AI Agent 核心组件深度解析:规划、记忆与工具使用的底层逻辑


1. 引言:从 "被动执行" 到 "主动决策"——AI Agent 为何不同?
当我们谈论 AI 时,多数场景仍停留在 "输入指令→输出结果" 的被动模式:比如用 ChatGPT 写一篇文章,用 DALL・E 生成一张图片,这些工具本质上是 "一次性响应系统",无法自主处理需要多步骤、多轮交互的复杂任务。
AI Agent 的革命性在于它实现了 "主动决策"—— 就像一个拥有目标的助手,能:
- 接到任务后先思考 "怎么做"(规划)
- 记住过去的经验和中间结果(记忆)
- 遇到不懂的问题时主动查天气、查航班、调用计算器(工具使用)
- 发现错误时自我修正(反思)
举个具体例子:当你让普通 AI 工具 "帮我规划从北京到上海的 3 天旅行",它可能直接生成一份固定行程;但 AI Agent 会:
- 先询问你的出行日期、预算、兴趣偏好(明确目标)
- 分解任务:订机票→订酒店→规划每日行程→推荐餐厅(任务拆分)
- 调用实时航班 API 查余票和价格,调用天气 API 确认出行日天气(工具使用)
- 如果你反馈 "酒店太贵",它会重新调整方案(自我反思)
- 保存你的偏好,下次规划时直接应用(长期记忆)
这种从 "被动响应" 到 "主动决策" 的转变,核心就依赖于规划、记忆、工具使用三大组件的协同工作。本文将逐层拆解这些组件的底层逻辑,让你明白 AI Agent 究竟 "智能" 在哪里。
2. 规划(Planning):Agent 的 "大脑决策系统"
规划是 AI Agent 最核心的能力,决定了它能否像人类一样有条理地解决复杂问题。简单来说,规划模块的任务是:将模糊的目标转化为清晰、可执行的步骤,并能根据执行结果动态调整。
2.1 任务分解:如何将复杂目标拆分为可执行步骤?
复杂目标(如 "做一顿生日晚餐")往往无法一步完成,需要拆解为子任务(买菜→洗菜→烹饪→摆盘)。Agent 的任务分解能力直接决定了其处理复杂问题的上限。
常见的分解策略:
递归分解:从目标出发,逐层拆分直到子任务可直接执行。
- 例:"规划公司年会"→"确定时间地点"→"联系场地供应商"→"确认场地容量 / 价格"
- 实现逻辑:通过 Prompt 引导模型生成分解步骤,如:
请将目标"{{goal}}"分解为不超过5个关键子任务,每个子任务需具体可执行。 输出格式:1. 子任务1;2. 子任务2;...
基于经验库的模板分解:对高频任务预设分解模板,提高效率。
- 例:旅行规划的固定模板:交通→住宿→行程→餐饮→预算
- 实现逻辑:维护任务类型与分解模板的映射表,匹配到已知类型时直接调用模板。
条件触发式分解:根据目标中的关键信息动态决定分解粒度。
- 例:若目标包含 "跨国",则在旅行规划中增加 "签证办理" 子任务
- 实现逻辑:通过关键词匹配或规则引擎触发额外子任务。
代码示例:递归任务分解的核心逻辑
public class TaskDecomposer {private final AiClient aiClient;// 递归分解任务,直到子任务可执行public List<Task> decompose(Task goalTask) {// 检查当前任务是否可直接执行(如是否需要调用工具或简单回答)if (isExecutable(goalTask)) {return List.of(goalTask);}// 调用大模型生成子任务String prompt = String.format("请将任务'%s'分解为3-5个更具体的子任务,每个子任务需可执行。输出格式:1. ... 2. ...",goalTask.getDescription());String response = aiClient.call(new Prompt(prompt)).getGeneration().getText();// 解析模型输出为子任务列表List<Task> subTasks = parseSubTasks(response);// 递归分解每个子任务List<Task> result = new ArrayList<>();for (Task subTask : subTasks) {result.addAll(decompose(subTask));}return result;}// 判断任务是否可直接执行(简化逻辑)private boolean isExecutable(Task task) {// 若任务包含"查询"、"调用"等关键词,或可映射到已知工具,则视为可执行return task.getDescription().contains("查询") || task.getDescription().contains("调用") ||ToolRegistry.hasMatchingTool(task);}
}
2.2 计划制定:动态规划与优先级排序的实现逻辑
分解出子任务后,Agent 需要确定执行顺序(哪些先做?哪些后做?),并形成可执行的计划。这一步的核心是优先级排序和依赖关系处理。
优先级排序策略:
- 时间敏感性:有截止时间的任务优先(如 "今天订机票" 优先于 "明天规划行程")
- 依赖关系:被依赖的任务优先(如 "订机票" 必须在 "规划每日行程" 之前)
- 资源约束:受限于外部资源的任务优先(如 "确认酒店空房" 需在房源紧张时优先)
- 目标相关性:与核心目标关联度高的任务优先(如 "买生日蛋糕" 在生日晚餐准备中优先级最高)
