数据库之多版本控制MVCC
目录
- 什么是MVCC
- MVCC实现方式
- Undo Log 版本链(mysql版本链共用一条)
- ReadView
- MVCC是否可以解决不可重复读与幻读
什么是MVCC
我们知道数据库实现隔离级别时候回用到各种锁,但是频繁加锁与释放锁会对性能产生比较大的影 响,为了提高性能,InnoDB与锁配合,同时采用另⼀种事务隔离性的实现机制即MVCC
MVCC实现方式
Undo Log 版本链(mysql版本链共用一条)
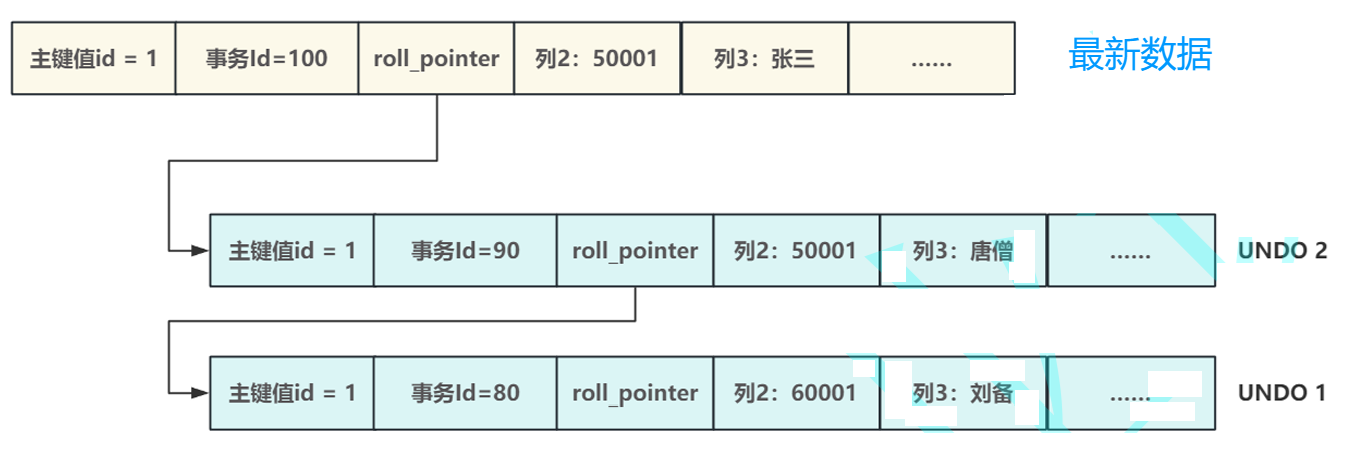
Undo Log 版本链:UndoLog做为回滚的基础,在执行Update或Delete操作时,会将每次操作的上⼀个版本录在UndoLog中,每条UndoLog中都记录⼀个叫做roll_pointer 的引用信息,通过roll_pointer 应的
UndoLog组织成⼀个Undo链,在数据⾏的头部通过数据⾏中的roll_pointer 与UndoLog中
的第⼀条日志进行关联,这样就构成⼀条完整的数据版本链
每⼀条被修改的记录都会有⼀条版本链,体现了这条记录的所有变更,当有事务对这条数据进行修
改时,将修改后的数据链接到版本链接的头部
如图:
**
**
ReadView
每条数据的版本链都构造好之后,在查询时具体选择哪个版本呢?这里就需要使用 构来实现了,所谓ReadView是一个内存结构,顾名思义是⼀个视图,在事务使用select 查询数据时就会构造⼀个ReadView,里面记录了该版本链的一些统计值,如下:
`
| Column 1 | Column 2 |
|---|---|
| m_ids | 当前所有活跃事务的集合(未提交) |
| m_low_limit_id | 活跃事务集合中最小事务Id(小于这个Id就说明事务已经提交) |
| m_up_limit_id | 下⼀个将被分配的事务Id,等于最大事务ID+1 |
