【论文精读】MicroCinema:基于分治策略的文本到视频生成新框架
标题:MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
作者:Yanhui Wang, Jianmin Bao, Wenming Weng, Ruoyu Feng, Dacheng Yin, Tao Yang, Jingxu Zhang, Qi Dai, Zhiyuan Zhao, Chunyu Wang, Kai Qiu, Yuhui Yuan, Chuanxin Tang, Xiaoyan Sun, Chong Luo, Baining Guo
单位:1. University of Science and Technology of China;2. Microsoft Research Asia;3. Xi’an Jiaotong University
发表:CVPR 2024
论文链接:https://arxiv.org/pdf/2311.18829
项目链接:https://wangyanhui666.github.io/MicroCinema.github.io/
代码链接:暂无
关键词:文本到视频生成、分治策略、扩散模型、外观注入网络、外观噪声先验、Stable Diffusion、时空超分辨率、零样本学习、FVD(Frechet Video Distance)、UCF-101、MSR-VTT
在 AI 生成内容(AIGC)领域,文本到视频(Text-to-Video)生成一直是极具挑战性的任务。它不仅要求模型理解文本语义并生成符合描述的视觉内容,还需要保证视频帧间的时间连贯性与视觉一致性。微软亚洲研究院与中国科学技术大学联合提出的MicroCinema框架,通过创新的分治策略与核心模块设计,在该领域取得了突破性进展。
一、研究背景与问题提出
1.1 文本到视频生成的技术现状
近年来,扩散模型(Diffusion Models)在文本到图像(Text-to-Image)生成领域取得了巨大成功,例如 Stable Diffusion、DALL-E 2、Midjourney 等模型已能生成照片级真实感与细节丰富的静态图像。受此启发,研究者开始探索将扩散模型扩展到文本到视频生成任务,目前主流技术路径分为两类:
- 直接训练大规模文本到视频扩散模型(如 Imagen Video、CogVideo):这类方法采用时空级联扩散模型,直接从文本 - 视频对中学习。虽然能生成高质量视频,但存在两个关键问题 ——GPU 资源消耗极大(需大规模算力支持训练)、依赖海量标注数据(难以覆盖多样化场景)。
