A2A协议的多智能体投顾引擎架构, 智能体生成年化418%,回撤11%,夏普比5.19的规则策略,附python代码
原创内容第1038篇,专注AGI+,AI量化投资、个人成长与财富自由。
基于A2A协议的多智能体投顾引擎架构:
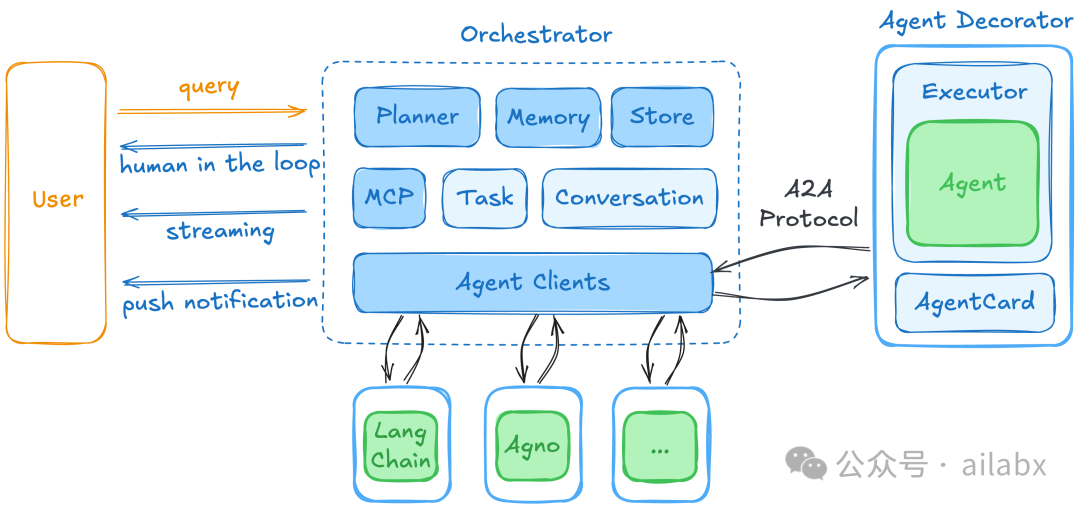
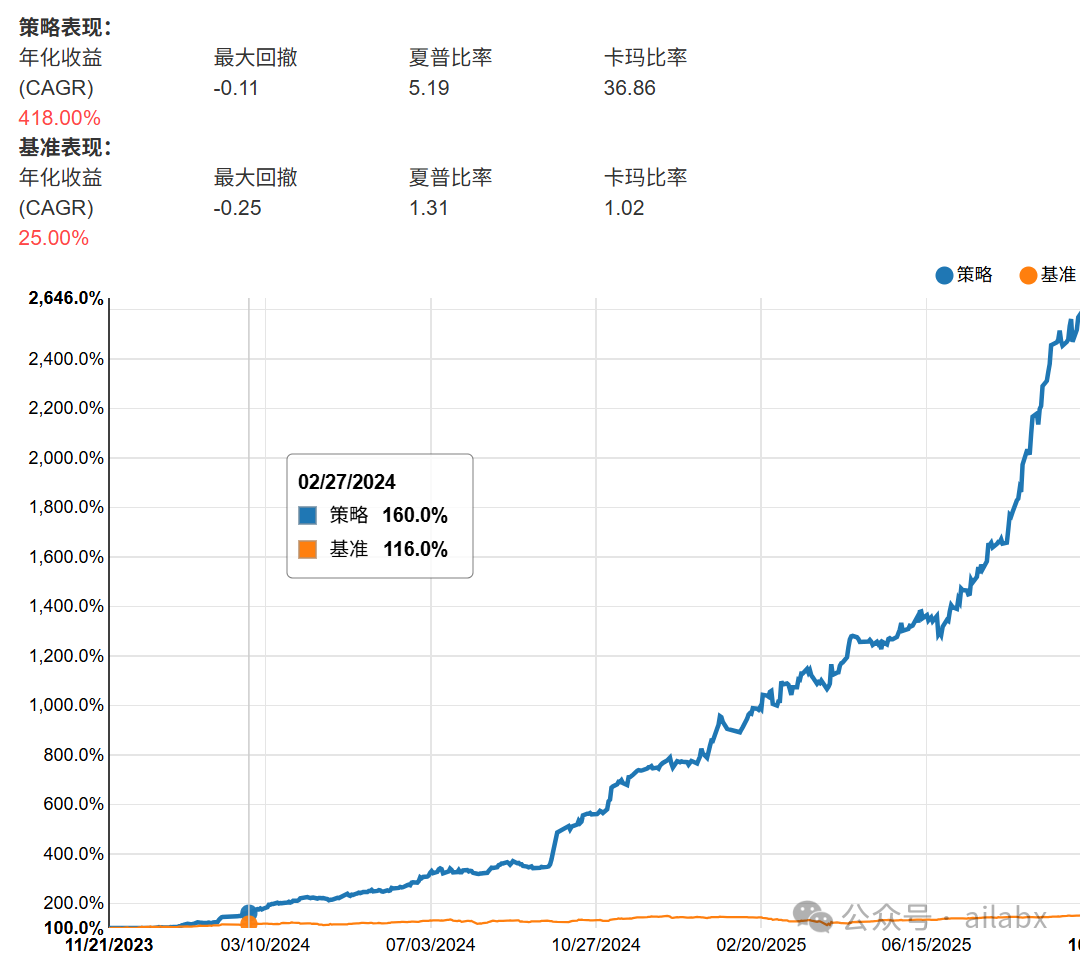
传统的规则策略,使用智能体,可以按我们的策略模板,按用户需求来写策略,本质还是一个规则策略,比如:年化418%,回撤11%,夏普比5.19的规则策略。
另外,还有更智能的,就是交易信号上多智能体来操作,我们只提供数据和要求。这就是多智能体真正做智能投顾了。
好处就是动态的,适应市场,缺点是不那么可控,这个需要更多的测试,不过我相信这是趋势。相当于把主观交易和量化交易更进一步整合了。
下一步,这两种形式,我们都会来实现。
valuecell里的交易逻辑提示词:
其实就是对相应的投资标的,做技术分析。
prompt = f"""You are an expert crypto trading analyst. Analyze the following technical indicators for {indicators.symbol} and provide a trading recommendation.Current Market Data:- Symbol: {indicators.symbol}- Price: ${indicators.close_price:,.2f}- Volume: {indicators.volume:,.0f}Technical Indicators:- MACD: {macd_str}- MACD Signal: {macd_signal_str}- MACD Histogram: {macd_histogram_str}- RSI: {rsi_str}- EMA 12: {ema_12_str}- EMA 26: {ema_26_str}- EMA 50: {ema_50_str}- BB Upper: {bb_upper_str}- BB Middle: {bb_middle_str}- BB Lower: {bb_lower_str}Based on these indicators, provide:1. Action: BUY, SELL, or HOLD2. Type: LONG or SHORT (if BUY)3. Confidence: 0-100%4. Reasoning: Brief explanation (1-2 sentences)Format your response as JSON:{{"action": "BUY|SELL|HOLD", "type": "LONG|SHORT", "confidence": 0-100, "reasoning": "explanation"}}"""agent = Agent(model=self.llm_client, markdown=False)response = await agent.arun(prompt)# Parse responsecontent = response.content.strip()# Extract JSON from markdown code blocks if presentif "```json" in content:content = content.split("```json")[1].split("```")[0].strip()elif "```" in content:content = content.split("```")[1].split("```")[0].strip()result = json.loads(content)action = TradeAction(result["action"].lower())trade_type = (TradeType(result["type"].lower()) if result["type"] else TradeType.LONG)reasoning = result["reasoning"]confidence = float(result.get("confidence", 75.0))logger.info(f"AI Signal for {indicators.symbol}: {action.value} {trade_type.value} "f"(confidence: {confidence}%) - {reasoning}")return (action, trade_type, reasoning, confidence)except Exception as e:logger.error(f"Failed to get AI trading signal: {e}")return None
当然它没有生成交易规则,而是由Agent动态判断。
项目代码是基于咱们之前聊过的Agno,后续我们用AgentScope来实现。
现在智能体框架里,基本ReactAgent已经成为标配了。
为什么ReactAgent有效,基本上它实现了think的模式。
普通 Agent 的核心是一个 “感知-决策-行动” 循环,但它缺少了显式的“推理”环节。核心:一个大语言模型。工具:可以被调用的外部函数,如搜索引擎、计算器、代码执行器。记忆:通常包括短期记忆(当前对话/状态)和长期记忆(向量数据库等)。
工作流程(Action-Observation Loop):
-
-
感知状态:Agent 接收到用户的请求和当前的环境状态(包括之前的行动结果)。
-
内部决策:LLM 内部处理这些信息,直接生成一个“行动”指令(例如,调用哪个工具,传入什么参数)。这个决策过程是黑盒的。
-
执行行动:系统执行该工具调用。
-
观察结果:获取工具返回的结果(如搜索到的网页内容、计算结果)。
-
循环:将结果作为新状态的一部分,重复步骤1,直到LLM认为任务完成并生成最终答案。
-
-
缺点:
-
像一个不假思索的执行者,容易“一条路走到黑”。
-
纠错难:一旦开始走错路,很难自我纠正,因为它没有显式地反思“我为什么错了”。
-
依赖模型内部能力:整个规划的负担完全压在LLM的内部表征上。
-
ReAct Agent 的原理
ReAct 的核心思想源于对人类解决问题方式的模仿:我们通常会先思考(Reasoning),再行动(Acting),并根据行动结果再次思考,调整策略。
组件和普通Agent基本相同(LLM + 工具 + 记忆),但提示工程和输出解析的方式完全不同。
工作流程:
这是一个结构化的循环,要求LLM严格按照特定格式(如 Thought:/Action:/Observation:)来输出。
每天“不管”一点点,每天就变强一天天。
代码和数据下载:AI量化实验室——2025量化投资的星辰大海
年化390%,回撤7%,夏普6.32 | A股量化策略配置
年化30.24%,最大回撤19%,综合动量多因子评分策略再升级(python代码+数据)
年化429%,夏普5.51 | 全A股市场回测引擎构建
年化443%,回撤才7%,夏普5.53,3积分可查看策略参数