【论文精读】迈向更好的指标:从T2VScore看文本到视频生成的新评测范式
标题:Towards A Better Metric for Text-to-Video Generation
作者:Qwen
单位:阿里巴巴云
发表:arXiv:2401.07781
论文链接:https://arxiv.org/pdf/2401.07781
项目链接:https://showlab.github.io/T2VScore
代码链接:https://github.com/showlab/T2VScore(coming soon)
关键词:文本到视频生成,评估指标,T2VScore,TVGE数据集,视频质量评估,文本-视频对齐
“用文字描绘一个场景,AI便为你生成一段视频。” 这曾是科幻小说中的情节,如今却已成现实。以Stable Video Diffusion、Pika、Gen-2等为代表的文本到视频(Text-to-Video, T2V)生成模型正以前所未有的速度发展,创造出令人惊叹的视觉内容。然而,随着生成能力的突飞猛进,一个更为严峻的问题浮出水面:我们该如何客观、可靠地衡量这些AI生成视频的好坏?
传统的自动化指标,如FVD、IS和CLIP Score,虽然被广泛使用,但它们往往与人类的真实感知相去甚远。而依赖人工进行用户研究,虽能反映真实感受,却又耗时耗力,难以大规模应用。这导致了一个困境:研究人员和开发者缺乏一个高效、准确的“标尺”来指导模型的迭代和比较。
今天要精读的这篇论文《Towards A Better Metric for Text-to-Video Generation》正是直面这一挑战的杰出之作。来自Show Lab、腾讯ARC Lab和新加坡国立大学等机构的研究团队,深刻剖析了现有评估方法的局限性,并提出了一个全新的、更贴近人类判断的评估框架——T2VScore。同时,他们还发布了首个专注于T2V评估的开源数据集TVGE。这项工作不仅提供了一个强大的新工具,更建立了一套完整的评估范式,为整个领域的发展指明了方向。
一、现状与挑战——为何需要新的评估指标?
在介绍T2VScore之前,我们必须先了解当前评估体系的短板。
1.1 现有自动化指标的三大痛点
论文系统地批判了当前主流的自动化评估指标:
-
全参考指标(Full-Reference Metrics)的失效: 像FVD(Frechet Video Distance)和Video IS这类指标,其核心思想是将生成视频与一个“真实”的参考视频进行对比。但在开放域的文本到视频生成中,同一个文本描述可以对应无数种合理的视频表现形式(例如,“一只狗在公园里奔跑”可以有无数个不同的狗、公园和奔跑方式)。强行要求生成视频与某个特定参考视频相似,是不切实际且不公平的。因此,这些指标不适合用于评估创造性T2V任务。
-
CLIP Score对时间动态的忽视: CLIP Score通过计算文本与视频中每一帧图像的平均相似度来衡量图文一致性。这是一个巨大的缺陷。视频的灵魂在于时间! 一个静态的、没有连贯运动的视频,即使每一帧都与文本相关,也无法被认为是高质量的。例如,一个描述“烟花在夜空中绽放”的视频,如果只是随机切换几张烟花图片,而没有绽放的动态过程,CLIP Score可能依然很高,但这显然不是一个好视频。
-
视频质量评估(VQA)指标的“水土不服”: 现有的VQA指标大多是为评估自然拍摄的视频(如监控录像、电影片段)的质量退化(如模糊、压缩伪影)而设计的。而AI生成的视频有着截然不同的“失真”模式,比如物体结构崩塌、身份闪烁、动作不连贯等。直接将这些指标用于生成视频,就如同用体温计量血压,结果自然不可靠。

