数据结构:单链表(2)
前言
上篇文章讲解了单链表的知识,包括:单链表的概念,单链表的结构、实现单链表(单链表的尾插、单链表的头插、单链表的尾删、单链表的头删)知识的相关内容,实现单链表其余的函数、链表的分类、单链表算法题知识的相关内容,为本章节知识的内容。
一、实现单链表
介绍:
1.链表节点查找
在链表中查找节点是基础操作,核心目标是根据指定条件(如值匹配)定位目标节点,本函数以值匹配作为条件:
函数形式:
SListNode* SLTFind(SListNode* h, type x)
代码实现为:
SListNode* SLTFind(SListNode* h, type x)
{SListNode* p = h;while (p){if (p->data == x){return p;}p = p->next;}return NULL;
}讲解:
函数参数:
SListNode* h:指向单链表头节点的指针。type x:要查找的值,type是一个泛型类型,可以是任意数据类型。函数返回值:
- 如果找到了值为
x的节点,则返回指向该节点的指针。- 如果没有找到,则返回
NULL。函数实现步骤:
- 初始化一个指针
p,并将其指向链表的头节点h。- 使用
while循环遍历链表,只要p不为NULL,就继续循环。- 在循环内部,检查当前节点
p的数据p->data是否等于要查找的值x。- 如果相等,则返回当前节点的指针
p。- 如果不相等,则将
p指向下一个节点,继续循环。- 如果遍历完整个链表都没有找到值为
x的节点,则返回NULL。
简单来说:如果找到对应的元素,返回指针,找不到就返回空。
2.链表在指定位置之前或之后插入元素
(1)链表在指定位置之前插入元素
函数形式:
void SLTInsert(SListNode** h, SListNode* pos, type x)
代码实现为:
void SLTInsert(SListNode** h, SListNode* pos, type x)
{if (h == NULL || pos == NULL||*h == NULL){printf("前插入失败\n");return;}if (*h == pos){SLTPushFront(h, x);return;}SListNode* p = *h;while (p!=NULL&&p->next != pos){p = p->next;}if (p){
SListNode* newnode = SLTBuyNode(x);newnode->next=pos;p->next=newnode ;}else{printf("没有找到该节点\n");return;}
}讲解:
// 1. 边界条件检查(避免无效操作) if (h == NULL || pos == NULL || *h == NULL)// 2. 特殊情况:pos是头节点 → 直接调用头插函数if (*h == pos){SLTPushFront(h, x);return;}// 3. 遍历链表,找pos的前驱节点p SListNode* p = *h; while (p != NULL && p->next != pos) {p = p->next; }// 4. 根据p是否存在,决定插入或报错 if (p) // p存在(pos在链表中)→ 执行插入 {SListNode* newnode = SLTBuyNode(x); // 创建新节点newnode->next = pos; // 新节点连接posp->next = newnode; // 前驱p连接新节点 } else // p不存在(pos不在链表中)→ 报错 {printf("没有找到该节点\n");return; } }为什么这两步不可颠倒?
