[人工智能-大模型-112]:用通俗易懂的语言,阐述代价函数Cost Function(误差函数、偏差函数、距离函数)
我们用大白话 + 生活例子,来彻底讲清楚什么是代价函数(Cost Function) ,它为什么又叫“误差函数”、“偏差函数”或“距离函数”,以及它在机器学习中到底起什么作用。
🎯 一、一句话通俗解释:
代价函数就是模型的“考试成绩单”——分数越低,说明模型表现越好。
就像你考试后看总分:
- 分数高 → 成绩好 ✅
- 分数低 → 成绩差 ❌
但在机器学习里,我们反过来:
👉 代价函数值越小,模型越优秀!
🍕 二、生活例子:披萨外卖预测
假设你开了一家披萨店,想训练一个模型来预测:
“顾客订了几个披萨,要送多久才能到?”
你的模型会说:“嗯……订了3个披萨,大概要25分钟。”
但实际呢?只用了20分钟就送到了。
那问题来了:
这个模型猜得准不准?差了多少?
这就轮到代价函数出场了!
它干的事很简单:
✅ 把模型的预测结果 和 实际结果 对比一下,
✅ 算出一个“错误程度”的数字 —— 这个数字就是“代价”。
比如:
- 预测:25分钟,实际:20分钟 → 差了5分钟 → 代价 = 5
- 另一次预测:30分钟,实际:20分钟 → 差了10分钟 → 代价 = 10
显然,第二次错得更离谱,所以“代价更高”。
🔍 三、为什么叫这些名字?
| 名字 | 为啥这么叫? | 通俗理解 |
|---|---|---|
| 代价函数 | 模型犯错要“付出代价”,这是称为代价函数的原因!! | 错得越多,代价越大 💸 |
| 误差函数 | 衡量预测和真实之间的“误差” | 就是“错了多少”📏 |
| 偏差函数 | 表示预测偏离了真实值 | 偏离越大,得分越差 🎯 |
| 距离函数 | 把预测值和真实值看成两个点,算它们之间的“距离” | 越远越不好 📏 |
✅ 其实这几个词意思差不多,都是在说:“模型离正确答案有多远?”
📈 四、数学上怎么算这个“代价”?
最常用的一种方法叫:均方误差(MSE)
公式长这样(别怕,我们慢慢拆):
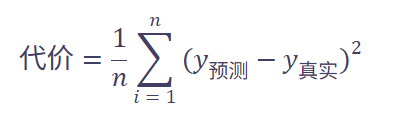
翻译成人话:
把所有样本的“预测值与真实值之差的平方”加起来,再取平均。
🌰 举个例子:
| 订单 | 预测时间 | 真实时间 | 差值 | 差的平方 |
|---|---|---|---|---|
| 1 | 25 | 20 | 5 | 25 |
| 2 | 22 | 20 | 2 | 4 |
| 3 | 18 | 20 | -2 | 4 |
总代价 = (25 + 4 + 4) / 3 = 11
这个“11”就是当前模型的“考试成绩”。我们要让它尽可能变小。
🧠 五、代价函数的核心作用:指导模型“改错”
模型一开始瞎猜,比如随便设几个参数,预测不准,代价很高。
然后它开始用梯度下降等方法调整自己:
“我刚才哪里猜错了?往哪个方向改能让代价变小一点?”
每改一次,算一次代价,直到:
✅ 代价越来越小 → 模型越来越准!
通过梯度下降法,反复计算和调整代价参数中的W, B参数,确保代价函数的输出值最小!!
🎯 所以说:
代价函数是模型的“老师”
它不教具体知识,但每次都说:“你这次考了80分,再努力点,争取考95!”
🔄 六、不同任务,不同的“打分方式”(代价函数类型)
| 任务类型 | 常见代价函数 | 举例 |
|---|---|---|
| 回归问题(预测数值) | 均方误差(MSE) | 预测房价、送餐时间 |
| 分类问题(判断类别) | 交叉熵损失(Cross-Entropy) | 判断图片是猫还是狗 |
| 带惩罚的模型 | 正则化代价函数 | 防止过拟合,不让模型“死记硬背” |
就像语文考试用作文评分,数学考试用选择题计分——不同任务,用不同的“打分标准”。
⚠️ 七、关键要点总结
| 观点 | 说明 |
|---|---|
| ✅ 代价函数是用来衡量模型有多“错” | 数值越小越好 |
| ✅ 它是优化算法的“指南针” | 告诉模型该往哪调参数 |
| ✅ 不是越复杂越好 | 要选适合任务的代价函数 |
| ✅ 不能只看训练集代价 | 还要看测试集表现,防止“死记硬背”(过拟合) |
🎉 最后打个比方总结:
想象你在练投篮:
- 每次投完,有人告诉你“离篮筐多远”(这就是代价)
- 你根据这个反馈,调整力度和角度
- 慢慢地,你每次都能投进,代价趋近于0
🎯 在机器学习中:
- 你 = 模型
- 投篮 = 预测
- 离篮筐的距离 = 代价函数
- 调整动作 = 梯度下降优化参数
✅ 所以记住:
代价函数,就是让模型知道自己“错在哪、错多远”,然后一步步变聪明的“反馈系统”。
是不是现在感觉它没那么抽象了?😄