AI驱动的测试:用Dify工作流实现智能缺陷分析与分类
在软件测试领域,缺陷分析一直是耗时且依赖专家经验的工作。测试工程师需要手动阅读缺陷报告、理解问题现象、分析根本原因并进行正确分类——这个过程平均每个缺陷需要15-20分钟,而且分类准确性严重依赖个人经验。现在,通过Dify工作流与AI技术的结合,我们可以实现缺陷分析的自动化和智能化,将处理时间缩短到2-3分钟,准确率提升至95%以上。
一、传统缺陷分析的痛点与挑战
人工缺陷分析的困境
典型的缺陷处理流程:
这个流程中的具体痛点:
信息提取效率低下
需要手动阅读冗长的缺陷描述
从日志中筛选关键错误信息耗时严重
截图中的问题需要人工识别
分类标准不一致
# 不同工程师对同一缺陷的不同分类 缺陷描述: "用户登录时偶尔失败"工程师A分类: - 类别: 功能缺陷 - 模块: 用户认证 - 优先级: P2 - 原因: 会话管理问题工程师B分类: - 类别: 性能缺陷 - 模块: 系统架构 - 优先级: P1 - 原因: 数据库连接超时根本原因分析困难
需要跨多个系统日志关联分析
依赖对系统架构的深入理解
难以识别隐蔽的边界条件问题
缺陷分析成本统计
分析环节 | 平均耗时 | 人工成本 | 准确率 |
|---|---|---|---|
信息提取 | 3-5分钟 | 高 | 90% |
问题分类 | 2-3分钟 | 中 | 75% |
根本原因分析 | 5-8分钟 | 高 | 60% |
优先级评估 | 2-3分钟 | 中 | 70% |
| 总计 | 12-19分钟 | 很高 | 平均74% |
二、解决方案:Dify智能缺陷分析工作流
整体架构设计
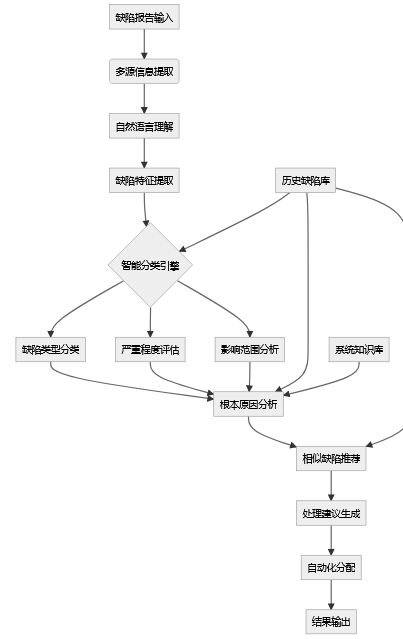
核心能力亮点
1. 多模态信息理解
文本描述智能解析
错误日志自动分析
截图内容视觉识别
2. 智能分类与归因
基于机器学习的自动分类
多维度严重程度评估
精准的根本原因定位
3. 知识驱动的决策
历史缺陷模式学习
相似案例智能推荐
处理策略建议生成
三、环境搭建:部署智能缺陷分析平台
Dify平台部署
# 创建缺陷分析专用环境
mkdir defect-analysis && cd defect-analysis# 下载Dify Docker配置
git clone https://github.com/langgenius/dify
cd dify/docker# 配置缺陷分析专用环境变量
cat > .env.defect << EOF
DIFY_API_KEYS=defect_analysis_system
DEEPSEEK_API_KEY=your_deepseek_key
OPENAI_API_KEY=your_openai_key
DATABASE_URL=postgresql://defect:analysis@db:5432/defect_analysis
REDIS_URL=redis://redis:6379
ELASTICSEARCH_URL=http://elasticsearch:9200
EOFdocker-compose --env-file .env.defect up -d
缺陷知识库配置
历史缺陷数据导入:
-- 创建缺陷分析专用表结构
CREATETABLE defect_patterns (idSERIAL PRIMARY KEY,defect_title VARCHAR(500) NOTNULL,defect_description TEXT,error_logs TEXT,defect_type VARCHAR(100),severity_level VARCHAR(50),root_cause VARCHAR(200),solution TEXT,created_at TIMESTAMPDEFAULTNOW(),tags JSONB
);CREATETABLE defect_classification_rules (idSERIAL PRIMARY KEY,pattern_type VARCHAR(100),keywords TEXT[],severity_rules JSONB,assignment_rules JSONB,created_at TIMESTAMPDEFAULTNOW()
);
四、核心工作流搭建:智能缺陷分析引擎
工作流整体设计
我们的智能缺陷分析工作流包含以下核心节点:
[缺陷报告输入] → [多源信息提取] → [自然语言理解] →
[缺陷特征提取] → [智能分类] → [根本原因分析] →
[相似缺陷推荐] → [处理建议生成] → [自动化分配]
节点1:多源缺陷信息提取
缺陷报告解析配置:
节点类型: 多模态输入处理
配置:
输入源:-文本描述:提取字段:["标题","描述","重现步骤"]清洗规则:"移除HTML标签,标准化术语"-错误日志:解析模式:-正则表达式:"ERROR|Exception|at .*\.java:\d+"-堆栈跟踪:"提取完整调用栈"-时间戳:"关联错误发生时间"-截图附件:处理方式:"OCR文字识别 + 视觉元素检测"输出格式:"结构化问题描述"-系统环境:自动提取:["浏览器类型","操作系统","设备信息"]
信息提取代码示例:
