C++ 分治 归并排序解决问题 力扣 493. 反转对 题解 每日一题
文章目录
- 题目描述
- 为什么这道题值得你花几分钟看懂?
- 题目解析
- 算法原理
- 暴力解法(超时)
- 归并排序解法
- 两种计数思路
- 代码实现
- 时间复杂度与空间复杂度分析
- 总结
- 下题预告


题目描述
题目链接:力扣 493. 反转对
题目描述:
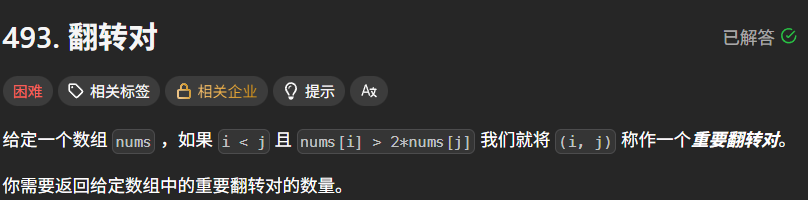
示例 1:
输入:nums = [1,3,2,3,1]
输出:2
解释:反转对为 (3,1) 和 (3,1)(分别对应索引 (1,4) 和 (3,4))
提示:
0 <= nums.length <= 5 * 10^4
为什么这道题值得你花几分钟看懂?
这道题是归并排序思想的“升级挑战场”,是从“基础逆序对”到“带倍数关系逆序对”的关键进阶。花上分钟的时间我们将收获:
-
深化分治计数的边界处理能力:相比普通逆序对(
nums[i] > nums[j]),本题的nums[i] > 2*nums[j]引入了更复杂的数值关系,需要重新设计计数逻辑,理解“为什么在归并中可以安全地移动指针而不遗漏计数”。 -
掌握“分阶段处理”的核心技巧:本题无法在合并排序的同时完成计数,必须拆分“计数”和“排序”两个阶段。这种“先统计跨数组反转对,再合并排序”的思路,能帮你突破“排序与计数必须同步”的思维定式。
-
强化数值比较的细节把控:由于涉及
2*nums[j],极易出现整数溢出问题(如nums[j] = 1e9时2*nums[j]超过 int 范围),通过本题可培养对边界值和数据类型的敏感度。
这道题不是简单的逆序对变种,而是检验你是否真正理解分治计数本质的“试金石”,学会它,你对归并排序的应用将更加灵活~
特别忠告:如果你是第一次读到我的算法博客建议先去看下我的上上篇博客 力扣 LCR 170. 交易逆序对的总数 ,我们要先确保完全掌握“归并排序解决逆序对”的核心逻辑,理解“拆分-统计-合并”的基本流程。本题的计数条件更复杂,需要在已有基础上调整指针移动规则,基础不牢可能导致核心逻辑理解断层,当然老朋友可以放心食用,这道题虽说是困难但是对于老朋友来说结合逆序对那道题的思路可以说很简单!
题目解析
乍一看,不少朋友可能会有点懵,没法一下子把这道题和我们前几天练的题目联系起来——实话说,我第一遍做的时候也没反应过来,还在傻乎乎地既判断i<j的位置关系,又纠结二倍的数值约束,思路特别零散。
其实咱们把这道题“翻译”一下就通透了:它要找的“反转对”,本质就是满足“前面的数 > 后面的数的二倍”的数对。这么一来是不是瞬间就和逆序对对上了?核心都是找“前大后小”的数对,只不过反转对在大小差距上多了个“二倍”的要求而已~

