JVM核心知识整理《1》
前言
- JVM 内存结构(运行时数据区)?哪些是线程共享的?
- 对象创建过程?对象在堆中如何分配?
- GC 算法有哪些?CMS vs G1 vs ZGC 的区别?
- 线上频繁 Full GC,如何排查?(工具链:jstat/jmap/MAT/GC 日志)
- JVM 调优参数:-Xmx、-XX:+UseG1GC、-XX:MaxGCPauseMillis?
- 类加载机制?双亲委派模型?如何打破?
1、JVM 内存结构(运行时数据区)?哪些是线程共享的?
根据《Java 虚拟机规范》,JVM 在运行时将内存划分为若干个运行时数据区,分为 线程私有 和 线程共享 两类。
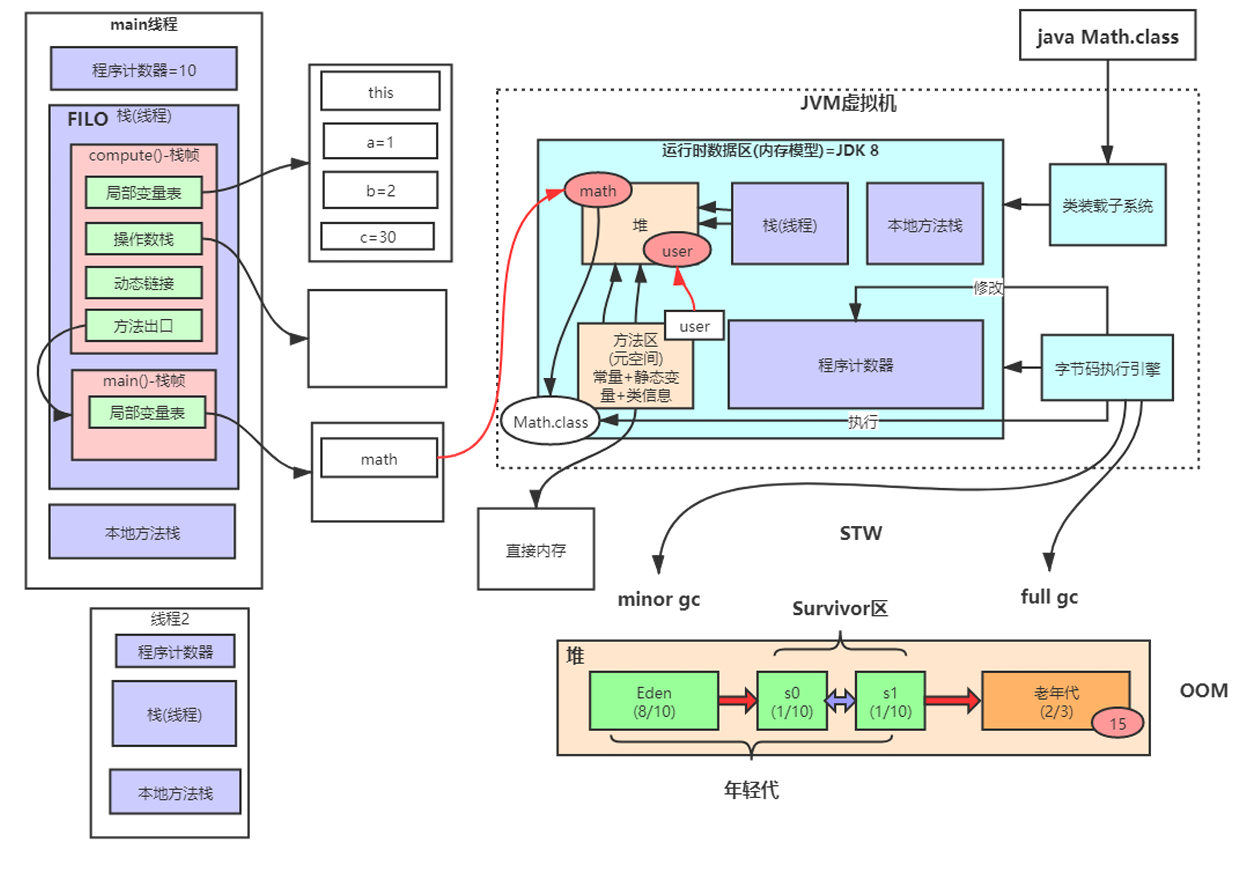
一、线程私有区域(每个线程独立拥有)
1. 程序计数器(Program Counter Register)
- 作用:记录当前线程正在执行的字节码指令地址(行号);
- 特点:
- 线程切换后能恢复执行位置;
- 是唯一不会发生 OutOfMemoryError 的区域;
- 若执行 Native 方法,计数器值为空(Undefined)。
2. Java 虚拟机栈(Java Virtual Machine Stack)
- 作用:存储栈帧(Stack Frame),每个方法调用创建一个栈帧;
- 栈帧包含:
- 局部变量表(Local Variables):存放方法参数、局部变量;
- 操作数栈(Operand Stack):执行字节码指令的临时空间;
- 动态链接(Dynamic Linking):指向运行时常量池的方法引用;
- 方法返回地址(Return Address):方法退出后返回位置。
- 异常:
- StackOverflowError:递归过深,栈深度超限;
- OutOfMemoryError:栈可动态扩展但内存不足(较少见)。
3. 本地方法栈(Native Method Stack)
- 作用:为 Native 方法(如 JNI 调用 C/C++)服务;
- 实现:HotSpot 虚拟机将 Java 栈和本地方法栈合并实现;
- 异常:同虚拟机栈。
二、线程共享区域(所有线程共用)
1. 堆(Heap)
- 唯一目的:存放所有对象实例和数组(JVM 规范要求,但 JIT 优化可能栈上分配);
- GC 主战场:新生代(Young)、老年代(Old);
- 参数:
- -Xms:初始堆大小;
- -Xmx:最大堆大小;
- 异常:java.lang.OutOfMemoryError:Java heap space
2. 方法区(Method Area)
- 存储内容:
- 类的元数据(Class 结构、字段/方法信息、字节码);
