RAGFlow:部署、理论与实战(一)
概述
官网,文档,GitHub,66.9K Star,7.1K Fork,但是Issues也挺高,2.9K,说明用户量是真多。
本文先汇总梳理一些核心功能和功能模块,有待进一步深入实战。
RAGFlow是一个基于对文档深入理解的开源RAG引擎,让用户创建自有知识库,根据设定参数对知识库文件进行切块处理,用户向LLM提问时,RAGFlow先查找自有知识库中的切块内容,把查找到的知识库数据输入到对话大模型中再生成答案输出。
能凭借引用知识库中各种复杂格式的数据为后盾,为用户提供真实可信,少幻觉的答案。技术原理涵盖文档理解、检索增强、生成模型、注意力机制等,特别强调深度文档理解技术,能够从复杂格式的非结构化数据中提取关键信息。
功能特性:
- Quality in, quality out
- 基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见
- 真正在无限上下文(token)的场景下快速完成大海捞针测试
- 基于模板的文本切片
- 多种文本模板可供选择
- 文本切片过程可视化,支持手动调整
- 有理有据:答案提供关键引用的快照并支持追根溯源
- 兼容各类异构数据源:支持丰富的文件类型,包括Word、PPT、Excel、TXT、图片、PDF、影印件、复印件、结构化数据、网页等
- 全面优化的RAG工作流
- 提供易用的API,可支持从个人应用、集成到各类超大型企业生态系统
- LLM以及向量模型均支持配置
- 基于多路召回、融合重排序
架构
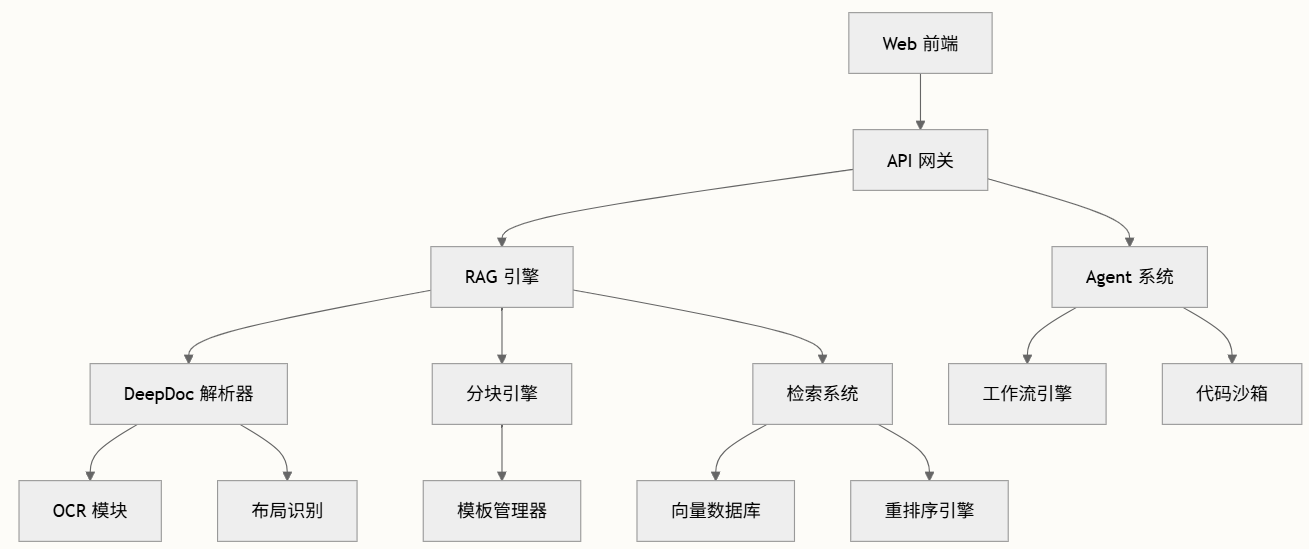
核心组件
| 组件 | 用途 | 关键文件 |
|---|---|---|
| API服务器 | 主HTTP服务器和请求路由 | api/ragflow_server.py |
| RAG引擎 | 文档处理与检索 | rag目录 |
| DeepDoc | 文档解析与理解 | deepdoc目录 |
| Web前端 | 用户界面与交互 | web目录 |
| Agent系统 | 工作流自动化与工具 | agent目录 |
提供多个分块模板,以便于不同布局的文件进行分块,并确保语义完整性。在分块方法(Chunk Method)中,可选择适合文件布局和格式的默认模板。
嵌入模型(embedding model),选择默认的BAAI/bge-large-zh-v1.5,专门针对中文语义理解进行优化,能够将文本映射为低维稠密向量,可用于检索、分类、聚类或语义匹配等任务。
在其聊天中使用全文搜索和矢量搜索的多次调用。在设置AI聊天之前,请考虑调整以下参数以确保预期信息始终出现在答案中:
- 相似度阈值:相似度低于阈值的数据块将被过滤。默认为0.2;
- 向量相似度权重:向量相似度占总分的百分比。默认为0.3。
必须先对上传的文件进行解析,才能让RAGFlow执行检索知识库功能。文件解析是知识库配置中的一个关键步骤。RAGFlow文件解析的含义有两个:基于文件布局对文件进行分块,并在这些块上构建嵌入和全文(关键字)索引。选择chunk方法和embedding模型后,可以开始解析文件:
RAGFlow使用的是混合检索,结合关键词检索和向量检索的优势,提供更准确和全面的搜索结果。
部署
通过Docker部署:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/docker
docker compose up -d
DeepDoc
在切片之前,需要将各类文档转换为文本格式,利用DeepDoc来实现。由两个主要组件组成:用于格式特定文档处理的解析器模块和用于OCR与布局识别功能的视觉模块。
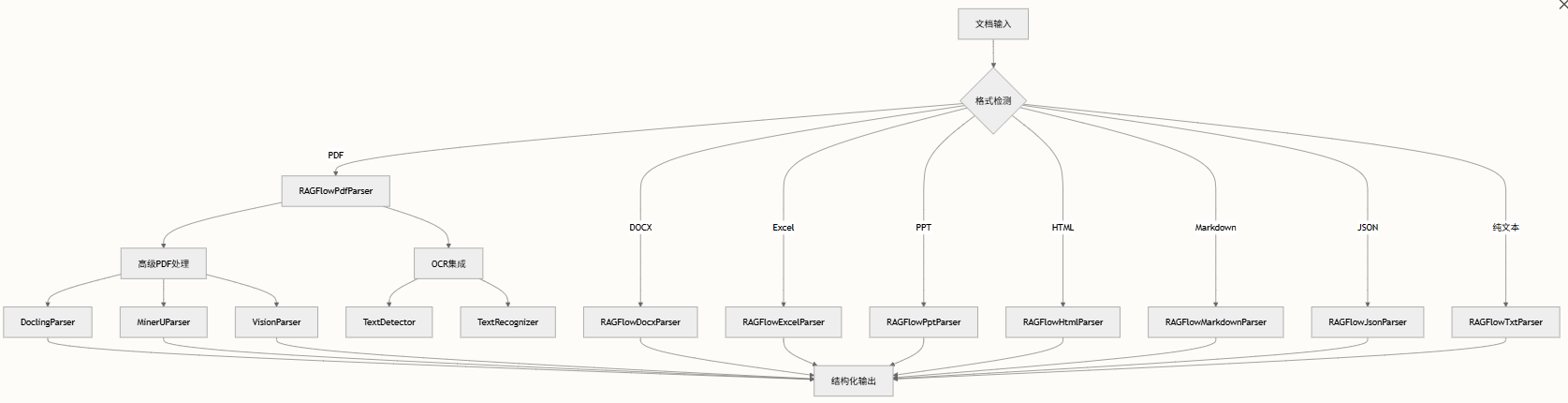
parser解析器:可以看到包括有如下的这些不同类型的文件解析器。
- DOCX:Word 文档解析,支持表格内容提取
- Excel:电子表格处理,支持 HTML 和 markdown 输出
