大模型应用开发与私有化部署
LLM
基本概念
大型语言模型,基于海量的数据进行学习得到的模型。
大模型技术选型
在线大模型:
OpenAI GPT
Google Gemini
Authropic Claude
智谱AI GLM
百度 文心一言
优缺点:
模型性能优越、研发成本低(0.005-0.008元/1000个token)、可以站在巨人的肩膀上快速探索前沿技术应用,稳定性和使用安全性高,但数据安全存在隐患,业务受制于人,上车容易下车难。
开源大模型:
Meta Llama(3.1 405B)
Mistral AI
X AI Grok
阿里 通义千问 Qwen
Baichuan
360 zhinao
优缺点:( 7B大模型->70亿->4张4090 ->语料->上十亿 -> )
完全自主可控,扩展性强,定制型强,数据安全有保障,但需要投入大量算力和开发成本,依赖开源,不好转身。
Llama系列
LLaMA系列大模型是Meta公司在2023年2月开源的基于 transformer 架构的大型语言模型, 包括四种尺寸(7B 、13B 、30B 和 65B),并在2024年进一步发展,推出了Llama 3版本。Llama3在多种行业基准测试中展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型之一。
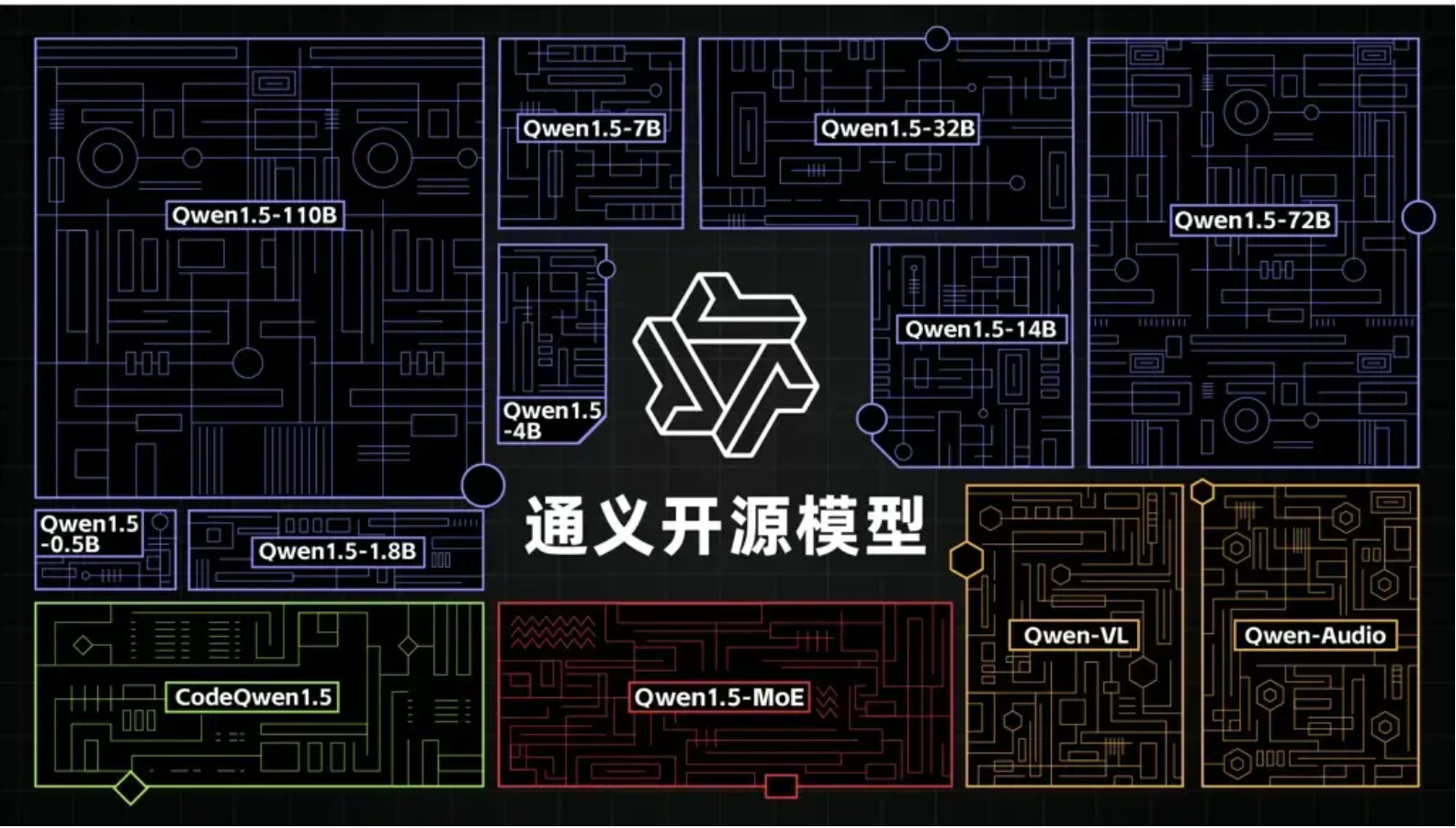
Qwen系列
文档:https://qwen.readthedocs.io/zh-cn/latest/getting_started/quickstart.html
随着GLM的闭源,阿里的通义千问已经成为了国内开源大模型的领袖。
Qwen平均1个季度发布一个版本,性能始终处于开源大模型的第一梯队水平。目前最新发布版本:Qwen2.5。
阿里的魔塔社区(https://modelscope.cn/models)也随着技术迭代更新,成为了国内第一AI模型社区,号称“中文版HuggingFace(https://huggingface.co/)”,吸引了大批优质的大模型开发者参与进来,同时魔塔社区不仅提供免费在线开发环境(类似谷歌的Colab)和限时GPU算力(100小时32GB显存),助力开发者在线训练微调大模型,还与阿里云灵积平台(DashScope)深度绑定,让开发者训练微调完成的模型可以快速落地实施到阿里云架构服务器上(按量收费),形成了一整套混合模型在线服务的生态模式。
阿里还提供了高度适配的SWIFT轻量级微调框架和Qwen-Agent开发框架,其中SWIFT提供了代码环境和脚本微调两种模式,配套海量开源微调数据集,可以执行包括知识灌注、模型自我意识微调、Agent能力微调和领域能力微调等功能,还提供一键微调等功能。Qwen-Agent则支持高效稳定Multi Function calling、ReAct功能,支持调用开源大模型以及灵积平台的在线模型。
prompt
提示工程(Prompt Engineering)是一项通过优化提示词(Prompt)和生成策略,从而获得更好的模型返回结果的工程技术。
其基本实现逻辑如下:
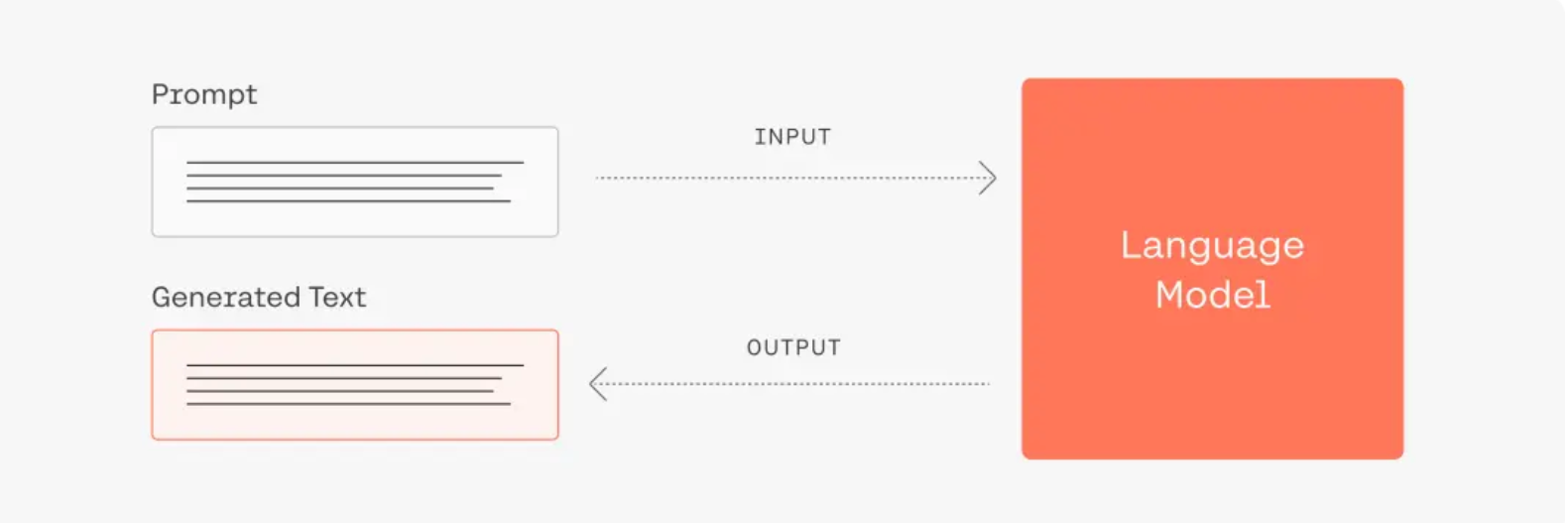
简单而言,大模型的运行机制是“下一个字词预测”。用户输入的prompt即为大模型所获得上下文,大模型将根据用户的输入进行续写,返回结果。因此,输入的prompt的质量将极大地影响模型的返回结果的质量和对用户需求的满足程度,总的原则是“用户表达的需求越清晰,模型更有可能返回更高质量的结果”。
prompt工程这种微调手段对于大模型本身的推理能力的提升的范围大概也就10%左右。大模型训练工程师,prompt工程多数用在在线大模型,而不是开源大模型。
Prompt经验总结:清晰易懂、提供例子和锁定上下文、明确步骤、准确表达意图。
去玩一下吧:https://modelscope.cn/studios/LLMRiddles/LLMRiddles/summary
通常情况下,每条信息都会有一个角色(role)和内容(content):
- 系统角色(system)用来向语言模型传达开发者定义好的核心指令,优先级是最高的。
- 用户角色(user)则代表着用户自己输入或者产生出来的信息。
- 助手角色(assistant)则是由语言模型自动生成并回复出来。
系统指令(system)
system message系统指令为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。大部分LLM模型的系统指令System message的权重强化高于人工输入的prompt,并在多轮对话中保持稳定,您可以使用系统消息来描述助手的个性,定义模型应该回答和不应该回答的内容,以及定义模型响应的格式。
默认的System message:You are a helpful assistant.
