YOLO系列算法学习:YOLOv8:系列又一力作
完成了YOLOv5的学习,接下来我将继续解析YOLOv8,当然YOLO系列的学习我也计划在此处画上一个休止符,原因一是以为我认为到了YOLOv8之后的系列更新幅度就远远没有先前的大,只是在算子上和网络结构上进行微调,在我们掌握了YOLOv5、v8之后剩余的新系列实际上也就能快速入门只需要学习一些微小改进。另一方面,由于Transformer的存在,性能实在是拉爆了传统的CNN和RNN,Attention is all you need不是说说而已,所以Transformer的学习迫在眉睫之。在做完这一篇YOLOv8的学习后我们将马不停蹄地开启Transformer的学习!
背景介绍
YOLOv8是Ultralytics公司(发布yolov5的公司) 在YOLO系列基础上进行优化的结果,发布于2023年 1 月。它是当前 YOLO系列模型中最新且性能最强的一 款,具备更高的速度、准确性,并支持多任务
Backbone: 骨干网络和 Neck部分可能参考了 YOLOv7ELAN 设计思想,将 YOLOv5的 C3结构换成了梯度流更丰 富的 C2f结构,并对不同尺度模型调整了不同的通道 数。
Head: Head部分较yolov5而言有两大改进:
1)换成了目前主流的解耦头结构(Decoupled-Head), 将分类和检测头分离
2)同时也从 Anchor-Based换成了 Anchor-Free
Loss: YOLOv8抛弃了以往的IOU匹配的分配方式,而是 使用了Task-AlignedAssigner (TAA)正负样本匹配方式。 并引入了 DistributionFocalLoss(DFL)
YOLOv8的整体网络结构
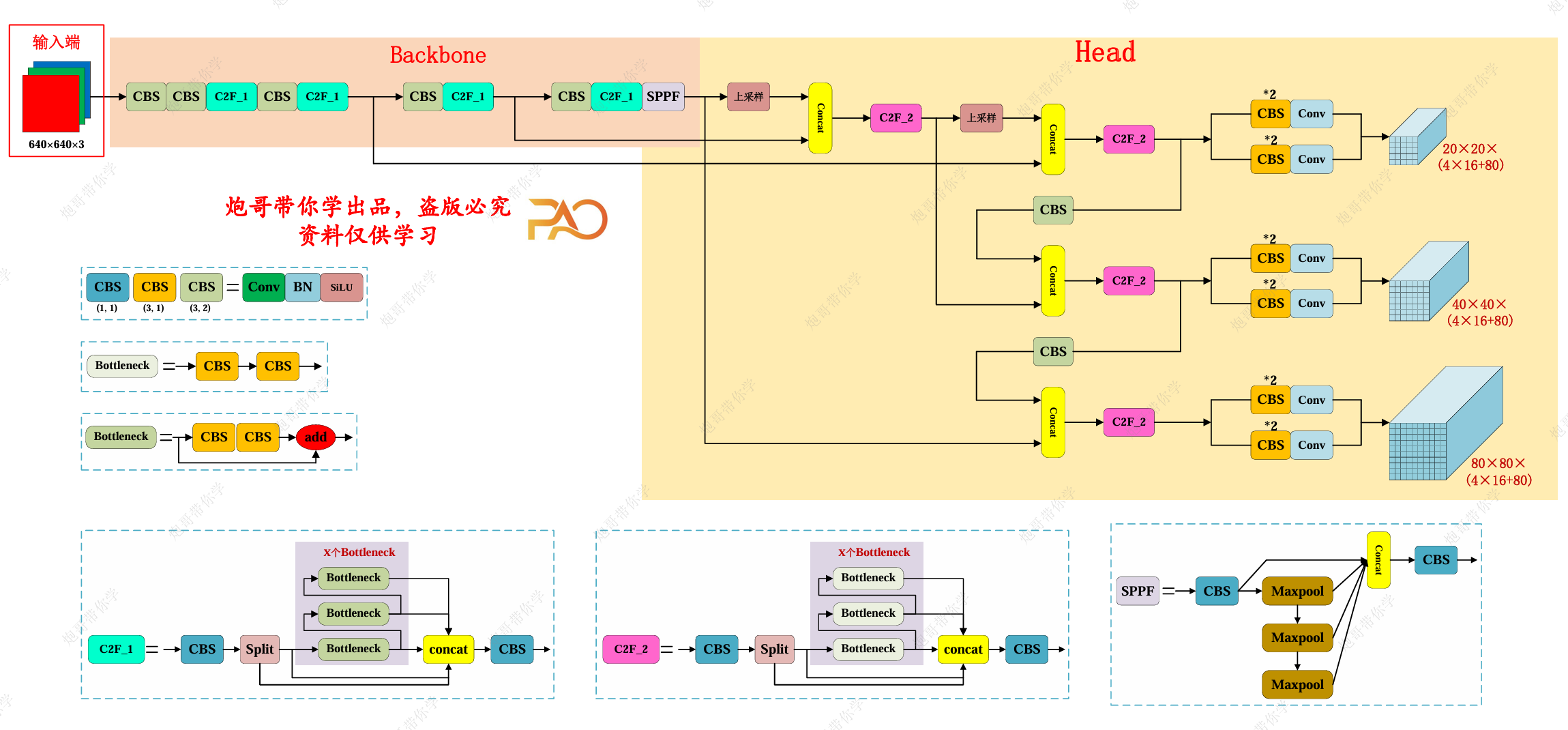
我们来对比一下YOLOv5的结构:

可以看到整体来说变化不太大,尤其对于Backbone部分而言,所做的更新只有算子的变化而主要的变化集中在Head部分,下面我们详细展开说说:
Bottleneck:
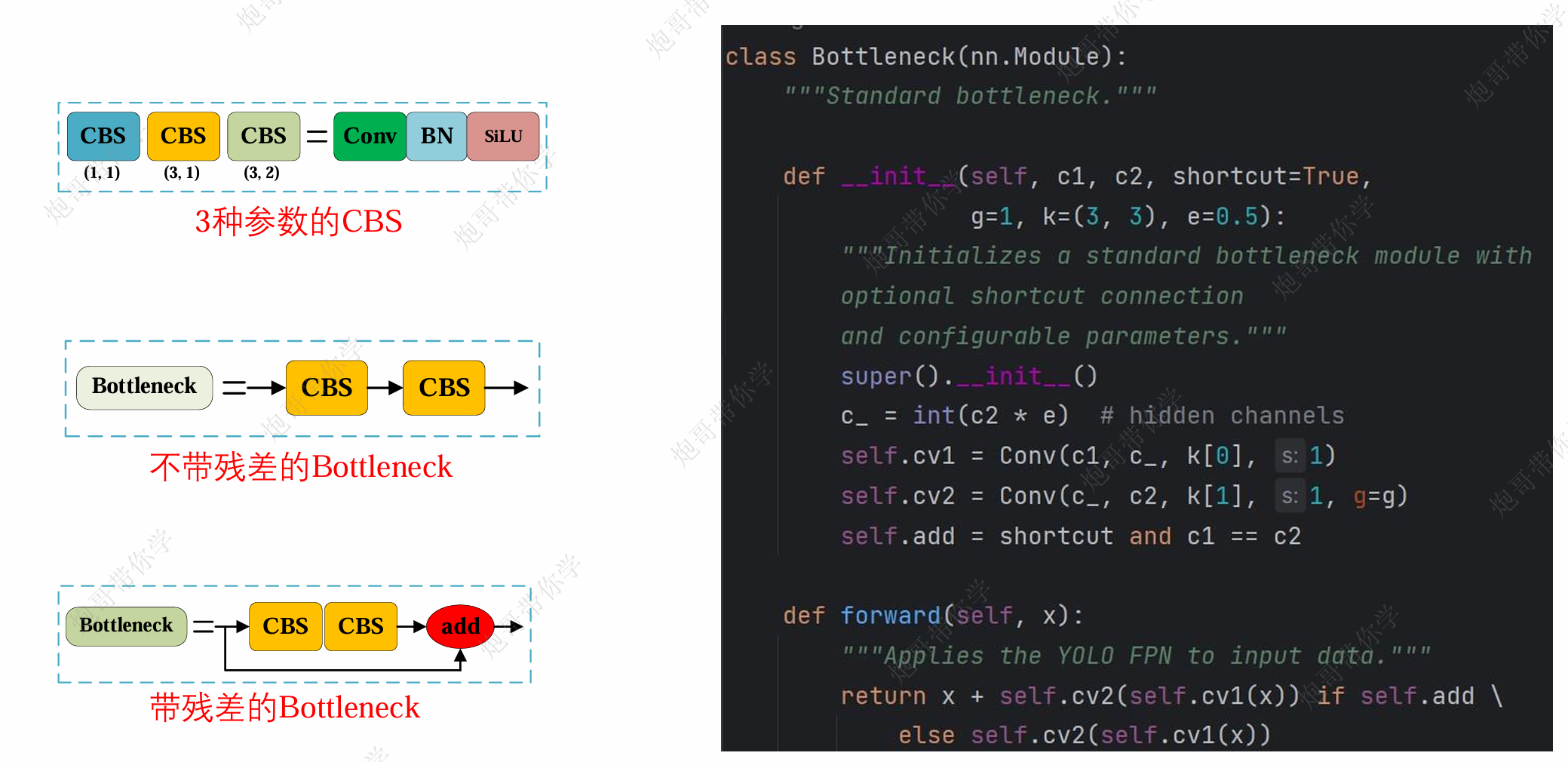
实际上对标YOLOv5的Res-Unit模块,变化不大
C2F:
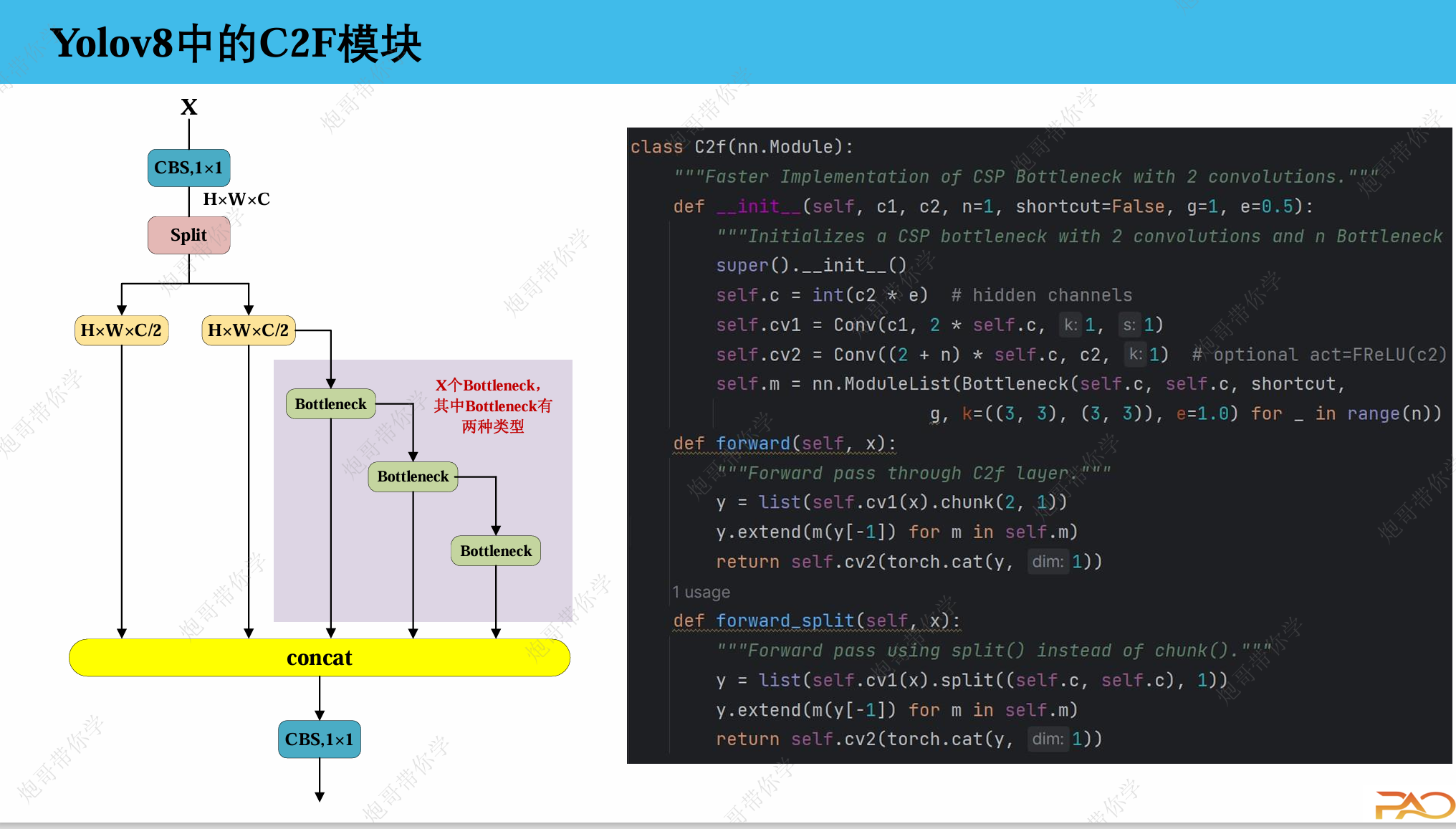
对标的是C3_X模块
1. 输入
输入特征图尺寸:
H x W x C
2. 第一个 1x1 卷积(CBS.1x1)