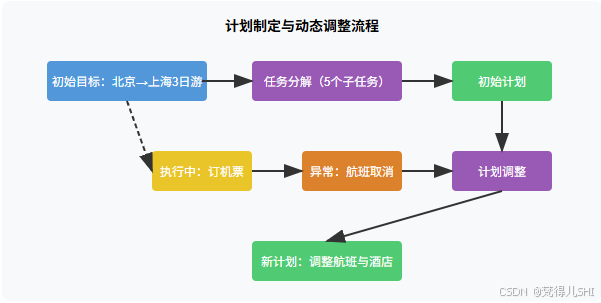
动态计划调整:当某个子任务执行失败或出现新信息时,计划需要实时更新。例如:
- 原计划 "周三飞上海",但查询到周三航班取消→自动调整为周四,并同步修改酒店预订日期
- 新增需求 "要去迪士尼"→在行程中插入 "购买迪士尼门票" 子任务,并调整当天其他安排
可视化:计划制定与调整流程
2.3 自我反思:Agent 如何修正错误、优化决策?
人类解决问题时会不断反思:"刚才的步骤对吗?有没有更优解?"AI Agent 的反思能力同样关键,它能帮助 Agent 从失败中学习,避免重复犯错。
反思的触发场景:
- 执行失败:子任务未完成(如 "查询航班" 返回空结果)→反思 "是否日期错误?是否城市名拼写错误?"
- 结果不符预期:生成的方案被用户否定(如 "酒店预算超支")→反思 "预算参数是否遗漏?价格查询是否准确?"
- 效率低下:完成任务的步骤过多→反思 "是否有更简洁的路径?"
反思的实现方式:
- 基于规则的反思:预设错误类型与修正策略(如 "若航班查询失败,则检查日期格式")
- 基于大模型的深度反思:让模型生成反思报告,如:
你刚才执行了任务:{{task}},结果是:{{result}}。 请分析可能的失败原因(至少2点),并提出具体的修正方案。
代码示例:基于反馈的反思逻辑
public class Reflector {private final AiClient aiClient;// 根据执行结果进行反思,生成修正方案public Task修正方案 reflect(Task task, TaskResult result) {// 若任务成功且结果符合预期,无需反思if (result.isSuccess() && result.meetsExpectation()) {return null;}// 构建反思PromptString prompt = String.format("""任务描述:%s执行结果:%s问题:%s请分析失败原因,并提出具体的修正步骤(1-2步即可)。""", task.getDescription(), result.getContent(), result.getErrorMessage());// 调用模型生成修正方案String reflection = aiClient.call(new Prompt(prompt)).getGeneration().getText();// 解析修正方案为新的任务列表return parse修正方案(reflection);}
}
反思的价值:单一任务的修正可能微不足道,但长期来看,反思能让 Agent 的决策质量持续提升,逐渐适应复杂场景的变化。
3. 记忆(Memory):Agent 的 "经验积累系统"
如果说规划是 Agent 的 "思考能力",那么记忆就是 Agent 的 "经验基础"。没有记忆的 Agent 就像 "金鱼"—— 每次交互都是全新的开始,无法利用历史信息优化决策。Agent 的记忆系统分为短期记忆和长期记忆,二者分工不同但协同工作。
3.1 短期记忆:对话上下文的存储与管理策略
短期记忆(Short-Term Memory)主要存储当前会话的上下文信息,比如:
- 用户的最新需求("我想住靠近地铁站的酒店")
- 刚刚执行的子任务结果("查询到 3 家符合条件的酒店")
- 临时产生的中间结论("用户预算在 500 元 / 晚以内")
核心特点:
- 生命周期短:随会话结束而失效(如用户关闭聊天窗口)
- 容量有限:通常只保留最近几轮交互(避免信息过载)
- 访问速度快:多存储在内存中,无需复杂检索
管理策略:
滑动窗口机制:只保留最近 N 条消息(如最近 5 轮对话), older 信息自动丢弃。
public class ShortTermMemory {private final int maxSize = 5; // 最大存储5条消息private final LinkedList<Message> messages = new LinkedList<>();public void addMessage(Message message) {messages.add(message);// 超过容量时移除最早的消息if (messages.size() > maxSize) {messages.removeFirst();}}// 获取当前上下文public List<Message> getContext() {return new ArrayList<>(messages);} }关键信息提取:不存储原始消息,而是提取关键信息(如用户偏好、任务状态),减少冗余。
- 例:从 "我是学生,预算有限,想住便宜点的酒店,最好离景点近" 中提取:
{ "userType": "student", "budget": "limited", "preference": "cheap, near attractions" }
- 例:从 "我是学生,预算有限,想住便宜点的酒店,最好离景点近" 中提取:
3.2 长期记忆:向量数据库如何实现知识的持久化与高效检索?
长期记忆(Long-Term Memory)用于存储需要长期复用的信息,比如:
- 用户的历史偏好("用户每年夏天都去海边旅行")
- 通用知识("上海迪士尼需要提前预约")
- 成功的任务解决方案("规划北京到上海行程的最优步骤")
