聊聊Oracle数据库的向量能力
当下 IT 领域最火的技术,如果 AI 说自己排第二,那就没有什么技术敢说第一了。各种软硬件产品都在尽力向 AI 靠齐,如果不支持 AI 出门都不好意思和人打招呼,数据库当然也不例外。不论国际数据库巨头还是国产数据库厂商,都通过支持向量的方式,让自己的产品离 AI 更近一些。深入去看就会发现每个产品在实现方式和能力支持上还是有所差别的。作为数据库领域的霸主,Oracle 将自己的新一代数据库产品冠以 ai 的代称,宣示产品的 ai 能力以及进入 ai 的决心,今天我们就来聊聊 Oracle 数据库在向量处理方面的能力。
向量类型的定义和存储管理
Oracle 23.4 版本中引入了 Vector 数据类型,因为 Vector 数据类型的数值特性,可以将其用于诸如分类、回归、异常、聚类、特征提取等机器学习算法的输入,以支持更多的功能和使用。
通过以下语句即可创建一张存储向量数据的表,相信大家也看出来了,语法上和传统表没有什么区别。其中,768 定义向量的维度数量,INT8 则定义了维度的格式。当前 Oracle Vector 类型支持 INT8、FLOAT32、FLOAT64 和 BINARY 等四种维度格式。
CREATE TABLE docs (doc_id INT, doc_text CLOB, doc_vector VECTOR(768, INT8));
如果创建表时没有指定 VECTOR 类型参数,则意味着这个列可以用于存储多种维度的数据,以默认的 INT8 格式存储。这种方式虽然能在前期简化向量的使用和管理,但是索引查询不支持多种维度数据混合存储,因此建议在系统前期建设阶段就要定义好这些参数。
物理存储上,Oracle Vector 支持 DENSE 和 SPARSE 两种存储格式,默认的物理存储方式为 DENSE,即所有维度的数据都会被物理存储,而 SPARSE 方式下仅保存非 0 的向量数据。
SQL 语法上,DENSE 和 SPARSE 格式有所区别,不支持使用 DENSE 语法插入 SPARSE 向量表,反之亦然,但是可以通过 TO_VECTOR 函数对向量值进行转换。以下是一个创建和插入 SPARSE 表的语句。
create table my_sparse_tab(v01 vector(5, INT8, SPARSE));
insert inot my_sparse_tab values('[5,[2,4],[10,20]]');
其中,第一个字段表示向量的个数,第二个字段表示非零值的坐标列表,第三个字段是相应坐标列表所对应的值。比如例中,第一个字段值为 5 表示这组向量共有 5 个,第二个参数表示坐标 2 和 4 是非零值,第三个参数则表示 2 和 4 坐标对应的值分别是 10 和 20。
相信大家也看出来了,SPARSE 向量其实是一种压缩算法,对于高维度但非零值比较少的向量,使用 SPARSE 格式会比较节省存储空间。
向量类型的全流程支持能力
从非结构化或半结构化的数据,到向量化之后存储的到数据库中,期间需要经过分块、分词及向量嵌入等一系列的处理流程,而 Oracle 23ai 强大的地方正是在于对向量数据的全流程支持能力。
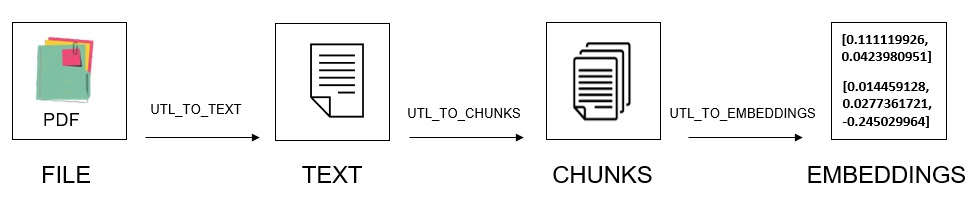
为了帮助大家更好的理解这个过程,这里我们展开来说一说。
- 首先,对于 PDF 或 Word 等分结构化的文本数据,需要将文档转换成纯文本发送给 Chunker,Chunker 将文本拆分为多个大小适中的段,这个过程称之为 Chunking。单个文档可拆分为多个 Chunk,Chunk 可以是一组单词、句子或段落,每个 Chunk 都可以转换成一个向量。
- 接下来将拆分好的 Chunk 传递给预定义好的向量嵌入模型,向量模型中关联的标记器(Tokenizer)进一步将 Chunk 拆分为被称为 Token 的独立单词或单词片段,最后根据数据语义或上下文将每个 Token 嵌入到向量表示中。嵌入模型使用的标记器通常会对可处理的输入文本长度进行限制,如果 Token 的数量大于模型允许的最大输入限制,则某些 Token 会被截断为定义的输入长度,这意味着某些数据会丢失。
- 最后,我们可以将提取的向量存储在向量索引中,以便于在这些向量上实现组合的相似性和关系搜索。Oracle 支持常见的 HNSW(Hierarchical Navigable Small World)和 IVF(Inverted File Flat)向量索引,以及混合索引检索。向量索引和传统索引的区别比较大,我们放在后面的文章中专门介绍。
上述向量化过程在数据库中即可完成,不需要借助于第三方的开发语言或框架,而这些离不开数据库对预定义模型的支持。
开放神经网络交换模型支持
所谓预定义模型指的是已经基于文本、图像等数据上进行训练并保存为存储格式以供将来使用的模型。Oracle 支持在数据库中直接调用嵌入模型来生成向量数据,该功能是通过 ONNX 模型来实现的。
ONNX(Open Neural Network Exchange)是一种用于存储和交换机器学习模型的开放标准,旨在实现不同深度谢谢框架之间的互操作性,由微软和 Facebook 于 2017 年推出,已经发展成为代表深度学习模型的实际标准。Oracle 提供了 ONNX 模型转换及导入工具,将 ONNX 模型导入到数据库中,通过 DBMS 包和函数在库内就完成了分词和向量嵌入的操作,这也是 Oracle 向量数据库强于其他数据库的能力之一。
写在最后
这篇文章给大家简单介绍了 Oracle 数据库在向量数据上的支持能力,通过导入开放预定义模型,以及一系列的 DBMS 包和函数,开发人员能够在数据库内实现向量化流程的闭环,而不需要借助于第三方的工具,这也是和同类产品最大的区别。
这篇文章没有介绍向量检索和索引的内容,向量检索模式和索引实现与传统的基于关键字的检索差别很大,限于篇幅的原因,我们另开一篇单独介绍,欢迎大家持续关注!