图神经网络分享系列-GAT(GRAPH ATTENTION NETWORKS) (三)
目录
一、评估
1.1 数据集
直推式学习
归纳式学习
1.2 最先进的方法
直推式学习
归纳式学习
1.3 实验设置
直推式学习
归纳式学习
训练细节
1.4 实验结果
直推式任务:
归纳任务:
性能分析
特征可视化
二、总结
图形注意力网络(GATs)的介绍与特点
实验成果与应用场景
未来研究方向
上一篇文章:图神经网络分享系列-GAT(GRAPH ATTENTION NETWORKS) (二)
一、评估
针对GAT模型(图注意力网络),在四项成熟的基于图的基准任务(包括直推式和归纳式)中,与多种强基线及先前方法进行了对比评估,所有任务均达到或匹配当前最优性能。本节总结了实验设置、结果,并对GAT模型提取的特征表示进行了简要定性分析。
关键术语说明
- GAT模型:图注意力网络(Graph Attention Network),一种基于注意力机制的图神经网络架构。
- 直推式(transductive):模型在训练时能观察到全部图结构,但仅部分节点带有标签。
- 归纳式(inductive):模型需在训练未见的图结构上泛化,适用于动态图场景。
- 强基线(strong baselines):指对比实验中采用的具有竞争力的基准模型或方法。
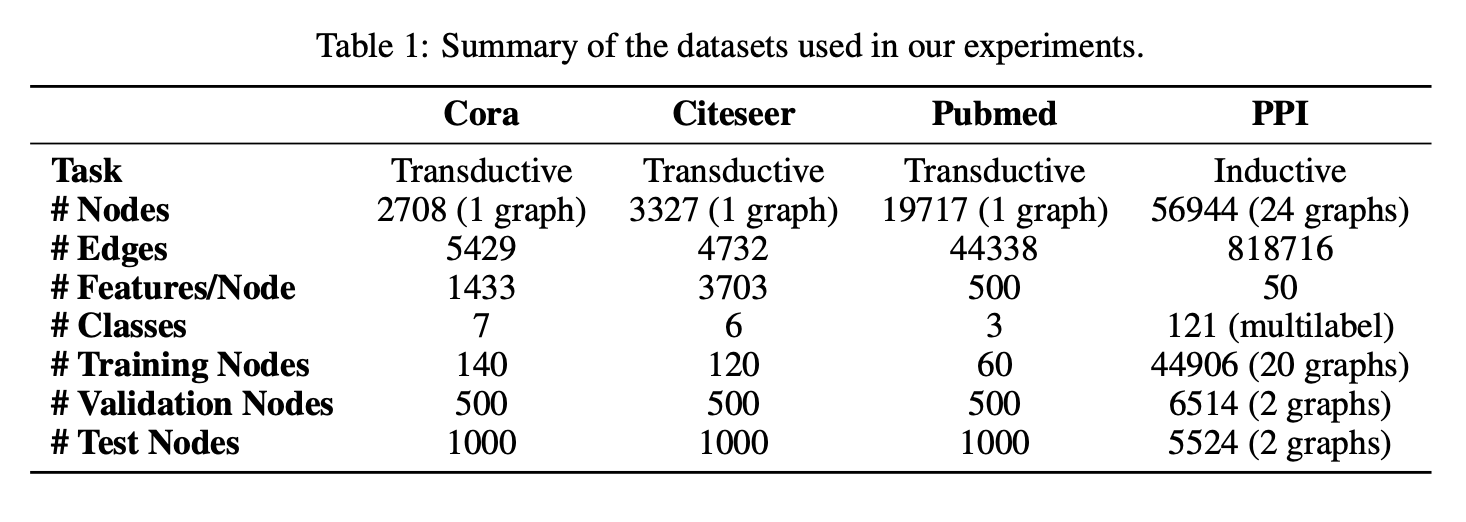
1.1 数据集
直推式学习
采用三个标准引文网络基准数据集——Cora、Citeseer和Pubmed(Sen等,2008),并严格遵循Yang等(2016)的直推式实验设置。这些数据集中,节点代表文档,边代表(无向的)引用关系。节点特征对应文档的词袋表示元素,每个节点带有类别标签。每类仅允许20个节点用于训练,但根据直推式设置,训练算法可访问所有节点的特征向量。训练模型的预测能力在1000个测试节点上评估,并额外使用500个节点进行验证(与Kipf & Welling(2017)的设置相同)。
- Cora数据集:包含2708个节点、5429条边、7个类别,每个节点1433维特征。
- Citeseer数据集:包含3327个节点、4732条边、6个类别,每个节点3703维特征。
- Pubmed数据集:包含19717个节点、44338条边、3个类别,每个节点500维特征。
