从 VLDB‘25 看向量数据库发展方向:行业观察与技术前瞻
蚂蚁向量检索 VSAG 团队在 VLDB'25 发表论文并受邀现场分享报告论文内容。我们从会上带来对向量数据库的观察与见解,在这里与大家分享。本文将对发表在 VLDB 2025 的向量检索的最新的四个研究方向的前沿工作进行解读。同时,分别从工业界和学术界的视角分享对向量数据库发展的观察。最后,介绍蚂蚁向量数据库团队发表在 Industrial Track 的图检索优化框架 VSAG 和实现哲学。
VLDB'25 参会见闻
会议简介
第 51 届国际大型数据库会议(The 51st International Conference on Very Large Data Bases,简称 VLDB 2025)是数据管理、数据库系统与大规模数据处理领域最具影响力的国际顶级学术会议之一。本届 VLDB 在于 2025 年 9 月 1 日至 9 月 5 日在英国伦敦 Queen Elizabeth II Centre (QEII Centre) 举办。

近年来,向量检索由于其在检索和大模型相关领域的广泛应用,备受学界和业界的关注。体现在本届 VLDB 会议中,与往届最为不同在有 4 场独立的向量检索的议程。其中 Research-track 有 3 场, Industial-tack 有 1 场。同时,另有 2 场综合性的索引议程中也有诸多向量检索的文章。蚂蚁向量检索 VSAG 团队在本届会议发表 Industial-track论文:VSAG: An Optimized Search Framework for Graph-based Approximate Nearest Neighbor Search(https://www.vldb.org/pvldb/vol18/p5017-cheng.pdf) 受邀现场分享报告论文内容。我们带回了对向量数据库的观察与见解,在这里与大家分享。

今年会议的领域和方向
-
今年 Research Track 收到 1613 篇提交,接收 369 份,接收率 22.8%。
- Database Engines,Graph,AI 三大研究领域有最多的文章,占比 16%,15%,13%
向量检索研究现状
在本届会议中,一共收录了约 20 篇向量检索领域相关的论文。接下来,我们重点分析本次会议中向量检索领域关注度最高的四大研究方向的研究路径,包括但不仅限于本届会议的成果。
索引和检索
该问题聚焦于纯粹的向量检索方法。例如,目前主流的方法可以被分为基于图的方法(以 HNSW 为代表)、基于划分的方法(以 IVF 为代表)。当前绝大多数工作围绕着基于图索引的检索,主要可以被分为两个方向:
【方向一】如何更好更快地构建索引(FastHNSW@VLDB'25,PSP@VLDB'25)
回顾当下两条图索引构建算法的技术路线:NSWG-based 路线(NSW、HNSW)和 RNG-based 路线(NSG、NSSG、Vamana)。从下图中可以看出,基于图的向量检索中,图的最近邻的精确度直接决定了图的性能。
基于上述结论,FastHNSW(the Index Construction of Proximity Graph-Based Approximate Nearest Neighbor Search:https://vldb.org/pvldb/volumes/18/paper/Revisiting)提出了一种结合 RNG 和 NSWG 的算法框架,通过迭代的方法分别构造每层的近邻图,去除掉图中没有意义的长边。在迭代的过程中,记录构图中间距离计算,减少重复计算。同时,提出一种新的剪枝策略,以提高检索的性能。
PSP(Inner Product is Query-Scaled Nearest Neighbor:https://vldb.org/pvldb/volumes/18/paper/Maximum)探讨了当距离度量为 IP 时图索引上的优化。在构建阶段,可以使用 L2 距离来进行构图来保证图索引整体的收敛性,并通过理论证明了这一个结论。
【方向二】如何更好地检索(SHG@VLDB'25,HAKES@VLDB'25)
这一方向主要是利用基于量化的二阶段检索模式。也就是说,在一些对精度不敏感的阶段(例如搜索前期)可以使用量化向量来搜索。对搜索后期,可以使用高精度向量来保证结果质量。其中,SHG(Approximate Nearest Neighbor Search in Hierarchical Graphs%3A Efficient Level Navigation with Shortcuts:https://vldb.org/pvldb/volumes/18/paper/Accelerating)为 HNSW 的层次图添加直连通路,在层次图中使用量化向量进行检索,同时提供量化误差上限的理论证明。
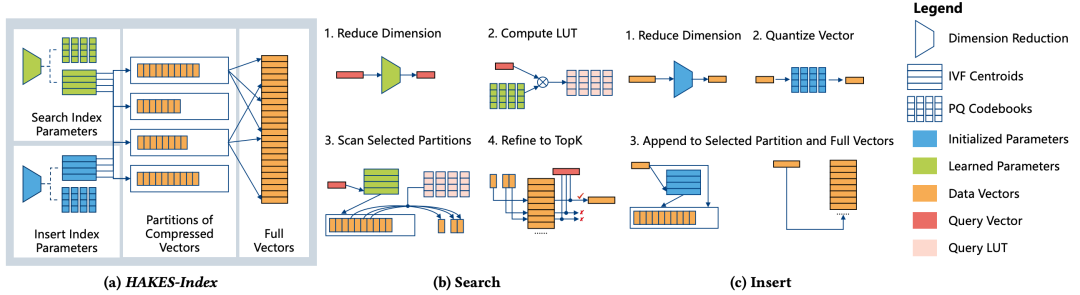
HAKES(Scalable Vector Database for Embedding Search Service:https://vldb.org/pvldb/volumes/18/paper/HAKES%3A)使用 PCA 压缩,PQ 量化,高精度重排来实现了一整套混合检索。
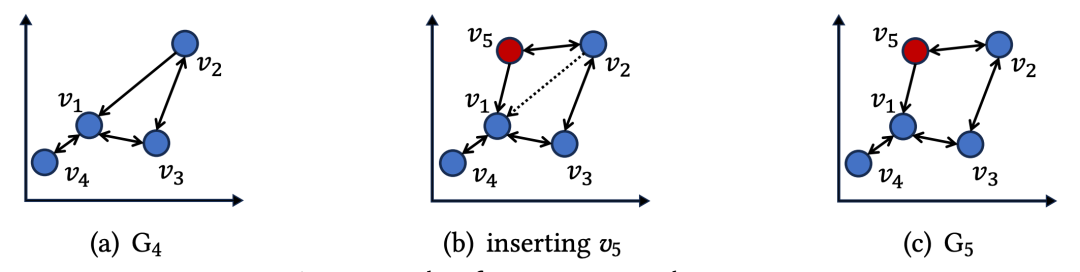
动态性
