RabbitMQ:仲裁队列 HAProxy
搭建好单机多节点集群
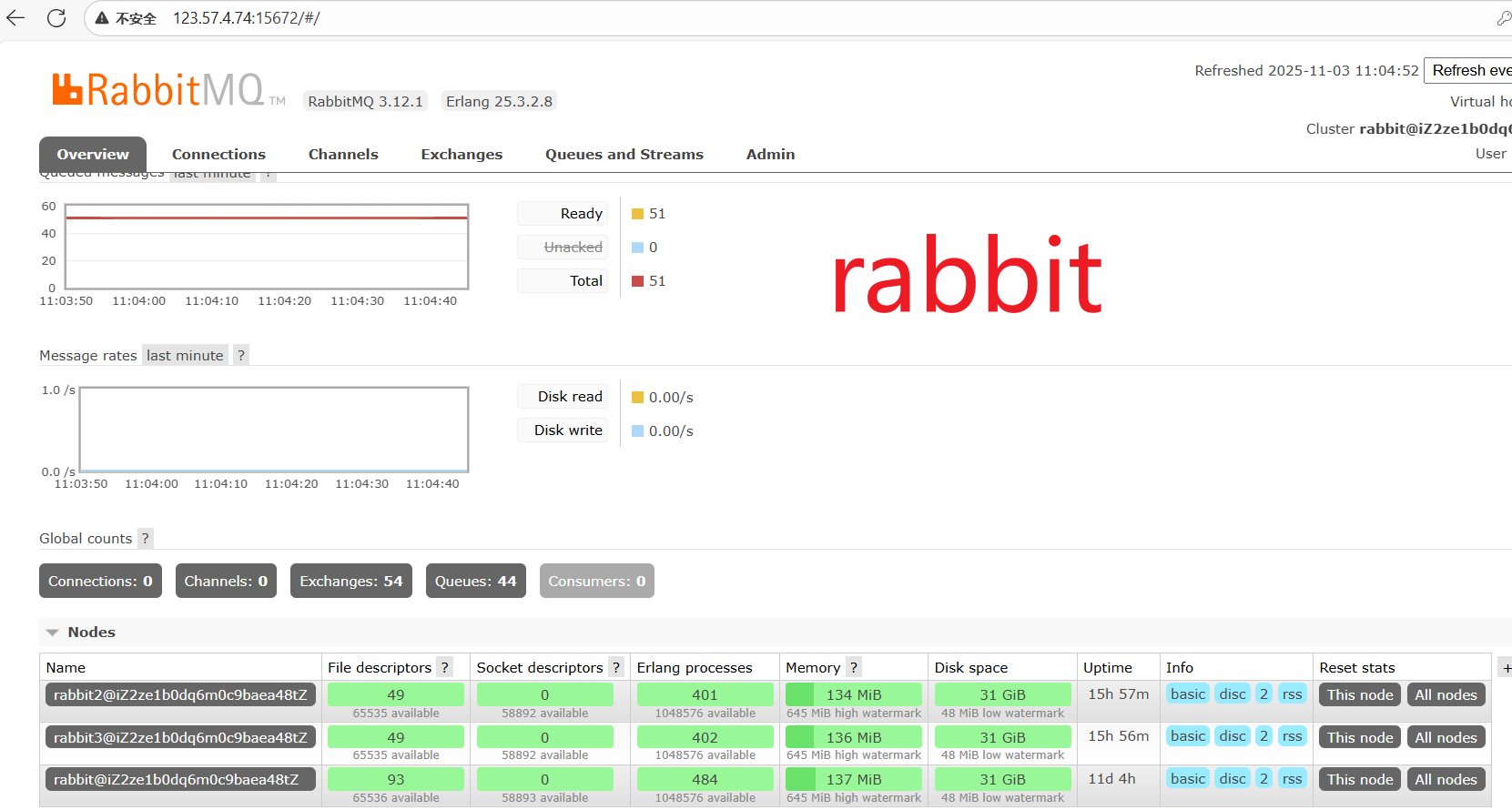
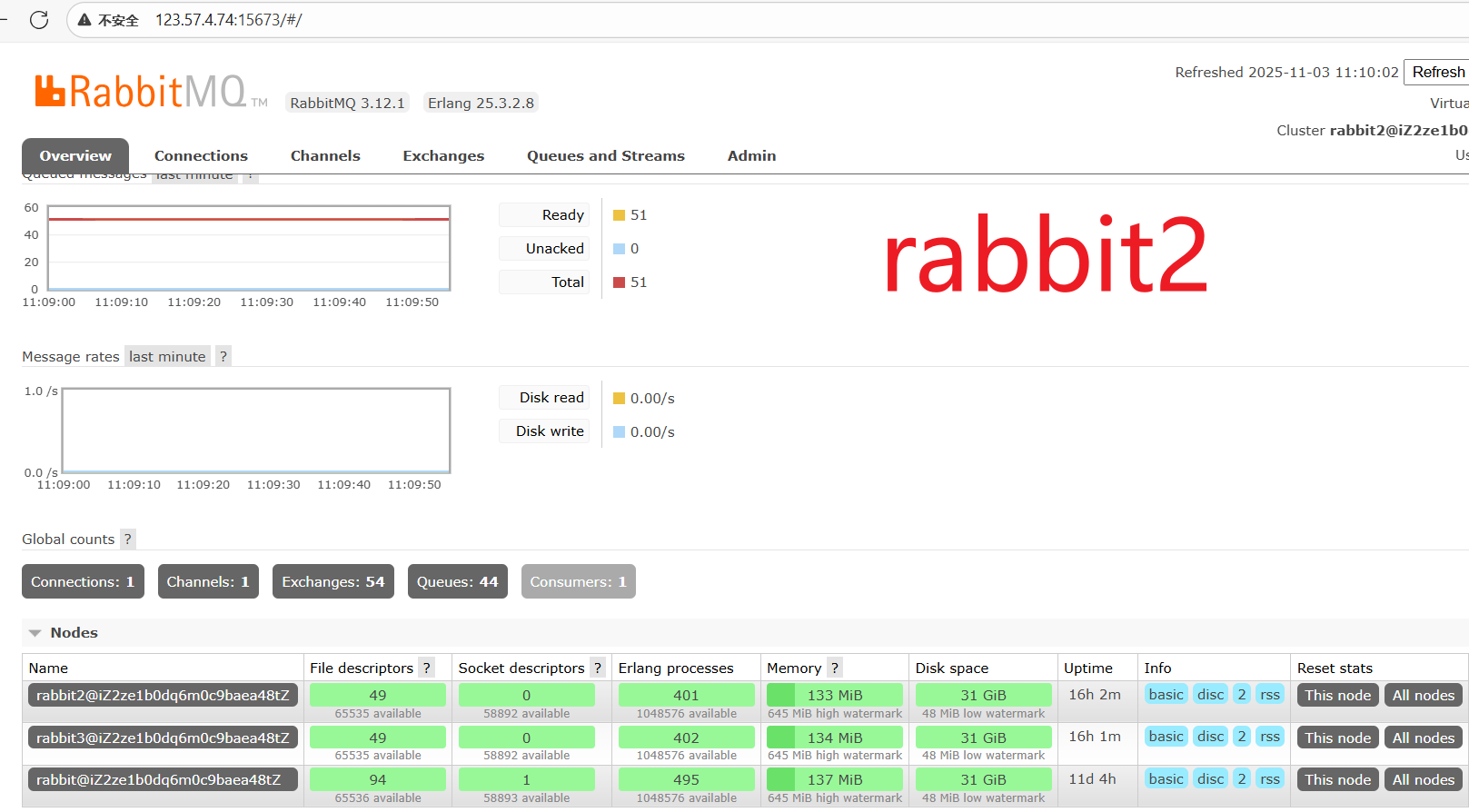
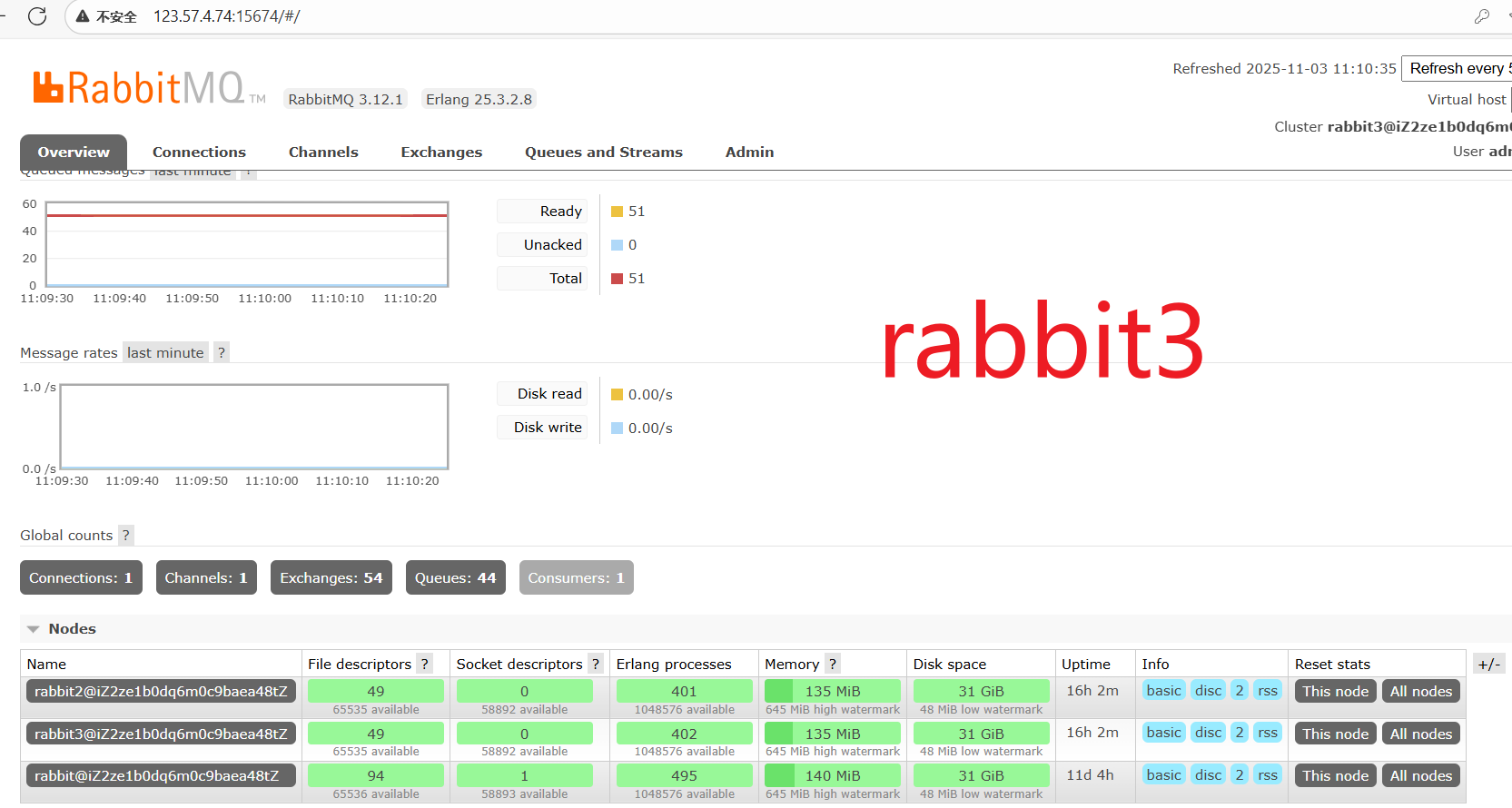
当挂掉一个节点->rabbit

我们发现该节点中的队列状态为down,并且队列中的消息也没了,无法进行接收,也就是说这些数据只在主节点中存在,在从节点中不存在,只要主节点挂了,从节点就无法进行消息的接收

仲裁队列
因此我们引入了仲裁队列
我们首先创建一个仲裁队列来观察一下它的作用最后再来讲解一下它的原理
我们在随机的一个节点中创建一个仲裁队列,类型选择为Quorum,主节点设置为rabbit2
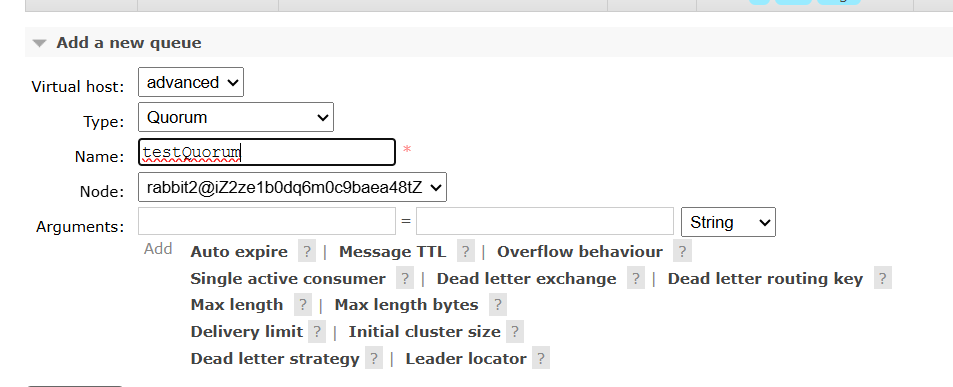
![]()
随机在仲裁队列中发送一条消息