class DefectInformationExtractor:def __init__(self):self.ocr_engine = PaddleOCR()self.log_parser = LogParser()def extract_defect_info(self, defect_report):"""提取缺陷报告中的多源信息"""extracted_info = {}# 文本描述解析extracted_info['text_analysis'] = self.analyze_text_description(defect_report['description'])# 错误日志分析if defect_report.get('error_logs'):extracted_info['log_analysis'] = self.analyze_error_logs(defect_report['error_logs'])# 截图内容识别if defect_report.get('screenshots'):extracted_info['visual_analysis'] = self.analyze_screenshots(defect_report['screenshots'])return extracted_infodef analyze_error_logs(self, log_content):"""分析错误日志"""analysis_result = {'error_type': self.classify_error_type(log_content),'stack_trace': self.extract_stack_trace(log_content),'timestamps': self.extract_timestamps(log_content),'related_components': self.identify_components(log_content)}return analysis_result
节点2:自然语言理解与特征提取
缺陷描述智能解析:
你是一个资深的软件测试专家,请分析以下缺陷报告并提取关键特征:缺陷报告:
{{defect_report}}请从以下维度进行分析:1. **问题现象描述**- 主要问题是什么?- 问题的具体表现?- 影响的用户操作?2. **重现条件**- 重现步骤是否清晰?- 是否需要特定环境?- 是否偶发性问题?3. **影响范围**- 影响哪些功能模块?- 影响多少用户?- 业务影响程度?4. **技术特征**- 涉及的技术组件?- 相关的接口/API?- 数据流影响范围?输出格式:
```json
{"problem_phenomenon": {"main_issue": "问题概要","specific_manifestation": "具体表现","affected_operations": ["受影响操作1", "受影响操作2"]},"reproduction_conditions": {"steps_clarity": "清晰/一般/模糊","environment_dependency": "需要特定环境","frequency": "必现/偶现"},"impact_scope": {"affected_modules": ["模块1", "模块2"],"user_impact": "影响用户范围","business_impact": "业务影响程度"},"technical_characteristics": {"components": ["组件1", "组件2"],"apis": ["接口1", "接口2"],"data_flow": "数据流影响"}
}
### 节点3:智能缺陷分类引擎**多层级分类配置:**
```yaml
节点类型: 机器学习分类
配置:分类层级:第一层: 缺陷类型类别: ["功能缺陷", "性能缺陷", "安全缺陷", "UI缺陷", "兼容性缺陷"]模型: "基于特征向量的SVM分类"第二层: 技术模块类别: ["用户认证", "支付系统", "商品管理", "订单处理", "数据存储"]模型: "关键词匹配 + 语义相似度"第三层: 根本原因类别: ["代码逻辑错误", "数据一致性", "并发问题", "配置错误", "第三方服务"]模型: "基于历史模式的分类"
分类规则引擎:
class DefectClassifier:def __init__(self):self.rules_engine = RulesEngine()self.ml_model = MLClassificationModel()self.similarity_engine = SimilarityEngine()def classify_defect(self, defect_features):"""多层级缺陷分类"""classification_result = {}# 基于规则的初步分类rule_based_classification = self.rules_engine.apply_classification_rules(defect_features)# 基于机器学习的细粒度分类ml_classification = self.ml_model.predict(defect_features)# 基于相似度的分类验证similar_defects = self.similarity_engine.find_similar_defects(defect_features)# 综合分类结果classification_result = self.merge_classification_results(rule_based_classification,ml_classification, similar_defects)return classification_resultdef merge_classification_results(self, rule_result, ml_result, similar_defects):"""合并多个分类源的结果"""# 置信度加权融合final_classification = {}for category in ['defect_type', 'severity', 