深入浅出 Java 虚拟机之进阶部分
第17讲:动手实践:从字节码看方法调用的底层实现
本课时我们主要分析从字节码看方法调用的底层实现。
字节码结构
基本结构
在开始之前,我们先简要地介绍一下 class 文件的内容,这个结构和我们前面使用的 jclasslib 是一样的。关于 class 文件结构的资料已经非常多了(点击这里可查看官网详细介绍),这里不再展开讲解了,大体介绍如下。
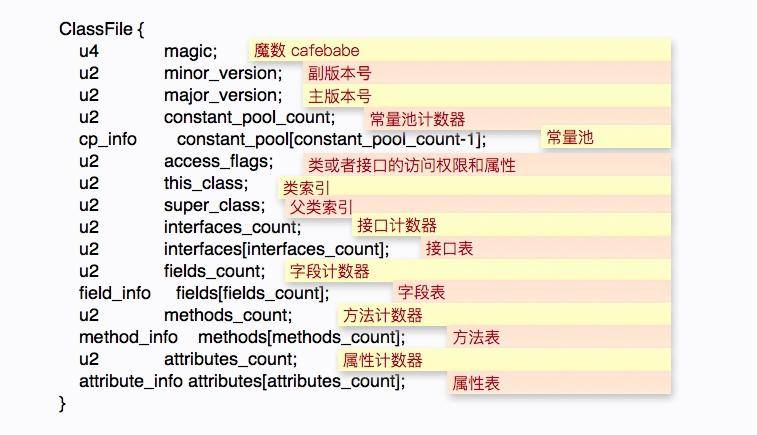
magic:魔数,用于标识当前 class 的文件格式,JVM 可据此判断该文件是否可以被解析,目前固定为 0xCAFEBABE。
major_version:主版本号。
minor_version:副版本号,这两个版本号用来标识编译时的 JDK 版本,常见的一个异常比如 Unsupported major.minor version 52.0 就是因为运行时的 JDK 版本低于编译时的 JDK 版本(52 是 Java 8 的主版本号)。
constant_pool_count:常量池计数器,等于常量池中的成员数加 1。
constant_pool:常量池,是一种表结构,包含 class 文件结构和子结构中引用的所有字符串常量,类或者接口名,字段名和其他常量。
access_flags:表示某个类或者接口的访问权限和属性。
this_class:类索引,该值必须是对常量池中某个常量的一个有效索引值,该索引处的成员必须是一个 CONSTANT_Class_info 类型的结构体,表示这个 class 文件所定义的类和接口。
super_class:父类索引。
interfaces_count:接口计数器,表示当前类或者接口直接继承接口的数量。
interfaces:接口表,是一个表结构,成员同 this_class,是对常量池中 CONSTANT_Class_info 类型的一个有效索引值。
fields_count:字段计数器,当前 class 文件所有字段的数量。
fields:字段表,是一个表结构,表中每个成员必须是 filed_info 数据结构,用于表示当前类或者接口的某个字段的完整描述,但它不包含从父类或者父接口继承的字段。
methods_count:方法计数器,表示当前类方法表的成员个数。
methods:方法表,是一个表结构,表中每个成员必须是 method_info 数据结构,用于表示当前类或者接口的某个方法的完整描述。
attributes_count:属性计数器,表示当前 class 文件 attributes 属性表的成员个数。
attributes:属性表,是一个表结构,表中每个成员必须是 attribute_info 数据结构,这里的属性是对 class 文件本身,方法或者字段的补充描述,比如 SourceFile 属性用于表示 class 文件的源代码文件名。
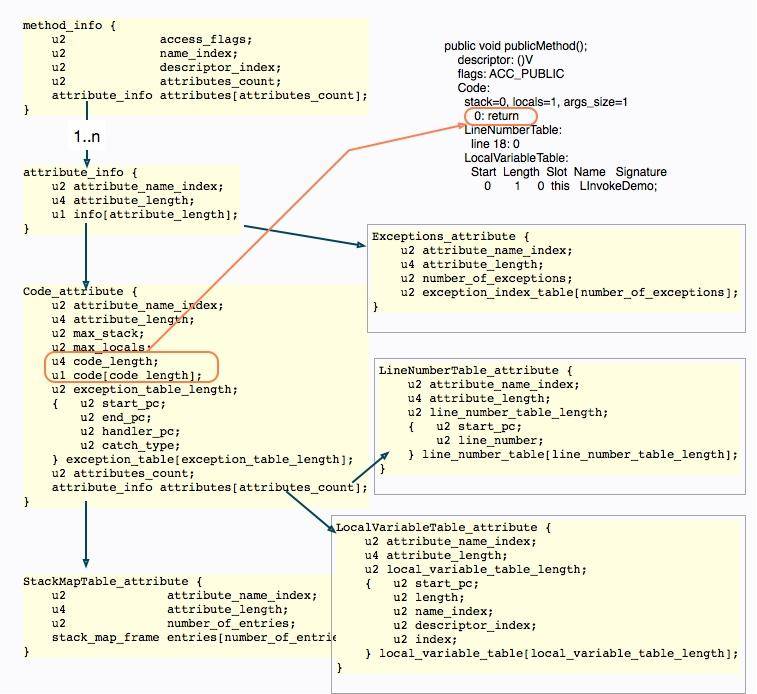
当然,class 文件结构的细节是非常多的,如上图,展示了一个简单方法的字节码描述,可以看到真正的执行指令在整个文件结构中的位置。
实际观测
为了避免枯燥的二进制对比分析,直接定位到真正的数据结构,这里介绍一个小工具,使用这种方式学习字节码会节省很多时间。这个工具就是 asmtools,为了方便使用,我已经编译了一个 jar 包,放在了仓库里。
执行下面的命令,将看到类的 JCOD 语法结果。
java -jar asmtools-7.0.jar jdec LambdaDemo.class
输出的结果类似于下面的结构,它与我们上面介绍的字节码组成是一一对应的,对照官网或者资料去学习,速度飞快。若想要细挖字节码,一定要掌握好它。
class LambdaDemo {0xCAFEBABE;0; // minor version52; // version[] { // Constant Pool; // first element is emptyMethod #8 #25; // #1InvokeDynamic 0s #30; // #2InterfaceMethod #31 #32; // #3Field #33 #34; // #4String #35; // #5Method #36 #37; // #6class #38; // #7class #39; // #8Utf8 "<init>"; // #9Utf8 "()V"; // #10Utf8 "Code"; // #11
了解了类的文件组织方式,下面我们来看一下,类文件在加载到内存中以后,是一个怎样的表现形式。
内存表示
准备以下代码,使用 javac -g InvokeDemo.java 进行编译,然后使用 java 命令执行。程序将阻塞在 sleep 函数上,我们来看一下它的内存分布:
interface I {default void infMethod() { }void inf();
}abstract class Abs {abstract void abs();
}public class InvokeDemo extends Abs implements I {static void staticMethod() { }private void privateMethod() { }public void publicMethod() { }@Overridepublic void inf() { }@Overridevoid abs() { }public static void main(String[] args) throws Exception{InvokeDemo demo = new InvokeDemo();InvokeDemo.staticMethod();demo.abs();((Abs) demo).abs();demo.inf();((I) demo).inf();demo.privateMethod();demo.publicMethod();demo.infMethod();((I) demo).infMethod();Thread.sleep(Integer.MAX_VAL
为了更加明显的看到这个过程,下面介绍一个 jhsdb 工具,这是在 Java 9 之后 JDK 先加入的调试工具,我们可以在命令行中使用 jhsdb hsdb 来启动它。注意,要加载相应的进程时,必须确保是同一个版本的应用进程,否则会产生报错。
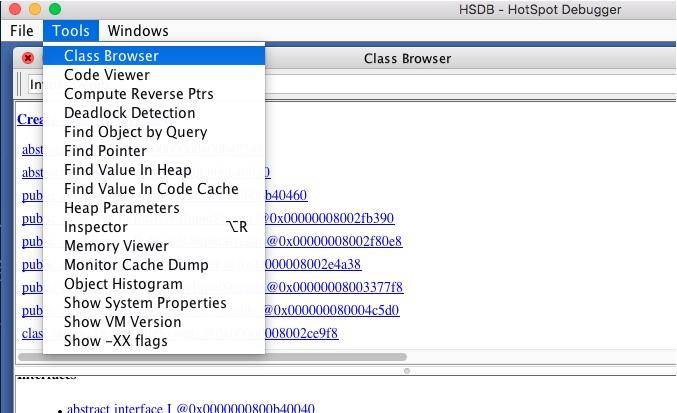
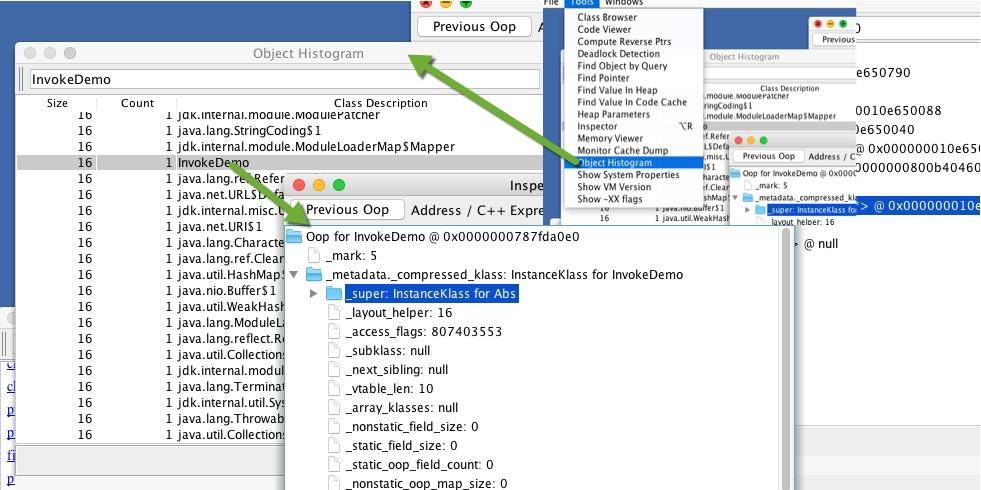
attach 启动 Java 进程后,可以在 Class Browser 菜单中查看加载的所有类信息。我们在搜索框中输入 InvokeDemo,找到要查看的类。
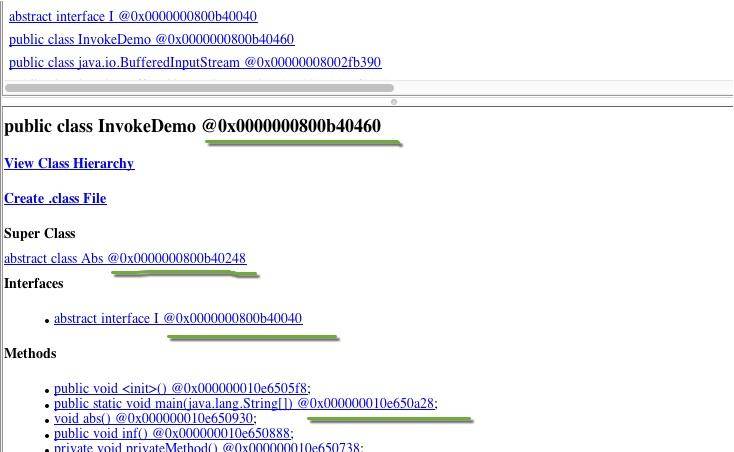
@ 符号后面的,就是具体的内存地址,我们可以复制一个,然后在 Inspector 视图中查看具体的属性,可以大体认为这就是类在方法区的具体存储。
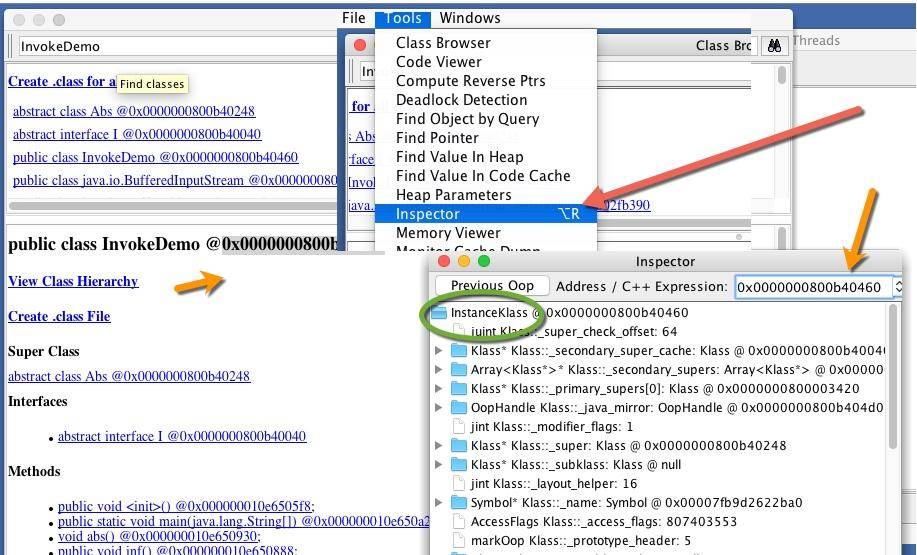
在 Inspector 视图中,我们找到方法相关的属性 _methods,可惜它无法点开,也无法查看。
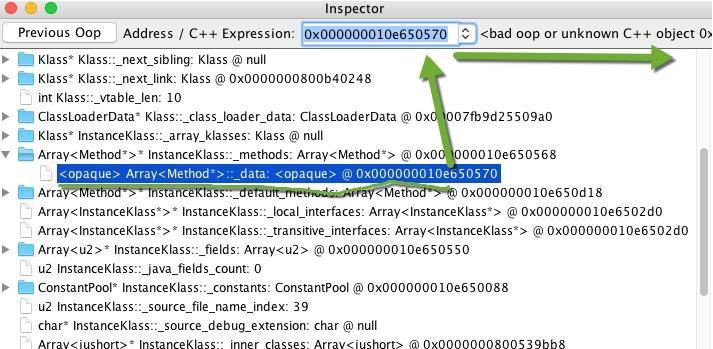
接下来使用命令行来检查这个数组里面的值。打开菜单中的 Console,然后输入 examine 命令,可以看到这个数组里的内容,对应的地址就是 Class 视图中的方法地址。
examine 0x000000010e650570/10
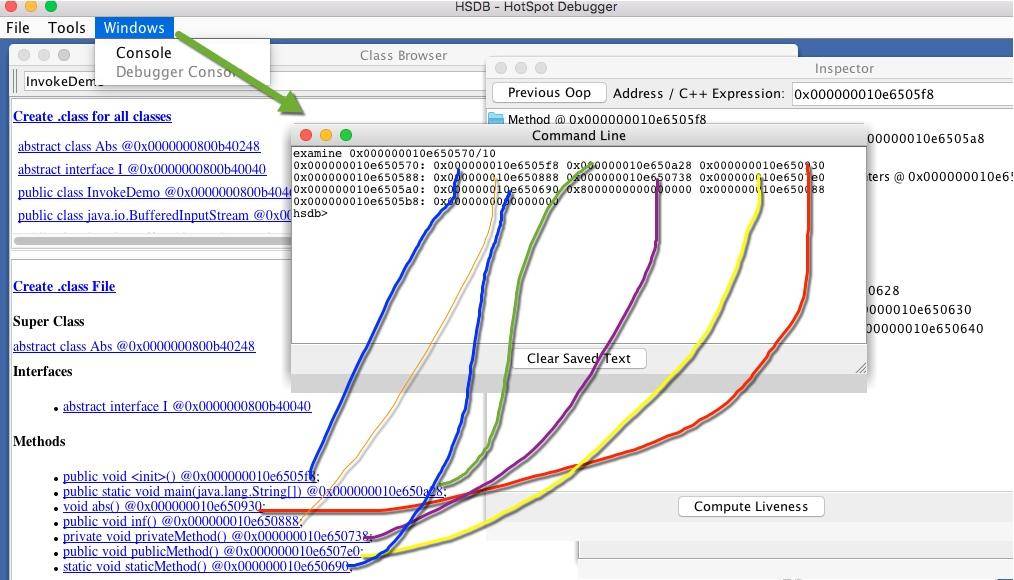
我们可以在 Inspect 视图中看到方法所对应的内存信息,这确实是一个 Method 方法的表示。
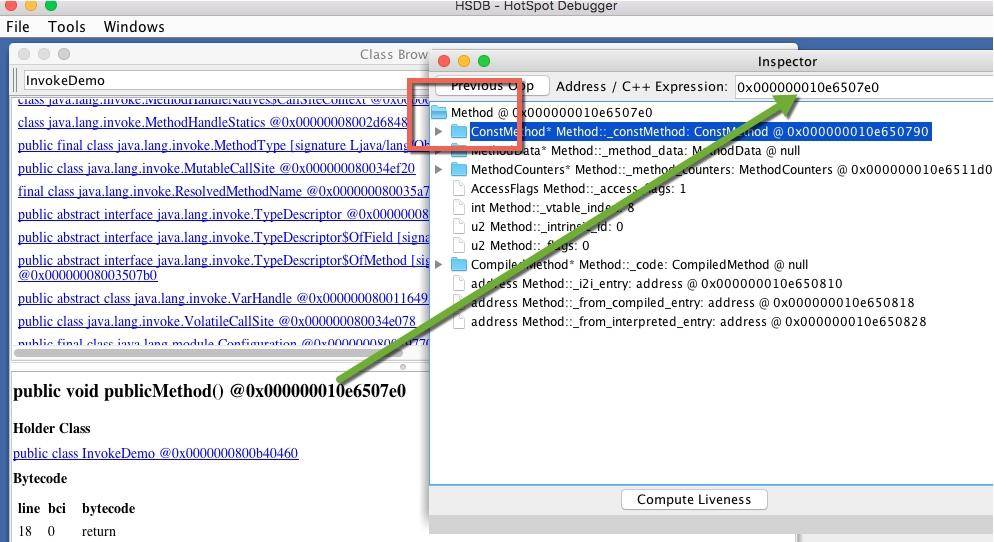
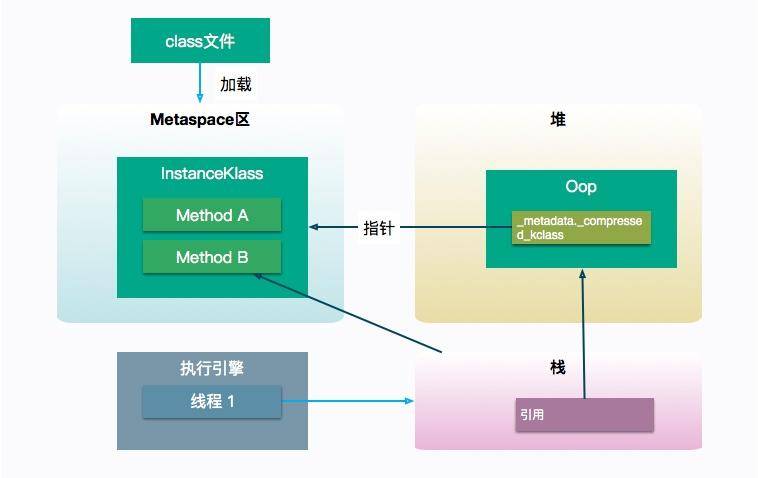
相比较起来,对象就简单了,它只需要保存一个到达 Class 对象的指针即可。我们需要先从对象视图中进入,然后找到它,一步步进入 Inspect 视图。
由以上的这些分析,可以得出下面这张图。执行引擎想要运行某个对象的方法,需要先在栈上找到这个对象的引用,然后再通过对象的指针,找到相应的方法字节码。
方法调用指令
关于方法的调用,Java 共提供了 5 个指令,来调用不同类型的函数:
- invokestatic 用来调用静态方法;
- invokevirtual 用于调用非私有实例方法,比如 public 和 protected,大多数方法调用属于这一种;
- invokeinterface 和上面这条指令类似,不过作用于接口类;
- invokespecial 用于调用私有实例方法、构造器及 super 关键字等;
- invokedynamic 用于调用动态方法。
我们依然使用上面的代码片段来看一下前四个指令的使用场景。代码中包含一个接口 I、一个抽象类 Abs、一个实现和继承了两者类的 InvokeDemo。
回想一下,第 03 课时讲到的类加载机制,在 class 文件被加载到方法区以后,就完成了从符号引用到具体地址的转换过程。
我们可以看一下编译后的 main 方法字节码,尤其需要注意的是对于接口方法的调用。使用实例对象直接调用,和强制转化成接口调用,所调用的字节码指令分别是 invokevirtual 和 invokeinterface,它们是有所不同的。
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=2, locals=2, args_size=10: new #2 // class InvokeDemo3: dup4: invokespecial #3 // Method "<init>":()V7: astore_18: invokestatic #4 // Method staticMethod:()V11: aload_112: invokevirtual #5 // Method abs:()V15: aload_116: invokevirtual #6 // Method Abs.abs:()V19: aload_120: invokevirtual #7 // Method inf:()V23: aload_124: invokeinterface #8, 1 // InterfaceMethod I.inf:()V29: aload_130: invokespecial #9 // Method privateMethod:()V33: aload_134: invokevirtual #10 // Method publicMethod:()V37: aload_138: invokevirtual #11 // Method infMethod:()V41: aload_142: invokeinterface #12, 1 // InterfaceMethod I.infMethod:()V47: return
另外还有一点,和我们想象中的不同,大多数普通方法调用,使用的是 invokevirtual 指令,它其实和 invokeinterface 是一类的,都属于虚方法调用。很多时候,JVM 需要根据调用者的动态类型,来确定调用的目标方法,这就是动态绑定的过程。
invokevirtual 指令有多态查找的机制,该指令运行时,解析过程如下:
- 找到操作数栈顶的第一个元素所指向的对象实际类型,记做 c;
- 如果在类型 c 中找到与常量中的描述符和简单名称都相符的方法,则进行访问权限校验,如果通过则返回这个方法直接引用,查找过程结束,不通过则返回 java.lang.IllegalAccessError;
- 否则,按照继承关系从下往上依次对 c 的各个父类进行第二步的搜索和验证过程;
- 如果始终没找到合适的方法,则抛出 java.lang.AbstractMethodError 异常,这就是 Java 语言中方法重写的本质。
相对比,invokestatic 指令加上 invokespecial 指令,就属于静态绑定过程。
所以静态绑定,指的是能够直接识别目标方法的情况,而动态绑定指的是需要在运行过程中根据调用者的类型来确定目标方法的情况。
可以想象,相对于静态绑定的方法调用来说,动态绑定的调用会更加耗时一些。由于方法的调用非常的频繁,JVM 对动态调用的代码进行了比较多的优化,比如使用方法表来加快对具体方法的寻址,以及使用更快的缓冲区来直接寻址( 内联缓存)。
invokedynamic
有时候在写一些 Python 脚本或者JS 脚本时,特别羡慕这些动态语言。如果把查找目标方法的决定权,从虚拟机转嫁给用户代码,我们就会有更高的自由度。
之所以单独把 invokedynamic 抽离出来介绍,是因为它比较复杂。和反射类似,它用于一些动态的调用场景,但它和反射有着本质的不同,效率也比反射要高得多。
这个指令通常在 Lambda 语法中出现,我们来看一下一小段代码:
public class LambdaDemo {public static void main(String[] args) {Runnable r = () -> System.out.println("Hello Lambda");r.run();}
}
使用 javap -p -v 命令可以在 main 方法中看到 invokedynamic 指令:
public static void main(java.lang.String[]);descriptor: ([Ljava/lang/String;)Vflags: ACC_PUBLIC, ACC_STATICCode:stack=1, locals=2, args_size=10: invokedynamic #2, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;5: astore_16: aload_17: invokeinterface #3, 1 // InterfaceMethod java/lang/Runnable.run:()V12: return
另外,我们在 javap 的输出中找到了一些奇怪的东西:
BootstrapMethods:0: #27 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;Method arguments:#28 ()V#29 invokestatic LambdaDemo.lambda$main$0:()V#28 ()V
BootstrapMethods 属性在 Java 1.7 以后才有,位于类文件的属性列表中,这个属性用于保存 invokedynamic 指令引用的引导方法限定符。
和上面介绍的四个指令不同,invokedynamic 并没有确切的接受对象,取而代之的,是一个叫 CallSite 的对象。
static CallSite bootstrap(MethodHandles.Lookup caller, String name, MethodType type);
其实,invokedynamic 指令的底层,是使用方法句柄(MethodHandle)来实现的。方法句柄是一个能够被执行的引用,它可以指向静态方法和实例方法,以及虚构的 get 和 set 方法,从 IDE 中可以看到这些函数。