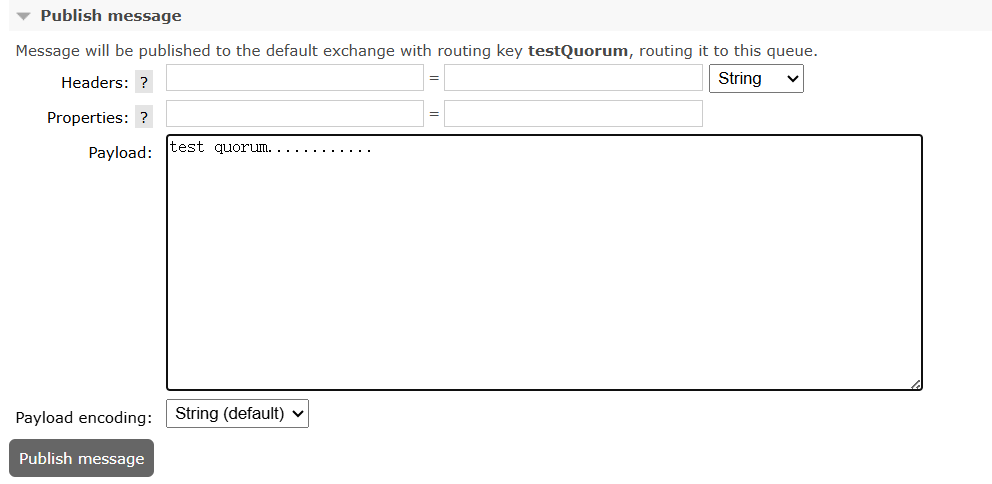
观察,消息发送成功
![]()
当我挂掉当前这个队列的主节点rabbit2,继续观察
![]()
刚刚挂掉的时候
![]()
过了几秒,我们发现现在的主节点变成了rabbit,从节点只有rabbit3,但是队列中的消息依旧存在
![]()
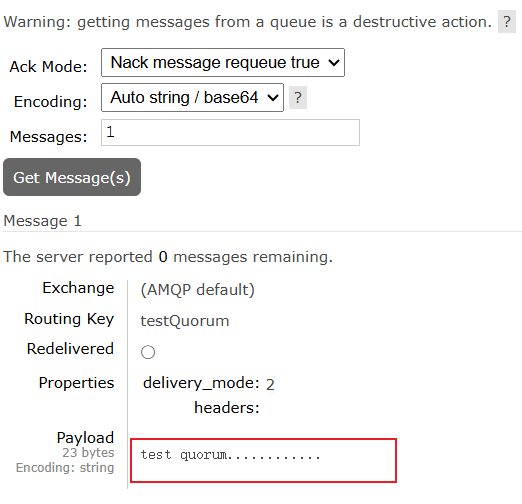
我们重新启动rabbit2这个节点

我们发现现在的主节点依旧是rabbit,不会因为rabbit2的重启而改变,rabbit2变成了从节点

仲裁队列解决了普通队列因为挂掉而丢失消息
仲裁队列的原理
仲裁队列的本质:
仲裁队列是基于Raft算法实现的
仲裁队列的节点选举制度:
当节点开始启动的时候,每个节点都是一个follower,当某个节点一段时间没有收到心跳就会变成候选节点,候选节点发起投票,若同意超过半数,就会成为leader节点,选举完成后,leader节点定期的向follower节点发送心跳维持权威
