CS336笔记2-Architectures,Hyperparameters
timeline:
11月4日开始学,
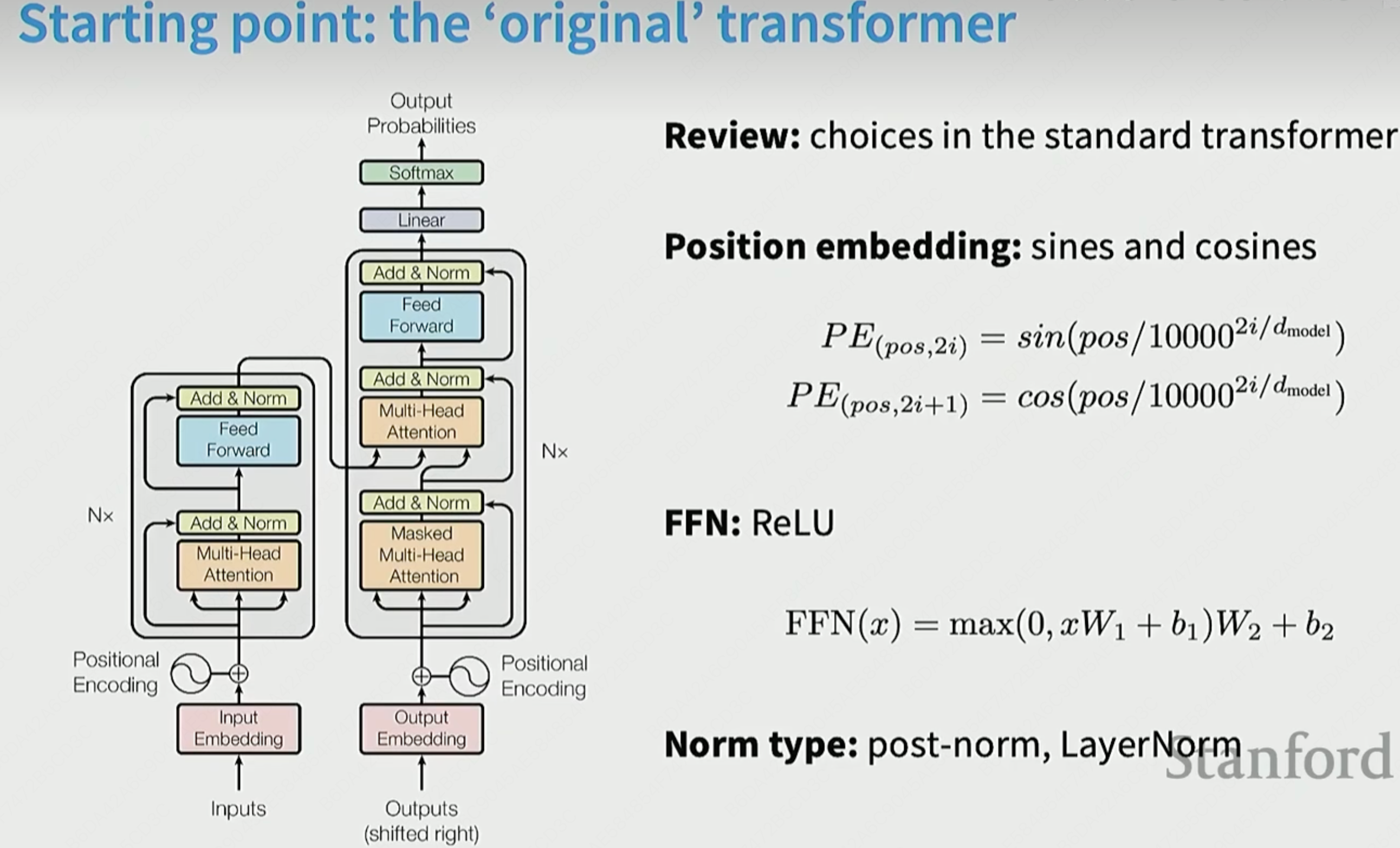
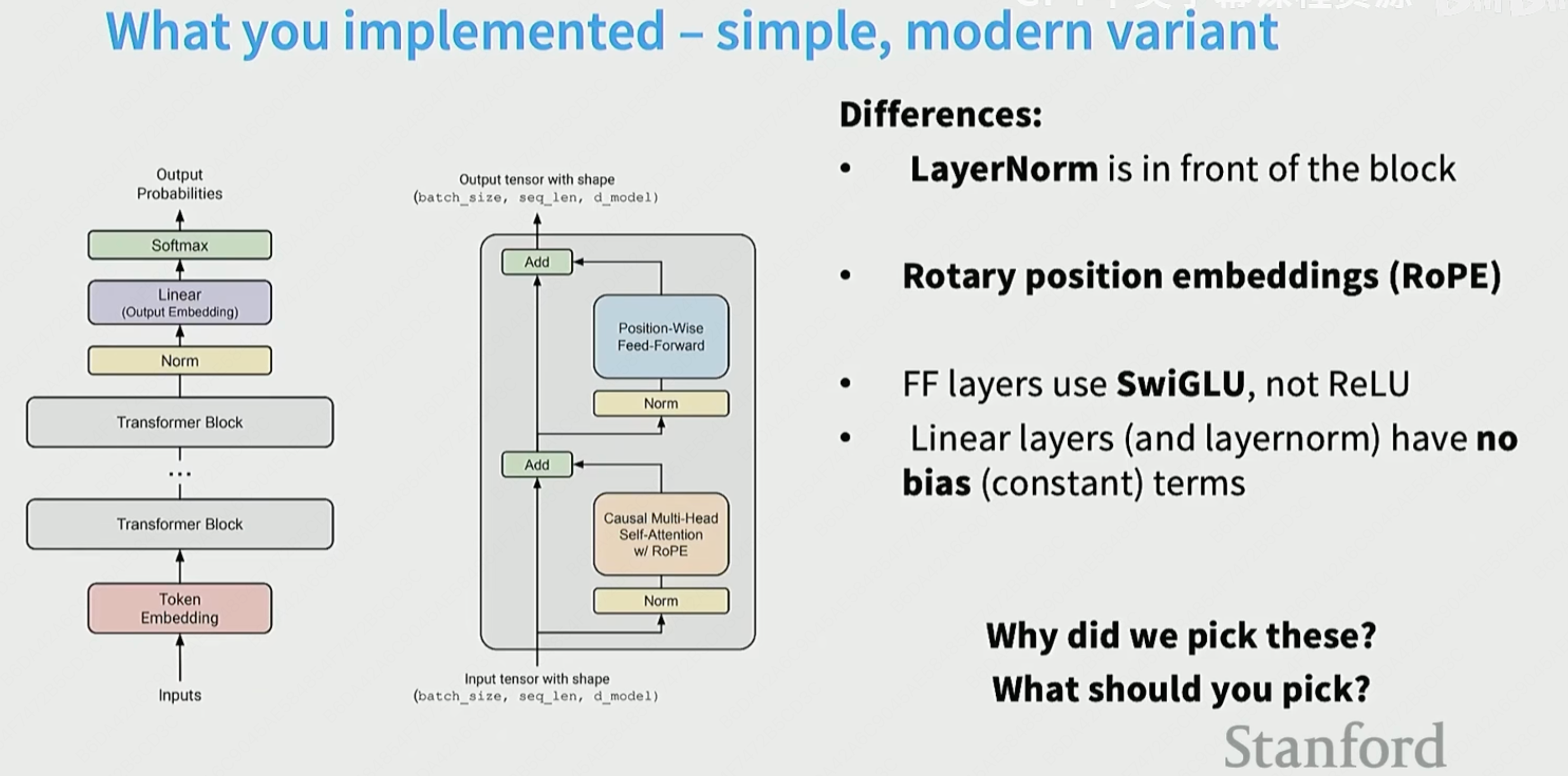


Postnorm->Prenorm->RMSNorm
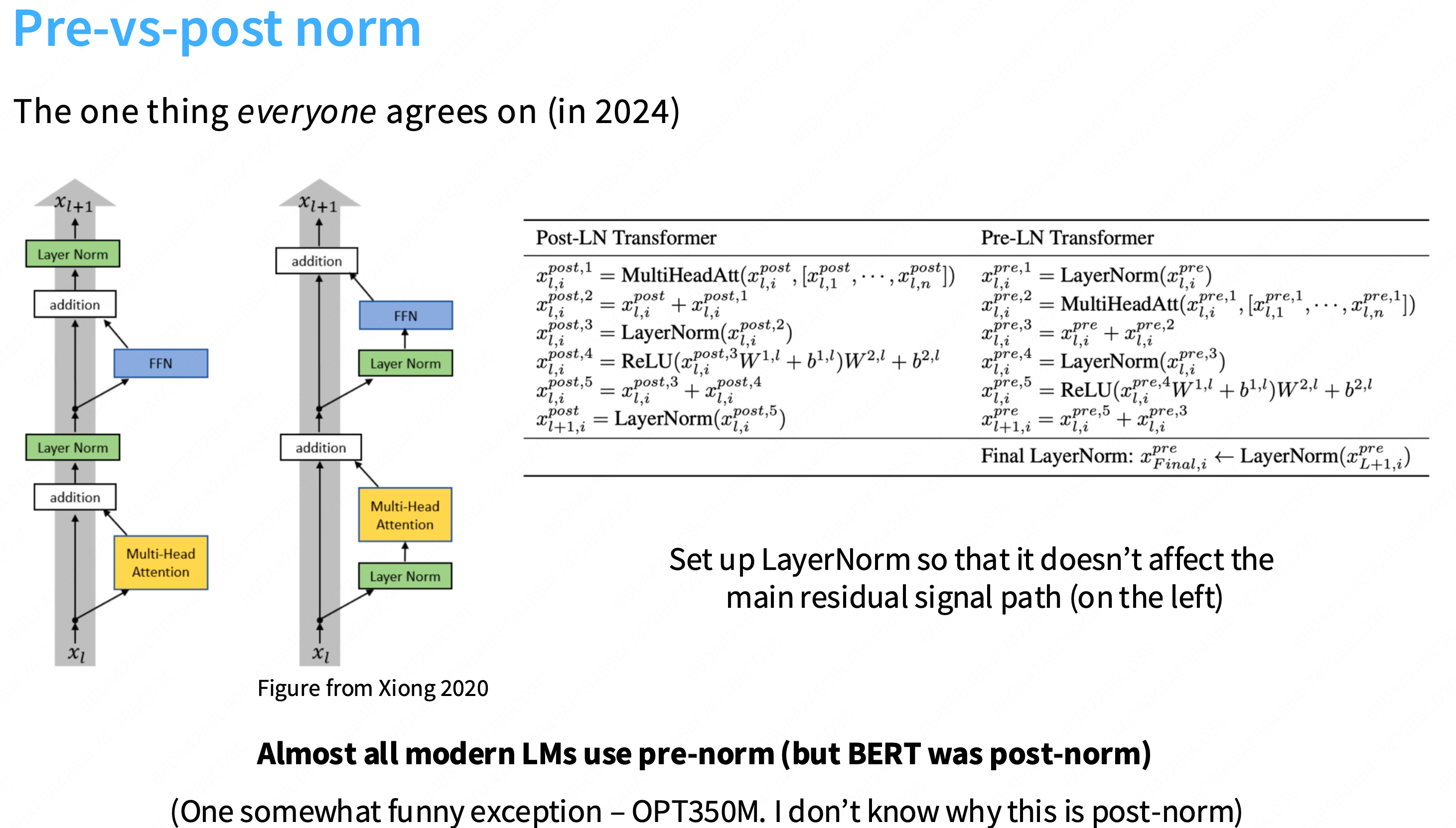
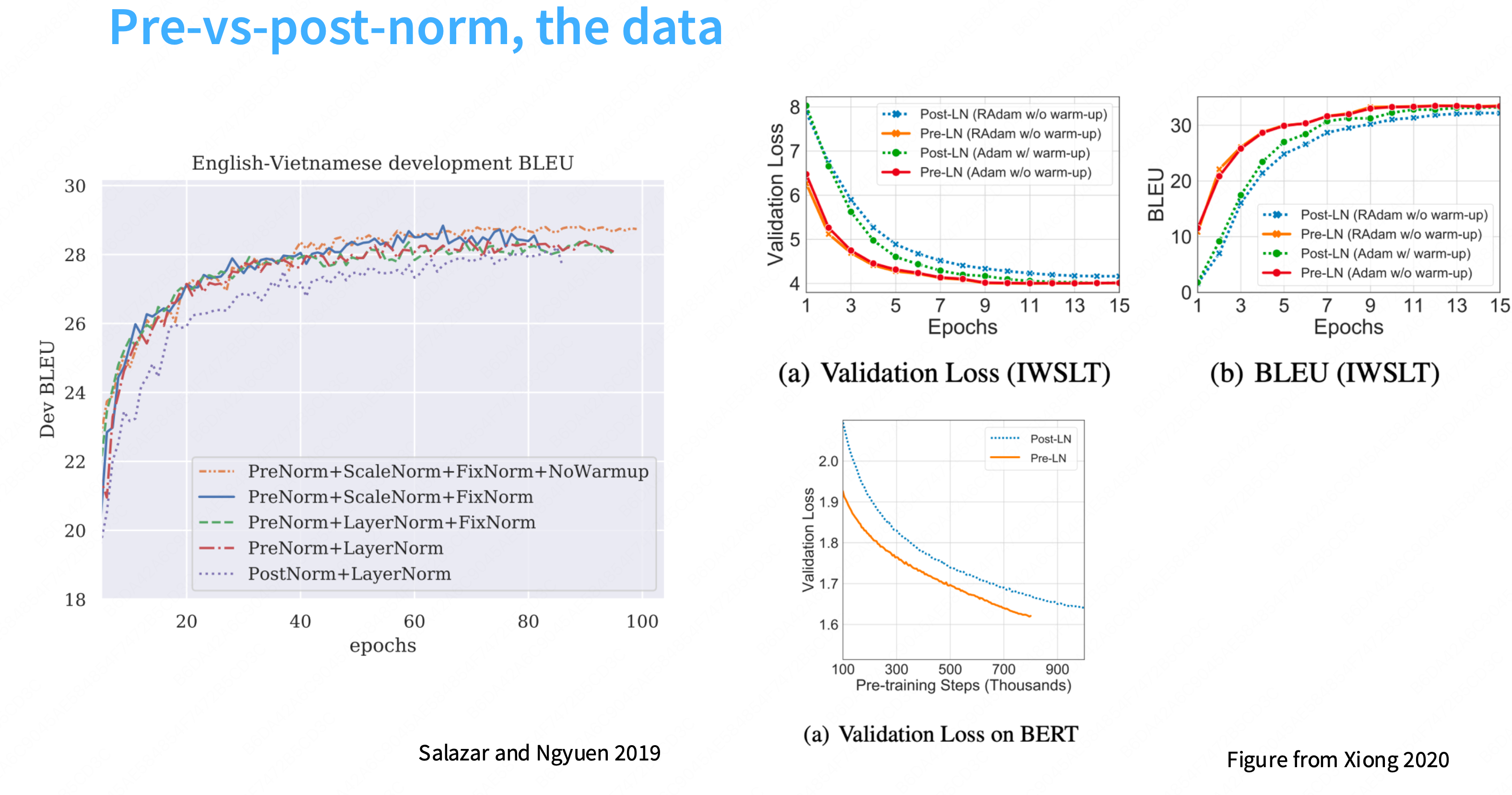
为什么layernorm放在后面更加有效?
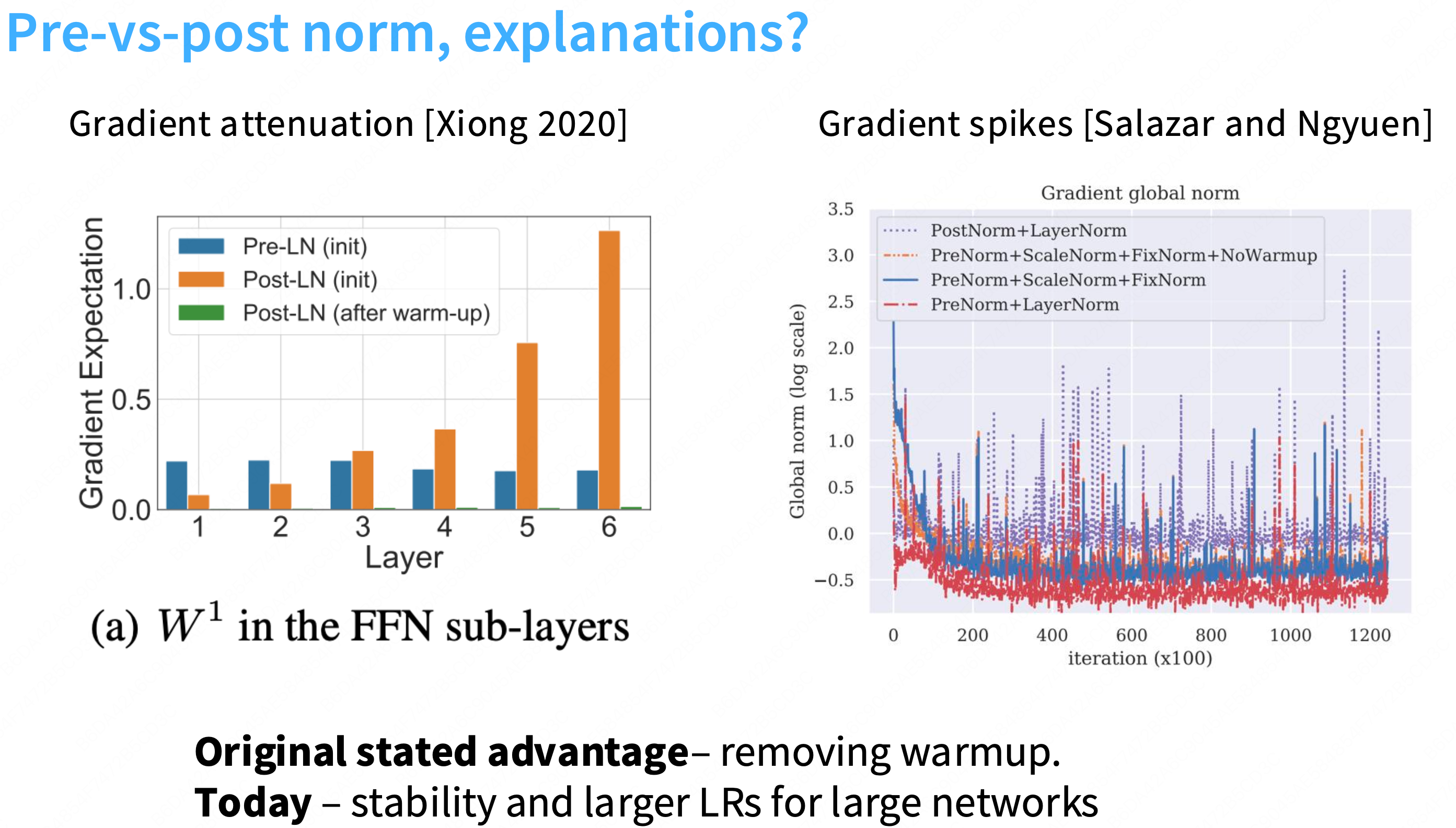
更多的一种解释是:“前置归一化是一个更加稳定的训练架构”。不容易出现梯度尖刺的情况,更加稳定。在残差流中放置layernorm是不好的

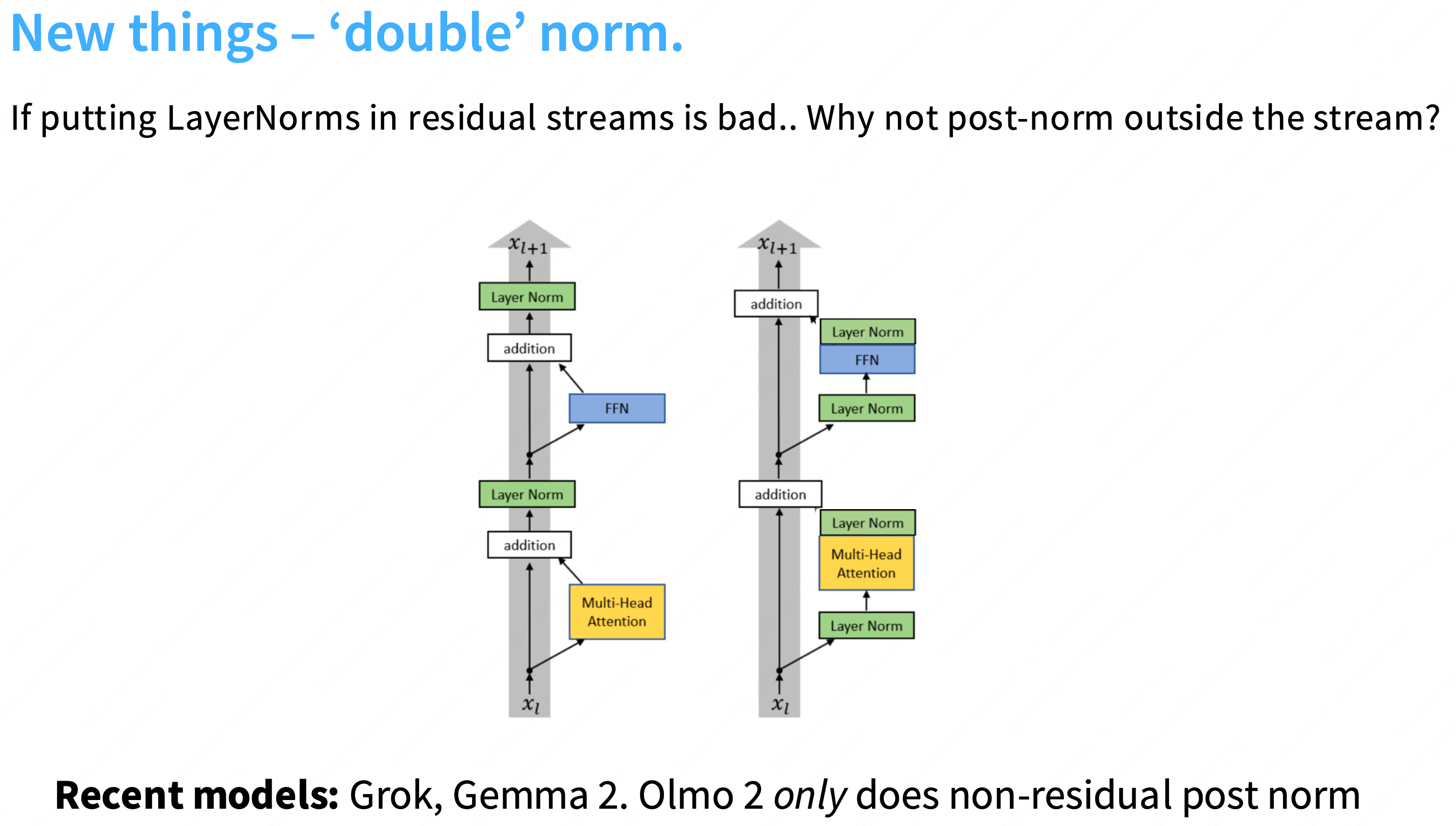
Q: 为什么在残差流中加入layernorm不好?
a: 一个直观的观点是,残差给你从网络顶部到底部的这种恒等链接,因此,如果你视图训练非常深的网络,这使得梯度传播非常容易,因此,有很多关于lstm和其他状态空间模型在反向传播梯度时困难的讨论,但这种恒等链接没有任何这样的问题,因此,在中间放置layernorm可能会干扰这种梯度行为。
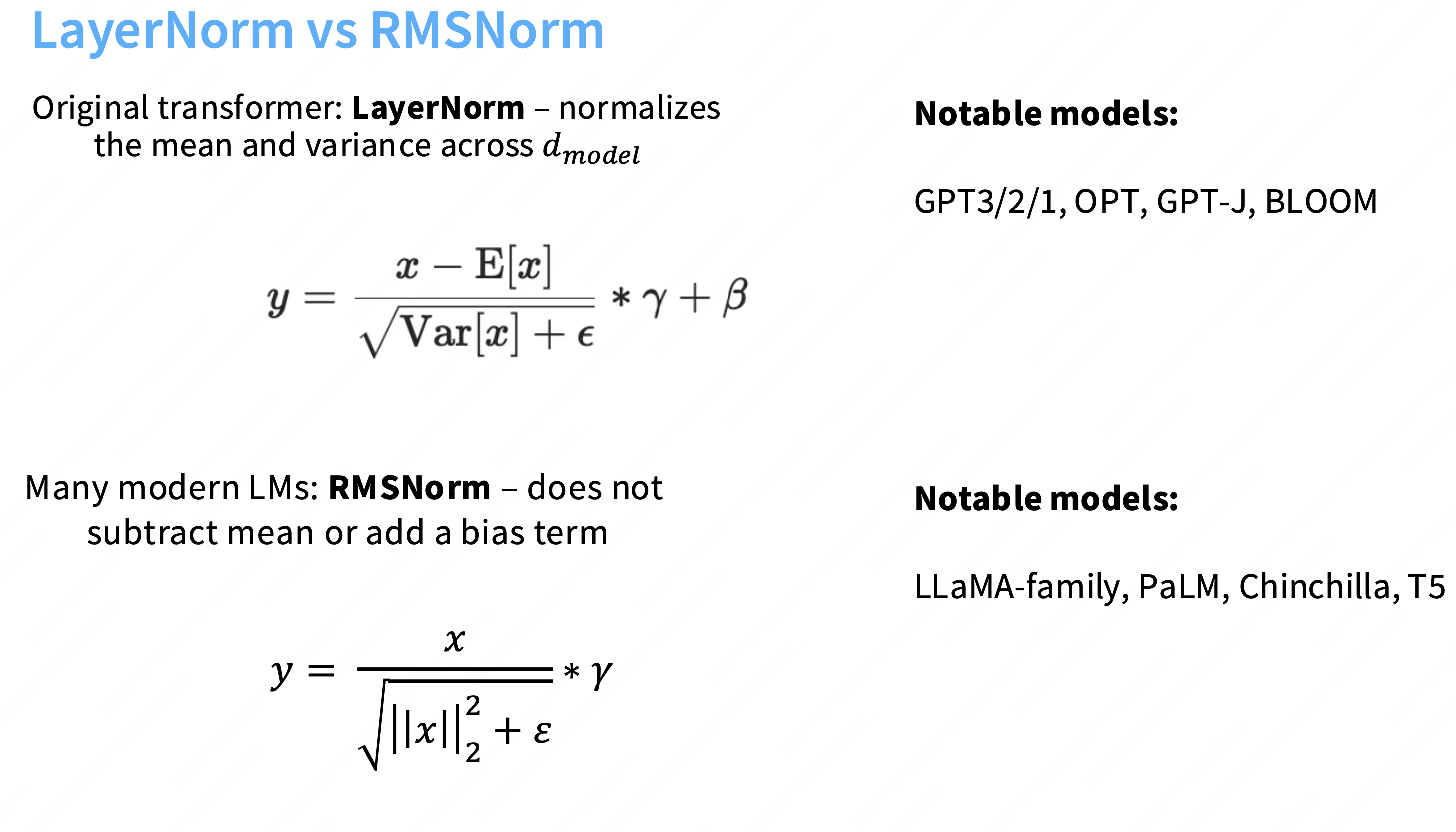
