小杰-自然语言处理(eleven)——transformer系列——Attention中的mask
1.引入
在 Attention 模型中,Mask 的核心作用是限制模型对序列特定位置的关注,常见于两类场景:
- 变长序列填充屏蔽(如机器翻译):
用特殊标记(如[PAD])填充短句子至统一长度后,通过 Mask 让模型忽略这些无意义的填充位置,避免学习到错误依赖。 - 未来信息屏蔽(如文本生成):
在语言模型训练或文本生成时,强制模型在预测当前词时只能看到过去的上下文(左半部分序列),防止 “未卜先知”,确保生成逻辑符合人类语言的时序依赖。
本质:通过掩码矩阵将无效位置的注意力分数置为负无穷,经 Softmax 后权重趋近于 0,实现对模型关注范围的精准控制。
2. 原理
Attention中的mask有两种作用:
- 限制模型对序列中某些位置的关注(padding mask)。
- 确保模型在生成序列时遵循因果关系(sequence mask)。
在批量处理不等长序列时,需用特殊符号(如[PAD])将短序列填充至同长度。此时padding mask的作用是:通过掩码矩阵标记填充位置,让模型在计算注意力时忽略这些无意义区域,避免学习到错误的语义依赖。其核心逻辑是将填充位置的注意力分数置为负无穷,经 Softmax 后权重趋近于 0,实现对无效信息的屏蔽。
2.2 padding mask
当句子不是等长的时候,会在句子后通过特殊符号<pad>进行补全,<pad>只是为了改变句子长度,方便将不同长度的句子组成batch而进行填充。
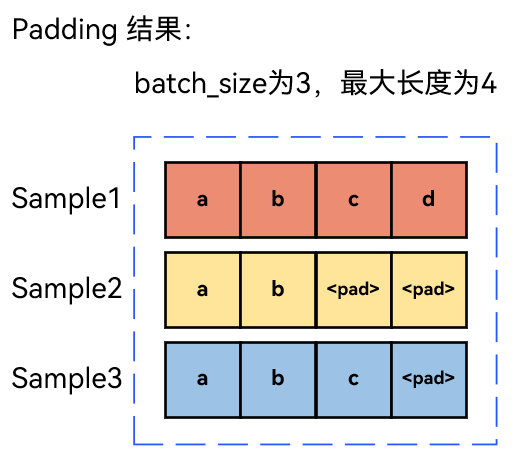
对于上面3 个样本(长度 4、2、3),补全至最大长度 4 后,padding mask 矩阵为:
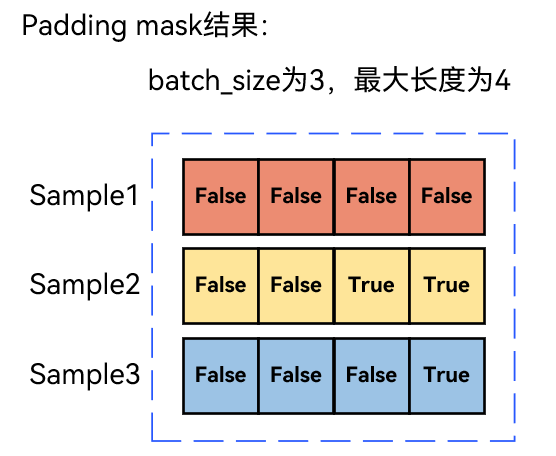