消息的写入流程:
生产者把 消息发送到leader,leader写入本地日志,然后发送给follower,每个follower返回已同步,当半数节点确认后,leader将消息标记为已提交,
消息消费流程:
leader将已经提交的消息发送给消费者,消费者确定消息,leader将ack状态同步给follower,超过半数节点确认ack后,该消息可以安全的删除
Raft的leader宕机恢复:
如果leader挂了,follower等待一段时间没收到心跳,发送新一轮选举,新的leader产生,如果宕机的前leader恢复,也不会继续恢复leader位置,会变成follower位置
仲裁队列在Spring中的创建
创建仲裁队列,添加仲裁队列的函数
@Configuration
public class QuorumConfig {// 创建仲裁队列@Bean("quorumQueue")public Queue quorumQueue(){return QueueBuilder.durable("quorum.queue").quorum().build();}
}发送消息
@RequestMapping("/producer")
@RestController
public class ProducerController {@Autowiredprivate RabbitTemplate rabbitTemplate;@RequestMapping("/quorum")public String sendMessage(){rabbitTemplate.convertAndSend("","quorum.queue","quorum test........");return "消息发送成功";}
}
接收消息
@Component
public class QuorumListener {@RabbitListener(queues = "quorum.queue")public void receiveMessage(Message message){System.out.println("接收的消息:"+message);}
