『 数据库 』MySQL复习 - 查询进阶指南:基于经典测试表的复合查询实践
文章目录
- 1 例表
- 2 基本查询回顾
- 2.1 查询工资高于500或岗位为MANAGER的雇员, 同时还要满足他们的姓名首写为J
- 2.2 按照部门号升序而雇员工资降序
- 2.3 按照年薪进行降序排序
- 2.4 显示工资最高的员工名字和工作岗位 (子查询)
- 2.5 显示工资高于平均工资的员工信息
- 2.7 显示每个部门的平均工资和最高工资
- 2.8 显示平均工资低于 2000 的部门号和它的平均工资
- 2.9 显示每种岗位的雇员总数和平均工资
- 3 多表查询
- 3.1 多表笛卡尔积
- 3.2 显示雇员名, 雇员工资以及所在部门的名字
- 3.3 显示部门号为10的部门名, 雇员名与薪资
- 3.4 显示各个员工的姓名, 薪资以及薪资级别
- 3.5 自连接
- 4 子查询
- 4.1 单行子查询
- 4.2 多行子查询
- 4.3 多列子查询
- 4.4 在 from 子句中使用的子查询
- 4.4.1 显示每个高于自己部门平均工资的姓名, 部门, 工资, 平均工资
- 4.4.2 查找每个部门工资最高的人的姓名, 工资, 部门以及最高工资
- 4.4.3 显示每个部门的信息 (部门名, 编号, 地址)和人员数量
- 4.5 合并查询
- 4.5.1 UNION 关键字
- 4.5.2 UNION ALL 关键字
- 5 表的内外连接
- 5.1 内连接
- 5.2 外连接
- 5.2.1 左外连接
- 5.2.2 右外连接
- 5.2.3 练习
- 6 总结
1 例表
该章节所需表表为如下:
- oracle9i经典测试用表
三张表的内容分别为如下:
-
emp表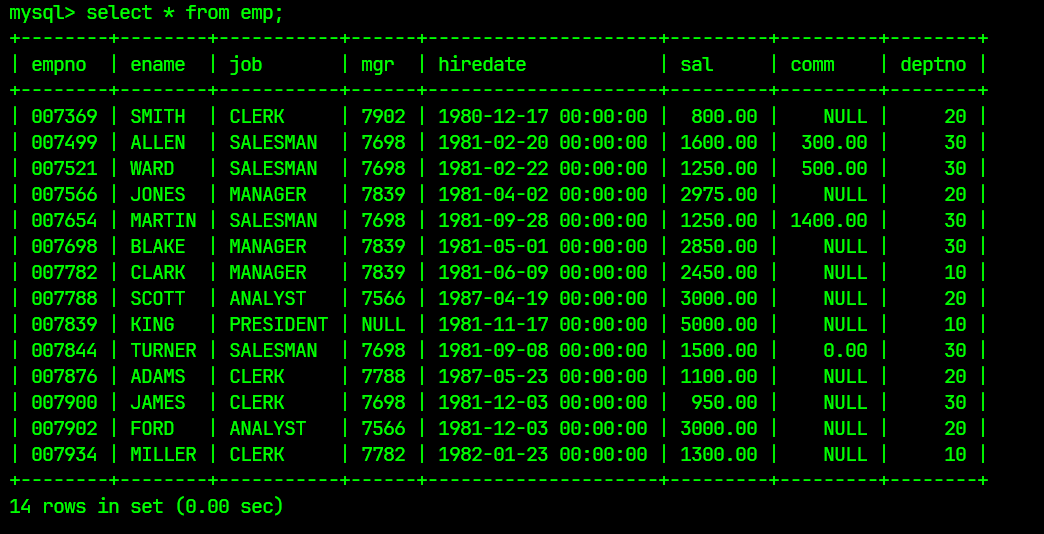
-
dept表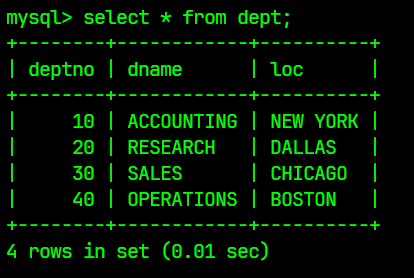
-
salgrade表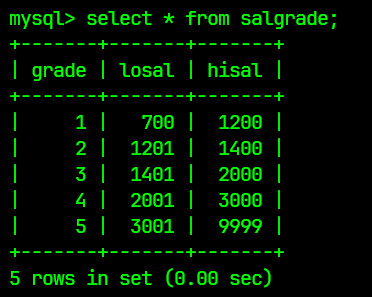
2 基本查询回顾
复合查询前回顾基本查询内容, 以为符合查询进行对应的准备;
2.1 查询工资高于500或岗位为MANAGER的雇员, 同时还要满足他们的姓名首写为J
这里分为几个条件:
- 查询工资高于
500或岗位为MANAGER - 上述条件满足后需要找到姓名首写字母为大写的
J
那么这样的条件就是1 AND 2(即SELECT ... FROM ... WHERE (工资高于500 OR 岗位为MANAGER) AND 姓名首写为 J );
所需的表为emp表, 其SQL语句为:
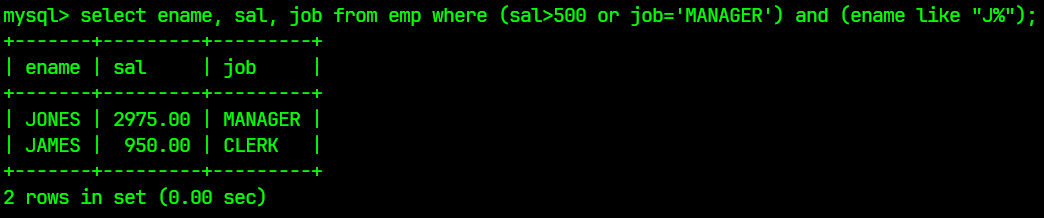
select ename, sal, job from emp where (sal>500 or job='MANAGER') and (ename like "J%");
结果为:
也可以使用内置函数:
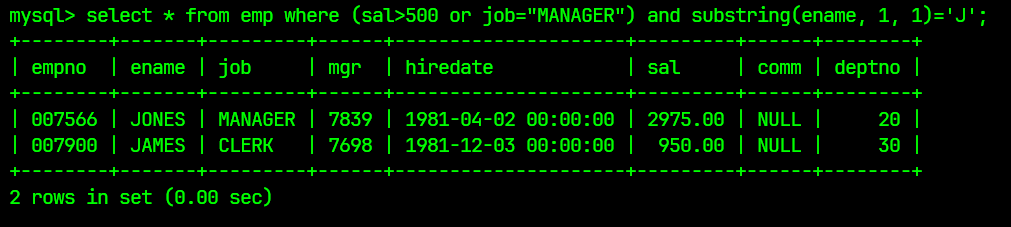
select * from emp where (sal>500 or job="MANAGER") and substring(ename, 1, 1)='J';
结果为:
2.2 按照部门号升序而雇员工资降序
这里的两个条件都是ORDER BY条件:
-
首要排序规则
部门号升序;
-
次要排序规则
雇员工资降序
对应的SQL语句即为:
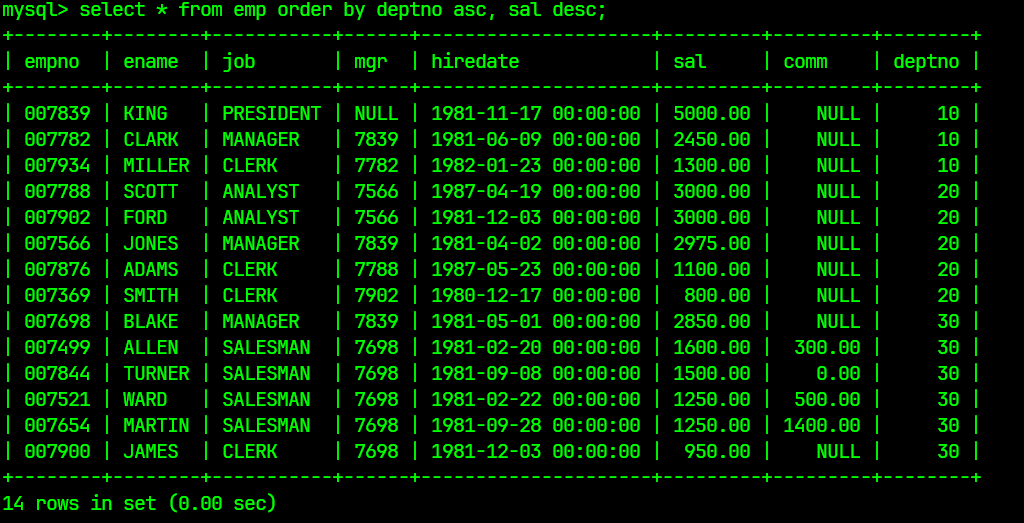
select * from emp order by deptno asc, sal desc;
结果为:
2.3 按照年薪进行降序排序
年薪即为sal * 12 + comm;
但是在emp表中的comm列存在很多NULL值, 而与NULL值进行计算的结果都为NULL;
mysql> select 100+NULL;
+----------+
| 100+NULL |
+----------+
| NULL |
+----------+
1 row in set (0.00 sec)
因此此处除了加上comm以外还需要将NULL排除;
可以采用IFNULL()函数来进行判断;
因此SQL语句为:
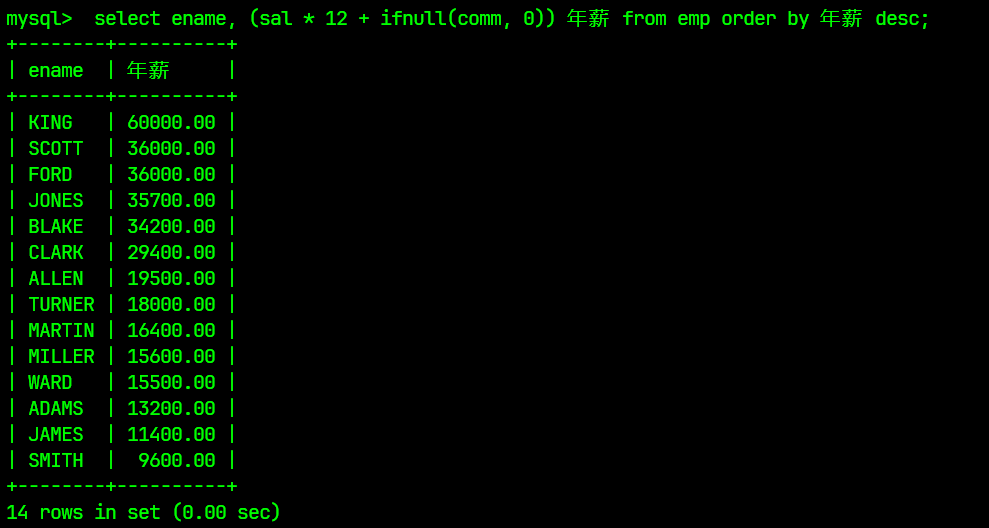
select ename, (sal * 12 + ifnull(comm, 0)) 年薪 from emp order by 年薪 desc;
结果为:
2.4 显示工资最高的员工名字和工作岗位 (子查询)
这一题的解法可以采用order by降序的方式对sal进行排序, 首行即为工资最高的员工, 此时使用limit 1, 1取其名字与岗位即可;
对应的SQL语句为:
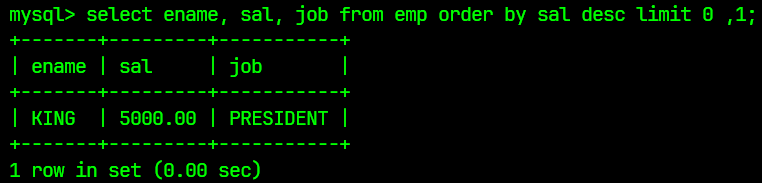
select ename, sal, job from emp order by sal desc limit 0 ,1;
或
select ename, sal, job from emp order by sal desc limit 1;
对应的结果为:
而实际上除了这种方式以外, 我们可以使用聚合函数MAX()来获取某一列的最大值, 但遗憾的是如果使用聚合函数来获取最大值, 对应的就不能将另外两列(姓名, 岗位)展现出来;

因此可以将这个语句变为两个步骤:
-
通过聚合函数找到最高的工资
mysql> select max(sal) from emp; +----------+ | max(sal) | +----------+ | 5000.00 | +----------+ 1 row in set (0.00 sec) -