- 运行时常量池(Runtime Constant Pool);
- 静态变量(static 字段);
- JIT 编译后的代码缓存。
- JDK 演进:
- JDK 1.6 及之前:由 永久代(PermGen) 实现,位于堆内;
- JDK 1.7:字符串常量池、静态变量移至堆;
- JDK 1.8+:永久代移除,由 元空间(Metaspace) 实现,使用本地内存(Native Memory)。
- 异常:
- JDK 8+:java.lang.OutOfMemoryError:Metaspace;
- JDK 7-:java.lang.OutOfMemoryError: PermGen space。
💡 关键澄清:
- 方法区 ≠ 永久代:永久代是 HotSpot 对方法区的旧实现;
- 字符串常量池在 JDK 1.7+ 已移至堆中,不在 Metaspace。
三、直接内存(Direct Memory)—— 非运行时数据
- 来源:NIO 的 ByteBuffer.allocateDirect();
- 特点:
- 不受 -Xmx 限制;-Xms
- 分配/回收成本高,但读写性能好(避免堆内拷贝);
- 异常:OutOfMemoryError(本地内存耗尽)。
四、线程共享总结
| 区域 | 是否线程共享 | 说明 |
|---|---|---|
| 堆 | ✅ | 所有对象实例 |
| 方法区 | ✅ | 类元数据、常量池、静态变量 |
| 程序计数器 | ❌ | 每线程独立 |
| 虚拟机栈 | ❌ | 每线程独立 |
| 本地方法栈 | ❌ | 每线程独立 |
五、最佳实践
- 提到 逃逸分析 + 栈上分配:JVM 可能将对象分配在栈上(避免堆分配);
- 举例:在高频交易系统中,通过 -XX:+DoEscapeAnalysis 优化对象分配;
- 强调:Metaspace 默认无上限,生产环境必须设置 -XX:MaxMetaspaceSize=256M。
2、对象创建过程?对象在堆中如何分配?
对象创建看似简单(new Object()),实则涉及 JVM 多个子系统的协作。
一、对象创建的 5 个步骤
1. 类加载检查
- JVM 遇到 new 指令时,先检查常量池中是否有该类的符号引用;
- 若无,先触发 类加载(加载、验证、准备、解析、初始化)。
2. 分配内存
- 指针碰撞(Bump the Pointer):
- 适用:Serial、ParNew 等带压缩整理的 GC;
- 堆内存规整(已用/未用分界清晰),只需移动指针。
- 空闲列表(Free List):
- 适用:CMS 等标记-清除 GC;
- 堆内存碎片化,维护一个空闲内存块列表。
💡 如何保证并发安全?
