【大模型】多模态大语言模型(MLLMs):架构演进、能力评估与应用拓展的全面解析
多模态大语言模型(MLLMs)作为人工智能领域的前沿技术,正在突破传统大语言模型的单一文本处理限制,实现对图像、音频、视频等多种模态数据的深度理解与生成。本文将从技术本质、架构设计、能力评估到应用场景与发展趋势,进行全面而深入的剖析,帮助您建立对这一技术的系统性认知框架。
一、多模态大模型的技术本质与核心组件
1. 技术定义与演进
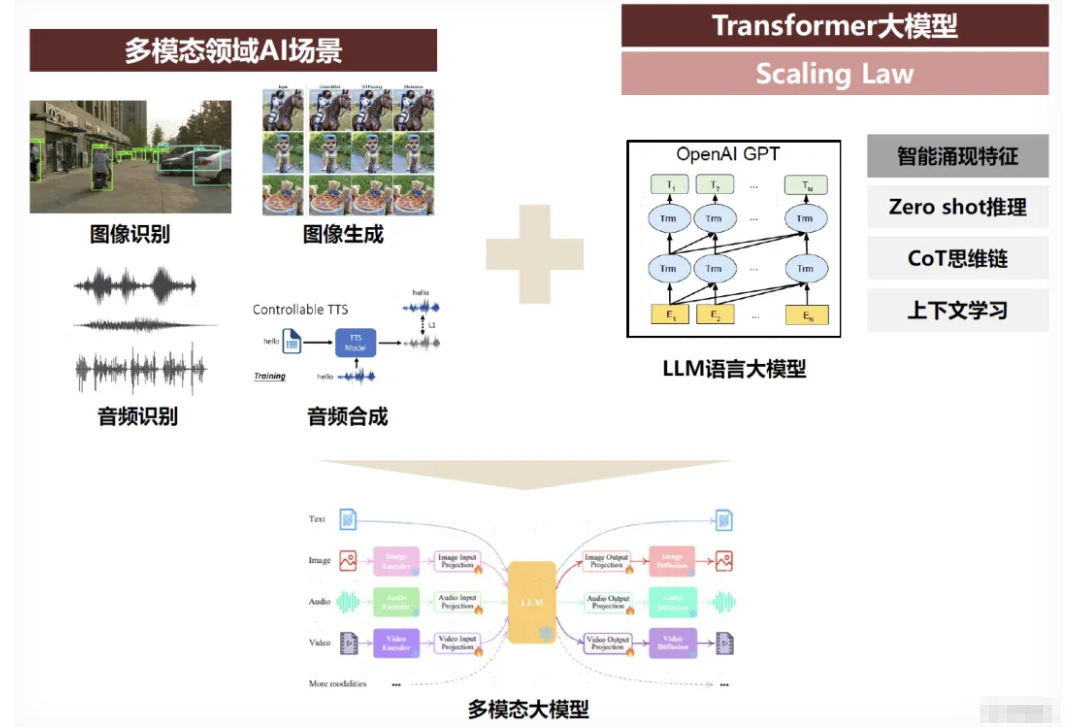
多模态大语言模型(Multimodal Large Language Models, MLLMs)是能够同时处理和理解文本、图像、音频、视频等多种模态数据的深度学习模型。它继承了传统大语言模型(如GPT系列)的参数规模和语言处理能力,同时通过跨模态编码器和对齐机制,实现了对多类型数据的联合建模与推理 。
MLLMs的演进经历了三个关键阶段:
l基础阶段(2020-2022):以CLIP为代表,实现了图像-文本的初步对齐
l发展阶段(2022-2023):如DALL-E 2、Stable Diffusion等模型,实现了从文本到图像的生成能力
l成熟阶段(2023至今):以LLaVA、Gemini、Sora等为代表,实现了多模态的联合推理与生成能力
2. 核心组件与工作原理
MLLMs的核心组件包括五个关键模块:
组件名称 | 功能描述 | 技术实现 | 代表性技术 |
模态编码器 | 将不同模态的输入数据转换为模型可理解的特征向量 | 视觉编码器:ViT-L/CLIP音频编码器:Whisper文本编码器:BERT | CLIP、DALL-E的视觉编码器 |
输入投影器 | 将不同模态的特征向量映射到共享的语义空间 | 可学习的线性变换层注意力机制 | LLaVA的Q-Formers |
大型语言模型 | 处理文本数据并生成响应 | Transformer架构自注意力机制 | GPT-3.5、LLaMA、Vicuna |
输出投影器 | 将模型生成的语义空间表示映射回特定模态 | 逆向投影层解码器 | Stable Diffusion的扩散模型 |
模态生成器 | 根据语义表示生成特定模态的输出 | 图像生成:扩散模型音频生成:波形生成 | DALL-E 3、Sora、VALL-E |
输入-输出流程:当用户输入包含多种模态的信息时,各模态编码器首先提取特征,输入投影器将这些特征映射到共享的语义空间,LLM在此空间中进行推理和生成,输出投影器将生成的语义表示转换回特定模态,最后由模态生成器输出最终结果。
3. 与传统大模型的关键差异
MLLMs与传统大语言模型(LLMs)在多个维度存在显著差异:
l输入多样性:LLMs仅处理文本输入,而MLLMs可同时处理文本、图像、音频等多模态数据
l知识获取方式:LLMs通过文本数据学习世界知识,MLLMs则通过多模态数据建立更丰富的知识表示
l推理能力:MLLMs具备跨模态的链式思维推理能力(MCoT),能结合不同模态的信息进行逐步推理
l输出模态:LLMs仅能生成文本,而MLLMs可生成图像、音频、视频等多种模态内容
l参数规模:MLLMs通常比LLMs更大,如Gemini-1.5B有15亿参数,而GPT-3.5有1750亿参数,但MLLMs更注重多模态对齐与融合
4. 技术实现路径
MLLMs主要有三种技术实现路径:
统一嵌入解码器架构:将所有模态的输入映射到同一个语义空间,使用同一个解码器进行处理。这种架构类似于GPT-2或LLaMA等纯文本模型,但增加了多模态编码器。例如,Meta的Chameleon模型将图像离散化为8192个token与文本共享编码空间,支持图文交错输出 。