- HTML:网页内容解析,具备智能文本分块功能
- JSON:JSON 文档处理,适用于结构化数据
- Markdown:结构化markdown处理,支持元素提取
- PDF:最复杂,灵活性高,pdf解析器的输出包括:在PDF中有自己位置的文本块(页码和矩形位置);带有PDF裁剪图像的表格,以及已经翻译成自然语言句子的内容;图中带标题和文字的图。
- PPT:PPT解析
- TXT:纯文本处理,支持编码检测
- figure
所有解析器遵循统一的接口模式,实现__call__方法进行文档处理。
PDF解析器是最复杂的组件,支持多种处理策略:
RAGFlowPdfParser作为基础,实现包含OCR、布局识别、表格提取和文本合并的综合流水线来源。处理遵循结构化序列:
- 图像处理:
__images__()将PDF页面转换为图像以进行OCR分析 - 布局识别:
_layouts_rec()识别文档结构和内容块 - 表格检测:
_table_transformer_job()使用ML模型提取表格数据 - 文本合并:
_text_merge()合并相关文本元素 - 内容过滤:
_filter_forpages()移除无关内容 - 最终提取:返回结构化文本和提取的表格/图表
解析器支持多种输出格式,通过集成的OCR功能处理基于文本和扫描的PDF来源。
高级PDF引擎
DoclingParser使用Docling引擎提供最先进的PDF处理,支持文本、表格、图像和方程式等高级内容类型识别来源。解析器提取带有精确边界框信息的结构化内容,并维护文档层次结构。
MinerUParser使用MinerU框架提供另一种高级PDF处理选项,支持代码块和列表等额外内容类型来源。两种解析器都扩展了基础RAGFlowPdfParser类,同时提供专门的处理流水线。
视觉处理:
- OCR:许多文档都是以图像形式呈现的,或者至少能够转换为图像,因此OCR是文本提取的一个非常重要、基本,甚至通用的解决方案。
- Recognizer:接收图像→预处理→模型推理→后处理→返回识别结果(包含类型、边界框和置信度)。
- LayoutRecognizer:布局识别,来自不同领域的文件有不同的布局。只有当机器有准确的布局分析时,才能决定这些文本部分是连续的还是不连续的,或这个部分需要TSR来处理,或者这个部件是一个图形并用这个标题来描述。RAGFlow提供10个基本布局组件:文本、标题、配图、配图标题、表格、表格标题、页头、页尾、参考引用、公式。
- TSR:Table Structure Recognition,表结构识别,数据表是一种常用的结构,用于表示包括数字或文本在内的数据。表的结构可能非常复杂,比如层次结构标题、跨单元格和投影行标题。除了TSR,我们还将内容重新组合成LLM可以很好理解的句子。TSR任务有五个标签:列、行、列标题、行标题、合并单元格。
init_in_out:用于初始化输入和输出的函数,主要功能是处理输入文件(图像或PDF)并准备相应的输出路径。这个函数在视觉识别流程中起到了准备数据的作用,为后续的识别过程提供了标准化的输入和输出路径。
DeepDoc框架与RAGFlow的更广泛架构无缝集成:
- 文档摄取:直接集成RAGFlow的文档处理管道
- 分块策略:支持基于模板的分块以优化RAG性能
- 引用管理:位置跟踪实现精确的引用生成
- 多模态支持:视觉功能支持处理图像密集型文档
分块方法
采用基于模板的文本切片方法(Template-based chunking),提供11种切片方法:
- General:覆盖所有文件类型和格式,如DOCX、XLSX、XLS(Excel97~2003)、PPT、PDF、TXT、JPEG、JPG、PNG、TIF、GIF、CSV、JSON、EML、HTML。切片逻辑:
- 使用视觉检测模型将连续文本分割成多个片段。
- 这些连续的片段被合并成Token数不超过Token数的块。
- Q&A:支持Excel和CSV、TXT格式。
- 对于Excel,应由两个列(问题和答案)组成,没有标题;答案列之前的问题列。支持正确列结构的多sheet;
- 对于CSV、TXT,以UTF-8编码,用TAB作分开问题和答案的定界符(这个规则适用于下面其他类型的分块方法);
- 未能遵循上述规则的文本行将被忽略,并且每个问答对将被认为是一个独特的部分。
- Resume:支持DOCX、PDF、TXT格式。简历有多种格式,但经常必须将它们组织成结构化数据,以便于搜索。不是将简历分块,而是将简历解析为结构化数据。
- Manual:仅支持PDF。假设手册具有分层部分结构。使用最低的部分标题作为对文档进行切片的枢轴。因此,同一部分中的图和表不会被分割,并且块大小可能会很大。
- Table:支持XLSX和CSV/TXT文件。
- 第一行必须是列标题;
- 列标题必须是有意义的术语,以便LLM能够理解。列举一些同义词时最好使用斜杠
/来分隔,甚至更好使用方括号枚举值,如'gender/sex(male,female)'; - 表中的每一行都将被视为一个块。
- Paper:仅支持PDF文件。如果模型运行良好,论文将按其部分进行切片,例如摘要、1.1、1.2等。优势是LLM可以更好的概括论文中相关章节的内容,产生更全面答案。缺点是增加LLM对话的背景并增加计算成本,可考虑减少
topN设置。 - Book:支持的文件格式为DOCX、PDF、TXT。由于一本书很长,并不是所有部分都有用,如果是PDF,请为每本书设置页面范围,以消除负面影响并节省分析计算时间。
- Laws:支持的文件格式为DOCX、PDF、TXT。法律文件有非常严格的书写格式。使用文本特征来检测分割点;chunk的粒度与’ARTICLE’一致,所有上层文本都会包含在chunk中。
- Presentation:支持PDF、PPTX格式,每个页面都将被视为一个块。每个页面的缩略图都会被存储;所有PPT文件都会使用此方法自动分块,无需为每个PPT文件进行设置。
- One:支持DOCX、EXCEL、PDF、TXT格式。文档将被视为一个完整的块,根本不会被分割。如果要总结的东西需要一篇文章的全部上下文,并且所选LLM的上下文长度覆盖文档长度,可以尝试这种方法。
- Tag:支持XLSX和CSV/TXT文件格式。
- 使用Tag分块方法的知识库用作标签集.其他知识库可以把标签集当中的标签按照相似度匹配到自己对应的文本块中,对这些知识库的查询也将根据此标签集对自己进行标记;
- 使用标签作为分块方法的知识库不参与RAG检索过程;
- 标签集中的每个文本分块是都是相互独立的标签和标签描述的文本对;
- 如果文件为XLSX格式,则它应该包含两列无标题:一列用于标签描述,另一列用于标签,标签描述列位于标签列之前。支持多个工作表,只要列结构正确即可;
- 在标签列中,标签之间使用英文逗号分隔。不符合上述规则的文本行将被忽略。
RAPTOR策略
标签集
Tag Set
知识图谱
源码
文件解析
do_handle_task任务处理函数,负责处理文档解析、分块、向量化和索引的完整流程。主要逻辑:
- 判断任务是否被取消,如果是,则直接返回;
- 根据任务配置绑定对应的嵌入模型,用于后续的向量化处理;
- 根据嵌入模型的向量维度,初始化知识库索引结构;
- 根据任务类型执行不同的处理流程:
- 如果是RAPTOR类型的任务,则执行递归抽象处理;
- 如果是GraphRAG类型的任务,则执行知识图谱构建;
- 如果是标准分块类型的任务,则执行普通分块处理;
- 批量插入分块数据到知识库索引中;
- 更新文档统计信息,包括分块数量、Token数量等;
源码:
async def do_handle_task(task):# 过程回调,用于报告进度progress_callback = partial(set_progress, task_id, task_from_page, task_to_page)# 判断任务是否已取消task_canceled = TaskService.do_cancel(task_id)if task_canceled:progress_callback(-1, msg="Task has been canceled.")return# 绑定嵌入模型embedding_model = LLMBundle(task_tenant_id, LLMType.EMBEDDING, llm_name=task_embedding_id, lang=task_language)# 验证模型可用性,获取向量维度信息vts, _ = embedding_model.encode(["ok"])vector_size = len(vts[0])# 初始化知识库init_kb(task, vector_size)if task.get("task_type", "") == "raptor":# 使用 RAPTOR 分块策略elif task.get("task_type", "") == "graphrag":# 使用 GraphRAG 分块策略else:# 使用标准分块策略chunks = await build_chunks(task, progress_callback)# 计算每个分块的向量token_count, vector_size = await embedding(chunks, embedding_model, task_parser_config, progress_callback)# 批量插入分块数据for b in range(0, len(chunks), DOC_BULK_SIZE):doc_store_result = await trio.to_thread.run_sync(lambda: settings.docStoreConn.insert(chunks[b:b + DOC_BULK_SIZE], search.index_name(task_tenant_id), task_dataset_id))# 更新文档统计信息DocumentService.increment_chunk_num(task_doc_id, task_dataset_id, token_count, chunk_count, 0)
通过LLMBundle将所有大模型操作统一封装在一个类里,通过LLMBundle.encode()方法调用嵌入模型,LLMBundle.chat()方法调用聊天模型。
LLMType枚举所有支持的模型类型。
def init_kb(row, vector_size: int):idxnm = search.index_name(row["tenant_id"])# 创建索引库return settings.docStoreConn.createIdx(idxnm, row.get("kb_id", ""), vector_size)
支持多租户,不同租户的索引库之间是隔离的。docStoreConn表示文档存储引擎,可以通过环境变量DOC_ENGINE进行切换,目前支持三种:
- Elasticsearch:默认,ES
- Infinity
- OpenSearch
ES和OpenSearch创建索引时不用指定向量维度,是因为将常见的向量维度提前预定义在Mapping里,参考conf/mapping.json和conf/os_mapping.json文件。支持512、768、1024、1536维,如果嵌入模型维度不是这几个,在创建索引时可能会报错,需修改Mapping文件来支持新的向量维度。
两个高级配置:
use_raptor:使用召回增强RAPTOR策略:为多跳问答任务启用RAPTOR提高召回效果;use_graphrag:提取知识图谱,在当前知识库的文件块上构建知识图谱,以增强涉及嵌套逻辑的多跳问答。
build_chunks()方法