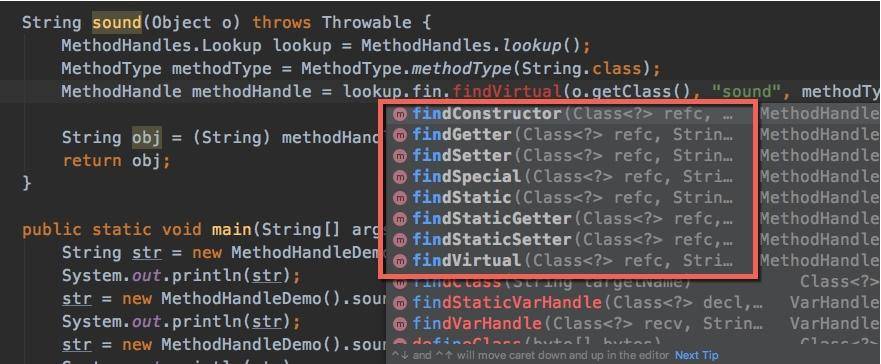
句柄类型(MethodType)是我们对方法的具体描述,配合方法名称,能够定位到一类函数。访问方法句柄和调用原来的指令基本一致,但它的调用异常,包括一些权限检查,在运行时才能被发现。
下面这段代码,可以完成一些动态语言的特性,通过方法名称和传入的对象主体,进行不同的调用,而 Bike 和 Man 类,可以没有任何关系。
import java.lang.invoke.MethodHandle;
import java.lang.invoke.MethodHandles;
import java.lang.invoke.MethodType;public class MethodHandleDemo {static class Bike {String sound() {return "ding ding";}}static class Animal {String sound() {return "wow wow";}}static class Man extends Animal {@OverrideString sound() {return "hou hou";}}String sound(Object o) throws Throwable {MethodHandles.Lookup lookup = MethodHandles.lookup();MethodType methodType = MethodType.methodType(String.class);MethodHandle methodHandle = lookup.findVirtual(o.getClass(), "sound", methodType);String obj = (String) methodHandle.invoke(o);return obj;}public static void main(String[] args) throws Throwable {String str = new MethodHandleDemo().sound(new Bike());System.out.println(str);str = new MethodHandleDemo().sound(new Animal());System.out.println(str);str = new MethodHandleDemo().sound(new Man());System.out.println(str);}
}
可以看到 Lambda 语言实际上是通过方法句柄来完成的,在调用链上自然也多了一些调用步骤,那么在性能上,是否就意味着 Lambda 性能低呢?对于大部分“非捕获”的 Lambda 表达式来说,JIT 编译器的逃逸分析能够优化这部分差异,性能和传统方式无异;但对于“捕获型”的表达式来说,则需要通过方法句柄,不断地生成适配器,性能自然就低了很多(不过和便捷性相比,一丁点性能损失是可接受的)。
除了 Lambda 表达式,我们还没有其他的方式来产生 invokedynamic 指令。但可以使用一些外部的字节码修改工具,比如 ASM,来生成一些带有这个指令的字节码,这通常能够完成一些非常酷的功能,比如完成一门弱类型检查的 JVM-Base 语言。
小结
本课时从 Java 字节码的顶层结构介绍开始,通过一个实际代码,了解了类加载以后,在 JVM 内存里的表现形式,并学习了 jhsdb 对 Java 进程的观测方式。
接下来,我们分析了 invokestatic、invokevirtual、invokeinterface、invokespecial 这四个字节码指令的使用场景,并从字节码中看到了这些区别。
最后,了解了 Java 7 之后的 invokedynamic 指令,它实际上是通过方法句柄来实现的。和我们关系最大的就是 Lambda 语法,了解了这些原理,可以忽略那些对 Lambda 性能高低的争论,要尽量写一些“非捕获”的 Lambda 表达式。
第18讲:大厂面试题:不要搞混JMM与JVM
本课时我们主要分析一个大厂面试题:不要搞混 JMM 与 JVM。
在面试的时候,有一个问题经常被问到,那就是 Java 的内存模型,它已经成为了面试中的标配,是非常具有原理性的一个知识点。但是,有不少人把它和 JVM 的内存布局搞混了,以至于答非所问。这个现象在一些工作多年的程序员中非常普遍,主要是因为 JMM 与多线程有关,而且相对于底层而言,很多人平常的工作就是 CRUD,很难接触到这方面的知识。
预警:本课时假设你已经熟悉 Java 并发编程的 API,且有实际的编程经验。如果不是很了解,那么本课时和下一课时的一些内容,可能会比较晦涩。
JMM 概念
在第 02 课时,就已经了解了 JVM 的内存布局,你可以认为这是 JVM 的数据存储模型;但对于 JVM 的运行时模型,还有一个和多线程相关的,且非常容易搞混的概念——Java 的内存模型(JMM,Java Memory Model)。
我们在 Java 的内存布局课时(第02课时)中,还了解了 Java 的虚拟机栈,它和线程相关,也就是我们的字节码指令其实是靠操作栈来完成的。现在,用一小段代码,来看一下这个执行引擎的一些特点。
import java.util.stream.IntStream;public class JMMDemo {int value = 0;void add() {value++;}public static void main(String[] args) throws Exception {final int count = 100000;final JMMDemo demo = new JMMDemo();Thread t1 = new Thread(() -> IntStream.range(0, count).forEach((i) -> demo.add()));Thread t2 = new Thread(() -> IntStream.range(0, count).forEach((i) -> demo.add()));t1.start();t2.start();t1.join();t2.join();System.out.println(demo.value);}
}
上面的代码没有任何同步块,每个线程单独运行后,都会对 value 加 10 万,但执行之后,大概率不会输出 20 万。深层次的原因,我们将使用 javap 命令从字节码层面找一下。
void add();descriptor: ()Vflags:Code:stack=3, locals=1, args_size=10: aload_01: dup2: getfield #2 // Field value:I5: iconst_16: iadd7: putfield #2 // Field value:I10: returnLineNumberTable:line 7: 0line 8: 10LocalVariableTable:Start Length Slot Name Signature0 11 0 this LJMMDemo;
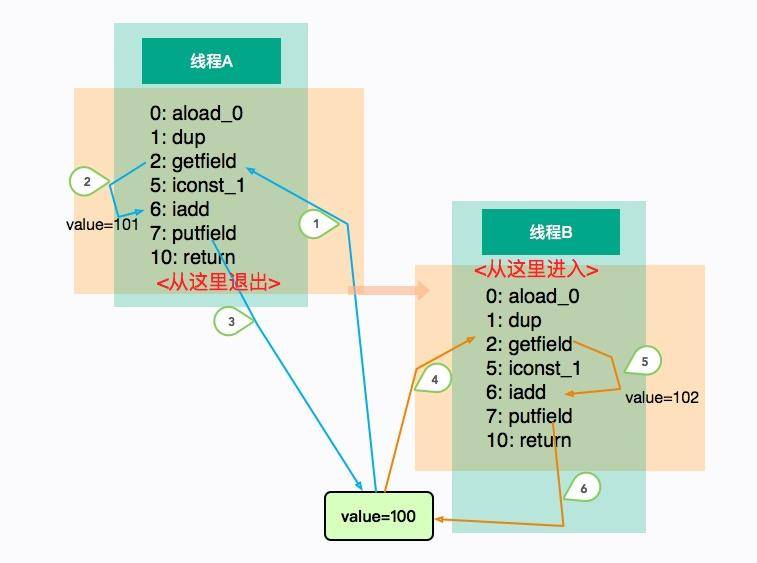
着重看一下 add 方法,可以看到一个简单的 i++ 操作,竟然有这么多的字节码,而它们都是傻乎乎按照“顺序执行”的。当它自己执行的时候不会有什么问题,但是如果放在多线程环境中,执行顺序就变得不可预料了。
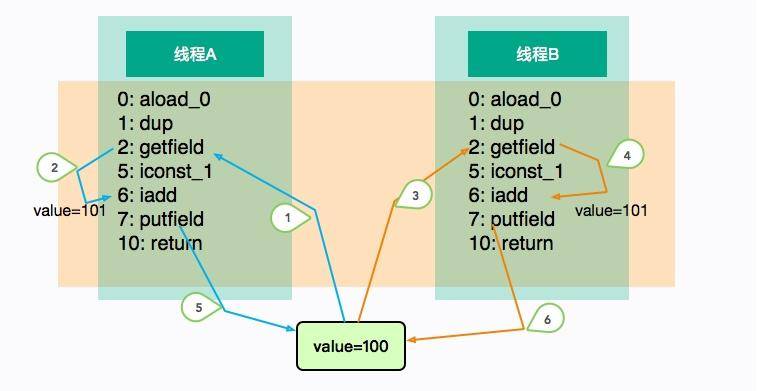
上图展示了这个乱序的过程。线程 A 和线程 B“并发”执行相同的代码块 add,执行的顺序如图中的标号,它们在线程中是有序的(1、2、5 或者 3、4、6),但整体顺序是不可预测的。
线程 A 和 B 各自执行了一次加 1 操作,但在这种场景中,线程 B 的 putfield 指令直接覆盖了线程 A 的值,最终 value 的结果是 101。
上面的示例仅仅是字节码层面上的,更加复杂的是,CPU 和内存之间同样存在一致性问题。很多人认为 CPU 是一个计算组件,并没有数据一致性的问题。但事实上,由于内存的发展速度跟不上 CPU 的更新,在 CPU 和内存之间,存在着多层的高速缓存。
原因就是由于多核所引起的,这些高速缓存,往往会有多层。如果一个线程的时间片跨越了多个 CPU,那么同样存在同步的问题。
另外,在执行过程中,CPU 可能也会对输入的代码进行乱序执行优化,Java 虚拟机的即时编译器也有类似的指令重排序优化。整个函数的执行步骤就分的更加细致,看起来非常的碎片化(比字节码指令要细很多)。
不管是字节码的原因,还是硬件的原因,在粗粒度上简化来看,比较浅显且明显的因素,那就是线程 add 方法的操作并不是原子性的。
为了解决这个问题,我们可以在 add 方法上添加 synchronized 关键字,它不仅保证了内存上的同步,而且还保证了 CPU 的同步。这个时候,各个线程只能排队进入 add 方法,我们也能够得到期望的结果 102。
synchronized void add() {value++;
}
讲到这里,Java 的内存模型就呼之欲出了。JMM 是一个抽象的概念,它描述了一系列的规则或者规范,用来解决多线程的共享变量问题,比如 volatile、synchronized 等关键字就是围绕 JMM 的语法。这里所说的变量,包括实例字段、静态字段,但不包括局部变量和方法参数,因为后者是线程私有的,不存在竞争问题。
JVM 试图定义一种统一的内存模型,能将各种底层硬件,以及操作系统的内存访问差异进行封装,使 Java 程序在不同硬件及操作系统上都能达到相同的并发效果。
JMM 的结构
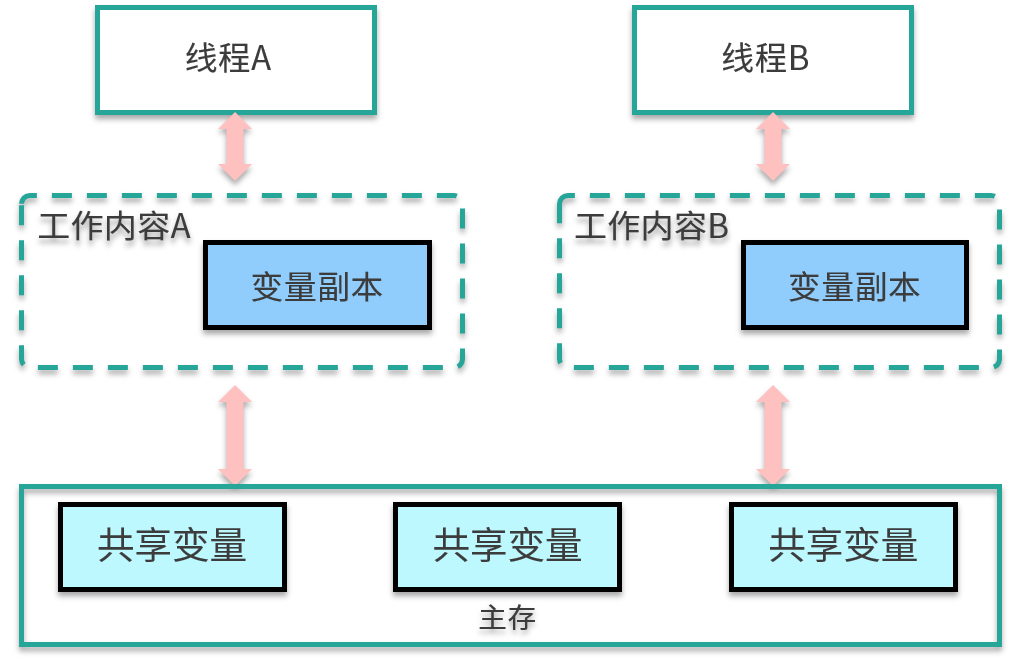
JMM 分为主存储器(Main Memory)和工作存储器(Working Memory)两种。
- 主存储器是实例位置所在的区域,所有的实例都存在于主存储器内。比如,实例所拥有的字段即位于主存储器内,主存储器是所有的线程所共享的。
- 工作存储器是线程所拥有的作业区,每个线程都有其专用的工作存储器。工作存储器存有主存储器中必要部分的拷贝,称之为工作拷贝(Working Copy)。
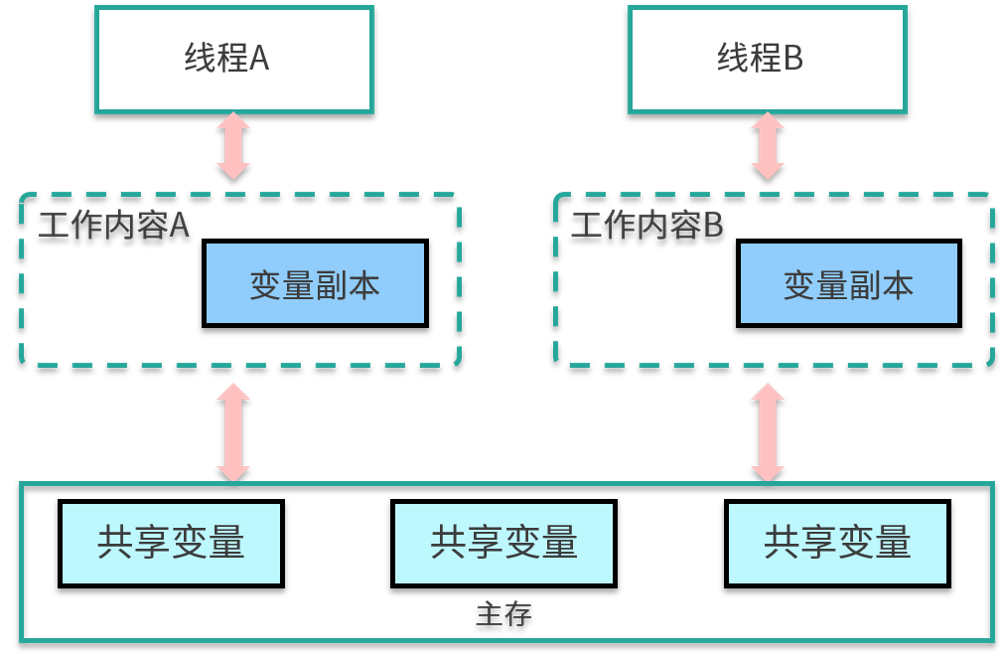
在这个模型中,线程无法对主存储器直接进行操作。如下图,线程 A 想要和线程 B 通信,只能通过主存进行交换。
那这些内存区域都是在哪存储的呢?如果非要有个对应的话,你可以认为主存中的内容是 Java 堆中的对象,而工作内存对应的是虚拟机栈中的内容。但实际上,主内存也可能存在于高速缓存,或者 CPU 的寄存器上;工作内存也可能存在于硬件内存中,我们不用太纠结具体的存储位置。
8 个 Action
操作类型
为了支持 JMM,Java 定义了 8 种原子操作(Action),用来控制主存与工作内存之间的交互。
(1)read(读取)作用于主内存,它把变量从主内存传动到线程的工作内存中,供后面的 load 动作使用。
(2)load(载入)作用于工作内存,它把 read 操作的值放入到工作内存中的变量副本中。
(3)store(存储)作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的 write 操作使用。
(4)write (写入)作用于主内存,它把 store 传送值放到主内存中的变量中。
(5)use(使用)作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时,将会执行这个动作。
(6)assign(赋值)作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时,执行该操作。
(7)lock(锁定)作用于主内存,把变量标记为线程独占状态。
(8)unlock(解锁)作用于主内存,它将释放独占状态。
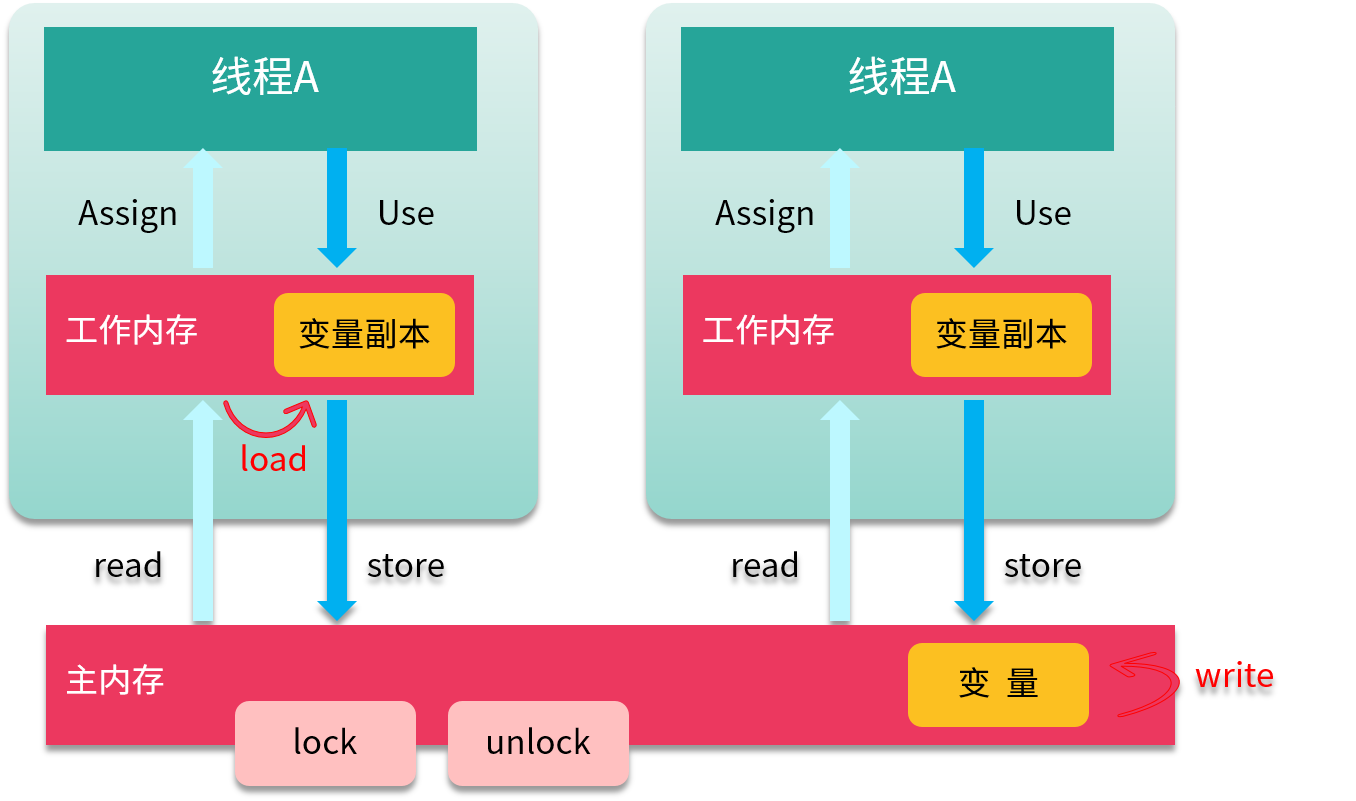
如上图所示,把一个变量从主内存复制到工作内存,就要顺序执行 read 和 load;而把变量从工作内存同步回主内存,就要顺序执行 store 和 write 操作。
三大特征
(1)原子性
JMM 保证了 read、load、assign、use、store 和 write 六个操作具有原子性,可以认为除了 long 和 double 类型以外,对其他基本数据类型所对应的内存单元的访问读写都是原子的。
如果想要一个颗粒度更大的原子性保证,就可以使用 lock 和 unlock 这两个操作。
(2)可见性
可见性是指当一个线程修改了共享变量的值,其他线程也能立即感知到这种变化。
我们从前面的图中可以看到,要保证这种效果,需要经历多次操作。一个线程对变量的修改,需要先同步给主内存,赶在另外一个线程的读取之前刷新变量值。
volatile、synchronized、final 和锁,都是保证可见性的方式。
这里要着重提一下 volatile,因为它的特点最显著。使用了 volatile 关键字的变量,每当变量的值有变动时,都会把更改立即同步到主内存中;而如果某个线程想要使用这个变量,则先要从主存中刷新到工作内存上,这样就确保了变量的可见性。
而锁和同步关键字就比较好理解一些,它是把更多个操作强制转化为原子化的过程。由于只有一把锁,变量的可见性就更容易保证。
(3)有序性
Java 程序很有意思,从上面的 add 操作可以看出,如果在线程中观察,则所有的操作都是有序的;而如果在另一个线程中观察,则所有的操作都是无序的。
除了多线程这种无序性的观测,无序的产生还来源于指令重排。
指令重排序是 JVM 为了优化指令,来提高程序运行效率的,在不影响单线程程序执行结果的前提下,按照一定的规则进行指令优化。在某些情况下,这种优化会带来一些执行的逻辑问题,在并发执行的情况下,按照不同的逻辑会得到不同的结果。
我们可以看一下 Java 语言中默认的一些“有序”行为,也就是先行发生(happens-before)原则,这些可能在写代码的时候没有感知,因为它是一种默认行为。
先行发生是一个非常重要的概念,如果操作 A 先行发生于操作 B,那么操作 A 产生的影响能够被操作 B 感知到。
下面的原则是《Java 并发编程实践》这本书中对一些法则的描述。
- 程序次序:一个线程内,按照代码顺序,写在前面的操作先行发生于写在后面的操作。
- **监视器锁定:**unLock 操作先行发生于后面对同一个锁的 lock 操作。
- volatile:对一个变量的写操作先行发生于后面对这个变量的读操作。
- 传递规则:如果操作 A 先行发生于操作 B,而操作 B 又先行发生于操作 C,则可以得出操作 A 先行发生于操作 C。
- 线程启动:对线程 start() 的操作先行发生于线程内的任何操作。
- 线程中断:对线程 interrupt() 的调用先行发生于线程代码中检测到中断事件的发生,可以通过 Thread.interrupted() 方法检测是否发生中断。
- 线程终结规则:线程中的所有操作先行发生于检测到线程终止,可以通过 Thread.join()、Thread.isAlive() 的返回值检测线程是否已经终止。
- 对象终结规则:一个对象的初始化完成先行发生于它的 finalize() 方法的开始。
内存屏障
那我们上面提到这么多规则和特性,是靠什么保证的呢?