| m_creator_trx_id | 创建当前ReadView 的事务Id |
MVCC就是根据ReadView和Undo Log 版本链实现的
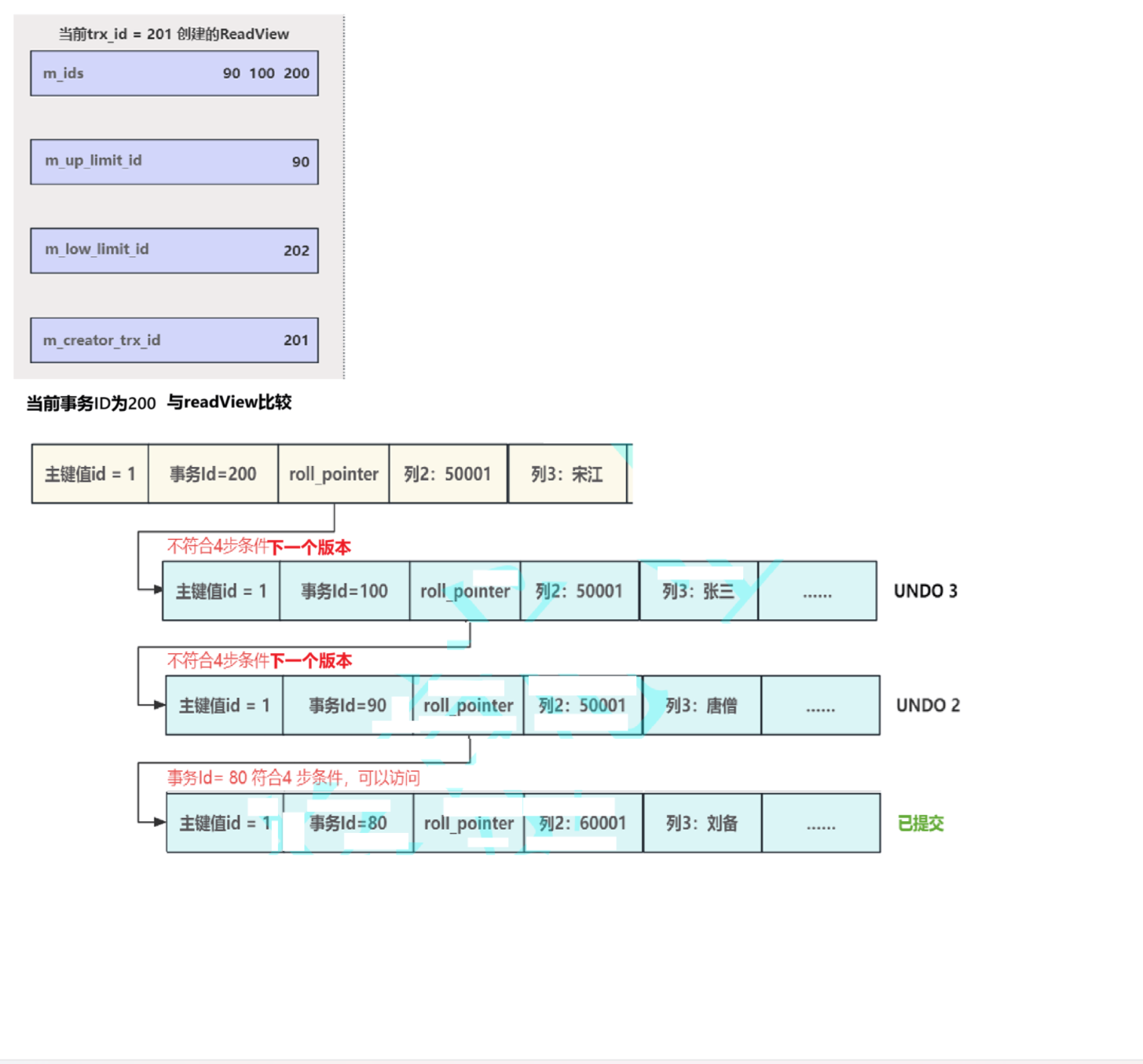
MCVV实现过程:
根据当前版本事务ID,从链头开始遍历所有版本,根据以下四步查找规则,判断每个版本
第一步:判断该版本是否为当前事务创建,若m_creator_trx_id 等于该版本事务id,意味着读取自己修改的数据,可以直接访问,如果不等则到第二步
第二步:若该版本事务Id<m_up_limit_id (最⼩事务Id),意味着该版本在ReadView⽣成之前已经提交,可以直接访问,如果不是则到第三步
第三步: 或该版本事务Id>=m_low_limit_id(最⼤事务Id),意味着该版本在ReadView生
成之后才创建,所以肯定不能被当前事务访问,所以无需第四步判断,直接遍历下一个版本,如果不则到第四步
第四步:若该版本事务Id在m_up_limit_id (最小事务Id)和m_low_limit_id (最大事务Id)之间,同时该版本不在活跃事务列表中,意味着创建ReadView时该版本已经提交,可以直接访问,如果不是则遍历并判断下⼀个版本
举个例子:
**
**
MVCC是否可以解决不可重复读与幻读
首先幻读无法通过MVCC单独解决,对于不可重复读问题,在事务中的第⼀个查询时创建⼀个ReadView,后续查询都是用这个
ReadView进行判断,所以每次的查询结果都是⼀样的,从而解决不可重复读问题,
注意:在REPEATABLE READ 可重复读,隔离级别下就采用的这种方式
如果事务每次查询都创建⼀个新的ReadView,这样就会出现不可重复读问题,
因为创建出多个ReadView,在比较过程中无法保证读到的数据是已经提交的
注意:在COMMITTED 读已提交的隔离级别下就是这种实现方式