若先执行p->next = newnode,会丢失pos的地址(p->next原指向pos),导致无法将newnode->next连接到pos。
插入之后的图示:
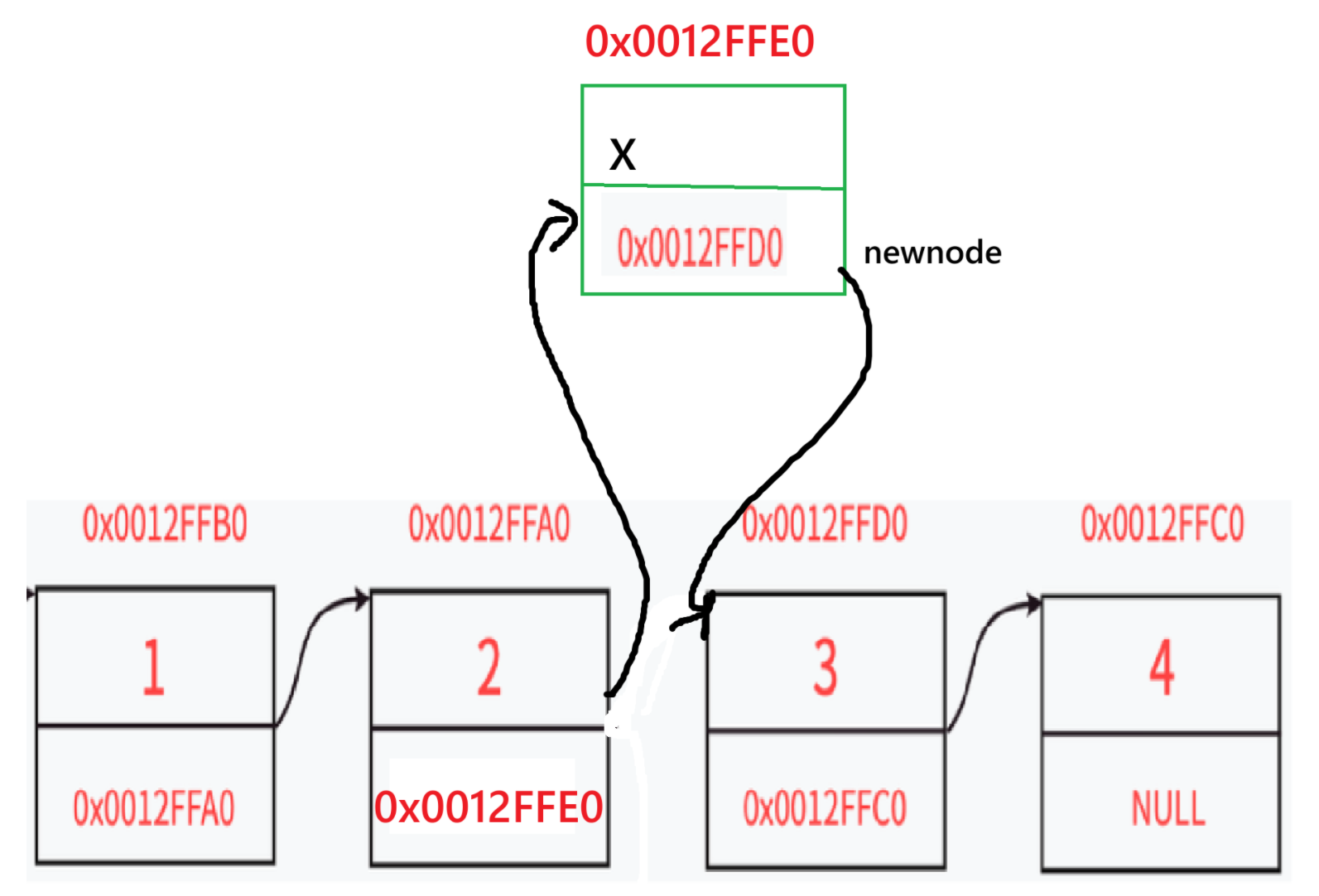
举实例:
首先操作的代码:
1.新用到的函数:
SListNode* SLTFind(SListNode* h, type x)
{SListNode* p = h;while (p){if (p->data == x){return p;}p = p->next;}return NULL;
}
void SLTInsert(SListNode** h, SListNode* pos, type x)
{if (h == NULL || pos == NULL||*h == NULL){printf("前插入失败\n");return;}if (*h == pos){SLTPushFront(h, x);return;}SListNode* p = *h;while (p!=NULL&&p->next != pos){p = p->next;}if (p){
SListNode* newnode = SLTBuyNode(x);newnode->next=pos;p->next=newnode ;}else{printf("没有找到该节点\n");return;}
}2.示例代码:
#include"1.h"
void test2()