可以简单的认为layernorm就是一个标准差,然后通过一个gamma因子γ放大。
Q:为什么当前的模型都转向于使用rmsnorm?
A:因为使用RMSnorm和使用layernorm效果一样好,现代模型(尤其是 LLaMA 系列)偏向于使用 RMSNorm 的最主要、最直接的原因是:为了提高计算效率(即速度)。

①不需要再减去均值,不必添加bias,需要从内存加载回计算单元的参数就会变少。
②虽然RMSnorm优化的浮点计算量仅在transformer中占比0.17%,但这并不是唯一需要考虑的。因为计算量flops≠运行时间runtime。还需要仔细的考虑内存移动。
下图可以看到,虽然归一化(如layernorm、softmax等)所占的计算量仅有0.17%,但是实际运行时间占比达到了25%。一个核心原因是:归一化操作仍然会产生大量的内存移动开销,因此优化这些底层的操作十分重要。

右边这张图有点意思,不仅仅是一个架构图(它展示了 MHA 子层),更是一个性能瓶颈分析图。
核心概念:两大瓶颈
GPU 只有两种工作状态,这由计算强度 (AI) 决定:
计算受限 (Compute-Bound)
高 AI (如
153)含义: 每从显存 (HBM) 中读取 1 字节的数据,GPU 都能执行大量的计算(例如 153 次 FLOPs)。
状态: GPU 的计算核心(Tensor Cores)100% 繁忙,而显存正在“休息”。这是理想状态,能实现高 MFU。