下面是一些system message的使用示例:
| 行业 | 角色 | system message |
|---|---|---|
| 教育 | 数学老师 | 你是一名优秀的数学老师,教导学生学习数学,经常使用简单通俗的生活例子使复杂的数学概念变得更容易理解。 |
| 工作 | python工程师 | 你是一名行业顶尖的Python开发工程师,会使用详细步骤和代码帮助公司和同事解决项目开发过程中的问题。 |
| 创作 | 小红书文案 | 你是一名优秀的小红书文案创作者,擅长使用诙谐风格来创作,经常会在创作中分享生活经验和工作经验。 |
System message可以被广泛应用在:角色扮演、语言风格、任务设定、限定回答范围。
用户指令(user)
用户指令是最常用的提示组件,主要功能是向模型说明要执行的操作。以下举例:
| 指令类型 | prompt |
|---|---|
| 简单指令 | 简要介绍一下xx公司。 |
| 详细指令 | 简要介绍一下xx公司,并介绍它的公司创始人,主营业务,使命和愿景。 |
ollama
基本介绍
Ollama 是一个开源的大型语言模型服务工具,专为在服务器上便捷部署和运行大型语言模型(LLMs)而设计,它提供了一个简洁且用户友好的命令行界面,通过这一界面,用户可以轻松地部署和管理各类开源的 LLM。具有以下特点和优势:
- 开源免费:Ollama 以及其支持的模型完全开源免费,任何人都可以自由使用、修改和分发
- 简化部署:Ollama 目标在于简化在 Docker 容器中部署大型语言模型的过程,使得非专业用户也能方便地管理和运行这些复杂的模型,无需复杂的配置和安装过程,只需几条命令即可启动和运行Ollama
- 轻量级与可扩展:作为轻量级框架,Ollama 保持了较小的资源占用,同时具备良好的可扩展性,允许用户根据需要调整配置以适应不同规模的项目和硬件条件,即使在普通笔记本电脑上也能流畅运行。
- API支持:提供了一个简洁的 API,使得开发者能够轻松创建、运行和管理大型语言模型实例,降低了与模型交互的技术门槛。
- 预构建模型库:包含一系列预先训练好的大型语言模型,用户可以直接选用这些模型应用于自己的应用程序,无需从头训练或自行寻找模型源。
官方站点:https://ollama.com/
Github:https://github.com/ollama/ollama
安装使用
下载地址:https://ollama.com/download,根据系统类型进行安装,这里演示的是window系统安装过程。
注意,在windows下安装ollama是不允许自定义位置的,会默认安装在系统盘,而后续使用的大模型可以选择自定义保存路径。
安装过程,非常简单:
安装完成以后,新开一个命令终端并输入命令ollama,如果效果如下则表示安装成功:
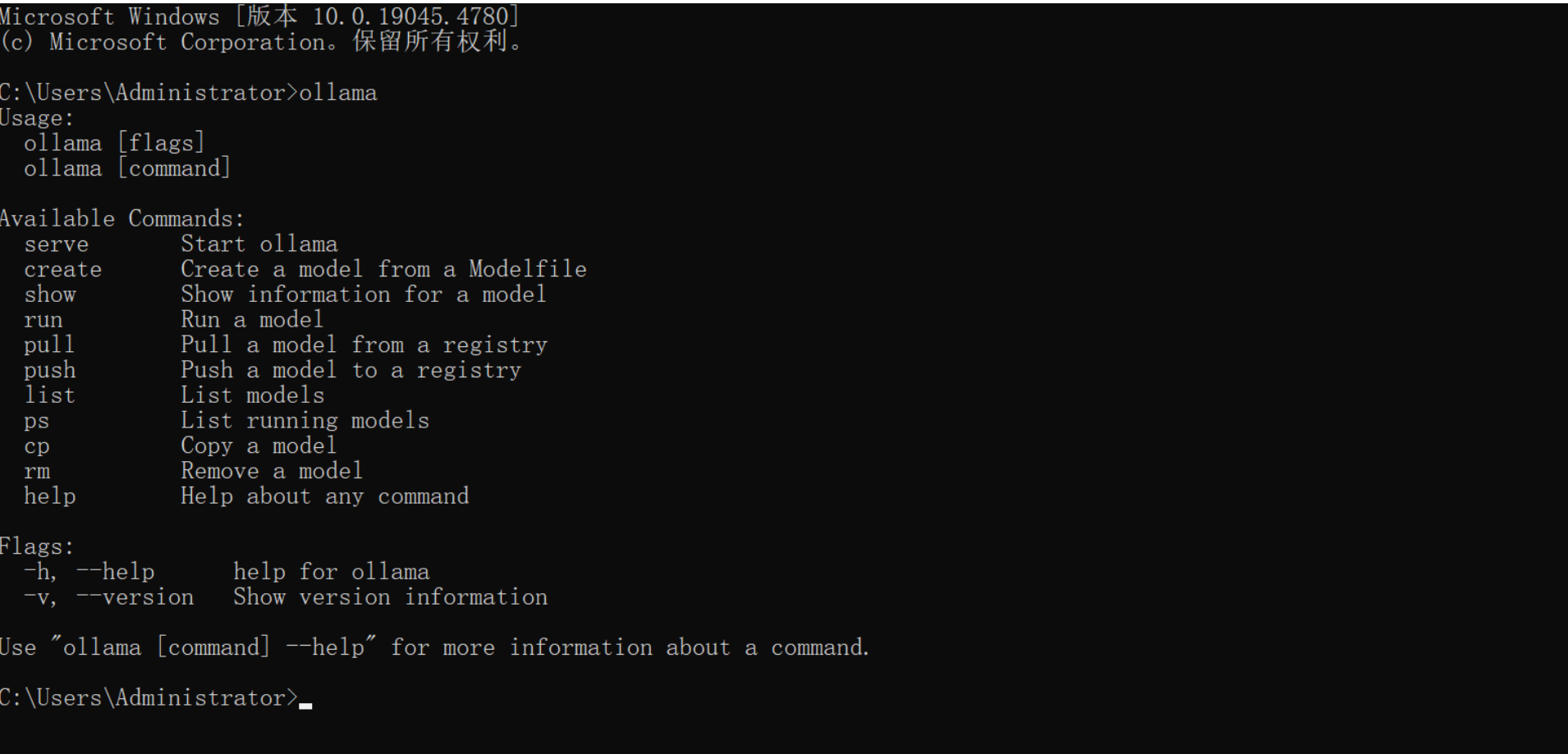
拉取并运行一个大模型:
ollama run qwen2.5:3b
常用命令
这里的命令,全系统通用的。
| 命令 | 描述 |
|---|---|
| ollama list | 列出本地拉取的模型镜像列表 |
| ollama pull | 从远程仓库中拉取模型镜像文件 |
| ollama run | 运行模型,如果本地没有则先默认执行pull命令进行拉取 |
| ollama ps | 展示当前加载的模型、它们所占的内存大小以及使用的处理器类型(GPU 或 CPU) |
| ollama serve | 启动ollama的http网络服务 |
| ollama rm | 删除模型 |
| ollama cp | 复制模型 |
| ollama push | 推送模型到远程仓库,需要在ollama官网上面注册账号。 |
| ollama create | 从模型文件Modelfile创建自定义模型 |
| help | 帮助提示 |
模型仓库
ollama仓库地址:https://ollama.com/library
hugging face仓库地址:https://huggingface.co/models 【镜像】https://hf-mirror.com/models
魔塔社区:https://modelscope.cn/models
自定义模型
魔塔下载大模型说明文档:https://www.modelscope.cn/docs/%E6%A8%A1%E5%9E%8B%E7%9A%84%E4%B8%8B%E8%BD%BD
使用魔塔下载大模型文件,安装魔塔工具(python3.10^):
pip install modelscope
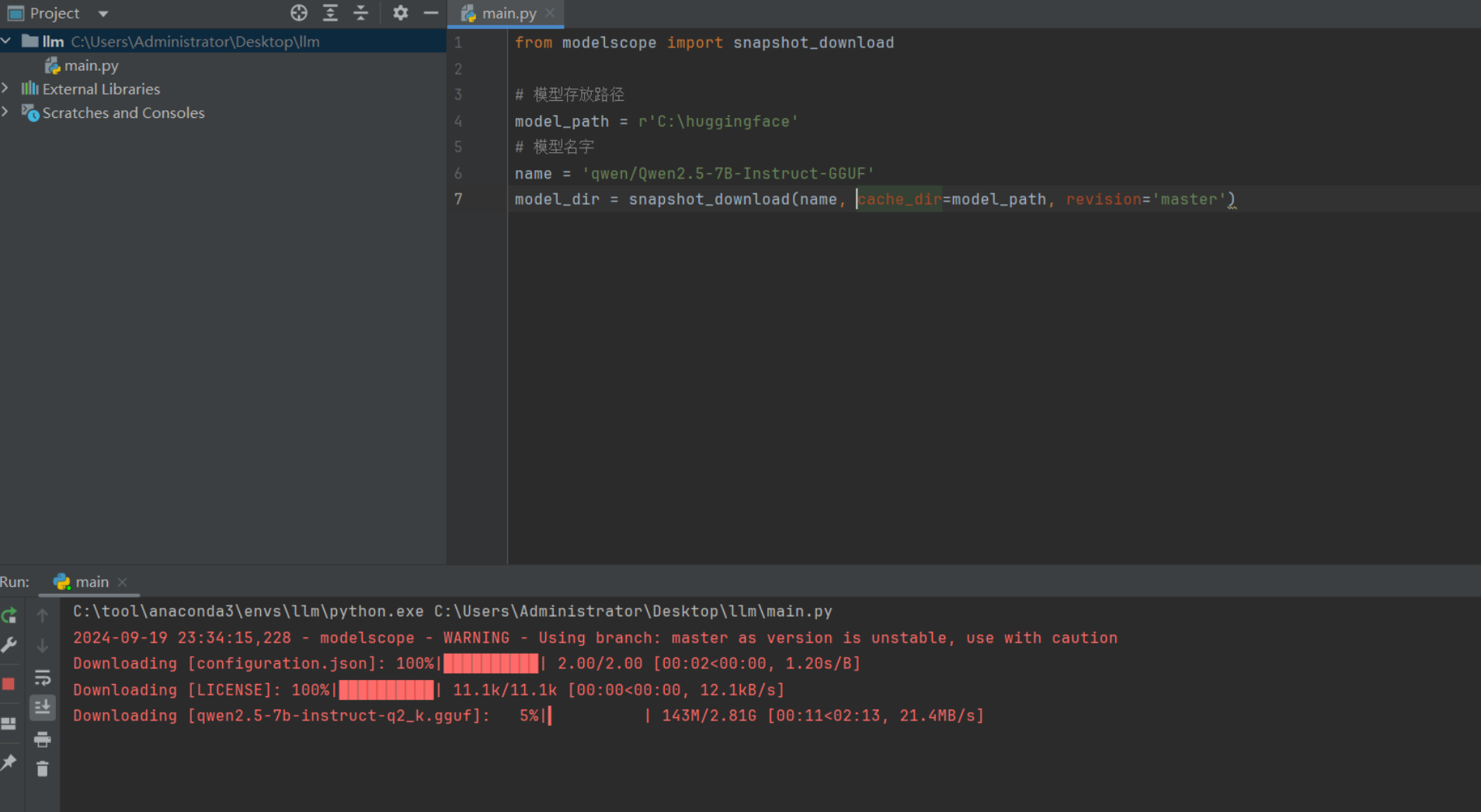
基于python脚本调用魔塔拉取模型文件,modelscope_download.py,代码:
from modelscope import snapshot_download# 模型名字
name = 'qwen/Qwen2.5-7B-Instruct-GGUF'
# 模型存放路径,需要手动创建对应的目录,并保证有足够的空间,否则下载出错。
model_path = r'C:\huggingface'
model_dir = snapshot_download(name, # 仓库中的模型名cache_dir=model_path, # 本地保存路径,revision='master', # 分支版本allow_file_pattern="Qwen2.5-7B-Instruct-GGUF" # 模糊匹配的文件名
)
# modelscope download --model=qwen/Qwen2.5-7B-Instruct-GGUF --include "qwen2.5-7b-instruct-q5_k_m*.gguf" --local_dir .
执行效果如下:
Modelfile
Ollama自定义大模型需要通过Modelfile定义和配置模型的行为和特性,在使用 Ollama 进行本地部署和运行大型语言模型时,Modelfile 扮演着至关重要的角色。
Modelfile 是使用 Ollama 创建和共享模型的方案。它包含了构建模型所需的所有指令和参数,使得模型的创建和部署变得简单而直接。
常用指令
Modelfile中不区分大小写,但是强烈要求一定大写!!
