【Agentic RL专题】一、LLM agent 与 agentic RL

🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
相信初学的小伙伴会对
LLM agent以及Agentic RL两个名词有点混淆,因此,对于这两个名词的解释将作为专题第一章,带你深入理解LLM agent以及Agentic RL的区别
文章目录
- 一、为什么我们需要 Agentic RL?
- 二、两条研究主线:LLM Agents 与 RL for LLMs
- 三、静态对齐 vs. 动态决策
- 四、马尔可夫决策过程
- 五、奖励设计:从静态偏好到动态任务反馈
- 六、总结
- 🧠 下一步:走向策略优化(PPO)
一、为什么我们需要 Agentic RL?
在系统的学习agentic RL之前,我们需要去了解两个问题:① 什么是agent ② LLM agent 与 agentic RL之间有什么联系
过去几年,LLM 的飞速发展让语言理解与生成达到了惊人的水平——但在“行动”层面,它依然是被动的。给它一个 prompt,它给你一段回答。但这并不是智能,他更像是现代的“百度”,为我们提供答案。LLM 就像是一个知识库反馈我们答案
大语言模型(LLM)已经能写诗、写代码、答题——但它不会自己去行动。
比如它知道“去查天气”,但不会真的去打开天气网站。
那么,如何让它能感知世界、做决策、执行行动?
这正是Agent想要解决的问题。
因此,智能体(Agent)还需要:
- 感知(Perception):理解环境、状态、反馈;
- 规划(Planning):制定策略、选择行动;
- 执行(Action):调用工具、发出指令;
- 反思(Reflection):评估行动是否有效;
- 记忆(Memory):保留长期经验,形成习惯与风格
这些功能在专题会继续研究。
也就是说,① 现在的大语言模型我们更想让他成为一个智能体Agent,不仅仅是需要让他输出文字,还需要有感知、规划、推理、调用工具、维护记忆、适合策略等的能力。除此之外,② 强化学习 (Reinforcement Learning, RL) 正是让模型“学会在交互中行动”的关键。 而当这种强化学习与大型语言模型(LLM)结合——让语言模型从“说得对”变成“做得对”——就形成了一个新的研究分支:🧠 Agentic Reinforcement Learning (Agentic RL) ——让 LLM 成为会行动的智能体。

二、两条研究主线:LLM Agents 与 RL for LLMs
Agentic RL 的研究在这之前大致可以分为两条主线 : ① LLM Agents ② RL for LLMs