内存屏障(Memory Barrier)用于控制在特定条件下的重排序和内存可见性问题。JMM 内存屏障可分为读屏障和写屏障,Java 的内存屏障实际上也是上述两种的组合,完成一系列的屏障和数据同步功能。Java 编译器在生成字节码时,会在执行指令序列的适当位置插入内存屏障来限制处理器的重排序。
下面介绍一下这些组合。
Load-Load Barriers
保证 load1 数据的装载优先于 load2 以及所有后续装载指令的装载。对于 Load Barrier 来说,在指令前插入 Load Barrier,可以让高速缓存中的数据失效,强制重新从主内存加载数据。
load1
LoadLoad
load2
Load-Store Barriers
保证 load1 数据装载优先于 store2 以及后续的存储指令刷新到内存。
load1
LoadStore
store2
Store-Store Barriers
保证 store1 数据对其他处理器可见,优先于 store2 以及所有后续存储指令的存储。对于 Store Barrier 来说,在指令后插入 Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
store1
StoreStore
store
Store-Load Barriers
在 Load2 及后续所有读取操作执行前,保证 Store1 的写入对所有处理器可见。这条内存屏障指令是一个全能型的屏障,它同时具有其他 3 条屏障的效果,而且它的开销也是四种屏障中最大的一个。
store1
StoreLoad
load2
小结
好了,到这里我们已经简要地介绍完了 JMM 相关的知识点。前面提到过,“请谈一下 Java 的内存模型”这个面试题非常容易被误解,甚至很多面试官自己也不清楚这个概念。其实,如果我们把 JMM 叫作“Java 的并发内存模型”,会更容易理解。
这个时候,可以和面试官确认一下,问的是 Java 内存布局,还是和多线程相关的 JMM,如果不是 JMM,你就需要回答一下第 02 课时的相关知识了。
JMM 可以说是 Java 并发的基础,它的定义将直接影响多线程实现的机制,如果你想要深入了解多线程并发中的相关问题现象,对 JMM 的深入研究是必不可少的。
第19讲:动手实践:从字节码看并发编程的底层实现
本课时我们主要分享一个实践案例:从字节码看并发编程的底层实现。
我们在上一课时中简单学习了 JMM 的概念,知道了 Java 语言中一些默认的 happens-before 规则,是靠内存屏障完成的。其中的 lock 和 unlock 两个 Action,就属于粒度最大的两个操作。
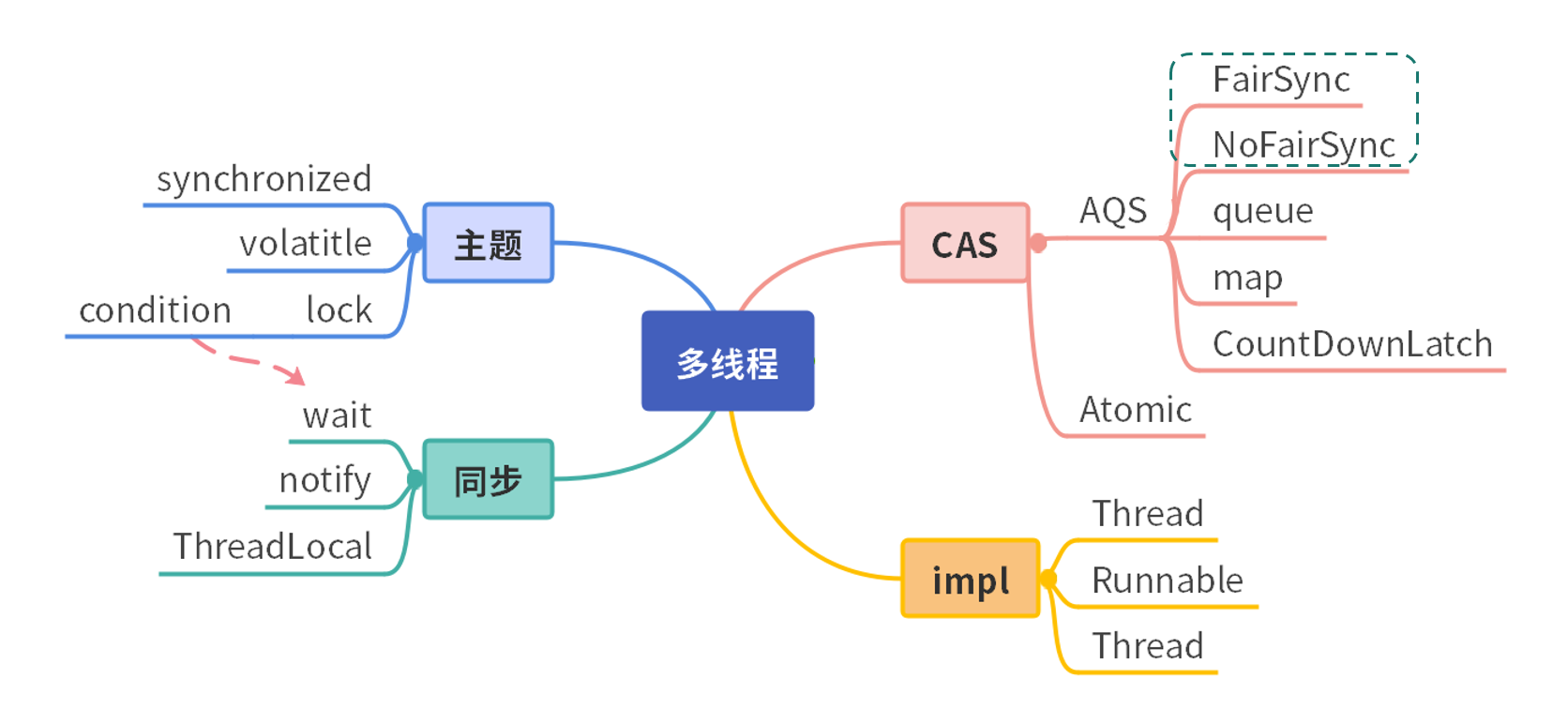
如下图所示,Java 中的多线程,第一类是 Thread 类。它有三种实现方式:第 1 种是通过继承 Thread 覆盖它的 run 方法;第 2 种是通过 Runnable 接口,实现它的 run 方法;而第 3 种是通过创建线程,就是通过线程池的方法去创建。
多线程除了增加任务的执行速度,同样也有共享变量的同步问题。传统的线程同步方式,是使用 synchronized 关键字,或者 wait、notify 方法等,比如我们在第 15 课时中所介绍的,使用 jstack 命令可以观测到各种线程的状态。在目前的并发编程中,使用 concurrent 包里的工具更多一些。
线程模型
我们首先来看一下 JVM 的线程模型,以及它和操作系统进程之间的关系。
如下图所示,对于 Hotspot 来说,每一个 Java 线程,都会映射到一条轻量级进程中(LWP,Light Weight Process)。轻量级进程是用户进程调用系统内核所提供的一套接口,实际上它还需要调用更加底层的内核线程(KLT,Kernel-Level Thread)。而具体的功能,比如创建、同步等,则需要进行系统调用。
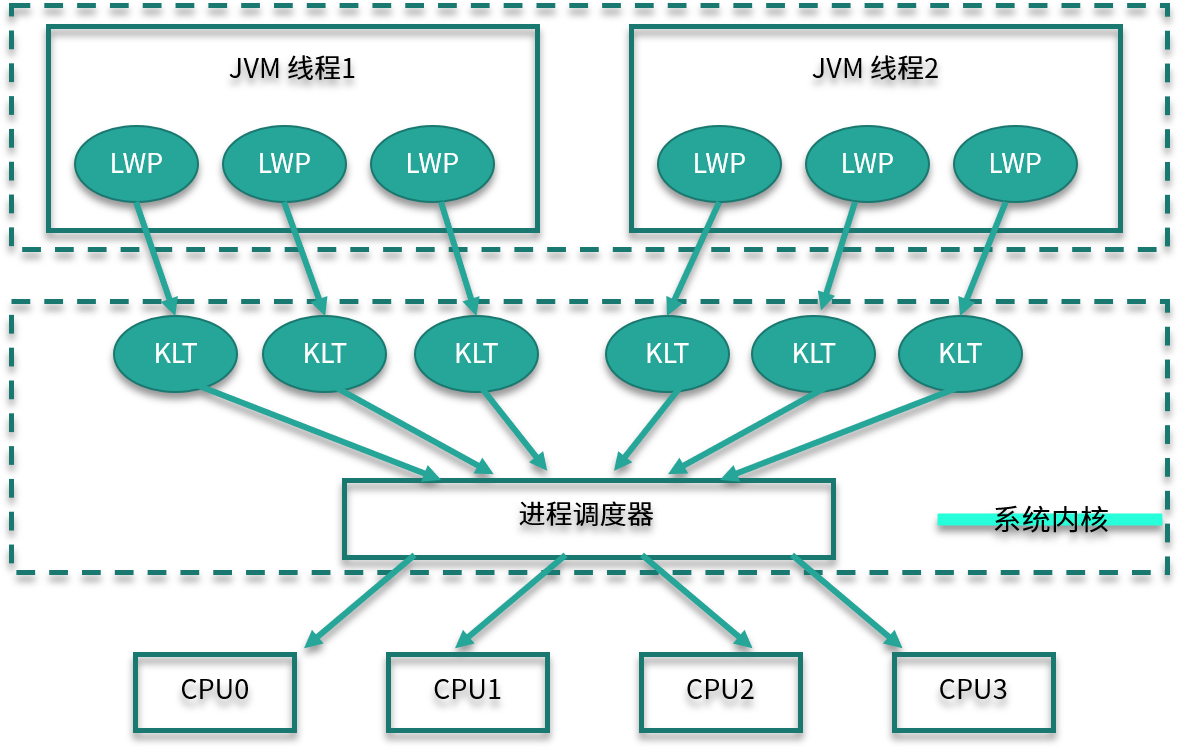
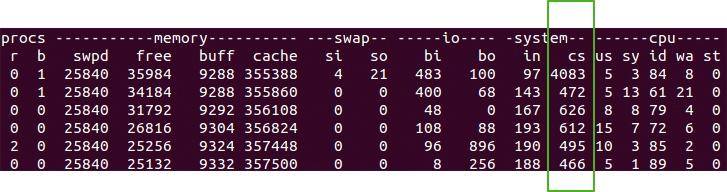
这些系统调用的操作,代价都比较高,需要在用户态(User Mode)和内核态(Kernel Mode)中来回切换,也就是我们常说的线程上下文切换( CS,Context Switch)。
使用 vmstat 命令能够方便地观测到这个数值。
Java 在保证正确的前提下,要想高效并发,就要尽量减少上下文的切换。
一般有下面几种做法来减少上下文的切换:
- CAS 算法,比如 Java 的 Atomic 类,如果使用 CAS 来更新数据,则不需要加锁;
- 减少锁粒度,多线程竞争会引起上下文的频繁切换,如果在处理数据的时候,能够将数据分段,即可减少竞争,Java 的 ConcurrentHashMap、LongAddr 等就是这样的思路;
- 协程,在单线程里实现多任务调度,并在单线程里支持多个任务之间的切换;
- 对加锁的对象进行智能判断,让操作更加轻量级。
CAS 和无锁并发一般是建立在 concurrent 包里面的 AQS 模型之上,大多数属于 Java 语言层面上的知识点。本课时在对其进行简单的描述后,会把重点放在普通锁的优化上。
CAS
CAS(Compare And Swap,比较并替换)机制中使用了 3 个基本操作数:内存地址 V、旧的预期值 A 和要修改的新值 B。更新一个变量时,只有当变量的预期值 A 和内存地址 V 当中的实际值相同时,才会将内存地址 V 对应的值修改为 B。
如果修改不成功,CAS 将不断重试。
拿 AtomicInteger 类来说,相关的代码如下:
public final boolean compareAndSet(int expectedValue, int newValue) {return U.compareAndSetInt(this, VALUE, expectedValue, newValue);
}
可以看到,这个操作,是由 jdk.internal.misc.Unsafe 类进行操作的,而这是一个 native 方法:
@HotSpotIntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset, int expected, int x);
我们继续向下跟踪,在 Linux 机器上参照 os_cpu/linux_x86/atomic_linux_x86.hpp:
template<>
template<typename T>
inline T
Atomic::PlatformCmpxchg<4>::operator()(T exchange_value, T
volatile*dest,T compare_value, atomic_memory_order /* order */)const{STATIC_ASSERT(4==sizeof(T));
__asm__ volatile ("lock cmpxchgl %1,(%3)":"=a"(exchange_value):"r"(exchange_value),"a"(compare_value),"r"(dest):"cc","memory");return exchange_value;
}
可以看到,最底层的调用是汇编语言,而最重要的就是 cmpxchgl 指令,到这里没法再往下找代码了,也就是说 CAS 的原子性实际上是硬件 CPU 直接实现的。
synchronized
字节码
synchronized 可以在是多线程中使用的最多的关键字了。在开始介绍之前,请思考一个问题:在执行速度方面,是基于 CAS 的 Lock 效率高一些,还是同步关键字效率高一些?
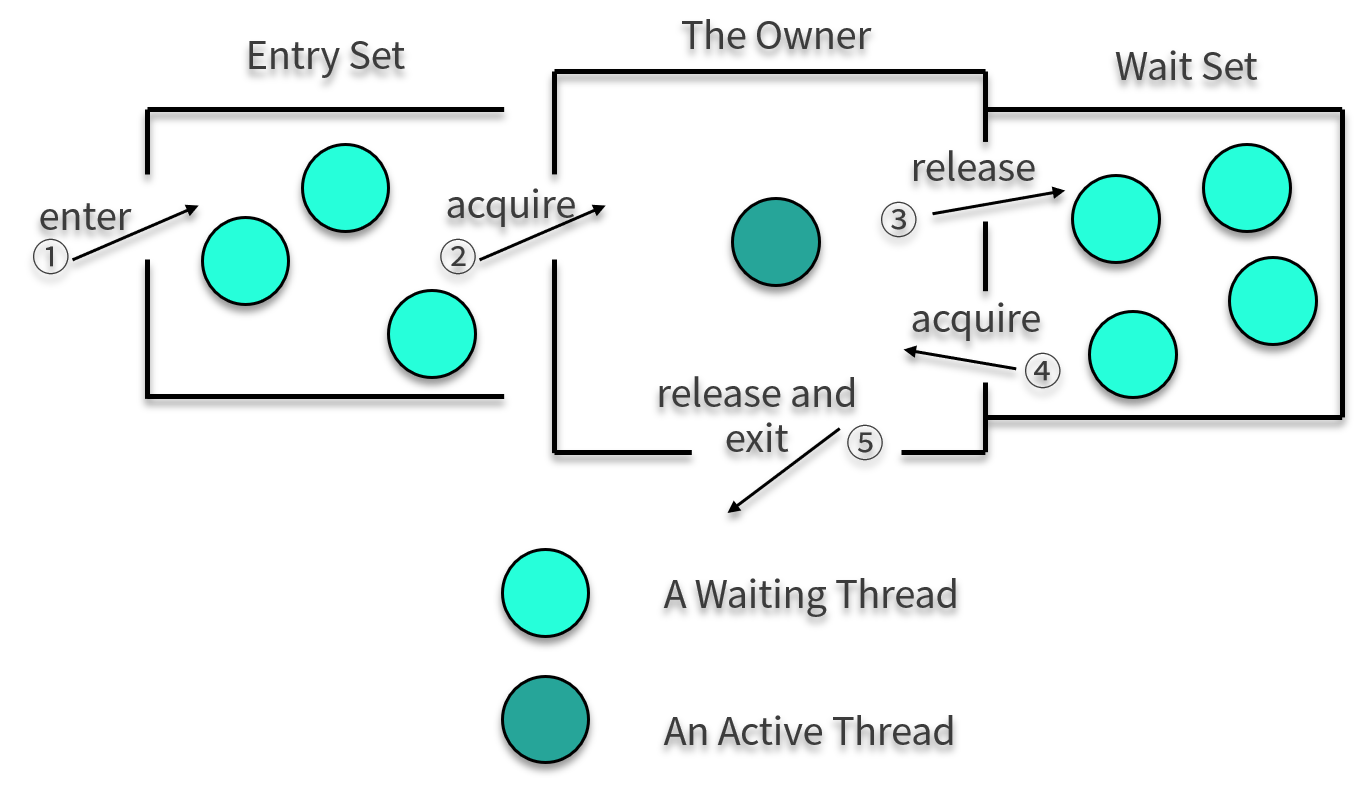
synchronized 关键字给代码或者方法上锁时,会有显示或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它必须先得到锁,而在退出或抛出异常时必须释放锁。
- 给普通方法加锁时,上锁的对象是 this,如代码中的方法 m1 。
- 给静态方法加锁时,锁的是 class 对象,如代码中的方法 m2 。
- 给代码块加锁时,可以指定一个具体的对象。
关于对象对锁的争夺,我们依然拿前面讲的一张图来看一下这个过程。
下面我们来看一段简单的代码,并观测一下它的字节码。
public class SynchronizedDemo {synchronized void m1() {System.out.println("m1");}static synchronized void m2() {System.out.println("m2");}final Object lock = new Object();void doLock() {synchronized (lock) {System.out.println("lock");}}
}
下面是普通方法 m1 的字节码。
synchronized void m1();descriptor: ()Vflags: ACC_SYNCHRONIZEDCode:stack=2, locals=1, args_size=10: getstatic #4 3: ldc #5 5: invokevirtual #6 8: return
可以看到,在字节码的体现上,它只给方法加了一个 flag:ACC_SYNCHRONIZED。
静态方法 m2 和 m1 区别不大,只不过 flags 上多了一个参数:ACC_STATIC。
相比较起来,doLock 方法就麻烦了一些,其中出现了 monitorenter 和 monitorexit 等字节码指令。
void doLock();descriptor: ()Vflags:Code:stack=2, locals=3, args_size=10: aload_01: getfield #3 // Field lock:Ljava/lang/Object;4: dup5: astore_16: monitorenter7: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;10: ldc #8 // String lock12: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V15: aload_116: monitorexit17: goto 2520: astore_221: aload_122: monitorexit23: aload_224: athrow25: returnException table:from to target type7 17 20 any20 23 20 any
很多人都认为,synchronized 是一种悲观锁、一种重量级锁;而基于 CAS 的 AQS 是一种乐观锁,这种理解并不全对。JDK1.6 之后,JVM 对同步关键字进行了很多的优化,这把锁有了不同的状态,大多数情况下的效率,已经和 concurrent 包下的 Lock 不相上下了,甚至更高。
对象内存布局
说到 synchronized 加锁原理,就不得不先说 Java 对象在内存中的布局,Java 对象内存布局如下图所示。
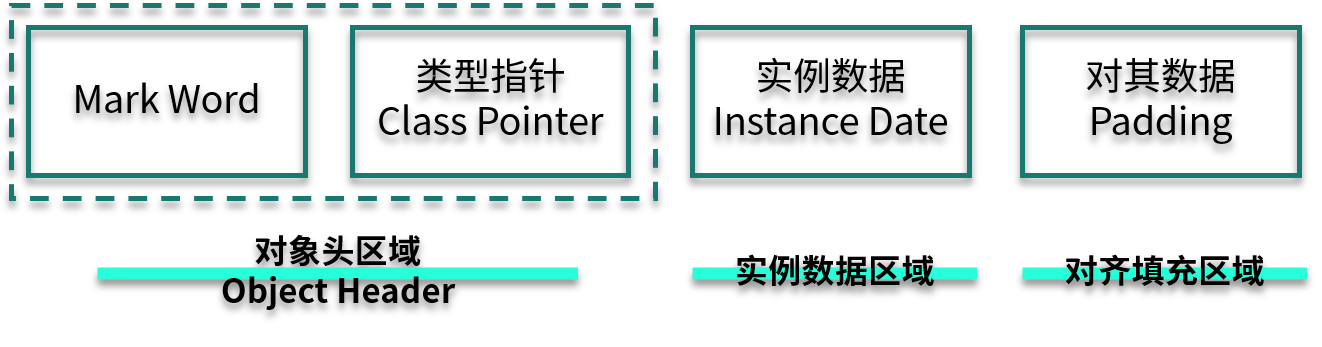
我来分别解释一下各个部分的含义。
Mark Word:用来存储 hashCode、GC 分代年龄、锁类型标记、偏向锁线程 ID、CAS 锁指向线程 LockRecord 的指针等,synconized 锁的机制与这里密切相关,这有点像 TCP/IP 中的协议头。
Class Pointer:用来存储对象指向它的类元数据指针、JVM 就是通过它来确定是哪个 Class 的实例。
Instance Data:存储的是对象真正有效的信息,比如对象中所有字段的内容。
Padding:HostSpot 规定对象的起始地址必须是 8 字节的整数倍,这是为了高效读取对象而做的一种“对齐”操作。
可重入锁
synchronized 是一把可重入锁。因此,在一个线程使用 synchronized 方法时可以调用该对象的另一个 synchronized 方法,即一个线程得到一个对象锁后再次请求该对象锁,是可以永远拿到锁的。
Java 中线程获得对象锁的操作是以线程而不是以调用为单位的。synchronized 锁的对象头的 Mark Work 中会记录该锁的线程持有者和计数器。当一个线程请求成功后,JVM 会记下持有锁的线程,并将计数器计为 1 。此时如果有其他线程请求该锁,则必须等待。而该持有锁的线程如果再次请求这个锁,就可以再次拿到这个锁,同时计数器会递增。当线程退出一个 synchronized 方法/块时,计数器会递减,如果计数器为 0 则释放该锁。
锁升级
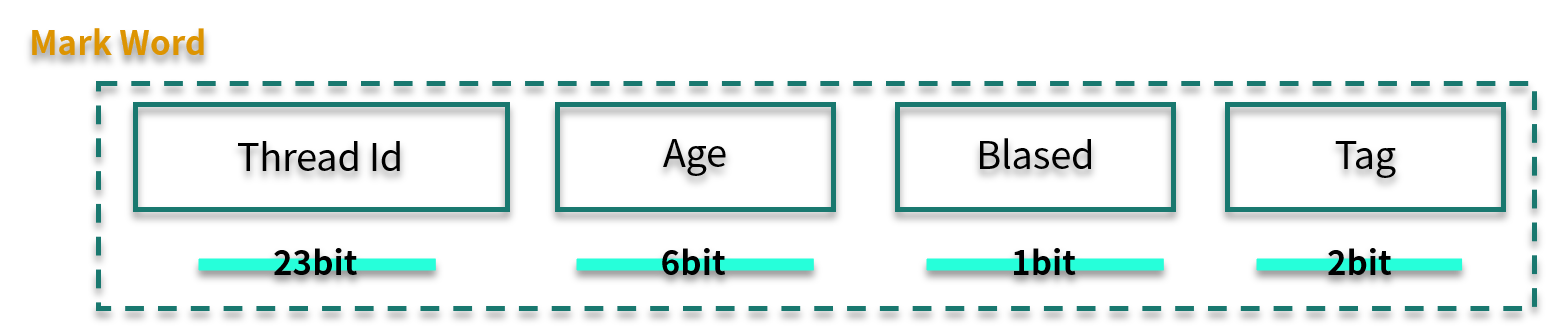
根据使用情况,锁升级大体可以按照下面的路径:偏向锁→轻量级锁→重量级锁,锁只能升级不能降级,所以一旦锁升级为重量级锁,就只能依靠操作系统进行调度。
我们再看一下 Mark Word 的结构。其中,Biased 有 1 bit 大小,Tag 有 2 bit 大小,锁升级就是通过 Thread Id、Biased、Tag 这三个变量值来判断的。
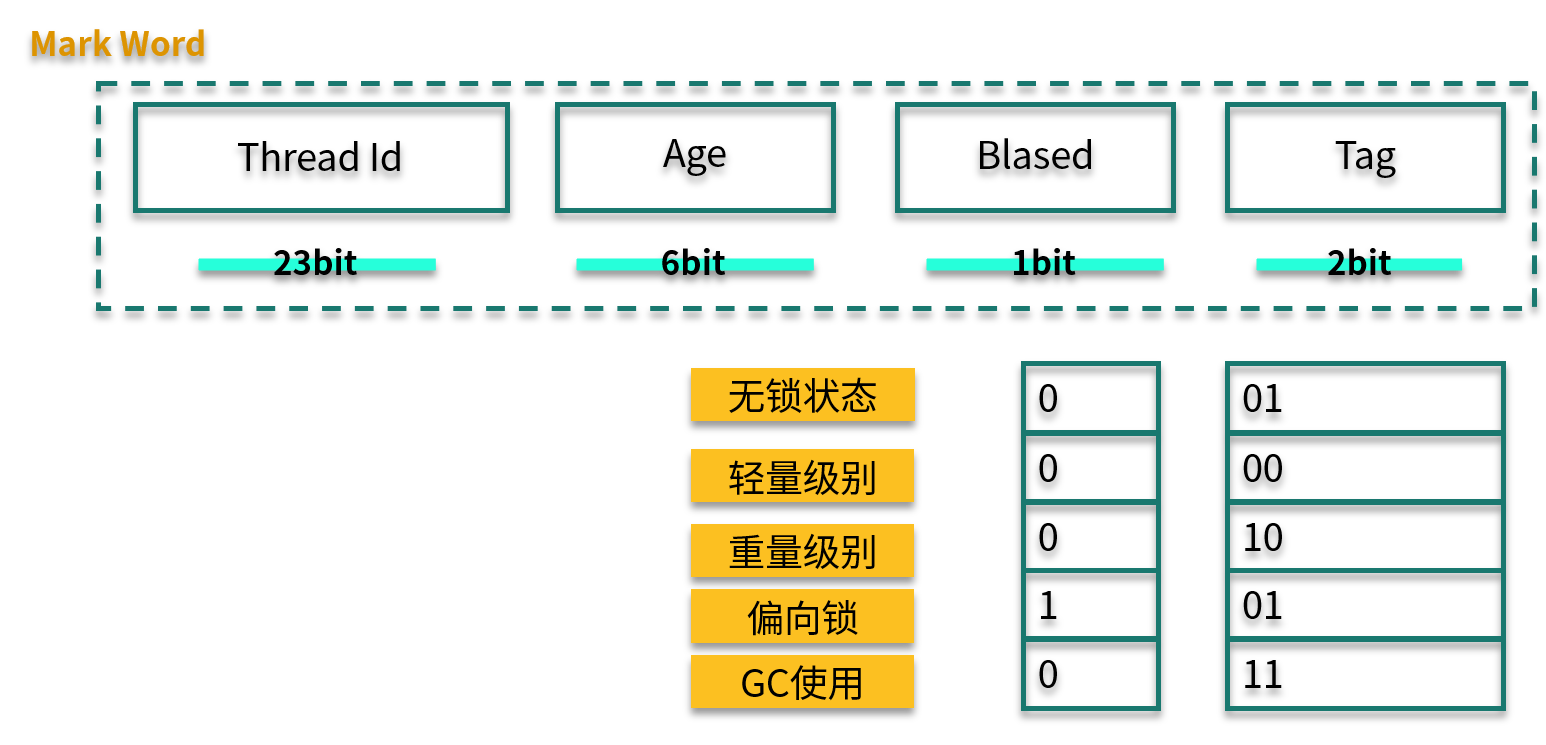
偏向锁
偏向锁,其实是一把偏心锁(一般不这么描述)。在 JVM 中,当只有一个线程使用了锁的情况下,偏向锁才能够保证更高的效率。
当第 1 个线程第一次访问同步块时,会先检测对象头 Mark Word 中的标志位(Tag)是否为 01,以此来判断此时对象锁是否处于无锁状态或者偏向锁状态(匿名偏向锁)。
这也是锁默认的状态,线程一旦获取了这把锁,就会把自己的线程 ID 写到 Mark Word 中,在其他线程来获取这把锁之前,该线程都处于偏向锁状态。
轻量级锁
当下一个线程参与到偏向锁竞争时,会先判断 Mark Word 中保存的线程 ID 是否与这个线程 ID 相等,如果不相等,则会立即撤销偏向锁,升级为轻量级锁。
轻量级锁的获取是怎么进行的呢?它们使用的是自旋方式。
参与竞争的每个线程,会在自己的线程栈中生成一个 LockRecord ( LR ),然后每个线程通过 CAS(自旋)的操作将锁对象头中的 Mark Work 设置为指向自己的 LR 指针,哪个线程设置成功,就意味着哪个线程获得锁。在这种情况下,JVM 不会依赖内核进行线程调度。
当锁处于轻量级锁的状态时,就不能够再通过简单的对比 Tag 值进行判断了,每次对锁的获取,都需要通过自旋的操作。
当然,自旋也是面向不存在锁竞争的场景,比如一个线程运行完了,另外一个线程去获取这把锁。但如果自旋失败达到一定的次数(JVM 自动管理)时,就会膨胀为重量级锁。
重量级锁
重量级锁即为我们对 synchronized 的直观认识,在这种情况下,线程会挂起,进入到操作系统内核态,等待操作系统的调度,然后再映射回用户态。系统调用是昂贵的,重量级锁的名称也由此而来。
如果系统的共享变量竞争非常激烈,那么锁会迅速膨胀到重量级锁,这些优化也就名存实亡了。如果并发非常严重,则可以通过参数 -XX:-UseBiasedLocking 禁用偏向锁。这种方法在理论上会有一些性能提升,但实际上并不确定。
因为,synchronized 在 JDK,包括一些框架代码中的应用是非常广泛的。在一些不需要同步的场景中,即使加上了 synchronized 关键字,由于锁升级的原因,效率也不会太差。
下面这张图展示了三种锁的状态和 Mark Word 值的变化。
小结
在本课时中,我们首先介绍了多线程的一些特点,然后熟悉了 Java 中的线程和它在操作系统中的一些表现形式;还了解了,线程上下文切换会严重影响系统的性能,所以 Java 的锁有基于硬件 CAS 自旋,也有基于比较轻量级的“轻量级锁”和“偏向锁”。
它们的目标是,在不改变编程模型的基础上,尽量提高系统的性能,进行更加高效的并发。
第20讲:动手实践:不为人熟知的字节码指令
本课时我们主要分享一个实践案例:不为人熟知的字节码指令。
下面将通过介绍 Java 语言中的一些常见特性,来看一下字节码的应用,由于 Java 特性非常多,这里我们仅介绍一些经常遇到的特性。javap 是手中的利器,复杂的概念都可以在这里现出原形,并且能让你对此产生深刻的印象。
本课时代码比较多,相关代码示例都可以在仓库中找到,建议实际操作一下。
异常处理
在上一课时中,细心的你可能注意到了,在 synchronized 生成的字节码中,其实包含两条 monitorexit 指令,是为了保证所有的异常条件,都能够退出。
这就涉及到了 Java 字节码的异常处理机制,如下图所示。
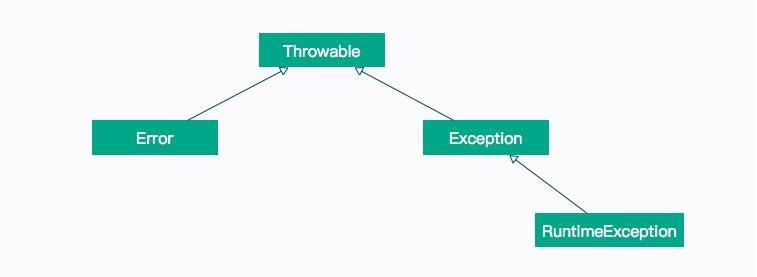
如果你熟悉 Java 语言,那么对上面的异常继承体系一定不会陌生,其中,Error 和 RuntimeException 是非检查型异常(Unchecked Exception),也就是不需要 catch 语句去捕获的异常;而其他异常,则需要程序员手动去处理。
异常表
在发生异常的时候,Java 就可以通过 Java 执行栈,来构造异常栈。回想一下第 02 课时中的栈帧,获取这个异常栈只需要遍历一下它们就可以了。
但是这种操作,比起常规操作,要昂贵的多。Java 的 Log 日志框架,通常会把所有错误信息打印到日志中,在异常非常多的情况下,会显著影响性能。
我们还是看一下上一课时生成的字节码:
void doLock();descriptor: ()Vflags:Code:stack=2, locals=3, args_size=10: aload_01: getfield #3 // Field lock:Ljava/lang/Object;4: dup5: astore_16: monitorenter7: getstatic #4 // Field java/lang/System.out:Ljava/io/PrintStream;10: ldc #8 // String lock12: invokevirtual #6 // Method java/io/PrintStream.println:(Ljava/lang/String;)V15: aload_116: monitorexit17: goto 2520: astore_221: aload_122: monitorexit23: aload_224: athrow25: returnException table:from to target type7 17 20 any20 23 20 any
可以看到,编译后的字节码,带有一个叫 Exception table 的异常表,里面的每一行数据,都是一个异常处理器:
- from 指定字节码索引的开始位置
- to 指定字节码索引的结束位置
- target 异常处理的起始位置
- type 异常类型
也就是说,只要在 from 和 to 之间发生了异常,就会跳转到 target 所指定的位置。
finally
通常我们在做一些文件读取的时候,都会在 finally 代码块中关闭流,以避免内存的溢出。关于这个场景,我们再分析一下下面这段代码的异常表。