核心挑战:如何高效存储海量信息,并在需要时快速检索相关内容?
解决方案:向量数据库 + 语义检索
向量嵌入(Embedding):将文本信息转换为数值向量(如 768 维数组),语义相似的文本向量距离更近。
- 例:"订机票" 和 "购买航班" 的向量距离很近,而和 "订酒店" 的距离较远。
向量数据库:专门存储向量的数据库(如 Pinecone、Milvus、Chroma),支持高效的近似最近邻(ANN)搜索。
检索流程:
- 当 Agent 需要相关知识时,将当前问题转换为向量
- 在向量数据库中搜索最相似的 N 个向量
- 将对应的文本信息提取出来,作为上下文输入大模型
代码示例:长期记忆的存储与检索
public class LongTermMemory {private final EmbeddingModel embeddingModel; // 向量生成模型private final VectorStore vectorStore; // 向量数据库// 存储信息到长期记忆public void store(String information, String metadata) {// 生成文本向量List<Double> embedding = embeddingModel.embed(information);// 存储到向量数据库(带元数据便于过滤)vectorStore.add(VectorRecord.builder().embedding(embedding).content(information).metadata(Map.of("type", metadata)).build());}// 检索相关信息public List<String> retrieve(String query, int topK) {// 将查询转换为向量List<Double> queryEmbedding = embeddingModel.embed(query);// 搜索最相似的topK条记录List<VectorRecord> results = vectorStore.search(SearchRequest.builder().queryEmbedding(queryEmbedding).topK(topK).build());// 提取文本内容return results.stream().map(VectorRecord::getContent).collect(Collectors.toList());}
}
适用场景:
- 用户偏好存储("记住用户对辣的食物过敏")
- 历史交互记录("用户去年去了三亚,喜欢海景房")
- 领域知识沉淀("记录各航空公司的行李政策")
3.3 记忆协同:短期与长期记忆的交互机制
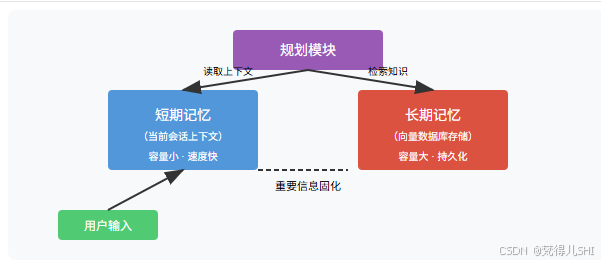
短期记忆和长期记忆并非孤立存在,而是通过协同机制共同支撑 Agent 的决策:
信息流转:短期记忆中的重要信息会被 "固化" 到长期记忆。
- 例:用户在当前会话中提到 "我喜欢素食"→短期记忆暂存→会话结束后,若判断为长期偏好,则存储到向量数据库。
检索触发:当短期记忆不足以支持决策时,自动触发长期记忆检索。
- 例:Agent 规划行程时,短期记忆中有 "用户喜欢安静"→触发长期记忆检索 "用户过去住过的安静酒店类型"。
优先级策略:短期记忆的信息优先级高于长期记忆(避免使用过时信息)。
- 例:若用户现在说 "预算 1000 元",而长期记忆中是 "用户去年预算 500 元",则以短期记忆为准。
可视化:记忆协同机制
3.4 对比分析:不同记忆类型的适用场景与性能特征
| 记忆类型 | 存储内容 | 存储介质 | 容量限制 | 访问速度 | 典型使用场景 |
|---|---|---|---|---|---|
| 短期记忆 | 会话上下文、临时结果 | 内存(如 List) | 小(数条) | 极快 | 当前任务的中间状态、用户最新需求 |
| 长期记忆 | 用户偏好、历史记录、知识 | 向量数据库 | 大(无限) | 较快(依赖检索效率) | 复用历史经验、调用领域知识 |
选择原则:
- 临时、会话内有效的信息→短期记忆
- 长期复用、跨会话的信息→长期记忆
- 平衡存储成本:高频访问的重要信息优先长期存储
4. 工具使用(Tool Use):Agent 的 "能力扩展接口"
大模型本身的能力是有限的 —— 它无法实时获取天气数据、查询航班余票、执行复杂计算。工具使用模块让 Agent 突破这些局限,通过调用外部资源扩展能力边界,就像人类使用计算器、查字典、打电话一样。
4.1 工具抽象层:如何定义统一的工具调用规范?
Agent 可能需要调用多种工具(API、数据库、代码解释器等),为了避免每种工具单独开发适配逻辑,需要定义统一的工具抽象层。
核心接口设计:
// 工具接口:所有工具都需实现
public interface Tool {// 工具名称(唯一标识)String getName();// 工具描述(用于Agent判断是否调用)String getDescription();// 工具参数定义(用于Agent生成调用参数)List<ToolParameter> getParameters();// 执行工具并返回结果ToolResult execute(Map<String, Object> parameters);
}// 参数定义