作用:通过布尔矩阵标记填充位置(True表示屏蔽,True的位置会被-inf所取代),计算注意力时将对应位置分数置为负无穷,使模型忽略[PAD]的影响。
2.3 sequence mask
在序列生成任务(如语言模型)中,sequence mask(序列掩码) 用于强制模型在预测第 t 个词时,只能看到 t 时刻之前的上下文,避免 “偷看” 未来信息。以句子['a', 'b', 'c', 'd']为例,其序列掩码是一个下三角矩阵,如下图所示:
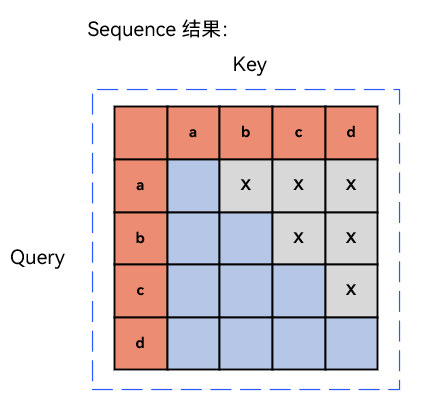
当我们有‘a’了,想要预测‘a’后面的一个token(即quary是a时),那么模型只能看见‘a’(即key的a),在想要预测‘b’后面的一个token,模型可以看到‘a’和‘b’,即待预测单词之后的单词都不分配注意力。根据上面提到的mask的构造方法,还是使用一个bool值构成的矩阵定义mask,对应本例可以得到attn_mask为:
对于句子['a', 'b', 'c', 'd'],生成下一个词时的sequence mask(序列掩码) 是一个下三角矩阵(对角线及左下为有效,右上为屏蔽):
预测'a'的下一个词时,只能看到'a',
预测'b'的下一个词时,能看到'a'和'b',
预测'c'的下一个词时,能看到'a','b','c'
预测'd'的下一个词时,能看到全部
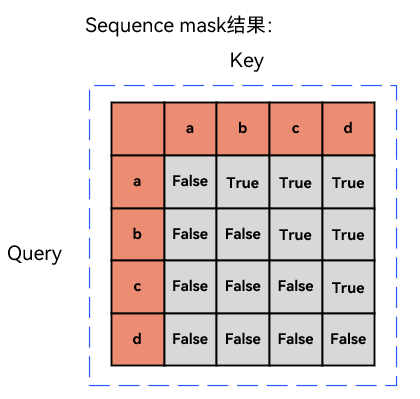
作用:矩阵中False表示允许关注,True表示屏蔽未来位置,确保模型在生成每个词时,仅能利用历史上下文信息,避免 “未卜先知”。
2.4 自注意力机制中sequence mask
在自注意力机制中,sequence mask 通过以下流程工作:
- 掩码构造:生成与注意力分数矩阵同形状的下三角矩阵(对角线及左下为有效,右上为屏蔽)。