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;public class A {public void read() {InputStream in = null;try {in = new FileInputStream("A.java");} catch (FileNotFoundException e) {e.printStackTrace();} finally {if (null != in) {try {in.close();} catch (IOException e) {e.printStackTrace();}}}}
}
上面的代码,捕获了一个 FileNotFoundException 异常,然后在 finally 中捕获了 IOException 异常。当我们分析字节码的时候,却发现了一个有意思的地方:IOException 足足出现了三次。
Exception table:from to target type17 21 24 Class java/io/IOException2 12 32 Class java/io/FileNotFoundException42 46 49 Class java/io/IOException2 12 57 any32 37 57 any63 67 70 Class java/io/IOException
Java 编译器使用了一种比较傻的方式来组织 finally 的字节码,它分别在 try、catch 的正常执行路径上,复制一份 finally 代码,追加在 正常执行逻辑的后面;同时,再复制一份到其他异常执行逻辑的出口处。
这也是下面这段方法不报错的原因,都可以在字节码中找到答案。
//B.java
public int read() {try {int a = 1 / 0;return a;} finally {return 1;}
}
下面是上面程序的字节码,可以看到,异常之后,直接跳转到序号 8 了。
stack=2, locals=4, args_size=10: iconst_11: iconst_02: idiv3: istore_14: iload_15: istore_26: iconst_17: ireturn8: astore_39: iconst_110: ireturnException table:from to target type0 6 8 any
装箱拆箱
在刚开始学习 Java 语言的你,可能会被自动装箱和拆箱搞得晕头转向。Java 中有 8 种基本类型,但鉴于 Java 面向对象的特点,它们同样有着对应的 8 个包装类型,比如 int 和 Integer,包装类型的值可以为 null,很多时候,它们都能够相互赋值。
我们使用下面的代码从字节码层面上来观察一下:
public class Box {public Integer cal() {Integer a = 1000;int b = a * 10;return b;}
}
上面是一段简单的代码,首先使用包装类型,构造了一个值为 1000 的数字,然后乘以 10 后返回,但是中间的计算过程,使用了普通类型 int。
public java.lang.Integer read();descriptor: ()Ljava/lang/Integer;flags: ACC_PUBLICCode:stack=2, locals=3, args_size=10: sipush 10003: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;6: astore_17: aload_18: invokevirtual #3 // Method java/lang/Integer.intValue:()I11: bipush 1013: imul14: istore_215: iload_216: invokestatic #2 // Method java/lang/Integer.valueOf:(I)Ljava/lang/Integer;19: areturn
通过观察字节码,我们发现赋值操作使用的是 Integer.valueOf 方法,在进行乘法运算的时候,调用了 Integer.intValue 方法来获取基本类型的值。在方法返回的时候,再次使用了 Integer.valueOf 方法对结果进行了包装。
这就是 Java 中的自动装箱拆箱的底层实现。
但这里有一个 Java 层面的陷阱问题,我们继续跟踪 Integer.valueOf 方法。
@HotSpotIntrinsicCandidate
public static Integer valueOf(int i) {if (i >= IntegerCache.low && i <= IntegerCache.high)return IntegerCache.cache[i + (-IntegerCache.low)];return new Integer(i);
}
这个 IntegerCache,缓存了 low 和 high 之间的 Integer 对象,可以通过 -XX:AutoBoxCacheMax 来修改上限。
下面是一道经典的面试题,请考虑一下运行代码后,会输出什么结果?
public class BoxCacheError{public static void main(String[] args) {Integer n1 = 123;Integer n2 = 123;Integer n3 = 128;Integer n4 = 128;System.out.println(n1 == n2);System.out.println(n3 == n4);}
当我使用 java BoxCacheError 执行时,是 true,false;当我加上参数 java -XX:AutoBoxCacheMax=256 BoxCacheError 执行时,结果是 true,ture,原因就在于此。
数组访问
我们都知道,在访问一个数组长度的时候,直接使用它的属性 .length 就能获取,而在 Java 中却无法找到对于数组的定义。
比如 int[] 这种类型,通过 getClass(getClass 是 Object 类中的方法)可以获取它的具体类型是 [I。
其实,数组是 JVM 内置的一种对象类型,这个对象同样是继承的 Object 类。
我们使用下面一段代码来观察一下数组的生成和访问。
public class ArrayDemo {int getValue() {int[] arr = new int[]{1111, 2222, 3333, 4444};return arr[2];}int getLength(int[] arr) {return arr.length;}
}
首先看一下 getValue 方法的字节码。
int getValue();descriptor: ()Iflags:Code:stack=4, locals=2, args_size=10: iconst_41: newarray int3: dup4: iconst_05: sipush 11118: iastorae9: dup10: iconst_111: sipush 222214: iastore15: dup16: iconst_217: sipush 333320: iastore21: dup22: iconst_323: sipush 444426: iastore27: astore_128: aload_129: iconst_230: iaload31: ireturn
可以看到,新建数组的代码,被编译成了 newarray 指令。数组里的初始内容,被顺序编译成了一系列指令放入:
- sipush 将一个短整型常量值推送至栈顶;
- iastore 将栈顶 int 型数值存入指定数组的指定索引位置。
为了支持多种类型,从操作数栈存储到数组,有更多的指令:bastore、castore、sastore、iastore、lastore、fastore、dastore、aastore。
数组元素的访问,是通过第 28 ~ 30 行代码来实现的:
- aload_1 将第二个引用类型本地变量推送至栈顶,这里是生成的数组;
- iconst_2 将 int 型 2 推送至栈顶;
- iaload 将 int 型数组指定索引的值推送至栈顶。
值得注意的是,在这段代码运行期间,有可能会产生 ArrayIndexOutOfBoundsException,但由于它是一种非捕获型异常,我们不必为这种异常提供异常处理器。
我们再看一下 getLength 的字节码,字节码如下:
int getLength(int[]);descriptor: ([I)Iflags:Code:stack=1, locals=2, args_size=20: aload_11: arraylength2: ireturn
可以看到,获取数组的长度,是由字节码指令 arraylength 来完成的。
foreach
无论是 Java 的数组,还是 List,都可以使用 foreach 语句进行遍历,比较典型的代码如下:
import java.util.List;public class ForDemo {void loop(int[] arr) {for (int i : arr) {System.out.println(i);}}void loop(List<Integer> arr) {for (int i : arr) {System.out.println(i);}}
}
虽然在语言层面它们的表现形式是一致的,但实际实现的方法并不同。我们先看一下遍历数组的字节码:
void loop(int[]);descriptor: ([I)Vflags:Code:stack=2, locals=6, args_size=20: aload_11: astore_22: aload_23: arraylength4: istore_35: iconst_06: istore 48: iload 410: iload_311: if_icmpge 3414: aload_215: iload 417: iaload18: istore 520: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;23: iload 525: invokevirtual #3 // Method java/io/PrintStream.println:(I)V28: iinc 4, 131: goto 834: return
可以很容易看到,它将代码解释成了传统的变量方式,即 for(int i;i 的形式。
而 List 的字节码如下:
void loop(java.util.List<java.lang.Integer>);Code:0: aload_11: invokeinterface #4, 1 // InterfaceMethod java/util/List.iterator:()Ljava/util/Iterator;6: astore_2-7: aload_28: invokeinterface #5, 1 // InterfaceMethod java/util/Iterator.hasNext:()Z13: ifeq 3916: aload_217: invokeinterface #6, 1 // InterfaceMethod java/util/Iterator.next:()Ljava/lang/Object;22: checkcast #7 // class java/lang/Integer25: invokevirtual #8 // Method java/lang/Integer.intValue:()I28: istore_329: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;32: iload_333: invokevirtual #3 // Method java/io/PrintStream.println:(I)V36: goto 739: return
它实际是把 list 对象进行迭代并遍历的,在循环中,使用了 Iterator.next() 方法。
使用 jd-gui 等反编译工具,可以看到实际生成的代码:
void loop(List<Integer> paramList) {for (Iterator<Integer> iterator = paramList.iterator(); iterator.hasNext(); ) {int i = ((Integer)iterator.next()).intValue();System.out.println(i);} }
注解
注解在 Java 中得到了广泛的应用,Spring 框架更是由于注解的存在而起死回生。注解在开发中的作用就是做数据约束和标准定义,可以将其理解成代码的规范标准,并帮助我们写出方便、快捷、简洁的代码。 那么注解信息是存放在哪里的呢?我们使用两个 Java 文件来看一下其中的一种情况。 MyAnnotation.java
public @interface MyAnnotation {
}
AnnotationDemo
@MyAnnotation
public class AnnotationDemo {@MyAnnotationpublic void test(@MyAnnotation int a){}
}
下面我们来看一下字节码信息。
{public AnnotationDemo();descriptor: ()Vflags: ACC_PUBLICCode:stack=1, locals=1, args_size=10: aload_01: invokespecial #1 // Method java/lang/Object."<init>":()V4: returnLineNumberTable:line 2: 0public void test(int);descriptor: (I)Vflags: ACC_PUBLICCode:stack=0, locals=2, args_size=20: returnLineNumberTable:line 6: 0RuntimeInvisibleAnnotations:0: #11()RuntimeInvisibleParameterAnnotations:0:0: #11()
}
SourceFile: "AnnotationDemo.java"
RuntimeInvisibleAnnotations:0: #11()
可以看到,无论是类的注解,还是方法注解,都是由一个叫做 RuntimeInvisibleAnnotations 的结构来存储的,而参数的存储,是由 RuntimeInvisibleParameterAnotations 来保证的。
小结
本课时我们简单介绍了一下工作中常见的一些问题,并从字节码层面分析了它的原理,包括异常的处理、finally 块的执行顺序;以及隐藏的装箱拆箱和 foreach 语法糖的底层实现。
由于 Java 的特性非常多,这里不再一一列出,但都可以使用这种简单的方式,一窥究竟。可以认为本课时属于抛砖引玉,给出了一种学习思路。
另外,也可以对其中的性能和复杂度进行思考。可以注意到,在隐藏的装箱拆箱操作中,会造成很多冗余的字节码指令生成。那么,这个东西会耗性能吗?答案是肯定的,但是也不必纠结于此。
你所看到的字节码指令,可能洋洋洒洒几千行,看起来很吓人,但执行速度几乎都是纳秒级别的。Java 的无数框架,包括 JDK,也不会为了优化这种性能对代码进行限制。了解其原理,但不要舍本逐末,比如减少一次 Java 线程的上下文切换,就比你优化几千个装箱拆箱动作,来的更快捷一些。
第21讲:深入剖析:如何使用JavaAgent技术对字节码进行修改
本课时我们主要分析如何使用 Java Agent 技术对字节码进行修改。
Java 5 版本以后,JDK 有一个包叫做 instrument ,能够实现一些非常酷的功能,市面上一些 APM 工具,就是通过它来进行的增强,这个功能对于业务开发者来说,是比较偏门的。但你可能在无意中已经用到它了,比如 Jrebel 酷炫的热部署功能(这个工具能够显著增加开发效率)。
本课时将以一个例子来看一下具体的应用场景,然后介绍一个在线上常用的问题排查工具:Arthas。
Java Agent 介绍
我们上面说的这些工具的基础,就是 Java Agent 技术,可以利用它来构建一个附加的代理程序,用来协助检测性能,还可以替换一些现有功能,甚至 JDK 的一些类我们也能修改,有点像 JVM 级别的 AOP 功能。
通常,Java 入口是一个 main 方法,这是毋庸置疑的,而 Java Agent 的入口方法叫做 premain,表明是在 main 运行之前的一些操作。Java Agent 就是这样的一个 jar 包,定义了一个标准的入口方法,它并不需要继承或者实现任何其他的类,属于无侵入的一种开发模式。
为什么叫 premain?这是一个约定,并没有什么其他的理由,这个方法,无论是第一次加载,还是每次新的 ClassLoader 加载,都会执行。
我们可以在这个前置的方法里,对字节码进行一些修改,来增加功能或者改变代码的行为,这种方法没有侵入性,只需要在启动命令中加上 -javaagent 参数就可以了。Java 6 以后,甚至可以通过 attach 的方式,动态的给运行中的程序设置加载代理类。
其实,instrument 一共有两个 main 方法,一个是 premain,另一个是 agentmain,但在一个 JVM 中,只会调用一个;前者是 main 执行之前的修改,后者是控制类运行时的行为。它们还是有一些区别的,agentmain 因为能够动态修改大部分代码,比较危险,限制会更大一些。
有什么用
获取统计信息
在许多 APM 产品里,比如 Pinpoint、SkyWalking 等,就是使用 Java Agent 对代码进行的增强。通过在方法执行前后动态加入的统计代码,来进行监控信息的收集;通过兼容 OpenTracing 协议,可以实现分布式链路追踪的功能。
它的原理类似于 AOP,最终以字节码的形式存在,性能损失取决于你的代码逻辑。
热部署
通过自定义的 ClassLoader,可以实现代码的热替换。使用 agentmain,实现热部署功能会更加便捷,通过 agentmain 获取到 Instrumentation 以后,就可以对类进行动态重定义了。
诊断
配合 JVMTI 技术,可以 attach 到某个进程进行运行时的统计和调试,比较流行的 btrace 和 arthas ,其底层就是这种技术。
代码示例
要构建一个 agent 程序,大体可分为以下步骤:
- 使用字节码增强工具,编写增强代码;
- 在 manifest 中指定 Premain-Class/Agent-Class 属性;
- 使用参数加载或者使用 attach 方式。
我们来详细介绍一下这个过程。
编写 Agent
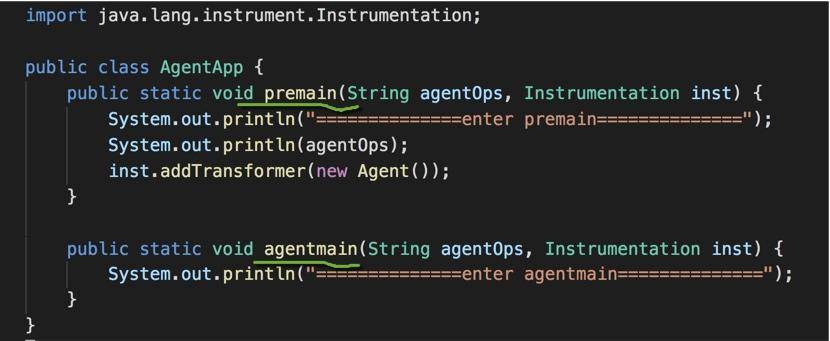
Java Agent 最终的体现方式是一个 jar 包,使用 IDEA 创建一个默认的 maven 工程即可。