- 基于文本到图像模型改造(如 Align-your-latents、Make-A-Video):这类方法通过在预训练文本到图像模型中插入时间层(如 3D 卷积、时间注意力),并在少量文本 - 视频对上微调,以降低训练成本。但该路径容易导致外观不一致(帧间物体形态、颜色突变)与时间连贯性差(运动逻辑断裂)的问题。
1.2 核心挑战与研究动机
文本到视频生成的核心矛盾在于:模型需要同时兼顾外观细节生成与运动动态建模,而单一阶段的模型难以在两者间取得平衡 —— 若侧重外观细节,会占用大量参数与计算资源,导致运动建模能力不足;若侧重运动生成,又会牺牲图像质量与帧间一致性。
MicroCinema 的核心动机正是解耦外观生成与运动建模:利用现有文本到图像模型的优势解决外观质量问题,再专注于运动动态的学习,从而实现 “1+1>2” 的效果。

二、MicroCinema 框架核心设计
MicroCinema 的核心思想是分治策略(Divide-and-Conquer),将文本到视频生成拆解为两个独立且互补的阶段:文本到关键帧生成(Text-to-Image) 与关键帧 & 文本到视频生成(Image&Text-to-Video)。整个框架的流程如图 2 所示,下方将逐一解析各阶段的技术细节。
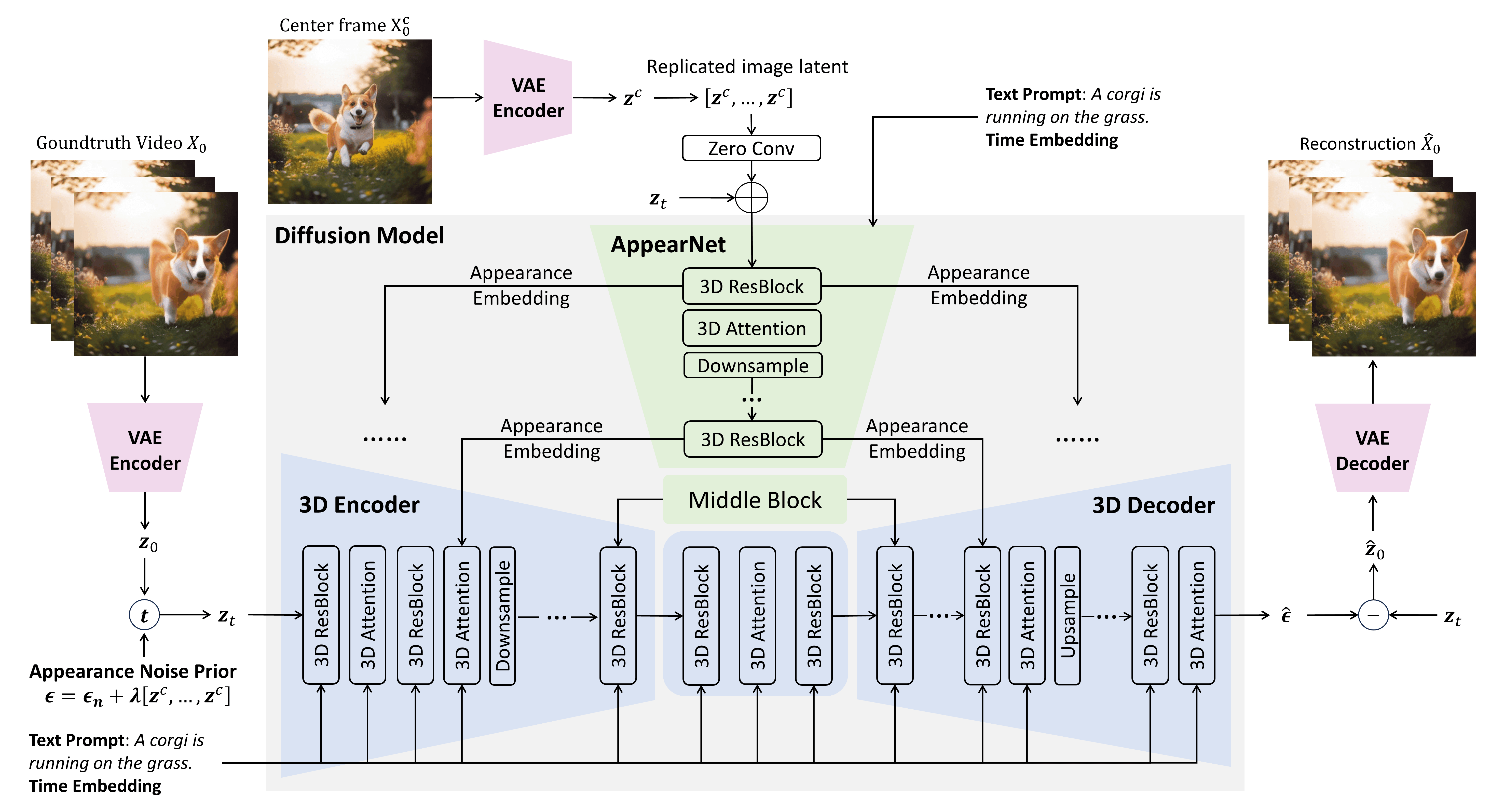
2.1 整体框架概览
MicroCinema 的两阶段流程如下:
-
第一阶段:文本到关键帧生成利用任意成熟的文本到图像模型(如 Stable Diffusion XL、Midjourney、DALL-E 2),根据输入文本生成一张中心帧(Key Frame)。这一阶段的目标是借助现有模型的优势,生成外观细腻、语义匹配的静态图像,为后续视频生成提供 “视觉基准”。该阶段的灵活性极强:用户可直接使用预训练模型生成关键帧,也可上传自定义图像作为初始帧,大幅拓展了应用场景。
-
第二阶段:关键帧 & 文本到视频生成以第一阶段生成的中心帧与原始文本为输入,通过改造后的 3D 扩散模型生成连续视频。该阶段的核心目标是在保留中心帧外观细节的前提下,学习符合文本描述的运动动态。为实现这一目标,论文设计了两个核心模块:外观注入网络(Appearance Injection Network, AppearNet) 与外观噪声先验(Appearance Noise Prior),同时引入时间插值模型提升视频帧率,最终生成高分辨率连贯视频。