图注:上图直观地展示了自然视频(左)与生成视频(右)在空间和时间上失真模式的巨大差异。自然视频的失真多为模糊或噪点,而生成视频则可能出现物体变形、身份突变等语义级错误。这说明了现有VQA指标存在显著的“领域鸿沟”。
1.2 人类评估的瓶颈
最可靠的评估方式无疑是让真人观看并打分。然而,大规模的人类评估成本高昂、周期漫长,且容易受到主观偏见的影响。这使得它无法成为一种可扩展、可复现的标准评测方法。
结论: 我们迫切需要一种自动化的、非全参考的、能够同时捕捉空间-时间对齐性和视频整体质量的新型评估指标。
二、核心创新——T2VScore框架详解
面对上述挑战,作者提出了T2VScore,一个双管齐下的评估框架。其核心思想如图1所示:从两个独立但同等重要的维度来评判一个T2V生成结果。
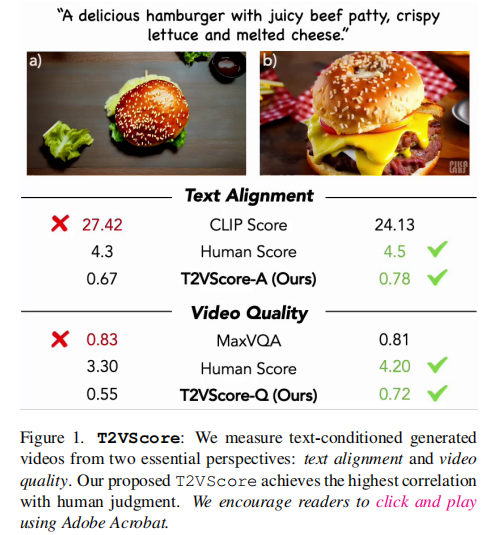
T2VScore由两个子指标构成:
- T2VScore-A (Alignment): 衡量视频内容与文本提示的匹配程度。
- T2VScore-Q (Quality): 衡量视频本身的视觉质量和制作水准。
下面我们分别解析这两个指标的设计。
2.1 T2VScore-A:基于视觉问答(VQA)的细粒度对齐评估
T2VScore-A的目标是回答:“这个视频是否准确地呈现了文本描述的所有细节?” 它摒弃了简单的全局相似度计算,转而采用了一种更精细、更智能的基于问题的答案(Question Answering, QA) 方法。

其流程如图2所示,包含三个关键步骤:
-
实体分解(Entity Decomposition): 首先,系统会解析输入的文本提示
P,将其分解为多个语义单元(entities),并构建它们之间的层次关系。例如,对于提示“一只戴着红色帽子的猫正在玩足球”,系统会识别出核心实体“猫”,以及修饰它的“戴着红色帽子”和动作“玩足球”。这种分解有助于确保评估的全面性。 -
问题/答案生成(Question/Answer Generation with LLMs): 利用像GPT-3.5这样的大语言模型(LLM),基于分解后的语义单元,自动生成一系列多样化的问题(Questions)、选项(Choices)和正确答案(Answers)。这些问题覆盖了文本的各个方面,特别强调了时间动态,例如“猫的帽子是什么颜色?”、“足球是如何移动的?”、“摄像机是平移还是旋转?”。
-
带辅助轨迹的视频问答(Video Question Answering with Auxiliary Trajectory): 这是最具创新性的一步。由于大多数多模态大模型(MLLMs)对视频的理解能力有限,尤其是对细微的运动变化。为此,作者引入了辅助轨迹(auxiliary trajectory) 作为额外的输入。
- 他们使用现成的光流或点跟踪模型(如CoTracker)来提取视频中关键物体和摄像机的运动轨迹。
- 将原始视频
V、提取的轨迹Vtrack和生成的问题Qi一起输入给MLLM。 - MLLM的任务是回答这些问题。
- 最终,T2VScore-A的得分就是所有问题回答正确的比例(即准确率)。公式如下:
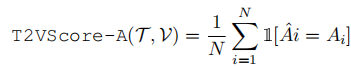 ,其中
,其中是问题总数,
是MLLM的回答,
是正确答案。
这种方法巧妙地将抽象的“对齐度”量化为了具体的“问答正确率”,并且通过引入轨迹信息,极大地增强了对时间一致性的评估能力。
2.2 T2VScore-Q:混合专家的鲁棒质量评估
T2VScore-Q的目标是回答:“这个视频本身的视觉质量如何?” 作者认识到,单一的评估模型可能存在偏差,因此他们设计了一个“混合专家”(Mix-of-Limited-Expert)结构,如图3所示。