创建一个普通的 Java 类,添加 premain 或者 agentmain 方法,它们的参数完全一样。
编写 Transformer
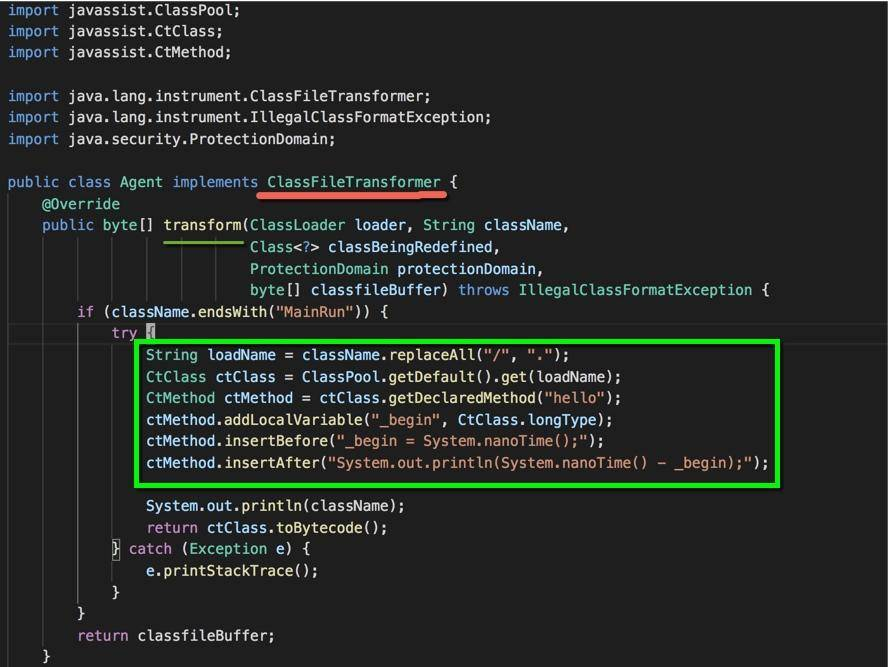
实际的代码逻辑需要实现 ClassFileTransformer 接口。假如我们要统计某个方法的执行时间,使用 JavaAssist 工具来增强字节码,则可以通过以下代码来实现:
- 获取 MainRun 类的字节码实例;
- 获取 hello 方法的字节码实例;
- 在方法前后,加入时间统计,首先定义变量 _begin,然后追加要写的代码。
别忘了加入 maven 依赖,我们借用 javassist 完成字节码增强:
<dependency><groupId>org.javassist</groupId><artifactId>javassist</artifactId><version>3.24.1-GA</version>
</dependency>
字节码增强也可以使用 Cglib、ASM 等其他工具。
MANIFEST.MF 文件
那么我们编写的代码是如何让外界知晓的呢?那就是依靠 MANIFEST.MF 文件,具体路径在
src/main/resources/META-INF/MANIFEST.MF:
Manifest-Version: 1.0
premain-class: com.sayhiai.example.javaagent.AgentApp
一般的,maven 打包会覆盖这个文件,所以我们需要为它指定一个。
<build><plugins><plugin>
<groupId>org.apache.maven.plugins</groupId><artifactId>maven-jar-plugin</artifactId><configuration><archive><manifestFile>src/main/resources/META-INF/MANIFEST.MF</manifestFile></archive></configuration></plugin></plugins></build>
然后,在命令行,执行 mvn install 安装到本地代码库,或者使用 mvn deploy 发布到私服上。
附 MANIFEST.MF 参数清单:
Premain-Class
Agent-Class
Boot-Class-Path
Can-Redefine-Classes
Can-Retransform-Classes
Can-Set-Native-Method-Prefix
使用
使用方式取决于你使用的 premain 还是 agentmain,它们之间有一些区别,具体如下。
premain
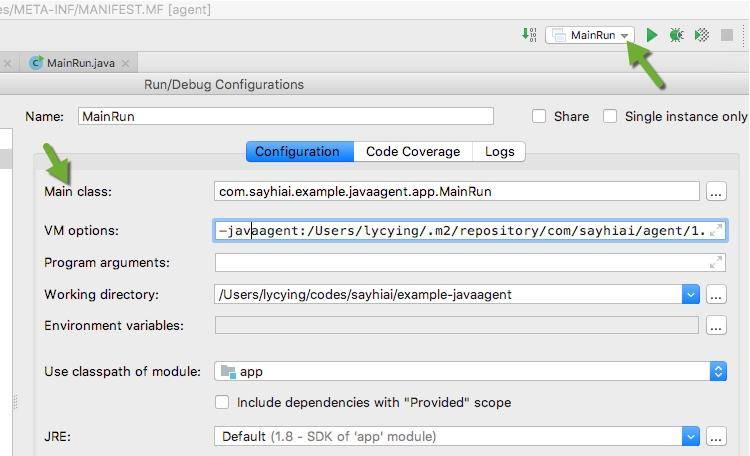
在我们的例子中,直接在启动命令行中加入参数即可,在 jvm 启动时启用代理。
java -javaagent:agent.jar MainRun
在 IDEA 中,可以将参数附着在 jvm options 里。
接下来看一下测试代码。
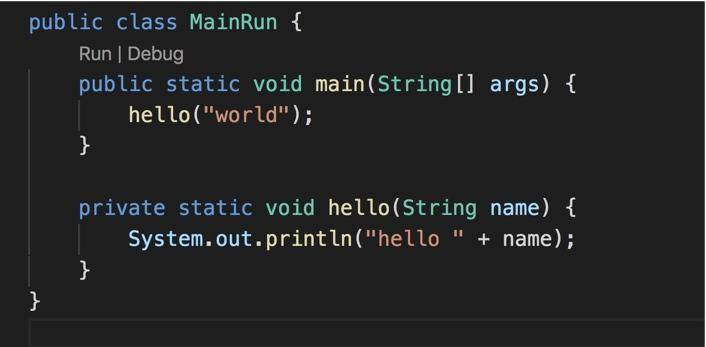
这是我们的执行类,执行后,直接输出 hello world。通过增强以后,还额外的输出了执行时间,以及一些 debug 信息。其中,debug 信息在 main 方法执行之前输出。
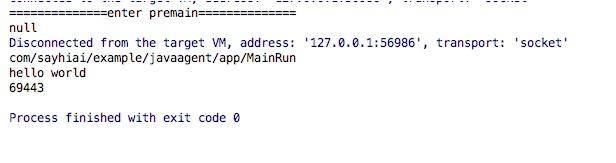
agentmain
这种模式一般用在一些诊断工具上。使用 jdk/lib/tools.jar 中的工具类,可以动态的为运行中的程序加入一些功能。它的主要运行步骤如下:
- 获取机器上运行的所有 JVM 进程 ID;
- 选择要诊断的 jvm;
- 将 jvm 使用 attach 函数链接上;
- 使用 loadAgent 函数加载 agent,动态修改字节码;
- 卸载 jvm。
代码样例如下:
import com.sun.tools.attach.VirtualMachine;
import com.sun.tools.attach.VirtualMachineDescriptor;import java.util.List;public class JvmAttach {public static void main(String[] args)throws Exception {List<VirtualMachineDescriptor> list = VirtualMachine.list();for (VirtualMachineDescriptor vmd : list) {if (vmd.displayName().endsWith("MainRun")) {VirtualMachine virtualMachine = VirtualMachine.attach(vmd.id());virtualMachine.loadAgent("test.jar ", "...");//.....virtualMachine.detach();}}}
}
这些代码功能虽然强大,但都是比较危险的,这就是为什么 Btrace 说了这么多年,还是只在小范围内被小心的使用。相对来说,Arthas 显的友好而且安全的多。
使用注意点
(1)jar 包依赖方式
一般,Agent 的 jar 包会以 fatjar 的方式提供,即将所有的依赖打包到一个大的 jar 包中。如果你的功能复杂、依赖多,那么这个 jar 包将会特别的大。
使用独立的 bom 文件维护这些依赖是另外一种方法。使用方自行管理依赖问题,但这通常会发生一些找不到 jar 包的错误,更糟糕的是,大多数在运行时才发现。
(2)类名称重复
不要使用和 jdk 及 instrument 包中相同的类名(包括包名),有时候你能够侥幸过关,但也会陷入无法控制的异常中。
(3)做有限的功能
可以看到,给系统动态的增加功能是非常酷的,但大多数情况下非常耗费性能。你会发现,一些简单的诊断工具,会占用你 1 核的 CPU,这是很平常的事情。
(4)ClassLoader
如果你用的 JVM 比较旧,频繁地生成大量的代理类,会造成元空间的膨胀,容易发生内存占用问题。
ClassLoader 有双亲委派机制,如果你想要替换相应的类,一定要搞清楚它的类加载器应该用哪个,否则替换的类,是不生效的。
具体的调试方法,可以在 Java 进程启动时,加入 -verbose:class 参数,用来监视引用程序对类的加载。
Arthas
我们来回顾一下在故障排查时所做的一些准备和工具支持。
在第 09 课时,我们了解了 jstat 工具,还有 jmap 等查看内存状态的工具;第 11 课时,介绍了超过 20 个工具的使用,这需要开发和分析的人员具有较高的水平;第 15 课时,还介绍了 jstack 的一些典型状态。对于这种瞬时态问题的分析,需要综合很多工具,对刚进入这个行业的人来说,很不友好。
Arthas 就是使用 Java Agent 技术编写的一个工具,具体采用的方式,就是我们上面提到的 attach 方式,它会无侵入的 attach 到具体的执行进程上,方便进行问题分析。
你甚至可以像 debug 本地的 Java 代码一样,观测到方法执行的参数值,甚至做一些统计分析。这通常可以解决下面的问题:
- 哪个线程使用了最多的 CPU
- 运行中是否有死锁,是否有阻塞
- 如何监测一个方法哪里耗时最高
- 追加打印一些 debug 信息
- 监测 JVM 的实时运行状态
Arthas 官方文档十分详细,也可以点击这里参考。
但无论工具如何强大,一些基础知识是需要牢固掌握的,否则,工具中出现的那些术语,也会让人一头雾水。
工具常变,但基础更加重要。如果你想要一个适应性更强的技术栈,还是要多花点时间在原始的排查方法上。
小结
本课时介绍了开发人员极少接触的 Java Agent 技术,但在平常的工作中你可能不知不觉就用到它了。在平常的面试中,一些面试官也会经常问一些相关的问题,以此来判断你对整个 Java 体系的掌握程度,如果你能回答上来,说明你已经脱颖而出了。
值得注意的是,这个知识点,对于做基础架构(比如中间件研发)的人来说,是必备技能,如果不了解,那面试可能就要凉了。
从实用角度来说,阿里开源的 Arthas 工具,是非常好用的,如果你有线上的运维权限,不妨尝试一下。
第22讲:动手实践:JIT参数配置如何影响程序运行?
本课时我们主要分享一个实践案例,JIT 参数配置是如何影响程序运行的。
我们在前面的课时中介绍了很多字节码指令,这也是 Java 能够跨平台的保证。程序在运行的时候,这些指令会按照顺序解释执行,但是,这种解释执行的方式是非常低效的,它需要把字节码先翻译成机器码,才能往下执行。另外,字节码是 Java 编译器做的一次初级优化,许多代码可以满足语法分析,但还有很大的优化空间。
所以,为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化。完成这个任务的编译器,就称为即时编译器(Just In Time Compiler),简称 JIT 编译器。
热点代码,就是那些被频繁调用的代码,比如调用次数很高或者在 for 循环里的那些代码。这些再次编译后的机器码会被缓存起来,以备下次使用,但对于那些执行次数很少的代码来说,这种编译动作就纯属浪费。
在第 14 课时我们提到了参数“-XX:ReservedCodeCacheSize”,用来限制 CodeCache 的大小。也就是说,JIT 编译后的代码都会放在 CodeCache 里。
如果这个空间不足,JIT 就无法继续编译,编译执行会变成解释执行,性能会降低一个数量级。同时,JIT 编译器会一直尝试去优化代码,从而造成了 CPU 占用上升。
JITWatch
在开始之前,我们首先介绍一个观察 JIT 执行过程的图形化工具:JITWatch,这个工具非常好用,可以解析 JIT 的日志并友好地展示出来。项目地址请点击这里查看。
下载之后,进入解压目录,执行 ant 即可编译出执行文件。
产生 JIT 日志
我们观察下面的一段代码,这段代码没有什么意义,而且写得很烂。在 test 函数中循环 cal 函数 1 千万次,在 cal 函数中,还有一些冗余的上锁操作和赋值操作,这些操作在解释执行的时候,会加重 JVM 的负担。
public class JITDemo {Integer a = 1000;public void setA(Integer a) {this.a = a;}public Integer getA() {return this.a;}public Integer cal(int num) {synchronized (new Object()) {Integer a = getA();int b = a * 10;b = a * 100;return b + num;}}public int test() {synchronized (new Object()) {int total = 0;int count = 100_000_00;for (int i = 0; i < count; i++) {total += cal(i);if (i % 1000 == 0) {System.out.println(i * 1000);}}return total;}}public static void main(String[] args) {JITDemo demo = new JITDemo();int total = demo.test();}
}
在方法执行的时候,我们加上一系列参数,用来打印 JIT 最终生成的机器码,执行命令如下所示:
$JAVA_HOME_13/bin/java -server -XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading -XX:+PrintAssembly -XX:+LogCompilation -XX:LogFile=jitdemo.log JITDemo
执行的过程,会输入到 jitdemo.log 文件里,接下来我们分析这个文件。
使用
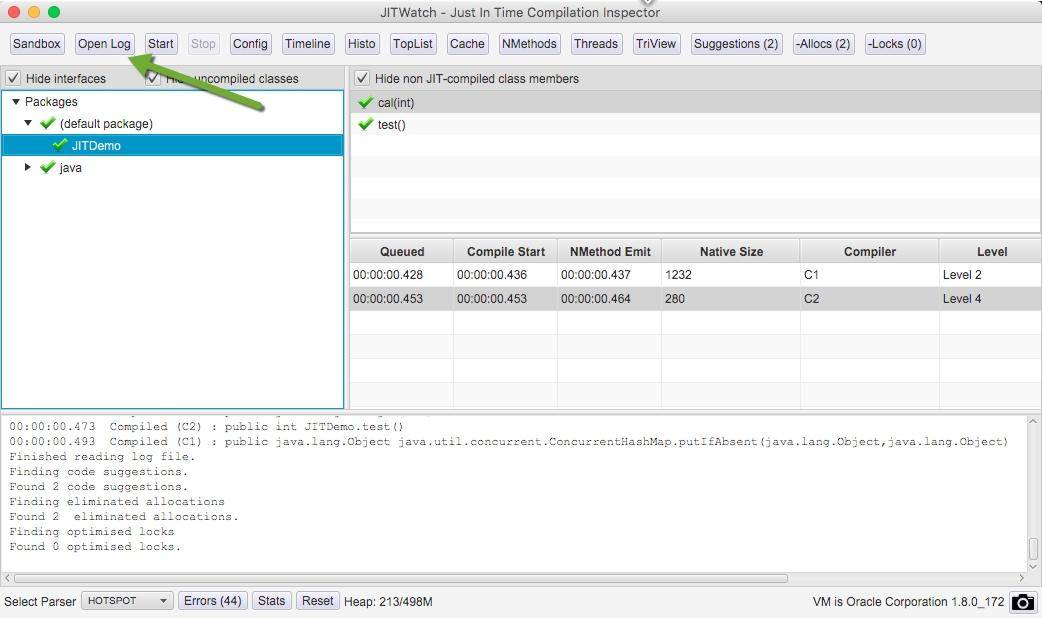
单击 open log 按钮,打开我们生成的日志文件。
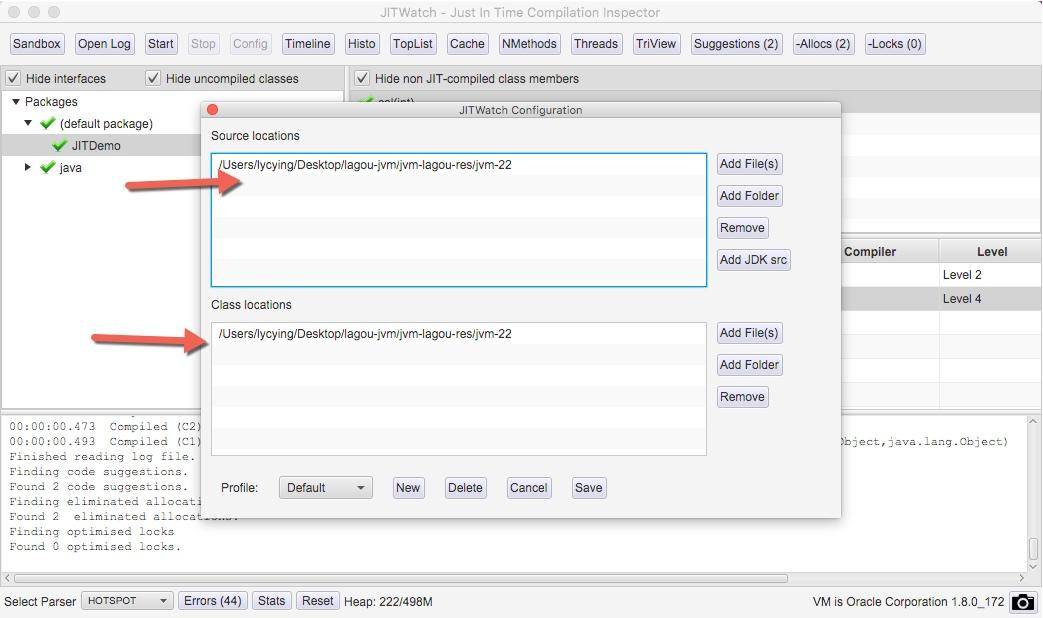
单击 config 按钮,加入要分析的源代码目录和字节码目录。确认后,单击 start 按钮进行分析。
在右侧找到我们的 test 方法,聚焦光标后,将弹出我们要分析的主要界面。
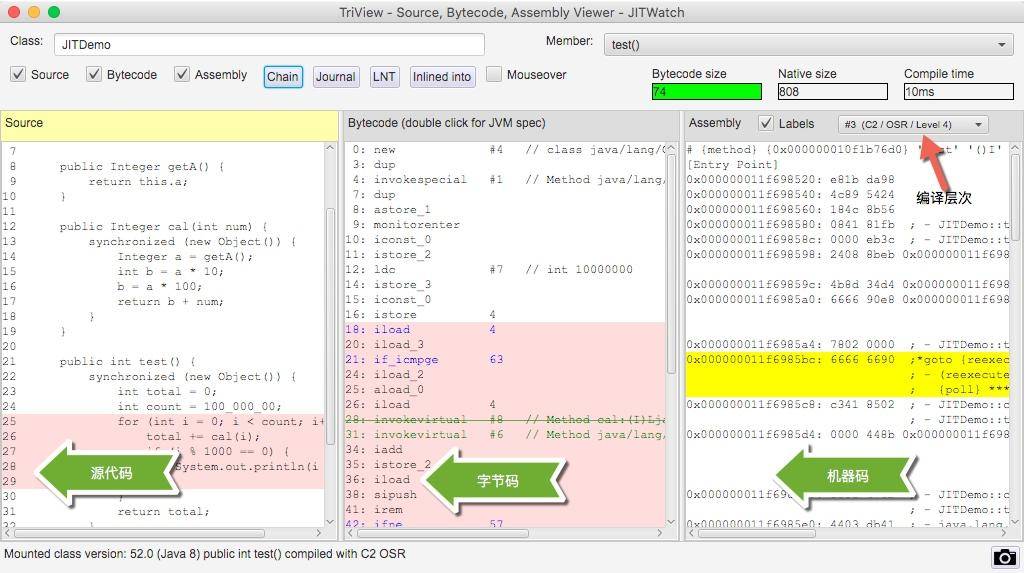
在同一个界面上,我们能够看到源代码、字节码、机器码的对应关系。在右上角,还有 C2/OSR/Level4 这样的字样,可以单击切换。
单击上图中的 Chain 按钮,还会弹出一个依赖链界面,该界面显示了哪些方法已经被编译了、哪些被内联、哪些是通过普通的方法调用运行的。
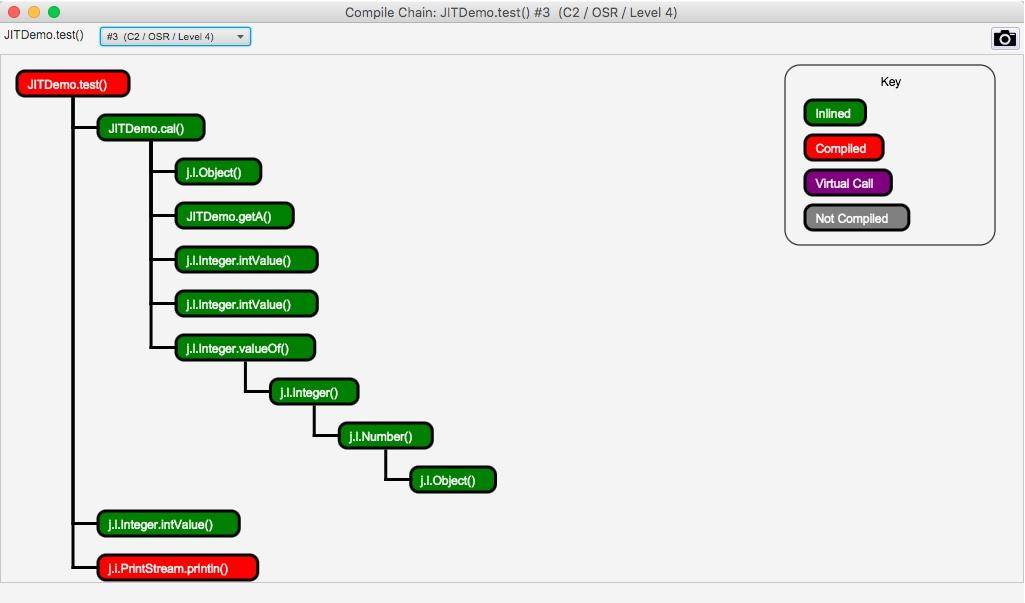
使用 JITWatch 可以看到,调用了 1 千万次的 for 循环代码,已经被 C2 进行编译了。
编译层次
HotSpot 虚拟机包含多个即时编译器,有 C1、C2 和 Graal,采用的是分层编译的模式。使用 jstack 获得的线程信息,经常能看到它们的身影。
实验性质的 Graal 可以通过追加 JVM 参数进行开启,命令行如下:
$JAVA_HOME_13/bin/java -server -XX:+UnlockDiagnosticVMOptions -XX:+TraceClassLoading-XX:+PrintAssembly -XX:+LogCompilation -XX:+UnlockExperimentalVMOptions-XX:+UseJVMCICompiler -XX:LogFile=jitdemo.log JITDemo
不同层次的编译器会产生不一样的效果,机器码也会不同,我们仅看 C1、C2 的一些特点。
JIT 编译方式有两种:一种是编译方法,另一种是编译循环。分层编译将 JVM 的执行状态分为了五个层次:
- 字节码的解释执行;
- 执行不带 profiling 的 C1 代码;
- 执行仅带方法调用次数,以及循环执行次数 profiling 的 C1 代码;
- 执行带所有 profiling 的 C1 代码;
- 执行 C2 代码。
其中,profiling 指的是运行时的程序执行状态数据,比如循环调用的次数、方法调用的次数、分支跳转次数、类型转换次数等。JDK 中的 hprof 工具就是一种 profiler。
在不启用分层编译的情况下,当方法的调用次数和循环回边的次数总和,超过由参数 -XX:CompileThreshold 指定的阈值时,便会触发即时编译;当启用分层编译时,这个参数将会失效,会采用动态调整的方式进行。
常见的优化方法有以下几种:
- 公共子表达式消除
- 数组范围检查消除
- 方法内联
- 逃逸分析
我们重点看一下方法内联和逃逸分析。
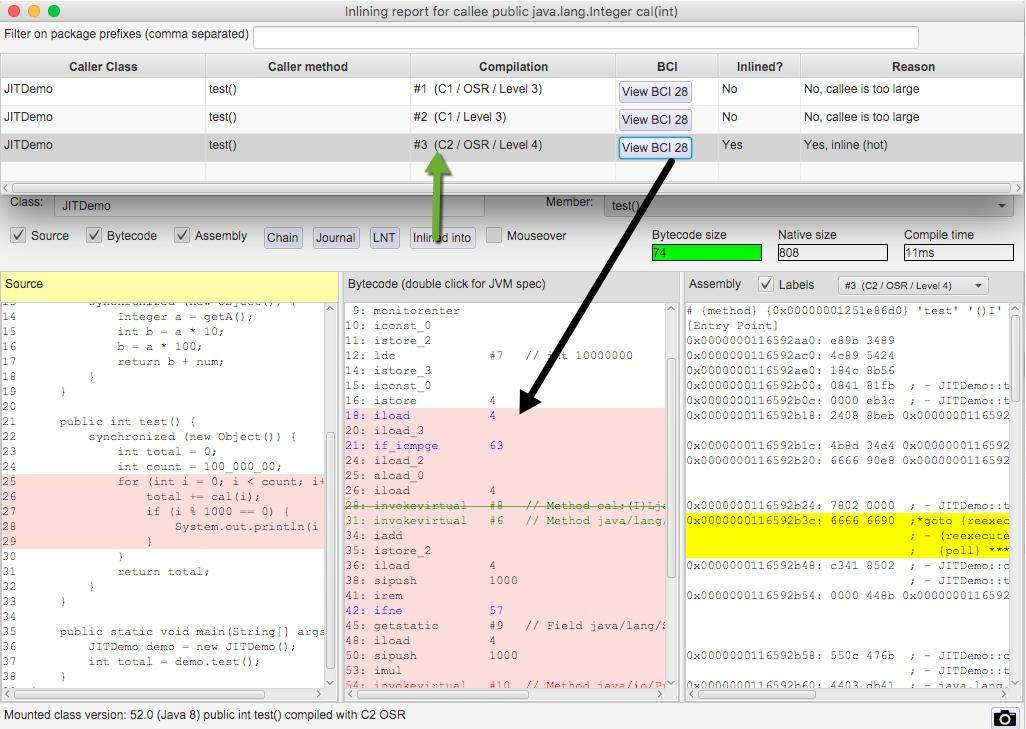
方法内联
在第 17 课时里,我们可以看到方法调用的开销是比较大的,尤其是在调用量非常大的情况下。拿简单的 getter/setter 方法来说,这种方法在 Java 代码中大量存在,我们在访问的时候,需要创建相应的栈帧,访问到需要的字段后,再弹出栈帧,恢复原程序的执行。
如果能够把这些对象的访问和操作,纳入到目标方法的调用范围之内,就少了一次方法调用,速度就能得到提升,这就是方法内联的概念。
C2 编译器会在解析字节码的过程中完成方法内联。内联后的代码和调用方法的代码,会组成新的机器码,存放在 CodeCache 区域里。
在 JDK 的源码里,有很多被 @ForceInline 注解的方法,这些方法会在执行的时候被强制进行内联;而被 @DontInline 注解的方法,则始终不会被内联,比如下面的一段代码。
java.lang.ClassLoader 的 getClassLoader 方法将会被强制内联。
@CallerSensitive
@ForceInline // to ensure Reflection.getCallerClass optimization
public ClassLoader getClassLoader() {ClassLoader cl = getClassLoader0();if (cl == null) return null;SecurityManager sm = System.getSecurityManager();if (sm != null) {ClassLoader.checkClassLoaderPermission(cl, Reflection.getCallerClass());}return cl;
}
方法内联的过程是非常智能的,内联后的代码,会按照一定规则进行再次优化。最终的机器码,在保证逻辑正确的前提下,可能和我们推理的完全不一样。在非常小的概率下,JIT 会出现 Bug,这时候可以关闭问题方法的内联,或者直接关闭 JIT 的优化,保持解释执行。实际上,这种 Bug 我从来没碰到过。
-XX:CompileCommand=exclude,com/lagou/Test,test
上面的参数,表示 com.lagou.Test 的 test 方法将不会进行 JIT 编译,一直解释执行。
另外,C2 支持的内联层次不超过 9 层,太高的话,CodeCache 区域会被挤爆,这个阈值可以通过 -XX:MaxInlineLevel 进行调整。相似的,编译后的代码超过一定大小也不会再内联,这个参数由 -XX:InlineSmallCode 进行调整。
有非常多的参数,被用来控制对内联方法的选择,整体来说,短小精悍的小方法更容易被优化。
这和我们在日常中的编码要求是一致的:代码块精简,逻辑清晰的代码,更容易获得优化的空间。
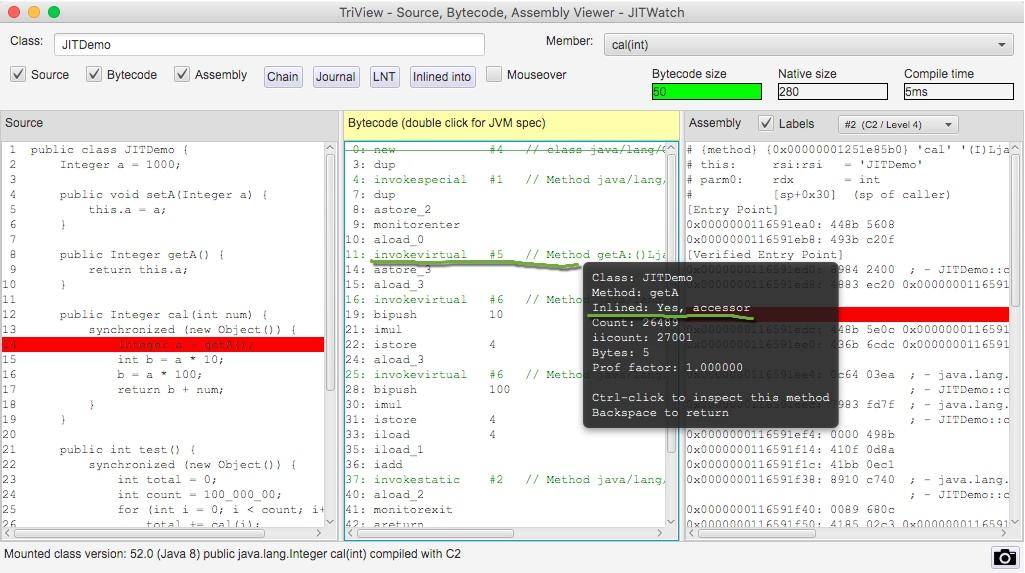
我们使用 JITWatch 再看一下对于 getA() 方法的调用,将鼠标悬浮在字节码指令上,可以看到方法已经被内联了。
逃逸分析
逃逸分析(Escape Analysis)是目前 JVM 中比较前沿的优化技术。通过逃逸分析,JVM 能够分析出一个新的对象使用范围,从而决定是否要将这个对象分配到堆上。
使用 -XX:+DoEscapeAnalysis 参数可以开启逃逸分析,逃逸分析现在是 JVM 的默认行为,这个参数可以忽略。
JVM 判断新创建的对象是否逃逸的依据有:
- 对象被赋值给堆中对象的字段和类的静态变量;
- 对象被传进了不确定的代码中去运行。
举个例子,在代码 1 中,虽然 map 是一个局部变量,但是它通过 return 语句返回,其他外部方法可能会使用它,这就是方法逃逸。另外,如果被其他线程引用或者赋值,则成为线程逃逸。
代码 2,用完 Map 之后就直接销毁了,我们就可以说 map 对象没有逃逸。
代码1:
public Map fig() {Map map = new HashMap();...return map;
}
代码2:
public void fig(){Map map = new HashMap();...