| 操作说明 | 描述 |
|---|---|
FROM <model name>:<tag> (必须) | 定义要使用的基础模型,如果值是一个路径表示镜像文件在本地,如果是模型名称则默认到官方仓库中拉取。 |
SYSTEM """<system message>""" | 指定将在模板中设置的系统消息. |
PARAMETER <parameter> <parametervalue> | 设置 Ollama 如何运行模型的参数 |
TEMPLATE | 要发送给模型的完整提示模板. |
ADAPTER | 定义适用于模型的 (Q)LoRA 适配器. |
LICENSE | 指定合法的许可证。 |
MESSAGE <role> <message> | 指定消息历史记录。 |
PARAMETER的有效参数和值
| 参数 | 描述 | 值类型 | 示例用法 |
|---|---|---|---|
| mirostat | 启用 Mirostat 采样来控制困惑度。(默认值:0,0 = 禁用,1 = Mirostat,2 = Mirostat 2.0) | int | mirostat 0 |
| mirostat_eta | 影响算法对生成文本反馈的响应速度。较低的学习率会导致调整速度较慢,而较高的学习率会使算法响应更快。(默认值:0.1) | float | mirostat_eta 0.1 |
| mirostat_tau | 控制输出的连贯性和多样性之间的平衡。值越低,文本越集中、越连贯。(默认值:5.0) | float | mirostat_tau 5.0 |
| num_ctx | 设置用于生成下一个标记的上下文窗口的大小。(默认值:2048) | int | num_ctx 4096 |
| repeat_last_n | 设置模型回溯多远以防止重复。(默认值:64,0 = 禁用,-1 = num_ctx) | int | repeat_last_n 64 |
| repeat_penalty | 设置对重复的惩罚力度。较高的值(例如 1.5)将对重复的惩罚力度更大,而较低的值(例如 0.9)将更宽松。(默认值:1.1) | float | repeat_penalty 1.1 |
| temperature | 模型的温度。增加温度将使模型的回答更具创意。(默认值:0.8) | float | temperature 0.7 |
| seed | 设置用于生成的随机数种子。将其设置为特定数字将使模型针对同一提示生成相同的文本。(默认值:0) | int | seed 42 |
| stop | 设置要使用的停止序列。遇到此模式时,LLM 将停止生成文本并返回。可以通过stop在模型文件中指定多个单独的参数来设置多个停止模式。 | string | stop “AI assistant:” |
| tfs_z | 尾部自由采样用于减少输出中可能性较小的标记的影响。较高的值(例如 2.0)将进一步减少影响,而值 1.0 则禁用此设置。(默认值:1) | float | tfs_z 1 |
| num_predict | 生成文本时要预测的最大标记数。(默认值:128,-1 = 无限生成,-2 = 填充上下文) | int | num_predict 42 |
| top_k | 降低产生无意义答案的概率。值越高(例如 100)答案就越多样化,值越低(例如 10)答案就越保守。(默认值:40) | int | top_k 40 |
| top_p | 与 top-k 配合使用。较高的值(例如 0.95)将产生更加多样化的文本,而较低的值(例如 0.5)将产生更加集中和保守的文本。(默认值:0.9) | float | top_p 0.9 |
TEMPLATE的模板变量
| 变量 | 描述 |
|---|---|
{{ .System }} | 用于指定自定义行为的系统消息。 |
{{ .Prompt }} | 用户提示消息。 |
{{ .Response }} | 来自模型的响应。生成响应时,此变量后的文本将被省略。 |
MESSAGE的有效角色
| 角色 | 描述 |
|---|---|
| system | 为模型提供系统消息的另一种方法。 |
| user | 用户可能询问的示例消息。 |
| assistant | 模型应如何响应的示例消息。 |
创建模型描述文件Modelfile,编写内容如下:
FROM C:\huggingface\qwen\Qwen2___5-7B-Instruct-GGUF\Qwen2.5-7B-Instruct.Q5_0.gguf# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20TEMPLATE """{{ if .Messages }}
{{- if or .System .Tools }}<|im_start|>system
{{ .System }}
{{- if .Tools }}# ToolsYou are provided with function signatures within <tools></tools> XML tags:
<tools>{{- range .Tools }}
{"type": "function", "function": {{ .Function }}}{{- end }}
</tools>For each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:
<tool_call>
{"name": <function-name>, "arguments": <args-json-object>}
</tool_call>
{{- end }}<|im_end|>
{{ end }}
{{- range $i, $_ := .Messages }}
{{- $last := eq (len (slice $.Messages $i)) 1 -}}
{{- if eq .Role "user" }}<|im_start|>user
{{ .Content }}<|im_end|>
{{ else if eq .Role "assistant" }}<|im_start|>assistant
{{ if .Content }}{{ .Content }}
{{- else if .ToolCalls }}<tool_call>
{{ range .ToolCalls }}{"name": "{{ .Function.Name }}", "arguments": {{ .Function.Arguments }}}
{{ end }}</tool_call>
{{- end }}{{ if not $last }}<|im_end|>
{{ end }}
{{- else if eq .Role "tool" }}<|im_start|>user
<tool_response>
{{ .Content }}
</tool_response><|im_end|>
{{ end }}
{{- if and (ne .Role "assistant") $last }}<|im_start|>assistant
{{ end }}
{{- end }}
{{- else }}
{{- if .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}{{ if .Prompt }}<|im_start|>user
{{ .Prompt }}<|im_end|>
{{ end }}<|im_start|>assistant
{{ end }}{{ .Response }}{{ if .Response }}<|im_end|>{{ end }}"""# set the system message
SYSTEM """你是江小白, 由林墨创建. 你是一个非常厉害的工具人."""
文档:https://qwen.readthedocs.io/en/latest/run_locally/ollama.html#
通过运行以下命令来创建ollama模型
ollama create qwen2.5-7b -f ./Modelfile
运行新建的ollama模型:
ollama run qwen2.5-7b
大模型开发
大模型的基本概念
大语言模型(Large Language Model): 通常是具有大规模参数和计算能力的自然语言处理模型,例如 OpenAI 的 GPT-3 模型。这些模型可以通过大量的数据和参数进行训练,以生成人类类似的文本或回答自然语言的问题。大型语言模型在自然语言处理、文本生成和智能对话等领域有广泛应用。
按照输入数据类型的不同,大模型的分类:
- 语言大模型(NLP):是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。这类大模型的主要特点是它们在大规模语料库上进行了训练,以学习自然语言的各种语法、语义和语境规则。例如:GPT 系列(OpenAI)、Bard(Google)、文心一言(百度)。
- 视觉大模型(CV):是指在计算机视觉(Computer Vision,CV)领域中使用的大模型,通常用于图像处理和分析。这类模型通过在大规模图像数据上进行训练,可以实现各种视觉任务,如图像分类、目标检测、图像分割、姿态估计、人脸识别等。例如:VIT 系列(Google)、文心UFO、华为盘古 CV、INTERN(商汤)。
- 多模态大模型: 是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了 NLP 和 CV 的能力,以实现对多模态信息的综合理解和分析,从而能够更全面地理解和处理复杂的数据。例如:DingoDB 多模向量数据库(九章云极 DataCanvas)、DALL-E(OpenAI)、悟空画画(华为)、midjourney。
按照应用领域的不同,大模型主要可以分为 L0、L1、L2 三个层级:
- 通用大模型 L0:是指可以在多个领域和任务上通用的大模型。它们利用大算力、使用海量的开放数据与具有巨量参数的深度学习算法,在大规模无标注数据上进行训练,以寻找特征并发现规律,进而形成可“举一反三”的强大泛化能力,可在不进行微调或少量微调的情况下完成多场景任务,相当于 AI 完成了“通识教育”。
- 行业大模型 L1:是指那些针对特定行业或领域的大模型。它们通常使用行业相关的数据进行预训练或微调,以提高在该领域的性能和准确度,相当于 AI 成为“行业专家”。
- 垂直大模型 L2:是指那些针对特定任务或场景的大模型。它们通常使用任务相关的数据进行预训练或微调,以提高在该任务上的性能和效果。
开发以大语言模型为功能核心、通过大语言模型的强大理解能力和生成能力、结合特殊的数据或业务逻辑来提供独特功能的应用称为大模型开发。
开发大模型相关应用,其技术核心点虽然在大语言模型上,但一般通过调用 API 或开源模型来实现核心的理解与生成,通过 Prompt Enginnering 来实现大语言模型的控制,因此,大模型虽然是深度学习领域的集大成之作,大模型开发却更多是一个工程问题。
在大模型开发中,我们一般不会去大幅度改动模型,而是将大模型作为一个调用工具,通过 Prompt Engineering、数据工程、业务逻辑分解等手段来充分发挥大模型能力,适配应用任务,而不会将精力聚焦在优化模型本身上。
大模型开发与传统的AI 开发在整体思路上有着较大的不同:
-
传统AI 开发:首先需要将复杂的业务逻辑依次拆解,对于每个子业务构造训练数据与验证数据,对于每个子业务训练优化模型,最后形成完整的模型链路来解决整个业务逻辑。

-