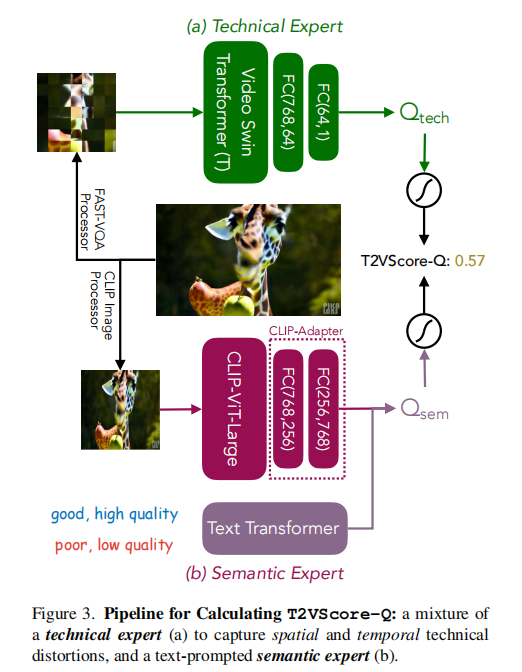
-
技术专家(Technical Expert - 图3a):
- 这是一个预训练的视频质量评估模型(采用FAST-VQA结构),在大型自然视频质量数据库(如LSVQ)上进行了预训练,并在包含多种时空失真的数据集(如MaxWell)上进行了微调。
- 它擅长发现诸如模糊、抖动、编码伪影等“技术性”缺陷。
-
语义专家(Semantic Expert - 图3b):
- 这是一个基于CLIP的模型(MetaCLIP),但它被改造成了一个二分类器。
- 它接收视频和两个对立的文本提示:“good, high quality” 和 “poor, low quality”。
- 模型计算视频与这两个提示的相似度,其差值或置信度被用作质量分数。
- 这种“文本提示”的方式使其能更好地捕捉生成视频特有的“语义失真”,如物体结构不合理、画面逻辑混乱等。
-
分数融合: 两个专家的输出分数
和
会被分别进行ITU标准的感知导向重映射(R(s)),然后取平均值,得到最终的T2VScore-Q:
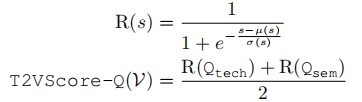
这种“混合专家”的设计,结合了传统VQA的稳健性和新兴文本提示方法的灵活性,旨在获得更强的泛化能力。
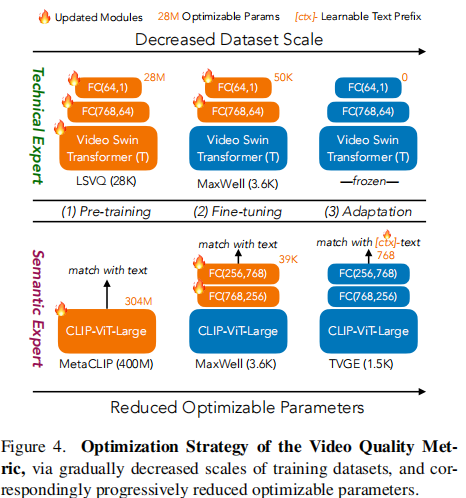
- 渐进式优化策略(Progressive Optimization Strategy - 图4): 为了进一步提升T2VScore-Q的泛化性,作者采用了三阶段的训练策略:
- 预训练(Pre-training): 在最大的自然视频质量数据集(LSVQ, 28K视频)上对技术专家进行端到端训练。
- 微调(Fine-tuning): 在包含生成式失真的数据集(MaxWell, 3.6K视频)上微调两个专家。
- 适应(Adaptation): 在最终的T2V生成视频数据集(TVGE, 1.5K视频)上进行轻量级适配。此时,技术专家被冻结,只更新语义专家的轻量级适配器(adapter)和一个可学习的文本前缀(prefix),以避免过拟合。
三、验证基石——TVGE数据集
任何评估指标的有效性都离不开可靠的基准测试。为此,作者贡献了TVGE (Text-to-Video Generation Evaluation) 数据集,这是该论文的另一项重大贡献。
- 内容: TVGE包含了由5个流行T2V模型(Floor33, Gen2, ModelScope, Pika, ZeroScope)生成的2,543个视频。
- 标注: 每个视频都由10名经验丰富的标注员从文本-视频对齐和视频质量两个维度进行独立评分。
- 意义:
- 首个专用数据集: 这是首个公开的、专门为评估T2V生成效果而设计的数据集,填补了领域的空白。
- 人类判断基准: 它提供了宝贵的人类判断基准,可用于验证任何新评估指标的有效性。
- 揭示领域特性: 如图6所示,数据显示当前T2V模型的平均对齐分(2.59)和质量分(2.77)均低于中等水平,且两者之间的相关性很低(Spearman's ρ=0.223),这证明了对齐和质量是两个独立的、都需要优化的维度,必须分开评估。
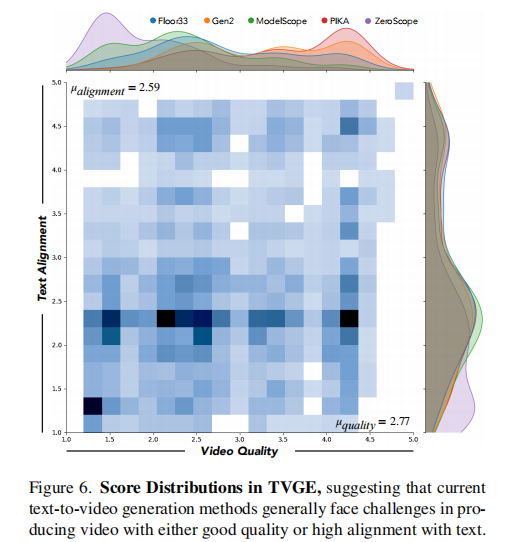
图注:上图展示了TVGE数据集中人类评分的分布情况。两个柱状图分别显示了对齐和质量得分的分布,均偏向低分,表明现有模型仍有很大提升空间。
四、实验与结果——T2VScore为何更优?