内存带宽受限 (Memory-Bound)
低 AI (如
3.5或1/3)含义: 每读取 1 字节,GPU 只能执行很少的计算。
状态: GPU 的计算核心极其空闲(“挨饿”),大部分时间都在**“等待”数据从缓慢的 HBM 显存加载到高速的 SRAM 缓存中。这是糟糕的状态**,导致 MFU 极低。
3. 逐一分析图中组件:现在,我们用这个“瓶颈”视角来分析这张图:
a) MHA (Multi-Head Attention)
FLOPs (
43G): 430 亿次运算。这几乎是这个块的全部计算量 (43G vs 4M+4M+29M)。AI (
153): 极高!结论: MHA 是**“计算受限 (Compute-Bound)”**的。CS336 关联: 这完全符合我们的推导。MHA 的核心是
Q@K.T和scores@V这样的大型矩阵乘法 (Matmul),它们具有极高的计算强度。这部分是“好”的,能跑满 MFU。b) Dropout 和
+(残差连接)
FLOPs (
4M): 仅 400 万次运算,计算量完全可以忽略不计。AI (
1/3): 极低! (小于 1)结论: 它们是**“内存带宽受限 (Memory-Bound)”**的。
CS336 关联: 这也符合我们的推导。
Dropout和Add都是逐元素 (Element-wise) 操作(图例○)。它们需要从 HBM 读取整个[B, L, D]张量,只做 1 次乘法或加法,再写回 HBM。这是纯粹的 I/O 瓶颈。c) LayerNorm