{SListNode* h=NULL;SLTPushBack(&h, 10); //10SLTPushBack(&h, 20); //10 20SLTPrint(h);SLTPushFront(&h, 30); // 30 10 20SLTPushFront(&h, 40); // 40 30 10 20SLTPrint(h);SLTPopBack(&h); //40 30 10SLTPrint(h);SLTPopFront(&h); //30 10SLTPrint(h);SListNode *p=SLTFind(h, 10);if (p){printf("%d\n", p->data); //10}SLTInsert(&h, p, 1000);SLTPrint(h); //30 1000 10SListDestroy(&h);}
int main()
{test2();
}
(2)链表在指定位置之后插入元素
函数形式:
void SLTInsertAfter(SListNode* pos, type x)
代码实现为:
void SLTInsertAfter(SListNode* pos, type x)
{if (pos == NULL){printf("后插入失败\n");return;}SListNode* p = pos->next;SListNode* newnode = SLTBuyNode(x);newnode->next = p;pos->next = newnode;
}讲解:
函数核心逻辑(一句话总结)
在
pos节点后插入新节点,本质是“切断pos与原后继节点的连接,插入新节点作为pos的新后继”。
流程:
- 检查
pos是否有效 → 2. 保存pos原后继节点 → 3. 创建新节点 → 4. 新节点连接原后继 → 5.pos连接新节点。代码逐行深度解析
1. 边界条件检查
if (pos == NULL) { printf("后插入失败\n"); return; }
- 作用:
pos是插入位置的基准节点,若pos为空(无效),直接报错并返回,避免后续pos->next导致空指针崩溃。- 对比前插函数:后插无需检查头节点(
h或*h),因为插入位置由pos直接确定,与头节点无关。2. 保存
pos的原后继节点SListNode* p = pos->next; // p暂存pos原本的下一个节点
- 必要性:若不保存
pos->next,后续pos->next = newnode会覆盖原后继地址,导致链表断裂(原后继节点永久丢失)。- 类比:相当于搬家时先把“当前位置的下一个箱子”挪开,腾出空间放新箱子。
3. 创建新节点
SListNode* newnode = SLTBuyNode(x); // 假设SLTBuyNode已实现:分配内存+初始化数据
- 核心功能:动态申请新节点内存,并将数据
x存入新节点。- 注意:实际工程中需检查
newnode是否为NULL(内存分配失败),此处简化未展开。4. 连接新节点与原后继
newnode->next = p; // 新节点的next指向pos原本的后继p
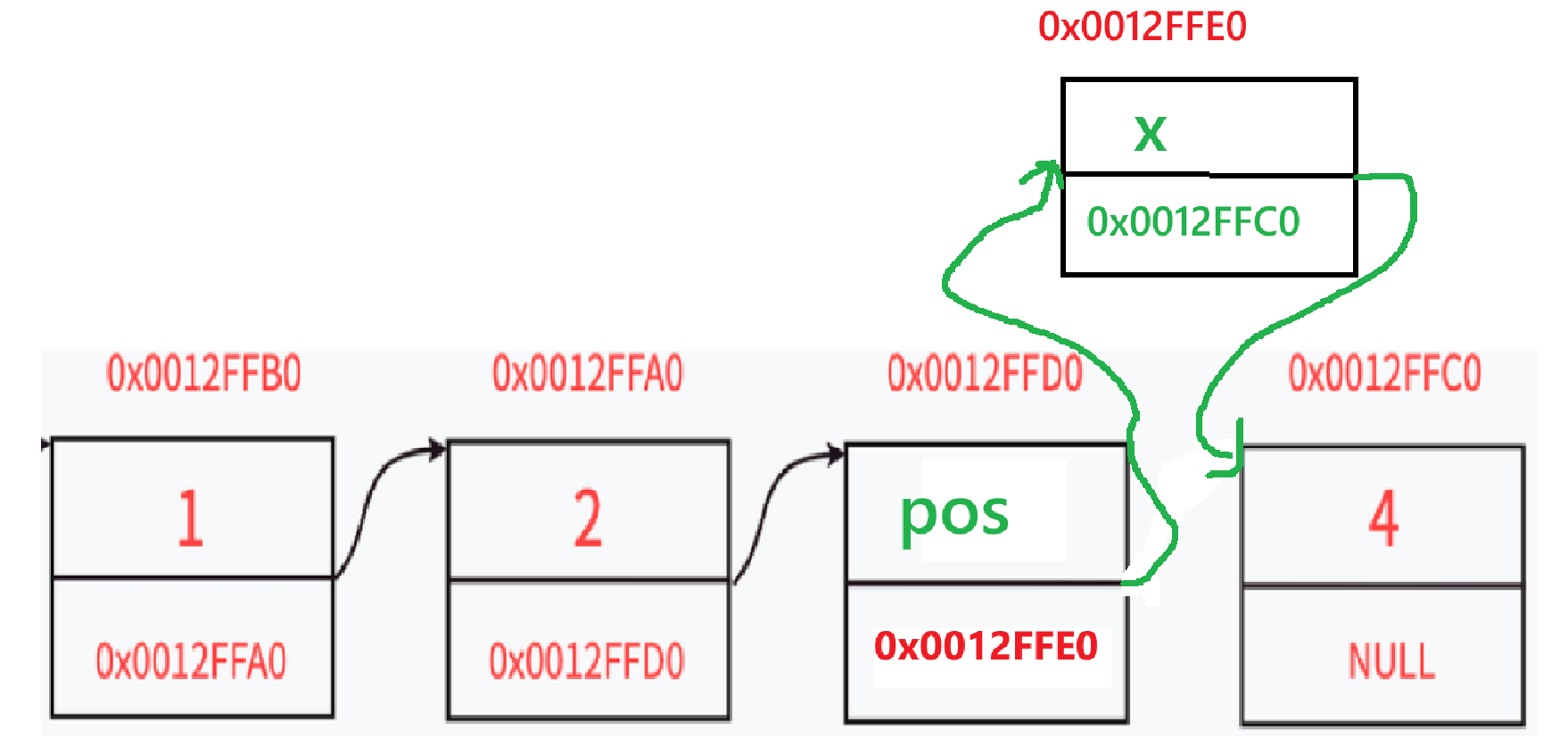
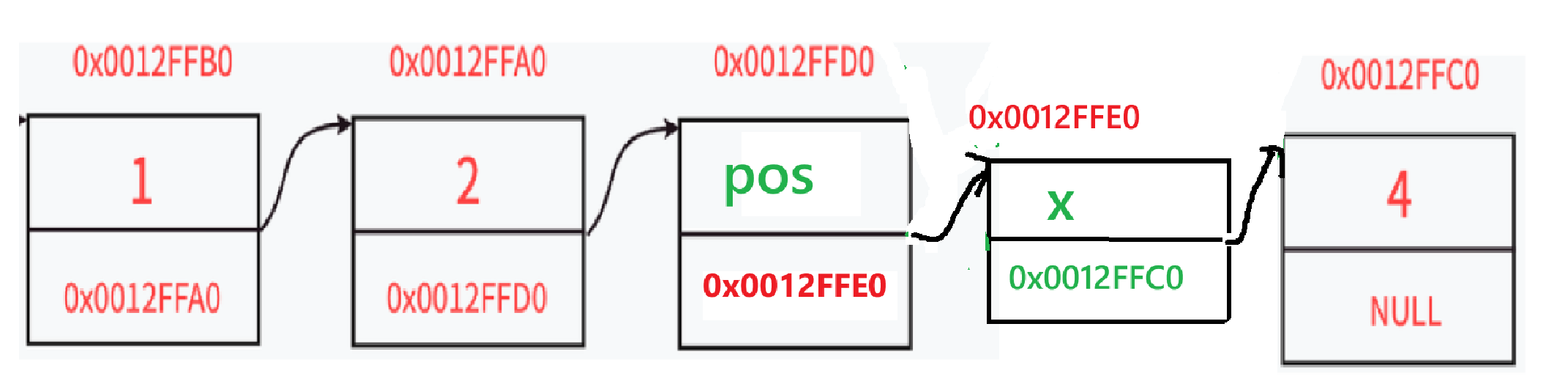
- 图示:
原链表:pos ——→ p ——→ ... 执行后:newnode ——→ p ——→ ...
