DeerFlow介绍
概述
在DeepResearch(上)里汇总介绍过几个开源或闭源深度研究项目。
字节开源(GitHub,17.8K Star,2.2K Fork)的社区驱动的深度研究框架,结合语言模型与专业化工具,用于自动化研究和内容生成。Deep Exploration and Efficient Research Flow缩写,官网。基于FastAPI+LangGraph,多智能体协作的架构模式。
能力
- LLM集成
- 通过LiteLLM支持集成绝大多数模型
- 支持开源模型如Qwen
- 兼容OpenAI的API接口
- 多层LLM系统适用于不同复杂度的任务
- 工具和MCP集成
- 搜索和检索:通过进行网络搜索;使用Jina进行爬取,高级内容提取
- MCP无缝集成:扩展私有域访问、知识图谱、网页浏览等能力;促进多样化研究工具和方法的集成
- 人机协作
- 人在环中:支持使用自然语言交互式修改研究计划;支持自动接受研究计划
- 报告后期编辑:支持类Notion的块编辑;允许AI优化,包括AI辅助润色、句子缩短和扩展;由tiptap提供支持
- 内容创作:播客和演示文稿生成
- AI驱动的播客脚本生成和音频合成
- 自动创建简单的PPT演示文稿
- 可定制模板以满足个性化内容需求
关键点
- 多智能体架构:基于LangGraph构建模块化多智能体系统,实现复杂研究任务的自动化分解与协作
- 全流程工具集成:支持网络搜索、学术检索、Python执行等研究全流程工具链
- 创新内容生成:突破传统报告形式,直接生成播客、PPT等多模态研究成果
- 人机协同机制:首创
Human-in-the-loop交互模式,支持自然语言指令调整研究计划 - 开源生态优势:通过开源社区驱动持续优化,已形成包括UI扩展、运行器等配套工具链
支持多种搜索引擎,可在.env文件中通过SEARCH_API变量进行配置:
- Tavily:默认
- DuckDuckGo
- Brave Search
- Arxiv
对比传统研究工具
| 功能维度 | 传统工具 | DeerFlow解决方案 |
|---|---|---|
| 文献检索 | 手动关键词搜索 | 自动关联扩展+权威源优先 |
| 数据分析 | 独立脚本开发 | 交互式Python沙箱 |
| 成果呈现 | 固定格式报告 | 多模态自适应输出 |
| 协作方式 | 线性流程 | 动态可中断工作流 |
| 学习曲线 | 专业工具链 | 自然语言交互 |
局限性分析
- 领域适应性
- 高度专业化领域(如量子物理)仍需人工校验
- 非英语文献处理准确率较低(约72%)
- 计算资源需求
- 完整工作流需要8GB+显存支持
- 复杂任务内存占用可达32GB
- 伦理考量
- 自动生成内容需明确标注AI参与度
- 学术诚信边界需要进一步明确
架构
模块化的多智能体系统架构,基于LangGraph构建,实现灵活的基于状态的工作流,其中组件通过定义良好的消息传递系统进行通信。
graph TD
A[用户输入]-->B[协调器]
B-->C{是否需要背景调研?}
C-->|是|D[背景研究]
C-->|否|E[规划器]
D-->E
E-->F[研究计划]
F-->G{人工申核?}
G-->|是|H[人工反馈]
H-->E
G-->|否|I[研究团队]
I-->J[程序员]
I-->K[研究员]
J-->L[报告生成器]
K-->L
L-->M[最终报告]
或大差不差:
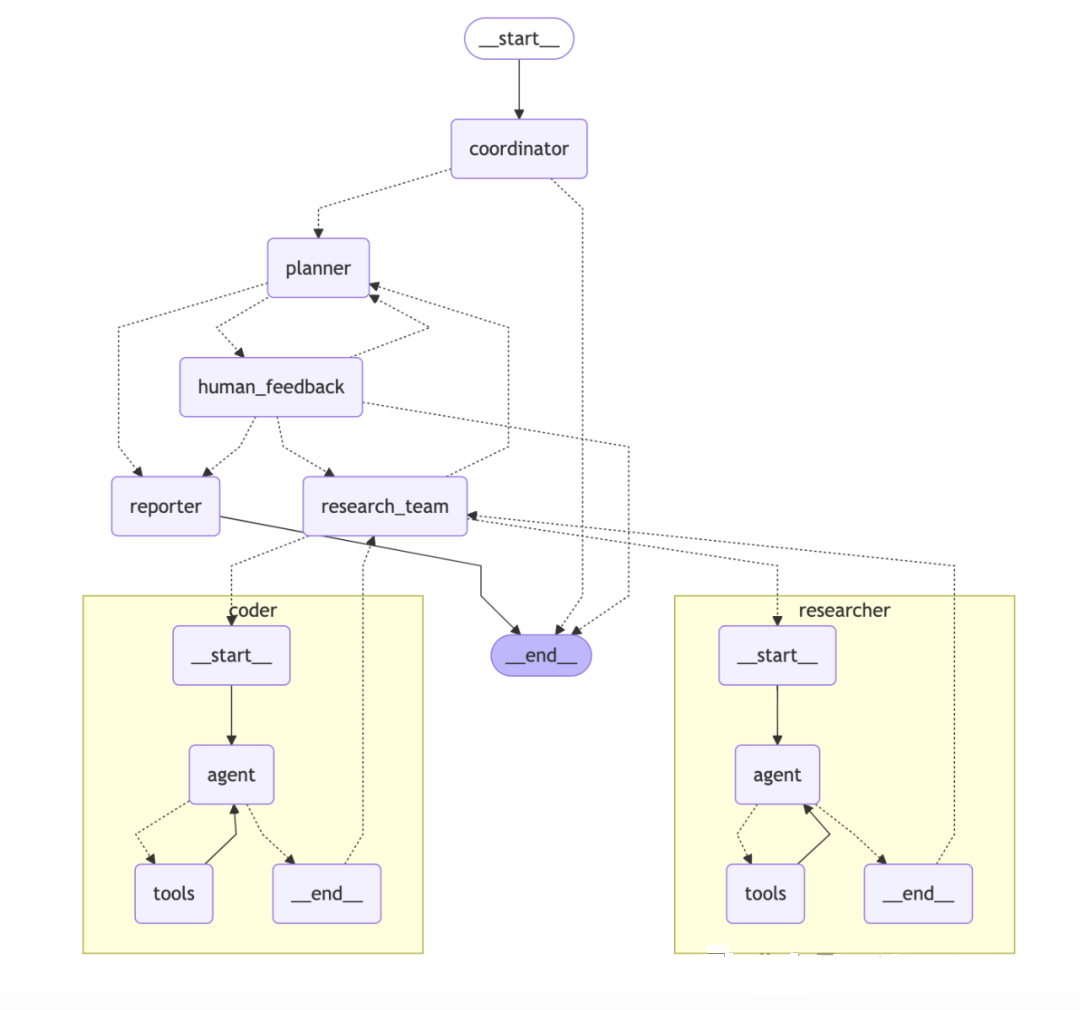
组件:
- 协调器:管理工作流生命周期的入口点
- 根据用户输入启动研究过程
- 在适当时候将任务委派给规划器
- 作为用户和系统之间的主要接口
- 规划器:负责任务分解和规划的战略组件
- 分析研究目标并创建结构化执行计划
- 确定是否有足够的上下文或是否需要更多研究
- 管理研究流程并决定何时生成最终报告
- 研究团队:执行计划的专业智能体集合:
- 研究员:使用网络搜索引擎、爬虫、MCP服务等工具进行网络搜索和信息收集。
- 编码员:使用Python REPL工具处理代码分析、执行和技术任务。
每个智能体都可以访问针对其角色优化的特定工具,并在LangGraph框架内运行
- 报告员:研究输出的最终阶段处理器
- 汇总研究团队的发现
- 处理和组织收集的信息
- 生成全面的研究报告
三层架构设计
| 架构层 | 核心组件 | 技术特点 |
|---|---|---|
| 协调层 | 任务规划器、状态管理器 | 基于LangGraph的DAG工作流,支持动态任务调整 |
| 执行层 | 搜索智能体、代码执行器、爬虫引擎 | 模块化设计,支持热插拔扩展 |
| 呈现层 | 报告生成器、播客合成器、PPT转换器 | 多模态输出,支持自定义模板 |
状态管理
工作流采用精密的状态管理系统(src/graph/types.py),追踪:
- 研究主题和澄清历史
- 计划迭代和执行结果
- 资源和观察记录
- 工作流控制参数
人在环中
DeerFlow包含一个人在环中机制,允许在执行研究计划前审查、编辑和批准:
- 计划审查:启用人在环中时,系统将在执行前向您展示生成的研究计划
- 提供反馈:
- 通过回复
[ACCEPTED]接受计划 - 通过提供反馈编辑计划(例如,
[EDIT PLAN] 添加更多关于技术实现的步骤) - 系统将整合您的反馈并生成修订后的计划
- 通过回复
- 自动接受:可启用自动接受以跳过审查过程:通过API在请求中设置
auto_accepted_plan: true - API集成:使用API时,可通过
feedback参数提供反馈:
{"messages": [{"role":"user","content":"什么是量子计算?"}],"thread_id": "my_thread_id","auto_accepted_plan": false,"feedback": "[EDIT PLAN]包含更多关于量子算法的内容"
}
搜索引擎
可在.env文件中通过SEARCH_API变量进行配置:
- Tavily(默认):专为AI应用设计的专业搜索API
- 需要在
.env文件中设置TAVILY_API_KEY - 注册地址:
https://app.tavily.com/home
- 需要在
- DuckDuckGo:注重隐私的搜索引擎,无需API密钥
- Brave Search:具有高级功能的注重隐私的搜索引擎
- 需要在
.env文件中设置BRAVE_SEARCH_API_KEY - 注册地址:
https://brave.com/search/api
- 需要在
- Arxiv:用于学术研究的科学论文搜索
- 无需API密钥
- 专为科学和学术论文设计
在.env文件中设置SEARCH_API变量,即可配置首选搜索引擎:
# 候选项:tavily, duckduckgo, brave_search, arxiv
SEARCH_API=tavily
LangGraph Studio
DeerFlow包含一个langgraph.json配置文件,定义LangGraph Studio的图结构和依赖关系,指向项目中定义的工作流图,并自动从.env文件加载环境变量。
实战
支持多种部署方式
uv:参考uv、Ruff、ty使用与实战nvm:轻松管理多个Node.js运行时版本pnpm:安装和管理Node.js项目的依赖
git clone https://github.com/bytedance/deer-flow.git
cd deer-flow
conda create -n deer-flow python=3.12
conda activate deer-flow
# 基于uv
uv sync
cp .env.example .env
cp conf.yaml.example conf.yaml
# 安装marp用于PPT生成
brew install marp-cli
# 控制台UI
uv run main.py
# 安装Web UI
cd deer-flow/web
pnpm install
pnpm run dev
# 运行所有测试
make test
# 运行特定测试文件
pytest tests/integration/test_workflow.py
# 运行覆盖率测试
make coverage
# 运行代码检查
make lint
# 格式化代码
make format
浏览器打开http://localhost:3000开始体验。
命令行使用
# 使用特定查询运行
uv run main.py "哪些因素正在影响医疗保健中的AI采用?"
# 使用自定义规划参数运行
uv run main.py --max_plan_iterations 3 "量子计算如何影响密码学?"
# 在交互模式下运行,带有内置问题
uv run main.py --interactive
# 使用基本交互提示运行
uv run main.py
# 查看所有可用选项
uv run main.py --help
应用程序支持多个命令行参数来自定义其行为:
- query:要处理的研究查询,可以是多个词
--interactive:以交互模式运行,带有内置问题--max_plan_iterations:最大规划周期数,默认1--max_step_num:研究计划中的最大步骤数,默认3--debug
TTS
TTS:通过/api/tts端点访问TTS功能:
# 使用curl的API调用示例
curl --location 'http://localhost:8000/api/tts' \
--header 'Content-Type: application/json' \
--data '{"text": "测试文本转语音功能","speed_ratio": 1.0,"volume_ratio": 1.0,"pitch_ratio": 1.0
}' \
--output speech.mp3
TTS功能作为独立工具实现,可被工作流中的不同Agent访问。采用模块化设计,职责分离明确:
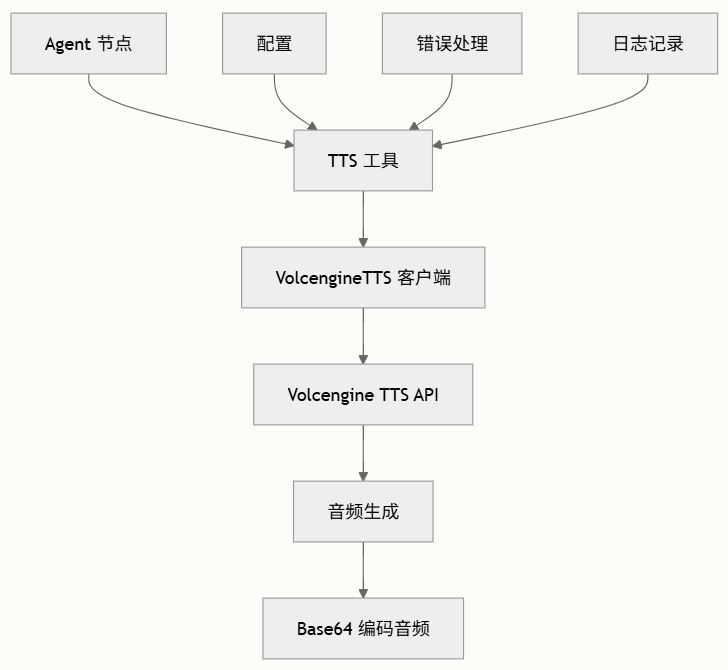
支持广泛的自定义选项:
| 参数 | 类型 | 默认值 | 范围/选项 |
|---|---|---|---|
text | str | 必需 | 要转换的输入文本 |
encoding | str | “mp3” | 音频格式(mp3、wav等) |
speed_ratio | float | 1.0 | 0.2-3.0 |
volume_ratio | float | 1.0 | 0.1-3.0 |
pitch_ratio | float | 1.0 | 0.1-3.0 |
text_type | str | “plain” | “plain"或"ssml” |
with_frontend | int | 1 | 0或1 |
frontend_type | str | “unitTson” | 前端处理类型 |
uid | str | 自动生成 | 用户标识符 |
PPT
采用两阶段方法:使用AI进行内容创作和使用Marp CLI进行文件生成,以最少的用户干预交付高质量的PowerPoint演示文稿。
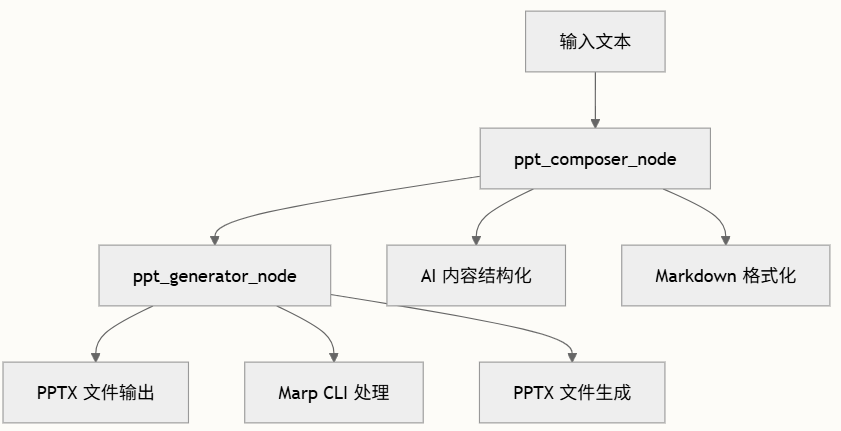
Mermaid语法:
源码
入口类
def _build_base_graph():builder = StateGraph(State)builder.add_edge(START, "coordinator")builder.add_node("coordinator", coordinator_node)builder.add_node("background_investigator", background_investigation_node)builder.add_node("planner", planner_node)builder.add_node("reporter", reporter_node)builder.add_node("research_team", research_team_node)builder.add_node("researcher", researcher_node)builder.add_node("coder", coder_node)builder.add_node("human_feedback", human_feedback_node)builder.add_edge("background_investigator", "planner")builder.add_conditional_edges("research_team",continue_to_running_research_team,["planner", "researcher", "coder"],)builder.add_edge("reporter", END)return builder
解读:包含八个节点的有向图结构。执行流程从协调器开始,通过条件边控制智能体之间的流转;将复杂的问答任务分解为多个相对独立的处理步骤。
流式响应
_astream_workflow_generator函数基于SSE,源码略。将LangGraph的异步流处理与FastAPI的StreamingResponse结合。系统能够区分不同类型的消息事件(工具调用、AI响应块、中断信号等),并为每种类型生成相应的SSE事件。
def _make_event(event_type: str, data: dict[str, any]):if data.get("content") == "":data.pop("content")return f"event: {event_type}\ndata: {json.dumps(data, ensure_ascii=False)}\n\n"
这个函数将结构化数据转换为符合SSE标准的文本格式。支持多种事件类型,包括消息块、工具调用、工具调用结果和中断信号。
LLM集成
多模型配置管理,支持多种类型的语言模型,通过配置文件和环境变量进行管理,源码。
def _create_llm_use_conf(llm_type: LLMType, conf: Dict[str, Any]) -> BaseChatModel:llm_type_config_keys = _get_llm_type_config_keys()config_key = llm_type_config_keys.get(llm_type)if not config_key:raise ValueError(f"Unknown LLM type: {llm_type}")llm_conf = conf.get(config_key, {})if not isinstance(llm_conf, dict):raise ValueError(f"Invalid LLM configuration for {llm_type}: {llm_conf}")env_conf = _get_env_llm_conf(llm_type)merged_conf = {**llm_conf, **env_conf}if "token_limit" in merged_conf:merged_conf.pop("token_limit")if not merged_conf:raise ValueError(f"No configuration found for LLM type: {llm_type}")if "max_retries" not in merged_conf:merged_conf["max_retries"] = 3verify_ssl = merged_conf.pop("verify_ssl", True)if not verify_ssl:http_client = httpx.Client(verify=False)http_async_client = httpx.AsyncClient(verify=False)merged_conf["http_client"] = http_clientmerged_conf["http_async_client"] = http_async_client
platform = merged_conf.get("platform", "").lower()is_google_aistudio = platform == "google_aistudio" or platform == "google-aistudio"if is_google_aistudio:gemini_conf = merged_conf.copy()if "api_key" in gemini_conf:gemini_conf["google_api_key"] = gemini_conf.pop("api_key")gemini_conf.pop("base_url", None)gemini_conf.pop("platform", None)gemini_conf.pop("http_client", None)gemini_conf.pop("http_async_client", None)return ChatGoogleGenerativeAI(**gemini_conf)if "azure_endpoint" in merged_conf or os.getenv("AZURE_OPENAI_ENDPOINT"):return AzureChatOpenAI(**merged_conf) if "base_url" in merged_conf and "dashscope." in merged_conf["base_url"]:if llm_type == "reasoning":merged_conf["extra_body"] = {"enable_thinking": True}else:merged_conf["extra_body"] = {"enable_thinking": False}return ChatDashscope(**merged_conf)if llm_type == "reasoning":merged_conf["api_base"] = merged_conf.pop("base_url", None)return ChatDeepSeek(**merged_conf)else:return ChatOpenAI(**merged_conf)
定义三种LLM类型:推理模型(reasoning)、基础模型(basic)和视觉模型(vision)。配置管理采用层级覆盖的方式,环境变量的优先级高于配置文件。
模型类型映射通过_get_llm_type_config_keys函数定义,这种分类方式反映不同智能体对模型能力的差异化需求。
Node
源码,包括如下几种节点(可理解为智能体Agent)类型:
- coordinator_node:协调器,工作流入口,管理整个工作流生命周期并启动研究流程;
- planner_node:规划器,战略组件,分析研究目标并创建结构化执行计划;
- researcher_node:执行网页搜索和信息收集;
- coder_node:使用Python REPL处理代码分析和执行;
- human_feedback_node:需要人类反馈,实现人在环中;
- reporter_node:汇总研究成果并生成综合报告;
- research_team_node:暂未实现
coordinator_node
协调器作为系统的入口点,负责对用户输入进行分类和路由。协调器通过调用handoff_to_planner工具来判断是否需要启动研究流程。根据其提示词模板,系统将用户请求分为三类:简单问候(直接处理)、有害请求(礼貌拒绝)和研究类问题(交给规划器处理)。
planner_node
源码,规划器负责将复杂问题分解为可执行的子任务。
规划器会首先评估当前可用信息是否足以回答用户问题。根据提示词内容,只有在信息确实充足的情况下,系统才会直接生成最终报告。否则,规划器会创建包含多个步骤的研究计划。
从提示词设计可看出,系统在信息充足性判断上采用较为严格的标准。即使有90%的把握,系统仍倾向于收集更多信息。这种保守策略有助于确保最终答案的准确性和完整性。提示词文件路径为:src/prompts/planner.md
researcher_node
研究员配备三类工具:网络搜索工具、网页抓取工具和本地检索工具,工具加载顺序体现系统的优先级策略:优先使用本地资源,然后是网络搜索和页面抓取。
coder_node
编码员节点,配备Python REPL工具,用于执行代码相关的任务,如数据分析、计算验证等。
步骤执行的通用逻辑在_execute_agent_step函数中实现,负责找到当前需要执行的步骤,并为智能体准备相应的输入。系统会将已完成步骤的信息一并提供给当前执行的智能体,确保上下文的连贯性。
MCP
允许系统在运行时动态加载外部工具,源码略,支持三种MCP传输方式:stdio、SSE、streamable_http,可在运行时集成各种外部服务,如GitHub trending工具、地图服务等。不同的协议构造不同的客户端,如stdio_client、sse_client、streamablehttp_client,最后都是通过调用函数_get_tools_from_client_session获取具体的工具。
配置
支持多层级的参数覆盖,源码
@dataclass(kw_only=True)
class Configuration:resources: list[Resource] = field(default_factory=list)max_plan_iterations: int = 1max_step_num: int = 3max_search_results: int = 3mcp_settings: dict = Nonereport_style: str = ReportStyle.ACADEMIC.valueenable_deep_thinking: bool = Falseenforce_web_search: bool = (False)interrupt_before_tools: list[str] = field(default_factory=list)@classmethoddef from_runnable_config(cls, config: Optional[RunnableConfig] = None) -> "Configuration":configurable = (config["configurable"] if config and "configurable" in config else {})values: dict[str, Any] = {f.name: os.environ.get(f.name.upper(), configurable.get(f.name))for f in fields(cls)if f.init}return cls(**{k: v for k, v in values.items() if v})
使用dataclass装饰器,定义系统运行所需的各种参数。配置的加载顺序是:环境变量优先于RunnableConfig中的配置值。
递归限制的配置:
def get_recursion_limit(default: int = 25) -> int:env_value_str = get_str_env("AGENT_RECURSION_LIMIT", str(default))parsed_limit = get_int_env("AGENT_RECURSION_LIMIT", default) if parsed_limit > 0:return parsed_limitelse:return default