找到通过最高的工资找到对应记录的姓名, 工资以及岗位
mysql> select ename, sal, job from emp where sal=5000; +-------+---------+-----------+ | ename | sal | job | +-------+---------+-----------+ | KING | 5000.00 | PRESIDENT | +-------+---------+-----------+ 1 row in set (0.00 sec)
而在MySQL中支持一种子查询的查询方式, 即为一条查询语句中可以嵌套另一条查询语句, 以此进行更为精确的查询;
对应的SQL语句为:
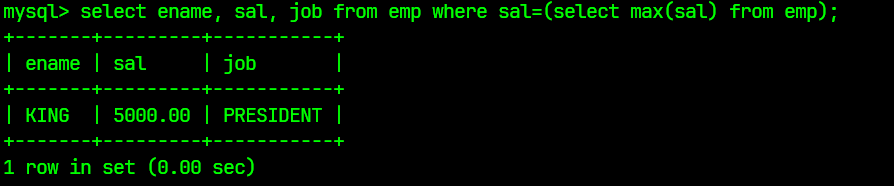
select ename, sal, job from emp where sal=(select max(sal) from emp);
对应的查询结果为:
2.5 显示工资高于平均工资的员工信息
与 2.4 相同, 只不过where条件由 = 变为 > ;
对应的查询语句为:
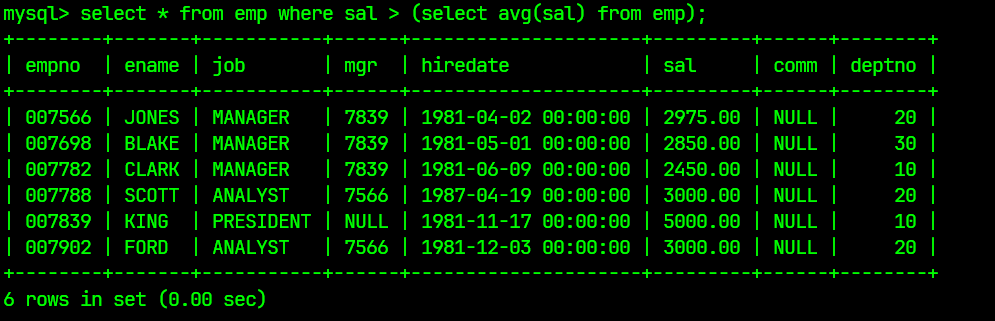
select * from emp where sal > (select avg(sal) from emp);
结果为:
2.7 显示每个部门的平均工资和最高工资
这里要求是每个部门, 因此需要用GROUP BY对部门进行分组, 而后通过聚合函数AVG()和MAX()来聚合对应的结果(工资);
对应SQL语句为:
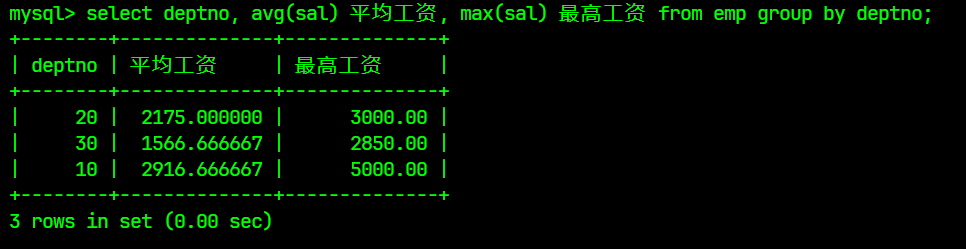
select deptno, avg(sal) 平均工资, max(sal) 最高工资 from emp group by deptno;
结果为:
2.8 显示平均工资低于 2000 的部门号和它的平均工资
这一个查询可以将问题拆成几个部分:
-
查询所有部门的平均工资
这里需要查到所有部门的平均工资也意味着需要使用
GROUP BY对deptno进行分组;而后再使用
avg()函数来找到他的平均工资;mysql> select deptno, avg(sal) 平均工资 from emp group by deptno; +--------+--------------+ | deptno | 平均工资 | +--------+--------------+ | 20 | 2175.000000 | | 30 | 1566.666667 | | 10 | 2916.666667 | +--------+--------------+ 3 rows in set (0.00 sec) -
找到平均工资
<2000的部门号和它的平均工资而后后加条件是查询平均工资少于
2000的记录, 而此处无法使用where语句对聚合函数的结果与别名进行展示, 因此需要使用HAVING语句对聚合的结果进行追加条件;
因此最终的SQL语句为:
select deptno, avg(sal) 平均工资 from emp group by deptno having 平均工资 < 2000;
结果为:

2.9 显示每种岗位的雇员总数和平均工资
这个与2.8相差无异, 主要是使用group by对岗位进行分组, 而后使用聚合函数COUNT()与AVG()分别对雇员数量和工资进行聚合;
对应的SQL语句为:
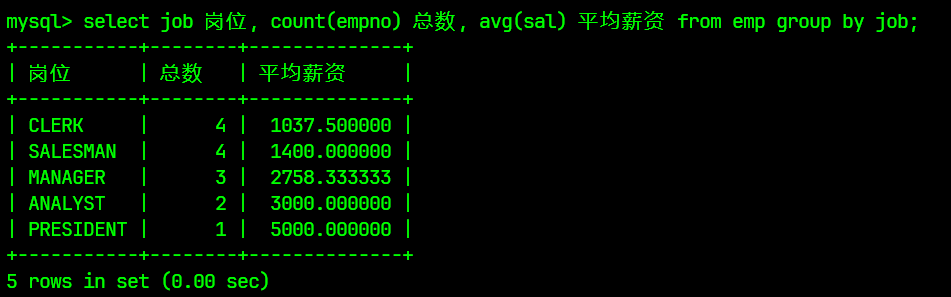
select job 岗位, count(empno) 总数, avg(sal) 平均薪资 from emp group by job;
结果为:
3 多表查询
通常情况下, 为了高内聚低耦合, 所查询的记录不一定只在一张表中所体现, 而是在多张表中体现, 多表通过一些外键等其他的约束进行关联, 因此表的查询不仅仅需要单表查询, 更需要多表查询;
如在 Oracle 9i经典测试用表中, 不同的关键数据被存储在不同的表之中, 在emp表中只有部门的编号而没有部门的名字;
而部门的名字在dept表中;
3.1 多表笛卡尔积
所谓的多表笛卡尔积是两张即以上的表的记录进行整合;
如假设存在两张表:
-
table_Amysql> create table if not exists table_A(-> val varchar(5)-> ); Query OK, 0 rows affected (0.03 sec)mysql> insert into table_A values ('A1'), ('A2'), ('A3'), ('A4'), ('A5'); Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0mysql> select * from table_A; +------+ | val | +------+ | A1 | | A2 | | A3 | | A4 | | A5 | +------+ 5 rows in set (0.00 sec) -
table_Bmysql> insert into table_B values ('B1'), ('B2'), ('B3'), ('B4'), ('B5'); Query OK, 5 rows affected (0.01 sec) Records: 5 Duplicates: 0 Warnings: 0mysql> select * from table_B; +------+ | val | +------+ | B1 | | B2 | | B3 | | B4 | | B5 | +------+ 5 rows in set (0.00 sec)
进行笛卡尔积的语句也很简单, 即from table_name的时候table_name有两张及以上的表即可以进行笛卡尔积;
即:
select * from table_A, table_B;
笛卡尔积会将所有有可能的记录进行穷举排列, 因此上述的查询语句执行结果将为:
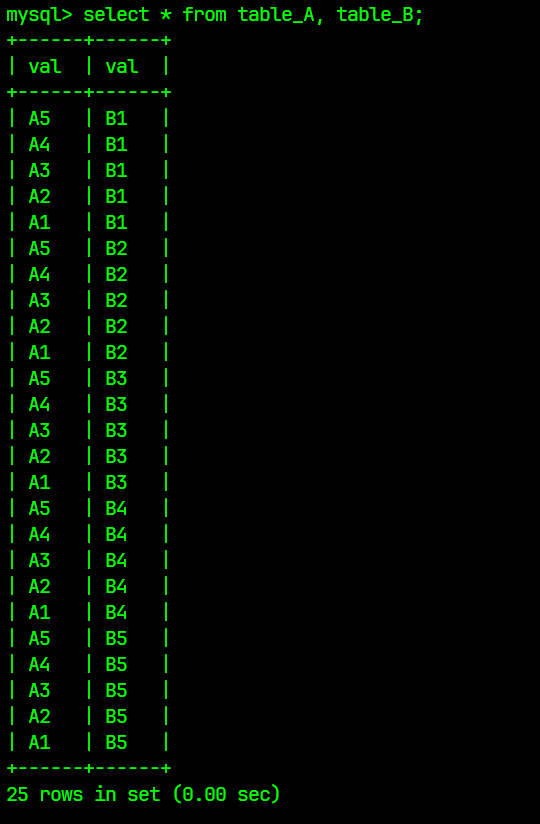
可以看到table_A表的所有记录和table_B表的所有记录进行了穷举组合, 每张表的记录为5条, 因此这个笛卡尔积的记录为25条;
mysql> select count(*) from table_A, table_B;
+----------+
| count(*) |
+----------+
| 25 |
+----------+
1 row in set (0.00 sec)
3.2 显示雇员名, 雇员工资以及所在部门的名字
由于雇员名, 工资和所在部门的名字分别来自emp与dept两张表, 因此需要使用联合查询, 此处需要使用笛卡尔积;
对应的语句为:
select * from emp, dept;
对两张表进行笛卡尔积;
结果为:
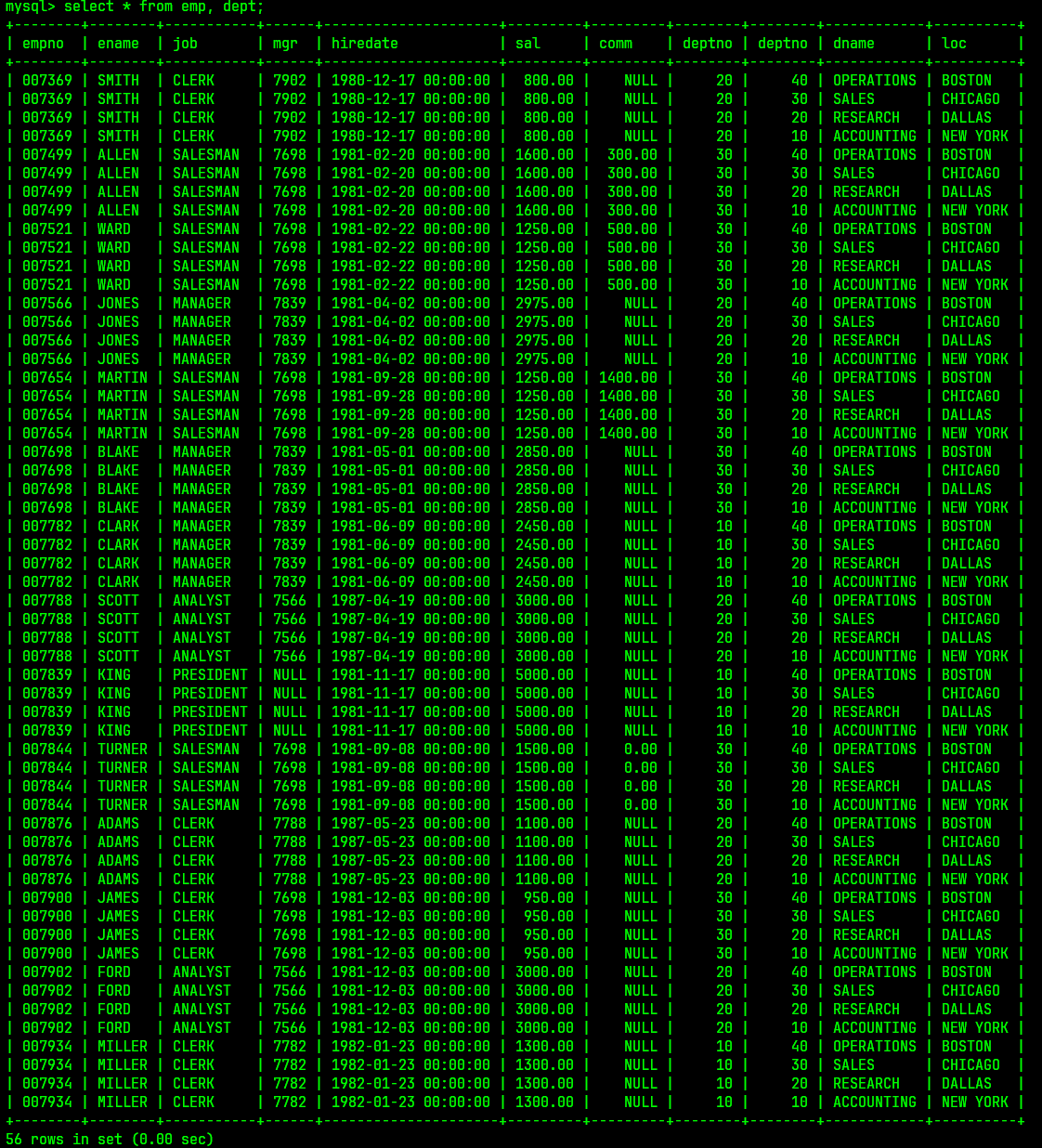
而从结果可以看出, 实际上笛卡尔积的很多结果并不如我们所愿;
在笛卡尔积的结果中出现了很多无用的记录, 如结果中存在两个deptno, 而deptno为20的记录与deptno为40的记录明显为无用的记录, 因此需要使用where语句进行条件筛选;
两个表中存在的共同列为deptno, 因此笛卡尔积后有用的记录的SQL语句为:
select * from emp, dept where emp.deptno=dept.deptno;
结果为:
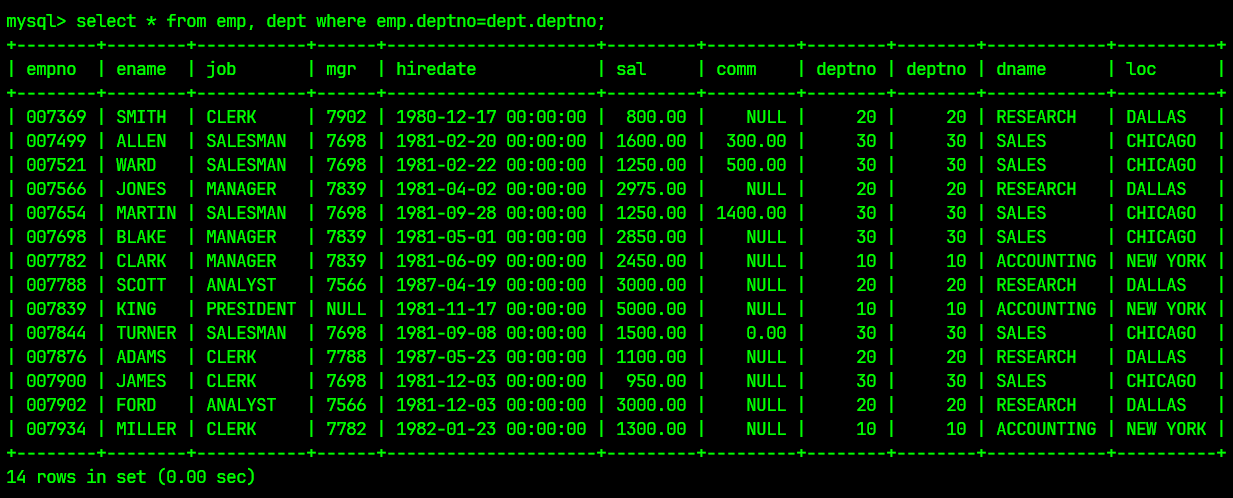
经过笛卡尔积与条件筛选后, 我们将两张表合并为了一张表, 此时重新回到题目, 可以看到我们可以对新整合出的一张表进行单表查询, 这就是笛卡尔积的最主要用法;
完整的SQL语句为:
select ename, sal, dname from emp, dept where emp.deptno=dept.deptno;
查询结果为:
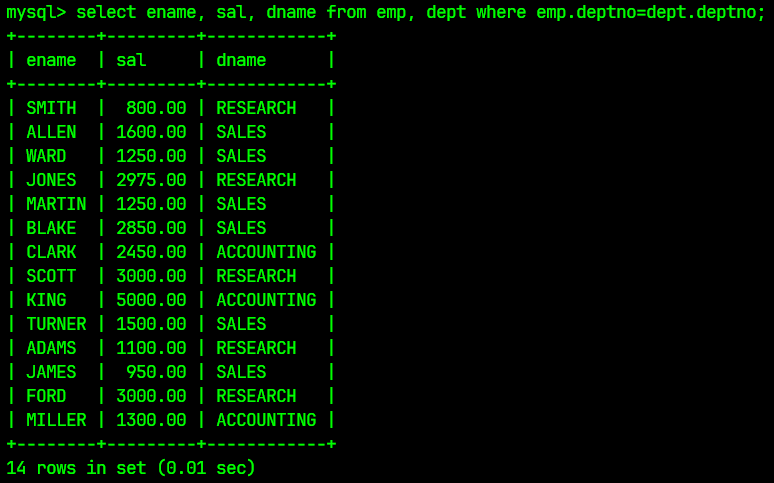
3.3 显示部门号为10的部门名, 雇员名与薪资
这个问题也是相同, 步骤为:
- 两张表进行笛卡尔积并使用
WHERE筛选出有效记录 - 将筛选出的有效记录作为一张表进行单表查询
对应的SQL语句为:
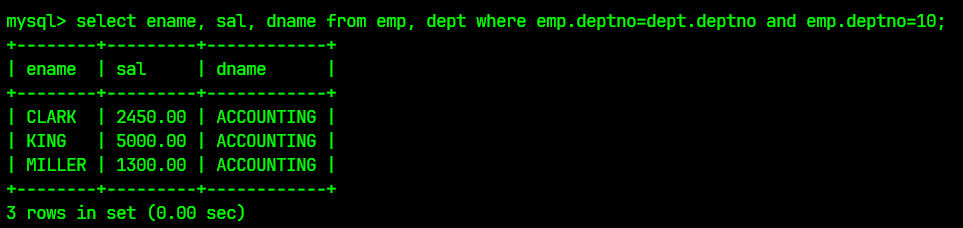
select ename, sal, dname from emp, dept where emp.deptno=dept.deptno and emp.deptno=10;
从这条SQL语句来看, 这一题只是增加了一个AND来并列其他条件;
查询结果为:
3.4 显示各个员工的姓名, 薪资以及薪资级别
其中姓名为emp表中的ename, 薪资为emp表中的sal, 薪资级别则属于为salgrade表中的grade;
这里同样对两张表进行笛卡尔积并筛选出有效数据;
其中笛卡尔积的SQL语句为:
select * from emp, salgrade;
在这张表中, 需要筛选出有效的数据不能单纯依靠=来判断, 而是需要使用其他的条件判断, > 与 <, 本质原因是两张表不存在相同的列名, 同时薪资的等级是依靠该薪资是否属于salgrade表中的[losal, hisal]范围;
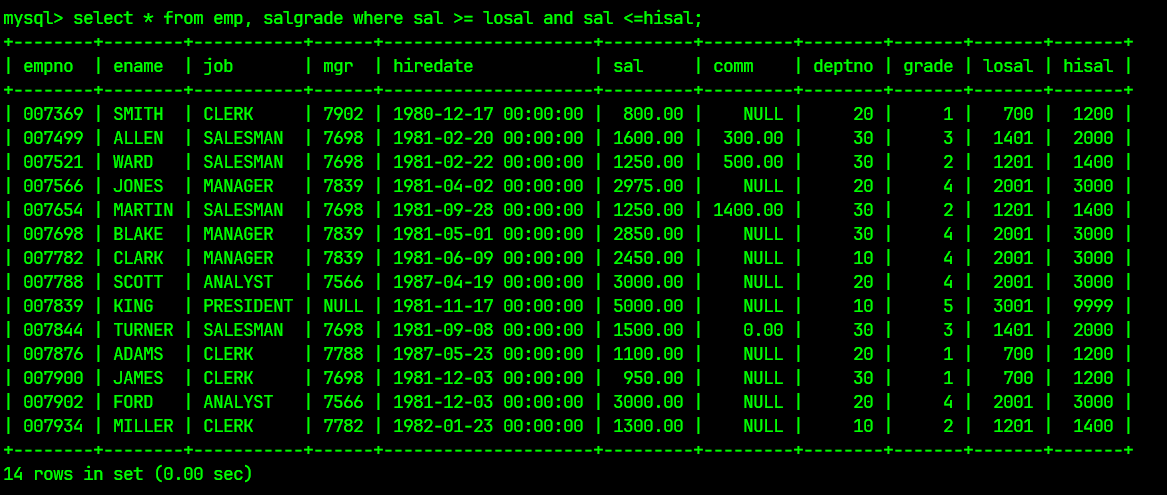
因此笛卡尔积后进行筛选的SQL语句为:
select * from emp, salgrade where sal >= losal and sal <=hisal;
筛选后的结果为:
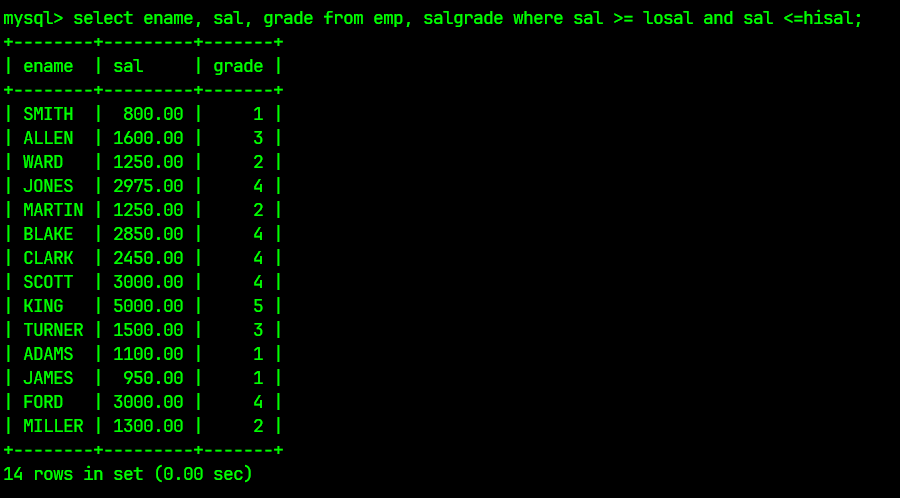
在查询到有效信息后对信息进行SELECT筛选出想要的列, 最终完整的SQL语句为:
select ename, sal, grade from emp, salgrade where sal >= losal and sal <=hisal;
筛选结果为:
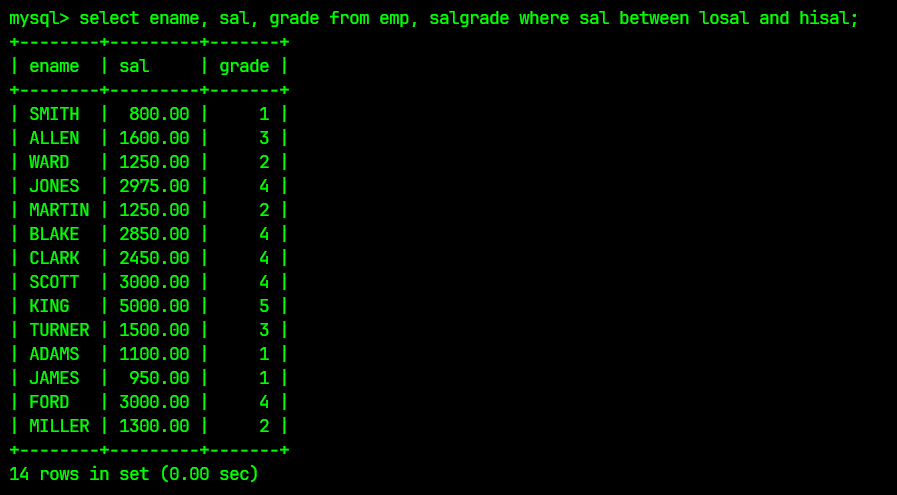
除此之外还可以使用between语句, 对应的SQL语句为:
select ename, sal, grade from emp, salgrade where sal between losal and hisal;
查询结果同样为:
3.5 自连接
自连接同样是一种多表查询, 与一般的多表查询不同的是, MySQL支持一张表与该表自身进行笛卡尔积;
如:
select * from emp as t1, emp as t2;
在这里进行自连接时无法使用from emp, emp的方式进行自连接, 本质是当进行自连接时, 需要使用as对表进行重命名以防止出现两张表都使用类似emp.deptno的方式引发的歧义;
在使用自连接后对有效记录进行筛选, 对应的SQL语句为:
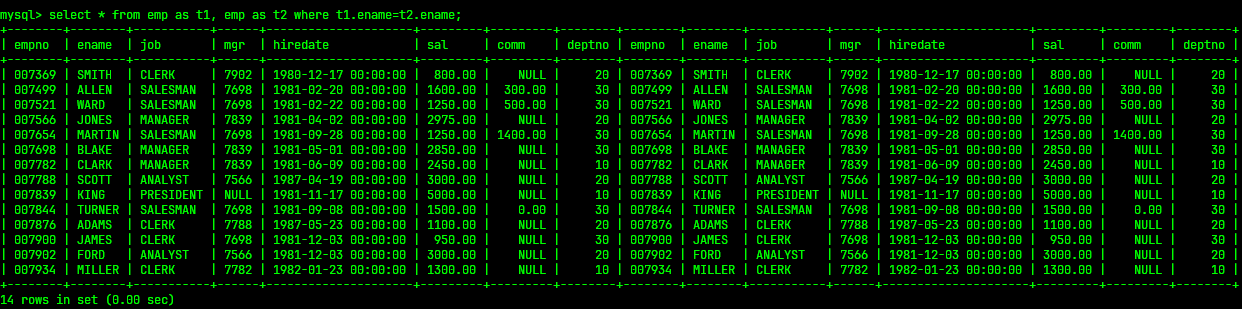
select * from emp as t1, emp as t2 where t1.ename=t2.ename;
最终的筛选结果为:
- 通常什么时候需要使用自连接?