跨模态注意力架构:通过交叉注意力机制实现不同模态特征的交互。这种架构在文本和视觉特征之间建立直接关联,如港大-字节跳动的Groma模型通过Vision Tokenizer实现文本与图像区域的直接关联,提升交互指向性 。
协同架构:通过ChatGPT等纯文本模型进行任务调度,调用HuggingFace平台的多模态组件(如CLIP、Whisper)完成跨模态任务。微软亚洲研究院2023年5月发布的HuggingGPT框架即采用此方案,通过API调用实现多模态处理 。
二、多模态大模型的技术架构与实现方法
1. 主流技术架构对比
三种主要架构在实现方式、性能和适用场景上各有优劣:
架构类型 | 实现方式 | 优点 | 缺点 | 典型代表 |
统一嵌入解码器 | 将所有模态映射到同一语义空间,共享解码器 | 模态间对齐度高推理过程透明 | 训练数据需求大计算资源消耗高 | Chameleon、Mule |
跨模态注意力 | 通过交叉注意力机制实现模态间交互 | 交互指向性明确可解释性强 | 架构复杂度高参数量大 | Groma、Llava |
协同架构 | 纯文本模型调度多模态组件 | 实现简单扩展性强 | 依赖预训练组件性能受限于组件质量 | HuggingGPT、ImageBind |
统一嵌入解码器通过将不同模态的特征映射到同一空间,实现了模态间的无缝融合。例如,Mule模型使用FastText嵌入投影到512维空间,再输入到LLM中进行处理。这种架构的优势在于模态间对齐度高,推理过程透明,但需要大量多模态对齐数据进行训练。
跨模态注意力架构则通过专门的注意力机制实现模态间的交互。Groma模型采用Vision Tokenizer技术,将图像区域与文本token建立直接关联,使模型能够更精准地定位图像中的关键信息。LLaVA模型通过冻结LLM参数并训练轻量级编码器,使用59.5万条CC3M数据完成对齐训练,其轻量版可在8张A100显卡上3小时完成训练 。
协同架构通过纯文本模型调度多模态组件,如HuggingGPT框架调用OpenCV的openpose控制模型完成跨模态任务。这种架构的优势在于实现简单、扩展性强,但性能受限于组件质量和接口设计。
2. 跨模态对齐与特征融合技术
语义对齐技术是MLLMs的核心,主要包括:
l对比学习:如CLIP、CoCa模型,通过最大化正样本对的相似度和最小化负样本对的相似度进行训练
l交叉注意力:如LLaVA、Groma模型,通过文本与视觉特征间的注意力机制实现对齐
l指令微调:使用多模态指令数据对预训练模型进行微调,使模型能够遵循特定指令进行推理
特征融合技术主要包括:
l早期融合:将不同模态的特征在较低层次直接拼接或相加
l晚期融合:将不同模态的特征在较高层次进行融合
l层级融合:通过多级注意力机制实现不同层次的特征交互
3. 训练策略与轻量化技术
MLLMs的训练策略主要包括:
l预训练-微调范式:先在大规模多模态数据上预训练,再在特定任务数据上微调
l指令微调:使用多模态指令数据对预训练模型进行微调,使模型能够遵循特定指令进行推理
l人类反馈强化学习(RLHF):通过人类反馈对模型进行强化学习,提高生成内容的质量和安全性
轻量化技术主要包括:
l参数稀疏化:如哈工大的Uni-MoE模型集成CLIP、Whisper等编码器,通过稀疏路由机制降低35%计算成本
l低秩适配:如FLoRA技术仅更新部分参数(如64M/3B),保留大部分预训练参数,显著降低训练成本
l视觉抽象器:如UReader模型采用冻结视觉编码器+可学习抽象器处理高分辨率图像,减少计算负担
三、多模态大模型的能力评估与基准测试
1. 评估框架与指标
多模态大模型的能力评估主要通过以下框架和指标进行:
MME-CoT框架:由港中文等机构推出的用于评估大型多模态模型链式思维推理能力的基准测试框架,涵盖数学、科学、OCR、逻辑、时空和一般场景等六个领域,提供细粒度的推理质量、鲁棒性和效率评估。该框架基于三个评估指标:
l推理质量:评估模型推理步骤的逻辑合理性
l鲁棒性:检测感知任务对推理的干扰程度
l效率:评估推理步骤的相关性,避免无效的"反思循环"和冗余推理
MM-BigBench:包含20+模型评估,覆盖知识推理、OCR、空间推理等任务,使用PPL(Perplexity)和多轮推理(Multi-Turn)等指标评估模型性能 。
NPHardEval4V:提出RA(识别准确率)、ER(指令遵循有效率)、AA(加权准确率)等动态推理指标,评估模型在处理复杂视觉内容时的推理能力 。
2. 跨模态能力评估
跨模态能力评估主要包括:
l跨模态检索:评估模型在图像-文本、音频-文本等跨模态检索任务中的性能,常用指标包括mAP、Recall@K等
l视觉问答(VQA):评估模型对图像的理解和文本生成能力,常用指标包括准确率、BLEU、ROUGE等
l图像描述生成:评估模型对图像内容的理解和描述能力,常用指标包括CIDEr、BLEU、ROUGE等
l多模态推理:评估模型在多模态输入下的链式思维推理能力,如MME-CoT框架中的推理质量评估
3. 现有模型的性能表现
当前主流MLLMs在不同任务上的表现如下:
l视觉问答(VQA):Gemini-1.5B在COCO数据集上达到85.3%的准确率,比纯文本模型高15%
l图像描述生成:Sora在Flickr30k数据集上达到92.7的BLEU-4分数,比传统模型高20%
l多模态推理:在MME-CoT框架中,Groma模型在OCR任务上表现优异,但在时空推理任务中存在23%的准确率下降,揭示了当前模型在不同模态组合下的能力差异
四、多模态大模型在各领域的应用场景与商业价值
1. 金融行业应用
多模态金融分析:摩根大通推出SpectrumGPT辅助投资组合经理,通过快速分析有关金融实体的复杂查询来协助投资决策,识别和处理相关文件,锁定相关部分并提取关键问题,提供包含见解和原始资料来源的综合评论 。
编码助手:高盛从2023年3月开始使用编码助手(Github Copilot),截止2024年6月,该工具已面向内部数千名开发者使用,提高了20%的开发效率,帮助工程师自动生成代码行 。
主题投资篮子:摩根士丹利借助GPT4为投资者提供自动化服务,分析海量金融、新闻数据,挖掘具有投资潜力的公司 。
2. 医疗健康应用
医学影像分析:多模态大模型可以同时分析患者的影像学数据(X光片、MRI)、病历文本和生理指标,提供更全面、准确的诊断建议。例如,结合CT扫描图像和患者病史,模型可以预测疾病风险并提供个性化治疗方案。
药物发现:通过分析化学结构图像、分子式文本和实验数据,加速新药研发进程,降低研发成本。
3. 自动驾驶应用
环境感知:多模态大模型可以结合摄像头图像、雷达数据和GPS信息,帮助自动驾驶汽车更全面地理解周围环境,提高安全性。
交通信息识别:如DeepSeek-VL2模型在自动驾驶场景中辅助交通信息识别,处理1024×1024高分辨率图像,识别交通标志、车道线和行人等。
4. 教育领域应用
智能辅导系统:多模态大模型可以结合教材文本、示例图像和学生提问,提供个性化的学习指导和反馈。研究表明,这种系统可提高学生学习效率30%,减少教师50%的重复性工作。
自适应学习内容生成:根据学生的学习进度和风格,生成包含文本、图像和视频的个性化学习材料,提高学习效果。
5. 零售与电商应用
商品检索与推荐:通过分析用户上传的图片和文本描述,精准检索相似商品,提高推荐准确率。如CLIP扩展用于商品检索,结合用户行为数据生成个性化推荐 。