5.
pos连接新节点(完成插入)pos->next = newnode; // pos的next指向新节点,新节点成为pos的直接后继
- 最终链表结构:
3.链表在指定位置删除或指定位置之后删除
(1)链表在指定位置删除
单链表删除指定位置节点包括 “删除指定节点 pos” 和 “删除第 n 个节点” 两种场景,删除第n个节点可通过循环来实现,而删除指定节点 pos较为复杂,所以,本文选取讲解删除指定节点 pos。
void SLTErase(SListNode** h, SListNode* pos)
具体代码:
void SLTErase(SListNode** h, SListNode* pos)
{if (h == NULL || *h == NULL || pos == NULL) {return; }if (pos == *h){SLTPopFront(h);}else{SListNode* p = *h;while (p != NULL && p->next != pos){p = p->next;}if (p == NULL){printf("没有该节点\n");return;}else{p->next = pos->next;free(pos);} }
}
讲解:
void SLTErase(SListNode** h, SListNode* pos) {// 前置过滤:空指针或空链表if (h == NULL || *h == NULL || pos == NULL) {return; }// 分支1:删除头节点 → 调用头删函数if (pos == *h) {SLTPopFront(h); // 头删后自动退出(无需显式return,因无后续代码)} // 分支2:删除中间/尾节点 → 找前驱+删除else { SListNode* p = *h;while (p != NULL && p->next != pos) { // 遍历找pos的前驱p = p->next;}if (p == NULL) { // 未找到pos节点printf("没有该节点\n");return;} else { // 找到前驱,执行删除p->next = pos->next;free(pos);}} }核心逻辑:分场景处理的底层原理
1. 分支1:删除头节点(
pos == *h)
- 触发条件:待删除节点
pos就是头节点(*h是头节点指针)。- 处理方式:调用
SLTPopFront(h),假设该函数实现如下(标准头删逻辑):void SLTPopFront(SListNode** h) {SListNode* tmp = *h; // 保存旧头节点*h = (*h)->next; // 更新头指针为下一个节点free(tmp); // 释放旧头节点内存 }- 为什么无需
return?
因if分支执行后,函数直接进入else分支或结束(无else时),当前代码通过else确保头删后不会执行后续遍历逻辑。2. 分支2:删除中间/尾节点(
pos != *h)
- 核心目标:找到
pos的 前驱节点p(即p->next == pos),通过修改p->next跳过pos节点。- 遍历逻辑:
SListNode* p = *h; // 从新头节点开始遍历(若头节点未删除) while (p != NULL && p->next != pos) {p = p->next; }
- 正常终止:
p->next == pos→ 找到前驱p,执行p->next = pos->next(切断pos节点)。- 异常终止:
p == NULL→ 遍历到链表尾仍未找到pos(pos不在链表中),打印提示并返回。边界场景:覆盖所有可能情况
场景 代码行为 空链表( *h == NULL)前置条件过滤,直接 return,无操作。删除头节点(唯一节点) pos == *h→ 调用SLTPopFront→*h变为NULL,链表为空。删除头节点(多节点) *h更新为原*h->next,旧头节点被释放,链表长度-1。删除尾节点 pos->next == NULL→p->next = NULL(p变为新尾节点),pos被释放。pos不在链表中遍历后 p == NULL→ 打印“没有该节点”,不修改链表。pos为中间节点p->next = pos->next→ 链表跳过pos,pos内存被释放。