自连接的使用方式通常为, 查询单张表中的数据, 但其数据并不属于同一列的复合查询情况;
如举个例子:
- 找出每个员工的领导
那么在这个例子下, 领导的编号为mgr, 而其名字不属于同一行的记录, 因此需要使用自连接;
首先需要表内进行自行的笛卡尔积, 即emp表的自连接;
select * from emp t1, emp t2;
而后使用where筛选无效记录的条件, 或者说筛选出有效的记录;
此处的有效记录为empno对mgr, 因此需要使用t1.empno = t2.mgr;
对应的sql语句为:
select * from emp t1, emp t2 where t1.empno=t2.mgr;
结果为: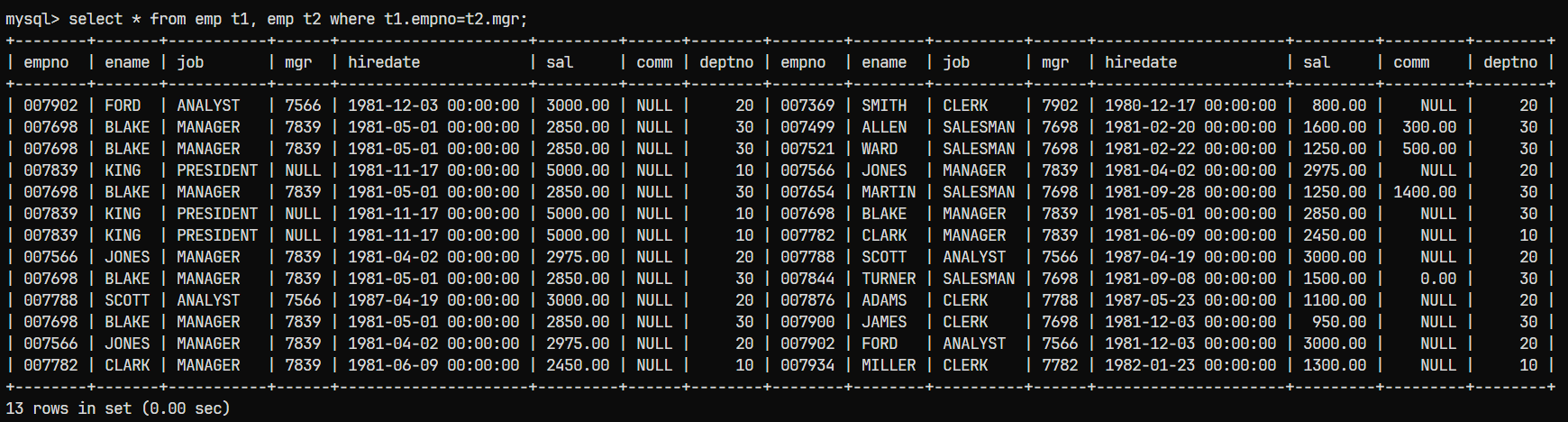
结果可以看出已经找出了每个员工的mgr;
4 子查询
在MYSQL中支持一句SELECT语句中嵌套另一条SELECT语句;
如:
select * from (select * from table_name where [...]) where [...];
即将子查询的结果视为一张临时表, 随后对该临时表进行一个查询操作;
在MySQL中一切皆为表;
4.1 单行子查询
单行子查询表示子查询结果中只有一条记录, 通常我们可以将返回一条记录的子查询作为条件的一部分, 这个条件比较可以是=, >, <, between … 等;
如:
- 显示
SMITH同一部门的员工
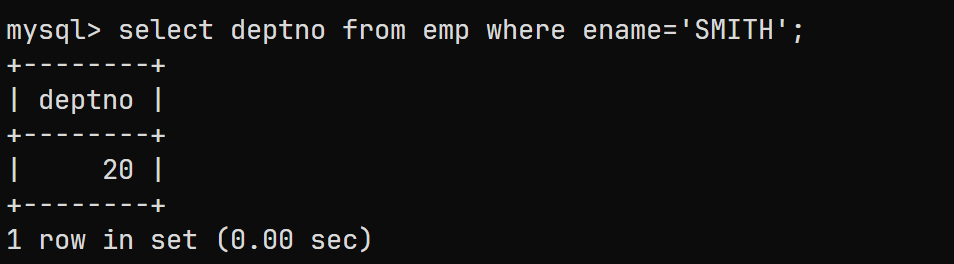
对于该问题而言, 可以先通过子查询找出SMITH的部门号:
select deptno from emp where ename='SMITH';
结果为:
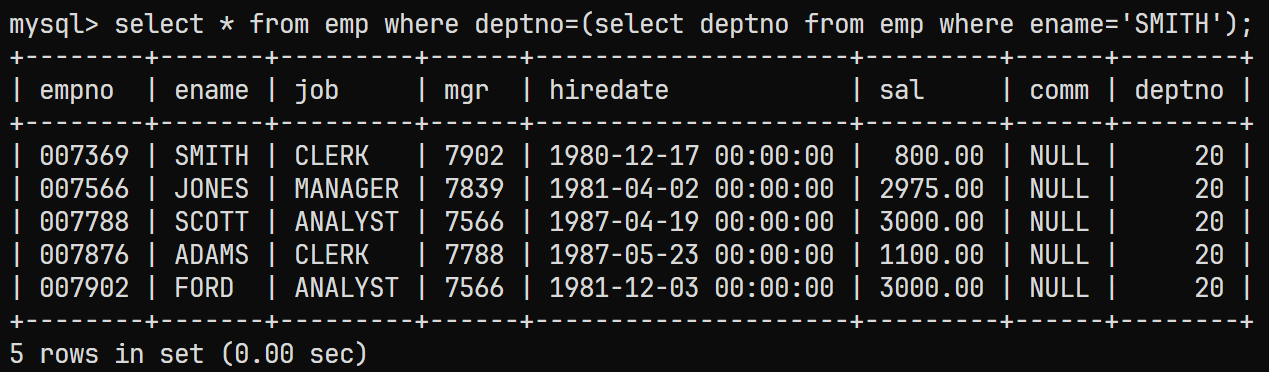
找到部门号后对整个emp表进行查询, 并通过deptno = (子查询结果)的方式:
select * from emp where deptno=(select deptno from emp where ename='SMITH');
结果为:
4.2 多行子查询
多行子查询时, 子查询结果通常存在多行, 多行的子查询结果可以作为一个新的临时表进行使用;
-
查询和
10号部门的工作岗位相同的雇员名字, 岗位, 工资, 部门号, 但是不包含10号部门自己-
找出
10号部门的员工所有的工作岗位:select job from emp where deptno=10;结果为:
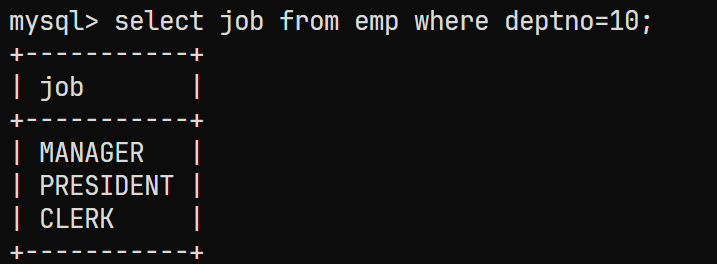
-
通过
IN子表来判断所有该工作岗位的对应所需信息的记录select ename, job, sal, deptno from emp where job in (select job from emp where deptno=10);结果为:
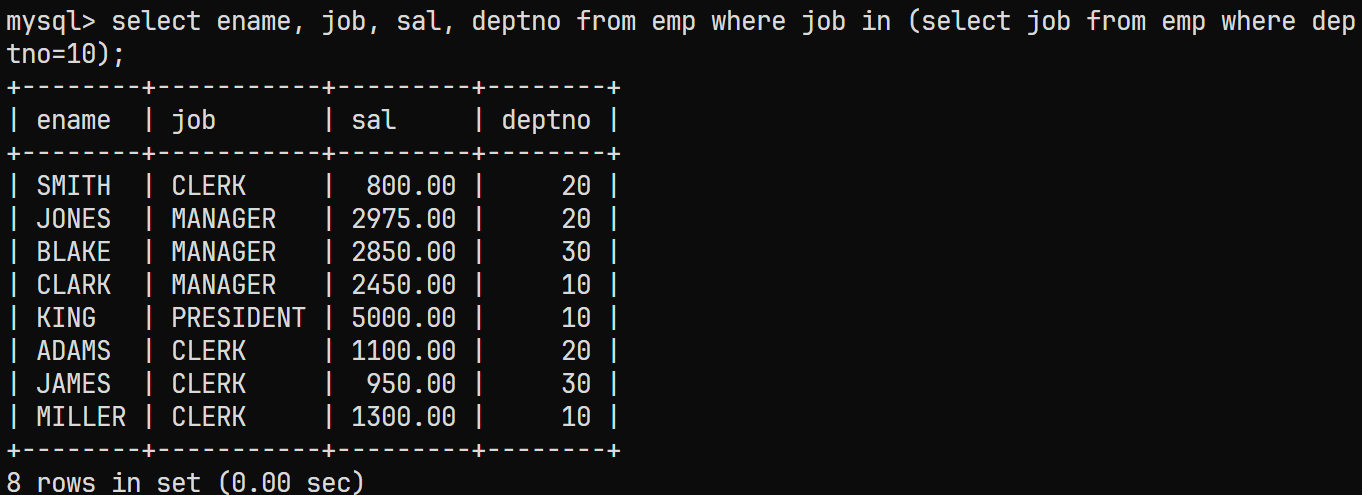
-
将所查询出的结果通过
AND增加并列条件来排除部门号为10的员工select ename, job, sal, deptno from emp where job in (select job from emp where deptno=10) and deptno <> 10; -
最终结果
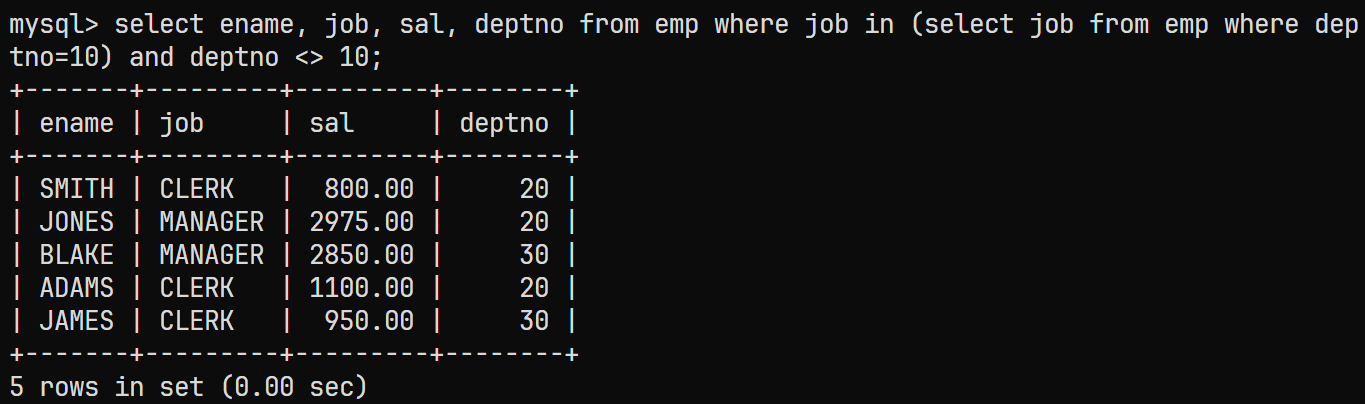
-
-
显示工资比部门
30所有员工的工资高的员工的姓名, 工资, 和部门号这里有两种解法, 分别为使用聚合函数
MAX()找出部门号为30的员工的最高工资, 还有一种方式是找出部门号30的所有员工的工资成为子表, 并通过> ALL (子表)关键字来找出比子表所有员工sal要大的记录;对应的聚合函数方式的子查询为:
select ename, sal, deptno from emp where sal > (select max(sal) from emp where deptno = 30); +-------+---------+--------+ | ename | sal | deptno | +-------+---------+--------+ | JONES | 2975.00 | 20 | | SCOTT | 3000.00 | 20 | | KING | 5000.00 | 10 | | FORD | 3000.00 | 20 | +-------+---------+--------+ 4 rows in set (0.00 sec)由于此处为多行子查询, 因此对上述的查询语句不进行解释;
多列子查询可以使用
ANY,ALL等关键字来进行配合比较;-
先找出部门号
30的所有员工的salselect sal from emp where deptno=30;结果为:
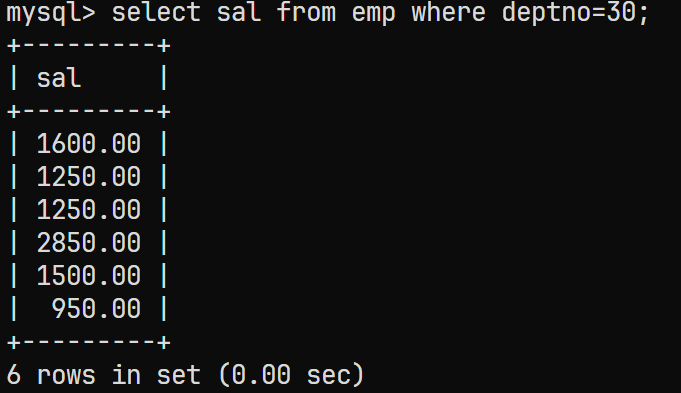
-
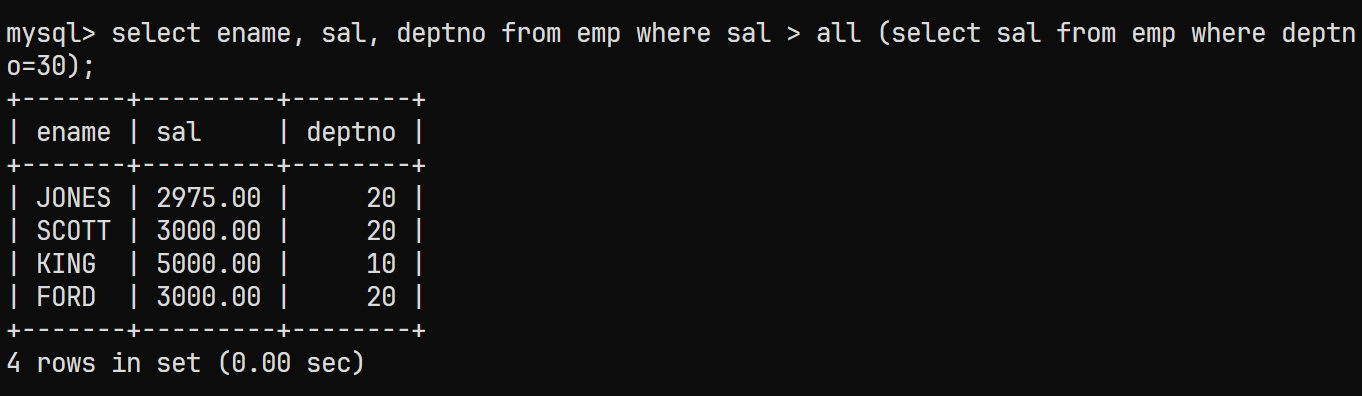
查询出子表后通过条件与关键字
ALL来比较sal大于该子查询结果表中所有sal的记录select ename, sal, deptno from emp where sal > all (select sal from emp where deptno=30); -
最终结果
-
-
显示工资比部门
30的任意员工的工资高的员工的姓名, 工资和部门号此处的条件较于宽泛, 与上一题类似, 不过在该题中可以使用
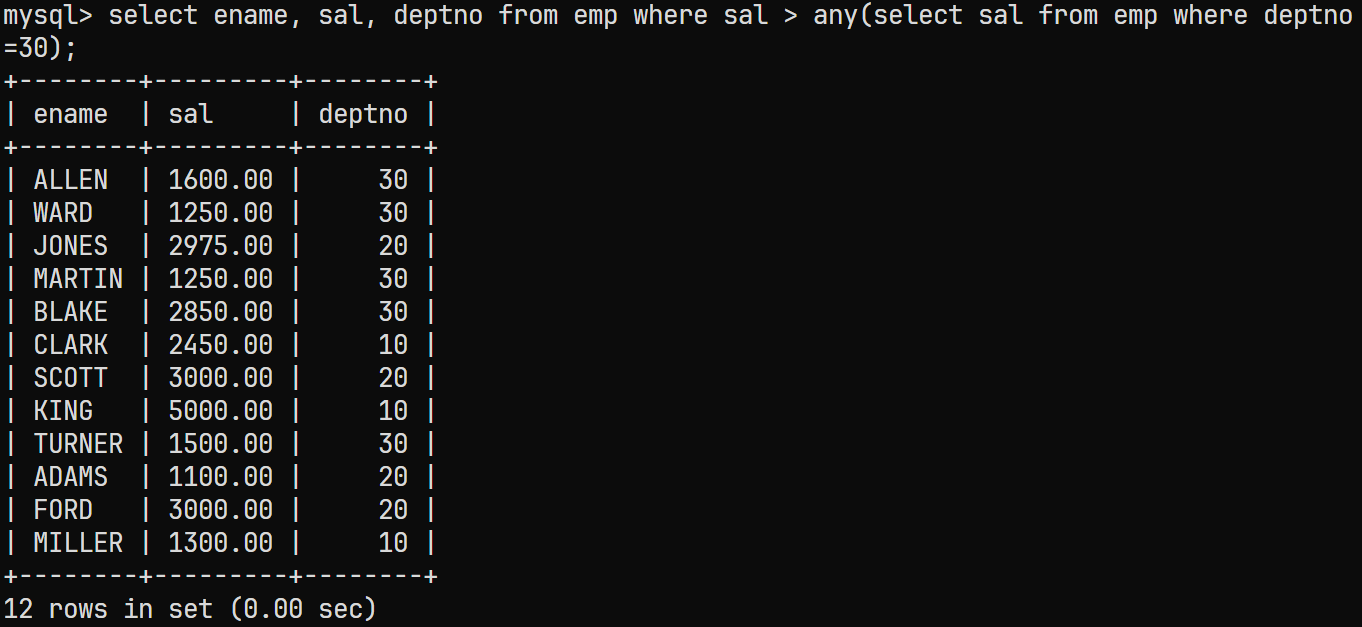
ANY关键字进行比较;对应的
SQL语句为:select ename, sal, deptno from emp where sal > any(select sal from emp where deptno=30);与
ALL不同,ANY表示任意的意思, 而ALL表示全部;该题与上一题中对应的意思是:
-
ALL子查询结果中所有的记录;
-
ANY子查询结果中的任意一条记录;
对应的结果为:
-
4.3 多列子查询
单行子查询通常表示子查询结果只返回单行单列的记录, 而多行子查询则表示子查询结果为单列多行的记录, 而多列子查询表示结果返回多个列记录的查询语句;
-
查询和
SMITH的部门和岗位完全相同的所有雇员, 不含SMITH本人;-
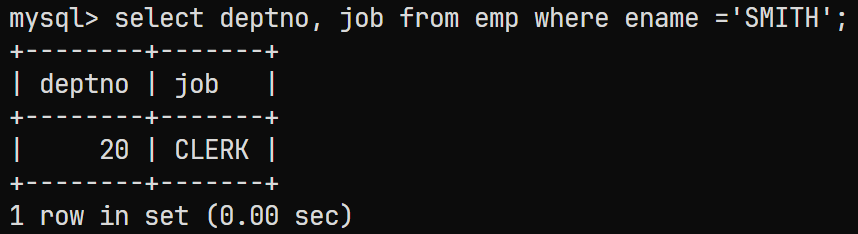
先通过子查询查出
SMITH的部门和岗位select deptno, job from emp where ename ='SMITH';结果为:
-
通过多列单行的比较来比较是否符合的记录
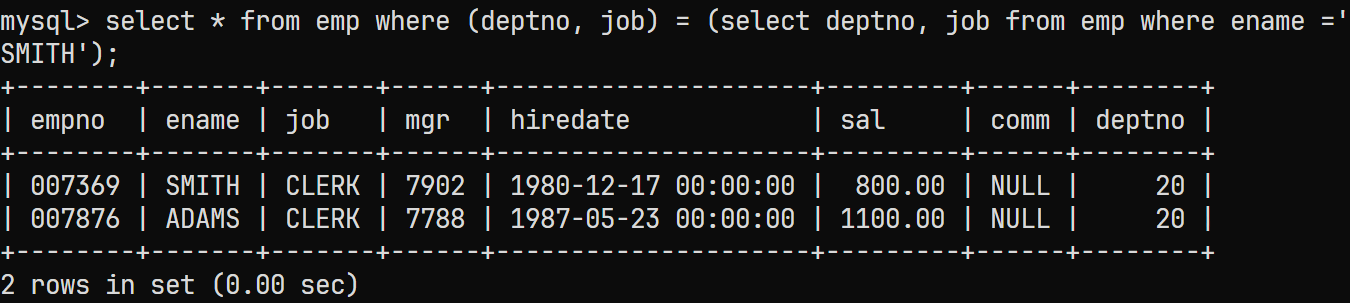
在
MySQL中支持对多列单行数据进行逻辑比较, 如= (column1, column2)等;通过该方式来查询
emp表与返回的单行多列数据进行比较的对应的sql语句为:select * from emp where (deptno, job) = (select deptno, job from emp where ename ='SMITH');结果为:
-
通过
AND增加并列条件来排除SMITH本人select * from emp where (deptno, job) = (select deptno, job from emp where ename ='SMITH') and ename <> 'SMITH'; -
最终查询结果
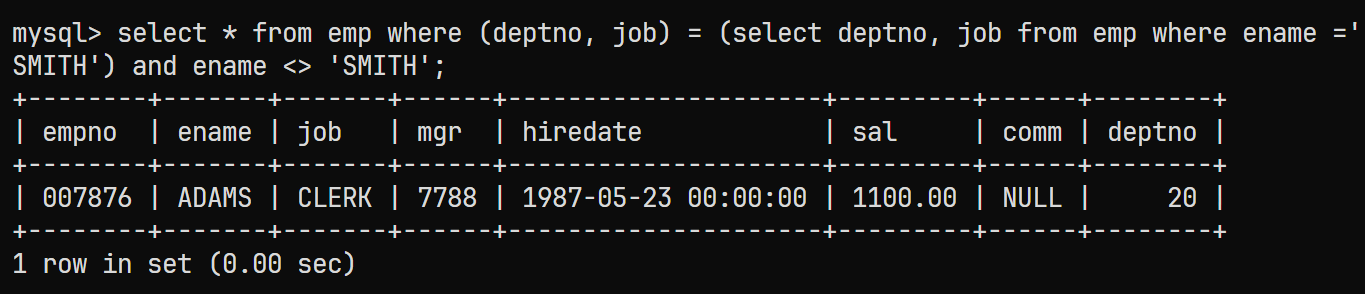
-
4.4 在 from 子句中使用的子查询
在上文中提到了, 我们可以对SELECT查询出的表作为子查询临时表, 而子查询表同样是一张表, 可以视该表为一张临时表进行查询;
4.4.1 显示每个高于自己部门平均工资的姓名, 部门, 工资, 平均工资
-
在该题中首先要准备一张子表, 该子表需要有平均工资与部门号因此来查出各个部门的平均工资
同时出现了各个部门说明需要根据部门进行
GROUP BY分组;对应的
sql语句为:select deptno, avg(sal) from emp group by deptno;结果为:
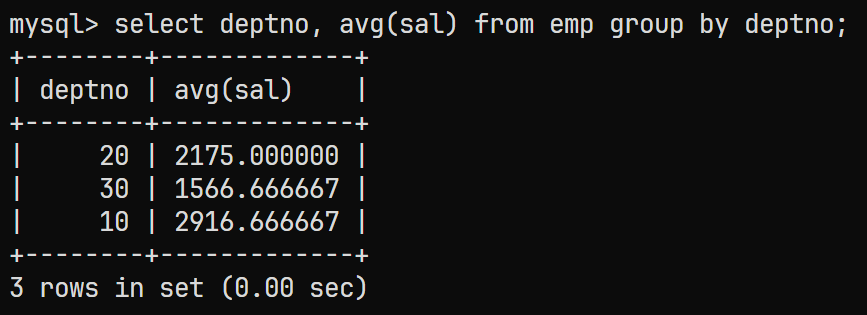
-
这张表需要与另一张表进行连接, 但由于该表与另一张表
emp的列值不同因此无法使用JOIN, 只能使用笛卡尔积的方式, 同时在笛卡尔积后需要筛选掉无用的数据select ename, emp.deptno, sal, asal from emp, (select deptno, avg(sal) asal from emp group by deptno) tmp where emp.deptno=tmp.deptno;对应的结果为:
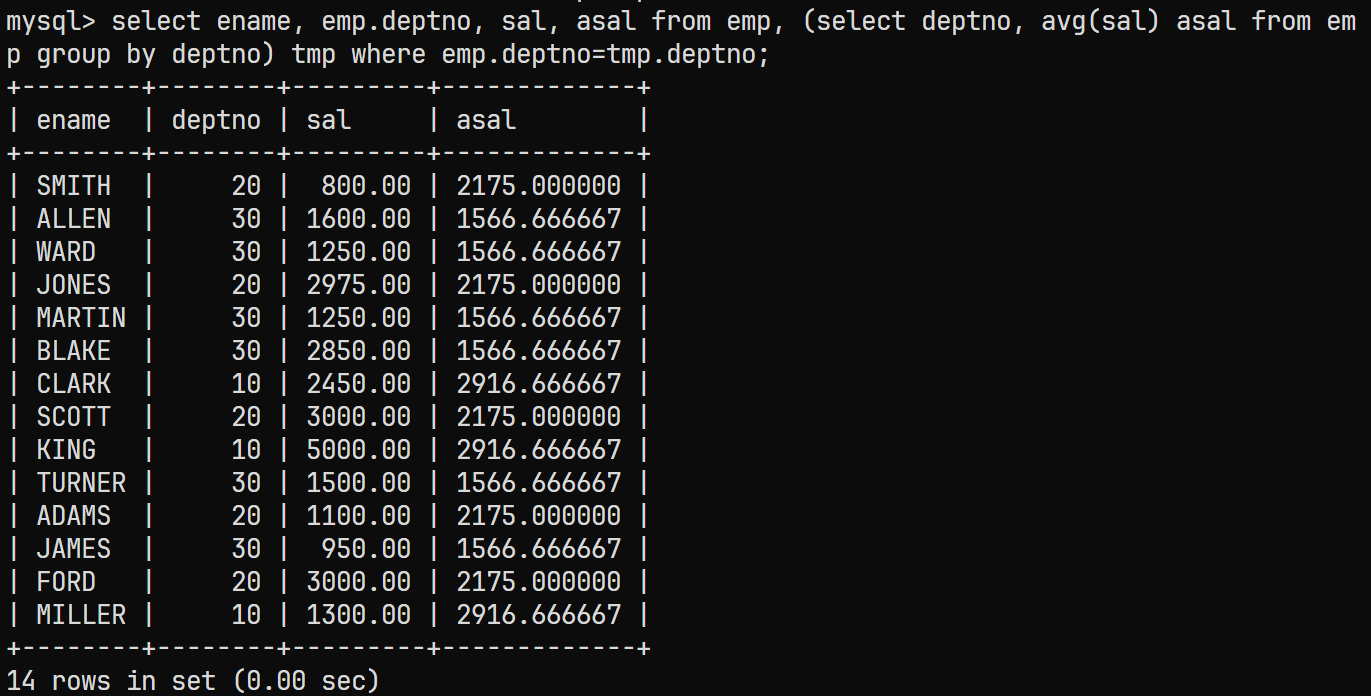
-
根据条件筛选记录
此时出现了一张新的表, 表中有每位雇员的薪资与平均薪资;
而该题需要薪资高于部门平均薪资的记录, 因此需要使用
AND来增加并列条件;select ename, emp.deptno, sal, asal from emp, (select deptno, avg(sal) asal from emp group by deptno) tmp where emp.deptno=tmp.deptno and sal>asal; -
最终结果
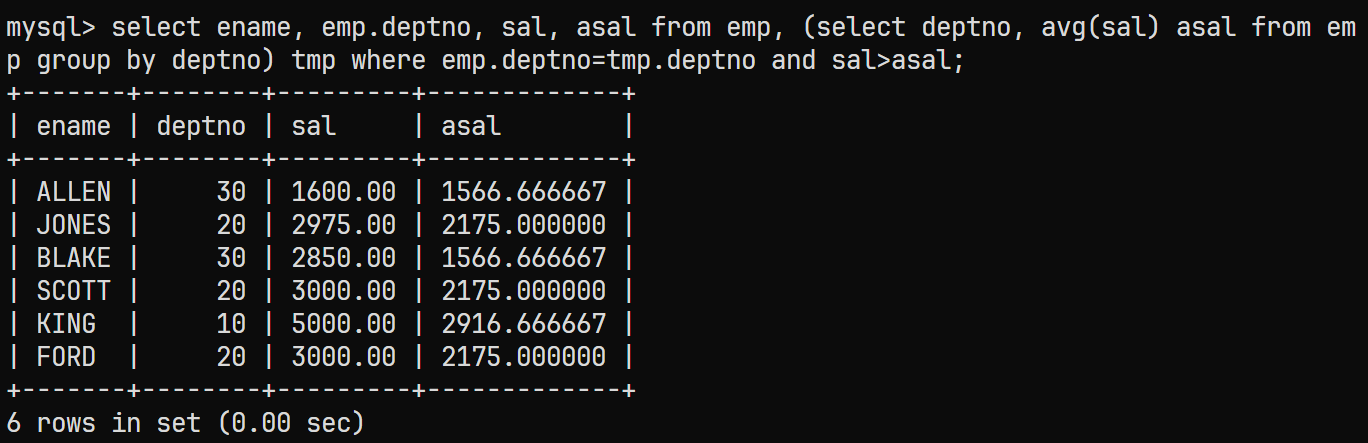
4.4.2 查找每个部门工资最高的人的姓名, 工资, 部门以及最高工资
该题与上一题4.4.1的解题思路基本相同, 即设计出一张子表找出各个部门的最高工资与部门号, 随后进行笛卡尔积最后进行筛选;
-
子查询找出各个部门的最高工资与部门号
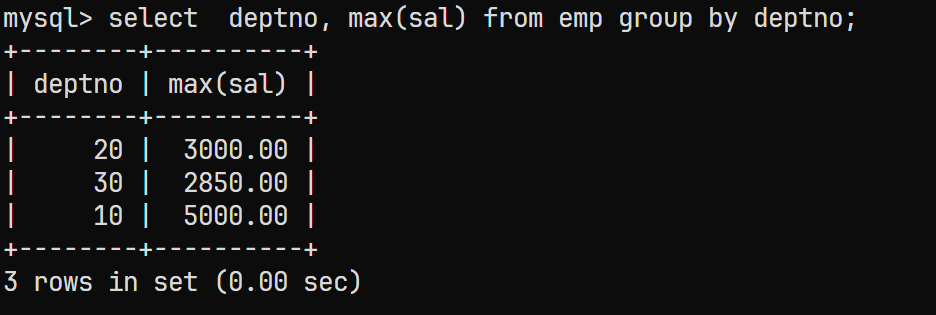
通过部门号进行筛选, 同样需要使用
GROUP BY;select deptno, max(sal) from emp group by deptno;结果为:
-
进行笛卡尔积并筛选掉无效记录
select * from emp, (select deptno, max(sal) from emp group by deptno) tmp where tmp.deptno=emp.deptno; -
筛选掉无效的记录后通过
AND增加条件筛选出sal=max(sal)的记录select * from emp, (select deptno, max(sal) maxsal from emp group by deptno) tmp where tmp.deptno=emp.deptno and maxsal=sal; -
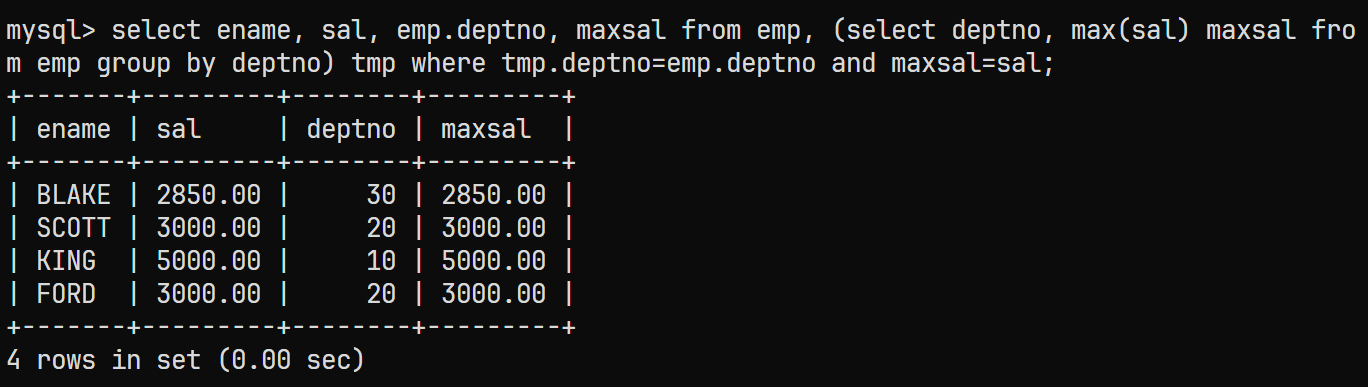
最终选择列进行展示
select ename, sal, emp.deptno, maxsal from emp, (select deptno, max(sal) maxsal from emp group by deptno) tmp where tmp.deptno=emp.deptno and maxsal=sal; -
结果
4.4.3 显示每个部门的信息 (部门名, 编号, 地址)和人员数量
该题的表可以使用emp表与dept两张表, 对应的解法也有两种:
-
多表查询
使用多表查询进行查询时同样需要对两张表进行笛卡尔积, 随后通过条件筛选筛选掉无用的记录:
select * from emp, dept where emp.deptno=dept.deptno;在此处我们需要显示部门名, 编号, 地址以及人员数量, 由于人员数量需要用聚合函数
COUNT, 因此可以先将前三列进行筛选;select dname, dept.deptno, loc from emp, dept where emp.deptno=dept.deptno;对应的结果为:
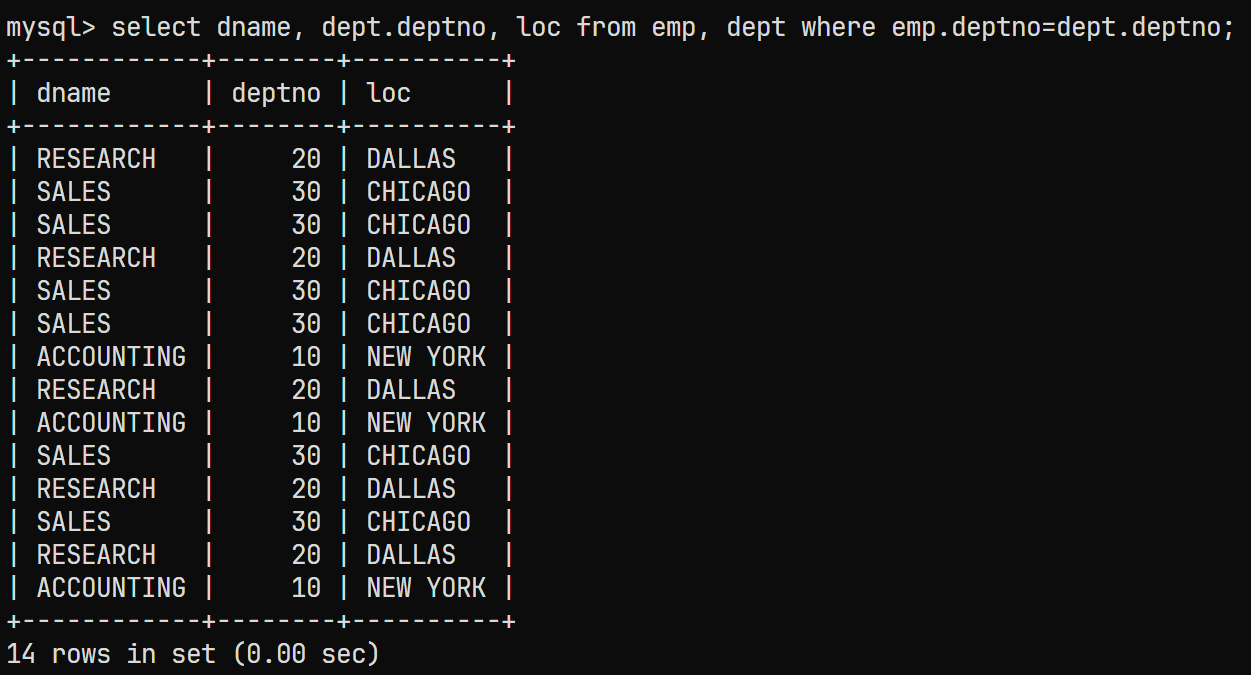
接下来需要分组与聚合统计, 其中分组为每个部门的分组, 聚合统计则是针对各个部门的人数进行统计, 因此拟出下步的
sql语句为:select dname, dept.deptno, loc, count(ename) from emp, dept where emp.deptno=dept.deptno group deptno; # Error但是这一步的
sql语句将会报错:select dname, dept.deptno, loc, count(ename) from emp, dept where emp.deptno=dept.deptno group by deptno; ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'scott.dept.dname' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by本质原因是在使用
SELECT 聚合函数时,SELECT后跟随的column需要满足两个条件之一:- 同样为
GROUP BY分组的其中一列 - 使用聚合函数的一列
因此这里无法使用聚合函数, 只能在语句末尾对剩余两列进行
GROUP BY:select dname, dept.deptno, loc, count(ename) from emp, dept where emp.deptno=dept.deptno group by deptno, dname, loc;最终的查询结果为:
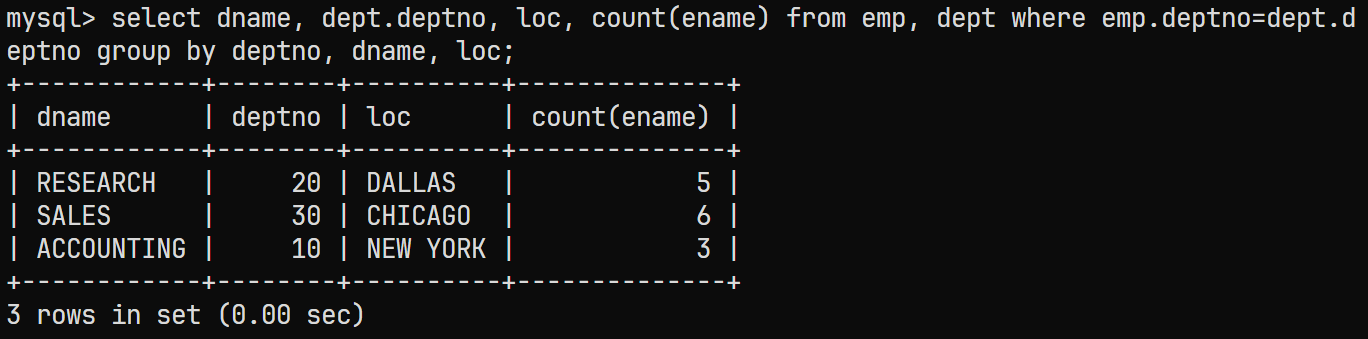
- 同样为
-
子查询
使用子查询的方式与
4.4.2,4.4.1的方式类似, 即对emp表使用聚合函数与分组作为子查询查询出子表(部门编号与各部门人数);随后对查询出的子表与
dept表进行笛卡尔积, 最后筛选出需要的数据;-
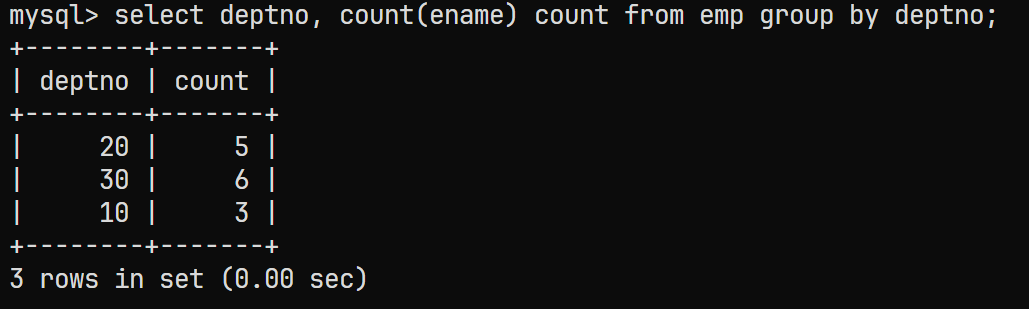
子查询语句查询出临时表
select deptno, count(ename) count from emp group by deptno;对应的结果为:
-
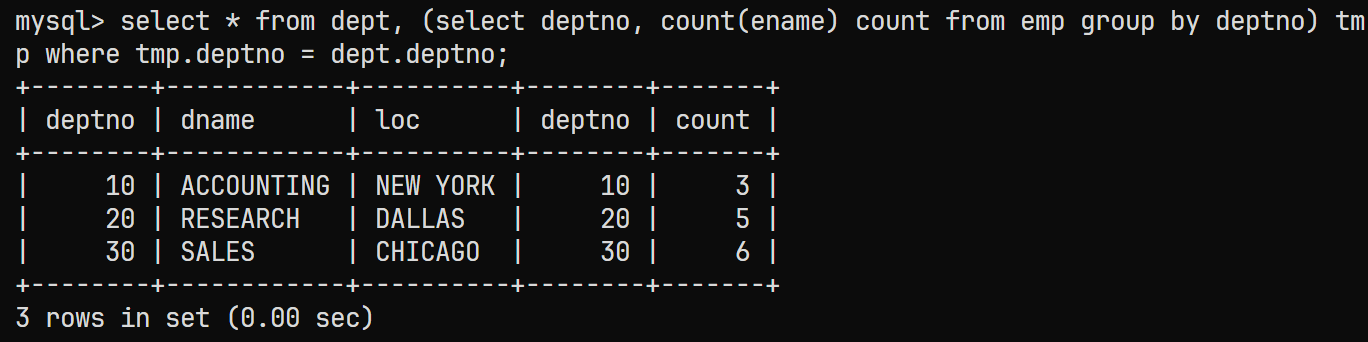
进行笛卡尔积并筛选掉无效记录
select * from dept, (select deptno, count(ename) count from emp group by deptno) tmp where tmp.deptno = dept.deptno; -
最终结果
-
4.5 合并查询
通常情况下, 实际的应用中, 为了合并多个SELECT的执行结果, 可以使用集合操作符union, union all来进行操作;
4.5.1 UNION 关键字
该关键字用来获取两个查询结果的并集, 当出现重复数据时将会去重;
假设题目为:
- 查询工资大于
2500或是职位是MANAGER的员工
在这一题中我们可以使用OR进行查询;
select ename, sal, job from emp where sal>2500 or job = 'MANAGER';
+-------+---------+-----------+
| ename | sal | job |
+-------+---------+-----------+
| JONES | 2975.00 | MANAGER |
| BLAKE | 2850.00 | MANAGER |
| CLARK | 2450.00 | MANAGER |
| SCOTT | 3000.00 | ANALYST |
| KING | 5000.00 | PRESIDENT |
| FORD | 3000.00 | ANALYST |
+-------+---------+-----------+
6 rows in set (0.00 sec)
但除了OR以外, 我们可以将两个条件各作为一条查询语句, 并使用关键字UNION将两个语句查询出来的结果进行并集;
对应的SQL语句为:
select ename, sal, job from emp where sal>2500
union
select ename, sal, job from emp where job='MANAGER';
结果与使用OR的结果相同, 此处不进行赘述;
4.5.2 UNION ALL 关键字
该关键字与UNION关键字类似, 与之不同的是该关键字并不会对重复记录进行去重;
此处的例题同样使用:
- 查询工资大于
2500或是职位是MANAGER的员工
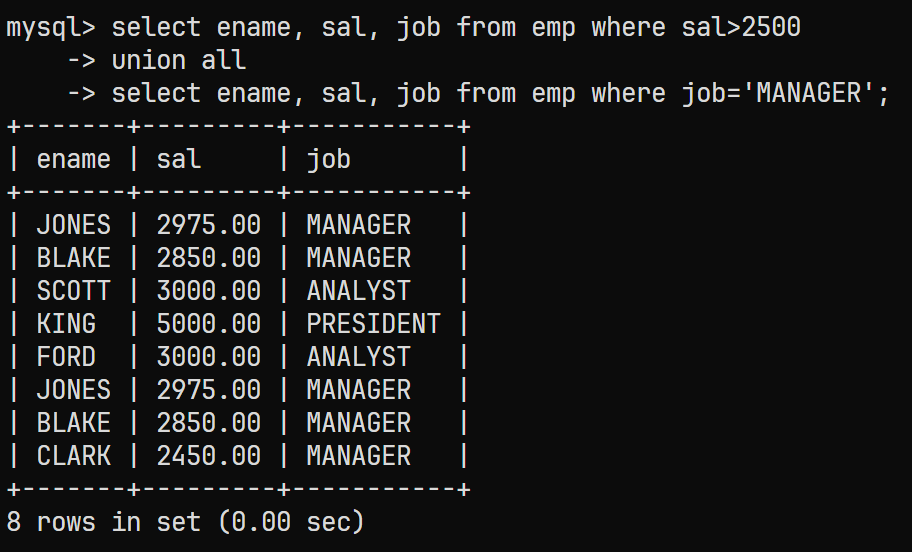
使用UNION ALL作为关键字的SQL语句为如下:
select ename, sal, job from emp where sal>2500
union all
select ename, sal, job from emp where job='MANAGER';
最终结果为:
5 表的内外连接
通常情况下, 多表之间可以进行连接, 常有的是内连接与外连接, 上文所提到的笛卡尔积的方式其次就是内连接的一种, 也是在开发过程中使用最多的连接查询;
其次在上文中所提到的所有的连接方式都属于内连接;
5.1 内连接
内连接的语法为如下:
SELECT column FROM table_1 INNER JOIN table_2 ON 连接条件 AND 其他条件 ...;
与笛卡尔积作为比较的就是上文中所使用的笛卡尔积写法中的","换成了INNER JOIN;
假设存在一个案例:
- 显示
SMITH的名字和部门名称
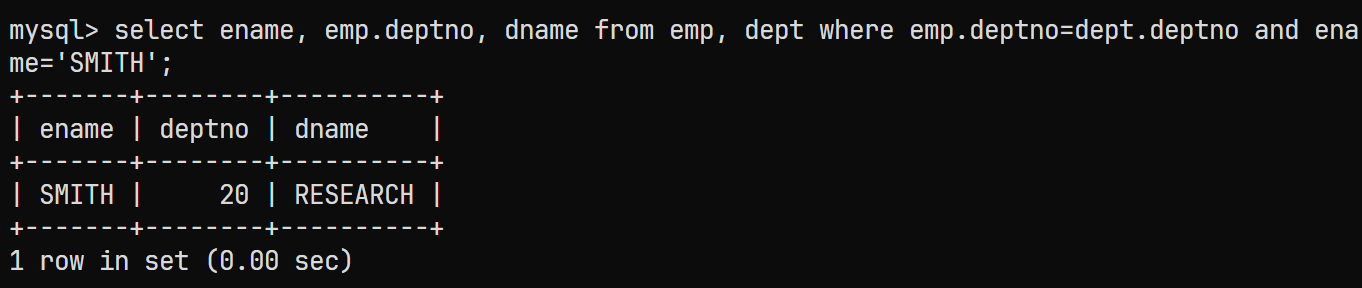
若是使用之前的写法, 对应的SQL语句为:
select ename, emp.deptno, dname from emp, dept where emp.deptno=dept.deptno and ename='SMITH';
对应的结果为:
而若是使用标准的内连接写法, 对应的SQL语句则为:
select ename, emp.deptno, dname from emp inner join dept where emp.deptno=dept.deptno and ename='SMITH';
对应的结果为:
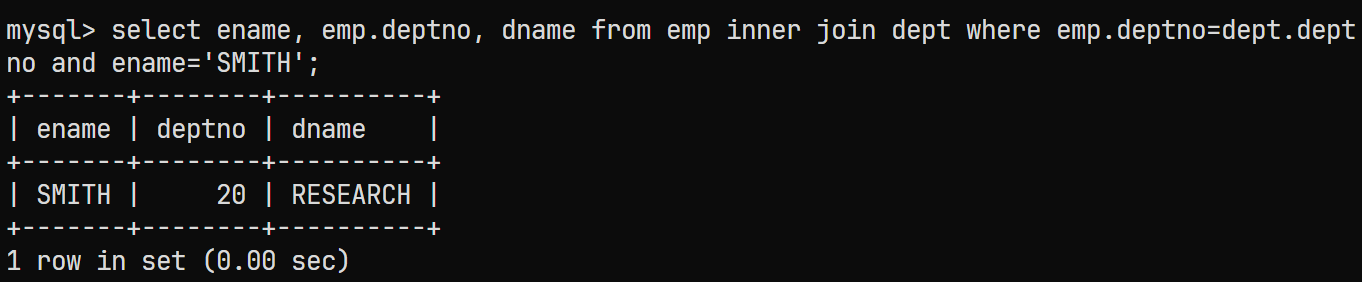
结果与上一个结果相同;
5.2 外连接
除了内连接以外还有一种连接方式被称为外连接;
外连接通常采用LEFT/RIGHT JOIN的方式对两张表进行连接;
即分为:
- 左连接 -
LEFT JOIN - 右连接 -
RIGHT JOIN
5.2.1 左外连接
假设两张表进行联合查询, 如果左侧的表完全显示, 我们就说是左外连接;
对应的语法为:
SELECT column1, column2... FROM table1 LEFT JOIN table2 ON condition;
假设存在两张表, 对应的表结构与所插入数据为如下:
-
表结构
show create table exam\G *************************** 1. row ***************************Table: exam Create Table: CREATE TABLE `exam` (`id` int DEFAULT NULL,`grade` int DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec)mysql> show create table stu\G *************************** 1. row ***************************Table: stu Create Table: CREATE TABLE `stu` (`id` int DEFAULT NULL,`name` varchar(30) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci 1 row in set (0.00 sec) -
表内数据
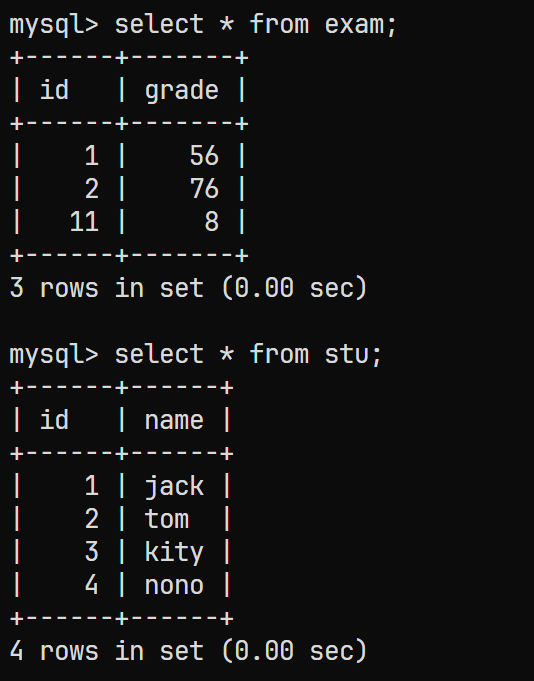
对应的题目为:
- 查询所有学生的成绩, 如果这个学生没有成绩, 也要将学生的个人信息显示出来
在这一题中, 可以看到条件, 如果学生没有成绩, 也要将学生的个人信息进行显示, 这也说明这里采用的是左外连接;
对应的SQL语句为:
select * from stu left join exam on exam.id=stu.id;
针对左外连接而言, 实际上主表将在左侧, 而副表将在右侧;
5.2.2 右外连接
假设两张表进行联合查询, 同样的如果右侧的表完全显示, 我们就说是右外连接;
语法为:
SELECT column1, column2... FROM table1 RIGHT JOIN table2 ON condition;
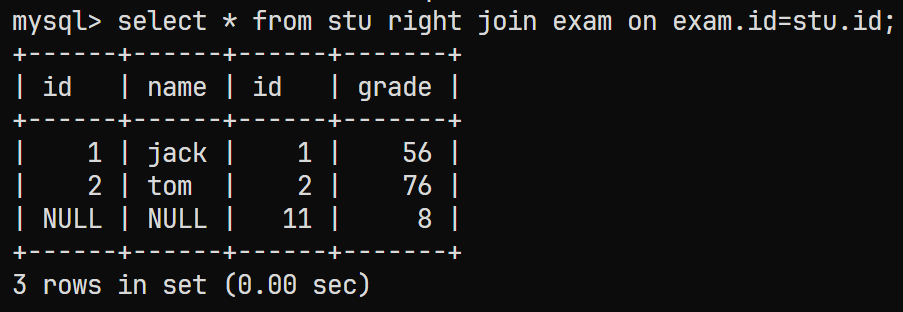
- 对
stu表和exam表联合查询, 将所有的成绩都显示出来, 即使这个成绩没有学生与它对应, 也进行显示;
与5.2.1的例题相同, 对应的SQL语句为:
select * from stu right join exam on exam.id=stu.id;
对应的结果为:
5.2.3 练习
回到Oracle 9i经典测试用表进行练习;
- 列出部门名称和这些部门的员工信息, 同时列出没有员工的部门
部门名称和这些部门的员工信息, 说明查询中存在多表;
而列出没有员工的部门说明部门表dept是主表, 而对应的员工表emp为副表;
分别都可以进行左右外连接, 只需要控制主表与副表的位置;
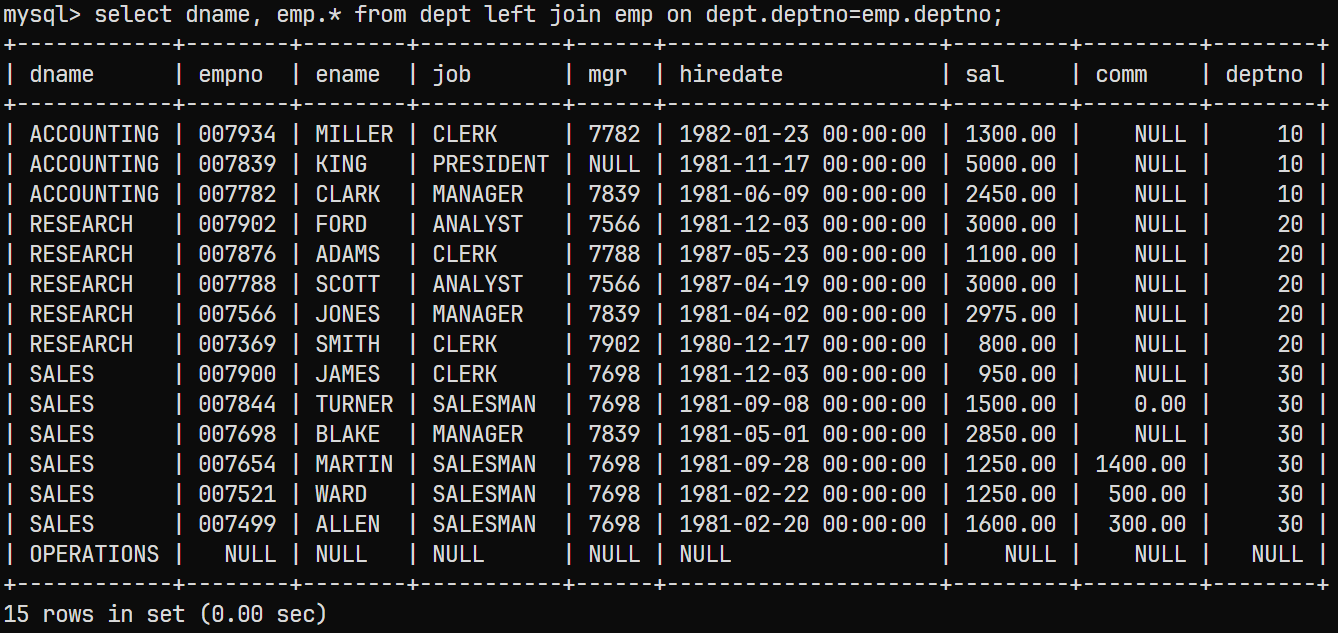
-
左外连接方式
select dname, emp.* from dept left join emp on dept.deptno=emp.deptno;查询结果为:
-
右外连接方式
与左外连接相同, 只不过需要调转主表与副表的位置;
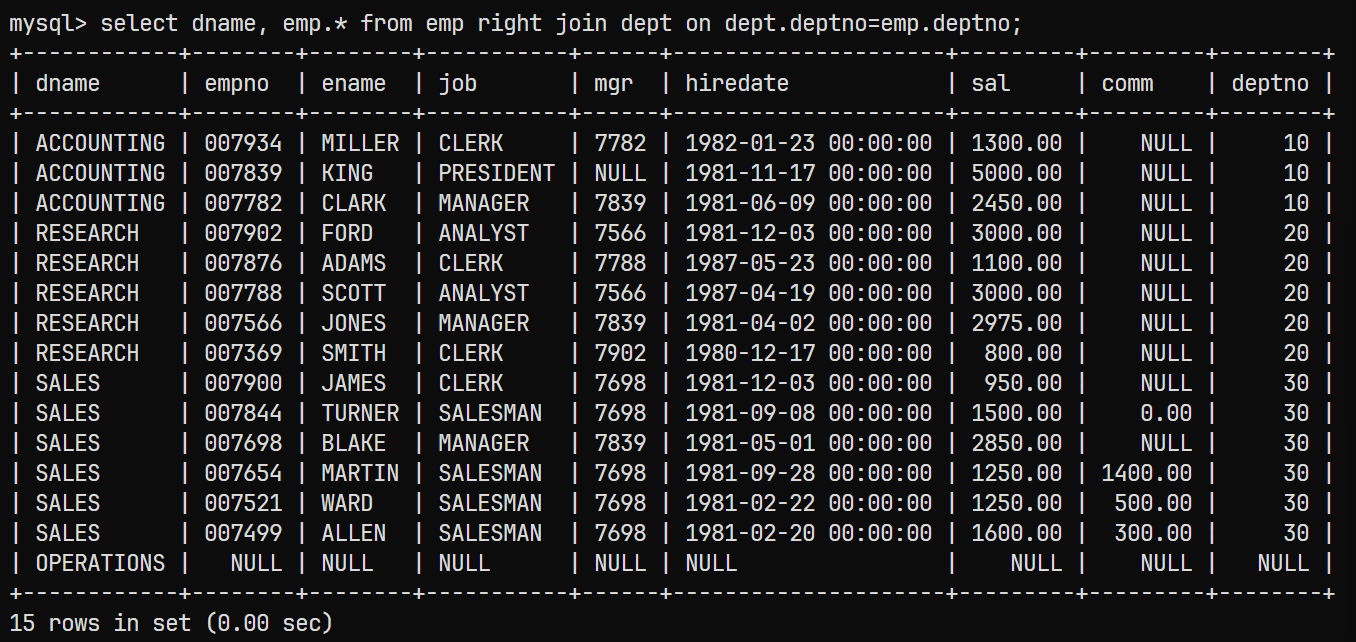
select dname, emp.* from emp right join dept on dept.deptno=emp.deptno;查询结果为:
6 总结
在MySQL中, 无论是物理磁盘中存在的表还是查询中出现的中间产物表, 都视为表, 可以这么说:
- "在
MySQL中, 一切皆为表”
同时在进行多表查询时, 本质上就是通过各种连接方式, 将多表问题转化为单表问题;