MicroCinema 的创新点在于:通过分治策略将 “生成外观” 与 “建模运动” 解耦,让每个阶段专注于单一任务,既复用了文本到图像模型的优势,又降低了视频生成的复杂度。
2.2 基础模型改造:从 2D 到 3D 扩散网络
第二阶段的基础模型基于Stable Diffusion 2.1(SD 2.1) 改造,核心是将原本处理静态图像的 2D U-Net 扩展为支持时空信息的 3D U-Net,具体改造包括:
- 插入时间卷积层:在每个 2D 空间卷积层后添加 1D 时间卷积层(卷积核大小为 3×1×1),用于捕捉帧间的短期运动依赖。
- 添加时间注意力层:在每个 2D 空间注意力层后添加 1D 时间注意力层(注意力窗口大小为 9×1×1),用于捕捉帧间的长期时空对应关系。
- 参数初始化与跳过连接:所有新增的时间层采用零初始化,并添加跳过连接(Skip Connection)。这一设计的目的是:在训练初期,模型仍能依赖预训练 SD 2.1 的空间特征提取能力,避免因时间层初始化导致的性能下降;随着训练推进,时间层逐步学习运动信息,实现 “空间能力保留 + 时间能力增量学习”。
改造后的 3D U-Net 既继承了 SD 2.1 在外观生成上的优势,又具备了处理视频时空信息的能力,为后续外观注入与运动建模奠定基础。
2.3 核心模块 1:外观注入网络(AppearNet)
为解决 “帧间外观不一致” 问题,论文设计了AppearNet,其核心功能是将中心帧的外观信息 “注入” 到 3D U-Net 的编码与解码过程中,强制模型在生成视频时保留关键帧的视觉特征(如物体形状、颜色、纹理)。
2.3.1 AppearNet 的结构设计
AppearNet 的结构与 3D U-Net 共享编码器与中间层,具体流程如图 3 所示:
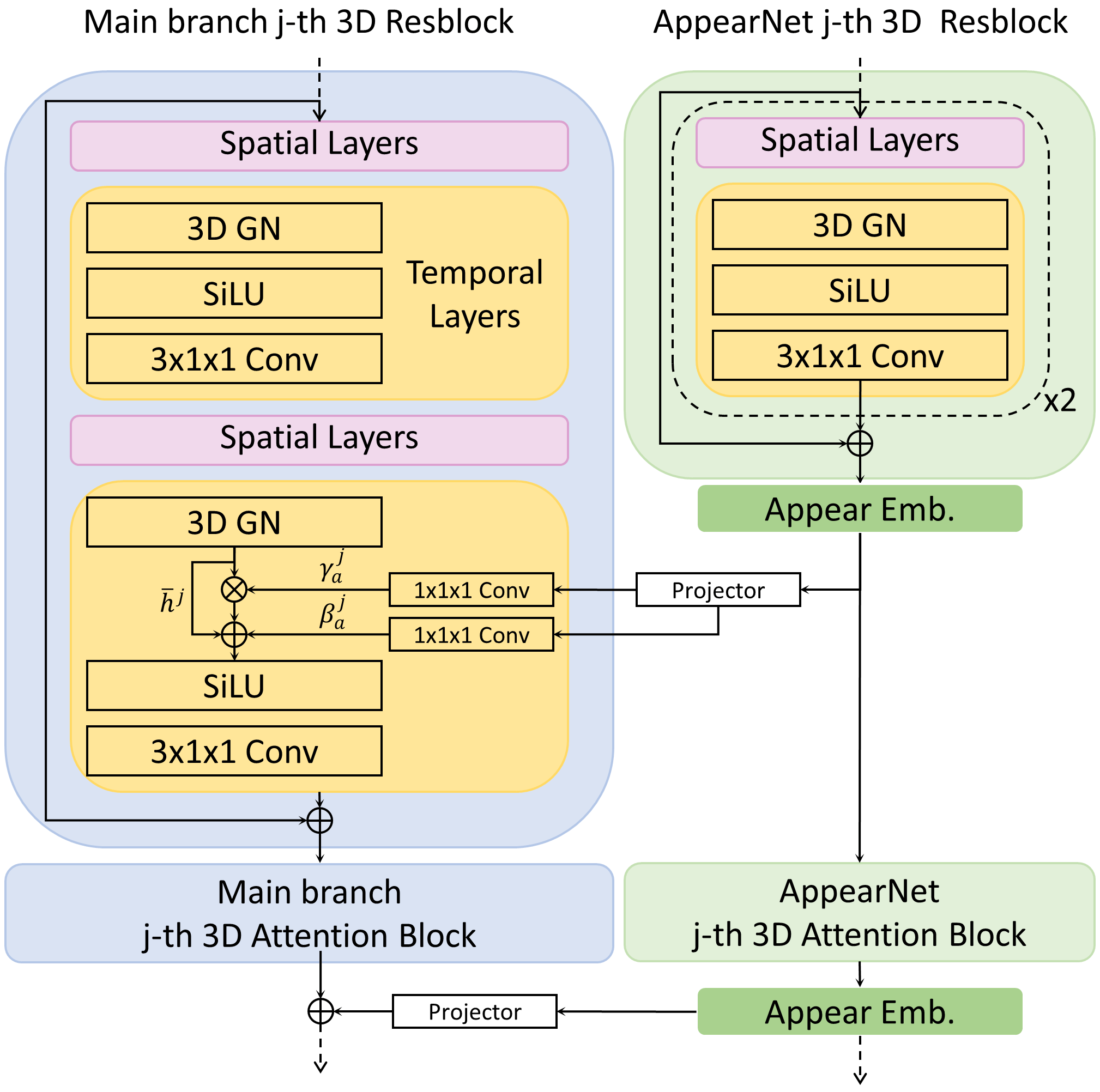
- 中心帧扩展:将中心帧的 latent 表示
复制 N 次(N 为输出视频的帧数),得到序列
,模拟 “静态视频” 作为外观参考。
- 多尺度特征提取:扩展后的序列输入 AppearNet,通过与 3D U-Net 对称的编码器,提取多尺度外观特征(对应 U-Net 的不同下采样层级)。
- 密集融合注入:采用多尺度 + 去归一化(De-normalization) 策略,将 AppearNet 的特征注入 3D U-Net 的主分支:
- 多尺度注入:AppearNet 在每个尺度的特征,分别注入 3D U-Net 编码器与解码器的对应尺度,确保全链路外观信息覆盖。
- 去归一化注入:不同于传统的 “特征相加”,AppearNet 的特征通过 1×1×1 卷积投影为归一化参数(