-
LLM Agents:研究
LLMs在交互式环境里能否自主完成任务。重点是让 LLM 具备感知、规划、推理、工具调用、记忆维护、交互等能力,像一个决策者一样行动。代表工作包括基于 ReAct、AutoGPT、Voyager 等框架的 LLM agents -
RL for LLMs:研究强化学习方法优化 LLM 的行为,让模型更符合人类或任务需求。最典型的是RLHF(从人类反馈中强化学习),以及其衍生的RLAIF、DPO、ORPO 等,用于对齐人类偏好。
| 分支 | 研究目标 | 代表工作 |
|---|---|---|
| LLM Agents | 让 LLM 拥有感知、规划、行动、反思的能力 | ReAct, AutoGPT, Voyager, MetaGPT, MemGPT |
| RL for LLMs | 用强化学习优化 LLM 行为,使其更符合人类或任务偏好 | RLHF, RLAIF, DPO, ORPO, GRPO, AgentTune |
硬币的两面:
- LLM Agents 关注“怎么让模型动起来”;
- RL for LLMs 关注“怎么让动作越来越聪明”。
最终,这两条路径正在融合——形成一个能“自主学习与改进”的智能体生态。
三、静态对齐 vs. 动态决策
1️⃣ RLHF——静态对齐
在过去的 RLHF(Reinforcement Learning from Human Feedback)中,例如InstructGPT的训练流程大致如下:
- 收集 prompt 与回答样本;
- 用人类标注的偏好训练奖励模型 (Reward Model, RM);
- 让语言模型通过 PPO 等算法最大化奖励分数。
这个过程的本质是单步强化学习:
- 输入 prompt → 输出完整回答;
- 奖励仅取决于最终输出;
- 没有过程状态的变化,也没有多步决策。
2️⃣ Agentic RL——动态决策
当我们更希望我们的模型能够:
- 主动去检索资料,
- 调用计算工具或执行代码,
- 与用户进行多轮交互,
- 或者在一个游戏/任务环境中逐步推理与探索,
那么原来的“一步到位”训练方式就不够用了。我们需要的是:多步决策 的强化学习。Agentic RL 把 LLM 看作一个“语言驱动的决策体”:
- 每一次生成 token、调用 API、执行代码,都是一个动作 (Action);
- 每一次环境反馈(检索结果、计算结果、用户回应)都是一个新状态 (State);
- 模型的目标是最大化长期累计奖励 (Return),不仅仅是“最终结果正确”,还包括“过程是否高效、合理、符合逻辑”。
四、马尔可夫决策过程
强化微调可以被认为是一个马尔可夫决策过程,一共包含了七个过程元素<S,O,A,P,R,T,γ><S,O,A,P,R,T,\gamma><S,O,A,P,R,T,γ>:
| 变量名 | 含义 |
|---|---|
S | 环境状态(包含任务上下文、历史、工具状态等) |
O | 模型能观察到的部分状态(可见内容) |
A | 模型的动作(生成 token、调用函数、发出指令) |
R | 奖励函数(任务成功率、逻辑正确性、工具使用效率) |
P | 状态转移概率(执行动作后环境变化) |
T | 任务步数上限 |
| γ\gammaγ | 折现因子(平衡短期与长期回报) |
RLHF 是单次决策的结果,不依赖过程的决策,通过起始状态S={prompt},执行一次动作为模型的输出,不需要有过程的输出以及奖励,因此在PBRFT中T = 1, y无效,并且下一个状态是确定的。就像在InstructGPT中一样,我们首先会构建偏好数据集训练一个奖励函数,其中prompt就是起始状态,而最后模型也只会根据输出进行奖励,训练目标是最大化似然估计输出。因此我们可以把 RLHF 看作是一种 偏好驱动的强化式微调(PBRFT / RFT),对应于一个简化的 MDP:
T=1,S=prompt,A=generatey,R=RM(y),P(S′∣S,A)=1T=1, S={prompt}, A={generate_y}, R=RM(y), P(S′∣S,A)=1T=1,S=prompt,A=generatey,R=RM(y),P(S′∣S,A)=1
Agentic RL被当作连续决策的智能体,每次动作的执行都可以观察到部分信息:包括外部环境、工具/代码运行的中间结果、数据库/网页内容、会话历史、代理的内存等。状态是不断变化的.有多步交互(T>1)、中间会拿到/影响后续信息与奖励,这时才需要γ\gammaγ来权衡短期和长期,训练会用终点奖励(目标是否完成)+ 过程奖励(步骤是否正确),属于POMDP、多步决策。
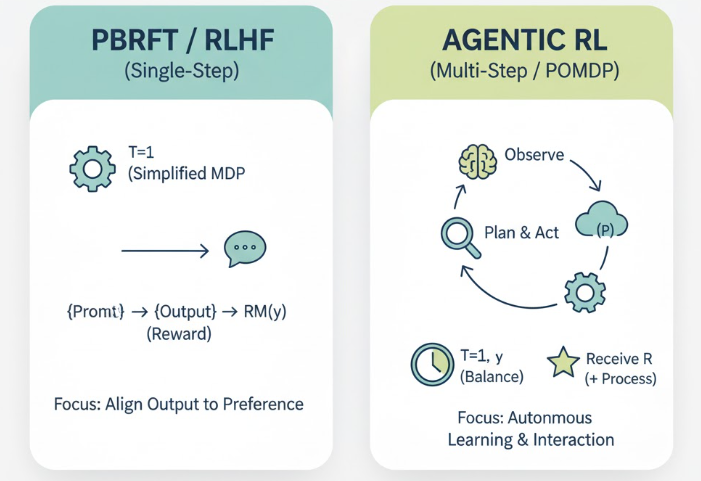
五、奖励设计:从静态偏好到动态任务反馈
在 Agentic RL 中,奖励不再只是“人类喜欢哪种回答”,而是更复杂的组合:
| 奖励类型 | 含义 | 例子 |
|---|---|---|
| 终点奖励 (Final Reward) | 任务是否完成 | 答案是否正确、任务是否达成 |
| 过程奖励 (Process Reward) | 行为过程是否合理 | 推理链条正确、逻辑合理、调用顺序合规 |
| 辅助奖励 (Auxiliary Reward) | 提升训练稳定性 | 输出长度、token 效率、工具使用代价 |
| 社会奖励 (Social Reward) | 人类偏好或安全性 | 是否有害、是否礼貌、是否合乎伦理 |
一种典型的实现方式是使用 PRM(Process Reward Model):
- PRM 不是只给最终答案打分,而是给整个 reasoning chain(例如一步步推理的过程)进行局部奖励;
- 这让 LLM 可以学会 “每一步都做得对”,而不是“结果对了就行”。
六、总结
我们在这一篇中,从最直觉的问题——“为什么 LLM 需要行动能力?”——出发,逐步理解了 Agentic RL(智能体强化学习) 的核心思想:
- 从语言到行动:
传统的 LLM 只会被动回答,而 Agentic RL 让它学会“感知—思考—行动—反思”,成为真正的智能体(Agent)。 - 两条发展主线:
- 一条是构建具备工具使用、记忆、推理能力的 LLM Agents;
- 另一条是用强化学习优化 LLM 的策略,即 RL for LLMs(例如 RLHF、DPO、RLAIF)。
它们正在融合,目标是让模型能在交互中不断提升自己。
- 静态对齐 vs. 动态决策:
RLHF 属于“单步决策”,仅优化最终回答;
Agentic RL 则是“多步决策”,模型需要在复杂环境中持续决策与调整。 - 统一视角:马尔可夫决策过程(MDP):
无论是 RLHF 还是 Agentic RL,本质上都是在学习“在某个状态下,执行哪个动作能获得更高的长期奖励”。 - 奖励函数的演化:
从“人类喜欢什么样的回答”扩展到“模型在执行过程中是否做得对”,
这让 LLM 真正具备了推理与改进的能力。
从“输出答案”到“行动决策”,Agentic RL 是让语言模型从“被动大脑”走向“主动智能”的关键一步。
🧠 下一步:走向策略优化(PPO)
理解了“为什么要强化学习”和“Agentic RL 的概念”,接下来我们就要进入最核心的算法——
👉 Proximal Policy Optimization(PPO)。
它是目前最主流、最稳定的强化学习方法,也是 RLHF 与 Agentic RL 的基石。
下一篇我们将详细拆解 PPO 的原理、推导与代码实现,从直觉到数学,一步步理解它如何让语言模型变得“又稳又聪明”。