PyTorch2 Python深度学习 - 全连接神经网络(FNN)
锋哥原创的PyTorch2 Python深度学习视频教程:
https://www.bilibili.com/video/BV1eqxNzXEYc
课程介绍

基于前面的机器学习Scikit-learn,深度学习Tensorflow2课程,我们继续讲解深度学习PyTorch2,所以有些机器学习,深度学习基本概念就不再重复讲解,大家务必学习好前面两个课程。本课程主要讲解基于PyTorch2的深度学习核心知识,主要讲解包括PyTorch2框架入门知识,环境搭建,张量,自动微分,数据加载与预处理,模型训练与优化,以及卷积神经网络(CNN),循环神经网络(RNN),生成对抗网络(GAN),模型保存与加载等。
PyTorch2 Python深度学习 - 全连接神经网络(FNN)
FNN介绍
全连接神经网络(FNN,Feedforward Neural Network)是最基本的神经网络类型,广泛应用于分类、回归等任务中。FNN由输入层、隐藏层和输出层组成,每层的神经元与下一层的神经元完全连接,因此称为“全连接”。
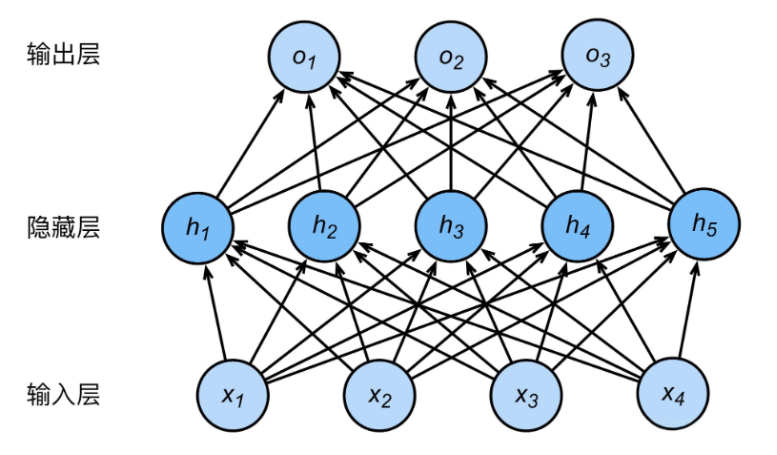
FNN的结构
-
输入层:接受输入数据,传递到下一层。
-
隐藏层:进行数据处理的中间层,可能有多个。每一层都由神经元组成,每个神经元与前一层的所有神经元相连接。
-
输出层:根据任务的要求输出最终的预测结果。
每个神经元通过加权求和后通过激活函数(如ReLU、Sigmoid、Tanh等)得到输出。模型的训练过程通过反向传播算法来优化参数。
使用FNN实现鸢尾花多分类问题
因为用到scikit-learn的鸢尾花数据集,所以我们先安装下scikit-learn库
pip install scikit-learn -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com用PyTorch 2 构建全连接神经网络(FNN)来分类鸢尾花数据集(Iris Dataset)是一个经典的机器学习任务。鸢尾花数据集包含150个样本,每个样本有4个特征,表示鸢尾花的花瓣长度、花瓣宽度、萼片长度和萼片宽度。目标是预测鸢尾花的种类,种类有3种:Setosa、Versicolor和Virginica。
任务目标
-
使用全连接神经网络(FNN)实现对鸢尾花数据集的分类。
-
使用PyTorch 2进行模型的构建、训练和测试。
代码实现
下面是一个简单的PyTorch 2实现,使用全连接神经网络对鸢尾花数据集进行分类。
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import torch
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 150个样本 4个特征
y = iris.target # 3个类别(Setosa, Versicolor, Virginica)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 将数据转换为Pytorch的Tensor格式
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
# 创建数据集和数据加载器
train_dataset = torch.utils.data.TensorDataset(X_train, y_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = torch.utils.data.TensorDataset(X_test, y_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 定义全连接神经网络模型
class FNN(torch.nn.Module):def __init__(self, input_size, hidden_size, output_size):super(FNN, self).__init__()self.fc1 = torch.nn.Linear(input_size, hidden_size) # 输入层到隐藏层的全连接层self.relu = torch.nn.ReLU() # 激活函数self.fc2 = torch.nn.Linear(hidden_size, output_size) # 隐藏层到输出层的全连接层
def forward(self, x):x = self.fc1(x) # 输入到隐藏层x = self.relu(x) # 激活函数x = self.fc2(x) # 隐藏层到输出层return x
# 超参数定义
input_size = 4 # 输入特征数
hidden_size = 16 # 隐藏层节点数
output_size = 3 # 输出类别数 (鸢尾花有3个类别)
# 创建模型
model = FNN(input_size, hidden_size, output_size)
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 优化器
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):model.train() # 设置为训练模式for inputs, labels in train_loader:# 前向传播outputs = model(inputs)loss = criterion(outputs, labels) # 计算损失
# 反向传播和优化optimizer.zero_grad() # 梯度清零loss.backward() # 计算梯度optimizer.step() # 更新参数
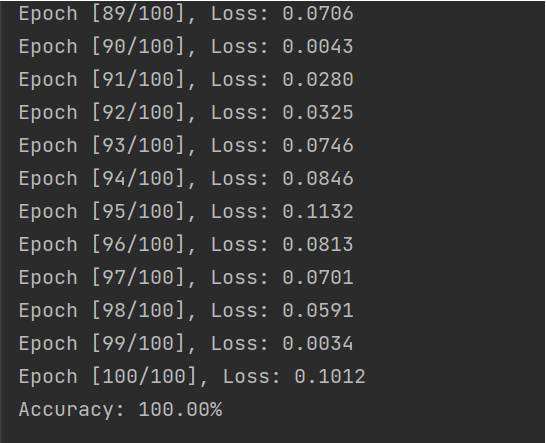
# 输出训练结果print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试模型
model.eval() # 设置为测试模式
y_pred = []
y_true = []
with torch.no_grad(): # 禁用梯度计算for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs, 1) # 获取预测结果 获取最大概率的索引y_pred.extend(predicted.numpy())y_true.extend(labels.numpy())
# 计算准确率
accuracy = accuracy_score(y_true, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')代码解析
-
数据加载与预处理:首先使用
load_iris加载鸢尾花数据集,然后对特征进行标准化(即均值为0,方差为1),并将数据分为训练集和测试集。 -
FNN模型:
FNN类继承自nn.Module,包含一个输入层到隐藏层的全连接层,ReLU激活函数,以及一个隐藏层到输出层的全连接层。输出层的大小为3,因为有3个类别。 -
训练过程:使用交叉熵损失函数(
CrossEntropyLoss),这是分类问题常用的损失函数。优化器使用Adam算法进行参数更新。 -
评估过程:在测试阶段,关闭梯度计算(
torch.no_grad()),并使用torch.max获取每个样本的预测类别,最后计算准确率。
运行输出:
引入nn.Sequential顺序模型简化代码结构
在 PyTorch 2 中,nn.Sequential 是一种 快捷定义神经网络模型的容器(container)。 它允许你 按顺序堆叠网络层,无需显式编写 forward() 函数,是构建简单前馈神经网络(如 FNN)的最简方式之一。
# 创建模型
model = torch.nn.Sequential(torch.nn.Linear(input_size, hidden_size), # 输入层 -> 隐藏层torch.nn.ReLU(),torch.nn.Linear(hidden_size, output_size) # 隐藏层 -> 输出层(3类)
)我们使用nn.Sequential来改写下前一小节的FNN实现鸢尾花多分类问题
完整代码:
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import torch
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 150个样本 4个特征
y = iris.target # 3个类别(Setosa, Versicolor, Virginica)
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 将数据转换为Pytorch的Tensor格式
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.long)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.long)
# 创建数据集和数据加载器
train_dataset = torch.utils.data.TensorDataset(X_train, y_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)
test_dataset = torch.utils.data.TensorDataset(X_test, y_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=32, shuffle=False)
# 超参数定义
input_size = 4 # 输入特征数
hidden_size = 16 # 隐藏层节点数
output_size = 3 # 输出类别数 (鸢尾花有3个类别)
# 创建模型
model = torch.nn.Sequential(torch.nn.Linear(input_size, hidden_size), # 输入层 -> 隐藏层torch.nn.ReLU(),torch.nn.Linear(hidden_size, output_size) # 隐藏层 -> 输出层(3类)
)
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # 优化器
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):model.train() # 设置为训练模式for inputs, labels in train_loader:# 前向传播outputs = model(inputs)loss = criterion(outputs, labels) # 计算损失
# 反向传播和优化optimizer.zero_grad() # 梯度清零loss.backward() # 计算梯度optimizer.step() # 更新参数
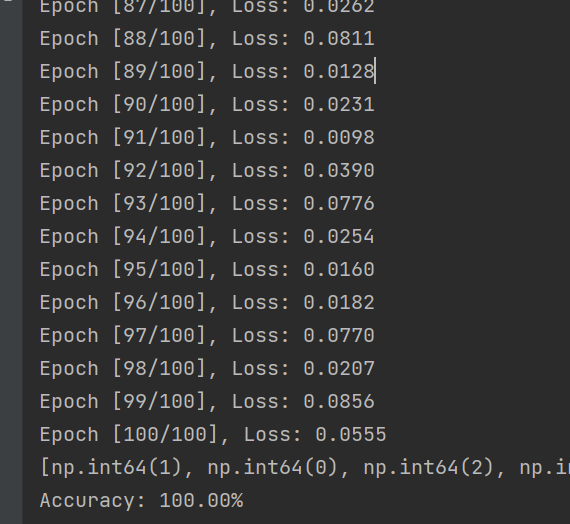
# 输出训练结果print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}')
# 测试模型
model.eval() # 设置为测试模式
y_pred = []
y_true = []
with torch.no_grad(): # 禁用梯度计算for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs, 1) # 获取预测结果 获取最大概率的索引y_pred.extend(predicted.numpy())y_true.extend(labels.numpy())
# 计算准确率
accuracy = accuracy_score(y_true, y_pred)
print(f'Accuracy: {accuracy * 100:.2f}%')运行输出: