【数据库】增删改查 高阶(超级详细)保姆级教学
文章目录
- 插入
- 聚合查询
- 聚合函数
- GROUP BY
- HAVING
- 联合查询
- 一般连接
- 内连接
- 外连接
- 自连接
- 子查询
- 拓展
- 合并查询
- 总结
插入
我们在向表中插入数据时,其实可以一次性把另一张表中的数据都插入进来。
语法:
INSERT INTO table_name [(column [, column ...])] SELECT ...


插入之后:

注意:插入的列要与指定的列一一对应,否则会产生错误。

聚合查询
聚合函数

COUNT
使用count可以查询目标数据的数量。
查询所有数据的个数:
1.count(*)
2.count(x)->x为常量



select(column)可以查询特定列的数据数量,如果有null,则不会被计算在内。

SUM
sum就是计算一列数据的总和。

我们之前学过,null与任何值相加结果都是null。但是在sum函数中,系统会自动处理null值,最终把他当成“0”来看待。

查询中我们也可以像之前一样加where条件来约束。

AVG
对指定的列求平均

仍然可以使用表达式和别名。
MAX&&MIN
求某一列的最大值最小值

GROUP BY
SELECT 中使用 GROUP BY 子句可以对指定列进行分组查询。需要满足:使用 GROUP BY 进行分组查询时,SELECT 指定的字段必须是“分组依据字段”,其他字段若想出现在SELECT 中则必须包含在聚合函数中。
建立一个emp表:
源码:码云地址


查询不同职位的平均工资:

round函数可以传递 数值以及位数的参数,位数代表小数点后的位数。
分组查询后可以再用排序。

HAVING
GROUP BY 子句进行分组以后,需要对分组结果再进行条件过滤时,不能使用 WHERE 语句,而需要用HAVING


这条 SQL 语句存在语法错误,核心问题在于 WHERE 子句中不能直接使用聚合函数(如 avg(salary))。因为聚合函数得到的数据是不真实的数据。


跟在group by 子句之后,对分组结果进行过滤。


这两段代码虽然运行结果相同,但是只要数据特殊,就会产生不一样的结果,而且代码在执行过程中的运行逻辑也完全不同。
联合查询
一般连接
实际开发中往往数据来自不同的表,所以需要多表联合查询。多表查询是对多张表的数据取笛卡尔积:




1.去两张表的笛卡尔积

但是,这其中有很多无效数据,如何去除呢?
2.去除无效数据
依然是使用where筛选。
如果量表之间是主外键关系,一般通过主外键相连。
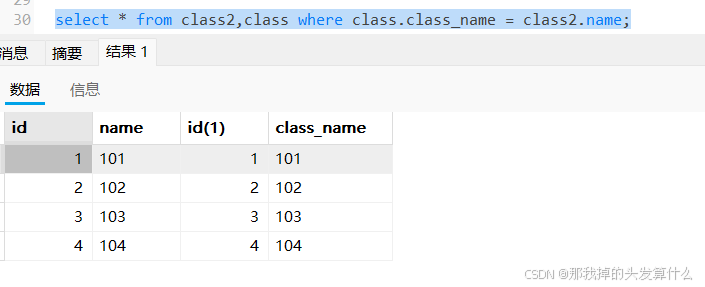
3.能通过指定列查询来精简结果集。
后面的代码演示我们使用码云中的java113.sql来继续学习。
链接在上面↑

当然在使用中我们也可以去给表起别名来精简代码。

内连接
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件;
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
内连接就是在一般连接的基础上,多了一种写法而已。

练习:
(1)查询“许仙”同学的 成绩

(2)查询所有同学的总成绩,及同学的个人信息:

外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;

案例:查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示:

用这种方法我们也可以解决找到缺考的同学类似的问题。
自连接
自连接顾名思义就是一张表自己和自己相连接。
自己怎么跟自己比较呢?

像这样的表就没法实现行与行之间的比较。因为每一行都是不同的数据。

这样的表设计,可以在同一行进行列与列的比较。
示例:显示所有“计算机原理”成绩比“Java”成绩高的成绩信息
我们如果实现自己与自己相连,不可以直接向其他情况那样,而是要给两个表取一个不同的别名。

-- 也可以使用join on 语句来进行自连接查询
SELECTs1.*
FROMscore s1JOIN score s2 ON s1.student_id = s2.student_idAND s1.score < s2.scoreAND s1.course_id = 1AND s2.course_id = 3;
子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
单行子查询:返回一行记录的子查询
查询与“不想毕业” 同学的同班同学:

多行查询:返回多行子记录的查询:
案例:查询“语文”或“英文”课程的成绩信息:
这里要用in ,因为多行不可以使用 = 。

not in 也可以使用。

exists [not] exists

相当于 if。

select null 会返回一个非空的单行的表,只不过这个表列名和值都为null。

拓展
可以用子查询创建一个临时表,用来查询。
select * from student (select * from..)[where] ...
查询所有比“中文系2019级3班”平均分高的成绩信息:

合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:查询id小于3,或者名字为“英文”的课程:

该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
案例:查询id小于3,或者名字为“Java”的课程

总结
本文围绕 SQL 查询展开,涵盖多方面内容:插入操作支持从其他表批量插入且需保证列一一对应;聚合查询包含 COUNT、SUM 等聚合函数,结合 GROUP BY 可实现分组统计,分组后需用 HAVING 而非 WHERE 过滤聚合结果;联合查询涉及一般连接、内连接、外连接、自连接,还有子查询(含单行、多行及 exists 用法)及基于子查询创建临时表的拓展,同时讲解了合并查询的 UNION(去重)和 UNION ALL(保留重复)操作,且需保证合并的结果集字段一致。