}
那逃逸分析有什么好处呢?
- 同步省略,如果一个对象被发现只能从一个线程被访问到,那么对于这个对象的操作可以不考虑同步。
- 栈上分配,如果一个对象在子程序中被分配,那么指向该对象的指针永远不会逃逸,对象有可能会被优化为栈分配。
- 分离对象或标量替换,有的对象可能不需要作为一个连续的内存结构存在也可以被访问到,那么对象的部分(或全部)可以不存储在内存,而是存储在 CPU 寄存器中。标量是指无法再分解的数据类型,比如原始数据类型及 reference 类型。
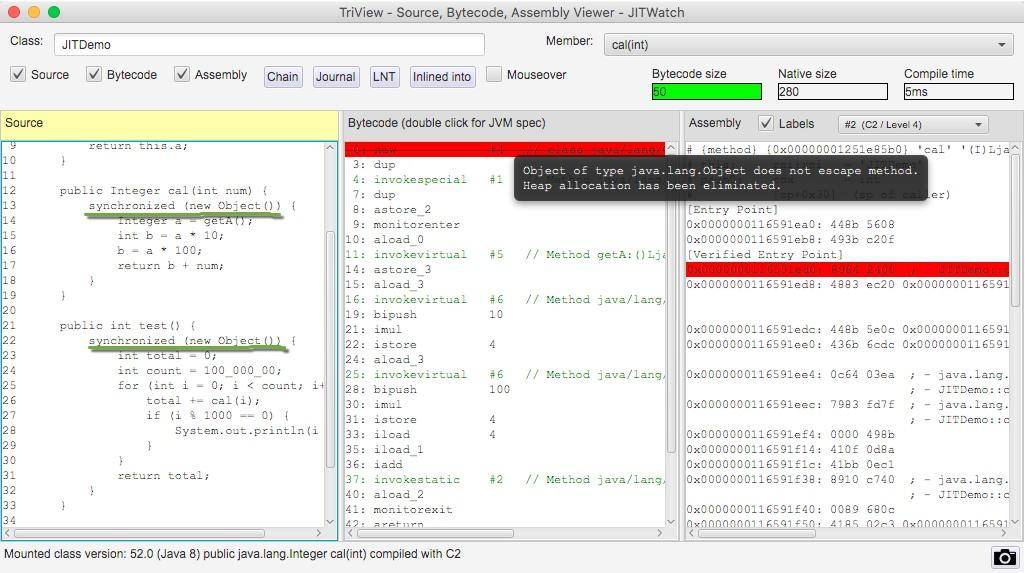
再来看一下 JITWatch 对 synchronized 代码块的分析。根据提示,由于逃逸分析了解到新建的锁对象 Object 并没有逃逸出方法 cal,它将会在栈上直接分配。
查看 C2 编译后的机器码,发现并没有同步代码相关的生成。这是因为 JIT 在分析之后,发现针对 new Object() 这个对象并没有发生线程竞争的情况,则会把这部分的同步直接给优化掉。我们在代码层次做了一些无用功,字节码无法发现它,而 JIT 智能地找到了它并进行了优化。
因此,并不是所有的对象或者数组都会在堆上分配。由于 JIT 的存在,如果发现某些对象没有逃逸出方法,那么就有可能被优化成栈分配。
intrinsic
另外一个不得不提的技术点那就是 intrinsic,这来源于一道面试题:为什么 String 类的 indexOf 方法,比我们使用相同代码实现的方法,执行效率要高得多?
在翻看 JDK 的源码时,能够看到很多地方使用了 HotSpotIntrinsicCandidate 注解。比如 StringBuffer 的 append 方法:
@Override
@HotSpotIntrinsicCandidate
public synchronized StringBuffer append(char c) {toStringCache = null;super.append(c);return this;
}
被 @HotSpotIntrinsicCandidate 标注的方法,在 HotSpot 中都有一套高效的实现,该高效实现基于 CPU 指令,运行时,HotSpot 维护的高效实现会替代 JDK 的源码实现,从而获得更高的效率。
上面的问题中,我们往下跟踪实现,可以发现 StringLatin1 类中的 indexOf 方法,同样适用了 HotSpotIntrinsicCandidate 注解,原因也就在于此。
@HotSpotIntrinsicCandidate
public static int indexOf(byte[] value, byte[] str) {if (str.length == 0) {return 0;}if (value.length == 0) {return -1;}return indexOf(value, value.length, str, str.length, 0);
}@HotSpotIntrinsicCandidate
public static int indexOf(byte[] value, int valueCount, byte[] str, int strCount, int fromIndex) {byte first = str[0];
}
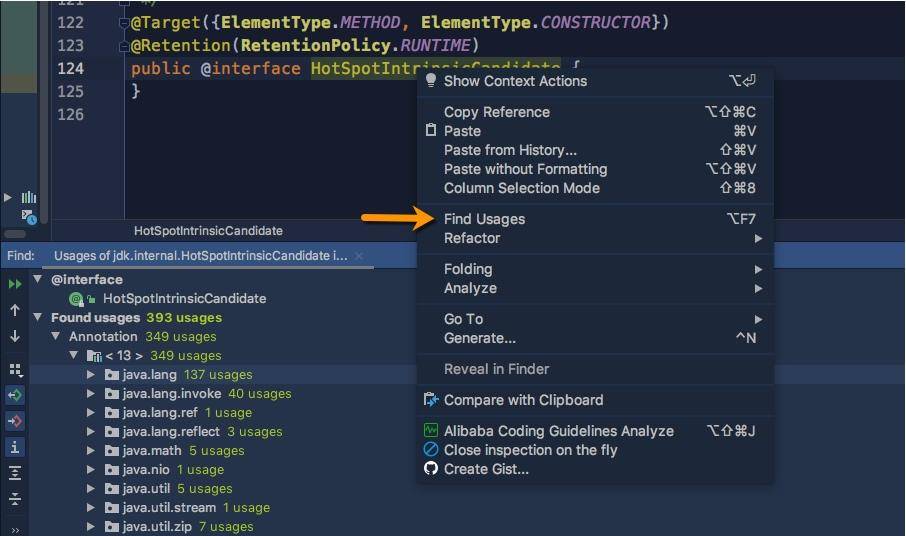
JDK 中这种方法有接近 400 个,可以在 IDEA 中使用 Find Usages 找到它们。
小结
JIT 是现代 JVM 主要的优化点,能够显著地增加程序的执行效率,从解释执行到最高层次的 C2,一个数量级的性能提升也是有可能的。但即时编译的过程是非常缓慢的,耗时间也费空间,所以这些优化操作会和解释执行同时进行。
一般,方法首先会被解释执行,然后被 3 层的 C1 编译,最后被 4 层的 C2 编译,这个过程也不是一蹴而就的。
常用的优化手段,有公共子表达式消除、数组范围检查消除、方法内联、逃逸分析等。
其中,方法内联通过将短小精悍的代码融入到调用方法的执行逻辑里,来减少方法调用上的开支;逃逸分析通过分析变量的引用范围,对象可能会使用栈上分配的方式来减少 GC 的压力,或者使用标量替换来获取更多的优化。
这个过程的执行细节并不是那么“确定”,在不同的 JVM 中,甚至在不同的 HotSpot 版本中,效果也不尽相同。
使用 JITWatch 工具,能够看到字节码和机器码的对应关系,以及执行过程中的一系列优化操作。若想要了解这个工具的更多功能,可以点击这里参考 wiki。
第23讲:案例分析:大型项目如何进行性能瓶颈调优?
本课时我们主要分享一个实践案例,即大型项目如何进行性能瓶颈调优,这也是对前面所学的知识进行总结。
性能调优是一个比较大且比较模糊的话题。在大型项目中,既有分布式的交互式调优问题,也有纯粹的单机调优问题。由于我们的课程主要讲解 JVM 相关的知识点,重点关注 JVM 的调优、故障或者性能瓶颈方面的问题排查,所以对于分布式应用中的影响因素,这里不过多介绍。
优化层次
下面是我总结的一张关于优化层次的图,箭头表示优化时需考虑的路径,但也不总是这样。当一个系统出现问题的时候,研发一般不会想要立刻优化 JVM,或者优化操作系统,会尝试从最高层次上进行问题的解决:解决最主要的瓶颈点。
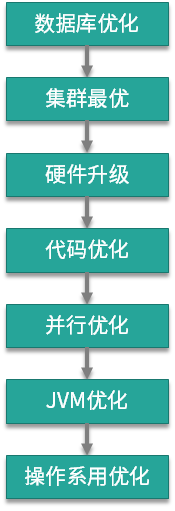
数据库优化: 数据库是最容易成为瓶颈的组件,研发会从 SQL 优化或者数据库本身去提高它的性能。如果瓶颈依然存在,则会考虑分库分表将数据打散,如果这样也没能解决问题,则可能会选择缓存组件进行优化。这个过程与本课时相关的知识点,可以使用 jstack 获取阻塞的执行栈,进行辅助分析。
集群最优:存储节点的问题解决后,计算节点也有可能发生问题。一个集群系统如果获得了水平扩容的能力,就会给下层的优化提供非常大的时间空间,这也是弹性扩容的魅力所在。我接触过一个服务,由最初的 3 个节点,扩容到最后的 200 多个节点,但由于人力问题,服务又没有什么新的需求,下层的优化就一直被搁置着。
硬件升级:水平扩容不总是有效的,原因在于单节点的计算量比较集中,或者 JVM 对内存的使用超出了宿主机的承载范围。在动手进行代码优化之前,我们会对节点的硬件配置进行升级。升级容易,降级难,降级需要依赖代码和调优层面的优化。
代码优化:出于成本的考虑,上面的这些问题,研发团队并不总是坐视不管。代码优化是提高性能最有效的方式,但需要收集一些数据,这个过程可能是服务治理,也有可能是代码流程优化。我在第 21 课时介绍的 JavaAgent 技术,会无侵入的收集一些 profile 信息,供我们进行决策。像 Sonar 这种质量监控工具,也可以在此过程中帮助到我们。
并行优化:并行优化的对象是这样一种接口,它占用的资源不多,计算量也不大,就是速度太慢。所以我们通常使用 ContDownLatch 对需要获取的数据进行并行处理,效果非常不错,比如在 200ms 内返回对 50 个耗时 100ms 的下层接口的调用。
JVM 优化:虽然对 JVM 进行优化,有时候会获得巨大的性能提升,但在 JVM 不发生问题时,我们一般不会想到它。原因就在于,相较于上面 5 层所达到的效果来说,它的优化效果有限。但在代码优化、并行优化、JVM 优化的过程中,JVM 的知识却起到了关键性的作用,是一些根本性的影响因素。
操作系统优化:操作系统优化是解决问题的杀手锏,比如像 HugePage、Luma、“CPU 亲和性”这种比较底层的优化。但就计算节点来说,对操作系统进行优化并不是很常见。运维在背后会做一些诸如文件句柄的调整、网络参数的修改,这对于我们来说就已经够用了。
虽然本课程是针对比较底层的 JVM,但我还是想谈一下一个研发对技术体系的整体演进方向。
首先,掌握了比较底层、基础的东西后,在了解一些比较高层的设计时,就能花更少的时间,这方面的知识有:操作系统、网络、多线程、编译原理,以及一门感兴趣的开发语言。对 Java 体系来说,毫无疑问就是 Java 语言和 JVM。
其次,知识体系还要看实用性,比如你熟知编译原理,虽然 JIT 很容易入门,但如果不做相关的开发,这并没有什么实际作用。
最后,现代分布式系统在技术上总是一个权衡的结果(比如 CAP)。在分析一些知识点和面试题的时候,也要看一下哪些是权衡的结果,哪些务必是准确的。整体上达到次优,局部上达到最优,就是我们要追寻的结果。
代码优化、JVM 的调优,以及单机的故障排查,就是一种局部上的寻优过程,也是一个合格的程序员必须要掌握的技能。
JVM 调优
由于 JVM 一直处在变化之中,所以一些参数的配置并不总是有效的,有时候你加入一个参数,“感觉上”运行速度加快了,但通过
-XX:+PrintFlagsFinal 来查看,却发现这个参数默认就是这样,比如第 10 课时提到的 UseAdaptiveSizePolicy。所以,在不同的 JVM 版本上,不同的垃圾回收器上,要先看一下这个参数默认是什么,不要轻信他人的建议。
java -XX:+PrintFlagsFinal -XX:+UseG1GC 2>&1 | grep UseAdaptiveSizePolicy
内存区域大小
首先要调整的,就是各个分区的大小,不过这也要分垃圾回收器,我们来看一些全局参数及含义。
- -XX:+UseG1GC:用于指定 JVM 使用的垃圾回收器为 G1,尽量不要靠默认值去保证,要显式的指定一个。
- -Xmx:设置堆的最大值,一般为操作系统的 2⁄3 大小。
- -Xms:设置堆的初始值,一般设置成和 Xmx 一样的大小来避免动态扩容。
- -Xmn:表示年轻代的大小,默认新生代占堆大小的 1/3。高并发、对象快消亡场景可适当加大这个区域,对半,或者更多,都是可以的。但是在 G1 下,就不用再设置这个值了,它会自动调整。
- -XX:MaxMetaspaceSize:用于限制元空间的大小,一般 256M 足够了,这一般和初始大小 -XX:MetaspaceSize 设置成一样的。
- -XX:MaxDirectMemorySize:用于设置直接内存的最大值,限制通过 DirectByteBuffer 申请的内存。
- -XX:ReservedCodeCacheSize:用于设置 JIT 编译后的代码存放区大小,如果观察到这个值有限制,可以适当调大,一般够用即可。
- -Xss:用于设置栈的大小,默认为 1M,已经足够用了。
内存调优
- -XX:+AlwaysPreTouch:表示在启动时就把参数里指定的内存全部初始化,启动时间会慢一些,但运行速度会增加。
- -XX:SurvivorRatio:默认值为 8,表示伊甸区和幸存区的比例。
- -XX:MaxTenuringThreshold:这个值在 CMS 下默认为 6,G1 下默认为 15,这个值和我们前面提到的对象提升有关,改动效果会比较明显。对象的年龄分布可以使用 -XX:+PrintTenuringDistribution 打印,如果后面几代的大小总是差不多,证明过了某个年龄后的对象总能晋升到老生代,就可以把晋升阈值设小。
- PretenureSizeThreshold:表示超过一定大小的对象,将直接在老年代分配,不过这个参数用的不是很多。
其他容量的相关参数可以参考其他课时,但不建议随便更改。
垃圾回收器优化
接下来看一下主要的垃圾回收器。
CMS 垃圾回收器
- -XX:+UseCMSInitiatingOccupancyOnly:这个参数需要加上 -XX:CMSInitiatingOccupancyFraction,注意后者需要和前者一块配合才能完成工作,它们指定了 MajorGC 的发生时机。
- -XX:ExplicitGCInvokesConcurrent:当代码里显示调用了 System.gc(),实际上是想让回收器进行 FullGC,如果发生这种情况,则使用这个参数开始并行 FullGC,建议加上这个参数。
- -XX:CMSFullGCsBeforeCompaction:这个参数的默认值为 0,代表每次 FullGC 都对老生代进行碎片整理压缩,建议保持默认。
- -XX:CMSScavengeBeforeRemark:表示开启或关闭在 CMS 重新标记阶段之前的清除(YGC)尝试,它可以降低 remark 时间,建议加上。
- -XX:+ParallelRefProcEnabled:可以用来并行处理 Reference,以加快处理速度,缩短耗时,具体用法见第 15 课时。
G1 垃圾回收器
- -XX:MaxGCPauseMillis:用于设置目标停顿时间,G1 会尽力达成。
- -XX:G1HeapRegionSize:用于设置小堆区大小,这个值为 2 的次幂,不要太大,也不要太小,如果实在不知道如何设置,建议保持默认。
- -XX:InitiatingHeapOccupancyPercent:表示当整个堆内存使用达到一定比例(默认是 45%),并发标记阶段 就会被启动。
- -XX:ConcGCThreads:表示并发垃圾收集器使用的线程数量,默认值随 JVM 运行的平台不同而变动,不建议修改。
其他参数优化
- -XX:AutoBoxCacheMax:用于加大 IntegerCache,具体原因可参考第 20 课时。
- -Djava.security.egd=file:/dev/./urandom:这个参数使用 urandom 随机生成器,在进行随机数获取时,速度会更快。
- -XX:-OmitStackTraceInFastThrow:用于减少异常栈的输出,并进行合并。虽然会对调试有一定的困扰,但能在发生异常时显著增加性能。
存疑优化
- -XX:-UseBiasedLocking:用于取消偏向锁(第 19 课时),理论上在高并发下会增加效率,这个需要实际进行观察,在无法判断的情况下,不需要配置。
- JIT 参数:这是我们在第 22 课时多次提到的 JIT 编译参数,这部分最好不要乱改,会产生意想不到的问题。
GC 日志
这部分我们在第 9 课时进行了详细的介绍,在此不再重复。
下面来看一个在 G1 垃圾回收器运行的 JVM 启动命令。
java \-XX:+UseG1GC \-XX:MaxGCPauseMillis=100 \-XX:InitiatingHeapOccupancyPercent=45 \-XX:G1HeapRegionSize=16m \-XX:+ParallelRefProcEnabled \-XX:MaxTenuringThreshold=3 \-XX:+AlwaysPreTouch \-Xmx5440M \-Xms5440M \-XX:MaxMetaspaceSize=256M \-XX:MetaspaceSize=256M \-XX:MaxDirectMemorySize=100M \-XX:ReservedCodeCacheSize=268435456 \-XX:-OmitStackTraceInFastThrow \-Djava.security.egd=file:/dev/./urandom \-verbose:gc \-XX:+PrintGCDetails \-XX:+PrintGCDateStamps \-XX:+PrintGCApplicationStoppedTime \-XX:+PrintGCApplicationConcurrentTime \-XX:+PrintTenuringDistribution \-XX:+PrintClassHistogramBeforeFullGC \-XX:+PrintClassHistogramAfterFullGC \-Xloggc:/tmp/logs/gc_%p.log \-XX:+HeapDumpOnOutOfMemoryError \-XX:HeapDumpPath=/tmp/logs \-XX:ErrorFile=/tmp/logs/hs_error_pid%p.log \-Djava.rmi.server.hostname=127.0.0.1 \-Dcom.sun.management.jmxremote \-Dcom.sun.management.jmxremote.port=14000 \-Dcom.sun.management.jmxremote.ssl=false \-Dcom.sun.management.jmxremote.authenticate=false \-javaagent:/opt/test.jar \MainRun
故障排查
有需求才需要优化,不要为了优化而优化。一般来说,上面提到的这些 JVM 参数,基本能够保证我们的应用安全,如果想要更进一步、更专业的性能提升,就没有什么通用的法则了。
打印详细的 GCLog,能够帮助我们了解到底是在哪一步骤发生了问题,然后才能对症下药。使用 gceasy.io 这样的线上工具,能够方便的分析到结果,但一些偏门的 JVM 参数修改,还是需要进行详细的验证。
一次或者多次模拟性的压力测试是必要的,能够让我们提前发现这些优化点。
我们花了非常大的篇幅,来讲解 JVM 中故障排查的问题,这也是和我们工作中联系最紧密的话题。
JVM 故障会涉及到内存问题和计算问题,其中内存问题占多数。除了程序计数器,JVM 内存里划分每一个区域,都有溢出的可能,最常见的就是堆溢出。使用 jmap 可以 dump 一份内存,然后使用 MAT 工具进行具体原因的分析。
对堆外内存的排查需要较高的技术水平,我们在第 13 课时进行了详细的讲解。当你发现进程占用的内存资源比使用 Xmx 设置得要多,那么不要忘了这一环。
使用 jstack 可以获取 JVM 的执行栈,并且能够看到线程的一些阻塞状态,这部分可以使用 arthas 进行瞬时态的获取,定位到瞬时故障。另外,一个完善的监控系统能够帮我们快速定位问题,包括操作系统的监控、JVM 的监控等。
代码、JVM 优化和故障排查是一个持续优化的过程,只有更优、没有最优。如何在有限的项目时间内,最高效的完成工作,才是我们所需要的。
小结