(2)链表在指定位置之后删除
操作位删除 pos 节点的下一个节点(若 pos 是尾节点或链表为空,则不操作)。
- 删除单链表中
pos节点之后 的第一个节点(即删除pos->next)。 - 适用场景:需删除指定位置后续节点时使用(注意:不能删除头节点前的节点,也不能直接删除
pos自身)。
函数形式:
void SLTEraseAfter(SListNode* pos)
代码实现为:
void SLTEraseAfter(SListNode* pos)
{if (pos==NULL || pos->next == NULL){printf("不可删后节点\n");return;}SListNode* p = pos->next;pos->next = p->next;free(p);
}讲解:
void SLTEraseAfter(SListNode* pos) // 参数:指向目标节点的指针 pos {// 1. 边界条件判断:过滤无效删除场景if (pos == NULL || pos->next == NULL) // 两种不可删除的情况{printf("不可删后节点\n"); // 错误提示return; // 直接返回,不执行删除}// 2. 保存待删除节点的地址SListNode* p = pos->next; // p 指向 pos 的下一个节点(即要删除的节点)// 3. 修改指针:跳过待删除节点,维持链表连续性pos->next = p->next; // pos 的 next 指向 p 的下一个节点(切断与 p 的连接)// 4. 释放待删除节点的内存(避免内存泄漏)free(p); // 释放 p 指向的节点内存 }边界条件
if (pos == NULL || pos->next == NULL)的必要性
条件 含义 风险 pos == NULLpos是空指针(未指向任何节点)直接访问 pos->next会导致 空指针异常(崩溃)pos->next == NULLpos是链表的 尾节点尾节点没有后续节点,删除操作无意义
- 结论:两种情况均需提前拦截,避免程序崩溃或无效操作。
SListNode* p = pos->next; // 步骤1:用 p 暂存待删除节点地址
pos->next = p->next; // 步骤2:pos 直接指向 p 的下一个节点(链表"跳过" p)
free(p); // 步骤3:释放 p 指向的内存(避免内存泄漏)
三、举实例,测试代码(包括所有代码展现)
首先操作的代码,我分为三个文件所写,接下来,我将展示代码内容:
1.h
#include<stdio.h>
#include<stdlib.h>
typedef int type;
typedef struct SListNode
{type data;struct SListNode* next;
}SListNode;void SLTPrint(SListNode* h);
void SListDestroy(SListNode** h);
void SLTPushBack(SListNode** h, type x);
void SLTPushFront(SListNode** h, type x);
void SLTPopBack(SListNode** h);
void SLTPopFront(SListNode** h);
SListNode* SLTBuyNode(type x);
SListNode* SLTFind(SListNode* h, type x);
void SLTInsert(SListNode** h, SListNode* pos, type x);
void SLTInsertAfter(SListNode* pos, type x);
void SLTErase(SListNode** h, SListNode* pos);
void SLTEraseAfter(SListNode* pos);1.cpp
#include"1.h"
