VQ-VAE 代码详细解析及记录
最近找了几篇VQ-VAE的相关博文学习,视频讲解的也很通俗,下面做一个简单的记录,以防忘记。
1.背景-VAE的问题
- 后验塌缩(Posterior Collapse):当解码器(如强大的自回归模型)过于复杂时,模型会忽略 latent code,直接依赖解码器生成数据,导致 latent 失效。
- 静态先验:VAE 通常假设 latent 服从固定的简单分布(如高斯分布),限制了表征能力。
- 生成图像更清晰,VAE总是倾向于生成所有可能输出的平均,导致图像“模糊”
2.VQ-VAE结构
定义一个离散的隐空间(embedding space),里面有K个向量,每个向量的维度为D。
(这里可以理解为,我定义了一个字典,这个字典里面有K个字,每个字有一个编号。)
跟VAE一样,VQ-VAE也存在编码器(Encoder)和解码器(Decoder)。不同的点是,经过编码输出的隐变量,需要先在字典里面查表,并根据最近邻原则转为字典里面的向量。
(这里可以理解为,原始的隐变量是16*16*5的向量,其中5表示向量的深度,也就是上文的D。我们对16*16中的每一个向量,都找到embedding space里距离最近的向量,然后替换成组成新)
这个新的会当成解码器的输入,重构出新的图像。
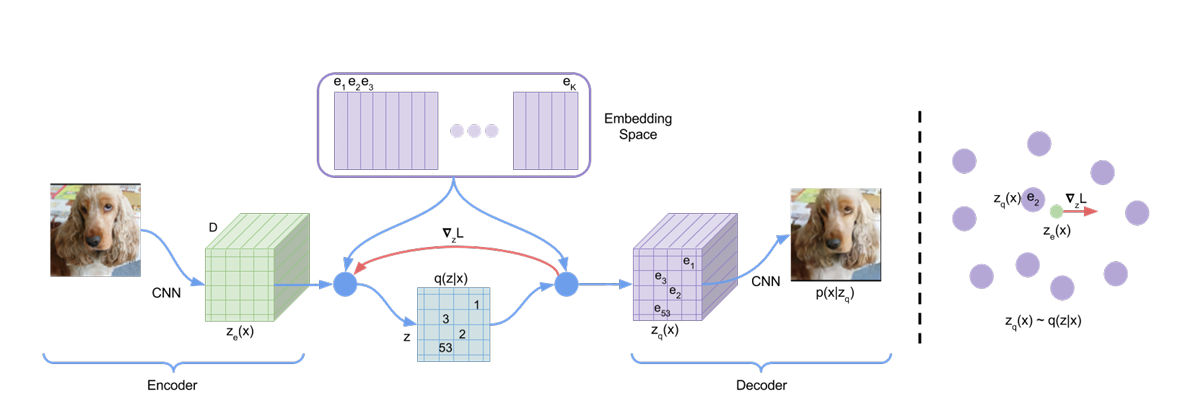
3.VQ-VAE的训练
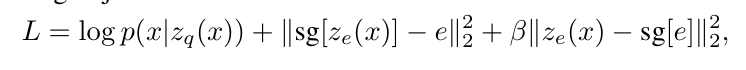
该模型的损失函数包括三个部分,第一部分是重构损失,即输入和输出图像之间的误差。第二部分,是使embedding space的设计尽可能向实际的隐空间靠近,即设计嵌入空间。第三部分是使隐空间尽可能向嵌入空间靠近。
一个很形象的解释是(视频里头的hhh),嵌入空间是包装,隐空间是待包装的产品。两者双向奔赴。
【AIGC生成技术之——VQVAE与VQGAN】
4.代码解释
这里解释的是keras版本的代码:VQ-VAE的简明介绍:量子化自编码器
#! -*- coding: utf-8 -*-
# Keras简单实现VQ-VAE
import numpy as np
import scipy as sp
from scipy import misc
import glob
import imageio
from keras.models import Model
from keras.layers import *
from keras import backend as K
from keras.optimizers import Adam
from keras.callbacks import Callback
import osif not os.path.exists('samples'):os.mkdir('samples')imgs = glob. Glob('../../CelebA-HQ/train/*.png')
np.random.shuffle(imgs)
img_dim = 128
z_dim = 128
num_codes = 64
batch_size = 64
# 残差层数:log2(128)=7,7-4=3,即 3 个残差层堆叠(后面会看到), num_layers 的计算依赖 img_dim,如果换分辨率要对应调整。
num_layers = int(np.log2(img_dim) - 4)# 读取数据处理,缩放至-1~1,大小为128*128
def imread(f):x = misc.imread(f, mode='RGB')x = misc.imresize(x, (img_dim, img_dim))x = x.astype(np.float32)return x / 255 * 2 - 1class img_generator:"""图片迭代器,方便重复调用"""# 记录数据与批大小,计算每个 epoch 的步数。def __init__(self, imgs, batch_size=64):self.imgs = imgsself.batch_size = batch_sizeif len(imgs) % batch_size == 0:self.steps = len(imgs) // batch_sizeelse:self.steps = len(imgs) // batch_size + 1# 让生成器有“长度”概念(和 Keras 配合)。def __len__(self):return self.steps# 无限生成批:每次打乱路径,收集 batch_size 张图,yield (X, None)(无标签)# 输出的 None 只是占位,训练里用 add_loss 自定义损失,不用 y。def __iter__(self):X = []while True:np.random.shuffle(self.imgs)for i,f in enumerate(self.imgs):X.append(imread(f))if len(X) == self.batch_size or i == len(self.imgs)-1:X = np.array(X)yield X, NoneX = []# 预激活风格(先 ReLU 再卷积)
# 两个卷积:3×3 保持空间,1×1 调整通道(这里通道不变)
# 残差连接:输入 xo + 变换 x, 最后返回的张量通道等于 dim(和输入一样)
def resnet_block(x):"""残差块"""dim = K.int_shape(x)[-1]xo = xx = Activation('relu')(x)x = Conv2D(dim, 3, padding='same')(x)x = BatchNormalization()(x)x = Activation('relu')(x)x = Conv2D(dim, 1, padding='same')(x)return Add()([xo, x])# 编码器
x_in = Input(shape=(img_dim, img_dim, 3))
x = x_in
x = Conv2D(z_dim, 4, strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(z_dim, 4, strides=2, padding='same')(x)
# 32*32*128
x = BatchNormalization()(x)for i in range(num_layers):# 32*32*128x = resnet_block(x)# 编码器输出层无batchnormalizationif i < num_layers - 1:x = BatchNormalization()(x)e_model = Model(x_in, x)
e_model.summary()# 解码器
z_in = Input(shape=K.int_shape(x)[1:])
z = z_infor i in range(num_layers):z = BatchNormalization()(z)z = resnet_block(z)
# 反卷积可能出现棋盘格伪影,可改“UpSampling2D + Conv2D”。
z = Conv2DTranspose(z_dim, 4, strides=2, padding='same')(z)
z = BatchNormalization()(z)
z = Activation('relu')(z)
z = Conv2DTranspose(3, 4, strides=2, padding='same')(z)
z = Activation('tanh')(z)g_model = Model(z_in, z)
g_model.summary()# 硬编码模型
z_in = Input(shape=K.int_shape(x)[1:])
z = z_inclass VectorQuantizer(Layer):"""量化层"""def __init__(self, num_codes, **kwargs):super(VectorQuantizer, self).__init__(**kwargs)self.num_codes = num_codesdef build(self, input_shape):super(VectorQuantizer, self).build(input_shape)dim = input_shape[-1]self.embeddings = self.add_weight(name='embeddings',shape=(self.num_codes, dim),initializer='uniform')def call(self, inputs):"""inputs.shape=[None, m, m, dim]"""l2_inputs = K.sum(inputs**2, -1, keepdims=True)l2_embeddings = K.sum(self.embeddings**2, -1)for _ in range(K.ndim(inputs) - 1):l2_embeddings = K.expand_dims(l2_embeddings, 0)embeddings = K.transpose(self.embeddings)dot = K.dot(inputs, embeddings)distance = l2_inputs + l2_embeddings - 2 * dotcodes = K.cast(K.argmin(distance, -1), 'int32')code_vecs = K.gather(self.embeddings, codes)return [codes, code_vecs]def compute_output_shape(self, input_shape):return [input_shape[:-1], input_shape]vq_layer = VectorQuantizer(num_codes)
codes, code_vecs = vq_layer(z)q_model = Model(z_in, [codes, code_vecs])
q_model.summary()# 训练模型
x_in = Input(shape=(img_dim, img_dim, 3))
x = x_inz = e_model(x) # 连续编码
_, e = q_model(z) # 量化得到码字向量 e
# ze = z + stop_grad(e - z) 反向损失直通
ze = Lambda(lambda x: x[0] + K.stop_gradient(x[1] - x[0]))([z, e])
x = g_model(ze) # 解码重建train_model = Model(x_in, [x, _])mse_x = K.mean((x_in - x)**2)