self.cv1 = Conv(c1, 2 * self.c, k=1, s=1)将输入通道
c1转换为2 * self.c(其中self.c = int(c2 * e))输出特征图尺寸:
H x W x (2 * self.c)
3. Split 操作
y = list(self.cv1(x).chunk(2, 1))将
2 * self.c的通道分成两个self.c的部分得到两个特征图:
H x W x self.c和H x W x self.c
4. Bottleneck 处理流
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))只对 第二个分支 进行 Bottleneck 处理
每个 Bottleneck 的输出都会 保留并传递 给下一个 Bottleneck
图示中有 4 个 Bottleneck,实际数量由参数
n控制
5. 特征合并
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, dim=1))最终合并的特征包括:
原始 split 的两个分支
所有 Bottleneck 的输出
总通道数:
(2 + n) * self.c
6. 最终 1x1 卷积
self.cv2 = Conv((2 + n) * self.c, c2, k=1)将合并后的特征通道数调整回目标输出
c2输出特征图尺寸:
H x W x c2
SPPF:

SPPF这个算子与YOLOv5差别不大,同样沿用了串行计算,这里不再赘述。
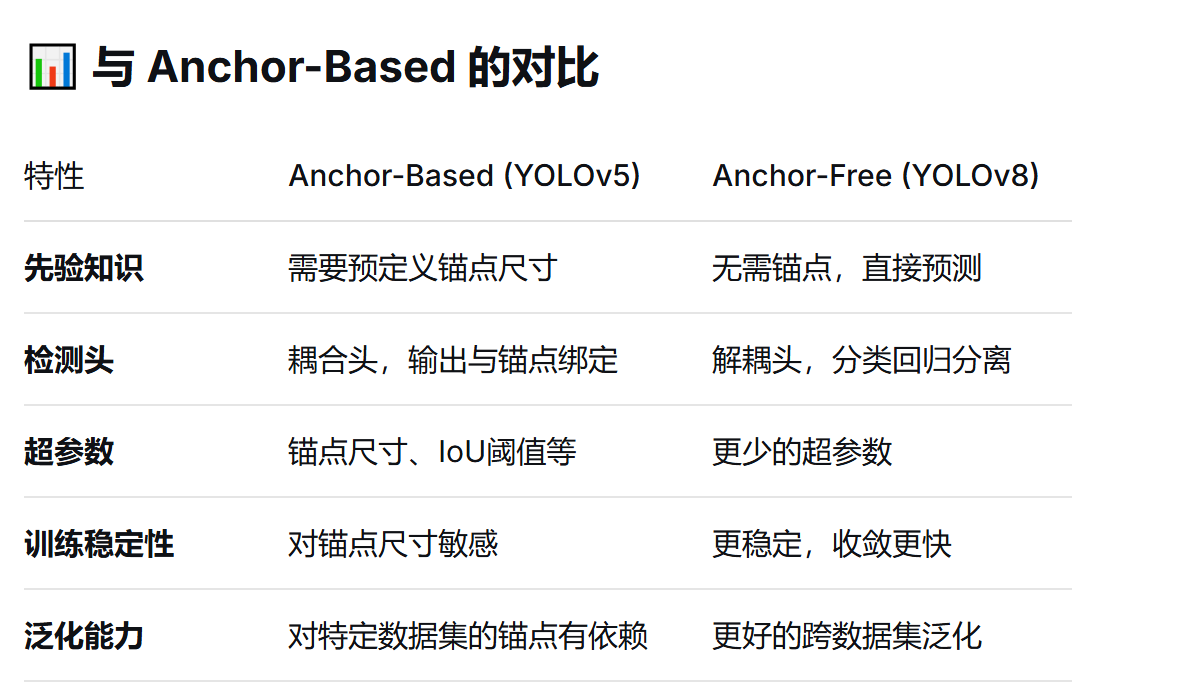
Anchor-Free
在 YOLOv5、YOLOv4 等早期版本中,使用的是 Anchor-Based 方法:
预先定义不同尺寸的锚点框(anchors)
让模型学习预测相对于这些锚点的偏移量
需要聚类统计数据集中的目标尺寸来确定最佳锚点
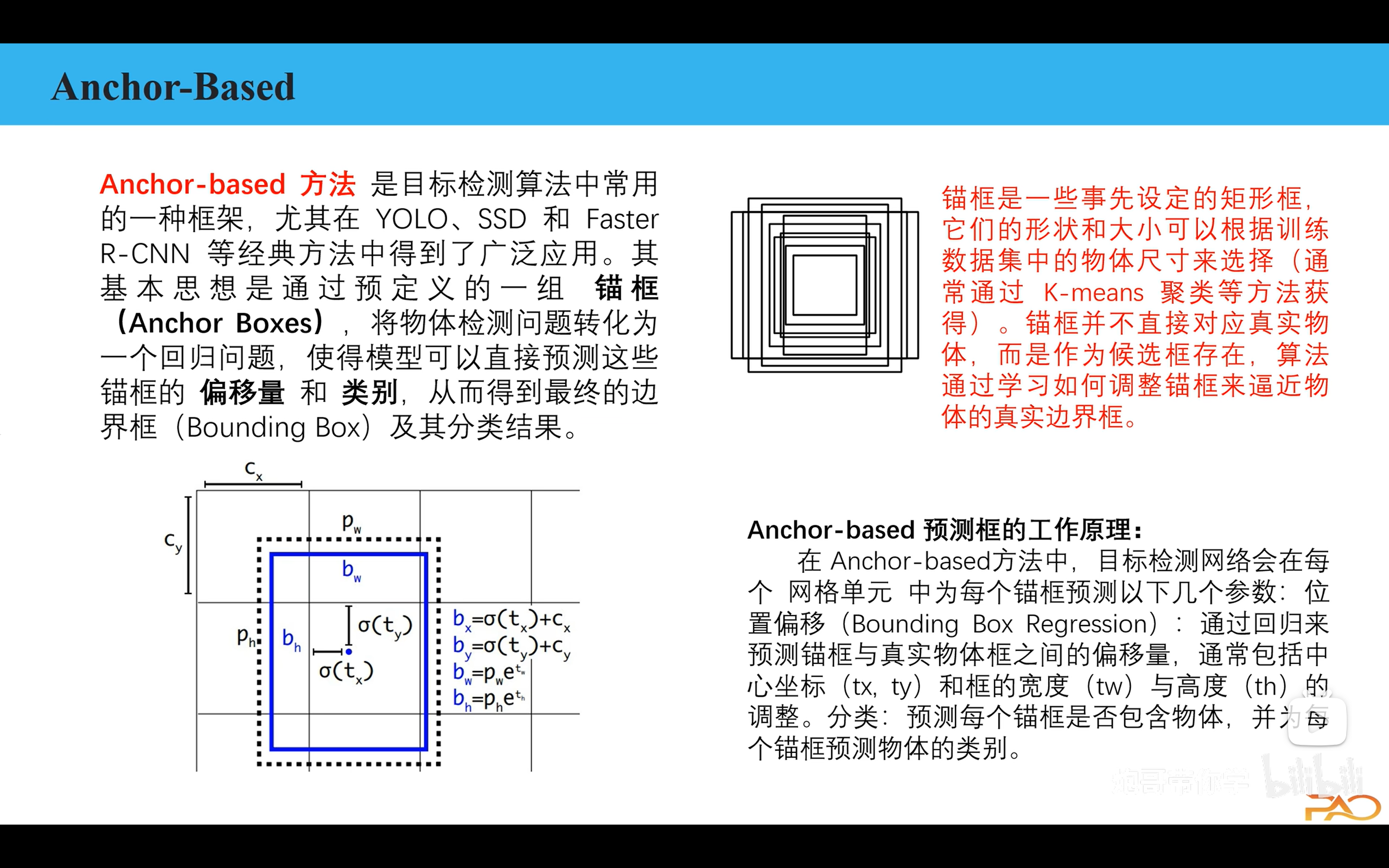
YOLOv8 转向了 Anchor-Free 方法,这是一个重要的架构变革。
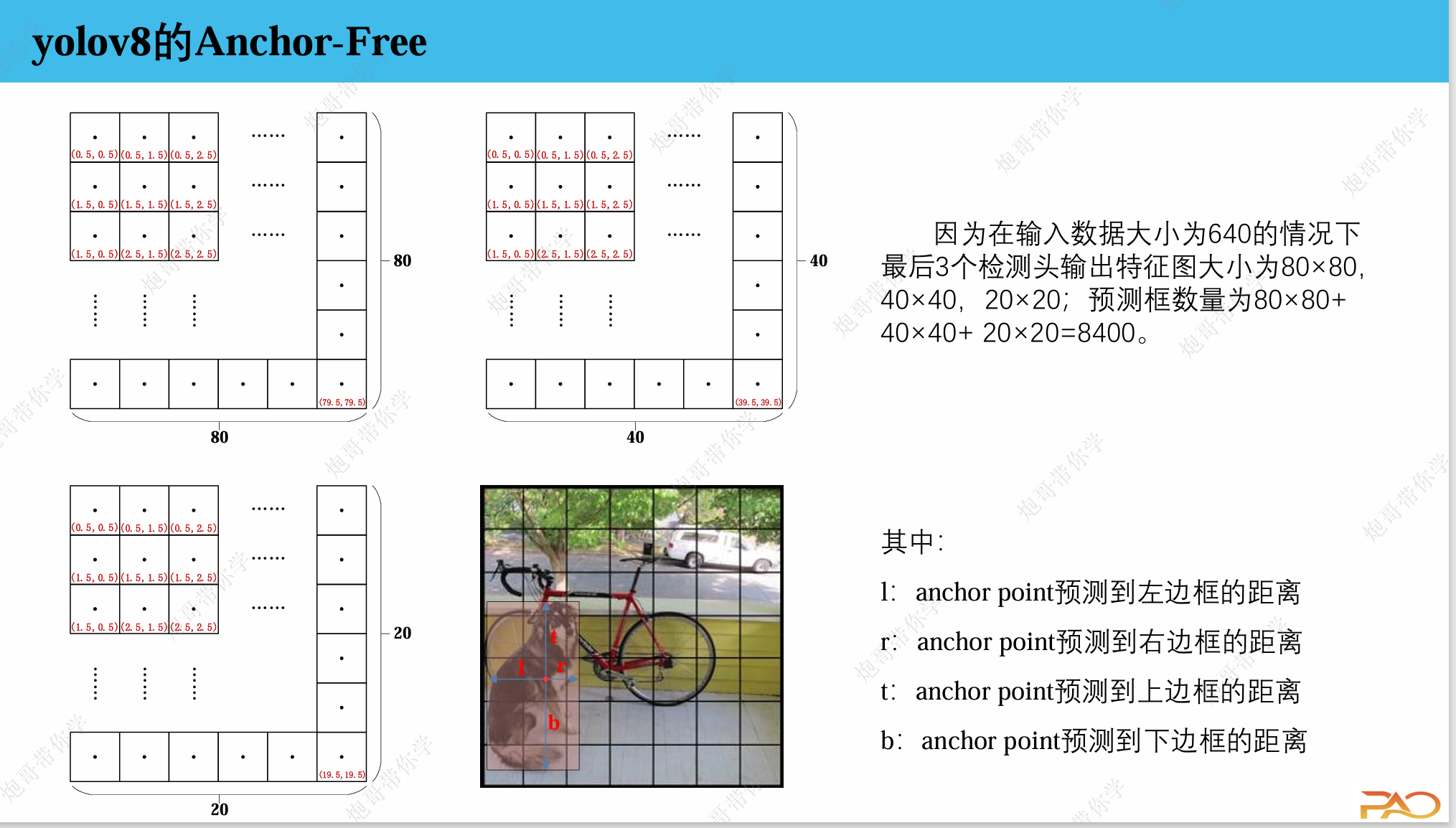
基本概念
Anchor-Free 直接预测目标框,而不依赖预定义的锚点。具体来说:
直接预测边界框:每个网格直接输出目标的中心点坐标、宽高
简化检测头:不再需要复杂的锚点匹配和偏移量计算
端到端优化:整个流程更加简洁和统一
具体实现:
1. 检测头设计