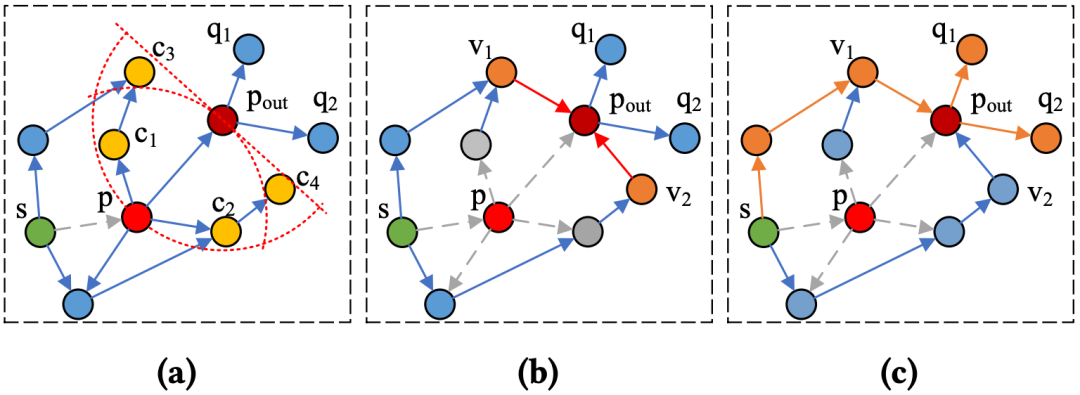
对在向量索引上进行增删改查的需求长期以来都是业界痛点和学界难点。其中,插入和查询不会导致索引劣化。更新操作可以被处理为一次删除和插入。从而,在动态性层面只有删除场景这一问题需要解决。而难的是,在近邻图索引上删除可能会导致单调递减路径(Monotonic Decrease Path)的缺失,甚至图的不联通。从而大幅度影响索引的性能和召回率。
虽然有许多启发式方法可以通过打补丁的方式来修复图索引。但问题的难点在于业界中使用的图几乎都是有向图(MRNG 裁边策略)。因此,即使能找到点的出边并修复,也难以获取点的入边。这使得这些打补丁的方式只能缓解而不能从根本上解决删除导致的索引劣化。
近年来,由于该问题本身的难度,对其的探索多数也只针对于“打补丁”的算法。freshDiskANN@arxiv(https://arxiv.org/pdf/2105.09613)首先提出了如何在 DiskANN 上删除需要修复出边点的邻居关系来缓解劣化。
Wolverine@VLDB'25(Highly Efficient Monotonic Search Path Repair for Graph-based ANN Index Updates:https://vldb.org/pvldb/volumes/18/paper/Wolverine%3A)进一步,限制搜索空间到删除点的两跳邻居内来提高删除 TPS 。并结合了搜索路径来进一步启发了对修复点的选择。
混合检索
接下来我们讨论混合检索中,“标量”“字段”“属性值”都表示关系型数据库中的表的某一列的值。
混合检索是指向量和标量共同作为检索条件的场景。例如,想要搜索“价格在 10 元到 100 元和给定商品图片相似的商品”就是一个典型的混合检索场景。近年来,学界在混合检索的解法和问题上,主流的方案有三种:
-
方案一:按属性值划分子索引,构建子索引树,找到一个最小覆盖子集(ESG@arxiv,SIEVE@VLDB'25)
-
方案二:按属性值划分子索引,在子索引之间增加边使之能够导航(UNG@SIGMOD'24,UNIFY@VLDB'25)
-
方案三:按过滤范围构建子图,压缩子图(SeRF@SIGMOD'24,DSG@VLDB'25
对于前两种方案,是在前置过滤(Pre-filter)的基础上做优化。前置过滤主要面向高选择度的过滤场景。能够精确到个别子索引,从而能够极大程度减小检索范围。然而,这样的做法对于通用的查询(例如,选择度低的过滤场景或者不过滤的场景)存在问题,因其需要检索大量的子索引。虽然每个子索引上的查询时间少,但是查询次数多,带来无法忍受的延迟。
【方案一】通过在子索引之上构建树来解决这一问题。多个子索引可以合并一个更大的子索引,在树中是一个中间节点。
ESG(https://arxiv.org/pdf/2504.04018)即是这样的一种技术。对目标的过滤范围找到最多两个子索引进行搜索。
SIEVE(Effective Filtered Vector Search with Collection of Indexes:https://vldb.org/pvldb/volumes/18/paper/SIEVE%3A)在此基础上,通过结合历史查询和用户目标召回率来在树上找到最佳的搜索方案。但是这一类方案有两个问题:
1. 需要为中间节点重复构建子索引:索引的层次数即为内存膨胀的倍数(例如,2 层子索引则相比原始索引膨胀 2 倍内存空间);
2. 无法处理多个属性字段的过滤场景。
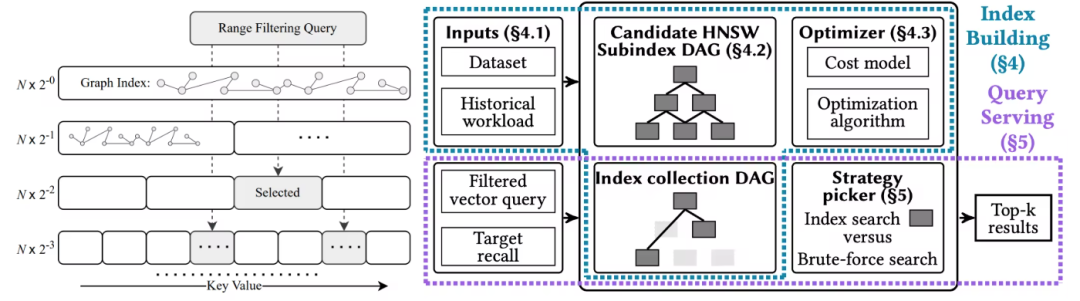
【方案二】使用了另一套方式:不合并子索引,而是在子索引之间连边。一方面,这解决了第一套方案的内存问题;另一方面,子索引不完全依赖单一属性,使用中置过滤来搜索,解决了第二个问题。但是这套方案长期面临问题是如何添加边。
UNG(https://dl.acm.org/doi/10.1145/3698822)首次提出在子索引之间用最近的向量对来连边,并理论证明了在中置过滤下的检索收敛性。
UNIFY(Unified Index for Range Filtered Approximate Nearest Neighbors Search:https://vldb.org/pvldb/volumes/18/paper/UNIFY%3A)也采用了类似的思想,并结合 HNSW 的分层设计来对检索进一步的加速和定位。
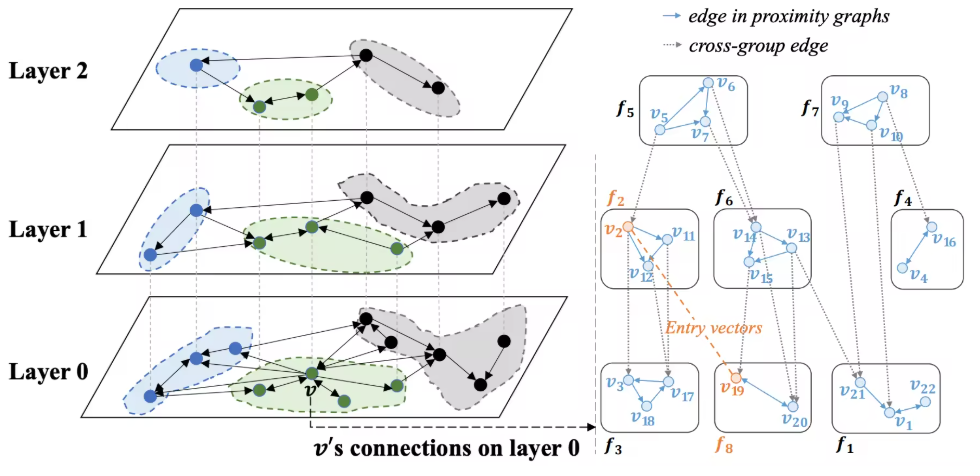
【方案三】从另一种截然不同的角度来考虑过滤问题。不关注每个向量的值,而是关注理论最优的图。例如,理论最优的前置过滤方案是能找到一个子图,图中的所有的点都满足过滤条件。于是在这个图上进行搜索的过程不需要考虑过滤条件,能够达到极高的精度,并且不会造成结果的浪费。
SeRF(https://miaoqiao.github.io/paper/SIGMOD24_SeRF.pdf)首次提出了当节点的插入顺序和属性值顺序相同时,可以以极小的代价为边打标签,从而通过区分标签的方式来快速找到目标子图。
DSG(Range-Filtering Approximate Nearest Neighbor Search:https://vldb.org/pvldb/volumes/18/paper/Dynamic)在此基础上,将范围代表的 rectrangle 合并成树来解决随机到达的数据的问题。但和方案一相似的是,这一套方案也不支持多属性值的情况。
软硬件结合
在数据量小的情况下,向量索引通常是纯内存态的。但由于高维向量的特性,随着数据量增加,内存成本急剧增加。例如,对于 100w 的 960 维向量数据,索引占用 4GB 内存。在 10 亿向量规模下,索引占用 4000 GB 以上。因此,在海量数据的背景下,向量索引往内存 + 磁盘,内存 + 远端存储等方向演进。在此基础上,磁盘的 IO 速度、带宽等因素导致检索的耗时瓶颈和内存完全不同。另一方面,随着学界对 Smart SSD、FPGA、GPU 等硬件的探索,发现内存的检索模式并不能很好的利用到这些新硬件。这要求我们探索新的方法来适配这些不同的硬件。近年来,学界研究的主流的方向有两个:
【方向一】改造检索算法,使之更适配于硬件(CAGRA@ICDE'24,MARGO@VLDB'25)
CAGRA(https://www.computer.org/csdl/proceedings-article/icde/2024/1.715E241/1YOtVakjDy0)针对在 GPU 上难以直接应用在单核场景下的检索算法的问题。其对图构建算法、检索流程、流水线优化、查询计划四个方面均为在 GPU 上部署向量检索服务提供针对性的优化。其核心思路是让图变得更加扁平化,从而减少并行场景线程之间的计算浪费和资源冲突。这一思想可以应用于目前大部分的检索场景,包括使用 Smart SSD、FPGA 等硬件的场景。
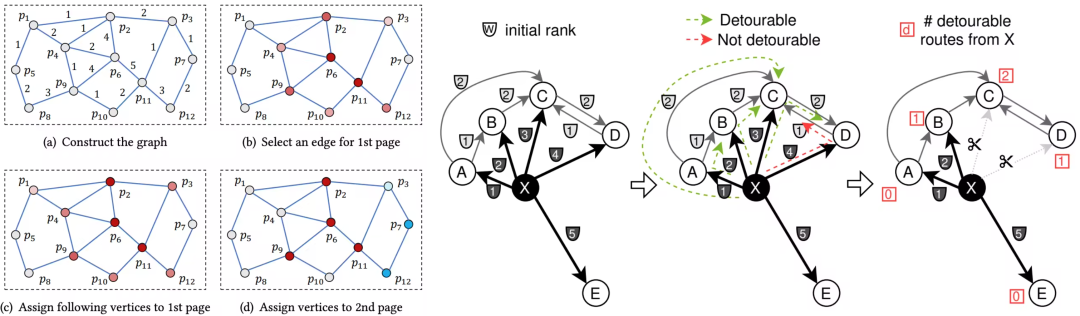
MARGO(Edges Wisely%3A Monotonic Path Aware Graph Layout Optimization for Disk-based ANN Search:https://vldb.org/pvldb/volumes/18/paper/Select) 研究者主要探索更好的图分片的算法。以减少 SSD 和 CPU 的 IO 次数,来降低检索的延迟。
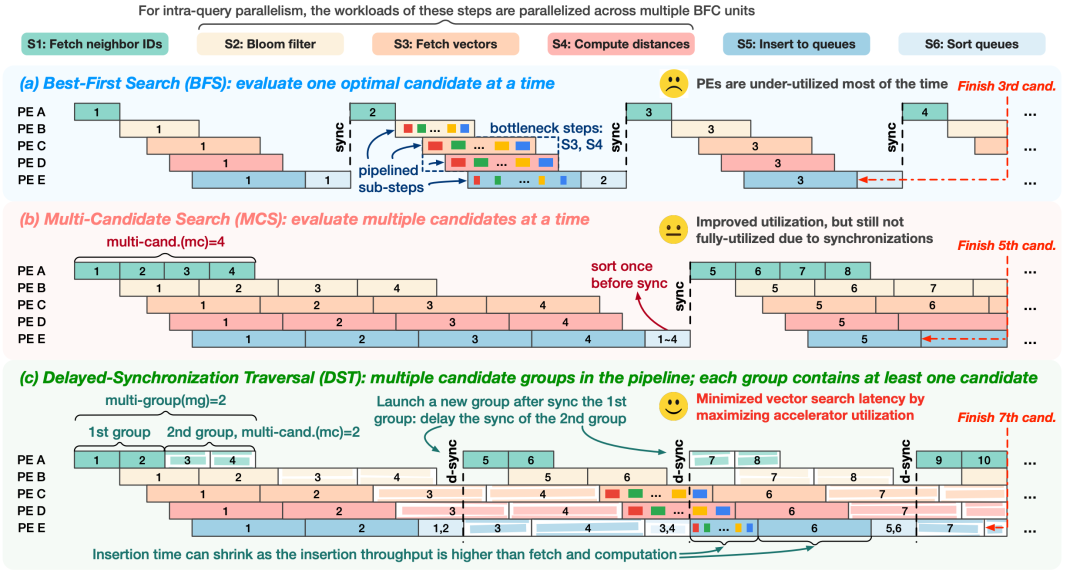
【方向二】改造硬件或者流水线,使之更适配向量检索的算法(DST@VLDB'25,PGV-ASYNC-IOU@VLDB'25)
PGV-ASYNC-IOU(Vector Databases using Modern SSDs:https://vldb.org/pvldb/volumes/18/paper/Turbocharging)为现代 SSD 内的并行 IO 和 io_uring 接口减少搜索延迟。
DST(Graph Vector Search via Hardware Acceleration and Delayed-Synchronization Traversal:https://vldb.org/pvldb/volumes/18/paper/Fast)采用了类似的思想在 FPGA 上精心设计了硬件的分工,并优化了在检索过程中的流水线模式。
向量检索未来发展方向
算法方向:从业界需求的角度观察
低成本图索引构建
挑战:当下大多数的研究工作围绕如何减少索引服务时的成本,比如通过对向量进行量化、对图进行压缩的方法等,但是鲜少有工作考虑针对构建的内存进行优化。在低成本场景下,构建的挑战主要主要由两方面:
-
构建时逐一插入向量并不是幂等操作,这是因为前置插入的向量会影响到后续向量的插入准确性,这使得在搜索过程中常用的量化方法在构建过程中由于误差的累积,会变得不可用
-
构建时由于裁边操作的存在使得其需要访问的向量总量要远大于搜索过程;
现有方法:当下在低成本图构建方向上的 SOTA 方法是 DiskANN(NIPS'18)。它的主要思想是通过分区和冗余的方式构建多个子索引,然后将这些图索引进行合并。然而,由于每个子索引在构建时只包含了当前分区的点的信息,导致最终合并得到的索引的性能不佳。
低成本高吞吐检索场景
挑战:随着 DiskANN、SPANN 等方法的提出,向量检索时的内存压力得到了极大的改善。由于 DiskANN 方法相较于 SPANN 方法能够实现更高的精度,因而在工业界得到了大规模的应用。然而,基于图的向量检索存在大量的随机 IO,这导致现有方法无法实现较高的 QPS。我们通过以下例子说明:
假设单台服务器我们将数据分成 64 个包含 10M 数据的图索引切片,一次查询需要访问 500 个点,每秒的 QPS 在 200。假设单台服务器有 64 个线程,那么当这 64 个线程同时搜索时,对服务器的检索需求将会是 6.4M 的 IOPS。
现有方法:针对上述问题,一个可行的解法是增大单个图索引的规模,然而这种增大规模不是无限的,很快就会面临低成本图索引构建问题;第二个解法是提高每次 IO的 缓存命中,STARLING(SIGMOD'24)通过尽可能将点和其邻居存储在一起来解决这个问题;第三个解法是通过剪枝的方式,去除掉一些不必要的重排,例如DDC(ICDE'25)通过研究量化误差的分布,选择性地减少了部分的重排成本。
自定义度量
挑战:L2、IP、COSINE 是当下最主流的在向量检索中使用的 metric。然而他们并不一定是衡量 query 和 doc 相关性最好的 metric。自定义度量存在即为广泛的应用需求,比如,多向量检索本质上也是一种自定义度量问题。然而,并不是任意的 metric 都能应用于向量检索的过程。下面是应用不同 metric 存在的挑战
-
适用于向量检索的 metric 需要满足以下条件:对于任意的查询 q 和数据库中的任意两个点 a, b, 都需要满足
其中 d 是搜索时使用的 metric,而 d' 是构建时使用的 metric,
α 是一个描述数据集特性的系数,越小意味着 metric 越适合向量检索算法
-
metric 是向量检索过程中最主要的计算代价,因此,过于复杂的 metric 将会导致显著增加
现有方法:现在几乎没有什么方法能够解决自定义度量的检索问题,主流的方法通常以 L2、COSINE、IP 为距离度量进行向量检索,然后使用自定义的距离度量进行重排。
OOD检索
挑战:OOD(Out Of Distribution)是现在向量检索中普遍存在的现象,OOD 问题的来源主要是数据。例如,通过文本检索图片和用用户的短查询去检索数据库中的长文本本质上都是一种 OOD 检索。OOD 现象的存在会导致检索变得困难,往往需要消耗更多的资源才能达到一个可用的召回率。
现有方法:当下主流的解决 OOD 问题的方法就是增大参数来扩大搜索空间,防止搜索陷入到局部最优解中,然而这种解决方案会显著增加检索成本。此外,RoarGraph(VLDB'24)提出了一种基于 query 的图索引构建,通过向图索引中补充 OOD 的 query 来实现算法的增强。
系统方向:Native & Extended Systems
Native System or Extended System?如何选择系统
现有的“向量数据库”产品可以分为三种:
1. 向量检索库Search Engine & Library:关注纯粹的向量检索算法,典型的如 VSAG、Faiss。能做到极高性能和极高索引层面的灵活度。并且,在设计时不需要考虑标量表、分布式、安全等复杂场景,使得其性能是三种产品中最好的。但是其往往只适用于单机快速POC场景。
2. 向量数据库Native System:在向量检索库之上搭建了数据管理能力、事务能力和分布式处理等数据库特性能力,典型的如 Milvus、Qdrant。其主要关注向量检索的能力。适用于集群级大规模向量数据的管理和检索场景。
3. 有向量能力的数据库Extended System:在关系型数据库等传统数据库上拓展向量检索能力,典型的如 OceanBase、GaussDB。其有更加丰富的对标量数据的管理能力。特别的,有长年积淀的查询优化的能力。适用于主要检索标量,小规模向量的场景。
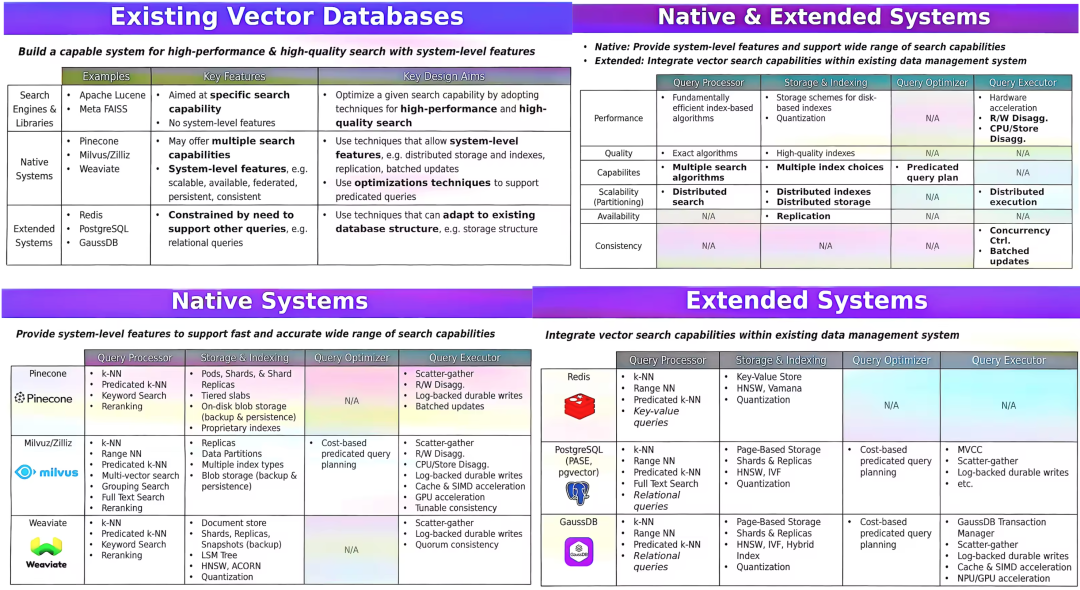
因此,对于一个新的需要向量检索能力的应用,如何选择这三种产品呢?首先,在 POC 阶段使用【向量检索库】做快速 POC,验证链路的可行性。然后,根据对标量或者向量能力的检索需求选择不同的数据库。如果应用的查询中有大量标量过滤字段,则应该选择【有向量能力的数据库】。如果只有少量的过滤字段,则应该选择【向量数据库】。
复杂混合检索任务的数据库选型和算法研究
然而, 现有的一些应用对两者都同样看重,造成了两难问题。如果选择有向量能力的数据库,虽然能快速在数据库层面过滤标量,但计算向量字段的速度远低于标量字段的检查,导致查询的延时高。如果选择向量数据库,则因为对标量的管理能力欠缺,难有高的召回精度。
从长期来看,我们认为较优的情况是将具有强大标量和向量混合检索的算法部署在数据库上。这类混合检索算法(如 ACRON,UNG 等)结合了标量的特性和向量的特性对索引结构做针对性的调优。这使得索引能原生支持混合检索,而不是为了某一方去做妥协。然而,正如我们对今年VLDB混合检索的分析,目前最新的算法也只能在特定场景上做优化。一旦标量条件变得复杂,混合检索的算法收益和通用性将面临巨大的挑战。目前的原生混合检索算法也仅适用于简单字段的过滤,或对数据有强假设。
从短期来看,这使得两种数据库的研发同学有不同的研发方向:
1. 对于向量数据库的发展,完善在标量上的检索能力,或者选取部分对向量检索重要的标量做特殊处理。这一条链路有明确的实现路径,对标量的检索能力可以借鉴传统数据库沉淀多年的算法。在对部分标量特殊处理的角度,可以复现学界提出的新的算法。
2. 对于有向量能力的数据库的发展,则可以尝试融合传统场景的优化方案和向量,提出新的联合优化方案,把向量视为一个特殊的索引而不是数据库的新的模块。
接下来,我们将以 Optimizer 和 Cost Estimator 为例,来探索联合优化的一些方向。
Extended System 的联合优化 —— 以 Optimizer 和 Cost Estimator 为例
在数据库层面,Optimizer(优化器) 是数据库管理系统(DBMS)中的一个核心组件,它的主要任务是:为 SQL 查询选择最高效的执行计划。简单来说,当执行一条 SQL 语句(比如 SELECT * FROM users WHERE age > 30),数据库可能有多种方式来执行它(例如先扫描表再过滤,或使用索引等)。优化器就是负责从这些可能的执行路径中,选出速度最快、资源消耗最少的那个方案。
无独有偶,标量和向量混合检索领域也适用于 Optimizer 的逻辑。其中也有复杂的索引选择、查询计划、参数选择等问题:
-
索引:在哪一个子索引上搜索?
-
查询计划:前置过滤?中置过滤?后置过滤?
-
参数选择:在过滤场景下,搜索候选集ef_search大小?搜索的跳过率?
对于不同的过滤场景,不同的过滤率,甚至于不同的 workload 都有可能促使我们从这些问题中做出不同选择。例如,当能过滤率低时,应选择大索引并使用中置过滤;当过滤率高时,应选择小索引走前置过滤。而在结合了历史查询、查询本身的难度等因素下,选择问题变得更加复杂。人工选取一个查询计划是几乎不可能的,难以适配多变的 workload 和业务场景。
此时,需要我们能快速估计查询的代价,让优化器在多个方案中自动根据场景选择。
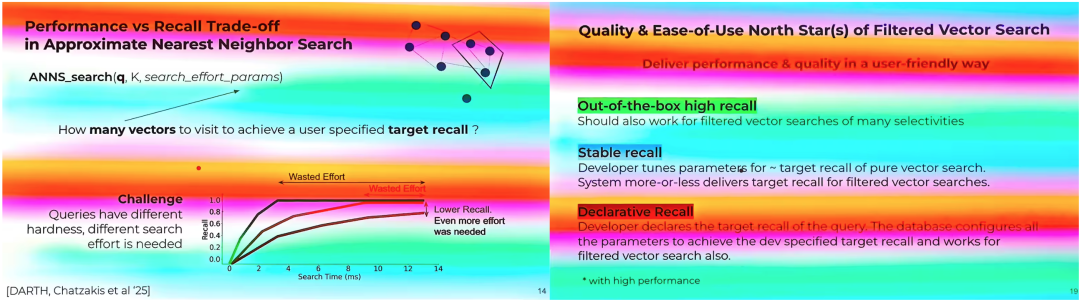
接下来,我们从几个例子来分析:
【Case 1】:Optimizer 根据字段选择索引
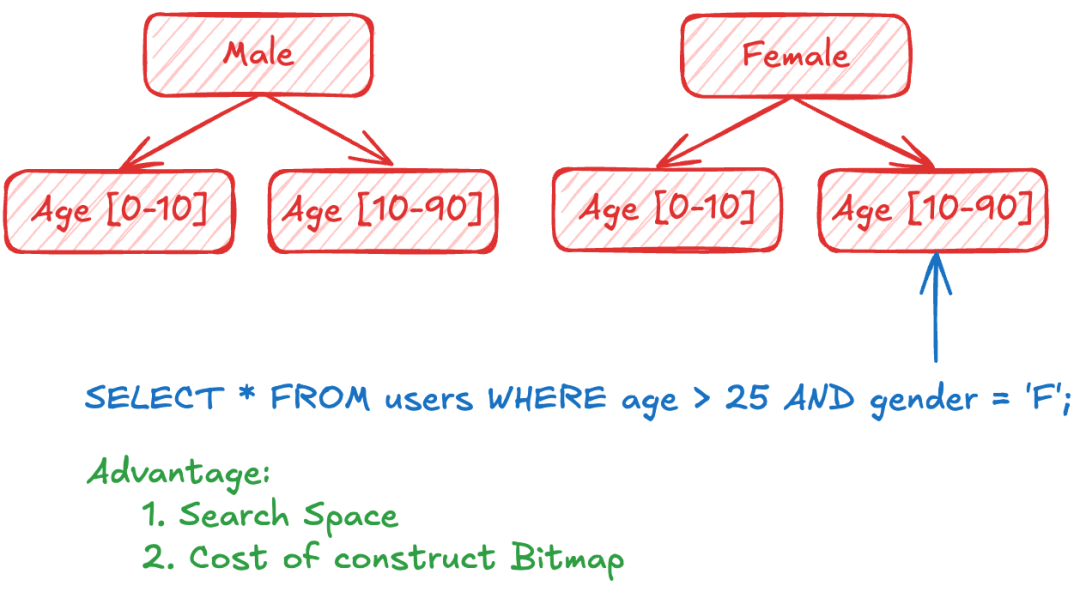
这个例子中一共有 6 个混合索引。在标量字段,分别按照年龄和年纪来区分。在这样的简单查询中,优化器可以快速选择最小的目标子索引。这样能极大程度减少向量的搜索空间和构建过滤的 bitmap 的成本。同时,在检索时也完全不需要考虑过滤条件,因为在选择子索引时已经满足过滤条件了。在图例中,我们选择了女性下的一个子索引进行搜索即可。这就是一个典型的优化器通过字段选择索引的场景。
【Case 2】:Optimizer 根据基数估计选择搜索策略
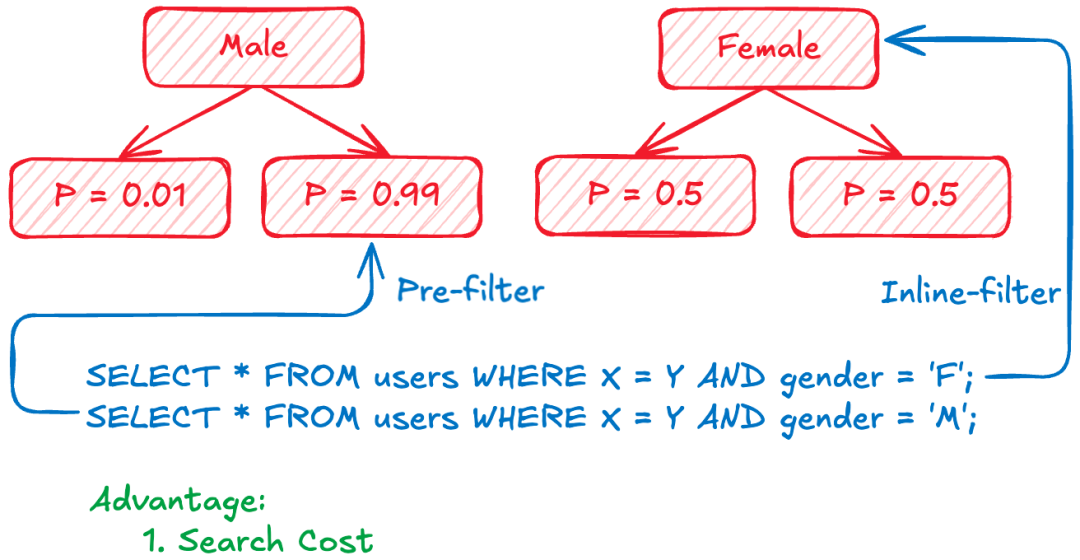
进一步对于一些复杂的过滤条件,难以提前根据字段提前对索引分区。在这个例子中,我们对“性别”等简单字段可以提前划分子索引,但无法定位到确切的满足过滤条件的子索引。此时,最朴素的做法是扫描所有的子索引,但显然这会使得这次搜索耗时严重。而在结合基数估计后,我们可以对子索引满足过滤条件的比率做估计。
例如,对于图中限定男性查询,我们有一个子索引有 99% 的概率满足过滤条件。则可以在该子索引上进行前置过滤检索。而代价仅为牺牲 1% 的精度。而对于另一个限定女性的查询中,两个子索引有相似的概率。此时则需要在女性下的大索引走中置过滤搜索。在整个过程中,我们不只是通过字段去选择搜索策略,而是通过基数估计。
【Case 3】:Optimizer 根据基数估计选择索引和参数
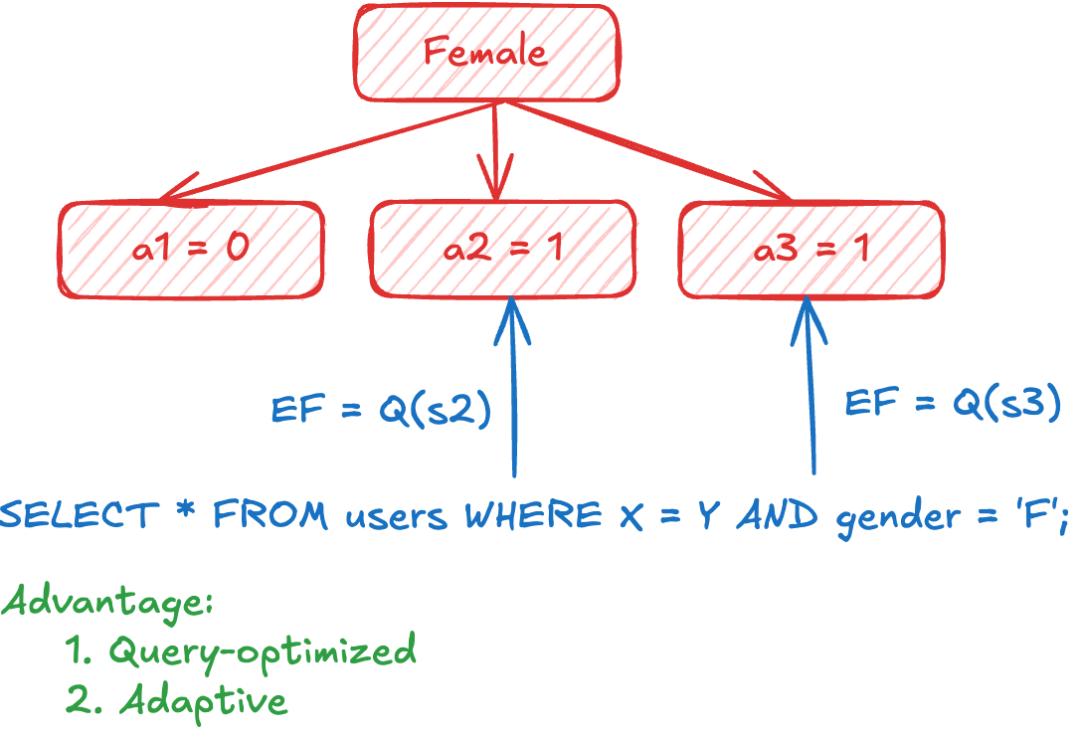
更进一步,在子索引的基数严重不均衡的情况,我们可能必须要选择多个子索引进行搜索。而显然,搜索的努力程度是随着基数的不同变化的。对于基数大的子索引,存在答案的概率更高,更值得我们花费大代价去做搜索,基数小的子索引则反之。此时,优化器可以结合在满足过滤条件的代价的基础上,增加向量侧的查询代价估计。值得注意的是,即使是没有过滤场景,对向量检索的查询代价估计也是近年热门的课题。在这个例子中,优化器已经需要处理标量和向量混合的代价估计,去选择合适的索引和参数进行检索,以在满足用户目标的基础上最小化查询代价。
【Case4】:Optimizer(强化学习其他 AI 方法)根据历史 workload 选择索引、策略和参数
在 AI4DB 的大背景上,我们可能不满足于以启发式方法或者基于规则的算法来生成查询计划。受到 workload、查询本身的特征等影响,我们更期望于有一个更有泛化性,更能捕捉查询深层特征的优化器。例如,可以基于强化学习动态选择有价值的子索引,也可以通过对查询难度的估计,来动态选择向量检索的参数。从而,向量只成为了一个特殊的索引字段,向模型输出索引结构,查询状态,难度估计等特征,让模型来端到端决策整个搜索过程中需要用到的索引、策略和参数。
联合优化的工程问题
虽然通过上面四个例子,我们简单描述了 Extended System 联合优化的算法部分。但在落地层面,还有许多工程问题急需解决。
首先是构建多向量子索引带来的内存膨胀问题。与传统数据库的不同点在于,向量数据往往是高维的浮点数据。这使得子索引的内存成本膨胀是难以忽视的。例如,在之前的例子中我们有两层子索引,则至少膨胀一倍的向量空间,何论复杂查询划分多层子索引的情况。而索引划分的层数少,会使得复杂过滤下的性能糟糕。划分的多,则使得内存成倍膨胀。这一问题,在大规模向量数据的场景是无法接受的。因此,我们需要引入工程优化方案来解决。例如:子索引中不存储向量;子索引只存量化向量;只考虑关键字段等。
另一方面,如果引入 AI 决策,精度和耗时的 Trade-Off 也令人头大。如果使用大规模神经网络,单个查询的耗时被约束在模型推理上;如果使用小规模网络,则精度不佳。这也促使我们在引擎层面需要做更多的如:批处理、参数化、启发式规则等优化方法。
总的来说,当我们将向量视为是一个索引而不是传统数据库的模块时,可以引入许多的传统数据库沉淀多年的方法来进行向量和标量的联合优化。在本章中笔者主要阐述了通过引入查询难度估计来从 Optimizer 对混合检索进行联合优化。在更多领域,相信未来的研究者也会探索更多曾经我们的先辈深耕多年的解决方案如何适配于向量检索这一熟悉的陌生场景。
系统研发趋势:重心已发生变动
当前,尽管向量索引种类繁多且多采用各自独立的端到端实现,但在实践中我们发现,许多索引在底层组件——如图结构管理、分区策略、向量量化等方面具有高度共性。这表明,不同索引之间的差异往往不在于模块本身,而在于这些组件的组合方式与配置逻辑。例如,HNSW 的多层图结构在各层实现上高度一致,其图管理模块与 DiskANN 也基本相同,主要区别仅体现在 I/O 访问模式等局部特性上。这也揭示了一种系统研发趋势:重心将从重复造轮子转向打磨高可靠的基础组件,而系统集成则由 AI 根据业务需求、数据分布和查询模式等输入,智能地拼装出最优架构。本次会议的首个 keynote 也分享了类似的观点。
我们是否正站在“手工定制系统时代”的终点?
本次会议的首个 keynote 是来自哈佛大学的教授 Stratos Idreos 分享的《ALPHABETS, GRAMMARS, CALCULATORS, AND THE END OF HAND-CRAFTED SYSTEMS》。以宏大的视角审视了数据库系统设计的过去、现在与未来,提出了一个根本性的问题:我们是否正站在“手工定制系统时代”的终点?Keynote 链接:https://vldb.org/2025/files/keynote/vldb25-keynote1.pdf当前,人工智能正以前所未有的速度重塑科学发现与产业实践。生成式模型、大规模训练、实时推理等新兴应用对底层系统的性能、灵活性和适应性提出了极高要求。与此同时,数据类型、硬件平台和工作负载的多样性也在迅速扩展。然而,支撑这一切的数据库与数据系统,其发展节奏却明显滞后。主流架构仍高度依赖几十年来积累的“经典模板”——如 B-tree、LSM-tree、列存引擎等。每一个系统的构建往往需要数年时间,涉及大量人工调优与经验判断。当新需求出现时,工程师通常面临两种选择:在旧系统上“打补丁”,或从零开始重建。这种手工艺式(artisanal)的系统开发模式,已难以匹配上层应用的迭代速度。
Stratos 开篇便抛出一个哲学性命题:AI 会取代数据库研究者吗?答案是否定的——因为我们面对的是无限的研究课题。真正限制我们的,不是问题的数量,而是探索空间的速度与效率。宇宙中的恒星数量约为 1024 颗,而可能的数据结构组合却高达 1048 种;若将一个完整系统视为多个组件(存储、移动、处理)的协同构造,则其设计空间呈指数级爆炸。
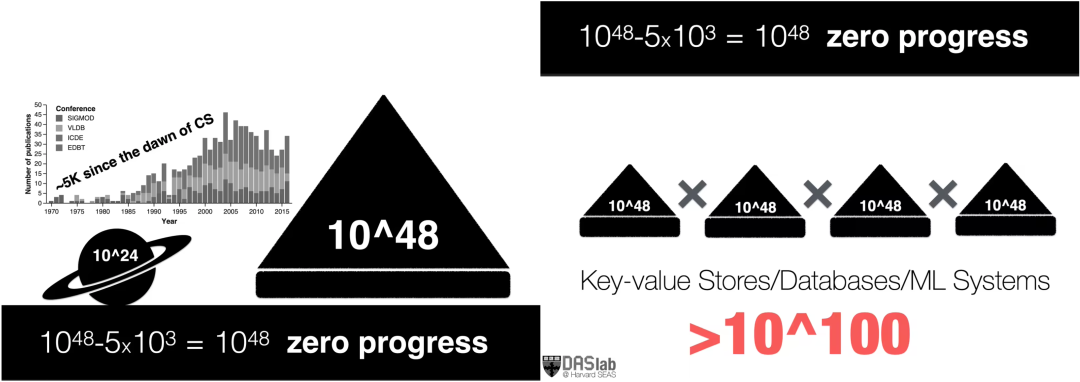
相比之下,自 1970 年以来,数据库顶级会议发表的论文总数不过约 5,000 篇,意味着人类至今探索的设计点仍是沧海一粟。更令人担忧的是:
-
每篇系统论文平均耗时 1-2 年;
-
一个完整系统从构思到落地常需 7-10 年;
-
待系统部署完成,原始假设可能早已失效。
当前系统构建的本质,是依赖 N 位博士生和 T 年时间,祈祷能撞见一个优秀的系统设计。一篇论文往往耗时 1–2 年,一个完整系统的研发周期则长达 7–10 年。当系统终于落地,工作负载、硬件平台或用户需求早已变迁。更令人困扰的是:当我们试图在一个成熟系统中引入新特性时,往往面临“牵一发而动全身”的困境——什么会被破坏?是否应彻底重构?