归纳式学习
使用蛋白质相互作用(PPI)数据集,该数据集由不同人体组织的图构成(Zitnik & Leskovec,2017)。训练集含20张图,验证集和测试集各2张图,关键点在于测试图在训练期间完全不可见。图的构建基于Hamilton等(2017)提供的预处理数据。
- 图结构:平均每图2372个节点,每个节点50维特征(包括位置基因集、基序基因集和免疫学特征)。
- 标签:121个多标签类别,源自基因本体论和分子特征数据库(Subramanian等,2005),节点可同时拥有多个标签。
表1总结了数据集的特性。
1.2 最先进的方法
直推式学习
在直推式学习任务中,比较对象与Kipf & Welling (2017)中指定的强大基线及前沿方法相同。包括标签传播(LP)(Zhu等,2003)、半监督嵌入(SemiEmb)(Weston等,2012)、流形正则化(ManiReg)(Belkin等,2006)、基于Skip-gram的图嵌入(DeepWalk)(Perozzi等,2014)、迭代分类算法(ICA)(Lu & Getoor,2003)以及Planetoid(Yang等,2016)。模型还直接与GCN(Kipf & Welling,2017)、使用高阶切比雪夫滤波器的图卷积模型(Defferrard等,2016)以及Monti等(2016)提出的MoNet模型进行对比。
归纳式学习
在归纳式学习任务中,比较对象为Hamilton等(2017)提出的四种监督式GraphSAGE归纳方法。这些方法提供了多种特征聚合策略:GraphSAGE-GCN(将图卷积操作扩展至归纳场景)、GraphSAGE-mean(对特征向量逐元素取均值)、GraphSAGE-LSTM(通过LSTM聚合邻域特征)、GraphSAGE-pool(对经共享非线性多层感知机变换的特征向量逐元素取最大值)。其他直推式方法要么完全不适合归纳场景,要么假设节点逐步添加到单一图中,导致其无法适用于训练期间完全未见测试图(如PPI数据集)的场景。
补充对照
两项任务中均提供了节点共享多层感知机(MLP)分类器的性能(该分类器完全不利用图结构)。
1.3 实验设置
直推式学习