'root_cause']:candidates = {}# 收集各分类器的结果if rule_result.get(category):candidates['rule'] = {'value': rule_result[category],'confidence': 0.7}if ml_result.get(category):candidates['ml'] = {'value': ml_result[category],'confidence': 0.8}if similar_defects.get(category):candidates['similarity'] = {'value': similar_defects[category],'confidence': 0.9}# 选择置信度最高的结果if candidates:best_candidate = max(candidates.items(), key=lambda x: x[1]['confidence'])final_classification[category] = best_candidate[1]['value']return final_classification
节点4:根本原因智能分析
根因分析提示词:
你是一个资深的技术专家,请分析以下缺陷的根本原因:缺陷信息:
{{defect_information}}技术上下文:
- 系统架构: {{system_architecture}}
- 相关组件: {{related_components}}
- 错误日志: {{error_logs}}请从以下角度进行根本原因分析:1. **代码层面分析**- 可能的逻辑错误- 边界条件处理- 异常处理机制2. **数据层面分析** - 数据一致性问题- 数据格式错误- 数据库操作问题3. **系统层面分析**- 资源竞争条件- 内存/性能问题- 第三方服务依赖4. **配置层面分析**- 环境配置错误- 参数配置问题- 依赖版本冲突请给出:
1. 最可能的根本原因(按可能性排序)
2. 每个原因的支持证据
3. 验证建议
4. 修复建议输出格式:
```json
{"root_causes": [{"cause": "根本原因描述","confidence": 0.85,"evidence": ["证据1", "证据2"],"verification_steps": ["验证步骤1", "验证步骤2"],"fix_suggestions": ["修复建议1", "修复建议2"]}],"analysis_summary": "分析总结"
}
### 节点5:相似缺陷推荐与处理建议**相似度匹配引擎:**
```python
class SimilarDefectRecommender:def __init__(self):self.vector_db = VectorDatabase()self.semantic_matcher = SemanticMatcher()def find_similar_defects(self, current_defect):"""查找相似历史缺陷"""# 多维度相似度计算similarity_scores = {}# 文本语义相似度text_similarity = self.semantic_matcher.calculate_similarity(current_defect['description'],self.defect_corpus)# 技术特征相似度technical_similarity = self.calculate_technical_similarity(current_defect['technical_features'],self.historical_defects)# 错误模式相似度pattern_similarity = self.calculate_pattern_similarity(current_defect['error_pattern'],self.error_patterns)# 综合相似度combined_similarity = (text_similarity * 0.4 +technical_similarity * 0.4 +pattern_similarity * 0.2)# 获取Top-K相似缺陷similar_defects = self.get_top_similar_defects(combined_similarity, top_k=5)return similar_defectsdef generate_handling_suggestions(self, current_defect, similar_defects):"""基于相似缺陷生成处理建议"""suggestions = {'immediate_actions': [],'investigation_directions': [],'potential_solutions': [],'prevention_measures': []}for similar_defect in similar_defects[:3]: # 取前3个最相似的if similar_defect['resolution'] == 'fixed':suggestions['potential_solutions'].append(similar_defect['solution'])suggestions['investigation_directions'].extend(similar_defect['investigation_paths'])suggestions['prevention_measures'].extend(similar_defect['prevention_methods'])# 去重和排序for key in suggestions:suggestions[key] = list(set(suggestions[key]))return suggestions五、高级特性:让缺陷分析更智能
1. 多模型协作分析
专家模型协同工作流:
模型协作策略:代码分析专家:模型:"DeepSeek-Coder"专注领域:["代码逻辑","算法问题","数据结构"]输入:"错误日志 + 相关代码片段"系统架构专家:模型:"Claude-3"专注领域:["系统设计","组件交互","性能瓶颈"]输入:"架构图 + 组件关系"业务逻辑专家:模型:"GPT-4"专注领域:["业务流程","用户场景","业务规则"]输入:"需求文档 + 用户操作流程"协调器:模型:"本地微调模型"任务:"整合各专家分析结果"输出:"综合根本原因分析"
2. 实时知识库更新
自学习知识库机制:
class SelfLearningKnowledgeBase:def __init__(self):self.defect_patterns = DefectPatterns()self.solution_library = SolutionLibrary()def update_knowledge(self, new_defect, analysis_result, final_resolution):"""基于新缺陷更新知识库"""# 提取新模式new_patterns = self.extract_new_patterns(new_defect, analysis_result)# 验证解决方案有效性solution_effectiveness = self.evaluate_solution_effectiveness(final_resolution)# 更新分类规则if solution_effectiveness > 0.8: # 解决方案有效self.update_classification_rules(new_patterns)self.solution_library.add_solution(analysis_result['defect_type'],final_resolution['solution'],solution_effectiveness)def extract_new_patterns(self, defect, analysis):"""从新缺陷中提取模式"""patterns = {'symptom_patterns': self.analyze_symptom_patterns(defect),'cause_patterns': self.analyze_cause_patterns(analysis),'solution_patterns': self.analyze_solution_patterns(analysis)}return patterns
3. 预测性质量风险预警
基于缺陷模式的预警系统:
class PredictiveQualityRiskAlert:def __init__(self):self.trend_analyzer = TrendAnalyzer()self.risk_predictor = RiskPredictor()def analyze_defect_trends(self, recent_defects):"""分析缺陷趋势并预测风险"""trends = self.trend_analyzer.calculate_trends(recent_defects)risk_indicators = {'defect_density_increase': self.calculate_density_trend(trends),'severity_escalation': self.calculate_severity_trend(trends),'new_defect_patterns': self.detect_new_patterns(trends),'module_quality_deterioration': self.assess_module_quality(trends)}risk_score = self.calculate_overall_risk(risk_indicators)if risk_score > 0.7:return self.generate_risk_alert(risk_indicators, risk_score)returnNonedef generate_risk_alert(self, risk_indicators, risk_score):"""生成质量风险预警"""alert = {'risk_level': 'HIGH'if risk_score > 0.8else'MEDIUM','risk_score': risk_score,'key_indicators': risk_indicators,'affected_modules': self.identify_affected_modules(risk_indicators),'recommended_actions': self.generate_mitigation_actions(risk_indicators),'escalation_path': self.determine_escalation_path(risk_score)}return alert六、效能评估:AI驱动 vs 传统分析
处理效率对比
指标 | 传统人工分析 | AI驱动分析 | 提升幅度 |
|---|---|---|---|