}

HAProxy负载均衡
当我们挂掉rabbit这个节点的时候,我们发现服务器中RabbitMQ服务器监听的端口无法进行正常的监听,因为配置的监听端口号是5672,所以我们需要使用HAProxy来进行负载均衡

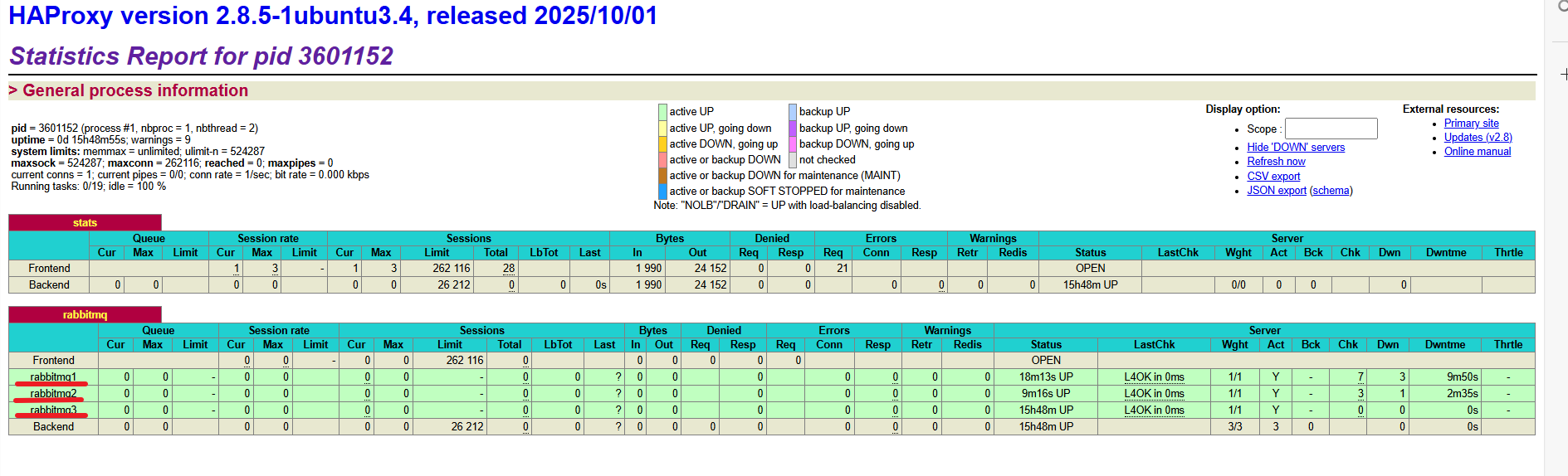
下载配置好的HAProxy,进行查看查看HAProxy
![]()
修改其配置
vim/etc/haproxy/haproxy.cfg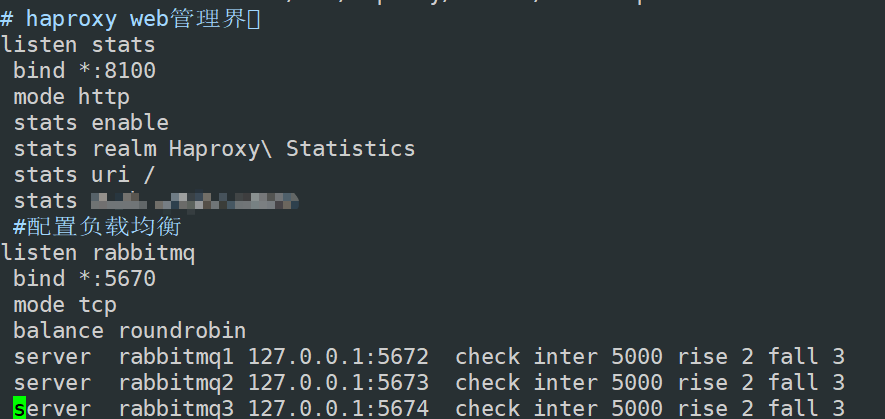
配置好后,进行重启
sudo systemctl restart haproxy修改yml文件中rabbitmq服务器监听的的端口号

运行程序,进行消息的发送,消息接收成功
![]()
如果挂掉原本的5672的机器,服务器也是可以继续的运行的