和
),对 3D U-Net 主分支特征的 3D 组归一化(3D GroupNorm)结果进行调整,公式如下:
,其中,
是 3D U-Net 主分支第 j 层的特征,
是归一化后特征,
是注入外观信息后的输出特征。
这种注入方式的优势在于:外观信息直接作用于主分支的归一化过程,能更高效地约束特征分布,避免外观特征被运动建模 “稀释”,同时释放主分支的参数用于运动学习。
2.3.2 AppearNet 的消融验证
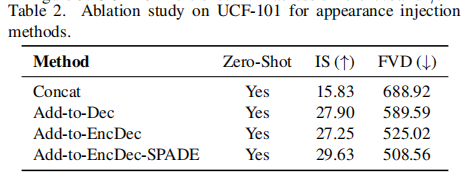
论文通过对比四种不同的外观注入方式,验证了 AppearNet 设计的有效性(实验基于 UCF-101 零样本测试集,结果如下表所示):
- Concat:将中心帧 latent 与噪声输入直接拼接(传统方法);
- Add-to-Dec:仅在 3D U-Net 解码器中添加 AppearNet 特征;
- Add-to-EncDec:在编码器与解码器中均添加 AppearNet 特征;
- Add-to-EncDec-SPADE:在 Add-to-EncDec 基础上引入去归一化(即 AppearNet 的最终设计)。
从表中可见,AppearNet 的最终设计(Add-to-EncDec-SPADE)取得了最低的 FVD(508.56)与最高的 IS(29.63),证明多尺度 + 去归一化的注入策略能最有效地保留外观一致性。
2.4 核心模块 2:外观噪声先验(Appearance Noise Prior)
在扩散模型中,噪声的分布直接影响生成结果。传统文本到视频模型使用独立同分布的高斯噪声,容易导致帧间外观随机变化。为解决这一问题,论文提出外观噪声先验,通过修改扩散过程的噪声分布,让模型在生成初期就 “感知” 到中心帧的外观信息,从而约束视频的视觉一致性。
2.4.1 噪声分布的修改逻辑
扩散模型的训练目标是预测噪声 ,传统噪声为
。MicroCinema 对噪声进行如下改造:
- 训练阶段噪声:将中心帧 latent
其中,
是控制中心帧权重的超参数(实验中最优值为 0.03),
- 推理阶段噪声:为进一步增强外观约束,在推理时额外添加
项,最终噪声为:
,实验中最优
为 0.02。
2.4.2 理论兼容性与实验验证
外观噪声先验的关键优势在于与现有 ODE 采样器完全兼容:论文通过推导证明,修改后的噪声分布仅需调整初始采样噪声,无需改变扩散过程的 ODE 求解逻辑(具体推导见论文附录 B),可直接复用 Stable Diffusion 的采样算法(如 EulerEDM)。
为验证超参数 与
的影响,论文在 UCF-101 数据集上进行了消融实验,结果如图 5 所示。
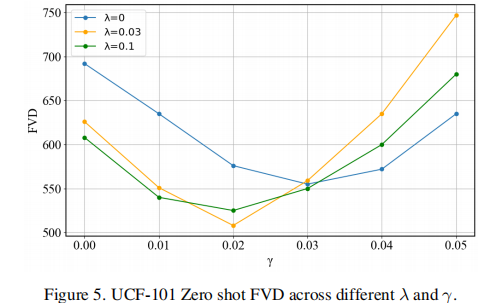
当 且
时,FVD 值最低(约 508),相比无外观噪声先验(
)的 FVD=692,性能提升近 27%,同时 IS 从 18.5 提升至 29.6,证明该模块能在保留外观的同时提升视频质量。
2.5 视频质量增强:时间插值与空间超分辨率
基础 3D 模型生成的视频分辨率为 320×320,帧率仅为 2fps,难以满足实际应用需求。论文通过两步优化提升视频质量:
- 时间插值模型(Temporal Interpolation):基于基础模型改造,将输入从 “单中心帧” 改为 “起始帧 + 结束帧”,通过学习帧间插值规律实现 4 倍时间超分辨率(TSR)。连续应用该模型可将帧率从 2fps 提升至 32fps(2→8→32),解决视频 “卡顿” 问题。
- 空间超分辨率(Spatial Super-Resolution):采用现有成熟的图像超分辨率模型(如 Real-ESRGAN),将 320×320 视频提升至更高分辨率(如 1024×1024),补充细节信息。
三、实验验证与结果分析
为全面验证 MicroCinema 的性能,论文在公开数据集上进行了定量与定性实验,并与当前主流文本到视频模型进行对比。
3.1 实验设置
3.1.1 数据集
- 训练集:WebVid-10M(1000 万文本 - 视频对,涵盖近静态到剧烈运动的多样化场景),训练前通过 CLIP 分数过滤低质量样本。
- 测试集:
- UCF-101:101 类人类动作视频,用于评估时间连贯性,采用 “类别名 + 动作描述” 的模板生成 10K 测试文本。
- MSR-VTT:10K 视频片段,用于评估帧质量与语义匹配度,采用数据集自带的 2.9K 验证集文本。
3.1.2 评价指标
- FVD(Frechet Video Distance):衡量生成视频与真实视频的分布差异,值越低越好(时间连贯性越强)。
- IS(Inception Score):衡量生成帧的多样性与真实性,值越高越好(外观质量越高)。
- CLIPSIM:衡量生成帧与文本的语义相似度,值越高越好(语义匹配度越强)。
3.2 定量对比:SOTA 性能验证
论文将 MicroCinema 与两类模型对比:使用额外数据训练的模型(如 Make-A-Video、PYoCo)与仅使用 WebVid-10M 训练的模型(如 CogVideo、Show-1),结果如下表所示。