- CAS + 失败重试:分配指针更新时用 CAS;
- TLAB(Thread Local Allocation Buffer):每个线程预分配一小块私有内存(默认开启 -XX:+UseTLAB),避免竞争。
3. 初始化零值
- 将分配到的内存空间初始化为零值(不包括对象头);
- 保证对象实例字段在 Java 代码未赋值前可安全使用(如 int = 0,boolean=false)。
4. 设置对象头
- Mark Word:存储哈希码、GC 分代年龄、锁状态(偏向/轻量/重量);
- Klass Pointer:指向类元数据(Metaspace 中的 Class 对象)。
5. 执行 <init> 方法
- 调用构造函数,初始化成员变量;
- 此时对象才真正“可用”。
二、对象在堆中的内存布局
| 部分 | 内容 | 大小(64 位 JVM) |
|---|---|---|
| 对象头(Header) | Mark Word(4/8) + Klass Pointer(4/8)(+数组长度) | 12 字节(默认,未开启指针压缩) |
| 实例数据(Instance Data) | 成员变量(按继承顺序 + 字段对齐) | 可变 |
| 对齐填充(Padding) | 保证对象大小为 8 字节倍数 | 0–7 字节 |
🔧 指针压缩(Compressed Oops):
- -XX:+UseCompressedOops(默认开启);
- class Pointer 从 8 字节 → 4 字节;
- 对象头从 16 字节 → 12 字节。
三、最佳实践
- 提到 对象年龄:每经历一次 Minor GC 未被回收,年龄 +1,最大 15(4 位);
- 举例:在压测中通过 -XX:-UseTLAB 观察到分配性能下降 30%;
- 强调:大对象(> Eden 区一半)直接进入老年代,避免 Survivor 复制开销。
3、GC 算法有哪些?CMS vs G1 vs ZGC 的区别?
一、基础 GC 算法(理论)
| 算法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 标记-清除(Mark-Sweep) | 标记存活对象,清除死亡对象 | 简单 | 内存碎片 |
| 复制(Copying) | 将存活对象复制到另一块内存 | 无碎片、高效 | 内存利用率 50% |
| 标记-整理(Mark-Compact) | 标记后将存活对象向一端移动 | 无碎片 | 移动成本高 |
| 分代收集(Generational) | 新生代(复制)、老年代(标记-清除/整理) | 符合“弱代假设” | 实现复杂 |
二、主流 GC 器对比(CMS vs G1 vs ZGC)-XX:+UseZGC
| 特性 | CMS | G1 | ZGC |
|---|---|---|---|
| 目标 | 低延迟(<100ms) | 可预测停顿(<200ms) | 超低延迟(<10ms) |
| 适用堆大小 | < 4GB | 4GB – 100GB | > 100GB(支持 TB 级) |
| 是否分代 | ✅ | ✅ | ❌(不分代) |
| 核心算法 | 并发标记-清除 | 分 Region + 标记-整理 | 并发标记 + 并发整理 |
| 停顿时间 | 初始标记、重新标记(STW) | 初始标记、最终标记(STW) | 仅标记根(<1ms) |
| 内存碎片 | ✅(严重) | ❌(整理) | ❌(整理) |
| JDK 版本 | JDK 5–13(JDK 14+ 废弃) | JDK 7u4+(默认 JDK 9+) | JDK 11+(生产可用) |
| 关键参数 | -XX:+UseConcMarkSweepGC | -XX:+UseG1GC | -XX:+UseZGC |
三、深度解析
1. CMS(Concurrent Mark Sweep)
- 阶段:
- 初始标记(STW)
- 并发标记
- 重新标记(STW)
- 并发清除
- 致命缺陷:
- 并发模式失败(Concurrent Mode Failure):老年代满时退化为 Serial Old(Full GC,STW 数秒);
- 内存碎片:无法分配大对象时触发 Full GC。
2. G1(Garbage First)
- 核心思想:
- 将堆划分为 2048 个 Region(大小 1–32MB);
- 每次回收价值最高的 Region(Garbage First);
- 混合回收(Mixed GC):年轻代 + 部分老年代。
- 优势:
- 可预测停顿(-XX:MaxGCPauseMillis=200);
- 无内存碎片。
3. ZGC(Z Garbage Collector)
- 革命性设计:
- 着色指针(Colored Pointer):利用 64 位指针的高位存储元数据;
- 读屏障(Load Barrier):在读取对象时修正指针;
- 优势:
- 停顿时间与堆大小无关(<10ms);
- 支持 TB 级堆。
四、最佳实践
- 提到 Shenandoah GC(Red Hat 主导,类似 ZGC);
- 举例:将 CMS 升级为 G1 后,Full GC 从每天 10 次降至 0;
- 强调:ZGC 需要 Linux 64 位 + JDK 11+,且关闭指针压缩。
4、线上频繁 Full GC,如何排查?
Full GC 会暂停所有应用线程(Stop-The-World),频繁发生会导致服务卡顿甚至不可用。
一、常见原因
内存泄漏(最常见)
- 静态集合不断 add 对象(如 static
Map缓存未清理); - 未关闭的资源(数据库连接、文件流、网络连接);
ThreadLocal未 remove,线程复用导致内存堆积。
- 静态集合不断 add 对象(如 static
大对象直接进入老年代
- 对象大小 > Eden + 一个 Survivor 空间;
- 避免 Survivor 复制开销,直接分配到老年代。
对象过早晋升
- 年轻代过小,Minor GC 频繁;
- 对象在 Survivor 区熬过 15 次 GC(默认 MaxTenringThreshold=15)后进入老年代。
Metaspace 不足
- 动态类加载过多(如 Spring CGLib、Groovy 脚本);
- 类加载器泄漏,类无法卸载;
- 触发 Full GC 尝试卸载类,若仍不足则 OOM。
GC 策略问题
- CMS:老年代碎片化,无法分配大对象,触发 Full GC;
- G1:Mixed GC 未能及时回收,退化为 Full GC。
显式调用 System.gc()
- 某些框架(如 RMI)默认每小时调用一次;
- 可通过-XX:+DisableExplicitGC禁用。
二、排查步骤(工具链)
1.开启 GC 日志(启动参数):
-Xloggc:/app/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
分析 Full GC 频率、老年代使用率、Metaspace 增长趋势。
2.实时监控:
jstat -gc <pid> 1000 # 每秒输出 GC 统计
关注 OU(老年代使用量)、MU(Metaspace 使用量)。
3.堆内存分析:
jmap -histo:live <pid> # 查看存活对象分布
jmap -dump:format=b,file=heap.hprof <pid> # 生成堆转储
4.线程分析(排除死锁/阻塞):
jstack <pid> > thread.txt
三、优化建议
- 调整年轻代大小:-Xmn;
- 避免大对象,拆分数据结构;
- 使用 G1 或 ZGC 替代 CMS;
- 添加 -XX:+DisableExplictGC。
四、最佳实践
- 提到 Arthas 的
heapdump命令; - 举例:曾通过 MAT 发现 ThreadLocal 泄漏,修复后 Full GC 从每分钟 1 次降至 0;
- 强调:Full GC 不一定是内存不足,也可能是 GC 策略不合理。
5、JVM 调优参数:-Xmx、-XX:+UseG1GC、-XX:MaxGCPauseMillis?
JVM 调优的核心是 平衡吞吐量、延迟、内存占用。以下是关键参数详解。
一、堆内存参数
| 参数 | 说明 | 建议 |
|---|---|---|
| -Xms | 初始堆大小 | = -Xmx(避免动态扩容) |
| -Xmx | 最大堆大小 | 物理内存 50%–70%(留内存给 OS/直接内存) |
-Xmn | 新生代大小 | 1/3 堆(默认),高并发可调大 |
-XX:Metaspace | Metaspace 初始阈值 | 默认 20.8MB,避免频繁 GC |
| -XX:MaxMetaspaceSize | Metaspace 上限 | 必设!如 256m |
二、GC 算法参数
| 参数 | 说明 | 适用场景 |
|---|---|---|
| -XX:+UseG1GC | 启用 G1 GC | 堆 > 4GB,要求停顿 < 200ms |
| -XX:MaxGCPauseMillis=200 | 期望最大停顿时间 | G1 会据此调整回收策略 |
| -XX:G1HeapRegionSize | G1 Region 大小 | 默认 1–32MB,大堆可调大 |
| -XX:+UseZGC | 启用 ZGC | 超大堆(>100GB),停顿 <10ms |
| -XX:+DisableExplicitGC | 禁用System.gc() | 防止 Full GC |
三、诊断与监控参数 -XX:+HeapDumpPath=/data
| 参数 | 说明 |
|---|---|
| -Xloggc:gc.log | 输出 GC 日志 |
| -XX:+PrintGCDetails | 打印 GC 详细信息 |
| -XX:+PrintGCDateStamps | GC 日志带时间戳 |
| -XX:+HeapDumpOnOutOfMemoryError | OOM 时自动生成堆转储 |
| -XX:+HeapDumpPath=/data | 堆转储路径 |
四、调优原则
- 先监控,再调优:开启 GC 日志,观察 1–3 天;
- 新生代调优:Minor GC 频率高 → 调大
-Xmn; - 老年代调优:Full GC 频繁 → 检查内存泄漏 or 调大堆;
- Metaspace 调优:动态类加载多 → 调大 MaxMetaspace。
五、最佳实践
- 提到 JFR(Java Flight Recorder):JDK 11+ 内置性能分析工具;
- 举例:通过 -XX:MaxGCPauseMillis=100 将 G1 停顿从 300ms 降至 80ms;
- 强调:不要盲目调大堆,可能增加 GC 停顿时间。
6、类加载机制?双亲委派模型?如何打破?
一、类加载的 5 个阶段
| 阶段 | 作用 | 是否可定制 |
|---|---|---|
| 加载(Loading) | 获取类的二进制字节流,生成 Class 对象 | ✅(自定义 ClassLoader) |
| 验证(Verification) | 确保字节流符合 JVM 规范(文件格式、元数据、字节码、符号引用) | ❌ |
| 准备(Preparation) | 为 static 变量分配内存并设初值(如 int=0) | ❌ |
| 解析(Resolution) | 将符号引用转为直接引用 | ❌(或延迟到初始化) |
| 初始化(Initialization) | 执行 <clinit> 方法(static 块、static 变量赋值) | ❌ |
💡 注意:
- 准备阶段:public static int value = 123; ---->value = 0;
- 初始化阶段:value = 123;
二、类加载器(ClassLoader)层次
| 加载器 | 加载路径 | 说明 |
|---|---|---|
| Bootstrap ClassLoader | <JAVA_HOME>/lib | C++ 实现,加载核心类(如 java.lang.*) |
| Extension ClassLoader | <JAVA_HOME>/lib/ext | 加载扩展类 |
| Application ClassLoader | -classpath | 加载用户类(默认) |
| 自定义 ClassLoader | 任意 | 继承 ClassLoader |
三、双亲委派模型(Parents Delegation Model)
1. 工作流程
- 当一个类加载器收到加载请求:
- 先委托父加载器加载;
- 父加载器递归向上,直到 Bootstrap;
- 若父加载器无法加载,自己才尝试加载。
2. 优点
- 避免重复加载:核心类(如 String)只会被 Bootstrap 加载;
- 安全性:防止用户自定义java.lang.String篡改核心 API。
3. 源码体现
protected Class<?> loadClass(String name, boolean resolve) {synchronized (getClassLoadingLock(name)) {// 1. 检查是否已加载Class<?> c = findLoadedClass(name);if (c == null) {// 2. 委托父加载器if (parent != null) {c = parent.loadClass(name, false);} else {c = findBootstrapClassOrNull(name);}if (c == null) {// 3. 自己加载c = findClass(name);}}if (resolve) {resolveClass(c);}return c;}
}
四、如何打破双亲委派?
1. SPI 机制(Service Provider Interface)
- 场景:JDBC 的 DriverManager 加载数据库驱动;
- 问题:Bootstrap 加载 DriverManager,但驱动是用户类(Application 加载);
- 解决方案:线程上下文类加载器(Thread Context ClassLoader)
2. 热部署 / 模块化
- OSGi:每个模块有自己的 ClassLoader,可独立加载/卸载;
- Tomcat:每个 WebApp 有独立 WebAppClassLoader,优先加载 WEB-INF/lib。
3. 自定义 ClassLoader 重写 loadClass()
- 不调用 super.loadClass(),直接 findClass();
- 风险:可能破坏安全性。
五、最佳实践
- 提到 JDK 9 模块化(JPMS) 对类加载的影响;
- 举例:在插件系统中用自定义 ClassLoader 实现热加载;
- 强调:双亲委派是默认行为,打破需有充分理由。