作者在TVGE数据集上,将T2VScore与多个基线指标进行了相关性分析(以人类评分为黄金标准)。
4.1 文本-视频对齐(T2VScore-A)
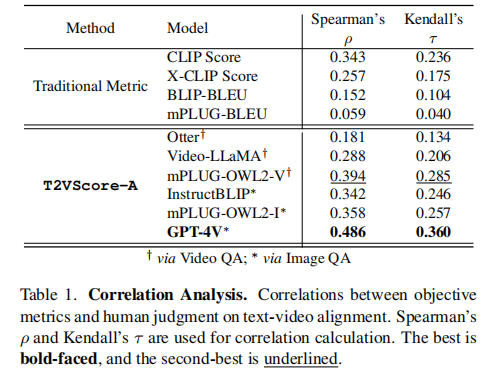
- 结果解读: 所有传统指标的相关性都很低,再次证实了它们的不足。而T2VScore-A,特别是使用GPT-4V作为MLLM时,取得了压倒性的优势。这证明了基于VQA的方法在捕捉细粒度对齐方面的巨大潜力。
4.2 视频质量(T2VScore-Q)
论文同样展示了T2VScore-Q在预测人类质量评分上的优越性,其相关性显著高于FVD、CLIP Score等基线指标。
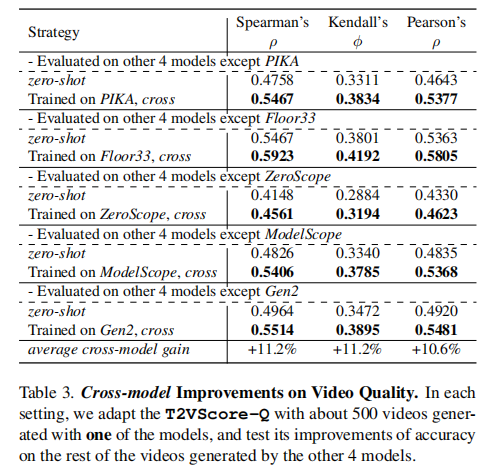
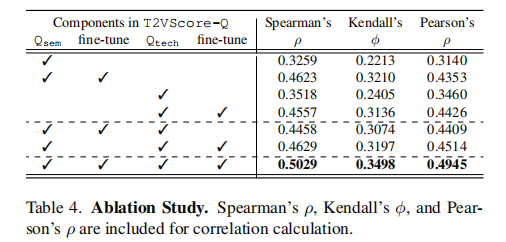
4.3 消融实验(Ablation Studies)
消融实验证明了“混合专家”结构和“渐进式优化”策略的有效性,二者共同提升了模型的泛化能力。
五、总结与展望
《Towards A Better Metric for Text-to-Video Generation》这篇论文是一项很有代表性的工作。它不仅仅提出了一个名为T2VScore的新指标,更是建立了一套完整的、科学的评估范式:
- 明确评估维度: 清晰地将评估拆解为“对齐”和“质量”两个独立方面。
- 创新技术路径: 对于“对齐”,采用基于VQA的细粒度评估;对于“质量”,采用混合专家的鲁棒评估。
- 提供基准数据: 发布TVGE数据集,为整个社区提供了不可或缺的验证平台。
未来展望:
- T2VScore的成功可能会启发更多基于“任务驱动”的评估方法,例如用VQA评估视频摘要,用交互式任务评估虚拟代理等。
- 随着MLLMs(尤其是视频LLMs)能力的不断提升,T2VScore-A的性能有望持续增强。
- TVGE数据集将成为未来T2V模型开发和评估的“必经之路”。
总而言之,T2VScore为我们提供了一把更精准的“尺子”,让我们能够更客观地衡量AI“造梦”的能力。这不仅有助于推动技术进步,也让整个生成式AI领域朝着更加可信赖、可评估的方向迈进。