本课时对前面的课程内容做了个简单的总结,从 7 个层面的优化出发,简要的谈了一下可能的优化过程,然后详细地介绍了一些常见的优化参数。
JVM 的优化效果是有限的,但它是理论的基础,代码优化和参数优化都需要它的指导。同时,有非常多的工具能够帮我们定位到问题。
偏门的优化参数可能有效,但不总是有效。实际上,从 CMS 到 G1,再到 ZGC,关于 GC 优化的配置参数也越来越少,但协助排查问题的工具却越来越多。在大多数场景下,JVM 已经能够达到开箱即用的高性能效果,这也是一个虚拟机所追求的最终目标。
第24讲:未来:JVM的历史与展望
本课时我们主要讲解 JVM 的历史与展望。
我们都知道,Java 目前被 Oracle 控制,它是从 Sun 公司手中收购的,HotSpot 最初也并非由 Sun 公司开发,是由一家名为 Longview Technologies 的小公司设计的,而且这款虚拟机一开始也不是为 Java 语言开发的。
当时的 HotSpot,非常优秀,尤其是在 JIT 编译技术上,有一些超前的理念,于是 Sun 公司在 1997 年收购了 Longview Technologies,揽美人入怀。
Sun 公司是一家对技术非常专情的公司,他们对 Java 语言进行了发扬光大,尤其是在 JVM 上,做了一些非常大胆的尝试和改进。
9 年后,Sun 公司在 2006 年的 JavaOne 大会上,将 Java 语言开源,并在 GPL 协议下公开源码,在此基础上建立了 OpenJDK。你应该听说过,GPL 协议的限制,是比较宽松的,这极大的促进了 Java 的发展,同时推动了 JVM 的发展。
Sun 是一家非常有技术情怀的公司,最高市值曾超过 2000 亿美元。但是,最后却以 74 亿美元的价格被 Oracle 收购了,让人感叹不已。
2010 年,HotSpot 进入了 Oracle 时代,这也是现在为什么要到 Oracle 官网上下载 J2SE 的原因。
幸运的是,我们有 OpenJDK 这个凝聚了众多开源开发者心血的分支。从目前的情况来看,OpenJDK 与 Oracle 版本之间的差别越来越小,甚至一些超前的实验性特性,也会在 OpenJDK 上进行开发。
对于我们使用者来说,这个差别并不大,因为 JVM 已经屏蔽了操作系统上的差异,而我们打交道的,是上层的 JRE 和 JDK。
其他虚拟机
由于 JVM 就是个规范,所以实现的方法也很多,完整的列表请点击这里查看。
JVM 的版本非常之多,比较牛的公司都搞了自己的 JVM,但当时谁也没想到,话语权竟会到了 Oracle 手里。下面举几个典型的例子。
J9 VM
我在早些年工作的时候,有钱的公司喜欢买大型机,比如会买 WebLogic、WebSphere 等服务器。对于你现在已经用惯了 Tomcat、Undertow 这些轻量级的 Web 服务器来说,这是一些很古老的名词了。
WebSphere 就是这样一个以“巨无霸”的形式存在,当年的中间件指的就是它,和现在的中间件完全不是一个概念。
WebSphere 是 IBM 的产品,开发语言是 Java。但是它运行时的 JVM,却是一个叫做 J9 的虚拟机,依稀记得当年,有非常多的 jar 包,由于引用了一些非常偏门的 API,却不能运行(现在应该好了很多)。
Zing VM
Zing JVM 是 Azul 公司传统风格的产品,它在 HotSpot 上做了不少的定制及优化,主打低延迟、高实时服务器端 JDK 市场。它代表了一类商业化的定制,比如 JRockit,都比较贵。
IKVM
这个以前在写一些游戏的时候,使用过 LibGDX,相当于使用了 Java,最后却能跑在 .net 环境上,使用的方式是 IKVM 。它包含了一个使用 .net 语言实现的 Java 虚拟机,配合 Mono 能够完成 Java 和 .net 的交互,让人认识到语言之间的鸿沟是那么的渺小。
Dalvik
Android 的 JVM,就是让 Google 吃官司的那个,从现在 Android 的流行度上也能看出来,Dalvik 优化的很好。
历史
下面我简单讲讲 Java 的发展历史:
- 1995 年 5 月 23 日,Sun 公司正式发布了 Java 语言和 HotJava 浏览器;
- 1996 年 1 月,Sun 公司发布了 Java 的第一个开发工具包(JDK 1.0);
- 1996 年 4 月,10 个最主要的操作系统供应商申明将在其产品中嵌入 Java 技术,发展可真是迅雷不及掩耳;
- 1996 年 9 月,约 8.3 万个网页应用了 Java 技术来制作,这就是早年的互联网,即 Java Applet,真香;
- 1996 年 10 月,Sun 公司发布了 Java 平台第一个即时编译器(JIT),这一年很不平凡;
- 1997 年 2 月 18 日,JDK 1.1 面世,在随后的三周时间里,达到了 22 万次的下载量,PHP 甘拜下风;
- 1999 年 6 月,Sun 公司发布了第二代 Java 三大版本,即 J2SE、J2ME、J2EE,随之 Java2 版本发布;
- 2000 年 5 月 8 日,JDK 1.3 发布,四年升三版,不算过分哈;
- 2000 年 5 月 29 日,JDK 1.4 发布,获得 Apple 公司 Mac OS 的工业标准支持;
- 2001 年 9 月 24 日,Java EE 1.3 发布,注意是 EE,从此开始臃肿无比;
- 2002 年 2 月 26 日,J2SE 1.4 发布,自此 Java 的计算能力有了大幅度的提升,与 J2SE 1.3 相比,多了近 62% 的类与接口;
- 2004 年 9 月 30 日 18:00PM,J2SE 1.5 发布,1.5 正式更名为 Java SE 5.0;
- 2005 年 6 月,在 JavaOne 大会上,Sun 公司发布了 Java SE 6;
- 2009 年 4 月 20 日,Oracle 宣布收购 Sun,该交易的总价值约为 74 亿美元;
- 2010 年 Java 编程语言的创始人 James Gosling 从 Oracle 公司辞职,一朝天子一朝臣,国外也不例外;
- 2011 年 7 月 28 日,Oracle 公司终于发布了 Java 7,这次版本升级经过了将近 5 年时间;
- 2014 年 3 月 18 日,Oracle 公司发布了 Java 8,这次版本升级为 Java 带来了全新的 Lambda 表达式。
小碎步越来越快,担心很快 2 位数都装不下 Java 的版本号了。目前 Java 的版本已经更新到 14 了,但市场主流使用的还是 JDK 8 版本。
最近更新
有些我们现在认为理所当然的功能,在 Java 的早期版本是没有的。我们从 Java 7 说起,以下内容仅供参考,详细列表见 openjdk JEP 列表。
Java 7
Java 7 增加了以下新特性:
- try、catch 能够捕获多个异常
- 新增 try-with-resources 语法
- JSR341 脚本语言新规范
- JSR203 更多的 NIO 相关函数
- JSR292,第 17 课时提到的 InvokeDynamic
- 支持 JDBC 4.1 规范
- 文件操作的 Path 接口、DirectoryStream、Files、WatchService
- jcmd 命令
- 多线程 fork/join 框架
- Java Mission Control
Java 8
Java 8 也是一个重要的版本,在语法层面上有更大的改动,支持 Lamda 表达式,影响堪比 Java 5 的泛型支持:
- 支持 Lamda 表达式
- 支持集合的 stream 操作
- 提升了 HashMaps 的性能(红黑树)
- 提供了一系列线程安全的日期处理类
- 完全去掉了 Perm 区
Java 9
Java 9 增加了以下新特性:
- JSR376 Java 平台模块系统
- JEP261 模块系统
- jlink 精简 JDK 大小
- G1 成为默认垃圾回收器
- CMS 垃圾回收器进入废弃倒计时
- GC Log 参数完全改变,且不兼容
- JEP110 支持 HTTP2,同时改进 HttpClient 的 API,支持异步模式
- jshell 支持类似于 Python 的交互式模式
Java 10
Java 10 增加了以下新特性:
- JEP304 垃圾回收器接口代码进行整改
- JEP307 G1 在 FullGC 时采用并行收集方式
- JEP313 移除 javah 命令
- JEP317 重磅 JIT 编译器 Graal 进入实验阶段
Java 11
Java 11 增加了以下新特性:
- JEP318 引入了 Epsilon 垃圾回收器,这个回收器什么都不干,适合短期任务
- JEP320 移除了 JavaEE 和 CORBA Modules,应该要走轻量级路线
- Flight Recorder 功能,类似 JMC 工具里的功能
- JEP321 内置 httpclient 功能,java.net.http 包
- JEP323 允许 lambda 表达式使用 var 变量
- 废弃了 -XX+AggressiveOpts 选项
- 引入了 ZGC,依然是实验性质
Java 12
Java 12 增加了以下新特性:
- JEP189 先加入 ShenandoahGC
- JEP325 switch 可以使用表达式
- JEP344 优化 G1 达成预定目标
- 优化 ZGC
Java 13
Java 13 增加了以下新特性:
- JEP354 yield 替代 break
- JEP355 加入了 Text Blocks,类似 Python 的多行文本
- ZGC 的最大 heap 大小增大到 16TB
- 废弃 rmic Tool 并准备移除
Java 14
Java 14 增加了以下新特性:
- JEP343 打包工具引入
- JEP345 实现了 NUMA-aware 的内存分配,以提升 G1 在大型机器上的性能
- JEP359 引入了 preview 版本的 record 类型,可用于替换 lombok 的部分功能
- JEP364 之前的 ZGC 只能在 Linux 上使用,现在 Mac 和 Windows 上也能使用 ZGC 了
- JEP363 正式移除 CMS,我们课程里提到的一些优化参数,在 14 版本普及之后,将不复存在
OpenJDK 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; support was removed in 14.0
现状
先看一下 2019 年 JVM 生态系统报告部分图示,部分图示参考了 snyk 这个网站。
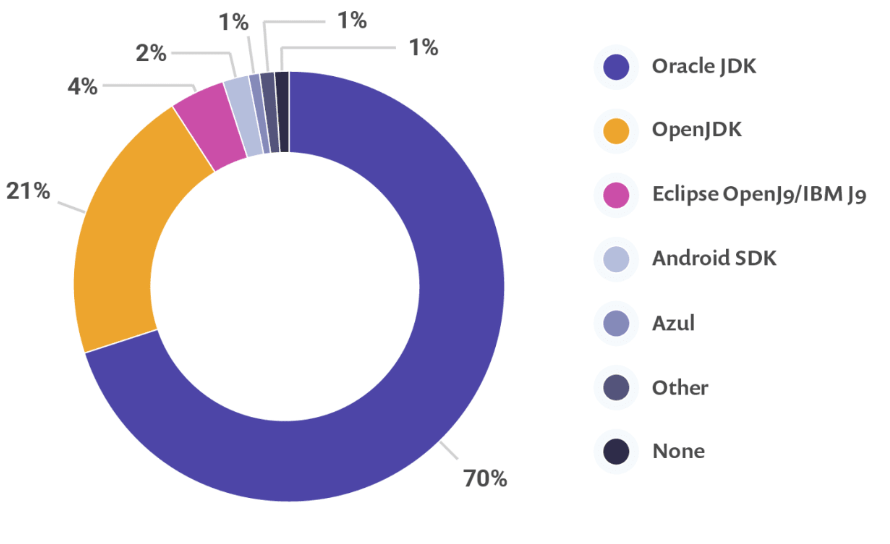
生产环境中,主要用哪些 JDK
可以看到 OracleJDK 和 OpenJDK 几乎统治了江湖,如果没有 IBM 那些捆绑销售的产品,份额只会更高。另外,使用 OpenJDK 的越来越多,差异也越来越小,在公有云、私有云等方面的竞争格局,深刻影响着在 OpenJDK 上的竞争格局;OpenJDK 很有可能被认为是一种退⽽求其次的选择。
生产环境中,用哪个版本的 Java
以 8 版本为主,当然还有 6 版本以下的,尝鲜的并不是很多,因为服务器环境的稳定性最重要。新版本升级在中国的宣传还是不够,如果很多企业看不到技术升级的红利,势必也会影响升级的积极性。
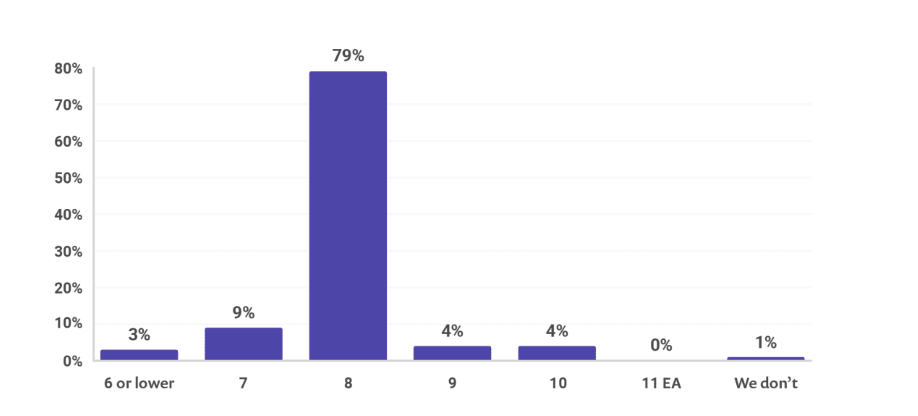
应用程序的主要 JVM 语言是什么
很多人反应 Kotlin 非常好用,我尝试着推广了一下,被喜欢 Groovy 的朋友鄙视了一番,目前还是以 Java 居多。
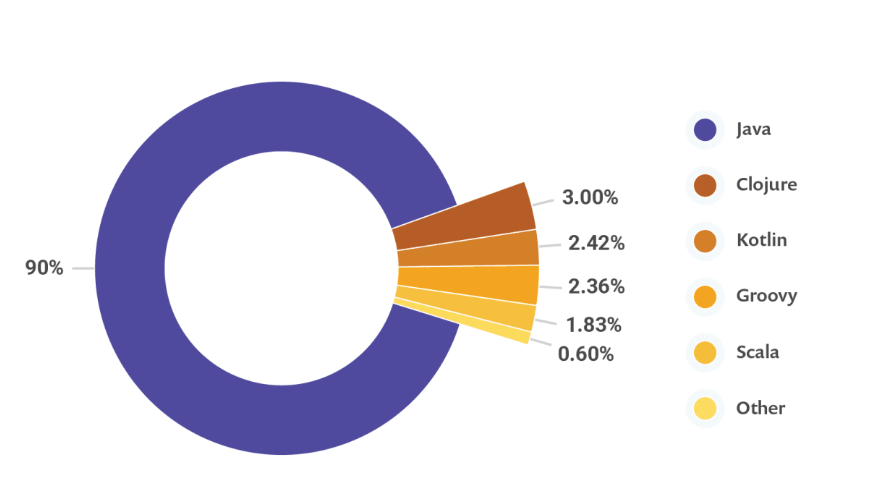
展望
有点规模的互联网公司,行事都会有些谨慎,虽然 JVM 做到了向下版本的兼容,但是有些性能问题还是不容忽视,尝鲜吃螃蟹的并不是很多。
现在用的最多的,就是 Java 8 版本。如果你的服务器用的这个,那么用的最多的垃圾回收器就是 CMS,或者 G1。随着 ZGC 越来越稳定,CMS 终将会成为过去式。
目前,最先进的垃圾回收器,叫做 ZGC,它有 3 个 flag:
- 支持 TB 级堆内存(最大 4T)
- 最大 GC 停顿 10ms
- 对吞吐量影响最大,不超过 15%
每一个版本的发布,Java 都会对以下进行改进:
- 优化垃圾回收器,减少停顿,提高吞吐
- 语言语法层面的升级,这部分在最近的版本里最为明显
- 结构调整,减少运行环境的大小,模块化
- 废弃掉一些承诺要废弃的模块
那么 JVM 将向何处发展呢?以目前来看,比较先进的技术,就是刚才提到的垃圾回收阶段的 ZGC ,能够显著的减少 STW 的问题;另外, GraalVM 是 Oracle 创建的一个研究项目,目标是完全替换 HotSpot,它是一个高性能的 JIT 编译器,接受 JVM 字节码,并生成机器代码。未来,会有更多的开发语言运行在 JVM 上,比如 Python、Ruby 等。
Poject Loom 致力于在 JVM 层面,给予 Java 协程 (fibers)的功能,Java 程序的并发性能会上一个档次。
Java 版本大部分是向下兼容的,能够做到这个兼容,是非常不容易的。但 Java 的特性越加越多,如果开发人员不能进行平滑的升级,会是一个非常严重的问题,JVM 也将会在这里花费非常大的精力。
那 JVM 将聚焦在哪些方面呢?又有哪些挑战?我大体总结了几点:
- 内存管理依然是非常大的挑战,未来会有更厉害的垃圾回收器来支持更大的堆空间
- 多线程和协程,未来会加大对多核的利用,以及对轻量级线程的支持
- 性能,增加整个 JVM 的执行效率,这通常是多个模块协作的结果
- 对象管理和追踪,复杂的对象,有着复杂的生命周期,加上难以预料的内存申请方式,需要更精准的管理优化
- 可预测性及易用性,更少的优化参数,更高的性能
- 更多 JVM 监控工具,提供对 JVM 全方面的监控,跟踪对象,在线优化
- 多语言支持,支持除了 Java 语言之外的其他开发语言,能够运行在 JVM 上
总结
Java 9 之后,已经进入了快速发布阶段,大约每半年发布一次,Java 8 和 Java 11 是目前支持的 LTS 版本,它的功能变动也越来越多、越来越快。让我们把握好 Java 发展的脉搏,一起加油吧。
第25讲:福利:常见JVM面试题补充
最后一课时我们来分析常见的 JVM 面试题。
市面上关于 JVM 的面试题实在太多了,本课程中的第 02 ~ 06 课时是理论面试题的重灾区,并且是比较深入的题目,而本课时则选取了一些基础且常见的题目。
有些面试题是开放性的,而有些面试题是知识性的,要注意区别。面试题并没有标准答案,尤其是开放性题目,你需要整理成白话文,来尽量的展示自己。如果你在回答的过程中描述了一些自己不是很熟悉的内容,可能会受到追问。所以,根据问题,建议整理一份适合自己的答案,这比拿来主义更让人印象深刻。
勘误
我们来回忆一下课程中曾讲解过的容易出错或模糊的知识点。
不知你是否还记得?我们在每一课时的讲解中,都有聚焦的点,不同的问法可能会有不同的回答,要注意。
对象在哪里分配?
在第 02 课时中,谈到了数组和对象是堆上分配,当学完第 22 课时的逃逸分析后,我们了解到并不完全是这样的。由于 JIT 的存在,如果发现某些对象没有逃逸出方法,那么就有可能被优化成了栈上分配。
CMS 是老年代垃圾回收器?
初步印象是,但实际上不是。根据 CMS 的各个收集过程,它其实是一个涉及年轻代和老年代的综合性垃圾回收器。在很多文章和书籍的划分中,都将 CMS 划分为了老年代垃圾回收器,加上它主要作用于老年代,所以一般误认为是。
常量池问题
常量池的表述有些模糊,在此细化一下,注意我们指的是 Java 7 版本之后。
JVM 中有多个常量池:
- 字符串常量池,存放在堆上,也就是执行 intern 方法后存的地方,class 文件的静态常量池,如果是字符串,则也会被装到字符串常量池中。
- 运行时常量池,存放在方法区,属于元空间,是类加载后的一些存储区域,大多数是类中 constant_pool 的内容。
- 类文件常量池,也就是 constant_pool,这个是概念性的,并没有什么实际存储区域。
在平常的交流过程中,聊的最多的是字符串常量池,具体可参考官网。
ZGC 支持的堆上限?
Java 13 增加到 16TB,Java 11 还是 4 TB,技术在发展,请保持关注。
年轻代提升阈值动态计算的描述
在第 06 课时中对于年轻代“动态对象年龄判定”的表述是错误的。
参考代码 share/gc/shared/ageTable.cpp 中的 compute_tenuring_threshold 函数,重新表述为:程序从年龄最小的对象开始累加,如果累加的对象大小,大于幸存区的一半,则将当前的对象 age 作为新的阈值,年龄大于此阈值的对象则直接进入老年代。
这里说的一半,是通过 TargetSurvivorRatio 参数进行设置的。
永久代
虽然课程一直在强调,是基于 Java 8+ 版本进行讲解的,但还是有读者提到了永久代。这部分知识容易发生混淆,面试频率也很高,建议集中消化一下。
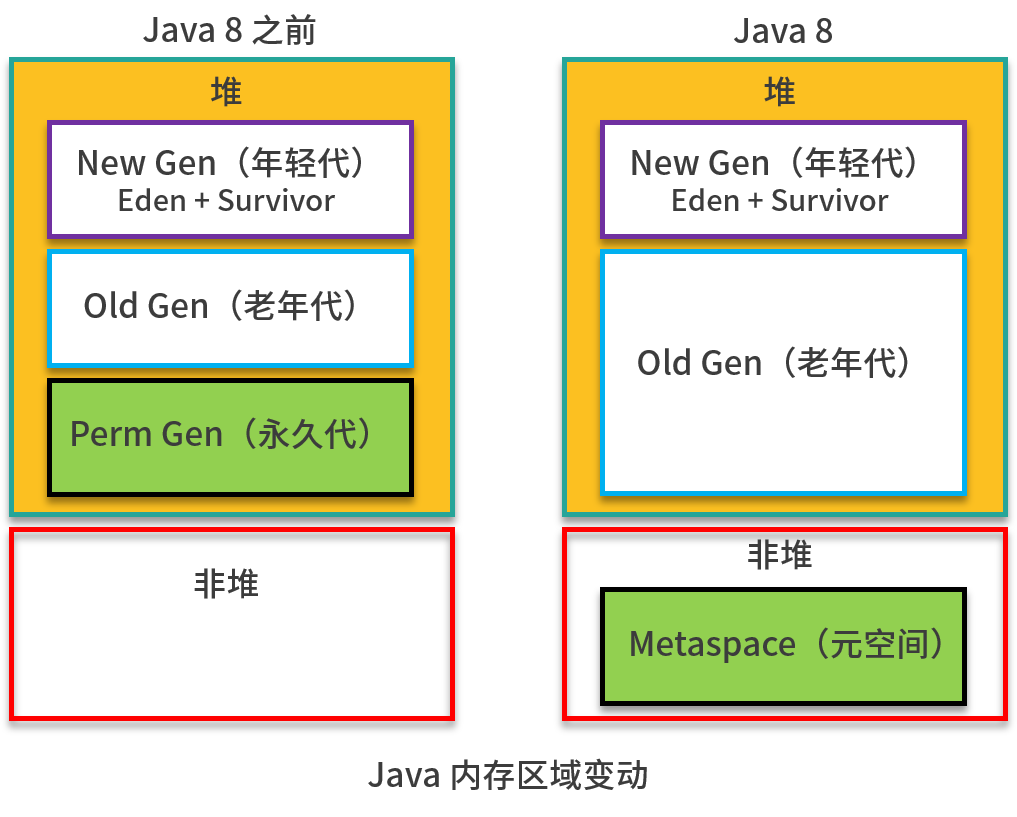
上面是第 02 课时中的一张图,注意左半部分是 Java 8 版本之前的内存区域,右半部分是 Java 8 的内存区域,主要区别就在 Perm 区和 Metaspace 区。
Perm 区属于堆,独立控制大小,在 Java 8 中被移除了(JEP122),原来的方法区就在这里;Metaspace 是非堆,默认空间无上限,方法区移动到了这里。
常见面试题
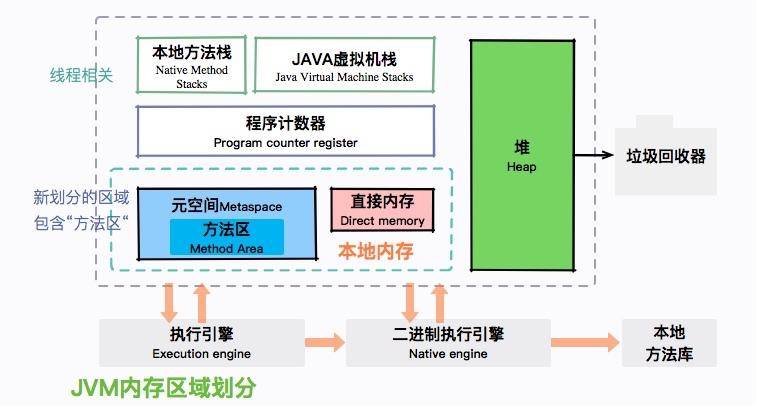
JVM 有哪些内存区域?(JVM 的内存布局是什么?)
JVM 包含堆、元空间、Java 虚拟机栈、本地方法栈、程序计数器等内存区域,其中,堆是占用内存最大的一块,如下图所示。
Java 的内存模型是什么?(JMM 是什么?)