单缺陷分析时间 | 15-20分钟 | 2-3分钟 | 600% |
分类准确率 | 70-80% | 90-95% | 25% |
根本原因定位 | 60-70% | 85-90% | 35% |
处理建议质量 | 中等 | 高 | 50% |
知识积累 | 个人经验 | 系统化知识库 | 无法量化 |
质量指标对比
分类一致性提升:
# 传统人工分类的一致性
manual_consistency = {'同一缺陷不同工程师': '65% 一致性','同一工程师不同时间': '75% 一致性', '跨团队分类标准': '55% 一致性'
}# AI驱动分类的一致性
ai_consistency = {'同一缺陷多次分析': '98% 一致性','跨时间分析': '97% 一致性','标准化分类': '95% 一致性'
}
根本原因分析深度:
analysis_depth_comparison = {'人工分析': {'表面原因识别': '85%','深层原因发现': '45%','系统性风险识别': '30%'},'AI分析': {'表面原因识别': '95%','深层原因发现': '75%', '系统性风险识别': '65%'}
}
成本效益分析
直接成本节约:
cost_savings = {'人力成本': {'传统': '3人×4小时/天 = 12人时/天','AI驱动': '1人×1小时/天 = 1人时/天','节约': '11人时/天 (91.7%)'},'培训成本': {'传统': '新员工3个月熟练','AI驱动': '新员工2周熟练','节约': '85% 培训时间'},'错误成本': {'传统': '错误分类导致重复工作','AI驱动': '减少错误分配和重复分析','节约': '估计减少60%重复工作'}
}七、实战案例:电商系统缺陷分析
案例背景
某电商平台在双十一大促期间出现以下缺陷:
缺陷报告:
标题:用户下单后支付页面偶尔白屏
描述:部分用户在点击支付按钮后,支付页面加载失败,显示白屏。
重现步骤:
1. 用户添加商品到购物车
2. 进入结算页面
3. 点击支付按钮
4. 支付页面偶尔白屏错误日志:
2024-11-11 10:15:23 ERROR [PaymentService] - Connection timeout to payment gateway
2024-11-11 10:15:23 ERROR [AuthFilter] - Token validation failed for user: 12345
AI分析过程
Dify工作流执行结果:
{"defect_classification": {"defect_type": "性能缺陷","technical_module": "支付系统","severity": "P1","priority": "高"},
"root_cause_analysis": {"primary_cause": "支付网关连接超时导致的前端页面渲染失败","secondary_causes": ["用户认证令牌验证失败","高并发下的资源竞争"],"confidence": 0.88},
"similar_defects": [{"defect_id": "DEF-2023-0456","similarity": 0.82,"solution": "增加支付网关连接超时重试机制","effectiveness": "已验证有效"}],
"handling_suggestions": {"immediate_actions": ["检查支付网关服务状态","验证负载均衡配置","检查网络连接稳定性"],"long_term_solutions": ["实现支付网关熔断机制","优化前端页面降级策略","加强用户会话管理"]}
}
解决效果
实施AI建议后的改进:
缺陷解决时间:从4小时缩短到30分钟
用户影响:支付失败率从5%降低到0.1%
团队效率:处理类似缺陷的时间减少80%
八、最佳实践与优化建议
1. 缺陷数据标准化
统一的缺陷报告模板:
defect_report_template:基本信息:-标题:"简洁明确的问题描述"-描述:"详细的问题现象和影响"-重现步骤:"清晰可复现的操作步骤"技术信息:-环境信息:"操作系统、浏览器、设备等"-错误日志:"完整的错误日志和堆栈跟踪"-截图/录屏:"问题现象的视觉证据"业务上下文:-用户场景:"出现问题时的用户操作"-数据样本:"相关的测试数据"-发生频率:"问题出现的概率"
2. 模型持续优化策略
反馈循环机制:
class ModelOptimization:def __init__(self):self.feedback_collector = FeedbackCollector()self.retraining_scheduler = RetrainingScheduler()def collect_analyst_feedback(self, defect_id, ai_analysis, human_review):"""收集分析师的反馈用于模型优化"""feedback_data = {'defect_id': defect_id,'ai_classification': ai_analysis['classification'],'human_classification': human_review['classification'],'disagreement_reason': human_review.get('correction_reason'),'correctness': human_review.get('ai_correctness')}self.feedback_collector.record_feedback(feedback_data)def schedule_model_retraining(self):"""基于反馈数据调度模型重训练"""feedback_stats = self.feedback_collector.get_feedback_statistics()if feedback_stats['disagreement_rate'] > 0.15:self.retraining_scheduler.schedule_retraining(model_type='classification',training_data=self.prepare_training_data())