mse_e = K.mean((K.stop_gradient(z) - e)**2)
mse_z = K.mean((K.stop_gradient(e) - z)**2)
loss = mse_x + mse_e + 0.25 * mse_ztrain_model.add_loss(loss)
train_model.compile(optimizer=Adam(1e-3))
train_model.summary()
train_model.metrics_names.append('mse_x'); train_model.metrics_tensors.append(mse_x)
train_model.metrics_names.append('mse_e'); train_model.metrics_tensors.append(mse_e)
train_model.metrics_names.append('mse_z'); train_model.metrics_tensors.append(mse_z)# 重构采样函数
def sample_ae_1(path, n=8):# 网格 n×n:偶数列用随机真图;奇数列把前一列的图编码→解码再放上figure = np.zeros((img_dim * n, img_dim * n, 3))for i in range(n):for j in range(n):if j % 2 == 0:x_sample = [imread(np.random.choice(imgs))]else:z_sample = e_model.predict(np.array(x_sample))x_sample = g_model.predict(z_sample)digit = x_sample[0]figure[i * img_dim:(i + 1) * img_dim,j * img_dim:(j + 1) * img_dim] = digitfigure = (figure + 1) / 2 * 255figure = np.round(figure, 0).astype('uint8')imageio.imwrite(path, figure)# 重构采样函数
def sample_ae_2(path, n=8):figure = np.zeros((img_dim * n, img_dim * n, 3))# 奇数列改为“编码→量化→码字向量→解码”重建for i in range(n):for j in range(n):if j % 2 == 0:x_sample = [imread(np.random.choice(imgs))]else:z_sample = e_model.predict(np.array(x_sample))z_sample = q_model.predict(z_sample)[1]x_sample = g_model.predict(z_sample)digit = x_sample[0]figure[i * img_dim:(i + 1) * img_dim,j * img_dim:(j + 1) * img_dim] = digitfigure = (figure + 1) / 2 * 255figure = np.round(figure, 0).astype('uint8')imageio.imwrite(path, figure)# 随机线性插值
def sample_inter(path, n=8):figure = np.zeros((img_dim * n, img_dim * n, 3))for i in range(n):img1, img2 = np.random.choice(imgs, 2)z_sample_1, z_sample_2 = e_model.predict(np.array([imread(img1), imread(img2)]))z_sample_1, z_sample_2 = np.array([z_sample_1]), np.array([z_sample_2])for j in range(n):alpha = j / (n - 1.)z_sample = (1 - alpha) * z_sample_1 + alpha * z_sample_2z_sample = q_model.predict(z_sample)[1]x_sample = g_model.predict(z_sample)digit = x_sample[0]figure[i * img_dim:(i + 1) * img_dim,j * img_dim:(j + 1) * img_dim] = digitfigure = (figure + 1) / 2 * 255figure = np.round(figure, 0).astype('uint8')imageio.imwrite(path, figure)class Trainer(Callback):def __init__(self):self.batch = 0self.n_size = 9self.iters_per_sample = 100# 每隔 iters_per_sample=100 个 batch,就导出两张可视化图并存权重。def on_batch_end(self, batch, logs=None):if self.batch % self.iters_per_sample == 0:sample_ae_1('samples/test_ae_1_%s.png' % self.batch)sample_ae_2('samples/test_ae_2_%s.png' % self.batch)train_model.save_weights('./train_model.weights')self.batch += 1batch = min(self.batch, 100000.)if __name__ == '__main__':trainer = Trainer()img_data = img_generator(imgs, batch_size)train_model.fit_generator(img_data.__iter__(),steps_per_epoch=len(img_data),epochs=1000,callbacks=[trainer])train_model.load_weights('./train_model.weights')e_model_size = K.int_shape(e_model.outputs[0])[1: -1]
e_model_total_size = np.prod(e_model_size)# 这段是训练完自编码器后,用自回归模型学习离散代码的分布,从而纯采样生成新图。
from tqdm import tqdm# 用 e_model+q_model 把训练图像编码成离散索引 train_codes(每张图一个 (h×w) 的索引网格,h×w=e_model_size)
train_D = img_generator(imgs)
train__D = train_D.__iter__()
train_codes = np.empty((0, e_model_total_size), dtype='int32')
for _ in tqdm(iter(range(len(train_D)))):d = train__D.next()[0]c = q_model.predict(e_model.predict(d))[0]c = c.reshape((c.shape[0], -1))train_codes = np.vstack([train_codes, c])# 在代码序列前面加起始 token 0,并把真实索引 +1(让 0 专属于起始符):
train_codes = np.hstack([np.zeros_like(train_codes[:, :1], dtype='int32'),train_codes + 1
])class OurLayer(Layer):"""定义新的Layer,增加reuse方法,允许在定义Layer时调用现成的层"""def reuse(self, layer, *args, **kwargs):if not layer.built:if len(args) > 0:layer.build(K.int_shape(args[0]))else:layer.build(K.int_shape(kwargs['inputs']))self._trainable_weights.extend(layer._trainable_weights)self._non_trainable_weights.extend(layer._non_trainable_weights)return layer.call(*args, **kwargs)class Attention(OurLayer):"""多头注意力机制"""def __init__(self, heads, size_per_head, key_size=None,mask_right=False, **kwargs):super(Attention, self).__init__(**kwargs)self.heads = headsself.size_per_head = size_per_headself.out_dim = heads * size_per_headself.key_size = key_size if key_size else size_per_headself.mask_right = mask_rightdef build(self, input_shape):super(Attention, self).build(input_shape)self.q_dense = Dense(self.key_size * self.heads, use_bias=False)self.k_dense = Dense(self.key_size * self.heads, use_bias=False)self.v_dense = Dense(self.out_dim, use_bias=False)def mask(self, x, mask, mode='mul'):if mask is None:return xelse:for _ in range(K.ndim(x) - K.ndim(mask)):mask = K.expand_dims(mask, K.ndim(mask))if mode == 'mul':return x * maskelse:return x - (1 - mask) * 1e10def call(self, inputs):q, k, v = inputs[:3]v_mask, q_mask = None, Noneif len(inputs) > 3:v_mask = inputs[3]if len(inputs) > 4:q_mask = inputs[4]# 线性变换qw = self.reuse(self.q_dense, q)kw = self.reuse(self.k_dense, k)vw = self.reuse(self.v_dense, v)# 形状变换qw = K.reshape(qw, (-1, K.shape(qw)[1], self.heads, self.key_size))kw = K.reshape(kw, (-1, K.shape(kw)[1], self.heads, self.key_size))vw = K.reshape(vw, (-1, K.shape(vw)[1], self.heads, self.size_per_head))# 维度置换qw = K.permute_dimensions(qw, (0, 2, 1, 3))kw = K.permute_dimensions(kw, (0, 2, 1, 3))vw = K.permute_dimensions(vw, (0, 2, 1, 3))# Attentiona = K.batch_dot(qw, kw, [3, 3]) / self.key_size**0.5a = K.permute_dimensions(a, (0, 3, 2, 1))a = self.mask(a, v_mask, 'add')a = K.permute_dimensions(a, (0, 3, 2, 1))if self.mask_right:ones = K.ones_like(a[:1, :1])mask = (ones - K.tf.matrix_band_part(ones, -1, 0)) * 1e10a = a - maska = K.softmax(a)# 完成输出o = K.batch_dot(a, vw, [3, 2])o = K.permute_dimensions(o, (0, 2, 1, 3))o = K.reshape(o, (-1, K.shape(o)[1], self.out_dim))o = self.mask(o, q_mask, 'mul')return odef compute_output_shape(self, input_shape):return (input_shape[0][0], input_shape[0][1], self.out_dim)from keras_layer_normalization import LayerNormalizationc_in = Input(shape=(None,))
c = c_indef posid(x):idx = K.arange(0, K.shape(x)[1])idx = K.expand_dims(idx, 0)idx = K.tile(idx, [K.shape(x)[0], 1])return idxc_pid = Lambda(posid)(c)
c_row_pid = Lambda(lambda x: x // e_model_size[0])(c_pid)
c_col_pid = Lambda(lambda x: x % e_model_size[1])(c_pid)def build_att(c):co = cc = Attention(8, 32, mask_right=True)([c, c, c])c = Dense(z_dim * 2, activation='relu')(c)return Add()([c, co])c = Embedding(num_codes + 1, z_dim * 2)(c)
c_row_p = Embedding(e_model_size[0], z_dim * 2)(c_row_pid)
c_col_p = Embedding(e_model_size[1], z_dim * 2)(c_col_pid)
c = Add()([c, c_row_p, c_col_p])
c = LayerNormalization()(c)
c = build_att(c)
c = LayerNormalization()(c)
c = build_att(c)
c = LayerNormalization()(c)
c = build_att(c)
c = LayerNormalization()(c)
c = build_att(c)
c = LayerNormalization()(c)
c = Dense(num_codes, activation='softmax')(c)c_model = Model(c_in, c)
c_model.summary()
c_model.compile(loss='sparse_categorical_crossentropy',optimizer='adam'
)
c_model.fit(train_codes[:, :-1],np.expand_dims(train_codes[:, 1:] - 1, 2),batch_size=32,epochs=1000