YOLOv8 使用 解耦检测头,将分类和回归任务分开:
# 传统的耦合头
class CoupledHead:# 同时输出分类和回归信息# YOLOv8 的解耦头
class DecoupledHead:# 分类分支单独处理# 回归分支单独处理2. 输出表示
对于每个预测位置,直接输出:
边界框坐标:(x, y, w, h) - 直接预测,不是偏移量
对象置信度:该位置存在目标的概率
分类分数:每个类别的概率分布
3. 标签分配策略
YOLOv8 使用 Task-Aligned Assigner:
综合考虑分类分数和预测框质量
动态选择正负样本
不再依赖固定的 IoU 阈值匹配锚点
损失函数

YOLOv8 的损失函数主要由三部分组成:
Total Loss = L_box + L_cls + L_obj
其中:
L_box: 边界框回归损失(Bounding Box Loss)
L_cls: 分类损失(Classification Loss)
L_obj: 目标置信度损失(Objectness Loss)
1. 边界框回归损失 (L_box)
使用的损失函数:CIoU Loss
YOLOv8 使用 CIoU(Complete IoU)来度量预测框与真实框的相似度。
CIoU 公式:
CIoU = IoU - (ρ²(b, b_gt) / c²) - αv
其中:
IoU: 交并比ρ²(b, b_gt): 预测框与真实框中心点的欧氏距离c: 最小外接矩形的对角线长度v: 宽高比一致性参数α: 平衡参数
CIoU Loss:
L_box = 1 - CIoU
CIoU 的优势:
同时考虑重叠面积、中心点距离、宽高比
收敛速度更快
回归更加准确
2. 分类损失 (L_cls)
使用的损失函数:二元交叉熵(Binary Cross-Entropy)
YOLOv8 对每个类别独立使用二元分类,而不是传统的多分类。
L_cls = Σ [y_gt * log(y_pred) + (1 - y_gt) * log(1 - y_pred)]
为什么使用二元交叉熵?
多标签支持:一个目标可以属于多个类别
更好的灵活性:适应复杂的现实场景
训练稳定性:避免类别间的竞争关系
3. 目标置信度损失 (L_obj)
使用的损失函数:二元交叉熵
衡量每个预测位置是否存在目标的置信度。
其中:
obj_gt: 真实标签(1表示有目标,0表示无目标)obj_pred: 模型预测的置信度
损失权重平衡
YOLOv8 为不同部分的损失设置了权重系数:
Total Loss = λ_box * L_box + λ_cls * L_cls + λ_obj * L_obj
典型的权重配置:
λ_box = 7.5(边界框损失权重)λ_cls = 0.5(分类损失权重)λ_obj = 1.0(置信度损失权重)
注意: 这些权重可能根据具体版本和任务有所调整。
标签分配策略
YOLOv8 使用 Task-Aligned Assigner 来确定正负样本,这是损失计算的前提:
Task-Aligned Assigner 工作原理:
计算对齐度分数:
score = classification_score ^ α * IoU_score ^ β
动态选择正样本:选择分数最高的前k个预测作为正样本
考虑分类和定位的一致性:不仅看IoU,还要看分类置信度
优势:
选择质量更高的样本进行训练
避免低质量锚点的干扰
提升训练效率和最终精度
损失计算流程
前向传播过程:
模型输出 → 得到预测的边界框、分类分数、置信度
标签分配 → 使用 Task-Aligned Assigner 匹配正负样本
损失计算:
对正样本计算 L_box, L_cls, L_obj
对负样本只计算 L_obj
加权求和 → 得到最终的总损失