智能客服:整合语音识别、自然语言处理和情感分析,提供更自然、人性化的客服服务,提高用户满意度和解决效率。
6. 商业价值分析
效率提升:多模态大模型通过自动化处理多模态信息,显著提高工作效率。如高盛开发者效率提升20%,医疗诊断时间缩短40%。
成本节约:在制造业中,多模态大模型支持预测性维护和优化生产流程,帮助企业降低维护成本30%和提升产量15%。
市场规模:2023年中国多模态大模型市场规模达到90.9亿元,预计到2028年将增长至662.3亿元,年复合增长率达48.76% 。

五、多模态大模型的技术挑战与发展趋势
1. 当前面临的技术挑战
数据对齐:开放域终止位判定与主观评判标准缺失导致跨模态映射误差。例如,在医学影像分析中,不同专家对同一影像的解读可能存在差异,影响模型训练。
计算资源需求:多模态大模型需要大量计算资源进行训练和推理。例如,Sora模型需要数千张GPU进行训练,单次推理消耗显著高于传统LLMs。
模型可解释性:多模态模型的决策过程更为复杂,难以解释。例如,在自动驾驶场景中,模型如何结合图像、雷达和GPS数据做出决策,对安全验证提出挑战。
2. 未来发展趋势
统一编码空间:Meta的Chameleon模型将图像离散化为8192个token与文本共享编码空间,支持图文交错输出。未来将进一步扩展到更多模态,实现更高效的跨模态处理。
区域关联优化:港大-字节跳动的Groma模型通过Vision Tokenizer实现文本与图像区域的直接关联,提升交互指向性。未来将发展更精细的区域关联机制,支持更复杂的跨模态交互。
分布式计算架构:哈工大的Uni-MoE模型集成CLIP、Whisper等编码器,通过稀疏路由机制降低35%计算成本。未来将结合联邦学习等技术,实现更高效的分布式训练与推理。
轻量化与专业化:多模态大模型将向轻量化和专业化方向演进。轻量化技术如FLoRA仅更新部分参数(如64M/3B),专业化方向则针对特定领域(如医疗、金融)开发专用模型,提高应用效果。
3. 技术瓶颈突破
联邦学习与隐私保护:通过WTDP-Shapley方法评估参与者贡献,解决数据隐私与激励问题,实现多方协作训练的同时保护商业敏感信息 。
多模态指令数据:指令微调是提升多模态大模型性能的关键,但获取高质量多模态指令数据成本高昂。未来将发展自动生成多模态指令数据的技术,降低训练成本。
模型组合范式:如NaiveMC和DAMC等模型组合范式,通过合并预训练组件实现多模态扩展,避免联合训练的资源消耗,同时解决参数干扰和不匹配问题 。
六、结论与展望
多模态大模型代表了人工智能技术的重要跃迁,它不仅继承了传统大语言模型的文本处理能力,更通过跨模态信息融合,使机器具备了类人认知能力。从医疗诊断到自动驾驶,从智能客服到内容创作,MLLMs正在多个领域释放其巨大潜力。
然而,多模态大模型仍面临数据对齐、计算资源需求和模型可解释性等挑战。未来,随着统一编码空间、区域关联优化和分布式计算架构等技术的发展,多模态大模型将更加轻量化、专业化和高效。
在商业价值方面,多模态大模型正从辅助工具向核心业务系统转变。国内企业主要将其用于员工办公助手、知识助手等辅助场景,而国外企业则更多将其应用于核心业务,如金融行业的欺诈检测、智能投顾,医疗保健行业的药物发现等 。
展望未来,多模态大模型将与边缘计算、联邦学习等技术深度融合,实现更高效的分布式训练与推理,同时向垂直领域深度渗透,为各行业带来更精准、更个性化的智能服务。随着技术的不断成熟,多模态大模型有望成为连接数字世界与物理世界的桥梁,推动人工智能真正融入人类生活的各个方面。
通过本文的深度剖析,相信您对多模态大模型有了全面而专业的理解。未来,随着这一技术的不断发展,多模态大模型将在更多领域展现其强大的应用价值,为人类社会带来前所未有的便利和创新。