- 分数处理:将掩码中无效位置(未来信息)的注意力分数置为
-inf。 - 归一化:经 Softmax 后,无效位置的权重趋近于 0,确保模型仅关注当前及历史位置的信息,避免 “偷看” 未来内容。
通过序列掩码,模型在预测每个词时,只能关注当前词及之前的词,符合自回归的特性,避免了模型在训练时看到未来的信息。如下图所示:
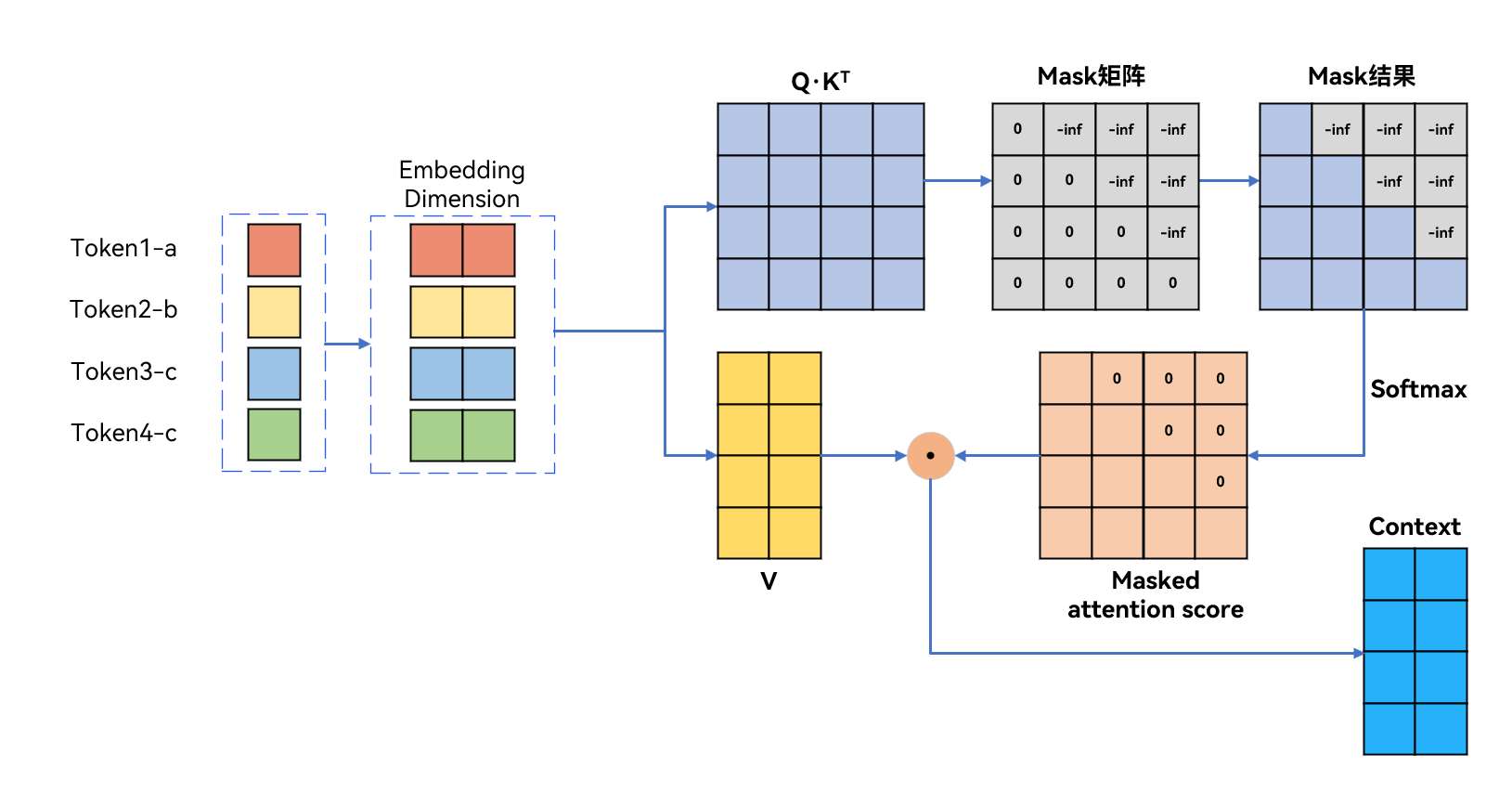
在这里,sequence mask矩阵对于所有的False设置为0,所有的True设置为-inf。
代码
import torch
def create_upper_triangle(sz):# 设定设备和数据类型device = torch.device("cuda" if torch.cuda.is_available() else "cpu")dtype = torch.float32# torch.triu 是 PyTorch 中的一个函数,用于构造一个上三角矩阵。上三角矩阵是一个矩阵。# diagonal=0:除了主对角线及其以上的元素外,其余元素都被设为零。# diagonal=1:除了主对角线以上的元素外,其余元素都被设为零。# 创建上三角矩阵upper_triangle_matrix = torch.triu(torch.full((sz, sz), float('-inf'), dtype=dtype, device=device),diagonal=1,)return upper_triangle_matrix# 示例:创建一个大小为 4x4 的上三角矩阵
sz = 4
result = create_upper_triangle(sz)
# 打印结果
print(result)在注意力机制中,通过将掩码矩阵中需屏蔽位置的注意力分数设为-inf,利用 Softmax 函数特性(e−∞≈0),使对应位置的注意力权重趋近于 0。具体来说:
softmax的函数公式为:
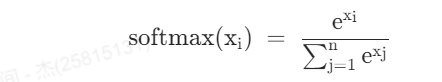
我们将注意力分数设为-inf,实际上就是将![]() 设为-inf,于是通过softmax后注意力权重就会趋于0。
设为-inf,于是通过softmax后注意力权重就会趋于0。
2.5 padding mask+sequence mask
在自注意力机制中处理不等长样本时,需同时使用padding mask和sequence mask
- 如果样本是“abcd”的话,加入padding mask+sequence mask如图所示:
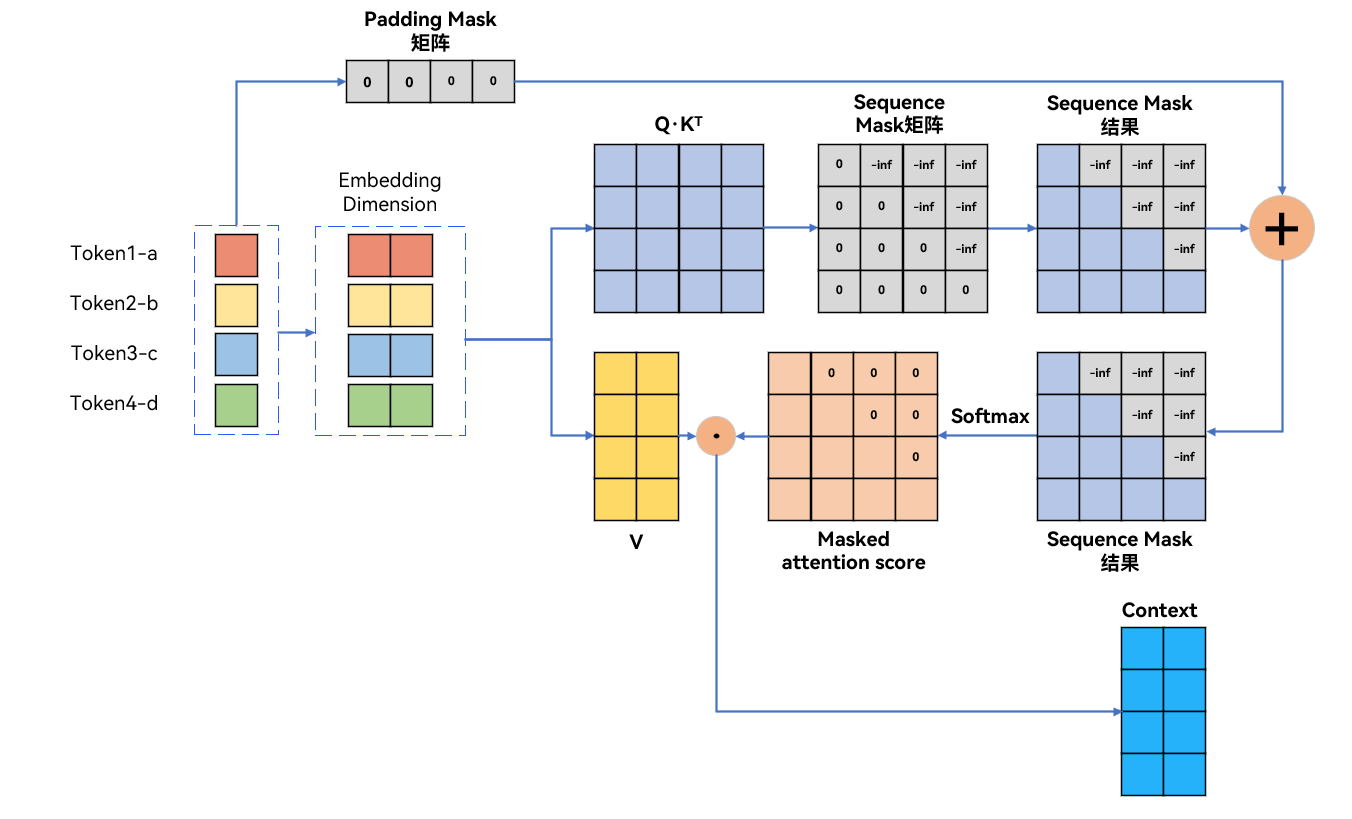
padding mask矩阵对于所有的False设置为0,所有的True设置为-inf。 (False(有效位置)置为 0,True(填充位置)置为 -inf)
如果样本是“abc”的话,加入padding mask+sequence mask如图所示:
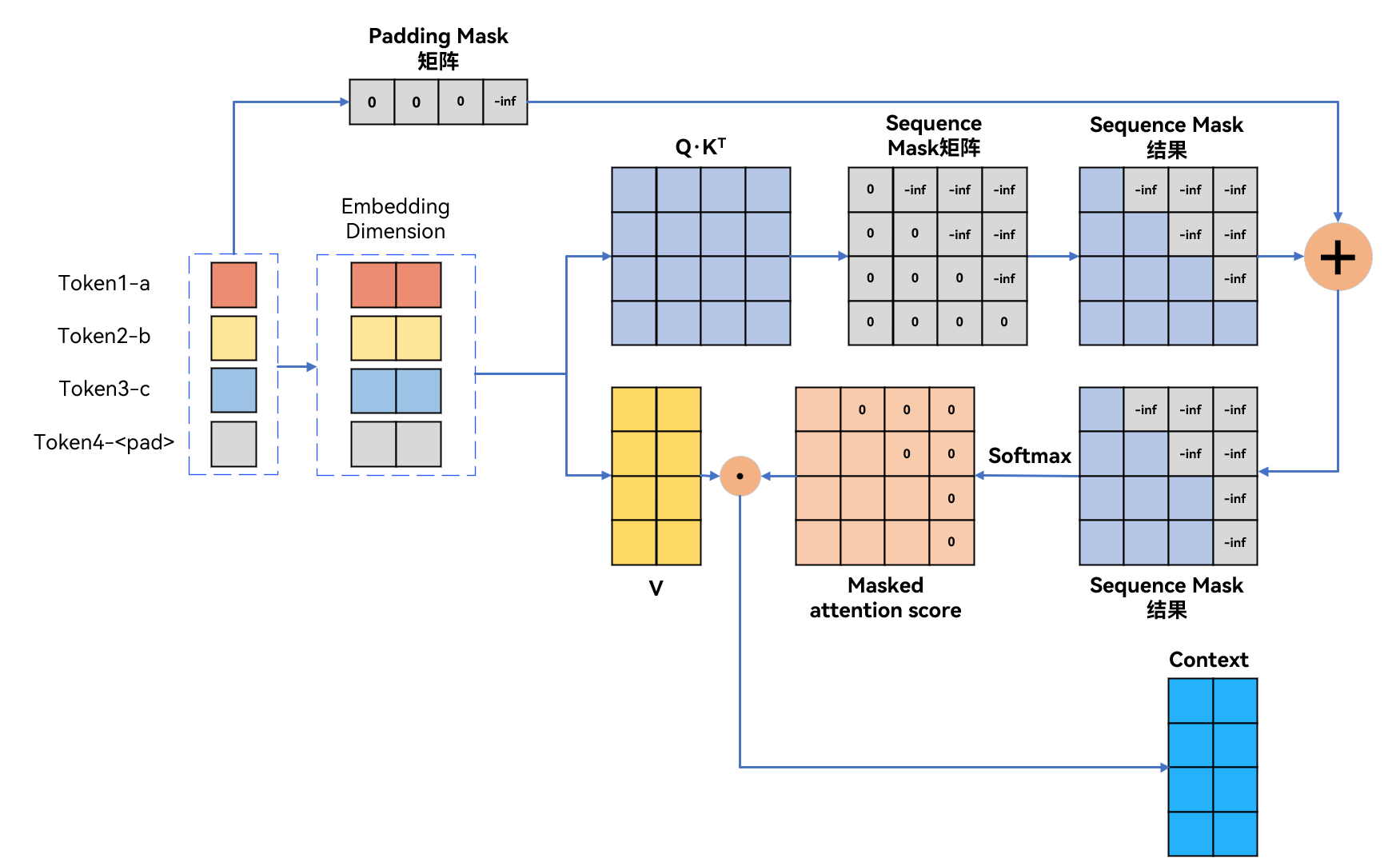
- 如果样本是“ab”的话,加入padding mask+sequence mask如图所示:
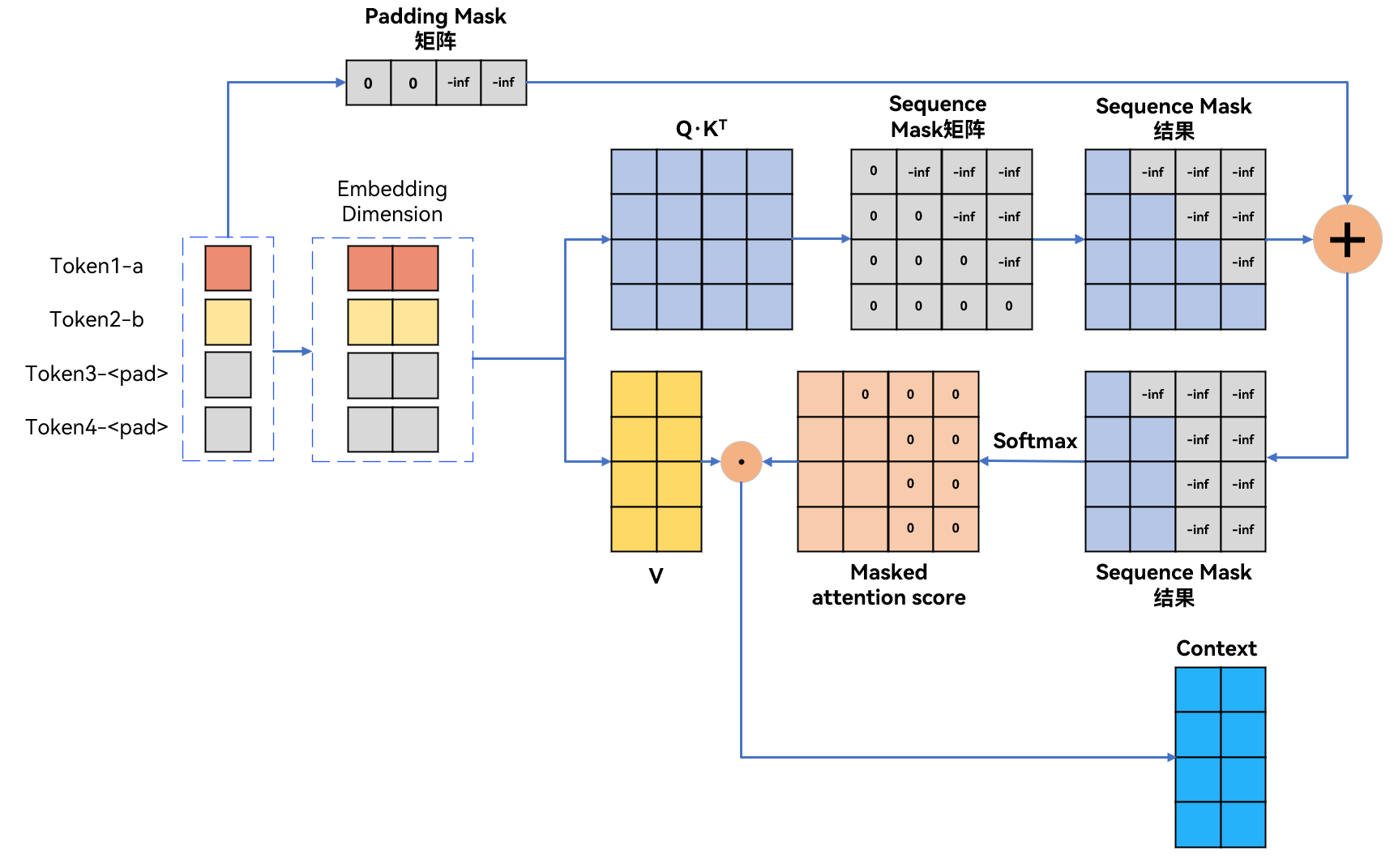
代码实现:
import torch
import torch.nn.functional as F# 模拟输入数据(batch_size=2)
# 序列1: Token1-a, Token2-b, Token3-c, Token4-d(无填充)
# 序列2: Token1-a, Token2-b, Token3-c, Token4-<pad>(最后一个是填充)
token_indices = torch.tensor([[0, 1, 2, 3], # 序列1(假设d对应索引3)[0,0,3,4] # 序列2(4为<pad>的索引)
]) # shape: [2, 4]
pad_idx = 4 # <pad> 对应的索引# 1. 生成词嵌入(实际是预训练或模型学习的嵌入)
embedding_dim = 2 # 嵌入维度
vocab_size = 5 # 词汇表大小(0-3为有效词,4为<pad>)
embedding = torch.randn(vocab_size, embedding_dim) # [5, 2]# 获取输入序列对应的嵌入
input_embedding = embedding[token_indices] # shape: [2, 4, 2]# 2. 生成 Q、K、V(简化:直接复用嵌入,实际需线性变换)
Q = input_embedding # shape: [2, 4, 2]
K = input_embedding # shape: [2, 4, 2]
V = input_embedding # shape: [2, 4, 2]# 3. 计算 Q·K^T(注意力分数矩阵)
scores = torch.matmul(Q, K.transpose(-2, -1)) # shape: [2, 4, 4]# 4. 生成 Padding Mask(标记填充位置)
padding_mask = (token_indices == pad_idx) # shape: [2, 4]
padding_mask_expanded = padding_mask.unsqueeze(1).expand(-1, scores.size(1), -1) # [2, 4, 4]
scores = scores.masked_fill(padding_mask_expanded, float('-inf')) # 填充位置分数设为-inf# 5. 生成 Sequence Mask(下三角掩码,屏蔽未来信息)
seq_len = scores.size(1) # 4
sequence_mask = torch.triu(torch.ones(seq_len, seq_len) * float('-inf'), diagonal=1) # [4, 4]
sequence_mask = sequence_mask.unsqueeze(0).expand(scores.size(0), -1, -1) # [2, 4, 4]
scores = scores + sequence_mask # 叠加序列掩码# 6. Softmax 计算注意力权重
attention_weights = F.softmax(scores, dim=-1) # shape: [2, 4, 4]# 7. 计算 Context(注意力加权和)
context = torch.matmul(attention_weights, V) # shape: [2, 4, 2]# 打印结果
print("输入序列索引:")
print(token_indices)
print("\nPadding Mask:")
print(padding_mask)
print("\nSequence Mask:")
print(sequence_mask[0]) # 所有样本共享相同的序列掩码print("\n注意力分数(应用双掩码后):")
print(scores)
print("\n注意力权重:")
print(attention_weights)
print("\nContext 结果:")
print(context)