public class ToolParameter {private String name; // 参数名private String type; // 类型(string/int/boolean等)private String description; // 参数描述private boolean required; // 是否必填
}
工具注册与管理:
public class ToolRegistry {private final Map<String, Tool> tools = new HashMap<>();// 注册工具public void register(Tool tool) {tools.put(tool.getName(), tool);}// 根据名称获取工具public Tool getTool(String name) {return tools.get(name);}// 获取所有工具的描述(用于Agent选择工具)public String getToolsDescription() {StringBuilder sb = new StringBuilder();for (Tool tool : tools.values()) {sb.append(tool.getName()).append(": ").append(tool.getDescription()).append("\n");sb.append("参数:").append(tool.getParameters()).append("\n");}return sb.toString();}
}
抽象层的价值:Agent 只需基于统一接口调用工具,无需关心工具的具体实现(是调用 HTTP API 还是数据库),新增工具时只需实现接口并注册,无需修改 Agent 核心逻辑。
4.2 API 调用:从参数解析到响应处理的完整流程
调用外部 API 是 Agent 最常用的工具能力(如查天气、订酒店、获取新闻)。完整流程包括:工具选择→参数生成→API 调用→结果解析。
第一步:工具选择
Agent 根据当前任务判断需要调用的工具。例如,任务是 "查询上海明天的天气"→匹配到 "天气查询 API"。
实现逻辑:通过 Prompt 让模型从工具列表中选择,如:
当前任务:{{task}}
可用工具:{{toolsDescription}}
请选择最合适的工具(只需返回工具名称):
第二步:参数生成
确定工具后,Agent 需要生成符合要求的参数。例如,天气 API 需要 "城市名" 和 "日期"。
实现逻辑:
你需要调用工具:{{toolName}}
工具参数要求:{{toolParameters}}
当前任务信息:{{task}}
请生成符合要求的参数(JSON格式):
第三步:执行调用与结果处理
调用 API 并处理响应(成功则用结果继续执行任务,失败则触发反思)。
代码示例:天气 API 工具实现
public class WeatherApiTool implements Tool {private final String apiKey;private final RestTemplate restTemplate;public WeatherApiTool(String apiKey) {this.apiKey = apiKey;this.restTemplate = new RestTemplate();}@Overridepublic String getName() {return "weatherApi";}@Overridepublic String getDescription() {return "查询指定城市和日期的天气情况";}@Overridepublic List<ToolParameter> getParameters() {return List.of(new ToolParameter("city", "string", "城市名称(如上海)", true),new ToolParameter("date", "string", "日期(格式:YYYY-MM-DD)", true));}@Overridepublic ToolResult execute(Map<String, Object> parameters) {String city = (String) parameters.get("city");String date = (String) parameters.get("date");// 调用天气APIString url = String.format("https://api.weather.com/v3/weather?city=%s&date=%s&key=%s",URLEncoder.encode(city, StandardCharsets.UTF_8),date,apiKey);try {WeatherResponse response = restTemplate.getForObject(url, WeatherResponse.class);return ToolResult.success(response.toString());} catch (Exception e) {return ToolResult.failure("查询失败:" + e.getMessage());}}
}
4.3 数据库操作:Agent 如何执行 SQL 实现数据查询与分析?