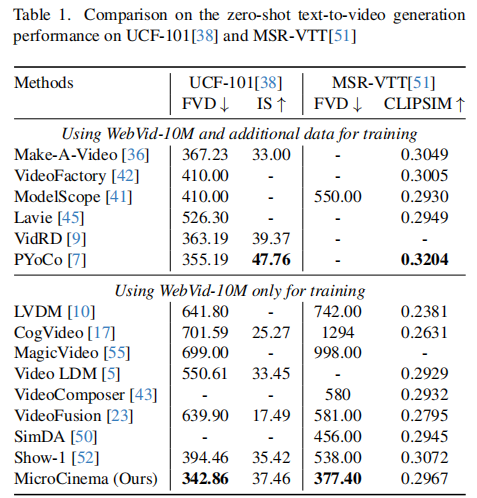
从表中可得出关键结论:
- 跨数据规模超越:尽管 MicroCinema 仅使用 WebVid-10M 训练,但其在 UCF-101(FVD=342.86)与 MSR-VTT(FVD=377.40)上的 FVD 值均低于使用额外数据的模型(如 Make-A-Video 的 367.23、PYoCo 的 355.19),证明分治策略的高效性。
- 同数据规模碾压:与仅使用 WebVid-10M 的模型相比,MicroCinema 的 FVD 值显著更低(如 CogVideo 的 701.59 vs 342.86),同时 IS 值更高,说明其在外观质量与时间连贯性上均有优势。
- 语义匹配均衡:MicroCinema 的 CLIPSIM 值(0.2967)虽略低于 PYoCo,但远高于 CogVideo 等模型,证明其在生成高质量视频的同时,未牺牲文本语义匹配度。
3.3 定性对比:视觉效果验证
论文通过可视化对比,直观展示了 MicroCinema 与主流模型(Make-A-Video、Video LDM、Imagen Video)的差异,部分结果如图 4 所示。

核心优势体现在:
- 外观一致性:MicroCinema 生成的视频帧间物体形态、颜色无明显突变(如 “泰迪熊在第五大道行走” 案例中,泰迪熊的毛发纹理与颜色全程一致)。
- 运动清晰度:相比 Video LDM 的 “模糊运动” 与 Make-A-Video 的 “不连贯运动”,MicroCinema 能生成符合物理逻辑的清晰运动(如 “帆船在山湖航行” 案例中,帆的摆动与船的位移连贯自然)。
- 细节保留:在复杂场景(如 “宇航员服装的吉娃娃在太空漂浮”)中,MicroCinema 能保留物体的精细细节(如宇航服的纹理、太空背景的星点),而对比模型易出现细节丢失或变形。
3.4 消融实验:核心模块有效性验证
为进一步验证各模块的必要性,论文进行了系列消融实验:
- AppearNet 的必要性:移除 AppearNet 后,UCF-101 的 FVD 从 342.86 升至 525.02,IS 从 37.46 降至 27.25,证明外观注入是保证帧间一致性的关键。
- 外观噪声先验的必要性:移除该模块后,FVD 升至 692,IS 降至 18.5,说明修改噪声分布能有效保留预训练文本到图像模型的外观生成能力。
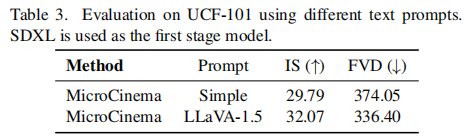