void SLTPrint(SListNode* h)
{if (h == NULL){printf("链表为空,无值\n");return;}SListNode* p = h;while (p){printf("%d ", p->data);p = p->next;}printf("\n");
}
void SListDestroy(SListNode** h)
{if (*h == NULL){printf("链表为空\n");return;}SListNode* p = *h;while(p){SListNode* q = p;p = p->next;free(q);}
}
SListNode* SLTBuyNode(type x)
{ SListNode* p = (SListNode*)malloc(sizeof(SListNode));if (p){p->data = x;p->next = NULL;return p;}else{perror("malloc failed"); return NULL; }
}
void SLTPushBack(SListNode** h, type x)
{SListNode* p = SLTBuyNode(x);if (*h == NULL){*h = p;}else{SListNode* pr = *h;while (pr->next){pr = pr->next;}pr->next = p;}
}
void SLTPushFront(SListNode** h, type x)
{SListNode* newnode = SLTBuyNode(x);if (*h == NULL){*h = newnode;}else{newnode->next = *h;*h = newnode;}
}
void SLTPopBack(SListNode** h)
{if (*h == NULL){return;}if ((*h)->next == NULL){free(*h);*h = NULL;}else{SListNode* p = *h;SListNode* pr = *h;while (p->next){pr = p;p = p->next;}free(p);pr->next = NULL;}
}
void SLTPopFront(SListNode** h)
{if (*h == NULL){return;}SListNode* p = (*h)->next;free(*h);*h = p;}
SListNode* SLTFind(SListNode* h, type x)
{SListNode* p = h;while (p){if (p->data == x){return p;}p = p->next;}return NULL;
}
void SLTInsert(SListNode** h, SListNode* pos, type x)
{if (h == NULL || pos == NULL||*h == NULL){printf("前插入失败\n");return;}if (*h == pos){SLTPushFront(h, x);return;}SListNode* p = *h;while (p!=NULL&&p->next != pos){p = p->next;}if (p){
SListNode* newnode = SLTBuyNode(x);newnode->next=pos;p->next=newnode ;}else{printf("没有找到该节点\n");return;}
}
void SLTInsertAfter(SListNode* pos, type x)
{if (pos == NULL){printf("后插入失败\n");return;}SListNode* p = pos->next;SListNode* newnode = SLTBuyNode(x);newnode->next = p;pos->next = newnode;
}
void SLTErase(SListNode** h, SListNode* pos)
{if (h == NULL || *h == NULL || pos == NULL) {return; }if (pos == *h){SLTPopFront(h);}else{SListNode* p = *h;while (p != NULL && p->next != pos){p = p->next;}if (p == NULL){printf("没有该节点\n");return;}else{p->next = pos->next;free(pos);} }
}
void SLTEraseAfter(SListNode* pos)
{if (pos==NULL || pos->next == NULL){printf("不可删后节点\n");return;}SListNode* p = pos->next;pos->next = p->next;free(p);
}
main.cpp
#include"1.h"
void test2()
{SListNode* h=NULL;SLTPushBack(&h, 10); //10SLTPushBack(&h, 20); //10 20SLTPrint(h);SLTPushFront(&h, 30); // 30 10 20SLTPushFront(&h, 40); // 40 30 10 20SLTPrint(h);SLTPopBack(&h); //40 30 10SLTPrint(h);SLTPopFront(&h); //30 10SLTPrint(h);SListNode *p=SLTFind(h, 10);if (p){printf("%d\n", p->data); //10}SLTInsert(&h, p, 1000);SLTPrint(h); //30 1000 10SListNode* q = SLTFind(h, 30);if (q){printf("%d\n", q->data); //30}SLTErase(&h, q);SLTPrint(h); // 1000 10SListDestroy(&h);}
int main()
{test2();
}
结果:

四、链表的分类
链表是一种动态数据结构,通过指针/引用连接节点,根据节点结构和连接方式可分为以下几类:
按节点连接方向分类
单链表(Singly Linked List)
- 结构:每个节点含 数据域 和 一个指针域(指向下一节点)。
- 特点:只能从表头向表尾遍历,插入/删除需修改前驱节点指针。
- 图示:
双链表(Doubly Linked List)
- 结构:每个节点含 数据域 和 两个指针域(前驱指针
prev和后继指针next)。- 特点:可双向遍历,插入/删除无需回溯前驱节点,但内存开销略大。
- 图示:
循环链表(Circular Linked List)
- 结构:尾节点指针指向头节点(单循环)或头节点前驱指向尾节点(双循环)。
- 特点:可从任意节点开始遍历,适合实现环形队列、约瑟夫问题等。
- 图示:
按是否有头节点分类
带头节点链表
- 结构:首节点为 头节点(不存储数据或存链表长度),后续为数据节点。
- 优势:统一空链表和非空链表的操作逻辑(无需单独处理头节点插入/删除)。
- 图示:
不带头节点链表
- 结构:首节点直接存储数据。
- 劣势:插入/删除首节点时需特殊处理(修改头指针)。
- 图示:

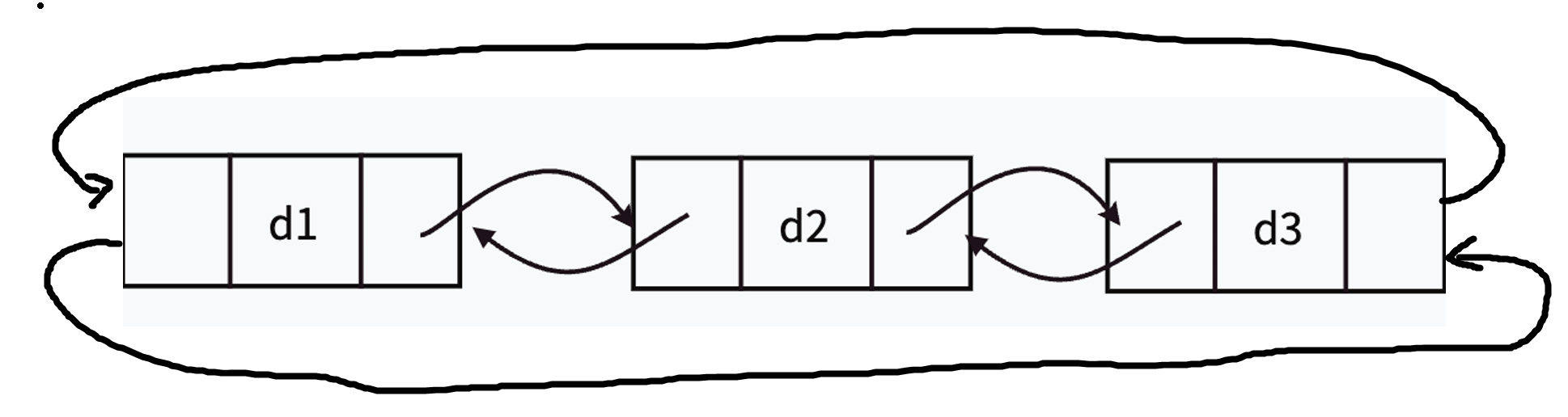


从上面讲解的类型中,我们可以总结一下:
链表的结构多样,总共能组合出来8种类型:
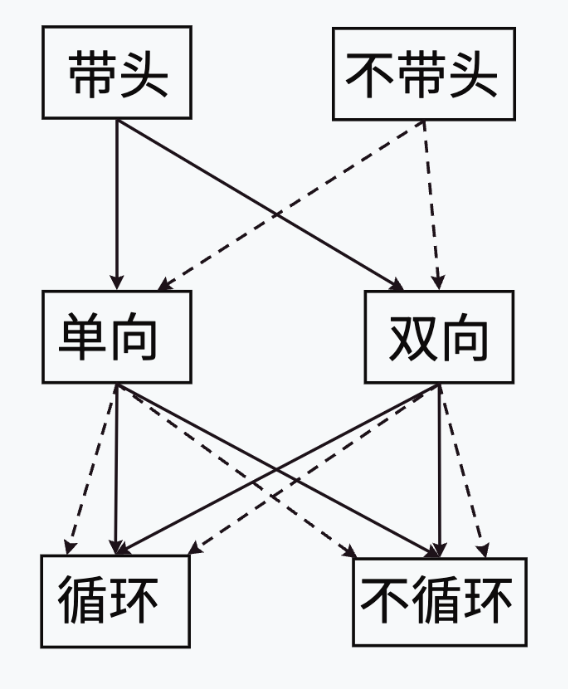
虽然链表的类型有很多种,但他们的结构体类型基本一样,都具有数据域和指针域两部分,根据上面的知识,我们可以得出本单链表为单向不带头不循环链表,而下篇文章,我将会讲解双向带头不循环链表,简称双链表,敬请期待。
总结
以上就是今天要讲的内容,本篇文章涉及的知识点为:实现单链表其余的函数、举实例,测试代码(包括所有代码展现)、链表的分类等知识的相关内容,为本章节知识的内容,希望大家能喜欢我的文章,谢谢各位,下篇文章,我将会讲解双向带头不循环链表,简称双链表,接下来的内容我会很快更新。
