spark读取table中的数据【hive】
- 场景:Hive底层默认是MR引擎,计算性能特别差,一般用Hive作为数据仓库,使用SparkSQL对Hive中的数据进行计算
- 存储:数据仓库:Hive:将HDFS文件映射成表
- 计算:计算引擎:SparkSQL、Impala、Presto:对Hive中的数据表进行处理
- 问题:SparkSQL怎么能访问到Hive中有哪些表,以及如何知道Hive中表对应的HDFS的地址?
Hive中的表存在哪里?元数据--MySQL , 启动metastore服务即可。
本质上:SparkSQL访问了Metastore服务获取了Hive元数据,基于元数据提供的地址进行计算
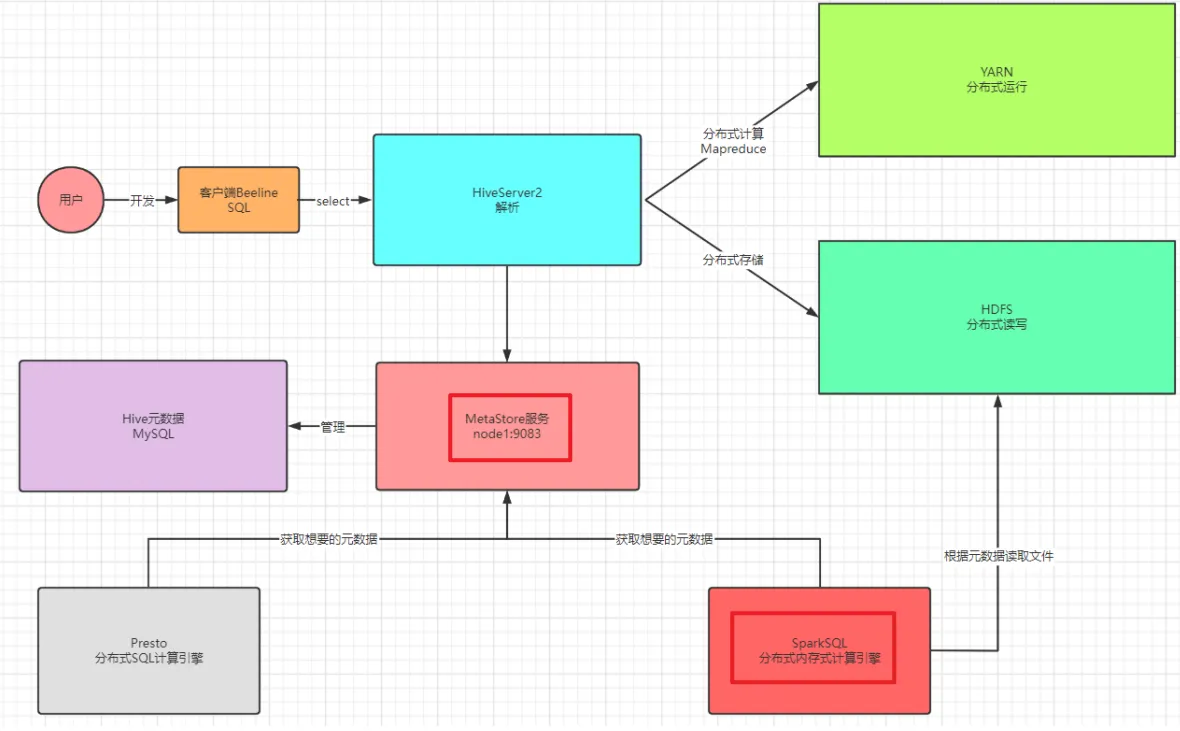
Spark读取Hive表数据
Apache Spark可以轻松集成Hive,通过Spark SQL直接读取Hive表中的数据。以下是逐步指南,确保操作结构清晰、可靠。假设您已配置好Spark和Hive环境(如Hive metastore服务可用),且Spark会话已正确初始化。
步骤1: 确保Spark与Hive集成
- 前提条件:
- Spark必须配置为使用Hive metastore。在
spark-defaults.conf文件中,设置spark.sql.catalogImplementation=hive。 - 确保Hive表已存在(例如,表名为
my_table)。
- Spark必须配置为使用Hive metastore。在
- 验证方法:在Spark应用中,初始化SparkSession时启用Hive支持。
步骤2: 初始化SparkSession并读取表
在Python代码中,使用pyspark库创建SparkSession,然后通过spark.sql()或spark.table()方法读取Hive表。以下是完整示例代码:
from pyspark.sql import SparkSession# 初始化SparkSession,启用Hive支持
spark = SparkSession.builder \.appName("ReadHiveTable") \.config("spark.sql.warehouse.dir", "/user/hive/warehouse") \ # Hive仓库路径,根据实际环境调整.enableHiveSupport() \ # 关键:启用Hive集成.getOrCreate()# 方法1: 使用spark.sql()执行SQL查询读取表
df_sql = spark.sql("SELECT * FROM my_table") # 替换"my_table"为您的表名# 方法2: 使用spark.table()直接读取表
df_table = spark.table("my_table")# 显示数据(可选,用于调试)
df_sql.show(5) # 显示前5行数据# 停止Spark会话(在应用结束时调用)
spark.stop()
代码说明
- 关键部分:
.enableHiveSupport():确保Spark能访问Hive metastore。.config("spark.sql.warehouse.dir", ...):指定Hive数据仓库路径,需匹配您的Hive配置。spark.sql("SELECT * FROM table_name"):通过SQL查询读取表,适合复杂操作。spark.table("table_name"):直接读取表对象,更简洁。
- 输出:
df_sql或df_table是DataFrame对象,可进行后续处理(如过滤、聚合)。
注意事项
- 常见错误:
- 如果表不存在,会抛出
AnalysisException。确保表名正确,且Hive metastore服务运行中。 - 权限问题:检查Spark用户是否有Hive表的读取权限。
- 配置路径:
spark.sql.warehouse.dir必须指向Hive的实际仓库目录(例如HDFS路径)。
- 如果表不存在,会抛出
- 优化建议:
- 对于大数据集,使用分区或过滤条件减少读取量,例如:
spark.sql("SELECT * FROM my_table WHERE partition_col = 'value'")。 - 在集群环境中,确保所有节点能访问Hive metastore(如通过Thrift服务)。
- 对于大数据集,使用分区或过滤条件减少读取量,例如:
如果遇到问题,请提供更多细节(如错误日志或环境配置),我可以进一步帮助您调试!