大模型开发:用 Prompt Engineering 来替代子模型的训练调优,通过 Prompt 链路组合来实现业务逻辑,用一个通用大模型 + 若干业务 Prompt 来解决任务,从而将传统的模型训练调优转变成了更简单、轻松、低成本的 Prompt 设计调优。

目前大部分企业都是基于 LangChain 、qwen-Agent、lammaIndex框架进行大模型应用开发。LangChain 提供了 Chain、Tool 、RAG等架构的实现,可以基于 LangChain 进行个性化定制,实现从用户输入到数据库再到大模型最后输出的整体架构连接。
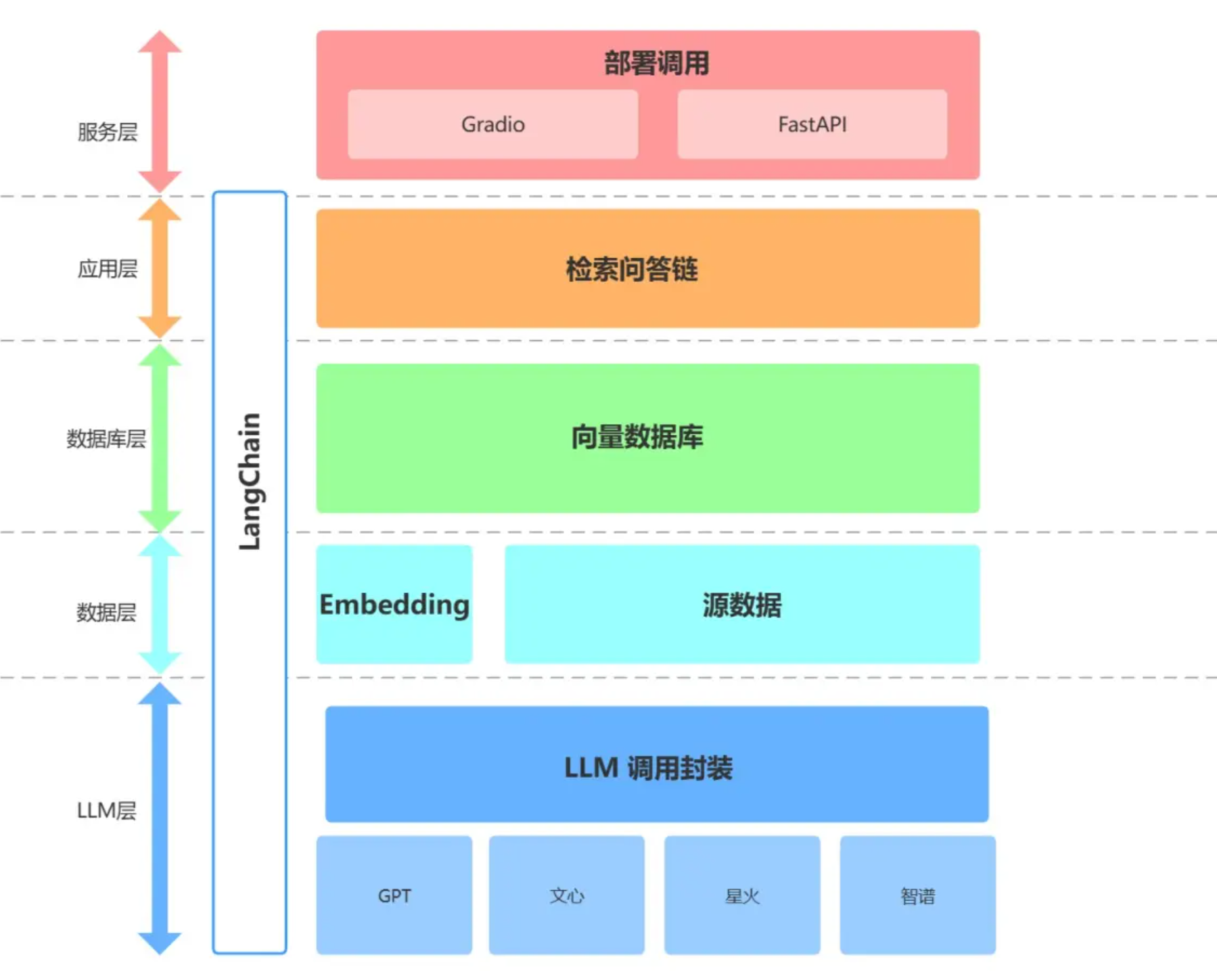
Embedding
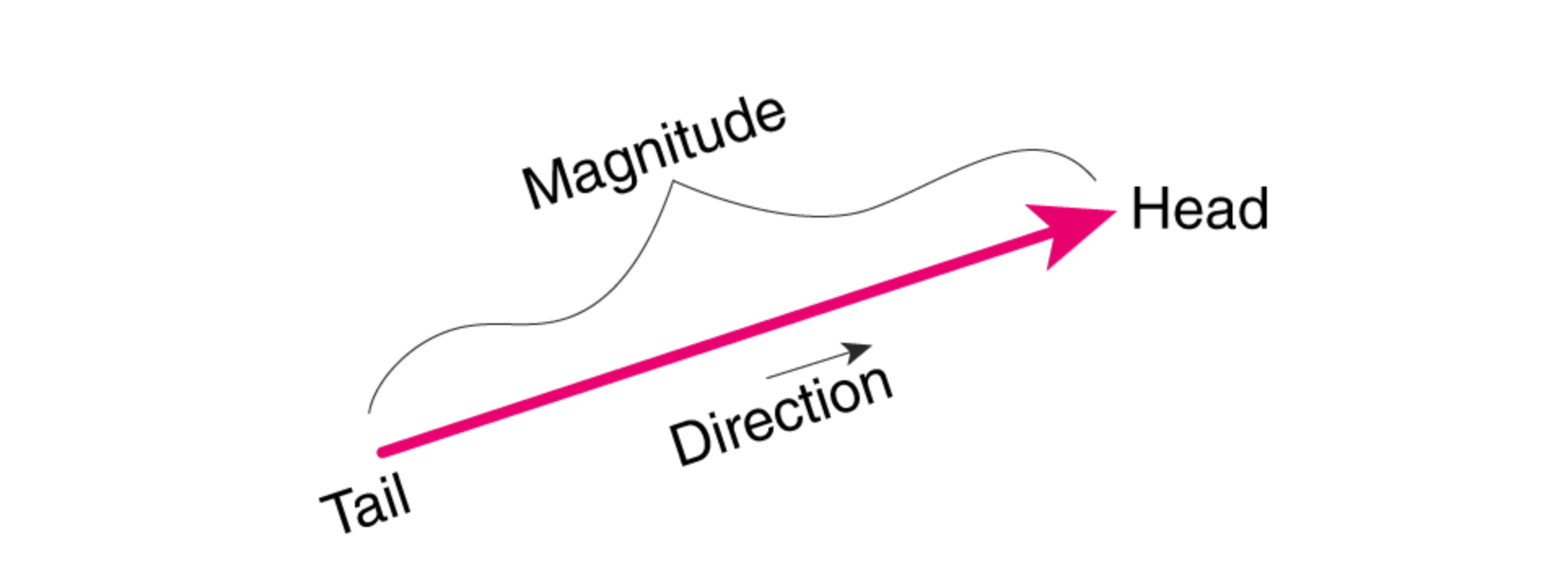
向量是多维数学空间中的一个坐标点,指具有大小和方向的量,它在直角坐标系里通常表现为一段带箭头的线段。
由于向量可以高度抽象地表示事物的特征和属性,世界上几乎所有类型的数据——视频、图像、声音、文本……统统都可以通过数据处理转换成向量数据。因而,在AI领域流传着一句话,万物皆可Embedding。
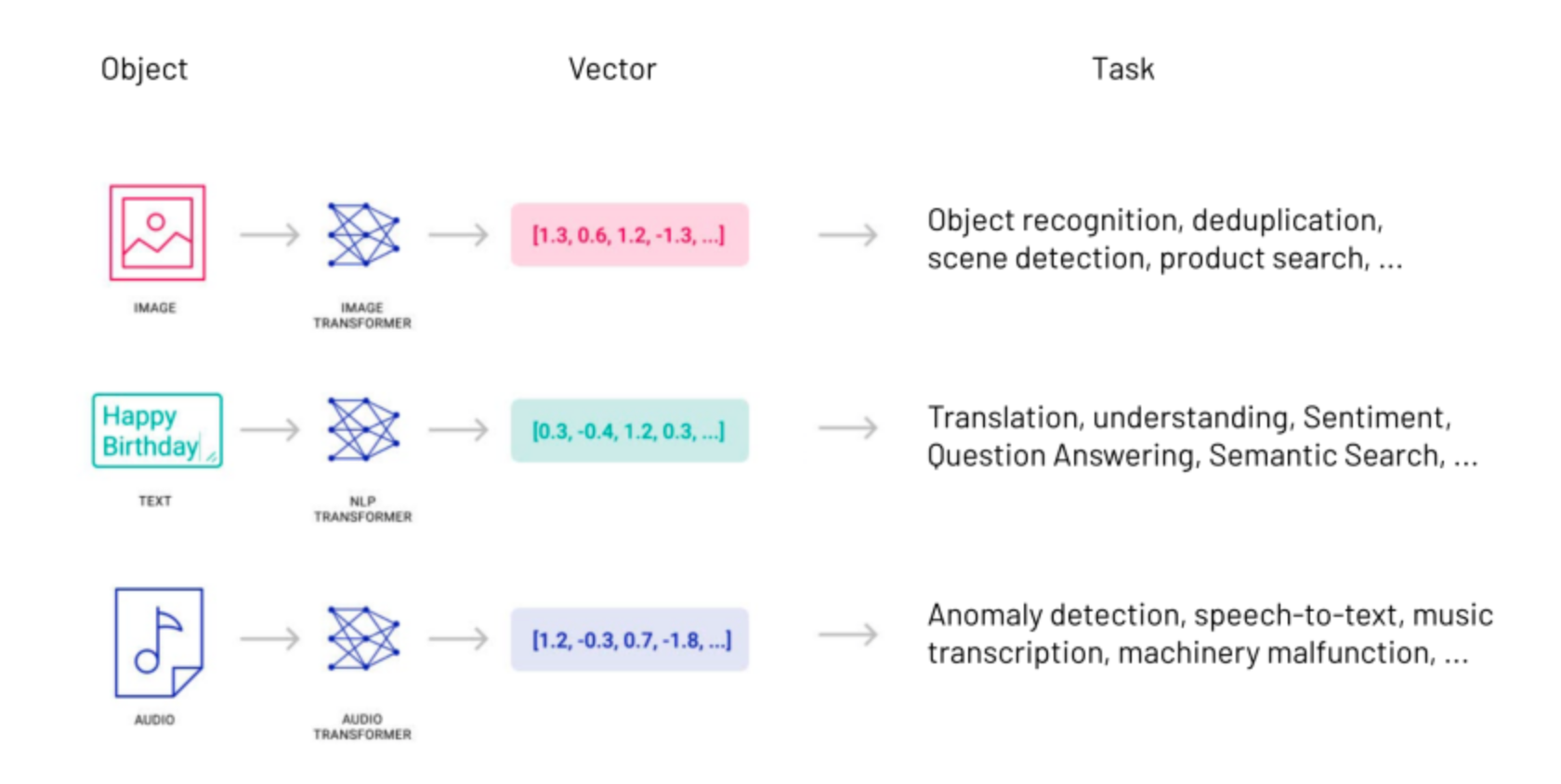
所谓的向量数据,通常指的是将实体(如文本、图像、音频等)转换为数值形式的高维向量。这些向量能够捕捉实体的关键特征,并在向量空间中进行各种计算和比较。向量数据在AI中的应用非常广泛,包括但不限于自然语言处理(NLP)、计算机视觉、语音识别、推荐系统等。通过向量化,AI系统能够更好地理解和处理复杂的数据类型,从而提供更加智能和个性化的服务。
将其他类型的信息转换为向量数据的过程就是向量化。
在传统AI领域中(机器学习和自然语言处理(NLP),Embeddings(嵌入,向量化)是一种将类别数据,如单词、句子或者整个文档,转化为实数向量的技术,这些实数向量可以被计算机更好地理解和处理。嵌入背后的主要想法是,相似或相关的对象在嵌入空间中的距离应该很近。
我喜欢吃苹果。 -> [1, 0, 0, 5, 2, 1]
我喜欢苹果手机。-> [1, 2, 5, 0, 3, 2.8]
我喜欢吃香蕉。 -> [1, 0, 0, 5, 2, 3]
举个例子,可以使用词嵌入(word embeddings)来表示文本数据,在词嵌入中,每个单词被转换为一个向量,这个向量捕获了这个单词的语义信息。例如,“king” 和 “queen” 这两个单词在嵌入空间中的位置将会非常接近,因为它们的词性与含义相似;而 “apple” 和 “orange” 也会很接近,因为它们都是水果;而 “king” 和 “apple” 这两个单词在嵌入空间中的距离就会比较远,因为它们的含义不同。
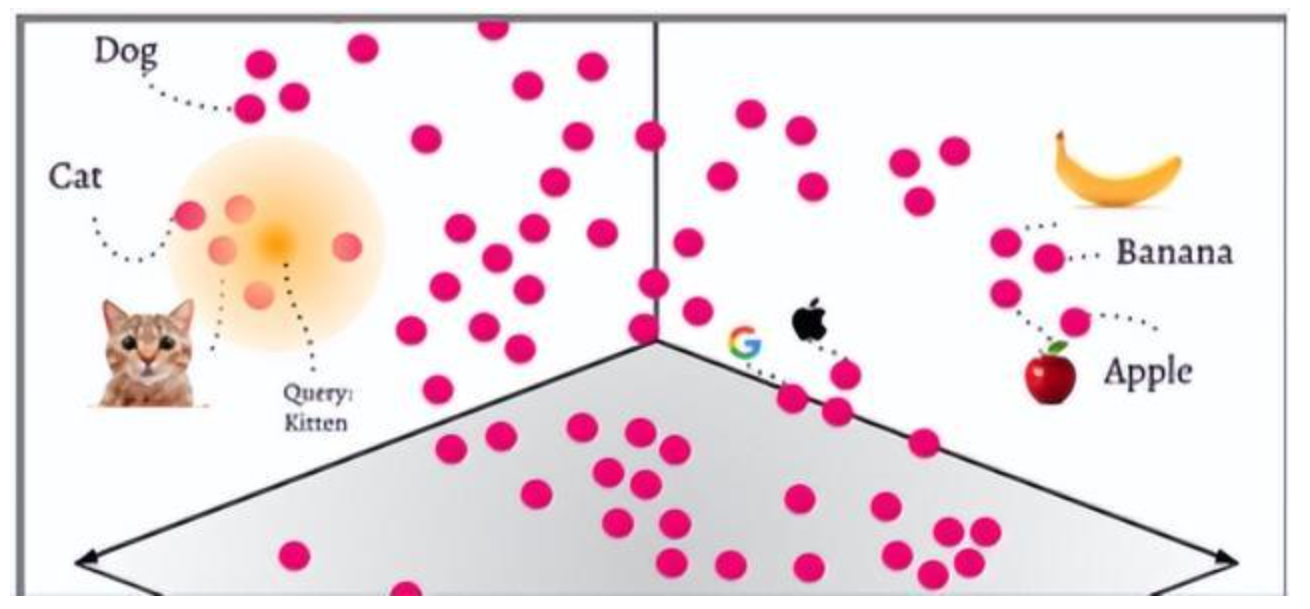
向量数据库
向量数据库(Vector Database)也叫矢量数据库,是专为存储、处理、分析「向量数据」而生的,能够基于目标向量快速进行相似度搜索,并返回最相近的数据。总而言之,就是用来存储和处理向量数据的数据库。
随着大型AI语言模型的崛起,向量数据库成为了解决模型“幻觉”问题的关键。它号称是LLM记忆的海马体,是大模型的记忆和存储核心,通过注入实时&私域数据的形式,可以使得LLM能够在更多通用场景中落地应用,缓解模型”幻觉“的问题。
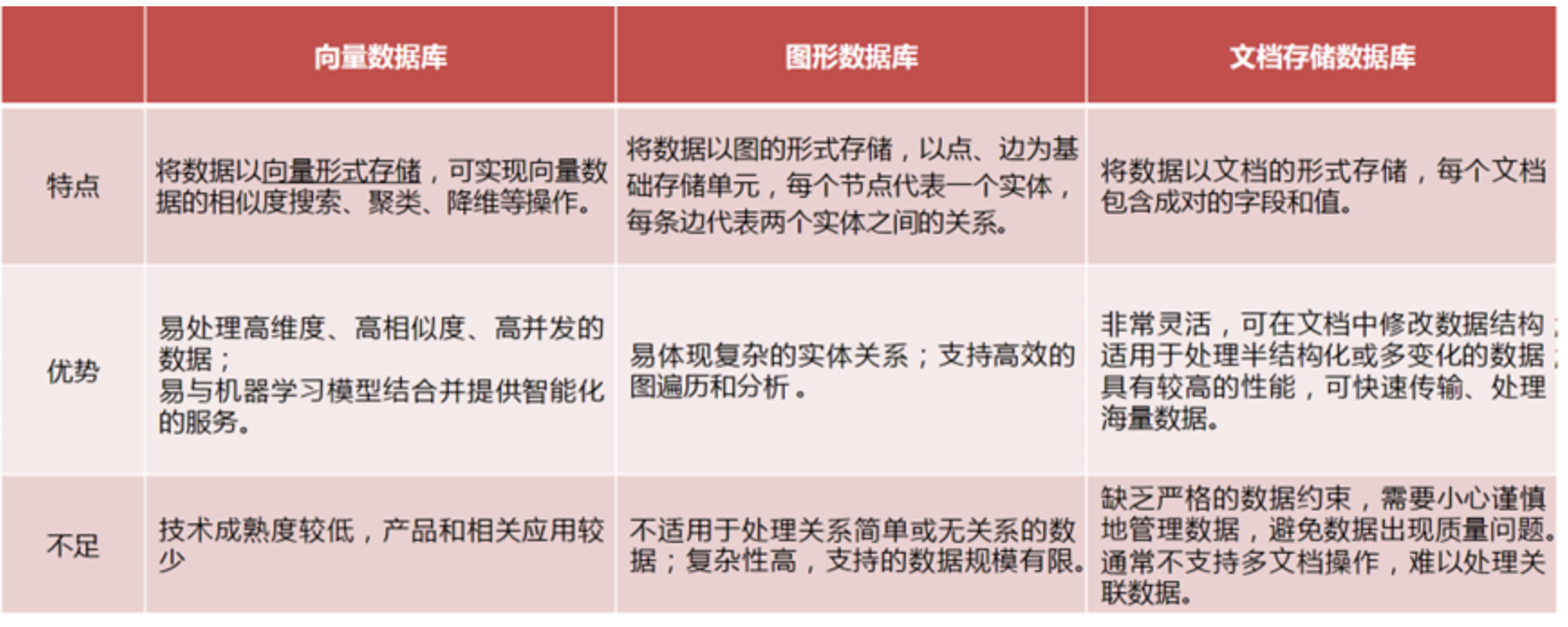
常见的向量数据库:Milvus、Chroma、Weaviate、Faiss、Elasticsearch、PGVector、opensearch、腾讯VectorDB,ClickHouse。
向量数据库的特点:
langchain
基本介绍
LangChain是一个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序。其作者是Harrison Chase(哈里森·蔡斯),最初是于 2022 年 10 月开源的一个项目,在 GitHub 上获得大量关注之后迅速转变为一家人工智能初创公司。
LangChain提供了一套工具、组件和接口,可简化创建由大型语言模型 (LLM) 和聊天模型提供支持的应用程序的过程。LangChain 可以轻松管理与语言模型的交互,将多个组件链接在一起,并集成额外的资源,例如 API 和数据库。
官方文档:https://python.langchain.com/en/latest/
中文文档:https://www.langchain.com.cn/
Github:https://github.com/langchain-ai/langchain
工作流程
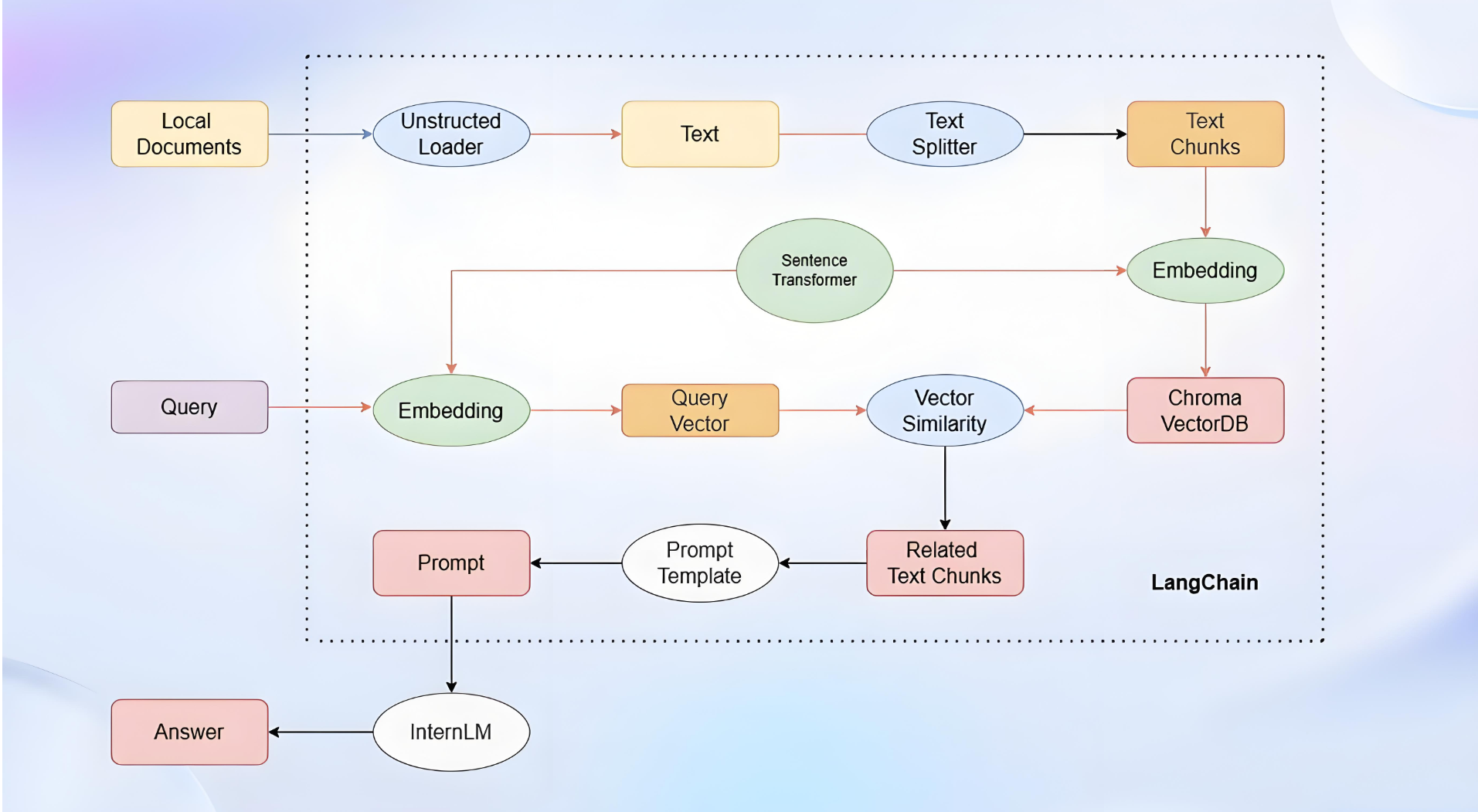
LLM大模型与AI应用的粘合剂
LangChain本身并不开发LLMs,它的核心理念是为各种LLMs提供通用的接口,降低开发者的学习成本,方便开发者快速地开发复杂的LLMs应用。
官方的定义:LangChain是一个基于语言模型开发应用程序的框架。它可以实现以下应用程序:
- 数据感知:将语言模型连接到其他数据源
- 自主性:允许语言模型与其环境进行交互
LangChain的主要价值在于:
- 组件化:为使用语言模型提供抽象层,以及每个抽象层的一组实现。组件是模块化且易于使用的,无论您是否使用LangChain框架的其余部分。
- 现成的链:结构化的组件集合,用于完成特定的高级任务。
应用场景
LangChain为构建基于大型语言模型的应用提供了一个强大的框架,将逐步的运用到各个领域中,如,智能客服、文本生成、知识图谱构建等。随着更多的工具和资源与LangChain进行集成,大语言模型对人的生产力将会有更大的提升。
常用的业务场景:
智能客服:结合聊天模型、自主智能代理和问答功能,开发智能客服系统,帮助用户解决问题,提高客户满意度。
个性化推荐:利用智能代理与文本嵌入模型,分析用户的兴趣和行为,为用户提供个性化的内容推荐。
知识图谱构建:通过结合问答、文本摘要和实体抽取等功能,自动从文档中提取知识,构建知识图谱。
自动文摘和关键信息提取:利用LangChain的文本摘要和抽取功能,从大量文本中提取关键信息,生成简洁易懂的摘要。
代码审查助手:通过代码理解和智能代理功能,分析代码质量,为开发者提供自动化代码审查建议。
搜索引擎优化:结合文本嵌入模型和智能代理,分析网页内容与用户查询的相关性,提高搜索引擎排名。
数据分析与可视化:通过与API交互和查询表格数据功能,自动分析数据,生成可视化报告,帮助用户了解数据中的洞察信息。
智能编程助手:结合代码理解和智能代理功能,根据用户输入的需求自动生成代码片段,提高开发者的工作效率。
在线教育平台:利用问答和聊天模型功能,为学生提供实时的学术支持,帮助他们解决学习中遇到的问题。
自动化测试:结合智能代理和代理模拟功能,开发自动化测试场景,提高软件测试的效率和覆盖率。
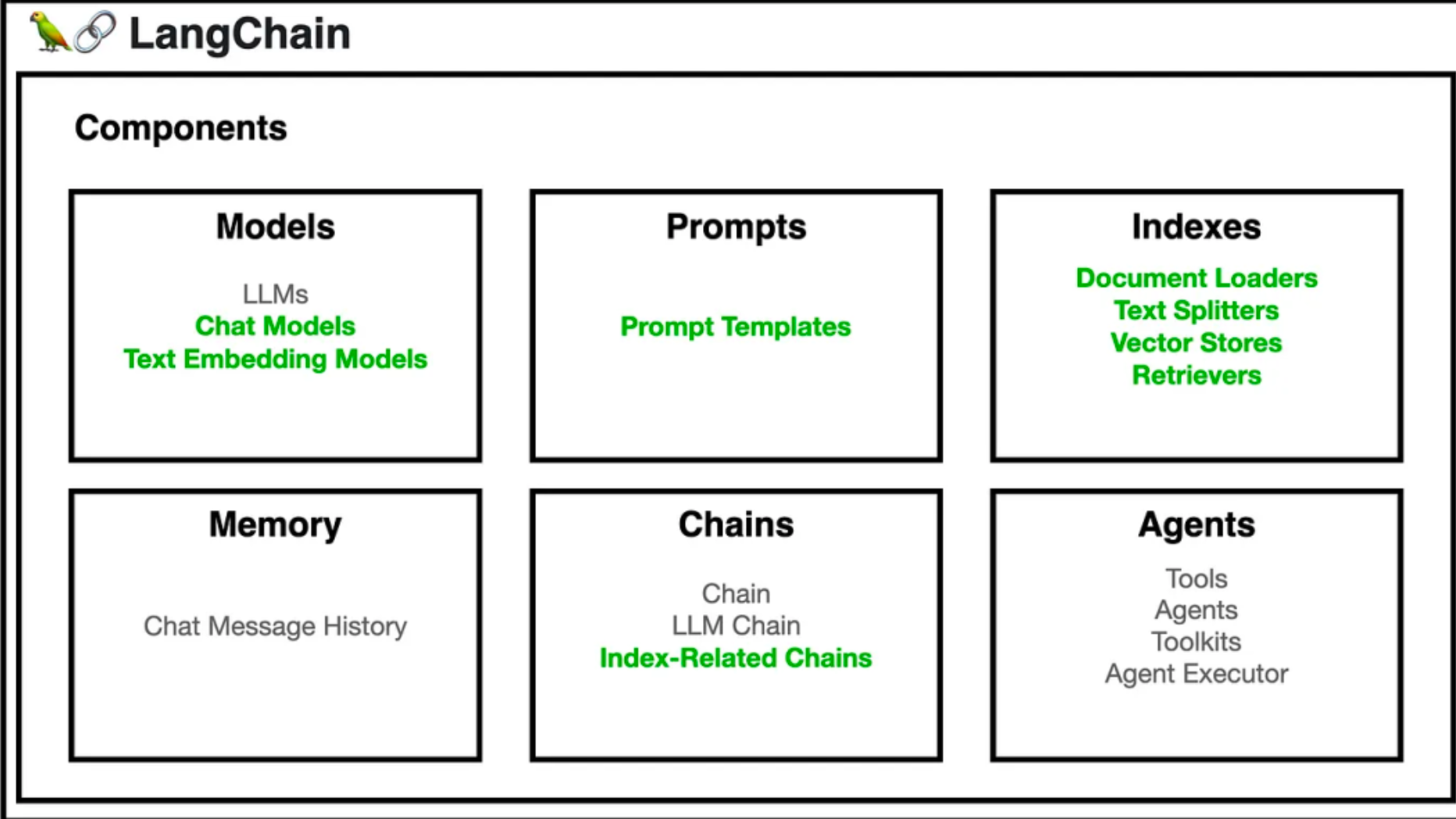
核心组件
要使用 LangChain,开发人员首先要导入必要的组件和工具,例如 LLMs, chat models, agents, chains, 内存功能。这些组件组合起来创建一个可以理解、处理和响应用户输入的应用程序。
- Model I/O:管理语言模型(Models),及其输入(Prompts)和格式化输出(Output Parsers)
- data connection:与特定任务的数据接口,管理主要用于建设私域知识(库)的向量数据存储(Vector Stores)、内容数据获取(Document Loaders)和转化(Transformers),以及向量数据查询(Retrievers)
- memory:在一个链的运行之间保持应用状态,用于存储和获取 对话历史记录 的功能模块
- chains:构建调用序列,用于串联 Memory ↔ Model I/O ↔ Data Connection,以实现 串行化 的连续对话、推测流程
- agents:给定高级指令,让链选择使用哪些工具,基于 Chains 进一步串联工具(Tools),从而将大语言模型的能力和本地、云服务能力结合
- callbacks:记录并流式传输任何链的中间步骤,可连接到 LLM 申请的各个阶段,便于进行日志记录、追踪等数据导流
核心模块
model
说到模型,在LangChain中 model 是一种抽象,表示框架中使用的不同类型的模型。单纯的模型只能生成文本内容。
LangChain的一个核心价值就是它提供了标准的模型接口,然后我们可以自由的切换不同的模型,当前主要有两种类型的模型,但是考虑到使用场景,对我们一般用户来说就是使用一种模型即文本生成模型。
LangChain 中的模型有语言模型、文本嵌入模型等多种分类。
语言模型(Language Models)
语言模型(Language Models),用于文本生成,文字作为输入,输出也是文字。
-
普通LLM(LLMS):接收文本字符串作为输入,并返回文本字符串作为输出。
-
聊天模型(Chat Model):将聊天消息列表作为输入,并返回一个聊天消息。
聊天模型是语言模型的一个变体,聊天模型以语言模型为基础,其内部使用语言模型,不再以文本字符串为输入和输出,而是将聊天信息列表为输入和输出,他们提供更加结构化的 API。通过聊天模型可以传递一个或多个消息。LangChain 目前支持四类消息类型:分别是 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 。目前支持四类消息类型:分别是 AIMessage、HumanMessage、SystemMessage 和 ChatMessage 。
代码:
from langchain.schema import HumanMessage
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
llm = OpenAI()
chat_model = ChatOpenAI()
print(llm("say hi!"))
print(chat_model.predict("say hi!"))
代码效果:
文本嵌入模型(Text Embedding Models)
把文字转换为浮点数形式的描述,表示这些模型接收文本作为输入并返回一组浮点数。这些浮点数通常用于表示文本的语义信息,以便进行文本相似性计算、聚类分析等任务。文本嵌入模型可以帮助开发者在文本之间建立更丰富的联系,提高基于大型语言模型的应用的性能。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
print(doc_result)
代码效果:
prompt
prompt(提示词)是我们与模型交互的方式,或者是模型的输入,通过提示词可以让模型返回我们期望的内容,比如让模型按照一定的格式返回数据给我们。LangChain提供了一些工具,可以方便我们更容易的构建出我们想要的提示词,主要工具如下:
PromptTemplates
语言模型提示词模板PromptTemplates,提示模板可以让我们重复的生成提示,复用我们的提示。它包含一个文本字符串(“模板”),从用户那里获取一组参数并生成提示,包含:
- 对语言模型的说明,应该扮演什么角色
- 一组少量示例,以帮助LLM生成更好的响应,
- 具体的问题
代码:
from langchain import PromptTemplatetemplate = """
I want you to act as a naming consultant for new companies.
What is a good name for a company that makes {product}?