在直推式学习任务中,采用双层图注意力网络(GAT)模型。其架构超参数在Cora数据集上优化后,直接复用于CiteSeer数据集。第一层包含K=8个注意力头,每个头计算F′=8个特征(共64维特征),随后接入指数线性单元(ELU)非线性激活函数。第二层用于分类:单注意力头计算C个特征(C为类别数),接Softmax激活函数。针对小规模训练集,模型内广泛采用正则化策略:训练时应用L2正则化(λ=0.0005),并对两层输入及归一化注意力系数均实施丢弃率为p=0.6的Dropout(关键之处在于,每次训练迭代中每个节点的邻域均为随机采样)。与Monti等人的发现类似,Pubmed数据集因训练集仅60个样本需调整架构:改用K=8个输出注意力头(原为1个),并增强L2正则化至λ=0.001,其余架构参数与Cora和CiteSeer一致。
归纳式学习
在归纳式学习任务中,采用三层GAT模型。前两层均含K=4个注意力头,每头计算F′=256维特征(共1024维),后接ELU激活。最终层用于多标签分类:K=6个注意力头各计算121维特征,经平均后接逻辑Sigmoid激活。此任务训练集规模充足,未使用L2正则化或Dropout,但成功在中间注意力层引入跳跃连接。训练时批处理大小为2张图。为严格评估注意力机制的作用(与近似GCN模型对比),在相同架构下测试了恒定注意力机制(a(x,y)=1,即所有邻居权重相同)的效果。
训练细节
两模型均采用Glorot初始化,使用Adam优化器最小化训练节点的交叉熵损失:Pubmed初始学习率为0.01,其他数据集为0.005。均基于验证节点交叉熵损失及准确率(直推式)或微观F1分数(归纳式)进行早停策略,耐心值设为100轮。
1.4 实验结果
我们的对比评估实验结果总结于表2和表3。
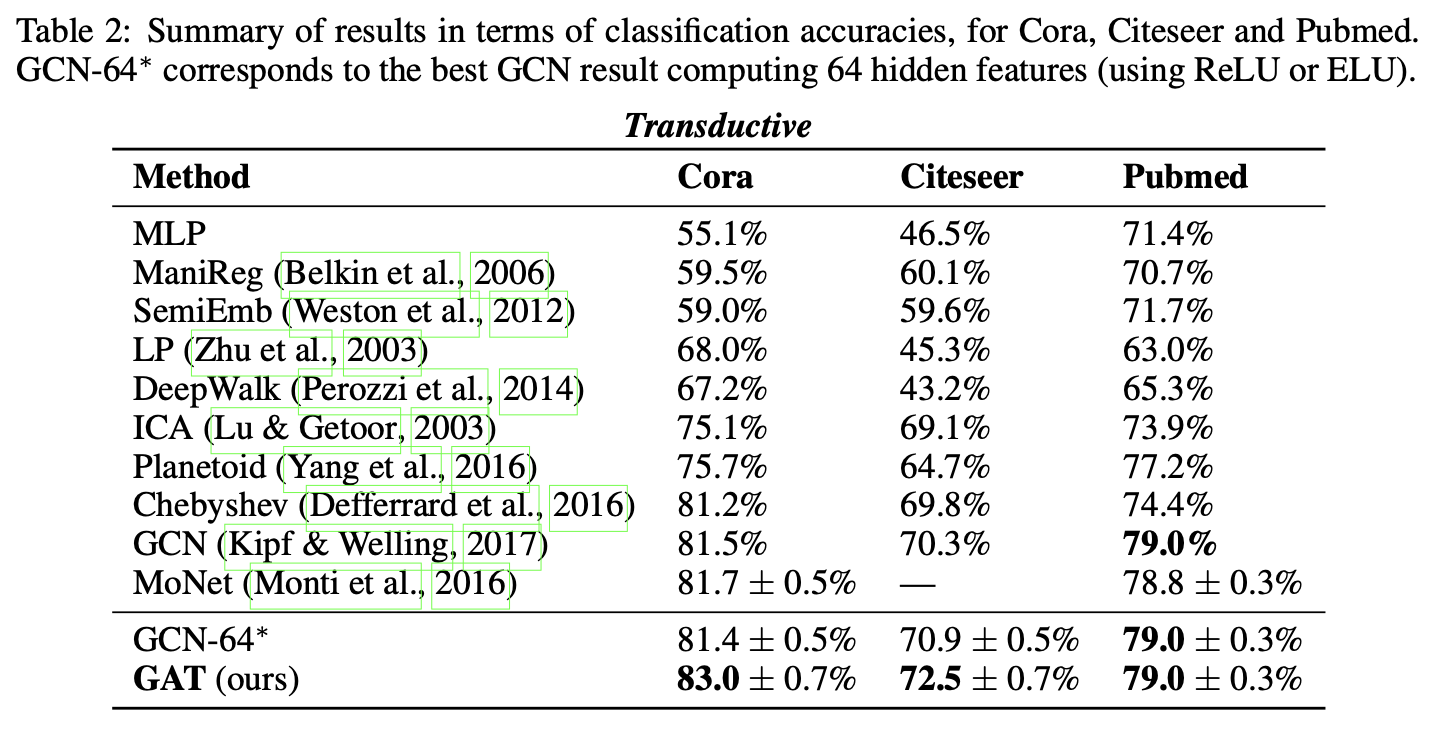
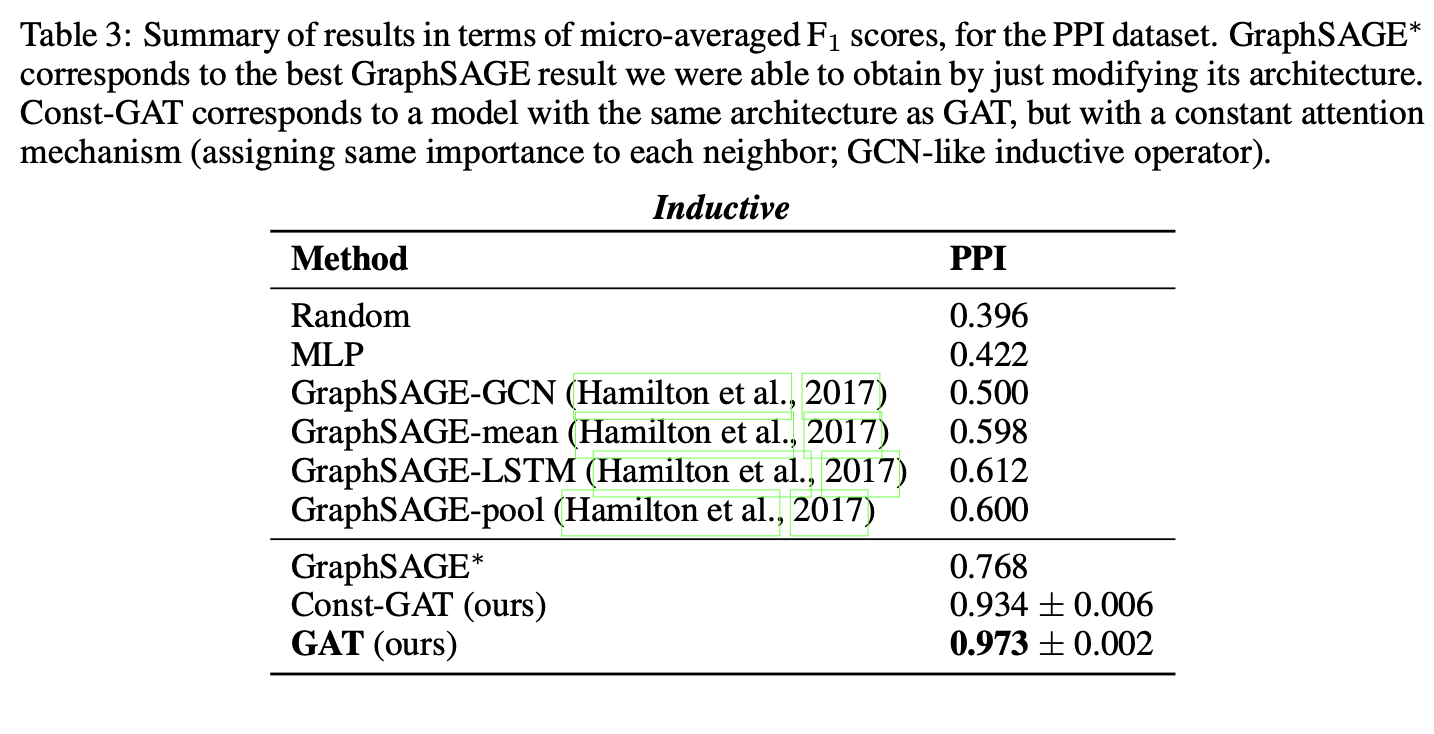
直推式任务:
测试节点的分类准确率(100次运行均值±标准差)与Kipf & Welling (2017)、Monti et al. (2016)报告的现有技术指标对比。对于基于切比雪夫滤波的方法(Defferrard等,2016),给出滤波阶数K=2和K=3时的最高性能。为公平评估注意力机制的优势,额外测试了含64维隐藏特征的GCN模型,尝试ReLU和ELU激活函数,并报告100次运行中的更优结果(标记为GCN-64*,三组实验均为ReLU更优)。
归纳任务:
两个未见测试图的节点微平均F1分数(10次运行均值),与Hamilton等(2017)报告的指标对比。由于实验为监督设置,仅对比监督式GraphSAGE方法。为评估全邻域聚合的优势,额外提供通过调整GraphSAGE架构获得的最佳结果(标记为GraphSAGE*,即三层LSTM架构,每层计算[512, 512, 726]维特征,邻域聚合使用128维特征)。最后报告恒定注意力GAT模型(Const-GAT)的10次运行结果,以对比类似GCN的聚合方案。
性能分析
所有四个数据集上均达到或匹配了最优性能,验证了2.2节的讨论预期:
- Cora和Citeseer数据集上分别比GCN提升1.5%和1.6%,表明对同邻域节点分配不同权重具有优势。
- PPI数据集提升显著:GAT模型比最佳GraphSAGE结果提高20.5%,证明模型在归纳场景的应用潜力;相比Const-GAT提升3.9%,直接验证了差异化注意力权重的重要性。
特征可视化

通过t-SNE降维可视化Cora数据集预训练GAT模型第一层提取的特征(图2)。投影后的二维空间呈现清晰聚类,对应数据集的七类主题标签,证实模型判别能力。同时展示了八头注意力系数的归一化强度分布,其具体解释需结合领域知识(如Bahdanau等2015年的方法),留待未来研究。
二、总结
图形注意力网络(GATs)的介绍与特点
我们提出了一种新型卷积式神经网络——图形注意力网络,其通过掩码自注意力层处理图形结构数据。该网络中的图形注意力层具有计算高效性(无需复杂矩阵运算,可跨图形节点并行计算),能够隐式地为邻域内不同节点分配差异化的注意力权重,同时适应不同规模的邻域范围,且不依赖预知完整图形结构。这些特性有效解决了以往基于谱方法理论的大部分问题。
实验成果与应用场景
基于注意力机制的模型在四个成熟的节点分类基准测试中(包括转导式和归纳式场景,特别是测试阶段使用完全未见过的图形),均达到或匹配了最先进性能水平。
未来研究方向
未来工作可从以下方面改进和扩展图形注意力网络:
解决第2.2小节所述的实际问题以支持更大批量规模
利用注意力机制开展模型可解释性深度分析具有重要研究价值
从应用角度出发,将方法扩展至图形分类任务而非仅限节点分类
引入边缘特征(可能表征节点间关系)的模型扩展将增强问题解决广度。
本篇内容就先到这里,实战相关会在下一篇文章给出,敬请期待~
传送门: