Dirichlet分布的理解与应用
联邦学习中的非独立同分布数据模拟:Dirichlet分布原理与应用
目录
- 联邦学习中的非独立同分布数据模拟:Dirichlet分布原理与应用
- Dirichlet分布基本原理
- 概念理解
- 数学形式
- Dirichlet分布在联邦学习中的应用
- 实践应用
- 函数介绍
- 代码示例
- 可视化结果分析
- 总结
在联邦学习中,模拟非独立同分布(Non-IID)数据是一个重要课题。Dirichlet分布为此提供了一种有效的数学工具。本文介绍了Dirichlet分布的基本原理,并详细探讨了其在联邦学习数据集划分中的应用方法。
Dirichlet分布基本原理
概念理解
Dirichlet分布可以被理解为"分布的分布":它描述的是概率分布向量的分布特性。具体来说,Dirichlet分布研究的随机变量是一个NNN维向量x=[x1,x2,...,xN]\boldsymbol{x} = [x_1, x_2, ..., x_N]x=[x1,x2,...,xN],其中每个元素xi>0x_i > 0xi>0且满足∑i=1Nxi=1\sum_{i=1}^N x_i = 1∑i=1Nxi=1,因此可以视为一个概率分布。
举例说明:假设小明午餐会选择香蕉、苹果或梨这三种水果中的一种。我们可以用一个概率分布向量x=[0.2,0.4,0.4]\boldsymbol{x} = [0.2, 0.4, 0.4]x=[0.2,0.4,0.4]来描述他选择每种水果的概率,即选择香蕉的概率为0.2,选择苹果和梨的概率各为0.4。而Dirichlet分布研究的正是这种概率分布向量x\boldsymbol{x}x本身的分布特性。
数学形式
Dirichlet分布的概率密度函数形式如下:
f(x∣αm)∝∏i=1Nxiαmi−1f(\boldsymbol{x}|\alpha\boldsymbol{m}) \propto \prod_{i=1}^N x_i^{\alpha m_i - 1}f(x∣αm)∝i=1∏Nxiαmi−1
我们无需过度关注公式的细节,但需要理解该分布由参数u=αm\boldsymbol{u} = \alpha\boldsymbol{m}u=αm控制,其中:
- 基向量m\boldsymbol{m}m:这是一个NNN维向量,满足mi>0m_i > 0mi>0且∑i=1Nmi=1\sum_{i=1}^N m_i = 1∑i=1Nmi=1,可以看作一个基准概率分布。该参数控制着x\boldsymbol{x}x的总体趋势。
- 浓度参数α\alphaα:这是一个正实数,控制着x\boldsymbol{x}x向基向量m\boldsymbol{m}m集中的程度。α\alphaα值越大,x\boldsymbol{x}x越可能接近m\boldsymbol{m}m。
直观理解是:基向量m\boldsymbol{m}m提供了一个基准分布,而α\alphaα衡量了生成分布与这个基准的相似程度。值得注意的是,m\boldsymbol{m}m实际上是随机向量x\boldsymbol{x}x的期望值,即E[x]=mE[\boldsymbol{x}] = \boldsymbol{m}E[x]=m。
Dirichlet分布在联邦学习中的应用
在联邦学习的数据集划分中,我们可以利用Dirichlet分布生成不同类别数据在各个客户端上的分布比例向量x\boldsymbol{x}x。通常,我们将基向量m\boldsymbol{m}m设为均匀向量(即每个元素相等),通过调节浓度参数α\alphaα来控制生成的比例向量x\boldsymbol{x}x的均衡程度。
当α\alphaα很小时,生成的分布向量x\boldsymbol{x}x会显著偏离基向量m\boldsymbol{m}m,导致x\boldsymbol{x}x中各元素间差异较大,从而实现不同客户端上数据分布的非独立同分布特性。
实践应用
我们可以使用NumPy库中的numpy.random.dirichlet函数来生成各类别数据在不同客户端上的分布比例。
函数介绍
numpy.random.dirichlet(alpha, size=None)参数说明:
alpha:Dirichlet分布的参数,长度为KKK的数组,表示分布的浓度参数size:输出形状。如果为None,则返回单个KKK维向量;如果给定形状,则返回该形状的数组,其中每个元素是一个KKK维向量
返回值:从Dirichlet分布中采样的随机向量,形状由size参数决定
代码示例
以下代码展示了如何使用Dirichlet分布生成不同浓度参数下的样本,并可视化结果:
import numpy as np
import matplotlib.pyplot as plt# 定义三组不同的浓度参数α和基向量m的组合
# 注意:这里实际上定义的是α*m,即Dirichlet分布的完整参数
us = [(0.1, 0.1, 0.1), (1, 1, 1), (10, 10, 10)] # 3组不同的u=alpha*m参数# 初始化存储采样点的列表
points = [[] for i in range(3)]# 对每组参数进行采样
for i in range(3):print(f"参数组 us[{i}]: {us[i]}")# 从Dirichlet分布中采样100个点points[i] = np.random.dirichlet(us[i], size=100)print(f"采样点 points[{i}] 的形状: {points[i].shape}")# 准备可视化数据:提取前两个维度用于二维散点图
xs, ys = [[] for i in range(3)], [[] for i in range(3)]for i in range(3):# 将三维点拆分为三个坐标列表,这里只取前两个维度用于绘图xs[i], ys[i], _ = list(zip(*points[i]))print(f"xs[{i}] 的前5个值: {xs[i][:5]}")print(f"ys[{i}] 的前5个值: {ys[i][:5]}")# 创建可视化图形
fig, axs = plt.subplots(1, 3, figsize=(12, 4), sharey=True)for i in range(3):axs[i].set_title(f"$αm={us[i]}$")axs[i].scatter(xs[i], ys[i], alpha=0.7)axs[i].set_xlabel("$X_1$")axs[i].set_ylabel("$X_2$")axs[i].set_xlim(0, 1)axs[i].set_ylim(0, 1)plt.suptitle(r"Dirichlet分布采样:$(X_1, X_2)$在$(X_1, X_2, X_3)$中的分布")
plt.tight_layout()
plt.show()
可视化结果分析
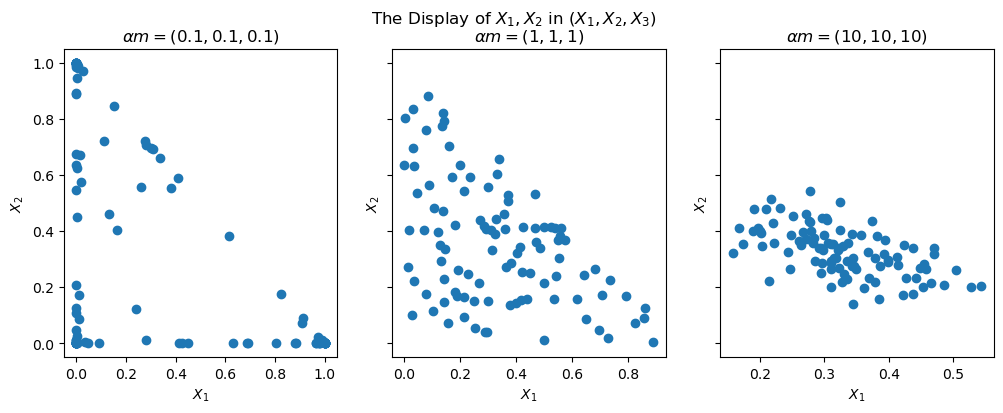
这三张图直观展示了Dirichlet分布的浓度参数α\alphaα对样本集中程度的控制作用:
- 当α\alphaα较小(如0.1)时,样本点分布较为分散,倾向于集中在单纯形的角落,这对应于联邦学习中高度非独立同分布的情况
- 当α\alphaα适中(如1)时,样本点分布相对均匀
- 当α\alphaα较大(如10)时,样本点高度集中于基向量m=(1/3,1/3,1/3)\boldsymbol{m}=(1/3,1/3,1/3)m=(1/3,1/3,1/3)附近,这对应于联邦学习中接近独立同分布的情况
这种特性使得Dirichlet分布成为联邦学习中控制数据分布不平衡程度的理想工具。
总结
Dirichlet分布通过调节浓度参数α\alphaα,能够有效地控制生成分布与基准分布的偏离程度,从而在联邦学习环境中灵活地模拟不同程度的非独立同分布数据。这种方法为研究不同数据分布特性对联邦学习算法性能的影响提供了有力的技术支持。