算法原理
暴力解法(超时)
最直观的思路是双重循环枚举所有 i < j 的 pairs,检查 nums[i] > 2*nums[j] 并计数:
int reversePairs(vector<int>& nums) {int count = 0;for (int i = 0; i < nums.size(); i++) {for (int j = i + 1; j < nums.size(); j++) {if (nums[i] > 2LL * nums[j]) { // 用2LL避免溢出count++;}}}return count;
}
但该解法时间复杂度为 O(n²),对于 n = 5*10^4 的数据规模,必然超时。因此需要更高效的算法——归并排序的分治思想仍然适用,但计数逻辑需要调整。
归并排序解法
与逆序对问题类似,反转对总数可拆分为三部分:
- 左子数组内部的反转对数量
- 右子数组内部的反转对数量
- 左子数组元素与右子数组元素形成的反转对数量(跨数组反转对)
通过递归处理左右子数组,可解决前两部分;第三部分则需要在合并阶段统计,关键是利用子数组的有序性优化计数效率。
关键差异:为什么不能在排序时同步计数?
普通逆序对(nums[i] > nums[j])可在合并排序时同步计数,因为排序的比较条件(nums[i] > nums[j])与计数条件一致。但本题中:
- 计数条件是
nums[i] > 2*nums[j] - 排序条件仍需基于
nums[i] > nums[j](保证子数组有序性,点不用担心在归并前我们的有序性自然满足,有疑问的朋友请看 力扣 LCR 170. 交易逆序对的总数 其中对这部分进行了详细解释)
两者并不一致,因此必须先统计跨数组反转对,再进行合并排序,形成“计数-排序”的两阶段处理流程。
两种计数思路
思路1:关注左子数组元素(降序排序)
核心逻辑:
对左右子数组进行降序排序,对于左子数组的每个元素 nums[cur1],找到右子数组中所有满足 nums[cur1] > 2*nums[cur2] 的元素,累加计数。
-
当
nums[cur1] > 2*nums[cur2]时:
此时右子数组中cur2及右侧所有元素都满足条件(因数组降序,2*nums[cur2]是当前最大的,此时的nums[cur1]都比2*nums[cur2]大那么cur2后面的数一定比目前的2*nums[cur2]小,那么nums[cur1]一定大于后面的),因此计数增加right - cur2 + 1,如下图👇:

统计结束,此时cur1++。 -
否则:
cur2++寻找更小的元素。
细节解释:
至于为什么每次 cur1 移动后 cur2 不用回退,cur2 前的部分表示前面的两倍是比之前的 cur1 大的当cur1++后只会变得更小,cur2 前面的二倍依然大于目前的 cur1 所以不用回退,细节如下图👇:

思路2:关注右子数组元素(升序排序)
核心逻辑:对左右子数组进行升序排序,对于右子数组的每个元素 nums[cur2],找到左子数组中所有满足 nums[cur1] > 2*nums[cur2] 的元素,累加计数。
-
当
nums[cur1] > 2*nums[cur2]时:
左子数组中cur1及右侧所有元素都满足条件(因左子数组升序,nums[cur1]是当前最小的),因此计数增加mid - cur1 + 1。

统计结束,此时cur2++。 -
否则:
cur1++寻找更大的元素。
细节解释:
至于为什么每次 cur2 移动后 cur1 不用回退,同理因为右子数组升序,cur2 右侧元素更大,不可能再与 cur1 左侧元素形成反转对。