"""prompt = PromptTemplate(input_variables=["product"],template=template,
)
prompt.format(product="colorful socks")
# -> I want you to act as a naming consultant for new companies.
# -> What is a good name for a company that makes colorful socks?
ChatPrompt Templates
聊天模型提示词模板ChatPrompt Templates, ChatModels接受聊天消息列表作为输入。列表一般是不同的提示,并且每个列表消息一般都会有一个角色。
from langchain.prompts import (ChatPromptTemplate,PromptTemplate,SystemMessagePromptTemplate,AIMessagePromptTemplate,HumanMessagePromptTemplate,
)
from langchain.schema import (AIMessage,HumanMessage,SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])# get a chat completion from the formatted messages
print(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
Example Selectors
示例选择器Example Selectors,如果有多个案例的时候,使用ExampleSelectors选择一个案例让提示词使用:
- 自定义的案例选择器
- 基于长度的案例选择器,输入长的时候按理会少一点,输入多的时候,案例会多一些。
- 相关性选择器,选择一个和输入最相关的案例
from langchain.prompts.example_selector.base import BaseExampleSelector
from typing import Dict, List
import numpy as npclass CustomExampleSelector(BaseExampleSelector):def __init__(self, examples: List[Dict[str, str]]):self.examples = examplesdef add_example(self, example: Dict[str, str]) -> None:"""Add new example to store for a key."""self.examples.append(example)def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:"""Select which examples to use based on the inputs."""return np.random.choice(self.examples, size=2, replace=False)examples = [{"foo": "1"},{"foo": "2"},{"foo": "3"}
]# Initialize example selector.
example_selector = CustomExampleSelector(examples)
# Select examples
print(example_selector.select_examples({"foo": "foo"}))
# -> array([{'foo': '2'}, {'foo': '3'}], dtype=object)
# Add new example to the set of examples
example_selector.add_example({"foo": "4"})
print(example_selector.examples)
# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]
# Select examples
print(example_selector.select_examples({"foo": "foo"}))
# -> array([{'foo': '1'}, {'foo': '4'}], dtype=object)代码效果:
Memory
Memory 是在用户与语言模型的交互过程中始终保持状态的概念。体现在用户与语言模型的交互聊天消息过程,这就涉及为从一系列聊天消息中摄取、捕获、转换和提取知识。Memory 在 Chains/Agents 调用之间维持状态,默认情况下,Chains 和 Agents 是无状态的,这意味着它们独立地处理每个传入的查询,但在某些应用程序中,如:聊天机器人,记住以前的交互非常重要,无论是在短期的还是长期的。“Memory”这个概念就是为了实现这一点。
LangChain 提供了两种方式使用记忆存储 Memory 组件,一种是提供了管理和操作以前的聊天消息的辅助工具来从消息序列中提取信息;另一种是在 Chains 中进行关联使用。Memory 可以返回多条信息,如最近的 N 条消息或所有以前消息的摘要等。返回的信息可以是字符串,也可以是消息列表。
from langchain.memory import ChatMessageHistory
from langchain.chat_models import ChatOpenAI
import os
openai_api_key=os.environ["OPENAI_API_KEY"]
chat = ChatOpenAI(temperature=0, openai_api_key=openai_api_key)
# 声明历史
history = ChatMessageHistory()
history.add_user_message("你是一个很好的 AI 机器人,可以帮助用户在一个简短的句子中找出去哪里旅行")
history.add_user_message("我喜欢海滩,我应该去哪里?")
# 添加AI语言
history.add_ai_message("你应该去广东深圳")
# 添加人类语言
history.add_user_message("当我在那里时我还应该做什么?")
print('history信息:', history.messages)
# 调用模型
ai_response = chat(history.messages)
print('结果', ai_response)
# 继续添加 AI 语言
history.add_ai_message(ai_response.content)
print('history信息:', history.messages)
# 继续添加人类语言
history.add_user_message("推荐下美食和购物场所")
ai_response = chat(history.messages)
print('结果', ai_response)
Agent
代理是使用LLM作为思考工具,决定当前要做什么。我们会给代理一系列的工具,代理根据我们的输入判断用哪些工具可以完成这个目标,然后不断的运行工具,来完成目标。
代理可以看做是增强版的Chain,不仅绑定模板、LLM,还可以给代理添加一些工具。
补充:
Agent是一个智能代理,它负责根据用户输入和应用场景,在一系列可用工具中选择合适的工具进行操作。Agent可以根据任务的复杂性,采用不同的策略来决定如何执行操作。
有两种类型的Agent:
- 动作代理(Action Agents):这种代理一次执行一个动作,然后根据结果决定下一步的操作。
- 计划-执行代理(Plan-and-Execute Agents):这种代理首先决定一系列要执行的操作,然后根据上面判断的列表逐个执行这些操作。
对于简单的任务,动作代理更为常见且易于实现。对于更复杂或长期运行的任务,计划-执行代理的初始规划步骤有助于维持长期目标并保持关注。但这会以更多调用和较高延迟为代价。这两种代理并非互斥,可以让动作代理负责执行计划-执行代理的计划。
Agent内部涉及的核心概念如下:
- 代理(Agent):这是应用程序主要逻辑。代理暴露一个接口,接受用户输入和代理已执行的操作列表,并返回AgentAction或AgentFinish。
- 工具(Tools):这是代理可以采取的动作。比如发起HTTP请求,发邮件,执行命令。
- 工具包(Toolkits):这些是为特定用例设计的一组工具。例如,为了让代理以最佳方式与SQL数据库交互,它可能需要一个执行查询的工具和另一个查看表格的工具。可以看做是工具的集合。
- 代理执行器(Agent Executor):这将代理与一系列工具包装在一起。它负责迭代运行代理,直到满足停止条件。
代理的执行流程:
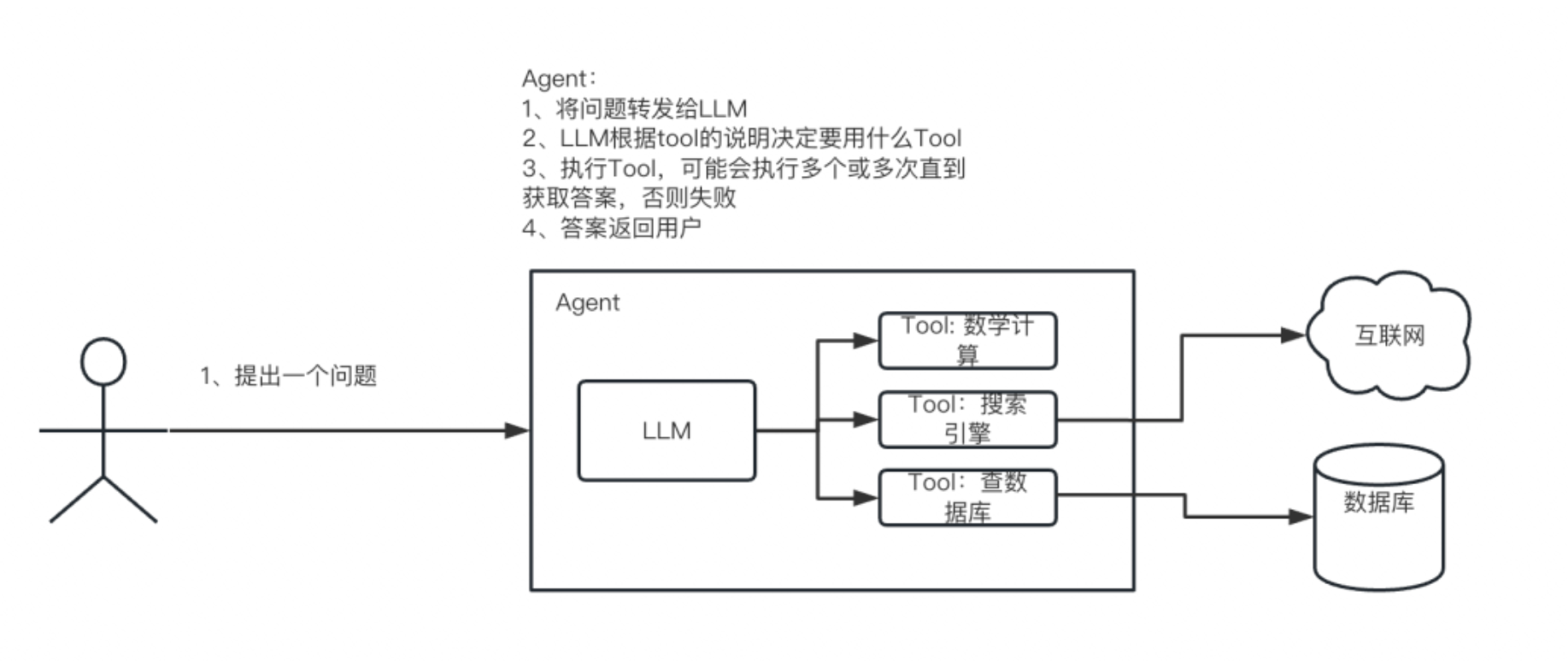
代码:
# 引入所需模块和类
from langchain.agents import load_tools # 引入加载工具函数
from langchain.agents import initialize_agent # 引入初始化代理函数
from langchain.agents import AgentType # 引入代理类型类
from langchain.llms import OpenAI # 引入OpenAI语言模型类
import os # 引入os模块# 创建OpenAI语言模型对象,设定temperature为0,即关闭随机性
llm = OpenAI(temperature=0)# 加载所需工具,包括serpapi和llm-math
tools = load_tools(["serpapi", "llm-math"], llm=llm)# 初始化代理对象,设定代理类型为ZERO_SHOT_REACT_DESCRIPTION,输出详细信息
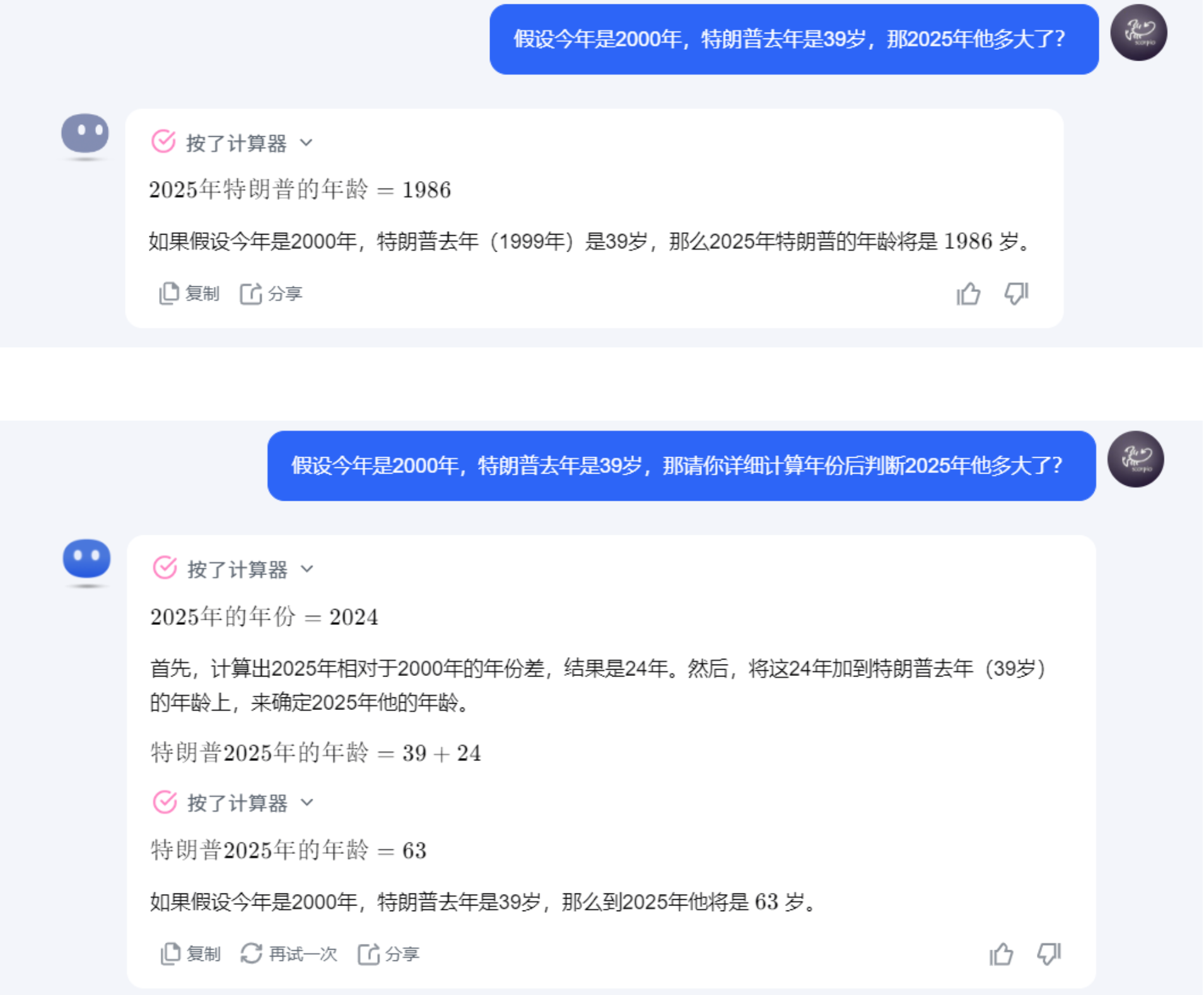
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)# 运行代理对象,向其提问特朗普的年龄和年龄除以2的结果
agent.run("特朗普今年多少岁? 他的年龄除以2是多少?")检索增强(RAG)
基于langchain实现RAG
新建 LLM.py 文件,代码:
from langchain.llms.base import LLM
from typing import Any, List, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig, LlamaTokenizerFast
import torchclass Qwen2_5_LLM(LLM):# 基于本地 Qwen2_5 自定义 LLM 类tokenizer: AutoTokenizer = Nonemodel: AutoModelForCausalLM = Nonedef __init__(self, mode_name_or_path :str):super().__init__()print("正在从本地加载模型...")self.tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, use_fast=False)self.model = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")self.model.generation_config = GenerationConfig.from_pretrained(mode_name_or_path)print("完成本地模型的加载")def _call(self, prompt : str, stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,**kwargs: Any):messages = [{"role": "user", "content": prompt }]input_ids = self.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = self.tokenizer([input_ids], return_tensors="pt").to('cuda')generated_ids = self.model.generate(model_inputs.input_ids, attention_mask=model_inputs['attention_mask'], max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = self.tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return response@propertydef _llm_type(self) -> str:return "Qwen2_5_LLM"
http://shiyanjun.cn/archives/2613.html
实战:AI管家私有化模型部署
创建虚拟环境,并安装基本依赖模块:
conda create -n myvllm python=3.11 -y
conda activate myvllm
pip install langchain==0.0.174
pip install faiss-gpu
再安装vllm,命令如下:
pip install ray
pip install vllm
# 或者 git clone https://github.com/vllm-project/vllm.git; cd vllm
# pip install ./ --no-build-isolation
再安装 flash-attention
# git clone https://github.com/Dao-AILab/flash-attention;cd flash-attention
# pip install ./ --no-build-isolation
pip install flash-attn
from transformers import AutoModelForCausalLM, AutoTokenizer
from abc import ABC
from langchain.llms.base import LLM
