write] = data[count];_buffer_write = (_buffer_write + 1) % _capacity;_buffer_remain--;count++;}return count;
}//读取端拿出len个
//! \param[in] len bytes will be copied from the output side of the buffer
string ByteStream::peek_output(const size_t len) const {std::string output;size_t count = 0, lop_ct = min(len, _capacity - _buffer_remain);//注意这里的循环条件,应该是读取的长度和剩余个数取minwhile(count < lop_ct) {output.push_back(_buffer[(_buffer_read + count)%_capacity]);count++;}return output;
}//读取段删除len个,读取指针往前移动len个
//! \param[in] len bytes will be removed from the output side of the buffer
void ByteStream::pop_output(const size_t len) { size_t count = 0;size_t lop_ct = min(len, _capacity - _buffer_remain);_tot_read +=lop_ct;while(count < lop_ct){_buffer_read = (_buffer_read + 1)%_capacity;count++;_buffer_remain++;}
}//读取len个并删除,在读取的同时移动读取指针即可。
//! Read (i.e., copy and then pop) the next "len" bytes of the stream
//! \param[in] len bytes will be popped and returned
//! \returns a string
std::string ByteStream::read(const size_t len) {std::string output;size_t count = 0, lop_ct = min(len, _capacity - _buffer_remain);_tot_read += lop_ct;//注意这里的循环条件,应该是读取的长度和剩余个数取minwhile(count++ < lop_ct) {output.push_back(_buffer[_buffer_read]);_buffer_read = (_buffer_read + 1)%_capacity;_buffer_remain++;}return output;
}//写入方是否结束,用bool标记即可。
void ByteStream::end_input() {_end = true;
}//询问写入放是否结束。
bool ByteStream::input_ended() const { return _end;
}//当前能够读取的最大数量,用总容量-剩余容量=当前容量中有的个数
size_t ByteStream::buffer_size() const {return _capacity - _buffer_remain;
}//当前容器是否为空,用剩余容量是否为容器容量判断即可
bool ByteStream::buffer_empty() const { return _buffer_remain == _capacity ? true : false;
}//是否到文件末尾,需要写方结束并且剩余为0
bool ByteStream::eof() const { if(_end && _buffer_remain == _capacity) return true;return false;
}//一共写的个数
size_t ByteStream::bytes_written() const { return _tot_write;
}//一共读的个数
size_t ByteStream::bytes_read() const { return _tot_read;
}//剩余容量直接返回
size_t ByteStream::remaining_capacity() const {return _buffer_remain;
}
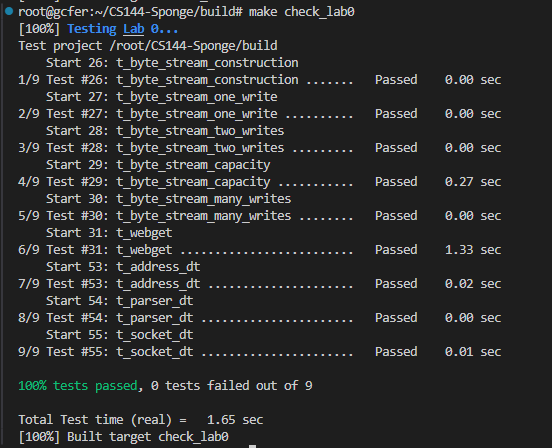
最后成功截图如下:
现代C++特性学习
- C++中类的声明和函数实现一般是分开的,类的声明一般在XXX.h中,其中只有极少数简单的函数会直接实现,大部分函数都在XXX.cpp中。在.cpp中需要包含.h文件即include "XXX.h"即可。其中<>主要包含标准库或系统级头文件,编译器只会在预定的系统目录中查找头文件。" "则主要包含自定义的头文件,编译器会首先在当前源文件所在目录查找,随后在用户包含路径中查找,最后在系统目录中查找。两种的区别便于区分是自定义还是标准库中的函数。
- 在cpp中的函数实现方式为返回类型 类名::函数名(参数列表){函数实现}。这里的::为作用域解析运算符,即告诉编辑器这里实现的函数名是哪个类的。
- 拓展:std命名空间。C++的标准库(Standard Library)中的所有组件(string类、cout对象、vector容器等)都被封装在一个名为std的命名空间。命名空间主要用于避免名称冲突,通过使用std::string才能明确引用标准库的字符串类。两种不需要每次都是用std::的方法(极其不推荐,每次都是用std::是最标准的方法):使用using namespace std;(OI/ACM的基因动了。。。),该方法会把std中的所有组件命名导入,但会污染该头文件的全局命名空间;使用using std::string;只引入string这个命名,较为安全。
- 在64位系统上,long和long long没区别,unsigned long 和unsigned long long没区别。long long和unsigned long long都是C++11引入的,追求最高移植性使用这两个;在系统编程中通常使用unsigned long(32为系统为unsigned int)表示内存地址、大小或与系统API交互(size_t为其别名)。
- 类成员一般_类成员名或者m_类成员名,表示其作为类成员,且权限为private或者protect。
- 类成员初始化:(1)类内初始化器,在类成员的定义中后跟{},表示该类型数据初始化为零值(类类型则为默认构造函数)。如size_t _buffer_read{};和std::vector<char> _buffer{};(2)构造函数初始化列表。在类的构造函数参数列表后跟:成员函数名(初始化值),...,成员函数名(初始化值){构造函数实现;} 例子如下:
ByteStream::ByteStream(const size_t capacity) :_buffer(capacity), _capacity(capacity), _buffer_remain(capacity) {}(3)构造函数内部赋值。这就不多说了。(4)需要注意的是常量(const修饰),只能被初始化不能被赋值,1,2都属于初始化,(静态常量例外,即可以在类内使用赋值语句赋初值)3属于赋值语句。(5)构造优先级,会先采取1即类内初始化器,后采取2初始化列表,最后采取构造函数内部赋值。
-
const成员函数,在成员函数参数列表之后,具体实现{}之间可以加const关键词,表示该函数是一个“只读”函数,不会修改对象的任何非静态数据成员。对于编译器而言,他会将this指针修改为常量指针,即不允许你修改非静态数据。
-
C++类型的string或者C类型的char*都是以'\0'结尾,C类型强制以这个结尾,C++为了和C兼容也有这个规定,但可以直接使用其内部成员函数更方便。