当 Agent 需要处理结构化数据(如用户订单、产品库存)时,需调用数据库工具执行 SQL 查询。
核心挑战:将自然语言转换为正确的 SQL 语句(如 "查询近 30 天销售额超过 10 万的产品"→生成对应的 SELECT 语句)。
实现方案:
定义数据库工具:支持执行 SQL 并返回结果
public class DatabaseTool implements Tool {private final JdbcTemplate jdbcTemplate;@Overridepublic String getName() {return "databaseTool";}@Overridepublic String getDescription() {return "执行SQL查询数据库,获取结构化数据";}@Overridepublic List<ToolParameter> getParameters() {return List.of(new ToolParameter("sql", "string", "SQL查询语句(仅支持SELECT)", true));}@Overridepublic ToolResult execute(Map<String, Object> parameters) {String sql = (String) parameters.get("sql");// 限制只执行SELECT语句,防止安全风险if (!sql.trim().toLowerCase().startsWith("select")) {return ToolResult.failure("仅支持SELECT查询");}try {List<Map<String, Object>> result = jdbcTemplate.queryForList(sql);return ToolResult.success(result.toString());} catch (Exception e) {return ToolResult.failure("SQL执行失败:" + e.getMessage());}} }生成 SQL 语句:通过大模型将自然语言转换为 SQL,需提供表结构信息
数据库表结构: - 表名:products,字段:id(产品ID)、name(名称)、sales(销售额)、date(日期)请将以下查询转换为SQL:"查询近30天销售额超过10万的产品名称和销售额" SQL语句:
4.4 代码执行:通过 Python/Java 扩展逻辑处理能力
对于复杂计算(如数据分析、图表生成、数学建模),纯自然语言处理效率低且容易出错。Agent 可通过代码执行工具调用 Python/Java 等语言的代码片段。
实现方案:集成代码解释器(如 Python 的 exec 函数、Java 的脚本引擎)。
代码示例:Python 代码执行工具
public class PythonCodeTool implements Tool {private final PythonInterpreter interpreter; // 需引入Jython依赖@Overridepublic String getName() {return "pythonCodeTool";}@Overridepublic String getDescription() {return "执行Python代码,处理复杂计算或数据分析";}@Overridepublic List<ToolParameter> getParameters() {return List.of(new ToolParameter("code", "string", "Python代码片段", true));}@Overridepublic ToolResult execute(Map<String, Object> parameters) {String code = (String) parameters.get("code");try {// 执行代码并捕获输出interpreter.exec(code);// 获取变量或输出结果PyObject result = interpreter.get("result");return ToolResult.success(result.toString());} catch (Exception e) {return ToolResult.failure("代码执行失败:" + e.getMessage());}}
}
使用场景:
- 数据分析:"用 Python 计算近 5 年销售额的年均增长率"
- 数学计算:"解一元二次方程 3x² + 5x - 2 = 0"
- 格式转换:"将 JSON 数据转换为 CSV 格式"
4.5 安全边界:工具调用中的权限控制与风险防护
工具调用是一把 "双刃剑"—— 能力扩展的同时也带来安全风险(如恶意 SQL 注入、API 滥用、代码执行漏洞)。必须建立严格的安全边界。
核心防护策略:
最小权限原则:
- 数据库工具仅授予 SELECT 权限,禁止 INSERT/UPDATE/DELETE
- API 调用限制访问范围(如只允许调用天气、航班等公开 API)
- 代码执行工具禁用文件操作、网络请求等危险函数
输入验证:
- 对工具参数进行格式校验(如日期必须符合 YYYY-MM-DD)
- 过滤 SQL 中的危险关键字(如 DROP、ALTER)
- 限制代码执行的时间和资源(如最多运行 10 秒,内存不超过 100MB)
审计日志:记录所有工具调用的详细信息(调用者、时间、参数、结果),便于追溯异常行为。
// 安全包装器:在工具执行前后添加安全检查