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRunmodel_name = "Qwen/Qwen2.5-7B-Instruct"model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype="auto",device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)class Qwen(LLM, ABC):max_token: int = 10000temperature: float = 0.01top_p = 0.9history_len: int = 3def __init__(self):super().__init__()@propertydef _llm_type(self) -> str:return "Qwen"@propertydef _history_len(self) -> int:return self.history_lendef set_history_len(self, history_len: int = 10) -> None:self.history_len = history_lendef _call(self,prompt: str,stop: Optional[List[str]] = None,run_manager: Optional[CallbackManagerForLLMRun] = None,) -> str:messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)generated_ids = model.generate(**model_inputs,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return response@propertydef _identifying_params(self) -> Mapping[str, Any]:"""Get the identifying parameters."""return {"max_token": self.max_token,"temperature": self.temperature,"top_p": self.top_p,"history_len": self.history_len}
import os
import re
import torch
import argparse
from langchain.vectorstores import FAISS
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from typing import List, Tuple
import numpy as np
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.docstore.document import Document
from langchain.prompts.prompt import PromptTemplate
from langchain.chains import RetrievalQAclass ChineseTextSplitter(CharacterTextSplitter):def __init__(self, pdf: bool = False, **kwargs):super().__init__(**kwargs)self.pdf = pdfdef split_text(self, text: str) -> List[str]:if self.pdf:text = re.sub(r"\n{3,}", "\n", text)text = re.sub('\s', ' ', text)text = text.replace("\n\n", "")sent_sep_pattern = re.compile('([﹒﹔﹖﹗.。!?]["’”」』]{0,2}|(?=["‘“「『]{1,2}|$))')sent_list = []for ele in sent_sep_pattern.split(text):if sent_sep_pattern.match(ele) and sent_list:sent_list[-1] += eleelif ele:sent_list.append(ele)return sent_listdef load_file(filepath):loader = TextLoader(filepath, autodetect_encoding=True)textsplitter = ChineseTextSplitter(pdf=False)docs = loader.load_and_split(textsplitter)write_check_file(filepath, docs)return docsdef write_check_file(filepath, docs):folder_path = os.path.join(os.path.dirname(filepath), "tmp_files")if not os.path.exists(folder_path):os.makedirs(folder_path)fp = os.path.join(folder_path, 'load_file.txt')with open(fp, 'a+', encoding='utf-8') as fout:fout.write("filepath=%s,len=%s" % (filepath, len(docs)))fout.write('\n')for i in docs:fout.write(str(i))fout.write('\n')fout.close()def separate_list(ls: List[int]) -> List[List[int]]:lists = []ls1 = [ls[0]]for i in range(1, len(ls)):if ls[i - 1] + 1 == ls[i]:ls1.append(ls[i])else:lists.append(ls1)ls1 = [ls[i]]lists.append(ls1)return listsclass FAISSWrapper(FAISS):chunk_size = 250chunk_conent = Truescore_threshold = 0def similarity_search_with_score_by_vector(self, embedding: List[float], k: int = 4) -> List[Tuple[Document, float]]:scores, indices = self.index.search(np.array([embedding], dtype=np.float32), k)docs = []id_set = set()store_len = len(self.index_to_docstore_id)for j, i in enumerate(indices[0]):if i == -1 or 0 < self.score_threshold < scores[0][j]:# This happens when not enough docs are returned.continue_id = self.index_to_docstore_id[i]doc = self.docstore.search(_id)if not self.chunk_conent:if not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc.metadata["score"] = int(scores[0][j])docs.append(doc)continueid_set.add(i)docs_len = len(doc.page_content)for k in range(1, max(i, store_len - i)):break_flag = Falsefor l in [i + k, i - k]:if 0 <= l < len(self.index_to_docstore_id):_id0 = self.index_to_docstore_id[l]doc0 = self.docstore.search(_id0)if docs_len + len(doc0.page_content) > self.chunk_size:break_flag = Truebreakelif doc0.metadata["source"] == doc.metadata["source"]:docs_len += len(doc0.page_content)id_set.add(l)if break_flag:breakif not self.chunk_conent:return docsif len(id_set) == 0 and self.score_threshold > 0:return []id_list = sorted(list(id_set))id_lists = separate_list(id_list)for id_seq in id_lists:for id in id_seq:if id == id_seq[0]:_id = self.index_to_docstore_id[id]doc = self.docstore.search(_id)else:_id0 = self.index_to_docstore_id[id]doc0 = self.docstore.search(_id0)doc.page_content += " " + doc0.page_contentif not isinstance(doc, Document):raise ValueError(f"Could not find document for id {_id}, got {doc}")doc_score = min([scores[0][id] for id in [indices[0].tolist().index(i) for i in id_seq if i in indices[0]]])doc.metadata["score"] = int(doc_score)docs.append((doc, doc_score))return docsif __name__ == '__main__':# load docs (pdf file or txt file)filepath = 'your file path'# Embedding model nameEMBEDDING_MODEL = 'text2vec'PROMPT_TEMPLATE = """Known information:{context_str}Based on the above known information, respond to the user's question concisely and professionally. If an answer cannot be derived from it, say 'The question cannot be answered with the given information' or 'Not enough relevant information has been provided,' and do not include fabricated details in the answer. Please respond in English. The question is {question}"""# Embedding running deviceEMBEDDING_DEVICE = "cuda"# return top-k text chunk from vector storeVECTOR_SEARCH_TOP_K = 3CHAIN_TYPE = 'stuff'embedding_model_dict = {"text2vec": "your text2vec model path",}llm = Qwen()embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL],model_kwargs={'device': EMBEDDING_DEVICE})docs = load_file(filepath)docsearch = FAISSWrapper.from_documents(docs, embeddings)prompt = PromptTemplate(template=PROMPT_TEMPLATE, input_variables=["context_str", "question"])chain_type_kwargs = {"prompt": prompt, "document_variable_name": "context_str"}qa = RetrievalQA.from_chain_type(llm=llm,chain_type=CHAIN_TYPE,retriever=docsearch.as_retriever(search_kwargs={"k": VECTOR_SEARCH_TOP_K}),chain_type_kwargs=chain_type_kwargs)query = "Give me a short introduction to large language model."print(qa.run(query))
include fabricated details in the answer. Please respond in English. The question is {question}“”"
# Embedding running device
EMBEDDING_DEVICE = “cuda”
# return top-k text chunk from vector store
VECTOR_SEARCH_TOP_K = 3
CHAIN_TYPE = ‘stuff’
embedding_model_dict = {
“text2vec”: “your text2vec model path”,
}
llm = Qwen()
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL],model_kwargs={‘device’: EMBEDDING_DEVICE})
docs = load_file(filepath)docsearch = FAISSWrapper.from_documents(docs, embeddings)prompt = PromptTemplate(template=PROMPT_TEMPLATE, input_variables=["context_str", "question"]
)chain_type_kwargs = {"prompt": prompt, "document_variable_name": "context_str"}
qa = RetrievalQA.from_chain_type(llm=llm,chain_type=CHAIN_TYPE,retriever=docsearch.as_retriever(search_kwargs={"k": VECTOR_SEARCH_TOP_K}),chain_type_kwargs=chain_type_kwargs)query = "Give me a short introduction to large language model."
print(qa.run(query))