数据仓库·简介(一)
数据仓库·简介(一)
- 一、数据仓库诞生背景
- 二、数据仓库基本概述
- 三、技术实现
- 四、MPP与分布式架构
- 五、常见产品
链接: 学习笔记来自哔哩哔哩视频
一、数据仓库诞生背景
1、诞生背景: 各系统自的业务数据库,个数据库没有统一规范
- 各自拥有的抽取系统(资源浪费)
- 抽取的数据不一致(权限)
- 各部门的分析结果不一致(比如:各个的取数口径不一致,A系统早上9点抽数分析,B系统下午5点抽数分析导致结果不一致)
2、数据仓库面向分析,业务数据库面向业务系统(作用的类型各不相同,各司其职)
二、数据仓库基本概述
1、数据仓库之父是:比尔·恩门(Bill Inmon)
2、数据仓库是一个面向主题的,集成的,非易失的且随时间变化的数据集合。
- 面向主题:为数据分析提供服务,根据主题将原始数据集合在一起。
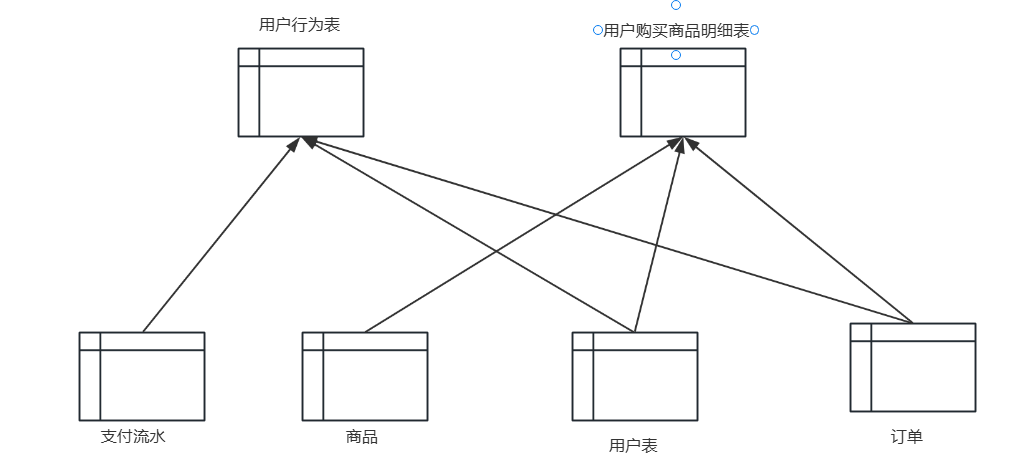
根据主题将业务数据抽取,形成一张宽表。 - 集成:将不同业务系统中,各种数据抽取,清洗,转换整合成最终的数据。(因为各业务系统,各厂商的库表数据,数据字段,字典类型的各不相同)
- 非易失:保存数据的一系列历史快照,定期从业务库同步数据,各个时间段的数据记录,不可修改只可查询分析。
- 时变性:数据仓库定期抽取集成新数据,反映数据的最新变化。(因业务库的数据每天都会存在变化,将数据存放到数据仓库使用时间戳标记,老旧数据也可以删除,但是不建议这么干)
作用:用于组织积累的历史数据,并使用分析法(OLPAP,数据分析) 进行分析整理,进而辅助决策,为管理者,企业系统提供数据支持,构建商业智能。
3、数据仓库和数据库对比
- 数据库面向事务设计,属于OLTP(在线事务处理)系统,主要操作随机读写,避免冗余,采用符合范式规范设计。
- 数据仓库面向主题设计,属于OLAP(在线分析处理)系统,主要操作批量读写,关注数据整合,以及分析处理性能,会有意引入冗余,采用反范式规范设计。
| 数据库 | 数据仓库 | |
|---|---|---|
| 面向 | 事务 | 分析 |
| 数据类型 | 细节,业务 | 综合,清洗过的数据 |
| 数据特点 | 当前的,最新的 | 历史的,跨时间维护 |
| 目的 | 日常操作 | 长期信息需求,决策支持 |
| 设计模型 | 基于R-R模型,面向应用 | 星形/雪花模型,面向主题 |
| 操作 | 读/写 | 大多为读 |
| 数据规模 | GB到TB | TB以上 |
三、技术实现
1、传统数据仓库:由关系型数据库组成的MPP(大规模并行处理)集群,早期的考虑也是由关系型数据来做数据仓库,方便数据迁移整合,但数据大了,单机就不够,就来个集群,完全兼容SQL,但是数据持续曾涨就出现了问题
- 扩展有限:即使使用集群始终还是关系型数据库(使用数据仓库就是关系型数据库出现瓶颈)
- 热点问题:假如有100万行数据,集群有十个库,每个库存放10万,恰巧第一个十万就是热点数据,该节点就出现了压力过大崩溃,就影响了整体。(虽然有一种数据加盐的技术可以分散到各个库,但依旧存在问题)
2、大数据仓库 - 利用大数据天然扩展性,完成海量数据的存储。
- 将SQL转换成大数据计算引擎任务,完成数据分析 。
易用性差,一般的数据存储在业务数据库,使用大数据需要大量数据迁移。
问:会不会同样有热点问题?
分布式数据仓库通常会有备份,备份三份,降低热点。
缺点:缺少事务支持,数据仓库主要关注分析
数据少时会很慢,浪费在调度上。
四、MPP与分布式架构
1、MPP架构(中等规模)
- 传统数据仓库技术架构,将单机数据库组成集群,提升整体处理性能。
- 节点间非共享,每个节点有独立磁盘和内存系统。
- 每台数据节点通过专网或者商业网络互连,彼此协同计算,为整体提供服务。
- 设计上优先考虑C(一致性),其次A(可用性),最后P(分区容错性)。
优点:
- 运算方式精细,延迟低,吞吐低。
- 适合中等规模结构化数据处理。数据量大因为太精细,吞吐查性能差。
缺点:
- 位置不透明,通过Hash确认物理节点,查询在所有节点均会执行。
- 并行计算:单节点瓶颈会成为整个系统短板,容错性差。
- 分布式事务实现导致扩展降低。
2、分布式架构(海量数据)
- 大数据中常见架构,也称为Hadoop架构/批处理架构。
- 各节点实现场地自治(可单独运行局部应用),数据在集群中透明共享。
- 各节点通过局域网或者广域网相连,节点通信开销大,运算致力减少数据移动。
- 先考虑P(分区容错性),其次A(可用性),最后C(一致性)。
五、常见产品
传统数据仓库:Oracle RAC, DB2, Teradata, Greenplum
大数据数据仓库:Hive(Hadoop),Spark SQL (Spark),Hbass(大数据NoSQL,高并发读),Impala,HAWQ, TIDB。