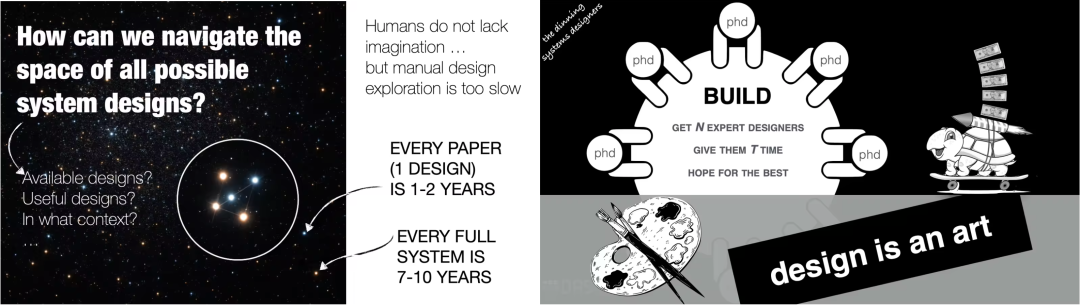
Stratos 指出,传统路径面临两大瓶颈:一是迭代速度跟不上变化速度,二是设计决策高度依赖专家经验。为此,我们需要一种全新的范式:输入是数据、查询、硬件约束、成本、延迟、精度等需求,输出是一个量身定制的数据库系统——即“自设计系统(Self-Designing Systems)”。
这类系统并非全新概念,其思想可追溯至计算机科学的早期,但如今的技术条件使其变得前所未有的可行。系统设计本质上是一系列低层次决策的组合:如何组织数据?如何调度计算?如何权衡内存与磁盘?关键在于,我们必须能够理解这些决策之间的依赖关系及其全局影响。
为了实现这一愿景,Stratos 提出将系统设计形式化为一种“语言”:
-
字母表(Alphabet):最基本的访问模式与数据布局原语;
-
词汇(Words):具体的数据结构,如 B-tree、LSM-tree、哈希索引等;
-
语法(Grammar):定义哪些结构可以合法组合,以及它们如何交互;
-
句子(Sentence):最终生成的、可执行的系统架构。
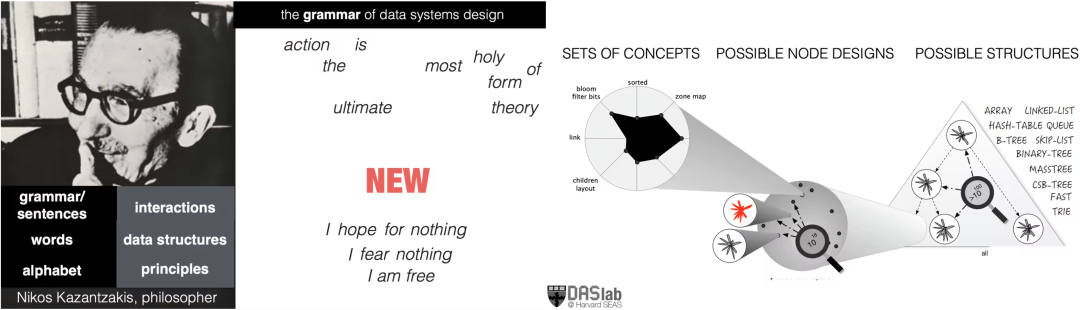
在此框架下,系统设计不再只是“艺术”,而成为一门可建模、可推理、可自动化的“工程科学”。基于上述形式化语言,一系列被称为“系统计算器”的自动化工具应运而生。它们能够在超大规模设计空间中高效搜索,并生成针对特定场景高度优化的新系统。典型代表包括:
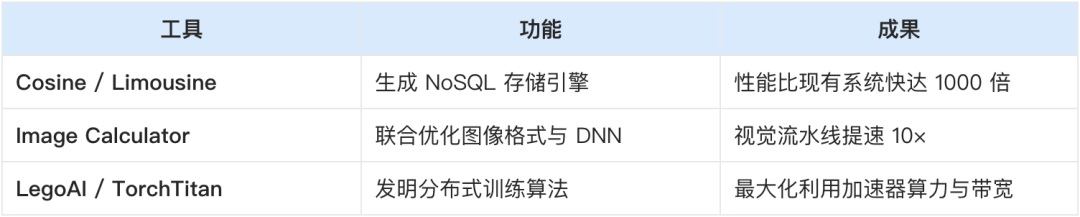

这些系统并非简单地调整参数或替换组件,而是从架构层面重新发明解决方案,展现出超越人类设计师的创新能力。随着自设计系统的兴起,系统研究的重点正在发生深刻迁移:
-
过去:研究人员亲自实现索引、调度器、事务协议,追求“极致优化”;
-
未来:研究重心转向构建更丰富的设计原语库、更精确的代价模型、更强大的合成引擎。
换句话说,未来的系统专家不再是“代码工匠”,而是“语言设计师”和“规则制定者”。他们不再直接编写系统,而是教会机器如何生成系统。最终目标,是构建一个“系统设计的计算器”——就像我们不再用手算微积分一样,未来的数据库工程师不应再手工雕琢每一个索引或调度器。通过形式化语法、自动化搜索与精准代价模型,我们可以让机器在 10^48 的设计星空中,快速定位那颗最亮的星。用户只需输入数据特征、查询模式、硬件预算、延迟与精度目标,系统计算器便能自动输出最优架构——就像使用计算器解方程一样自然。
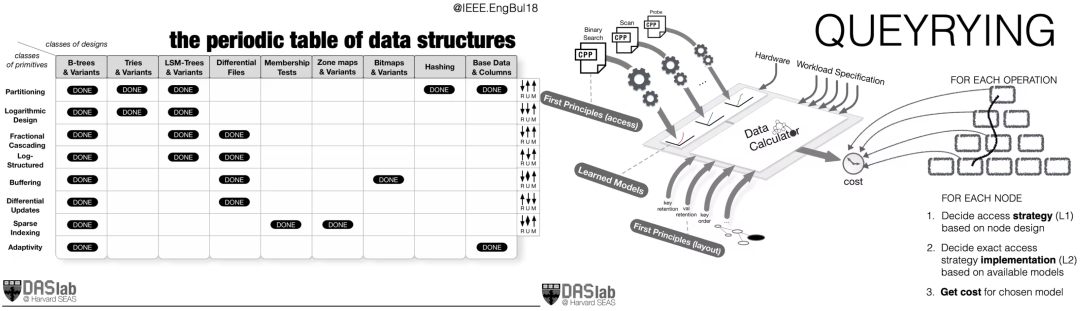
这不仅是效率的跃迁,更是系统科学的范式革命。它标志着:
-
手工构建系统的时代走向终结;
-
形式化、自动化、智能化的设计方法成为主流;
-
系统研究进入“元设计”(meta-design)的新阶段。
正如演讲者所言:“我们不是要让 AI 取代研究者,而是要让它解放研究者——让我们摆脱繁琐的实现细节,去思考更深邃的问题:什么是计算的本质抽象?哪些设计原则是普适的?”
向量检索的元素周期表:VSAG 向量检索库的设计理念
VSAG(https://github.com/antgroup/vsag)是蚂蚁向量检索团队自研打造的开源向量检索库。在工程实现上创新打造了模块化的设计,开发者能自由组合模块成为索引。呼应本届 VLDB 首场 keynote 中 Stratos 提出的“系统即语言”(systems as languages)设计理念,VSAG 在向量检索领域也构建了一套清晰的形式化设计体系——将索引结构的构造过程类比为语言的生成:从字母表到词汇,再到语法与句子。相比于业界其他的索引方法按索引粒度区分不同的检索算法, VSAG 提供的构造法带来了更强大的灵活性和自动化能力。
在这一框架下,VSAG 首先定义了向量存储与访问的基础原语集合,即系统的“字母表”(Alphabet)。这包括多样化的数据表示方式(如标量量化、乘积量化、二值编码等)和数据存储和访问(如内存存储、SSD 存储等),它们构成了所有高层设计的基本单元。
基于这些原语,VSAG 构造出一系列模块化的存储单元——“单词”(Words),称为 DataCell。每个 DataCell 是针对特定场景优化的语义完整块,封装了数据布局与访问逻辑。例如:
- FlattenDC
提供对线性存储向量的高效量化访问,适用于简单、高吞吐的扫描场景;
- GraphDC
则面向图结构邻居的动态跳转访问,支持复杂的近邻扩展路径;
-
其他专用 DataCell 还可服务于分区、标量存储等需求。
这些“单词”并非孤立存在,而是通过一组统一的 Interface Layer 实现组合与交互。该层充当系统的 “语法”(Grammar),规定了不同 DataCell 如何连接、协同与抽象化。
最终,在语法约束下生成的完整索引结构,便是这个语言中的 “句子”(Sentence)。它不再是手工拼凑的工程产物,而是一个由底层原语经合法规则推导出的、端到端一致的系统表达式,能够灵活支持 HNSW、IVF、DiskANN 等多种算法范式下的向量管理与检索任务。同时,能灵活切换句子中的单词从而做到适应多变的场景和需求,从而大幅度减少系统设计和开发时间。例如,在用户数据量小时,使用Memory IO;而随着业务数据增长需要切换成 SSD IO 时,并不需要从头设计一套全新的索引。而是可以通过切换 IO 这一个原语来做到。这种设计哲学,正体现了 Stratos 所呼吁的未来方向:告别手工艺式的系统堆砌,走向可组合、可推理、可自动化的系统构造范式。
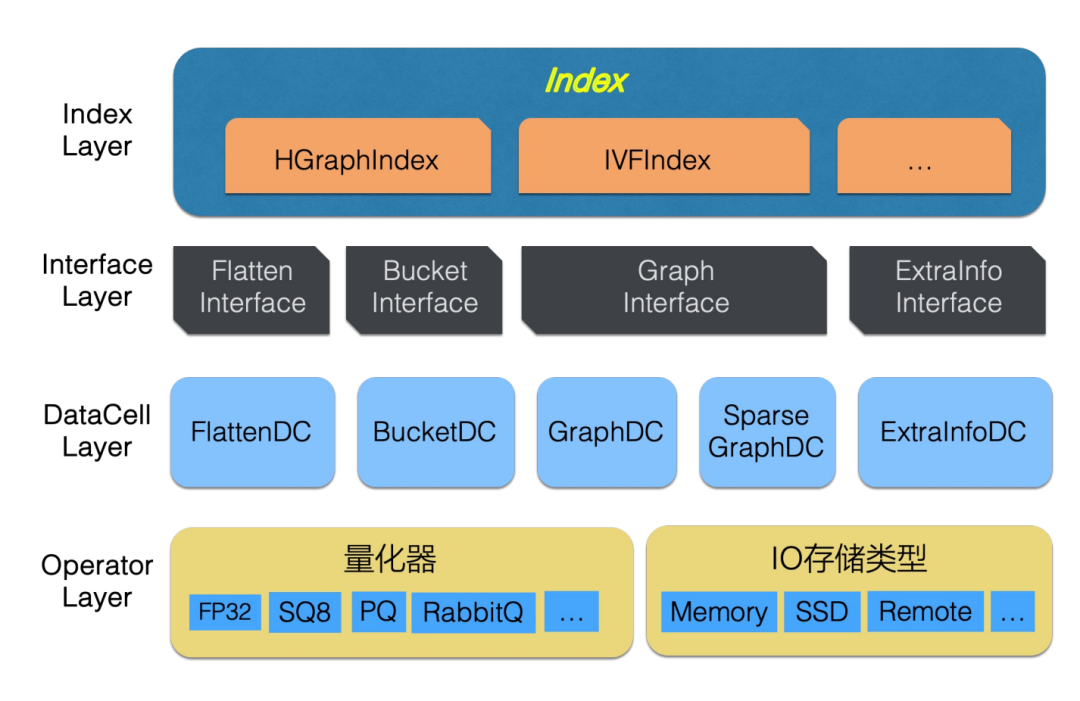
VSAG 检索优化框架
在算法上,VSAG 团队持续对不同的业务场景有深入的探索和创新,以提供强大的检索能力。今年 VLDB 中,以 VSAG 为主题的检索算法优化长文 VSAG: An Optimized Search Framework for Graph-based Approximate Nearest Neighbor Search 被 Industial-track 接收。在这篇论文中,我们系统性地介绍了 VSAG 在缓存优化、距离计算优化和自动调参优化三大块优化方向。其为 VSAG 提供了卓越的检索性能和易用性。
论文链接:https://www.vldb.org/pvldb/vol18/p5017-cheng.pdf
同时,VSAG 团队也在其他向量科研课题上保持投入:
-
图检索优化框架 VSAG【VLDB'25】(https://www.vldb.org/pvldb/vol18/p5017-cheng.pdf)
-
距离计算剪枝优化算法 DDC【ICDE'25】(https://arxiv.org/abs/2404.16322)
-
稀疏向量检索优化算法 SINDI【ICDE'26 under review】(https://arxiv.org/abs/2509.08395)
-
距离计算优化算法 MRQ【VLDB'26 Revision】(https://arxiv.org/abs/2411.06158)
-
高效的图合并算法 FGIM【SIGMOD'26 Revision】
-
召回率优化算法 EnhanceGraph【TKDE under review】(https://arxiv.org/abs/2506.13144)
-
分布式图索引优化算法 PAG【VLDBJ under review】(https://arxiv.org/abs/2510.17326)
附录:VLDB'25 收录向量文章
1. 混合检索
-
UNIFY: Unified Index for Range Filtered Approximate Nearest Neighbors Search:
(https://vldb.org/pvldb/volumes/18/paper/UNIFY%3A)
-
SIEVE: Effective Filtered Vector Search with Collection of Indexes:(https://vldb.org/pvldb/volumes/18/paper/SIEVE%3A)
-
Dynamic Range-Filtering Approximate Nearest Neighbor Search:(https://vldb.org/pvldb/volumes/18/paper/Dynamic)
2. 图构建
-
Maximum Inner Product is Query-Scaled Nearest Neighbor:(https://vldb.org/pvldb/volumes/18/paper/Maximum)
-
Revisiting the Index Construction of Proximity Graph-Based Approximate Nearest Neighbor Search:(https://vldb.org/pvldb/volumes/18/paper/Revisiting)
3. 动态性
-
Wolverine: Highly Efficient Monotonic Search Path Repair for Graph-based ANN Index Updates:(https://vldb.org/pvldb/volumes/18/paper/Wolverine%3A)
4. 软硬件结合
-
Select Edges Wisely: Monotonic Path Aware Graph Layout Optimization for Disk-based ANN Search:(https://vldb.org/pvldb/volumes/18/paper/Select)
-
Turbocharging Vector Databases using Modern SSDs:(https://vldb.org/pvldb/volumes/18/paper/Turbocharging)
-
Fast Graph Vector Search via Hardware Acceleration and Delayed-Synchronization Traversal:(https://vldb.org/pvldb/volumes/18/paper/Fast)
-
Graph Vector Search via Hardware Acceleration and Delayed-Synchronization Traversal
5. 检索优化
-
Accelerating Approximate Nearest Neighbor Search in Hierarchical Graphs: Efficient Level Navigation with Shortcuts:(https://vldb.org/pvldb/volumes/18/paper/Accelerating)
-
HAKES: Scalable Vector Database for Embedding Search Service:(https://vldb.org/pvldb/volumes/18/paper/HAKES%3A)
-
Steiner-Hardness: A Query Hardness Measure for Graph-Based ANN Indexes:(https://www.vldb.org/pvldb/volumes/17/paper/Steiner-Hardness%3A)
6. 分区优化
-
Cracking Vector Search Indexes:(https://vldb.org/pvldb/volumes/18/paper/Cracking)
-
Unleashing Graph Partitioning for Large-Scale Nearest Neighbor Search:(https://vldb.org/pvldb/volumes/18/paper/Unleashing)
-
Federated and Balanced Clustering for High-dimensional Data:(https://vldb.org/pvldb/volumes/18/paper/Federated)
7. 量化与距离计算加速
-
Not Small Enough? SegPQ: A Learned Approach to Compress Product Quantization Codebooks (https://www.vldb.org/pvldb/vol18/p3730-liu.pdf)
-
Efficient Data-aware Distance Comparison Operations for High-Dimensional Approximate Nearest Neighbor Search:(https://vldb.org/pvldb/volumes/18/paper/Efficient)
8. 系统
-
VStream: A Distributed Streaming Vector Search System:(https://vldb.org/pvldb/volumes/18/paper/VStream%3A)