指针不用回退的细节总结
两种思路的指针移动逻辑均基于子数组的有序性:
- 思路1中,左子数组降序,右子数组降序。若
nums[cur1]满足条件,则cur1+1元素更小,无需再检查cur2左侧元素(已处理过)。 - 思路2中,左子数组升序,右子数组升序。若
nums[cur2]满足条件,则cur2+1元素更大,无需再检查cur1左侧元素(已处理过)。
这种“单向移动”保证了计数的高效性(O(n) 时间完成跨数组统计)。
代码实现
思路1:降序排序
class Solution {
public:vector<int> marknums; // 临时数组,用于合并排序int reversePairs(vector<int>& nums) {int n = nums.size();marknums.resize(n);return Msort(nums, 0, n - 1);}int Msort(vector<int>& nums, int left, int right) {if (left >= right) return 0; // 递归终止// 1. 拆分:递归处理左右子数组int mid = left + (right - left) / 2;int ret = 0;ret += Msort(nums, left, mid); // 左子数组内部反转对ret += Msort(nums, mid + 1, right); // 右子数组内部反转对// 2. 统计跨数组反转对(左子数组元素 > 2*右子数组元素)int cur1 = left, cur2 = mid + 1;while (cur1 <= mid && cur2 <= right) {if (nums[cur1] > 2LL * nums[cur2]) {// 右子数组中cur2及右侧元素均满足条件ret += right - cur2 + 1;cur1++; // 左指针右移(当前元素已处理完所有可能的右元素)} else {cur2++; // 右指针右移(寻找更小的元素)}}// 3. 合并左右子数组为降序(为上层递归提供有序子数组)cur1 = left;cur2 = mid + 1;int i = 0;while (cur1 <= mid && cur2 <= right) {// 降序排序:取较大元素marknums[i++] = nums[cur1] > nums[cur2] ? nums[cur1++] : nums[cur2++];}// 处理剩余元素while (cur1 <= mid) marknums[i++] = nums[cur1++];while (cur2 <= right) marknums[i++] = nums[cur2++];// 复制回原数组for (int k = left; k <= right; k++) {nums[k] = marknums[k - left];}return ret;}
};
思路2:升序排序
class Solution {
public:vector<int> marknums; // 临时数组,用于合并排序int reversePairs(vector<int>& nums) {int n = nums.size();marknums.resize(n);return Msort(nums, 0, n - 1);}int Msort(vector<int>& nums, int left, int right) {if (left >= right) return 0; // 递归终止// 1. 拆分:递归处理左右子数组int mid = left + (right - left) / 2;int ret = 0;ret += Msort(nums, left, mid); // 左子数组内部反转对ret += Msort(nums, mid + 1, right); // 右子数组内部反转对// 2. 统计跨数组反转对(左子数组元素 > 2*右子数组元素)int cur1 = left, cur2 = mid + 1;while (cur1 <= mid && cur2 <= right) {if (nums[cur1] > 2LL * nums[cur2]) {// 左子数组中cur1及右侧元素均满足条件ret += mid - cur1 + 1;cur2++; // 右指针右移(当前元素已处理完所有可能的左元素)} else {cur1++; // 左指针右移(寻找更大的元素)}}// 3. 合并左右子数组为升序(为上层递归提供有序子数组)cur1 = left;cur2 = mid + 1;int i = 0;while (cur1 <= mid && cur2 <= right) {// 升序排序:取较小元素marknums[i++] = nums[cur1] < nums[cur2] ? nums[cur1++] : nums[cur2++];}// 处理剩余元素while (cur1 <= mid) marknums[i++] = nums[cur1++];while (cur2 <= right) marknums[i++] = nums[cur2++];// 复制回原数组for (int k = left; k <= right; k++) {nums[k] = marknums[k - left];}return ret;}
};
核心细节:避免整数溢出
代码中使用 2LL * nums[cur2] 而非 2 * nums[cur2],原因是:
- 当
nums[cur2]为较大正数(如1e9)时,2 * nums[cur2]可能超过 int 类型的最大值(2^31-1),导致溢出。 2LL强制将计算转换为 long long 类型,避免溢出问题。
也可以返过来用除法防止溢出,这里为了直观我直接进行了强转。
时间复杂度与空间复杂度分析
- 时间复杂度:O(nlogn)。递归深度为 O(logn),每层的计数和合并操作均为 O(n),总复杂度为 O(nlogn)。
- 空间复杂度:O(n)。主要开销为临时数组
marknums(O(n))和递归栈(O(logn)),总空间复杂度为 O(n)。
总结
- 核心思路:通过归并排序的分治思想,将反转对统计拆分为“左内部、右内部、跨数组”三类,利用子数组有序性优化跨数组计数,将时间复杂度从 O(n²) 降至 O(nlogn)。
- 关键差异:由于计数条件(
nums[i] > 2*nums[j])与排序条件(nums[i] > nums[j]或<)不一致,需拆分“计数”和“排序”两个阶段,先统计再排序。 - 指针逻辑:基于子数组的有序性,计数时指针可单向移动(无需回退),保证高效性。
- 细节提醒:注意
2*nums[j]的整数溢出问题,需用 long long 类型进行计算。
这道题进一步拓展了归并排序在计数问题中的应用,掌握“分阶段处理”和“有序性利用”的技巧,能帮你解决更多复杂的成对计数问题。
下题预告
至此,归并排序在“分治计数”系列问题中的实战就圆满告一段落啦!通过这几道题,相信大家已经从“会用归并”升级到“活用归并”,彻底吃透了“拆分-统计-合并”的核心逻辑~
接下来,我们将开启新的篇章——聚焦 链表操作!下一道题,我们就从经典入门题 力扣 2. 两数相加 入手,不仅帮大家搞定这道题的解题思路,更会借着这道题,和大家一起系统梳理链表操作的常用技巧(比如虚拟头节点、进位处理、指针移动等),一起夯实链表基础,为后续更复杂的链表问题铺路~
感兴趣的朋友记得持续关注,咱们一起攻克链表这块“高频考点”!
Doro 带着小花🌸来啦!🌸奖励🌸看到这里的你!如果这篇内容帮你理清了反转对的解题逻辑,或是让你对归并排序的分阶段处理有了更清晰的认识,别忘了点赞支持呀!把它收藏起来,以后复习这类问题时翻出来,就能快速回忆起关键细节~关注这个博主,他会持续更新算法系列内容,有什么疑问随时讨论!