public class SecureToolWrapper implements Tool {private final Tool targetTool;private final AuditLogger auditLogger;@Overridepublic ToolResult execute(Map<String, Object> parameters) {// 1. 记录审计日志(调用前)auditLogger.log("工具调用开始", targetTool.getName(), parameters);// 2. 输入验证if (!validateParameters(targetTool, parameters)) {auditLogger.log("工具调用失败(参数无效)", targetTool.getName(), parameters);return ToolResult.failure("参数无效");}// 3. 执行工具ToolResult result = targetTool.execute(parameters);// 4. 记录审计日志(调用后)auditLogger.log("工具调用结束", targetTool.getName(), result);return result;}// 参数验证逻辑private boolean validateParameters(Tool tool, Map<String, Object> parameters) {// 省略:根据tool.getParameters()验证参数类型、必填项、格式等}
}
5. 实战:构建一个旅行规划 Agent(完整案例)
5.1 需求分析:旅行规划的核心任务与 Agent 能力边界
核心目标:用户输入出发地、目的地、时间、预算等信息后,Agent 能自主规划完整行程,包括交通、住宿、每日活动、餐饮推荐。
核心任务分解:
- 收集用户需求(出发地、目的地、日期、预算、偏好)
- 查询交通方案(航班 / 高铁的时间、价格、余票)
- 预订住宿(符合预算和偏好的酒店 / 民宿)
- 规划每日行程(景点、开放时间、路线)
- 推荐餐饮(当地特色、符合口味偏好)
- 汇总行程并计算总预算
Agent 能力边界:
- 能调用外部工具(航班 API、酒店 API、天气 API、景点 API)
- 能记忆用户偏好(如 "不喜欢辣的食物"、"偏好四星酒店")
- 能根据实时信息调整计划(如航班取消时自动更换)
5.2 组件设计:规划、记忆与工具的协同方案
1. 规划模块设计:
- 任务分解模板:固定按 "交通→住宿→行程→餐饮→预算" 分解
- 优先级规则:交通(需确认日期)> 住宿(依赖交通日期)> 其他
- 反思触发:当某类工具调用失败(如无符合条件的酒店)时,反思是否需要调整预算或日期
2. 记忆系统设计:
- 短期记忆:存储当前会话的用户输入(日期、预算、偏好)、已查询的交通 / 酒店信息
- 长期记忆:存储用户历史旅行偏好(如 "2023 年去北京时选择了连锁酒店")、目的地常识(如 "上海迪士尼需提前预约")
- 记忆协同:规划住宿时,先从短期记忆获取当前预算,再从长期记忆检索用户偏好的酒店类型
3. 工具集成清单:
- 交通查询工具:调用 12306 API 查询高铁,调用飞猪 API 查询航班
- 住宿查询工具:调用携程 API 查询酒店
- 天气查询工具:调用高德天气 API
- 景点查询工具:调用马蜂窝 API 获取景点信息
- 餐饮推荐工具:调用大众点评 API
5.3 代码实现:核心模块的关键代码
第一步:Agent 核心控制器
public class TravelPlannerAgent {private final TaskPlanner planner; // 规划模块private final ShortTermMemory shortTermMemory; // 短期记忆private final LongTermMemory longTermMemory; // 长期记忆private final ToolRegistry toolRegistry; // 工具注册中心private final AiClient aiClient; // 大模型客户端// 处理用户请求的入口方法public String handleRequest(String userInput) {// 1. 将用户输入存入短期记忆shortTermMemory.addMessage(new UserMessage(userInput));// 2. 从长期记忆检索相关信息(如用户历史偏好)List<String> userPreferences = longTermMemory.retrieve(userInput, 3);// 3. 构建当前上下文(短期记忆 + 长期记忆)String context = buildContext(shortTermMemory.getContext(), userPreferences);// 4. 规划任务(确定下一步要做什么)Task currentTask = planner.plan(context);// 5. 执行任务(若需要工具则调用工具)TaskResult result = executeTask(currentTask);// 6. 若任务失败,触发反思并调整if (!result.isSuccess()) {Task修正方案修正方案 = new Reflector(aiClient).reflect(currentTask, result);currentTask = 修正方案.toTask();result = executeTask(currentTask);}// 7. 将结果存入短期记忆,并判断是否需要存入长期记忆shortTermMemory.addMessage(new AiMessage(result.getContent()));if (shouldStoreToLongTerm(result.getContent())) {longTermMemory.store(result.getContent(), "user_preference");}// 8. 