- 第一阶段模型的影响:对比 SD 2.1 与 SDXL 作为第一阶段模型的效果(表 3),发现 SDXL 生成的关键帧能让 MicroCinema 的 FVD 从 412.53 降至 336.40,IS 从 31.25 升至 32.07,证明高质量关键帧是提升视频质量的基础。

- 文本提示的影响:使用 LLaVA-1.5 生成的精细化提示(相比简单提示),能让 FVD 从 374.05 降至 336.40,说明文本语义的丰富度对运动建模的准确性有直接影响。
四、局限性与未来方向
尽管 MicroCinema 取得了显著成果,但论文也客观指出了当前存在的局限性,为后续研究提供了方向:
4.1 现有局限性
- 小物体外观重建不足:由于采用 SD 2.1 的预训练 VAE,其对小物体(如小尺寸人脸)的重建能力有限,导致生成视频中这类物体易出现细节模糊或形态畸变。
- 未联合时空超分辨率:当前框架中,时间插值(TSR)与空间超分辨率(SSR)是独立进行的,未考虑两者的协同优化。独立处理可能导致 “高帧率但低分辨率” 或 “高分辨率但运动卡顿” 的问题。
- 复杂运动建模能力有限:对于剧烈运动(如快速旋转、多物体交互)场景,模型仍可能出现运动逻辑断裂,需进一步增强时间注意力的建模能力。
4.2 未来研究方向
- 优化 VAE 架构:重新训练更高通道数的 VAE,提升对小物体与细节的重建能力。
- 联合时空超分辨率:设计端到端的时空超分辨率模块,同时优化帧率与分辨率,避免独立处理的弊端。
- 引入运动先验知识:结合物理引擎(如牛顿运动定律)或人体姿态估计等先验信息,增强复杂运动的逻辑性与连贯性。
五、总结与启发
MicroCinema 的核心贡献不仅在于提出了一个性能领先的文本到视频生成框架,更在于其分治策略的设计思想—— 通过解耦 “外观生成” 与 “运动建模”,充分复用现有文本到图像模型的优势,同时降低视频生成的复杂度。这种 “扬长避短” 的思路为 AIGC 领域的复杂任务提供了重要启发:
- 模块化设计:将复杂任务拆解为独立模块,每个模块专注于单一子问题,可大幅提升模型的训练效率与性能上限。
- 复用预训练资产:在 AIGC 任务中,充分利用现有成熟模型(如文本到图像、图像超分辨率)的能力,比 “从零开始训练” 更具性价比。
- 细节优化决定上限:AppearNet 的去归一化注入、外观噪声先验的超参数调优,这类细节设计是实现 “SOTA 性能” 的关键,体现了 “工程创新” 与 “理论创新” 的结合。
未来,随着多模态理解能力的提升与算力成本的降低,文本到视频生成有望在影视制作、游戏开发、教育演示等领域实现规模化应用,而 MicroCinema 的设计思想将为这一进程提供重要参考。