)def random_sample_code(n=1):c_sample = np.zeros((n, e_model_total_size + 1), dtype='int32')for i in tqdm(iter(range(e_model_total_size))):p = c_model.predict(c_sample[:, :i+1])[:, -1]for j in range(n):k = np.random.choice(num_codes, p=p[j])c_sample[j, i+1] = k + 1return c_sample[:, 1:].reshape((-1, e_model_size[0], e_model_size[1])) - 1def code2vec(codes):vecs = K.gather(vq_layer.embeddings, codes)return K.eval(vecs)# 随机采样
def sample(path, n=8):figure = np.zeros((img_dim * n, img_dim * n, 3))codes = random_sample_code(n**2)for i in range(n):for j in range(n):z_sample = code2vec(codes[[i * n + j]])z_sample = q_model.predict(z_sample)[1]x_sample = g_model.predict(z_sample)digit = x_sample[0]figure[i * img_dim:(i + 1) * img_dim,j * img_dim:(j + 1) * img_dim] = digitfigure = (figure + 1) / 2 * 255figure = np.round(figure, 0).astype('uint8')imageio.imwrite(path, figure)
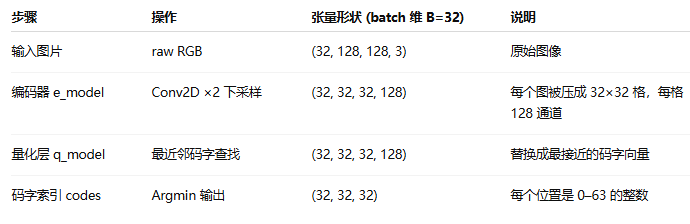
万字长文【VQ-VAE】原理与代码精讲这份脚本包含三大部分:
-
自编码(VQ-VAE 部分)
-
编码器
e_model:把图像压到低分辨率表征z -
量化层
VectorQuantizer:把连续z换成最近的码字向量 -
直通估计器(STE):
ze = z + stop_grad(e - z) -
解码器
g_model:从量化后的ze重建图像 -
训练损失:
重建 MSE + 码本拉近 + commitment
-
-
采样与可视化
-
sample_ae_1/2:按网格可视化重建效果(是否过量化对比) -
sample_inter:在潜空间线性插值(+量化)看平滑性 -
训练回调
Trainer:定期保存样例与权重
-
-
自回归先验(可选扩展)
-
把训练集编码成离散码字索引网格
train_codes -
用自定义多头注意力搭个“小型 Transformer”
c_model来学先验 -
逐点采样离散索引 → 查码本向量 → 解码器生成新图
-
先学量化自编码器,再在离散代码上学先验。也就是说,VQ-VAE需要与一个先验模型结合才能完整的使用。(VAE可以训练后就生成)。这里详细解释一下先验模型:
把“先验模型”想象成给离散潜码(codes)学一本语言词典 + 语法书。前面的 VQ-VAE 已经把每张图压成一个小网格里的离散编号(像 32×32 的“单词表格”,索引编号)。但这一步只会重构:给你 codes → 能还原图;却不会凭空“写”codes。要想“从无到有生成新图”,就需要学会这些 codes 在训练数据里是怎么组合出现的——这就是“先验模型(prior)”。
1) 把图像变成“离散句子”
-
先用
e_model + q_model把所有训练图像编码成离散索引网格train_codes(每个格点一个 code id)。 -
再把网格展平为序列(像把一幅图按行读成一句很长的话),并在最前面加一个起始 token 0。
-
具体就是每一个图片对应的32*32*128维的隐变量,首先变成32*32维的索引,然后Flatten成1024维的行向量,行向量前面加一个起始token,即1025维。

2) 训练一个“下一词预测”的语言模型(小型 Transformer)
-
构建
c_model:输入是前缀[..., c_t],输出是“下一个 code 的概率分布”。 -
里面的关键组件:
-
Embedding:把离散 id 变向量;
-
行/列位置嵌入:
c_row_p, c_col_p提示模型“现在在网格的第几行第几列”,相当于二维位置编码; -
Attention(mask_right=True):自回归掩码,只看左边历史,不能偷看未来;
-
若干堆叠的注意力 + 前馈(
build_att),再接Dense(num_codes, softmax)输出分类。
-

-
训练目标(teacher forcing):
输入:train_codes[:, :-1]
目标:train_codes[:, 1:](右移一位,即“下一个 token”)
3) 采样:像写一句话一样“一个格点一个格点”地生 codes
-
生成时从全零起步:
[<START>] -
循环每个位置 i:
-
把当前 前缀喂给
c_model,拿到下一个 code 的概率分布; -
用这个分布抽样一个 code(或用 top-k/温度调节);
-
把它接到序列末尾,进入下一步。
-
-
全部位置采完,得到一整句 codes(再 reshape 回原来的 H×W 网格):

最后使用解码器生成图像。
万字长文【VQ-VAE】原理与代码精讲