async def build_chunks(task, progress_callback):# 从对象存储中读取文件bucket, name = File2DocumentService.get_storage_address(doc_id=task["doc_id"])binary = await get_storage_binary(bucket, name)# 调用分块器进行分块,通过 chunk_limiter 限制并发路数chunker = FACTORY[task["parser_id"].lower()]async with chunk_limiter:cks = await trio.to_thread.run_sync(lambda: chunker.chunk(...))# 将分块结果上传到对象存储async with trio.open_nursery() as nursery:for ck in cks:nursery.start_soon(upload_to_minio, doc, ck)return docs
首先根据doc_id从数据库中查询出桶名和文件名,从对象存储中读取出文件内容;接着使用parser_id创建对应的分块器,然后调用chunk()方法对文件进行分块;最后将分块结果上传到对象存储。
embedding()方法:
async def embedding(docs, mdl, parser_config=None, callback=None):# 准备标题和内容数据tts, cnts = [], []for d in docs:tts.append(d.get("docnm_kwd", "Title"))cnts.append(d["content_with_weight"])# 计算标题的向量(只计算第一个标题,然后复制到所有文档,这里的 docs 属于同一个文档,因此文件名是一样的)tk_count = 0if len(tts) == len(cnts):vts, c = await trio.to_thread.run_sync(lambda: mdl.encode(tts[0: 1]))tts = np.concatenate([vts for _ in range(len(tts))], axis=0)tk_count += c# 计算内容的向量(按批生成)cnts_ = np.array([])for i in range(0, len(cnts), EMBEDDING_BATCH_SIZE):vts, c = await trio.to_thread.run_sync(lambda: mdl.encode([truncate(c, mdl.max_length-10) for c in cnts[i: i + EMBEDDING_BATCH_SIZE]]))if len(cnts_) == 0:cnts_ = vtselse:cnts_ = np.concatenate((cnts_, vts), axis=0)tk_count += c# 加权融合标题和内容向量cnts = cnts_filename_embd_weight = parser_config.get("filename_embd_weight", 0.1)title_w = float(filename_embd_weight)vects = (title_w * tts + (1 - title_w) * cnts) if len(tts) == len(cnts) else cnts# 将向量添加到每个文档中vector_size = 0for i, d in enumerate(docs):v = vects[i].tolist()vector_size = len(v)d["q_%d_vec" % len(v)] = vreturn tk_count, vector_size
在计算分块向量时综合考虑标题(文件名)和内容的,通过加权将标题和内容的向量进行融合,标题的权重默认为0.1,内容权重为0.9,可通过filename_embd_weight参数进行调整。最后计算出的向量会添加到每个文档的q_N_vec字段中,NNN表示向量的维度。