JVM 试图定义一种统一的内存模型,能将各种底层硬件以及操作系统的内存访问差异进行封装,使 Java 程序在不同硬件以及操作系统上都能达到相同的并发效果。它分为工作内存和主内存,线程无法对主存储器直接进行操作,如果一个线程要和另外一个线程通信,那么只能通过主存进行交换,如下图所示。
JVM 垃圾回收时如何确定垃圾?什么是 GC Roots?
JVM 采用的是可达性分析算法。JVM 是通过 GC Roots 来判定对象存活的,从 GC Roots 向下追溯、搜索,会产生一个叫做 Reference Chain 的链条。当一个对象不能和任何一个 GC Root 产生关系时,就判定为垃圾,如下图所示。
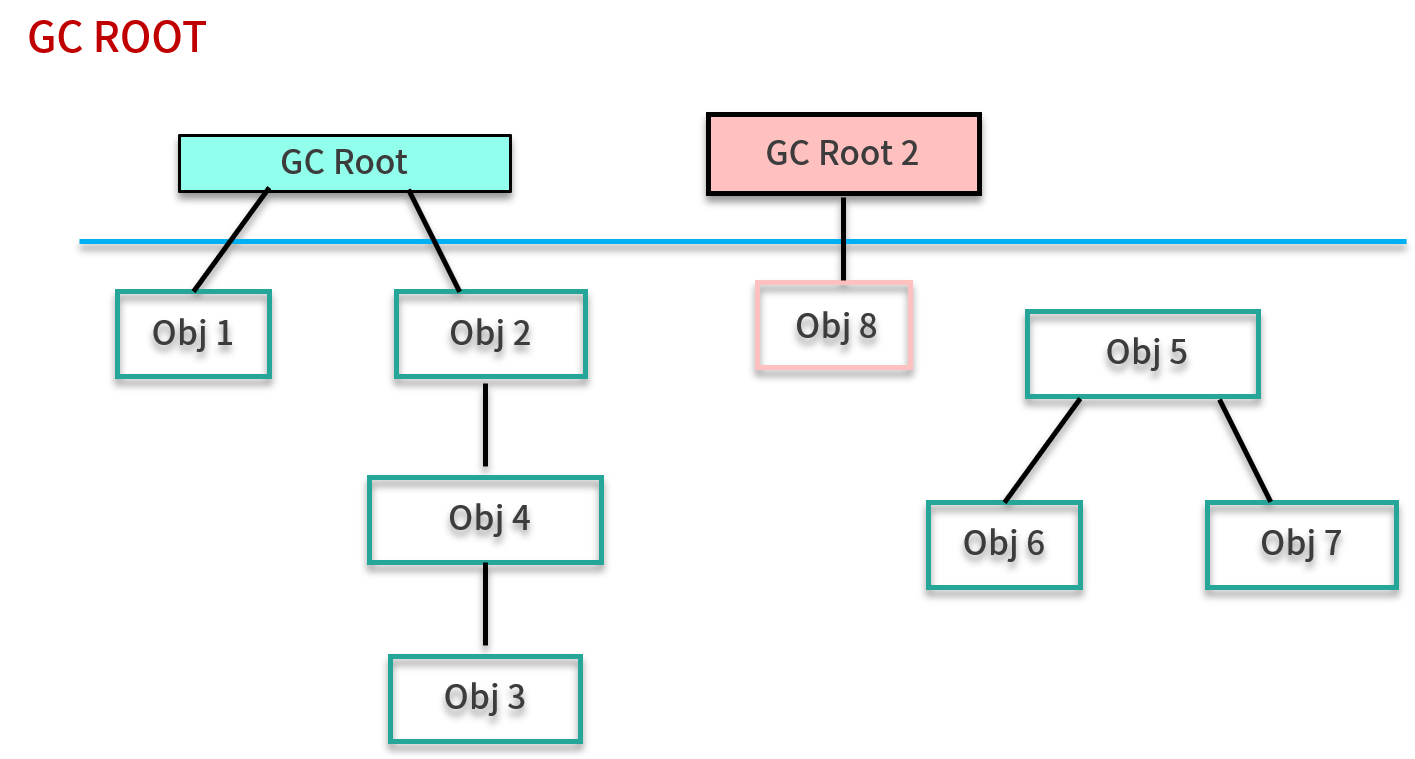
GC Roots 大体包括:
- 活动线程相关的各种引用,比如虚拟机栈中 栈帧里的引用;
- 类的静态变量引用;
- JNI 引用等。
注意:要想回答的更详细一些,请参照第 05 课时中的内容。
能够找到 Reference Chain 的对象,就一定会存活么?
不一定,还要看 Reference 类型,弱引用在 GC 时会被回收,软引用在内存不足的时候会被回收,但如果没有 Reference Chain 对象时,就一定会被回收。
强引用、软引用、弱引用、虚引用是什么?
普通的对象引用关系就是强引用。
软引用用于维护一些可有可无的对象。只有在内存不足时,系统则会回收软引用对象,如果回收了软引用对象之后仍然没有足够的内存,才会抛出内存溢出异常。
弱引用对象相比软引用来说,要更加无用一些,它拥有更短的生命周期,当 JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。
虚引用是一种形同虚设的引用,在现实场景中用的不是很多,它主要用来跟踪对象被垃圾回收的活动。
你说你做过 JVM 参数调优和参数配置,请问如何查看 JVM 系统默认值
使用 -XX:+PrintFlagsFinal 参数可以看到参数的默认值,这个默认值还和垃圾回收器有关,比如 UseAdaptiveSizePolicy。
你平时工作中用过的 JVM 常用基本配置参数有哪些?
主要有 Xmx、Xms、Xmn、MetaspaceSize 等。
更加详细的可参照第 23 课时的参数总结,你只需要记忆 10 个左右即可,建议记忆 G1 相关的参数。面试时间有限,不会在这上面纠结,除非你表现的太嚣张了。
请你谈谈对 OOM 的认识
OOM 是非常严重的问题,除了程序计数器,其他内存区域都有溢出的风险。和我们平常工作最密切的,就是堆溢出,另外,元空间在加载的类非常多的情况下也会溢出,还有就是栈溢出,这个通常影响比较小。堆外也有溢出的可能,这个就比较难排查了。
你都有哪些手段用来排查内存溢出?
这个话题很大,可以从实践环节中随便摘一个进行总结,下面举一个最普通的例子。
内存溢出包含很多种情况,我在平常工作中遇到最多的就是堆溢出。有一次线上遇到故障,重新启动后,使用 jstat 命令,发现 Old 区一直在增长。我使用 jmap 命令,导出了一份线上堆栈,然后使用 MAT 进行分析,通过对 GC Roots 的分析,发现了一个非常大的 HashMap 对象,这个原本是其他同事做缓存用的,但是一个无界缓存,造成了堆内存占用一直上升,后来,将这个缓存改成 guava 的 Cache,并设置了弱引用,故障就消失了。
GC 垃圾回收算法与垃圾收集器的关系?
常用的垃圾回收算法有标记清除、标记整理、复制算法等,引用计数器也算是一种,但垃圾回收器不使用这种算法,因为有循环依赖的问题。
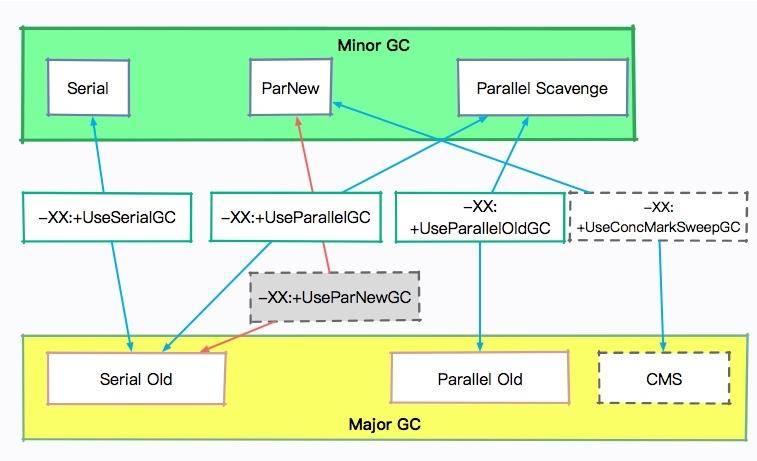
很多垃圾回收器都是分代回收的:
- 对于年轻代,主要有 Serial、ParNew 等垃圾回收器,回收过程主要使用复制算法;
- 老年代的回收算法有 Serial、CMS 等,主要使用标记清除、标记整理算法等。
我们线上使用较多的是 G1,也有年轻代和老年代的概念,不过它是一个整堆回收器,它的回收对象是小堆区 。
生产上如何配置垃圾收集器?

首先是内存大小问题,基本上每一个内存区域我都会设置一个上限,来避免溢出问题,比如元空间。通常,堆空间我会设置成操作系统的 2/3,超过 8GB 的堆,优先选用 G1。
然后我会对 JVM 进行初步优化,比如根据老年代的对象提升速度,来调整年轻代和老年代之间的比例。
接下来是专项优化,判断的主要依据是系统容量、访问延迟、吞吐量等,我们的服务是高并发的,所以对 STW 的时间非常敏感。
我会通过记录详细的 GC 日志,来找到这个瓶颈点,借用 GCeasy 这样的日志分析工具,很容易定位到问题。
怎么查看服务器默认的垃圾回收器是哪一个?
这通常会使用另外一个参数,即 -XX:+PrintCommandLineFlags,来打印所有的参数,包括使用的垃圾回收器。
假如生产环境 CPU 占用过高,请谈谈你的分析思路和定位。
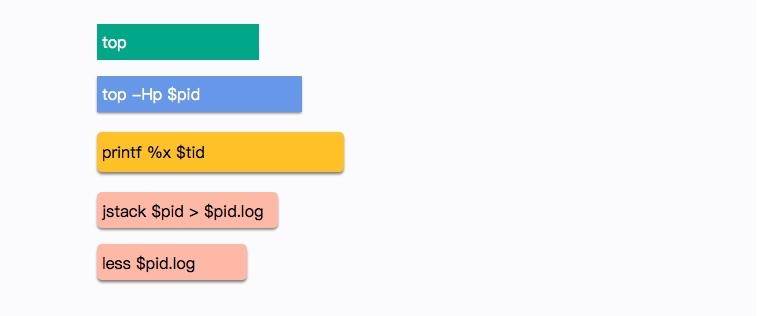
首先,使用 top -H 命令获取占用 CPU 最高的线程,并将它转化为十六进制。
然后,使用 jstack 命令获取应用的栈信息,搜索这个十六进制,这样就能够方便地找到引起 CPU 占用过高的具体原因。
对于 JDK 自带的监控和性能分析工具用过哪些?
- jps:用来显示 Java 进程;
- jstat:用来查看 GC;
- jmap:用来 dump 堆;
- jstack:用来 dump 栈;
- jhsdb:用来查看执行中的内存信息。
栈帧都有哪些数据?
栈帧包含:局部变量表、操作数栈、动态连接、返回地址等。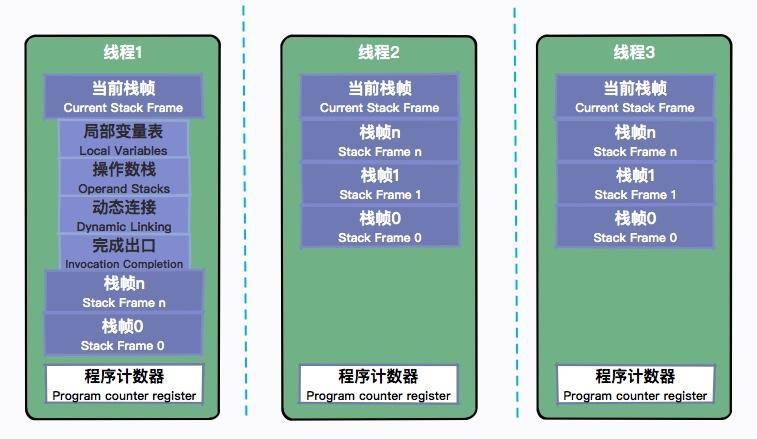
JIT 是什么?
为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器,就称为即时编译器(Just In Time Compiler),简称 JIT 编译器。
Java 的双亲委托机制是什么?
双亲委托的意思是,除了顶层的启动类加载器以外,其余的类加载器,在加载之前,都会委派给它的父加载器进行加载,这样一层层向上传递,直到祖先们都无法胜任,它才会真正的加载,Java 默认是这种行为。
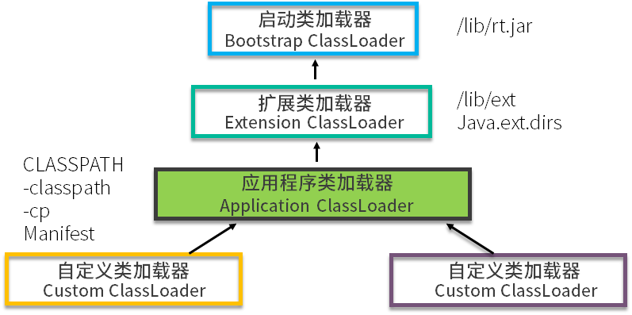
有哪些打破了双亲委托机制的案例?
- Tomcat 可以加载自己目录下的 class 文件,并不会传递给父类的加载器;
- Java 的 SPI,发起者是 BootstrapClassLoader,BootstrapClassLoader 已经是最上层了,它直接获取了 AppClassLoader 进行驱动加载,和双亲委派是相反的。
简单描述一下(分代)垃圾回收的过程
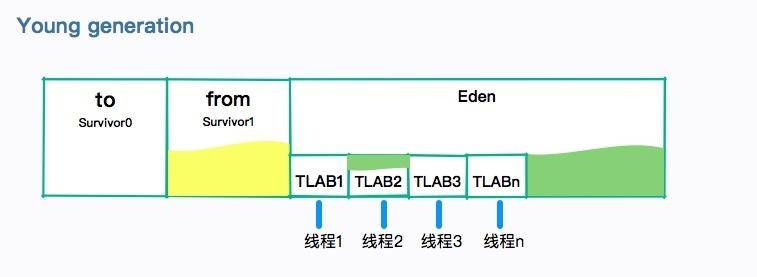
分代回收器有两个分区:老生代和新生代,新生代默认的空间占总空间的 1/3,老生代的默认占比是 2/3。
新生代使用的是复制算法,新生代里有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1。
当年轻代中的 Eden 区分配满的时候,就会触发年轻代的 GC(Minor GC),具体过程如下:
- 在 Eden 区执行了第一次 GC 之后,存活的对象会被移动到其中一个 Survivor 分区(以下简称 from);
- Eden 区再次 GC,这时会采用复制算法,将 Eden 和 from 区一起清理,存活的对象会被复制到 to 区,接下来,只要清空 from 区就可以了。
CMS 分为哪几个阶段?
- 初始标记
- 并发标记
- 并发预清理
- 并发可取消的预清理
- 重新标记
- 并发清理
由于《深入理解 Java 虚拟机》一书的流行,面试时省略并发清理、并发可取消的预清理这两个阶段,一般也是没问题的。
CMS 都有哪些问题?
- 内存碎片问题,Full GC 的整理阶段,会造成较长时间的停顿;
- 需要预留空间,用来分配收集阶段产生的“浮动垃圾”;
- 使用更多的 CPU 资源,在应用运行的同时进行堆扫描;
- 停顿时间是不可预期的。
你使用过 G1 垃圾回收器的哪几个重要参数?
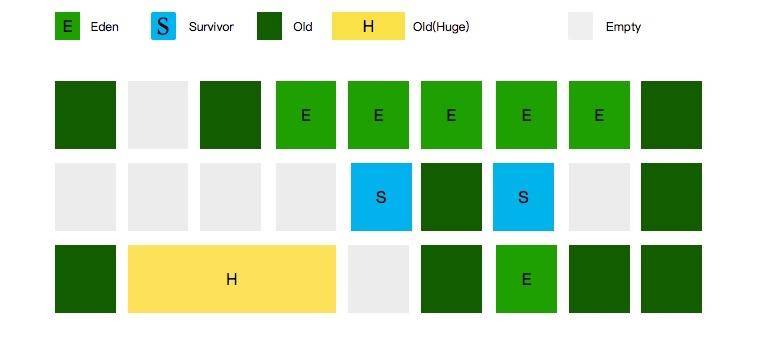
最重要的是 MaxGCPauseMillis,可以通过它设定 G1 的目标停顿时间,它会尽量去达成这个目标。G1HeapRegionSize 可以设置小堆区的大小,一般是 2 的次幂。InitiatingHeapOccupancyPercent 启动并发 GC 时的堆内存占用百分比,G1 用它来触发并发 GC 周期,基于整个堆的使用率,而不只是某一代内存的使用比例,默认是 45%。
GC 日志的 real、user、sys 是什么意思?
- real 指的是从开始到结束所花费的时间,比如进程在等待 I/O 完成,这个阻塞时间也会被计算在内。
- user 指的是进程在用户态(User Mode)所花费的时间,只统计本进程所使用的时间,是指多核。
- sys 指的是进程在核心态(Kernel Mode)所花费的 CPU 时间量,即内核中的系统调用所花费的时间,只统计本进程所使用的时间。
什么情况会造成元空间溢出?
元空间默认是没有上限的,不加限制比较危险。当应用中的 Java 类过多时,比如 Spring 等一些使用动态代理的框架生成了很多类,如果占用空间超出了我们的设定值,就会发生元空间溢出。
什么时候会造成堆外内存溢出?
使用了 Unsafe 类申请内存,或者使用了 JNI 对内存进行操作,这部分内存是不受 JVM 控制的,不加限制使用的话,会很容易发生内存溢出。
SWAP 会影响性能么?
当操作系统内存不足时,会将部分数据写入到 SWAP ,但是 SWAP 的性能是比较低的。如果应用的访问量较大,需要频繁申请和销毁内存,那么很容易发生卡顿。一般在高并发场景下,会禁用 SWAP。
有什么堆外内存的排查思路?
进程占用的内存,可以使用 top 命令,看 RES 段占用的值,如果这个值大大超出我们设定的最大堆内存,则证明堆外内存占用了很大的区域。 使用 gdb 命令可以将物理内存 dump 下来,通常能看到里面的内容。更加复杂的分析可以使用 Perf 工具,或者谷歌开源的 GPerftools。那些申请内存最多的 native 函数,就很容易找到。
HashMap 中的 key,可以是普通对象么?有什么需要注意的地方?
Map 的 key 和 value 可以是任何类型,但要注意的是,一定要重写它的 equals 和 hashCode 方法,否则容易发生内存泄漏。
怎么看死锁的线程?
通过 jstack 命令,可以获得线程的栈信息,死锁信息会在非常明显的位置(一般是最后)进行提示。
如何写一段简单的死锁代码?
详情请见第 15 课时的 DeadLockDemo,笔试的话频率也很高。
invokedynamic 指令是干什么的?
invokedynamic 是 Java 7 版本之后新加入的字节码指令,使用它可以实现一些动态类型语言的功能。我们使用的 Lambda 表达式,在字节码上就是 invokedynamic 指令实现的,它的功能有点类似反射,但它是使用方法句柄实现的,执行效率更高。
volatile 关键字的原理是什么?有什么作用?
使用了 volatile 关键字的变量,每当变量的值有变动的时候,都会将更改立即同步到主内存中;而如果某个线程想要使用这个变量,就先要从主存中刷新到工作内存,这样就确保了变量的可见性。
一般使用一个 volatile 修饰的 bool 变量,来控制线程的运行状态。
volatile boolean stop = false;void stop() {this.stop = true;
}void start() {new Thread(() -> {while (!stop) {//sth}}).start();
}
什么是方法内联?
为了减少方法调用的开销,可以把一些短小的方法,比如 getter/setter,纳入到目标方法的调用范围之内,这样就少了一次方法调用,速度就能得到提升,这就是方法内联的概念。
对象是怎么从年轻代进入老年代的?
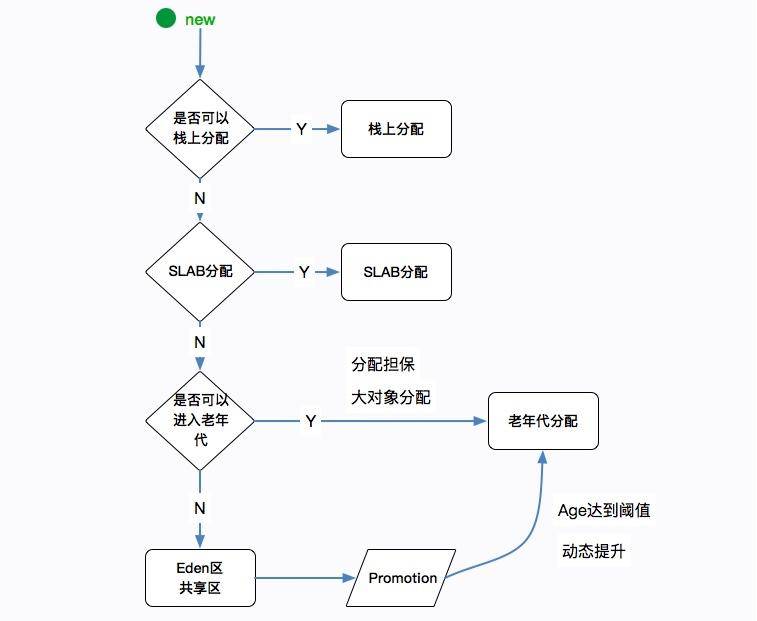
在下面 4 种情况下,对象会从年轻代进入到老年代。
- 如果对象够老,则会通过提升(Promotion)的方式进入老年代,一般根据对象的年龄进行判断。
- 动态对象年龄判定,有的垃圾回收算法,比如 G1,并不要求 age 必须达到 15 才能晋升到老年代,它会使用一些动态的计算方法。
- 分配担保,当 Survivor 空间不够的时候,则需要依赖其他内存(指老年代)进行分配担保,这个时候,对象也会直接在老年代上分配。
- 超出某个大小的对象将直接在老年代上分配,不过这个值默认为 0,意思是全部首选 Eden 区进行分配。
safepoint 是什么?
当发生 GC 时,用户线程必须全部停下来,才可以进行垃圾回收,这个状态我们可以认为 JVM 是安全的(safe),整个堆的状态是稳定的。

如果在 GC 前,有线程迟迟进入不了 safepoint,那么整个 JVM 都在等待这个阻塞的线程,造成了整体 GC 的时间变长。
MinorGC、MajorGC、FullGC 都什么时候发生?
MinorGC 在年轻代空间不足的时候发生,MajorGC 指的是老年代的 GC,出现 MajorGC 一般经常伴有 MinorGC。
FullGC 有三种情况:第一,当老年代无法再分配内存的时候;第二,元空间不足的时候;第三,显示调用 System.gc 的时候。另外,像 CMS 一类的垃圾回收器,在 MinorGC 出现 promotion failure 的时候也会发生 FullGC。
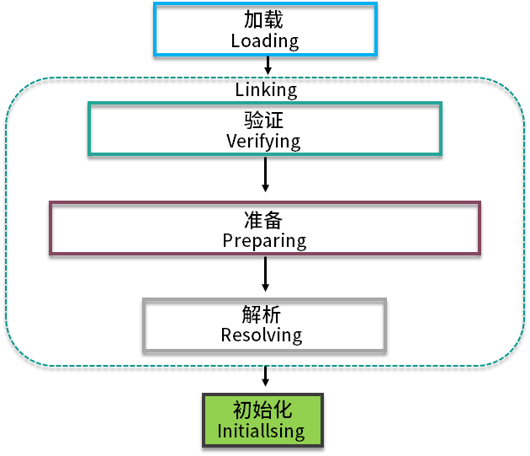
类加载有几个过程?
加载、验证、准备、解析、初始化。
什么情况下会发生栈溢出?
栈的大小可以通过 -Xss 参数进行设置,当递归层次太深的时候,则会发生栈溢出。
生产环境服务器变慢,请谈谈诊断思路和性能评估?
希望第 11 课时和第 16 课时中的一些思路,能够祝你一臂之力。下图是第 11 课时的一张影响因素的全景图。
从各个层次分析代码优化的手段,如下图所示:
如果你应聘的是比较高级的职位,那么可以说一下第 23 课时中的最后总结部分。
小结
本课时我们首先修正了一些表述错误的知识点;然后分析了一些常见的面试题,这些面试题的覆盖率是非常有限的,因为很多细节都没有触及到,更多的面试题还需要你自行提取、整理,由于篇幅有限,这里不再重复。
到现在为止,我们的课程内容就结束了。本课程的特色主要体现在实践方面,全部都是工作中的总结和思考;辅之以理论,给你一个在工作中,JVM 相关知识点的全貌。当然,有些课时的难度是比较高的,需要你真正的实际操作一下。