【RL】以信息熵的角度理解RL
Note
- 《The Entropy Mechanism》 关注的是宏观的、全局的“策略熵” (Policy Entropy)。它关心的是模型在RL训练过程中的整体健康状况,特别是策略熵是否会过早 “崩溃”。
- 《Beyond the 80/20 Rule》 关注的是微观的、局部的“Token级熵” (Token-level Entropy)。它把熵当作诊断工具,去寻找推理链条中那些最关键的“分叉路口”。
- RL训练的本质,是模型在“探索多样性”(高熵)和“追求正确答案”(高奖励)之间进行的一场极限拉扯。
- 为什么会发生“熵崩溃”?论文从数学上给出了一个解释。作者推导出,策略熵的变化与一个关键因素——动作概率和优势函数(Advantage)的协方差——有关(反比关系):
- 当模型选择一个高概率的动作(token),而这个动作又带来了高奖励(高Advantage)时,强化学习算法会大力强化这个选择。
- 这种“强强联合”的更新,会导致这个高概率动作的概率变得更高,其他动作的概率被压制,从而使得整个概率分布的熵急剧下降。
- RL for Reasoning的有效性,几乎完全来自于对这20%高熵“关键少数”的优化。
- RL并不是在机械地加强一整条“正确答案”的路径。它真正的作用,是帮助模型学会在那些充满不确定性的关键决策点,如何做出更优的选择。那80%的低熵部分,模型在SFT阶段已经学得很好了,再用RL去“用力”,反而是浪费计算资源,甚至可能破坏模型的语言流畅性。
文章目录
- Note
- 一、熵、交叉熵、KL散度
- 二、微观的Token熵与宏观的策略熵
- 1、奖励的提升 ≈ 熵的消耗
- 2、为啥会发生熵崩溃
- 3、二八原则
- Reference
一、熵、交叉熵、KL散度
《The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models》
https://arxiv.org/abs/2505.22617
《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》
https://arxiv.org/abs/2506.01939
交叉熵,信息熵和KL散度之间存在以下关系:
交叉熵 (H(P,Q))=信息熵 (H(P))+KL散度 (DKL(P∥Q))\text { 交叉熵 }(H(P, Q))=\text { 信息熵 }(H(P))+\mathrm{KL} \text { 散度 }\left(D_{K L}(P \| Q)\right) 交叉熵 (H(P,Q))= 信息熵 (H(P))+KL 散度 (DKL(P∥Q))
二、微观的Token熵与宏观的策略熵
1、奖励的提升 ≈ 熵的消耗
奖励的提升 ≈ 熵的消耗
论文发现了一个经验公式:R=−a⋅eH+bR=-a \cdot e^H+bR=−a⋅eH+b ,其中 RRR 是奖励,HHH 是熵。这个公式明确告诉我们:奖励的提升,是用熵的消耗换来的。当熵(探索能力)耗尽时,性能的提升也就到头了。
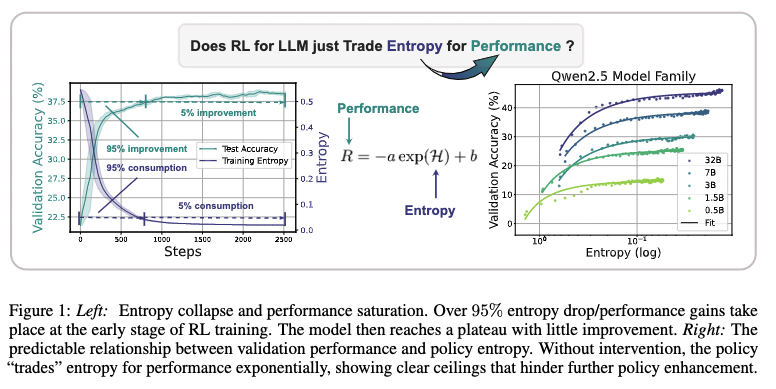
2、为啥会发生熵崩溃
为什么会发生“熵崩溃”?论文从数学上给出了一个解释。作者推导出,策略熵的变化与一个关键因素——动作概率和优势函数(Advantage)的协方差——有关(反比关系)。原文中的公式比较复杂,感兴趣的读者可以自行拜读。这里提供一个通俗易懂的说法(在数学上不一定严谨)。简单来说:
• 当模型选择一个高概率的动作(token),而这个动作又带来了高奖励(高Advantage)时,强化学习算法会大力强化这个选择。
• 这种“强强联合”的更新,会导致这个高概率动作的概率变得更高,其他动作的概率被压制,从而使得整个概率分布的熵急剧下降。
在RL训练初期,模型很容易找到一些“低垂的果实”,即一些简单、高回报的捷径。于是模型疯狂地在这些路径上进行自我强化,导致协方差持续为正,熵一路狂跌,最终“熵崩溃”,探索能力耗尽。
为了解决这个问题,论文提出了Clip-Cov和KL-Cov等方法,核心思想就是限制那些高协方差token的更新幅度。翻译成大白话就是:“我知道你这个选择又自信又正确,但你先别太激动,悠着点更新,给别的可能性留点机会。”
3、二八原则
《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》
https://arxiv.org/abs/2506.01939
RL训练真正起作用的,是优化那些“高熵”的关键决策点。
文章发现了一个“二八定律”:
- 80%的Token是低熵的:这些是推理过程中的“废话”或确定性的计算步骤(比如“因此”、“答案是”、“=”等)。模型生成这些词时很确定,RL训练对它们用力是白费功夫。
- 20%的Token是高熵的:这些才是真正的 “思维分叉路口” !比如,在解一道数学题时,决定“是先求面积还是先求周长?”;在逻辑推理中,决定“这个证据是支持A观点还是B观点?”。在这些节点上,模型非常纠结,熵很高。
研究者做了对比实验:
- 正常RL训练:更新所有Token。
- 只更新高熵Token:只在那20%的关键决策点上进行RL训练。
- 只更新低熵Token:只在那80%的“废话”上进行RL训练。
结果令人震惊:
- “只更新高熵Token”的效果,和“正常RL训练”差不多,有时甚至更好!
- “只更新低熵Token”的效果一塌糊涂。
实验结论:RL并不是在机械地加强一整条“正确答案”的路径。它真正的作用,是帮助模型学会在那些充满不确定性的关键决策点,如何做出更优的选择。那80%的低熵部分,模型在SFT阶段已经学得很好了,再用RL去“用力”,反而是浪费计算资源,甚至可能破坏模型的语言流畅性。
Reference
[1] https://zhuanlan.zhihu.com/p/1954330684970754139
[2] 《The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models》
[3]《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》
[4] 以信息熵的角度解构RL!大白话讲从“熵”到“RL”的探索之路