FLOPs (
29M): 计算量也基本可以忽略不计。AI (
3.5): 非常低!结论: LayerNorm 是**“内存带宽受限 (Memory-Bound)”**的。
这张图用数据可视化了 CS336 中一个的核心性能问题:
一个 Transformer 块 99% 以上的**计算量(FLOPs)**都集中在
MHA和FFN(图中未显示)中。但是,
MHA和FFN并不是唯一的性能瓶颈。诸如
LayerNorm,Dropout,Residual Add这样的“辅助”操作,虽然计算量(FLOPs)小到可以忽略,但它们是**严重的“内存带宽受限”**操作。总的执行时间 = Time(Compute-Bound) + Time(Memory-Bound)。
如果我们的 MFU 很低,很可能不是因为
MHA(43G FLOPs) 运行得慢,而是因为 GPU 的计算核心在空转,等待LayerNorm(29M FLOPs) 慢悠悠地从 HBM 读写数据。这精确地解释了为什么我们要痴迷于Kernel Fusion(内核融合),以及为什么
RMSNorm(比LayerNorm更快)会成为 LLaMA 的首选。
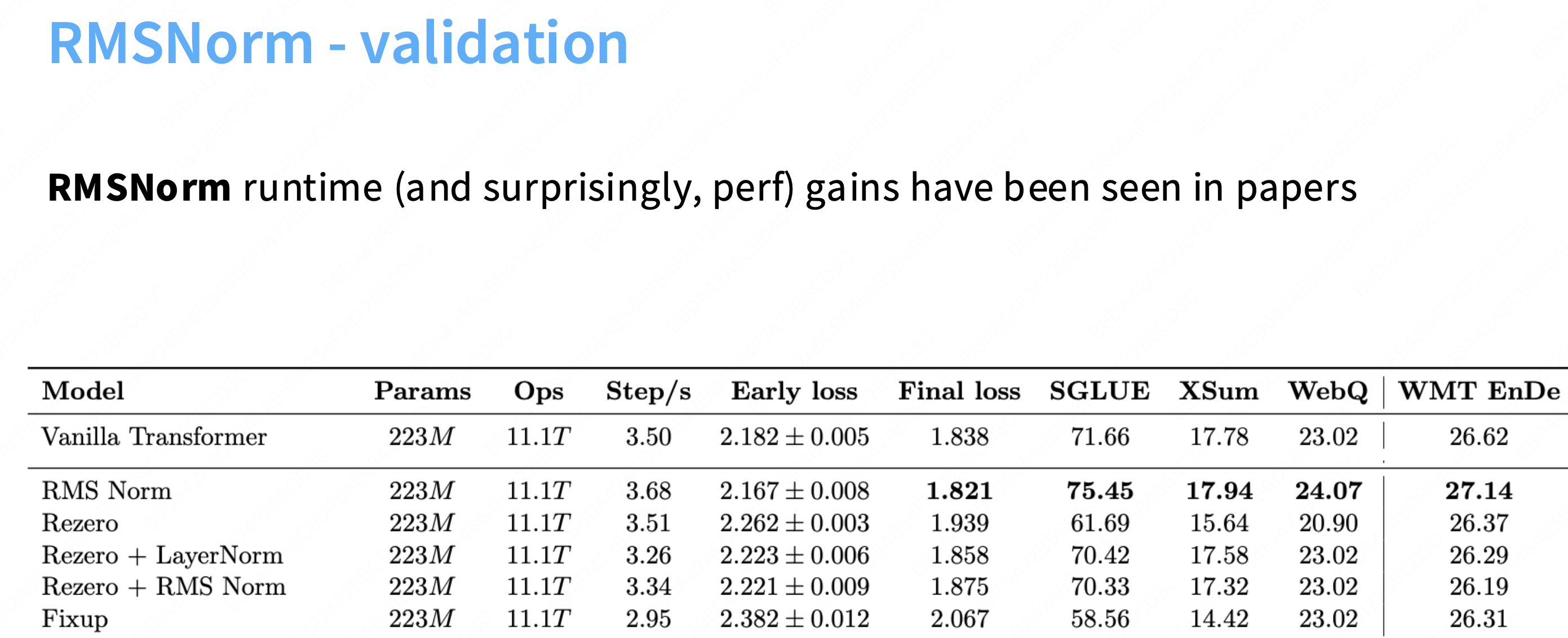
使用rmsnorm之后,step/s增加,final_loss也得到了优化。
去掉bias项

经验上,去掉这些bias通常会稳定这些llm的训练。