判断是否完成所有任务,若完成则生成最终行程if (planner.allTasksCompleted()) {return generateFinalItinerary();} else {// 未完成则继续处理下一个任务return result.getContent() + "\n正在为您规划下一步...";}}// 执行任务(调用工具或直接回答)private TaskResult executeTask(Task task) {if (task.needsTool()) {// 需要工具:选择工具→生成参数→执行String toolName = planner.selectTool(task);Tool tool = toolRegistry.getTool(toolName);Map<String, Object> parameters = planner.generateToolParameters(task, tool);return tool.execute(parameters);} else {// 不需要工具:直接调用大模型生成结果String prompt = "基于上下文回答:" + task.getDescription();return TaskResult.success(aiClient.call(new Prompt(prompt)).getGeneration().getText());}}
}
第二步:关键工具实现(以酒店查询为例)
public class HotelSearchTool implements Tool {private final HotelApiClient apiClient; // 酒店API客户端@Overridepublic String getName() {return "hotelSearchTool";}@Overridepublic String getDescription() {return "查询指定城市、日期、预算的酒店信息";}@Overridepublic List<ToolParameter> getParameters() {return List.of(new ToolParameter("city", "string", "城市名称", true),new ToolParameter("checkInDate", "string", "入住日期(YYYY-MM-DD)", true),new ToolParameter("checkOutDate", "string", "退房日期(YYYY-MM-DD)", true),new ToolParameter("maxPrice", "int", "最高预算(元/晚)", true),new ToolParameter("amenities", "string", "设施偏好(如免费WiFi、停车场)", false));}@Overridepublic ToolResult execute(Map<String, Object> parameters) {try {HotelSearchRequest request = new HotelSearchRequest((String) parameters.get("city"),(String) parameters.get("checkInDate"),(String) parameters.get("checkOutDate"),(Integer) parameters.get("maxPrice"),(String) parameters.get("amenities"));List<Hotel> hotels = apiClient.searchHotels(request);// 格式化结果StringBuilder result = new StringBuilder("找到以下符合条件的酒店:\n");for (Hotel hotel : hotels) {result.append("- ").append(hotel.getName()).append(",价格:").append(hotel.getPrice()).append("元/晚,地址:").append(hotel.getAddress()).append("\n");}return ToolResult.success(result.toString());} catch (Exception e) {return ToolResult.failure("酒店查询失败:" + e.getMessage());}}
}
5.4 测试验证:多场景下的 Agent 表现
场景 1:基础需求规划
用户输入:"帮我规划从北京到上海的3天旅行,6月10日出发,预算5000元,喜欢博物馆和特色美食。"Agent 执行流程:
1. 短期记忆存储用户输入,长期记忆检索到"用户2022年曾参观过故宫,喜欢历史类景点"
2. 规划模块分解任务:查高铁→订酒店→规划每日行程→推荐美食
3. 调用高铁API查询6月10日北京→上海的高铁,返回3个选项
4. 调用酒店API查询上海市区靠近地铁、预算内的酒店,返回4家
5. 结合天气API(6月10日上海多云)规划行程:- D1:上海博物馆 + 豫园- D2:外滩 + 南京路步行街- D3:迪士尼乐园(调用景点API确认开放时间)
6. 调用大众点评API推荐上海本帮菜餐厅(避开辣的选项)
7. 汇总行程,计算总预算4800元,返回给用户
场景 2:异常处理(酒店查询失败)
用户输入:"帮我订6月10日上海迪士尼附近的酒店,预算300元/晚。"Agent 执行流程:
1. 调用酒店API查询,返回"无符合条件的酒店"(失败)
2. 触发反思:"是否预算过低?是否日期错误?"
3. 生成修正方案:"建议提高预算至500元/晚,或调整日期至非周末"
4. 询问用户:"未找到300元/晚的酒店,是否接受提高预算至500元?"
5. 用户同意后,重新查询并返回结果
6. 避坑指南:Agent 开发中的常见问题与解决方案
6.1 规划陷阱:任务分解循环与计划冗余
问题表现:
- 任务分解陷入循环(如 "规划行程→确定交通→规划行程")
- 生成过多冗余步骤(如查询同一航班 3 次)
解决方案:
- 设定最大分解深度(如最多分解 3 层),超过则强制停止
- 记录已执行任务,避免重复调用(如 "10 分钟内不重复查询同一航班")
- 对高频任务使用固定模板,减少动态分解的不确定性
6.2 记忆瓶颈:检索精度与存储成本
问题表现:
- 长期记忆检索结果不相关(如查询 "上海酒店" 返回 "北京景点")
- 向量数据库存储成本过高(尤其当记忆内容海量时)
解决方案:
- 优化嵌入模型:使用领域专用的嵌入模型(如针对旅行的嵌入模型)
- 添加元数据过滤:检索时结合元数据(如 "type:hotel")提高相关性
- 记忆清理策略:定期删除低价值记忆(如 1 年未被检索的内容)
6.3 工具风险:调用失败与安全漏洞
问题表现:
- 工具调用频繁失败(如 API 超时、参数错误)
- 存在 SQL 注入、恶意代码执行等安全风险
解决方案:
- 实现工具调用重试机制(结合指数退避策略)
- 对所有用户输入和工具参数进行严格校验(如 SQL 参数化查询)
- 限制工具调用频率(如同一 IP 每分钟最多调用 10 次)
6.4 性能优化:减少决策步骤与提升响应速度
问题表现:
- Agent 决策步骤过多,响应时间过长(如规划一个行程需要 10 分钟)
- 高并发场景下系统卡顿
解决方案:
- 预计算高频任务的中间结果(如热门城市的交通方案)
- 简化规划逻辑:对简单任务使用固定流程,复杂任务才启用动态规划
- 异步执行非关键任务(如背景更新长期记忆,不阻塞主流程)
7. 未来趋势:AI Agent 的演进方向与技术突破点
AI Agent 正朝着更自主、更智能、更协作的方向发展,未来的突破点可能包括:
- 多 Agent 协作:多个专业 Agent 协同完成复杂任务(如旅行规划 Agent + 财务 Agent + 签证 Agent)
- 自主进化能力:通过持续的自我反思和经验积累,自动优化决策模型
- 具身智能:结合物理世界感知能力(如摄像头、传感器),实现实体场景的自主操作
- 情感理解:融入情感分析,根据用户情绪调整沟通方式和决策策略
- 轻量化部署:在边缘设备(如手机、智能家居)上运行的轻量级 Agent,降低依赖
8. 结语:构建真正 "自主智能" 的核心思考
AI Agent 的价值不在于 "模仿人类",而在于通过规划、记忆、工具使用的协同,实现 "超越人类个体能力" 的高效问题解决。从技术角度看,构建可靠的 Agent 系统需要平衡灵活性与稳定性 —— 既要有动态适应复杂场景的能力,又要通过工程化手段规避风险。
作为开发者,我们需要理解:Agent 的 "智能" 并非源于单一组件的强大,而是组件间的协同效率。规划模块决定了目标是否可达,记忆系统决定了经验能否复用,工具使用决定了能力边界能否扩展。只有三者有机结合,才能构建出真正能自主解决问题的智能系统。
未来已来,AI Agent 正在重新定义人与机器的交互方式。掌握其核心原理与开发技巧,不仅能跟上技术浪潮,更能创造出真正改变生活的智能应用。
欢迎在评论区分享你对 AI Agent 未来发展的看法,或提出开发中遇到的技术难题,一起探讨解决方案!