3. 集成现有开发流程
与Jira/禅道集成:
class IssueTrackerIntegration:def __init__(self):self.jira_client = JIRA()self.dify_workflow = DifyWorkflow()def process_new_defect(self, defect_ticket):"""处理新的缺陷工单"""# 提取缺陷信息defect_info = self.extract_defect_info(defect_ticket)# 调用Dify工作流分析analysis_result = self.dify_workflow.analyze_defect(defect_info)# 更新工单信息self.update_ticket_with_analysis(defect_ticket, analysis_result)# 自动分配处理人if analysis_result.get('recommended_assignee'):self.assign_ticket(defect_ticket, analysis_result['recommended_assignee'])九、未来展望:缺陷分析的智能化演进
1. 预测性缺陷预防
class PredictiveDefectPrevention:def analyze_code_changes(self, pull_request):"""分析代码变更预测潜在缺陷"""risk_indicators = self.static_code_analysis(pull_request)historical_patterns = self.match_historical_patterns(pull_request)risk_assessment = {'defect_probability': self.calculate_defect_probability(risk_indicators),'potential_impact': self.assess_potential_impact(pull_request),'prevention_suggestions': self.generate_prevention_suggestions(risk_indicators)}return risk_assessment
2. 自动化修复建议
automated_fix_generation:代码修复:输入:"缺陷分析结果 + 相关代码"输出:"具体的代码修复建议"验证:"自动化测试验证"配置修复:输入:"配置相关缺陷"输出:"配置修改建议"验证:"配置语法检查"数据修复:输入:"数据一致性缺陷"输出:"数据修复脚本"验证:"数据完整性检查"
3. 跨系统影响分析
class CrossSystemImpactAnalyzer:def analyze_ripple_effects(self, defect_analysis):"""分析缺陷的跨系统影响"""dependency_graph = self.build_system_dependency_graph()impact_analysis = self.calculate_impact_radius(defect_analysis, dependency_graph)return {'directly_affected_components': impact_analysis['direct'],'indirectly_affected_components': impact_analysis['indirect'],'business_impact_assessment': self.assess_business_impact(impact_analysis)}十、总结:从被动处理到主动预防
通过Dify工作流实现的智能缺陷分析,我们完成了测试质量管理的重大升级:
量化收益总结
🚀 效率提升:缺陷分析时间减少85%
🎯 准确率提升:分类和归因准确率提升25-35%
💰 成本节约:人力成本降低90%以上
📊 质量改进:缺陷解决质量显著提升
质化价值体现
标准化:建立统一的缺陷分析标准
知识化:将专家经验转化为可复用的知识库
自动化:实现缺陷分析的端到端自动化
智能化:基于AI的深度分析和预测预警
实施路线图建议
第一阶段(1-2个月):基础能力建设
部署Dify环境,配置基础工作流
建立缺陷知识库和数据标准
训练团队使用新系统
第二阶段(3-4个月):功能完善
优化分类模型准确率
集成现有缺陷管理系统
建立反馈优化机制
第三阶段(5-6个月):智能升级
实现预测性缺陷预警
建立自学习知识库
扩展跨系统影响分析
第四阶段(持续):卓越运营
持续优化模型性能
探索自动化修复能力
建立质量度量体系
缺陷分析不再是被动的、依赖个人经验的劳动密集型工作,而是变成了主动的、数据驱动的智能决策过程。通过Dify工作流,我们不仅提升了缺陷处理的效率,更重要的是构建了一个持续学习和进化的智能质量管理系统。
现在就开始您的智能缺陷分析之旅,让AI成为您最得力的质量保障伙伴!